 Slashdot Mirror
Slashdot Mirror
Domain: w3.org
Stories and comments across the archive that link to w3.org.
Comments · 6,785
-
CSS validator useless
I just had some experience with the CSS validator (http://jigsaw.w3.org/css-validator/validator.htm
l .en) since I tried to make my new pages CSS compliant. First even if I choose "English" on the front page the results are in "German". My dear, before making pages conform to standards they should first be functional correct. How could W3C put up such a silly beginners mistake.
Yet whenever an error is spotted the resulting error message is more or less useless.
td,th,tr{
align:left;
vertical-align:baseline;
}
=> td, th, tr Die Eigenschaft align existiert nicht : left
Now each browser I tried interprets this correct even if it might be wrong formulated. Why can't the validator detect it as well and give a better error message?
Another case is the "size=1" argument in a "select" statement.
select.mini {
width:10em;
size:1;
}
=> select.mini Ungültige Nummer : size Die Eigenschaft size existiert nicht : 1
Again any browser is able to interpret this correct only the validator isn't.
The question arises why have the W3C validator such silly beginners syntax detection while any browser is far better? How can standardization been taken serious if W3C can't provide better tools?
O. Wyss -
Re:10 years
http://www.w3.org/Style/Examples/007/center-examp
l e.html should do the trick, although I tend to be among those ridiculing the CSS zealots who resort to obscene hacks to get around using tables. This example seems like kind of a copout, since it uses the display:table functionality in CSS. So, you can't use a table, but it's perfectly fine to use a and tell the browser to render it like a table -
Heh, those funny typos
Nice to know that not even W3C can afford to spell check everything: teached CSS. It's not just
-
Slashdot using invalid css?
Trying slashdot.org on article's link http://www.w3.org/Style/CSS10/
18 December 2006 - Fuji CSS Validator released (more) http://jigsaw.w3.org/css-validator/
--
W3C CSS Validator Results for http://www.slashdot.org/
Sorry! We found the following errors
URI : http://images.slashdot.org/base.css?T_2_5_0_138
16 h1, h2, h3, h4, h5, h6 Invalid number : text-shadow Property text-shadow doesn't exist : #000 0 0 0
176 Invalid number : min-width Property min-width doesn't exist : 0
178 Combinator ~ between selectors is not allowed in this profile or version
345 div.storylinks ul li.comments Invalid number : text-shadow Property text-shadow doesn't exist : #000 0 0 0
638 div.storylinks ul li.bin Invalid number : text-shadow Property text-shadow doesn't exist : #000 0 0 0
659 a.ac-source Invalid number : background-color darkgray is not a color value : darkgray
668 #ac-select-widget Invalid number : background-color lightgray is not a color value : lightgray
674 #ac-select-widget input Invalid number : border lightgray is not a color value : 2px solid lightgray
688 #ac-choices
URI : http://images.slashdot.org/slashdot.css?T_2_5_0_13 8
15 a#newuser Invalid number : text-shadow Property text-shadow doesn't exist : #000 0 0 0
Warnings (224)
URI : http://images.slashdot.org/handheld.css?T_2_5_0_13 8
17 Same colors for color and background-color in two contexts #logo h1 a and #slogan h2
26 Same colors for color and background-color in two contexts div#links div.block div#links-sections-title and
26 Same colors for color and background-color in two contexts div.block div.title and
26 Same colors for color and background-color in two contexts div#links div.block div#links-sections-title and
26 Same colors for color and background-color in two contexts div#links div.block div.title and -
Slashdot using invalid css?
Trying slashdot.org on article's link http://www.w3.org/Style/CSS10/
18 December 2006 - Fuji CSS Validator released (more) http://jigsaw.w3.org/css-validator/
--
W3C CSS Validator Results for http://www.slashdot.org/
Sorry! We found the following errors
URI : http://images.slashdot.org/base.css?T_2_5_0_138
16 h1, h2, h3, h4, h5, h6 Invalid number : text-shadow Property text-shadow doesn't exist : #000 0 0 0
176 Invalid number : min-width Property min-width doesn't exist : 0
178 Combinator ~ between selectors is not allowed in this profile or version
345 div.storylinks ul li.comments Invalid number : text-shadow Property text-shadow doesn't exist : #000 0 0 0
638 div.storylinks ul li.bin Invalid number : text-shadow Property text-shadow doesn't exist : #000 0 0 0
659 a.ac-source Invalid number : background-color darkgray is not a color value : darkgray
668 #ac-select-widget Invalid number : background-color lightgray is not a color value : lightgray
674 #ac-select-widget input Invalid number : border lightgray is not a color value : 2px solid lightgray
688 #ac-choices
URI : http://images.slashdot.org/slashdot.css?T_2_5_0_13 8
15 a#newuser Invalid number : text-shadow Property text-shadow doesn't exist : #000 0 0 0
Warnings (224)
URI : http://images.slashdot.org/handheld.css?T_2_5_0_13 8
17 Same colors for color and background-color in two contexts #logo h1 a and #slogan h2
26 Same colors for color and background-color in two contexts div#links div.block div#links-sections-title and
26 Same colors for color and background-color in two contexts div.block div.title and
26 Same colors for color and background-color in two contexts div#links div.block div#links-sections-title and
26 Same colors for color and background-color in two contexts div#links div.block div.title and -
Re:10 years old...
With CSS, it is all about theory, without real world tests.
On the contrary, some of the most frequently complained about shortcomings of CSS are due to the desire to keep implementations simple, which is practically the opposite of being "all about theory". They purposefully left out things like a decent query mechanism because they considered it too hard for people to implement.
The only reason it got pushed as standard, is because the web evolved too fast for its own good, and no one realised what was happening before it was too late, to propose an alternative to CSS.
No, Netscape implemented an alternative (JSSSL) and submitted it to the W3C for standardisation. It was more powerful than CSS, and that's one of the reasons why CSS was a better choice.
-
Re:Good but not all there yet.
I hate to praise IE but IE has a way to only load certains stylesheets for IE or even certain versions of IE. It'd be nice to see that built into the standard so it'd be easier to make minor tweaks for individual cases.
Delivering differentiated content to work around buggy user-agents is a function of the transport protocol, not something you want to replicate for each and every file format delivered over that protocol. It is built into the standard - the right standard for this, HTTP. I quote from RFC 2616:
The User-Agent request-header field contains information about the user agent originating the request. This is for statistical purposes, the tracing of protocol violations, and automated recognition of user agents for the sake of tailoring responses to avoid particular user agent limitations.
Of course, it isn't reliable, but that's because of abuse from both web developers and browser developers. It's only in the face of this abuse that stupid workarounds in particular file formats is necessary.
Heck, I like to switch stylesheets based on window size even so why not make that possible also without resorting to Javascript
That's already possible with CSS 3 Media Queries, already implemented by Opera.
-
Uh oh
Uh oh
#navigation li Invalid number : text-shadow Property text-shadow doesn't exist : 0 2px 4px #000 -
Ten Year Anniversary Page @ w3c.org
http://www.w3.org/Style/CSS10/ first link points to the press release and the CSS Hall of Fame is worth visiting, too!
It was about ten years ago that I saw Hakon present CSS to some of the engineers and product managers at Netscape, where I was a technology evangelist. That was a great moment in my career, where I knew how much trouble we had with the rendering engine as well as how much responsibility we had to fight the good fight for standards.
Thanks to Hakon and Bert, congrats to the w3c, and keep on on styling your designs!
-
Ten Year Anniversary Page @ w3c.org
http://www.w3.org/Style/CSS10/ first link points to the press release and the CSS Hall of Fame is worth visiting, too!
It was about ten years ago that I saw Hakon present CSS to some of the engineers and product managers at Netscape, where I was a technology evangelist. That was a great moment in my career, where I knew how much trouble we had with the rendering engine as well as how much responsibility we had to fight the good fight for standards.
Thanks to Hakon and Bert, congrats to the w3c, and keep on on styling your designs!
-
Re:More "Cookie Monster" HysteriaSince you know what CGI stands for, perhaps you should read the description of it as well. Emphasis added by me.
The Common Gateway Interface, or CGI, is a standard for external gateway programs to interface with information servers such as HTTP servers.
Webservers don't create the CGI environment unless they're calling a CGI script. Some webserver modules duplicate the CGI environment as well: SSI and PHP as examples.
The referrer is an HTTP header, specifically the Referer header. I also mentioned Browser, so I'll point out the User-Agent header as well. -
Re:More "Cookie Monster" HysteriaSince you know what CGI stands for, perhaps you should read the description of it as well. Emphasis added by me.
The Common Gateway Interface, or CGI, is a standard for external gateway programs to interface with information servers such as HTTP servers.
Webservers don't create the CGI environment unless they're calling a CGI script. Some webserver modules duplicate the CGI environment as well: SSI and PHP as examples.
The referrer is an HTTP header, specifically the Referer header. I also mentioned Browser, so I'll point out the User-Agent header as well. -
Re:MS no longer "supports" win 2000
This has been covered before, but PNG transparency is considered "Ancillary Chunks" in the PNG spec that clearly describes it as an optional feature. While I generally agree that IE should have supported this for a long time because it is useful, you cannot classify it as a bug, since it wasn't broken, they just chose not to implement that feature. Once it became clear that many people wanted that feature, support was added through existing "AlphaImageLoader" techniques that you can find easily by searching. I do not know the reason they waited until IE7 to natively support it without CSS/Scripting hacks, but it probably related to breaking other stuff and not having the time to effectively QA the impact, especially knowing that a workaround existed. This is pretty common behavior for any software development company.
From w3c PNG spec: http://www.w3.org/TR/2003/REC-PNG-20031110/#11Anci llary-chunks
11.3 Ancillary chunks
11.3.1 General
The ancillary chunks defined in this International Standard are listed in the order in 4.7.2: Chunk types. This is not the order in which they appear in a PNG datastream. Ancillary chunks may be ignored by a decoder. For each ancillary chunk, the actions described are under the assumption that the decoder is not ignoring the chunk.
11.3.2 Transparency information
Note the "Ancillary chunks may be ignored by a decoder".
You can read the blog entry for the guy who added the PNG support in IE7 and it pretty much sums up that it wasn't added for a long time due to the breadth of the changes required to support it that might break other stuff. Again, seems like pretty reasonable behavior here, no grand conspiracy to ignore customers.
http://blogs.msdn.com/ie/archive/2005/04/26/412263 .aspx
-David -
Re:No...
The W3C doesn't make a browser (that I know of).
The W3C's browser is called Amaya It's been around for quite a while. -
From a non-profit standpoint
I work as the web master for a non-profit or not-for-profit group (I personally do not know its IRS filing status). One of the requirements written into our web publishing policies is that it must meet W3C accessibility guild lines. By default, this means that it must be reasonably standards compliant. I run into no issues making it work on any browser other then IE.
The thing I find most annoying is that everyone seems to consider writing a standards complaint web page is difficult. It's not unless you are using a WYSIWYG generator, especially FontPage, or your site requires JavaScript to display properly. Both of which are extremely bad practices for professional web sites and make them near impossible to read on hand held devices and screen readers for the blind.
For all of you web developers that have no idea why what I am talking about is such a big deal. As was mentioned in an earlier post, check out the Lynx text-only web browser and view your sites. Please note: Everything you see in the Lynx browser is all your average screen reader for the blind can see! Now, before I get nick-picked. There are better screen readers for the blind out there that can see more but, these programs cost money that blind people often do not have.
So please, don't be a web dork (name a co-worker called "web masters" that knew nothing more then FrontPage/Dreamweaver and didn't even know what an
-
Re:Where is the story here?
Oh, yes and the MBTA also sucks. And maybe their web site sucks, or maybe it doesn't.
Well the MBTA site sucks whether you look at the standards compliance or even just the general usability.
-
If you want it to work in your browser
you're a lot better just asking for W3 compliance than "support $my_browser because I use it". If it follows the W3 standard, we can all use it, and if we can't, it's because of our browser. Run the site through http://validator.w3.org/ and send them the URL as well as their list of errors.
-
Re:Protected blog, full text of post
Oddly enough, your link shows their page has 40 errors. Antiwar.com, the page you support by claiming it as your homepage, has 258 errors. Go ahead and check my homepage... here, I'll even link it for you... skorchedearth.
-
Re:Protected blog, full text of post
He's clearly ranting, and it doesn't all make sense.
If he doesn't care if pages work in someone else choice of browser why would anyone care if they work in his?
Personally, I do care that data which is presented as being a 'web page' should, in fact, be a web page. Web pages work in any browser, barring browser bugs.
So the question for me is, does this page not work in opera because the page is wrong, or because of a bug in Opera? I haven't used Opera in a long time, but it used to be a very solid browser with very few bugs when I used it, and I suspect it still is. Nonetheless, generalities don't solve the problem, specifics do. Is Opera correctly displaying a broken page, or is it displaying a good page improperly?
The page in question is far from a good web page, which reïnforces my suspicion, but still, does anyone know exactly the issue in question here?
-
Re:gecko 1.9
Maybe not, but it sounds like it will render obsolete most computers developed before the past 5 years. Nothing before Windows 2000 is compatible with the new version of Gecko? It sounds like something is wrong with that.
Pre-Win2K? Sure! People can install stable Debian, build Firefox 3 from source, and yep, it works... =)
(Kidding. I'm a Debian user.)
I guess the statement was just meant to say that this page's rendering doesn't break. =)
-
"Also, the first Web browsers."
Um. Yeah. Er.
"WorldWideWeb was written in Objective-C." -
Semantic Web - the new FIPA
It's all very well these hucksters peddling the semantic web to funding bodies who don't know any better, as long as they don't start pretending it's anything other than the new FIPA - a collection of committees generating specifications that the world will continue to ignore.
-
Re:The two that matter
There's only two that really reflect the power of Pagerank: Click here.
About 1.2 billion pages, and surprise surprise, Acrobat Reader tops the list, followed by a who's who of internet applications and plugins. But around result #30 it gets a bit more interesting, and when you're a few dozen pages in, "new patterns begin to emerge."
And to explain why not to use "click here", I found this buried on page 45. Thanks for the proof pudding guys, it's delicious. -
Re:it's a rather straightforward observationXML was intended to be easy to PARSE, not easy to read. From the Origin and Goals of XML: XML documents should be human-legible and reasonably clear. True, their primary purpose isn't to be read by human beings, but comparatively it is superior to non-ASCII binary formats by what I would say a significant amount.
-
Re:Tables should not be used for layout!
<font> and <table> are in the HTML 4 and XHTML 1.0 specifications.
According to the W3C HTML 4 Specification:
15.2.2 Font modifier elements: FONT and BASEFONT
FONT and BASEFONT are deprecated. -
CSS supports table layout
The CSS 2 standard actually supports table-based layout applied to any markup. However, it's one of the many things that Microsoft simply haven't bothered to implement in their butchered tag soup layout engine. Let's not blame CSS here, but instead blame the one browser that leaves out the two most important layout features of CSS: the table model and generated content. With those two things, the common grid-based layouts that we all desire would be so much easier to create.
There are still several things missing in CSS2, of course. Many of them are addressed in CSS3, but I doubt that'll ever see the light of day.
-
CSS supports table layout
The CSS 2 standard actually supports table-based layout applied to any markup. However, it's one of the many things that Microsoft simply haven't bothered to implement in their butchered tag soup layout engine. Let's not blame CSS here, but instead blame the one browser that leaves out the two most important layout features of CSS: the table model and generated content. With those two things, the common grid-based layouts that we all desire would be so much easier to create.
There are still several things missing in CSS2, of course. Many of them are addressed in CSS3, but I doubt that'll ever see the light of day.
-
Re:Just sit back...
What kind of programmer can't use XML effectively anyhow...oh wait... (No, I didn't read TFA!)
Helpful hint for understanding the above: Tim Bray, author of TFA, is one of the guys who originally developed and spec'd out XML. Really. His name's on the spec and everything. So if he says that a particular XML tool has problems, it's probably a good idea to take him at his word
-
Re:and Google has ...
Which Google have you been looking at?
-
Re:what I want
Sorry, I guess I wasn't specific enough.
I don't want a book. I just want an abridged version of http://www.w3.org/TR/CSS21/ with all the unsupported parts cut out. -
Re:I must say.I don't really think that there's anything particularly special or important about the W3C that makes their arbitary standards better than somebody else's arbitrary standards.
Too bad the standards aren't arbitrary. The W3C is an international consortium which holds meetings to try and get a consensus on what a web standard should be. Microsoft is part of this consortium but even after agreeing to the standards, chooses to ignore them.So who's fault is it again for not following the standards?
-
Re:I must say.I don't really think that there's anything particularly special or important about the W3C that makes their arbitary standards better than somebody else's arbitrary standards.
Too bad the standards aren't arbitrary. The W3C is an international consortium which holds meetings to try and get a consensus on what a web standard should be. Microsoft is part of this consortium but even after agreeing to the standards, chooses to ignore them.So who's fault is it again for not following the standards?
-
Re:Right case-wrong reasonStandards are important
One reason for the fire's duration was the lack of national standards in fire-fighting equipment. Although fire engines from nearby cities (such as Philadelphia and Washington, as well as units from New York City, Wilmington, and Atlantic City) responded, many were useless because their hose couplings failed to fit Baltimore hydrants. As a result, the fire burned over 30 hours, destroying 1,526 buildings spanning 70 city blocks.
Organisations like http://www.w3.org/ who publish open standards are important because it ensures that we're not stuck with a monoculture. This isn't about 'who sets the standards' so much as once a standard is set that more than one party is allowed to play. So there's two problems:Microsoft not playing by everyone else's standards hurts interoperability which hurts competition and leaves the computing world open to the problems of a mono-culture that gets basically wiped out by a single virus.
And MS generally has closed standards (word doc anyone?), meaning they are the only ones who can make a product that meets the standard. MS is free to publish/maintain any __open__ standard they wish and some segment of the computing world will follow their lead. In the absence of this, organisations like w3c, asni etc will form standards and people will follow their lead.
MS is all about embrace, extend and extinguish: that's not helping create interoperable products.
-
Don't test sites on browsers
Test your sites on the W3C's validators . That's the only testing you should EVER do.
-
Re:cough HYPERCARD cough
Point 1: Yes, Interface Builder and NeXTstep predate the web: The "web" was _created_ with Interface Builder and NeXTstep! Tim Berners-Lee says "
The first web browser was implemented in NeXTstep and was also the first web editor. The World Wide Web application was a WYSIWYG editor with collaborative user editing features far beyind standard wiki today.
pictures: http://info.cern.ch/NextBrowser.html
"It has taken a long time for technology to catch up with Berners-Lee's original vision. The first ever web browser was also an editor, making the web an interactive medium, the problem was that it only ran on the NeXTStep operating system."
Tim Berners-Lee worte "I wrote the program using a NeXT computer. This had the advantage that there were some great tools available -it was a great computing environment in general. In fact, I could do in a couple of months what would take more like a year on other platforms, because on the NeXT, a lot of it was done for me already. There was an application builder to make all the menus as quickly as you could dream them up. there were all the software parts to make a wysiwyg (what you see is what you get - in other words direct manipulation of text on screen as on the printed - or browsed page) word processor. I just had to add hypertext, (by subclassing the Text object)"
http://www.w3.org/People/Berners-Lee/WorldWideWeb. html
Note: He did not write the program on a Mac using Hypercard nore could he reasonably.
12 November 1990 proposal: http://www.w3.org/Proposal.html "... we extend the application area by also allowing the users to add new material."
http://public.web.cern.ch/Public/Content/Chapters/ AboutCERN/Achievements/WorldWideWeb/WebHistory/Web History-en.html
http://en.wikipedia.org/wiki/Tim_Berners-Lee
Point 2: NeXTstep predates XML: Prior to standard XML, NeXTstep used ASCII "Propert Lists" which are exactly the same concept with a different syntax and no user definable type qualification. When XML was standardized, NeXTstep transitioned to using it.
Point 3: Very few people (possibly only you) would claim that dropping Hypercard and adopting NeXTstep was even a small step backward. You don't seem to understand what NeXTstep/Openstep/Cocoa is or what it enables or why it is still ahead of the crowd 18 years later.
Point 4: How is Hypercard anything other than a tool to let users create quick and dirty applications also knows as "hacks" ? Don't be so quick to call things "Third party extension and hacks" particularly when they are full featured commecial tools used to build serious applications. -
Re:cough HYPERCARD cough
Point 1: Yes, Interface Builder and NeXTstep predate the web: The "web" was _created_ with Interface Builder and NeXTstep! Tim Berners-Lee says "
The first web browser was implemented in NeXTstep and was also the first web editor. The World Wide Web application was a WYSIWYG editor with collaborative user editing features far beyind standard wiki today.
pictures: http://info.cern.ch/NextBrowser.html
"It has taken a long time for technology to catch up with Berners-Lee's original vision. The first ever web browser was also an editor, making the web an interactive medium, the problem was that it only ran on the NeXTStep operating system."
Tim Berners-Lee worte "I wrote the program using a NeXT computer. This had the advantage that there were some great tools available -it was a great computing environment in general. In fact, I could do in a couple of months what would take more like a year on other platforms, because on the NeXT, a lot of it was done for me already. There was an application builder to make all the menus as quickly as you could dream them up. there were all the software parts to make a wysiwyg (what you see is what you get - in other words direct manipulation of text on screen as on the printed - or browsed page) word processor. I just had to add hypertext, (by subclassing the Text object)"
http://www.w3.org/People/Berners-Lee/WorldWideWeb. html
Note: He did not write the program on a Mac using Hypercard nore could he reasonably.
12 November 1990 proposal: http://www.w3.org/Proposal.html "... we extend the application area by also allowing the users to add new material."
http://public.web.cern.ch/Public/Content/Chapters/ AboutCERN/Achievements/WorldWideWeb/WebHistory/Web History-en.html
http://en.wikipedia.org/wiki/Tim_Berners-Lee
Point 2: NeXTstep predates XML: Prior to standard XML, NeXTstep used ASCII "Propert Lists" which are exactly the same concept with a different syntax and no user definable type qualification. When XML was standardized, NeXTstep transitioned to using it.
Point 3: Very few people (possibly only you) would claim that dropping Hypercard and adopting NeXTstep was even a small step backward. You don't seem to understand what NeXTstep/Openstep/Cocoa is or what it enables or why it is still ahead of the crowd 18 years later.
Point 4: How is Hypercard anything other than a tool to let users create quick and dirty applications also knows as "hacks" ? Don't be so quick to call things "Third party extension and hacks" particularly when they are full featured commecial tools used to build serious applications. -
Re:cough HYPERCARD cough
I am sorry, but HYPERCARD was and is a toy. It is fun and assesible to children, but it is not suitable for serious application development: particularly if more than one person is involved in the development.
In contrast, most important (quite possibly all by now) Mac OS X applications including the iWork suite were developed with Interface Builder and in most cases Cocoa. The very first web browser was developed with the precursor to Cocoa and Interface Builder. http://www.w3.org/People/Berners-Lee/WorldWideWeb. html
Tim Berners-Lee worte "I wrote the program using a NeXT computer. This had the advantage that there were some great tools available -it was a great computing environment in general. In fact, I could do in a couple of months what would take more like a year on other platforms, because on the NeXT, a lot of it was done for me already. There was an application builder to make all the menus as quickly as you could dream them up. there were all the software parts to make a wysiwyg (what you see is what you get - in other words direct manipulation of text on screen as on the printed - or browsed page) word processor. I just had to add hypertext, (by subclassing the Text object)"
Lotus Improv, the original Doom level editor, the untire user interface of NeXTstep were developed with Interface Builder.
What exactly was ever developed with HYPERCARD ? -
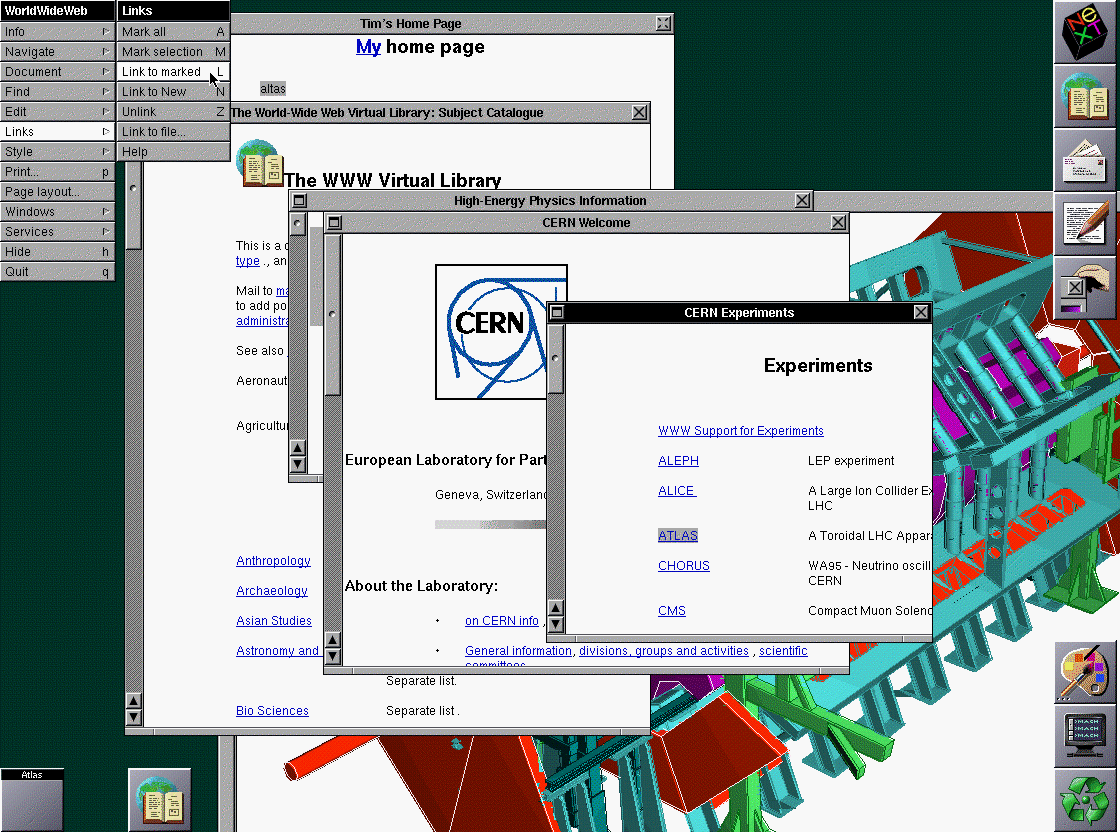
Re:You can't just type in a location?
I don't know what the default page was - from this screenshot it looks like the browser defaulted to your home page (which you might have needed to set by hand) but may have had a way to enter a URL from the menus.
-
Re:Does any major site use pure CSS?
I checked out the link "http://www.csszengarden.com/".
Question: have they ever heard of contrast?
I swear if a publisher sold me a book where the gray text blended with the white page I would never buy a book from them again.
Quality is about usability and when you need to read text you need contrast. This isn't artwork. It's text. To be read.
I have a LCD and CRT color tuned very nicely btw.
Here is another site with unreadable text, but very playable artistic games: http://www.ferryhalim.com/orisinal/
Here is a readable site with nice text contrast: http://www.w3.org/
Text != Art
Also those guys who use double spacing... yeah. It's annoying. -
Re: @_@
The reason I linked to w3cschools was to illustrate how CSS is well-published. We all know WHO publishes CSS standards and who is responsible for them.
Besides, I find content on w3cschools much, much more practical and relevant to my work in web design. Most of the content on w3c.org seem more relevant to browser-app developers. (except for those working on IE7, of course) To their credit, they do have nice tips for beginners; you might want to try them out.
As to the (thin) implication that w3cschools is the source of CSS standards, I say "touché". (the implication was not my intent) As for your personal issues with w3cschools, I suggest you take it up with them.
Have some context with your crack... takes the edge off.
-
Re:Well this sounds promising...
The issue with coding is not compliance with CSS standards (those are well published [w3schools.com])
Please don't link to the sleazy W3Schools when referencing the work of the W3C. They have nothing to do with the W3C and are not responsible for the CSS specifications.
-
Re:Why XML was successful
You are arguing that both ways: You claim to have no investment and then start trying to get authority by referring to your experience with it.
Sorry, this makes no sense. Having experience in something does not mean I have investment in that thing. I have been using Microsoft products since the 70s, but I have no loyalty or investment in them! However, I certainly consider myself an authority on many of their products, because of my experience.
Adding one more layer of indirection is usually just asking for trouble. Doing this because XML has flaws in its design is usually stupid, especially as you can't guarantee trivial transformations due to that brokenness. So, no, I cannot avoid the fallout from that design mistake. Either I take the fallout in the form of adding more indirection, implementing the code for that indreiction, not being able to use the present documentation, etc - or I take the fallout in the form of having to deal with arbitrary noise being thrown into the data formats.
Indirection != transformation. It is a mapping. One of the great things about XML is the ability to filter out arbtrary noise or transform it to something less noisy.
And no matter where I stand, I often have to debug other people's code. Where they have NOT thought that clearly around this - which is obvious, given that even you, with 30 years of experience in various formats including XML, do not get the point on the first explanation. Hopefully, you got it now.
Well, I thank you for your time and patience in trying to make me 'get it'. Unfortunately, it seems not to have worked
I spend a significant amount of time debugging other people's code too, unfortunately. That is precisely why I am so keen on XML, because much of that debugging has involved reverse-engineering undocumented formats.
People will add indirection and mess up ANY data format. This is precisely why having a standard format which is easily transformable and parsable is so vital.
To keep cutting down your arguments (though I'm not sure why I bother - I don't think you're going to dare to pull away your investment and see the flaws in XML anyway):
One good rule about arguing is not to invent characteristics of those you are arguing against. Firstly, you can't tell, unless you have some amazing psychic ability: I know there are faults in XML. In particular the validation languages have been pretty awful (with DTDs being ghastly). But, I see so much discussion that indicates a complete lack of understanding of why XML was invented. Without such understanding the benefits, which hugely outweigh the awfulness, are often not recognised. Secondly, resorting to ad hominem attacks does not help either. Many consider that this in inself is a sign of someone who has significant investment themselves in the point of view they are trying to defend. At the very least, it is a distraction from what might well be good arguments *you* are putting forward.
Your examples of XML application does not argue for cut/paste at all; it's processing done by a machine.
Individuals can do exactly what those machines did in that example. I have seen it done with students inventing their own format for science work (such as molecular models) and embedding that within standard XML document formats, to allow embedded display. Works like a dream!
I am in favour of having a standard, structured text format we can process - I just think XML is a horrible choice. It's bloated, denormalized for a proper hierarchy by the utterly arbitrary inclusion of attributes, and then, to add insult to injury, it can't represent graphs.
(1) Then don't use attributes. You only have to write the XSTL to transform from your attribute-free format to an attribute-based format (or back the other way) once.
(2) Of course it can represent graphs. There are well-established techniques for doing this. RDFis a W3C standard which includes representation of graphs. It is pure XML.
(And I would love to see some major document format using YAML). -
Re:Why XML was successful
A curly brace syntax would have been a better format for "large scale enterprise publishing"? As someone who has spent more than a decade in that field, I must disagree strongly. A curly brace would have been better to allow enable generic SGML to be served, received, and processed on the Web in the way that is now possible with HTML. Please do not confuse what XML is used for with what it was designed for. There is a reason that XML delivery units are called "documents" and not "messages".
-
No mention of XML's creators?
Strange that an article celebrating XML's anniversary would neglect to mention XML's creator. I wonder if the fact he works for a competitor has anything to do with it...
-
The "XXX" Project.html
http://www.w3.org/History/19921103-hypertext/hype
r text/WWW/MarkUp/Tags.html#20
A NAME=xxx HREF=XXX
They new what it would be used for, those sly dogs! -
16 years and...
16 years and I'm still waiting for them to finish writing this damn page! How does anybody ever manage to set up one of these new-fangled WWW servers anyway?
-
Re:Standards! Standards! Where are the standards!
Oh, c'mon, it's an HTML document, not an XHTML document. Let's see how it does in the latest version of HTML... Oh, look, it validates.
-
Re:Shame...Cool! The first example of teh is here.
qz
-
Re:Confirmed?
The URI changed, so it's not the oldest page on the net.
Well, the content is still the original one and (surprise!) is still almost 100% valid HTML 4.01 Transitional! I kid you not: try it for yourself!
The only missing thing is the DOCTYPE declaration, but everything else is just fine: call it a tribute to the incredible backward/forward/whatever compatibility and flexibility of HTML!
-
Standards! Standards! Where are the standards!
Try running the W3C Validator on that woozy.
Sheesh. Some people have no respect for standards...
{kind=link}