 Slashdot Mirror
Slashdot Mirror
The Hairy State of Linux Filesystems
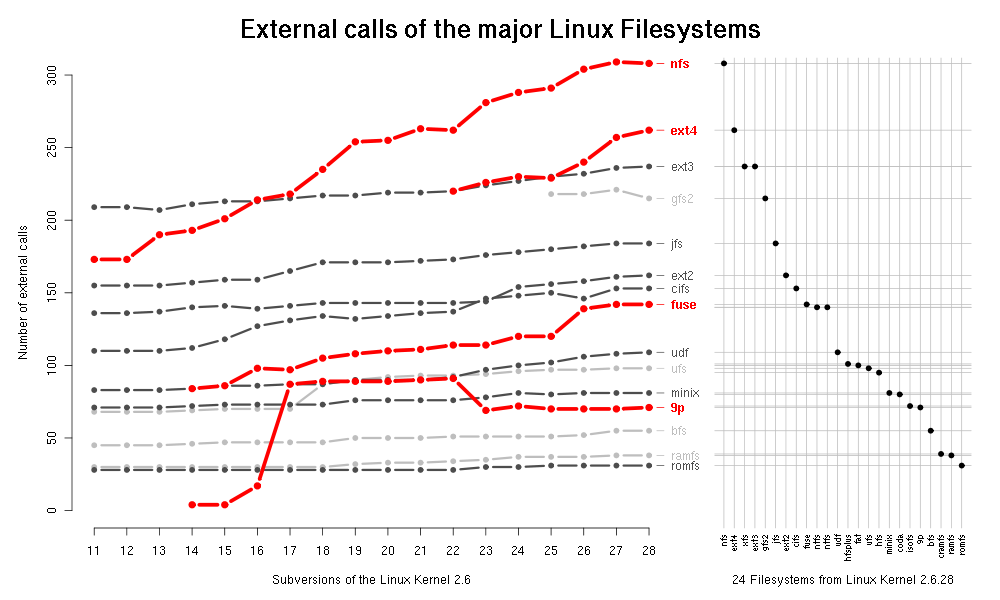
RazvanM writes "Do the OSes really shrink? Perhaps the user space (MySQL, CUPS) is getting slimmer, but how about the internals? Using as a metric the number of external calls between the filesystem modules and the rest of the Linux kernel I argue that this is not the case. The evidence is a graph that shows the evolution of 15 filesystems from 2.6.11 to 2.6.28 along with the current state (2.6.28) for 24 filesystems. Some filesystems that stand out are: nfs for leading in both number of calls and speed of growth; ext4 and fuse for their above-average speed of growth and 9p for its roller coaster path."
{kind=link}
In the case of NFS for instance, hasn't there been a performance improvement? Isn't that the thing that matters?
While OSes may be "sliming down" as the article says, what does the removal of standard db packages from Ubuntu have to do with filesystem-related kernel calls?
The article doesn't seem to mention the possiblity that more functionality may be pushed into the kernel from userspace, which might make sense in other situations, but I don't think that argument would hold up here.
I am struggling to make the connection between the summary and the so-called article. The fact that they are not stripping/locking fs functionality means that OSes aren't shrinking? That's the hypothesis?
Sometimes I wish there was a way to make my own meta-mod, like "don't include mods from the people that modded this up ever again". The same copy-paste has been in tons of stories now, and it's not funny anymore because it's the EXACT same thing. I'd even rather hear one more variation on our insensitive clod overlords from Soviet Russia.
Live today, because you never know what tomorrow brings
In fact, if you think about it, the greater the number of different functions a filesystem driver uses, the less functionality it needs to have within itself. I also don't think the number of external calls is a significant measure of anything related to the size or performance, really. It all depends on what calls are being made and for what purpose.
If anything, as you imply, it's a measure of complexity. But even that might not really be the case if you stop and think about it. As more stuff is abstracted out, the less code goes into the filesystem code, the simpler, really, not more complex that filesystem driver becomes.
I think this was a really poor choice of metric and that almost renders this entire article moot.
My blog
> The number of calls in the interface do matter because they increase complexity.
That is only true, if a similar functionality is provided and the function-calls are of similar complexity (e.g. number of parameters, complexity of arguments.
To my limited knowledge, over work has been done to extract more common functionality from file-systems. Should that be the the case, it would increase the number of function calls, but reduce the overall complexity.
"Between strong and weak, between rich and poor [...], it is freedom which oppresses and the law which sets free"
I think that you can compile only the filesystem you want in the kernel..
So the only complexity which matter to an user is the one of the filesystem they select to compile in the kernel!
Nevermind COMPILING stuff. You can just plain choose not to USE stuff.
Don't want the "bloat" of NFS or ext4, then don't bloody use them.
Yeah, the spiffy new things or inherently complex things might
show that complexity in the code. Imagine that. The source for
Halo looks bigger than the source for Pacman.
There is no news here.
As an nvidia user, ATI can make their Linux drivers as bad and
as bloated as they want. I don't care. It really doesn't effect
me.
A Pirate and a Puritan look the same on a balance sheet.
Nevermind the fact that modern processors can cache the entirety of the Linux kernel.
Simplicity of code is nearly always better than premature and not necessarily useful optimizations.
I believe I read somewhere or other that branch predictors need a certain number of instructions between the branch instruction and the branch target in order to do a good job. If the only instruction in the loop is a single increment, that might explain the problem. Unrolling the loop so it has more instructions might fix it.
So... rather surprisingly, the cost of these function calls is as close as doesn't matter, to exactly zero.
If the compiler knows the relative address of the function ahead of time, they are really fast.
Try replacing your direct function call with a function pointer instead. Assign the function pointer the address of your function during runtime. It will be many orders of magnitude slower.
Not sure why this is; just something I discovered the hard way.
DATABASE WOW WOW
Try replacing your direct function call with a function pointer instead. Assign the function pointer the address of your function during runtime. It will be many orders of magnitude slower.
It goes faster as an indirect functional call if anything. Go figure.
Anyway... orders of magnitude difference? Under some other rules of physics maybe. It would probably be a good idea to compile and time your program, as I did.
Have you got your LWN subscription yet?
Being dead doesn't sound too bad to me. The process of dying almost always sucks and I don't want to be dead, but once I am dead I can guarantee you I won't give a shit about it.
Chernobyl 'not a wildlife haven' - BBC News