 Slashdot Mirror
Slashdot Mirror
Domain: sethf.com
Stories and comments across the archive that link to sethf.com.
Stories · 22
-
Gore's Staff Says He Was Misquoted On Hexametric Hurricanes
jamie writes "In a story on Thursday, Slashdot and its readers had a little fun at the expense of Al Gore, who was quoted as saying that the hurricane severity scale was going to go to 6. A correction was made the next day. The author of the piece that Slashdot linked now writes 'I retract the balance of my criticism.' Turns out Gore was misquoted. Luckily for Gore, this is the first time he's been ridiculed for something he didn't actually say. Well, except for Love Story, Love Canal, farm chores, and everyone's favorite, inventing the internet. (The original Slashdot story is here and its central link now includes the Washington Post's correction.)" From Ezra Klein's update on his earlier piece: "I'm out-of-town and so away from my tape recorder. So I asked Gore's staff about the line and they have Gore saying: 'The scientists are now adding category six to the hurricane ... some are proposing we add category 6 to the hurricane scale that used to be 1-5.' That doesn't offend my memory of the discussion and it's entirely possible I missed Gore's qualifying sentence while trying to keep up. If so, that's my fault, and I apologize." -
Privacy Hacking Worse Than PR Flacking
Here's frequent Slashdot contributor Bennett Haselton who writes "Facebook apparently hired a PR firm that tried to seduce some pundits into writing negative editorials about Google. The 'attack angle' would have been that Google was endangering users' privacy by scraping information about users from Facebook and making such information easier to find with a Google search." Hit the link below to read the rest of Bennett's story.The reliably cynical Seth Finkelstein commented that the attempted editorial-planting was just "often implicit dealing made explicit", (i.e. that pundits are drafted as fronts for corporate publicity campaigns like this all the time, and that the PR firm in this case spoiled the game by rudely blurting out the terms of the deal, like a guy offering to buy a girl dinner if she'll sleep with him). Steven Levy of Wired opined that with regard to the privacy issues, Facebook was the real villain for exposing information in the first place that many users would rather keep private.
Some perspective here: In 2008, I was corresponding with a high school student (using one of the Circumventor sites to get around their local school Internet blocker, naturally) who mentioned that he was able to see all the personal information of other students in his Facebook high school network -- including email address, phone number, and home address, if the user had uploaded that information to Facebook -- even if those users had not confirmed him as a friend. (Facebook allows users to join one or more "networks" indicating their school affiliation, workplace, city of residence, etc. -- such networks are distinct from Facebook groups and fan pages.) Double-checking with a few more users in the same network and in other high school networks, we found that it really was possible for any member of a high school network to view the profiles of any other member of that high school network and see all of their personal information.
Unlike other types of "networks" on Facebook, it is not possible to join a high school network simply by specifying it in your preferences. However, all of the students that I corresponded with said that in order to join their high school networks, they simply had to request to join the network, and then get a friend request confirmed by an existing member of that high school network. Which means that conning your way into the network would be easy: either (1) create a profile with the name and photo of a real student at that school, and send out friend requests to that student's friends, hoping that one of them would confirm you (not remembering that they had already friended that person under their real account), or (2) create a profile with a hot girl's picture and send out random friend requests to a bunch of guys in the network. Once you got confirmed, you'd have access to all the personal information that any student in that high school had posted on their profile. (I hasten to add that we did not actually try either of these things, but it stands to reason that it would work, since it wasn't functionally any different from what all of those students actually had to do in order to join their networks in the first place!)
I sent a message to Facebook's security team about this, and got a non-form-letter response from a real person -- their reply, however, was that this behavior was by design:
We believe this allows for greater sharing and helps make the site more useful for people, though we also recognize the potential for misuse. That's why we've built a peer verification system around the joining of high school networks. We also use automated systems to detect and flag anomalous behavior, like lots of messages sent to non-friends or a high percentage of ignored friend requests.
Smart, but probably not secure enough. For one thing, if someone is creating disposable accounts to send out friend requests in hopes of getting into a high school network, it only has to work once, so even if most of their accounts get flagged for "anomalous behavior," they only need one that doesn't get flagged. And even if that account does get flagged and cancelled later, by that time it might be too late, if they've already grabbed enough users' information. In any case, some time between 2008 and 2011, Facebook did change the behavior of high school networks so that members can no longer see the personal information of other members without a confirmed friend request. But this loophole was not that difficult to find, and it's likely that at least a few other users had discovered the same issue.
Now, imagine what would have happened if Facebook had announced that, for a fee of a few hundred dollars, they were offering CDs for sale containing the names, addresses, mobile phone numbers, and instant messenger names of all the high school students on their site (along with, of course, all the photos those students had posted of themselves). It goes without saying that after the class action lawsuits had finished, there'd be nothing left of the company but a smoldering crater. Now, I'm not suggesting that Facebook's security policy for high school networks was anywhere near as bad as selling CDs with all the personal information of their high school users, but it's worth thinking about why it should not be considered as bad. In either case, anybody willing to spend a few hundred dollars (or, equivalently, a few hundred dollars' worth of effort -- the effort to discover the loophole, and then to crank out the friend requests) could obtain the personal information of as many high school students as they wanted. What's the difference?
Well, obviously, there's the message that it would send if a company like Facebook offered to sell CDs full of users' personal information. It would lower the bar for future behavior by similar companies, it would make users extremely cynical about trusting the motivations of social networking sites, and in the long run it might even cause courts to decide that users had no reasonable expectation of privacy when joining those sites, because it was "common knowledge" and "common practice" that those sites offered up people's personal information for sale! On the other hand, if Facebook makes that information available indirectly through "benign neglect" -- by, for example, forcing you to create a fake high school profile and send out a bunch of friend requests and create a new profile from scratch if your first one gets canned -- that's far less likely to cause the side effects I just listed. MySpace is not going to get the idea that it's OK to start selling CDs of users' personal information because, hey, Facebook let people pry out the same information if they jumped through enough hoops.
But what this means is that fairly mild privacy issues, if they arise as a result of deliberate choice by a company like Facebook, are likely to get more press attention than far more serious privacy issues that arise as a result of benign neglect. Because when Facebook makes a deliberate choice that affects user privacy (like sharing users' preferences with Pandora), the pundits and the public are reacting to the direct privacy implications of that action, plus all the auxiliary issues, like the "message" that it sends, and the precedent that it sets for future actions by that company and other companies. Whereas if an issue arises as a result of neglect (as in the case of PlayStation Networks users' credit cards being stolen), people are reacting only to the direct privacy implications of the incident, so the issue has to be much more serious to get the equivalent amount of press.
For example, the right reason to be concerned about Facebook sharing users' personal information with Pandora, was the principle that it violated -- if users say "no" to sharing their personal information, Facebook shouldn't be allowed to switch that choice unilaterally. But as for the practical implications -- come on. Facebook and Pandora are both big faceless corporate behemoths as far as we're concerned, so why would we trust one with our personal data but not the other? Besides, what if Facebook had simply bought out Pandora? Then they could share all of our personal information with all the employees of the newly merged Facepanbookdora, and the exact same people would have had access to the exact same data, but it wouldn't have violated the agreement against sharing information with "third parties," because they wouldn't be a third party any more.
When I first found that email addresses of Ameritrade customers had been obtained by a pump-and-dump stock spammer, I was sure (as were most readers, probably) that Ameritrade was not deliberately selling its customers' email addresses; I figured that they had simply left their database inadequately secured, and some third party had broken in and stolen it. On the other hand, because the incident happened as a result of benign neglect and not deliberate choice, I figured the incident would not garner much press as a result, and that seems to have been the case -- the wholesale thievery of Ameritrade customers' personal information by financial criminals received far less press attention than, say, Facebook's decision to change their privacy policy so they could share information with Pandora.
What this means is that if you're an ardent cyber-rights hippie like me, then yes, you should care about the privacy issues that set the blogosphere afire, even if they're fairly minor privacy issues that are magnified out of proportion because they speak to the deliberate intentions of the companies involved. It matters that Facebook decided one day to share our music preferences with Pandora, even if it doesn't hurt anyone.
On the other hand, if you simply care about threats to your personal privacy, then you should heavily discount the noise being made about deliberate choices taken by companies like Facebook, and pay far more attention to dangers of benign neglect by the company guarding your privacy, when that benign neglect is exploited by malicious outsiders. If you have a stalker and you're worried about them finding your Facebook profile, it makes no sense to be worried about Google scraping the information from the public version of your Facebook profile, if it's the same information that your stalker would be able to see anyway if they were logged in to Facebook themselves. It's far more likely that your stalker would try to exploit a weakness in Facebook's privacy settings -- for example, ingratiating themselves with one of your Facebook friends and getting them to accept a friend request, so that they can then see any information on your Facebook profile that is viewable to "friends of friends." Maybe you knew about that already, but if you didn't, you wouldn't know it from reading all the punditry about the Facebook-Google kerfuffle.
-
Power To the Pop-Ups
Slashdot frequent contributor Bennett Haselton writes a piece advocating for Pop-Ups and even more obtrusive advertising. But not for the reasons you might think. He says "Annoying pop-up ads have been a great friend to Internet freedom, by enabling the operation of proxy sites that would be too expensive to operate otherwise. With the rising costs of making new proxy sites to stay ahead of the 'censorware' companies, even more intrusive ads could be an even bigger friend to Internet freedom. Got any ideas for how those more intrusive ads could work?" Clicky clicky below to read his point.Most news and information websites carry advertisements, but usually not more than one pop-up ad, if they have pop-ups at all. This is because the costs of running the sites are low enough that they can usually pay for their costs with revenue from regular ads. Surely the site owners would like the extra money that they could get from pop-ups, if their viewers had nowhere else to go. But if they tried to get away with too many pop-ups on a typical news site, visitors would just leave for their competitors' sites instead. Competition keeps the "prices" — in terms of the ads that you have to view in order to visit a website — low.
By contrast, most proxy sites [that's not a link to one of my sites, so quit yer whining] — sites that you can use to get around Internet blocking, by using a form to type in the URL of the site that you want to access so the proxy site will fetch its contents for you — are festooned with pop-up ads, sometimes on every page load. As I can easily attest, the bandwidth and hardware costs of running a proxy site are sufficiently high that there would be no way to pay for the sites with the revenue from normal banner ads and AdSense blurbs. It's no exaggeration to say that most proxy sites, which enable people to circumvent government filtering in countries like China and Iran (not to mention helping millions of students get on Facebook and YouTube from school), would not exist without the pop-up ads to prop them up. (This may not be true of a proxy site that your high school classmate set up for himself and some friends, but it's true of most proxies created to serve a wide audience.)
Unfortunately it's becoming more expensive to run an effective proxy service that enables users to get around most enterprise filtering programs. If it gets to the point where normal pop-up ads do not bring in enough revenue to pay for the service, we might need a new breed of even more intrusive (and better-paying) ads. More intrusive than the drop-down ads that play noisy videos. More intrusive than the Flash animations that crawl across the screen on top of the words you're trying to read. I'm going to argue that a company that figures out how to run the most intrusive ads of all, could be the new best friend of Internet freedom. But first a note about why the costs are increasing.
Two years ago, I thought the cost of maintaining a proxy site to help people get around Internet filtering, would steadily fall, as bandwidth and processing power got cheaper. But bandwidth and hosting costs didn't drop as much as I had hoped, and the cost of maintaining an effective anti-filtering service has actually gone up, due to some advances made by Internet censoring programs. In 2007, the then-current versions of filtering programs like Smartfilter, Websense, and the 8e6 R3000 would typically only download updates to their blacklists once in the middle of the night. This meant that I could mail out a new proxy site to my proxy mailing list just after midnight, and it would be accessible to the mailing list subscribers all of the following day. (You wouldn't be able to get to them if your local network administrator subscribed to the mailing list and added the new sites to the local blacklist as soon as they came out, but most network admins didn't bother.) As of 2010, though, the latest versions of most enterprise filters are configured to automatically update their lists every hour or two. So to stay ahead of the filters, I have to mail out several sites every morning to different portions of the mailing list, so that the filtering companies generally learn about them and block them at different points throughout the day. Just registering several .com domains every day is not cheap. (GoDaddy sells .info domains for less than a dollar apiece, but this proved to be an ineffective solution because too many censored networks simply block all .info sites.)
There are also the increasing costs of maintaining compatibility with complex sites like Facebook and YouTube. Accessing Facebook through a proxy is still a hit-or-miss proposition. (I steer my users toward accessing the mobile version of Facebook, http://m.facebook.com/ , through the proxy, because it's a stripped-down version built for compatibility with mobile devices, and this simpler version is less likely to break when accessed with a proxy script.) YouTube access depends mainly on whether the latest YouTube plugin for the Glype proxy script is compatible with the current YouTube interface, and likewise can be working one week and broken the next. It's not hard to run a proxy site that provides compatibility with the most popular sites that people want to access, but it takes real work -- you can't just upload the script and forget about it.
(Many users in censored countries also use tools like Tor and UltraSurf to bypass their country's filters, but some of my contacts in those countries say that those tools are often too slow for them, so they end up using proxy sites instead. Since UltraSurf and Tor are free services, funded by donations and staffed by volunteers, the demand for those services can easily swell until they slow down from the overload.)
So what happens if maintaining an effective anti-censorship service becomes too expensive to pay for using just pop-up ads? Well, you could charge money for using your proxy site, but that brings with it a whole host of other problems. You have to set recurring billing in order to be paid through PayPal or some similar service, and run the risk of your funds being frozen if someone files a crank complaint against you. If one user has a paid account, you have to worry about them sharing the account with their friends or posting the account credentials on a public message board. And there are many proxy operators (including me) who would like to think that the proxies do provide a valuable public service to the world, and wouldn't want to exclude people who can't afford the monthly access fee.
I propose that ads which are even more intrusive than pop-ups -- thus grabbing more of the user's attention and providing more value to the advertiser, thus enabling them to pay more to sites which run the ads -- would enable proxy site operators to fund more of the costs of their operation, and hence would be a Good Thing. The existence of such intrusive ads does not mean that they would suddenly be plastered all over every proxy site. If your user base can be served for a lower cost, then you don't have to "charge" as much (in terms of advertisement intrusiveness) to use your proxy service. Over 90% of the traffic to my proxy sites is to domains that have already been blocked a long time ago by Websense, Smartfilter, Lightspeed, and most of the rest of the censorware companies. Apparently there are a lot of users who are on censored networks and who need proxies, but whose network admins just haven't updated the blacklists in a very long time, or who haven't paid the subscription fee to keep downloading database updates. Since you don't need to register 10 new domain names every day to serve that audience, there would continue to be proxies for those users with less-intrusive ads on them. But the more-intrusive (and higher-paying) ads would also enable proxy webmasters to serve a "higher-end" audience, the ones who need several new sites every day, to stay ahead of the more frequently-updated filters.
I can think of several ways that more intrusive ads might work. My favorite would be a "quiz" model wherein a drop-down advertisement appears in front of the site you're trying to access, consisting of some promotional content, and a little form at the bottom. In order to make the drop-down ad disappear, you have to read the ad and fill in the answers to some one-word questions or multiple-choice questions about the content, to prove you actually read it.
Perhaps I'm biased in favor of this idea because I'm tired of ads that contain splashy graphics and expensively licensed music and never contain any actual information. The only television ad that I can recall viewing in the past year which prompted me to actually buy the advertiser's product, was the Pizza Hut ad announcing that you could get a large pizza with any number of toppings for $10. That's what I want in an ad. I give you $10. You give me a pizza. (And this extra plug for their $10 pizza promotion, can be considered a thank-you to them for running an ad that actually had something to say.) Most ads on TV are far less informative, serving mostly to give a glossy sheen to the advertiser's brand name. Yet these ads are paid for by corporations who do the market research and the focus grouping, so the ads must work. Many economists, including Tim Harford in The Undercover Economist and Steven Landsburg in The Armchair Economist, have explained why companies pay for ads that do nothing except look expensive: Because they prove to the viewer that the company intends to be around for a long time, in order to capitalize on the long-term exposure given to them by the ad. This has become so standard that making an ad which actually gives the user information seems tawdry by comparison. The most ghetto-sounding word in TV advertising is "infomercial".
But I think that some companies could benefit from greater exposure of actual information about their product, just as there are companies that pay for informercials. And if a company like Linksys really wanted to run a splashy ad that contained no actual information, and then make me answer some questions at the bottom like:
Linksys is:
(a) the leading manufacturer of wireless adapter cards
(b) the leading manufacturer of wireless routers
(c) the leading manufacturer of wireless monitoring cameras
(d) all of the above!!!then that's their prerogative. The quiz-advertisement model only says that advertisers can require users to answer a question before closing the ad; it would be up to the advertiser to decide what question works best. I suspect that the actual-information model would work better for quiz ads, but advertisers could try both and see what works.
There are already some websites that require you to "complete an offer" (i.e. become a customer of some third-party company, at least for a free trial period) in order to use their services, but most proxy sites have so far declined to carry advertisements like these. Evidently their users consider this too high of a price to pay to access a proxy site. Filling out an offer is not just time-consuming, but leaves the door open to future problems -- will they sell your name or your e-mail address? Will they make it hard to cancel your "free trial", and then start billing you? The problem seems to be that there is too large of a gap between the "fees" associated with the two options -- a normal advertisement doesn't bring enough money to the proxy operator, but a complete-an-offer advertisement is such a steep price that most users won't pay it. The "quiz ad" is like a "fee" that falls nicely in the middle -- a smaller time commitment, and your worries are over after you fill in the quiz and hit submit.
If the very thought of such an ad still seems too annoying for words, then I think that objection misses the point. If the revenue from "normal" ads (pop-ups, drop-downs, AdSense widgets) is enough to pay for the operation of a "high-end" proxy service (catering to the people who need several new proxies every day), then such proxy services with "normal" ads will continue to exist. Indeed, anyone who tried running the more annoying "quiz ads" would not be able to get off the ground, because users would flock to the competing proxy sites using normal ads instead. If "high-end" proxy services flourished that were using quiz ads, it would only be because you simply can't provide a high-end service for less money than the quiz ads are bringing in.
It's possible that some advertisers would be reluctant to display ads in a manner that users would continue an annoying obstacle, but I'm not sure that's really a problem. The most intrusive advertisements currently in use on mainstream websites are probably the "premercials" that display before some news videos on CNN.com and other news sites. Unlike drop-down ads which can be closed with the click of a button, the video pre-mercials can't be skipped. Since you're actually expecting the news video to come up immediately when you click the link to start playing the video, you would think that many users would grit their teeth in annoyance upon seeing the "pre-mercial", and transfer that irritation to the advertiser's brand name, but there are so many big-name companies buying those pre-mercials that they must believe it's having a positive effect. So intrusiveness itself doesn't seem to tarnish a brand.
But I don't propose to micro-manage suggestions for how the more intrusive ads would look, or how advertisers should tailor their ads to fit the format. I'm just saying that a new breed of more intrusive ads, even more annoying than pop-ups, might be just what we need to stay ahead of increasingly sophisticated Internet censors. It's still technically quite trivial to release a steady stream of new proxy sites that defeat most Internet filters, but it costs money to buy domains and maintain the service, and the money has to come from somewhere.
-
Yes, Google Does De-List Pages; But When?
Frequent Slashdot contributor Bennett Haselton writes "Google finds itself inserting a disclaimer once again above some offensive search results. But the disclaimer still leads many to believe (incorrectly) that Google doesn't tamper with search results even in cases of 'harmful' or 'offensive' material. We know that Google has in fact de-listed some pages at the request of offended parties. What is their real policy on the issue?" Read on for Bennet's essay.In 2004, when Google users discovered that the top search result for the word "Jew" was the anti-semitic site Jew Watch, Google ran a disclaimer in the space usually reserved for ads, explaining that their results only reflected the reality of link counts on the Web, and that they did not endorse any Web sites which appeared at the top of their listings. Now the disclaimer has been dusted off again, as the top result on Google Images for "Michelle Obama" is a picture of a monkey's face with Michelle's hairdo. (Ironically, it looks as if the original image would have fallen out of the rankings, if it hadn't been for a follow-up blog post about the controversy, which itself now comes up as the first result.)
I first heard about the controversy from Dennis Prager's column in which he takes a New York Times columnist to task, because the columnist complained about "racially offensive images of the first couple" that come up in Google searches. Prager was unable to find any examples from Googling "first couple" or "Michelle and Barack Obama pictures," so he concluded that the NYT columnist "wildly exaggerated, if not made up" his claims. I tried Google Image searches for "first couple," "Barack Obama," and some other terms, and I couldn't find anything controversial either. However, it only took 10 seconds to enter "first couple google images controversy" on the regular Google Web search and find multiple blog posts explaining what all the fuss was about. Back to Google 101 for Dennis.
Many of the blog posts refer to Google's disclaimer about not tampering with search results. Those on one side are urging Google to make an exception and "fix" the results, while others sagely observe that Google just reflects reality, it doesn't create it.
All of this punditry is starting from a premise that's wrong. Google has actually removed pages from their search results — not because the pages were illegal or because the webmasters were search engine spamming, but because of the page's "offensive" content. In the "Chester's Guide" incident, a councilman in Chester, England discovered that one of the search results for "chester guide" was a satirical page titled "Chester's guide to picking up little girls." Although the page itself was obviously just someone's idea of sick humor, a Chester city councilman (who admitted that he hadn't looked at the page, saying that the title told him everything he needed to know) urged Google to remove the page from their index. Google at first refused, but later manually blacklisted the page to prevent it from appearing in their search results.
Whether or not you think this was the right decision, probably depends on what you think is the purpose of Google. If Google's purpose is to return the most useful results, then it made sense to remove the link, as Danny Sullivan of Search Engine Watch argued at the time, since it almost certainly was not a useful result for people searching for "Chester Guide." On the other hand, if the primary purpose of Google is to reflect the reality of what pages on the Web feature certain words most prominently (combined with all the other factors that Google weighs, of course), then the results shouldn't be altered.
But more people should at least realize that it happened. The Google disclaimer doesn't precisely say that they never blacklist pages or modify search results ("Google reserves the right to address such requests individually"), but it seems to give most people the impression that that's the case. According to that crudest of Googling techniques for which novice searchers are so frequently lampooned, there appear to be about 400 times as many stories on the Web about the Google "Jew Watch" controversy (where Google stood their ground) as there are stores about the "Chester's Guide" incident (where Google caved).
And Google-number-three Matt Cutts posted on his blog back in March explaining why Google does not remove "offensive" pages from search results; over a hundred comments followed, debating the pros and cons of the position, but none of them mentioned the Chester incident or any other case where Google actually had removed pages except as a result of a court order. One isolated comment from "Anonymous" said:
This is not quite true. I know of at least one web site that was de-listed for containing illegal content and/or promoting illegal activity.
which may or may not have been a reference to the Chester Guide incident. And that was it.
Is this a lot of hay to be making over something that happened years ago? Well, for one thing, I doubt if it happened just once. Consider that the Chester Guide incident involved a public declaration of outrage by a city council, and a public statement from Google, and still hardly anyone knows that it ever happened. If other incidents occurred without those high-profile elements, it would be even harder to discover them now. We'll probably never know how many such incidents took place, unless someone sues Google (maybe the owner of a blacklisted website, or maybe the victim of a RipOffReport hatchet job wondering why that site hadn't been blacklisted long ago), subpoenas Google for a list of cases where pages were de-indexed, and publishes the list if it's not sealed by a court order.
But whether it was one time or a handful, consider that political candidates like Arnold Schwarzenegger and Al Franken got asked during their campaigns about things they did 20 years earlier, and it's fair to ask a candidate about their past, because it's the same person standing in front of you now. Why did you do that? Have you stopped? Why?
And in the big scheme of things, Google is probably more powerful than a single US senator or the governor of California. So, can't we ask? What are their real rules about page removal? Have those rules changed since the Chester's Guide controversy? Can they even tell us what their rules are, or do they consider it a trade secret?
It is well known, of course, that Google censors some results in their search engines branded for different markets like China and even in liberal democracies like Germany. But nobody would call that a slippery slope towards censorship in the US version of Google, because the censorship in the Chinese and German versions is done at the behest of the governments there. On the other hand, Google does admit that they will de-index pages which include credit card numbers or social security numbers (which are all too easy to find on the Web). This might not seem like a controversial position, but even this act of voluntary self-censorship may be dipping their toe in the water further than it seems. Most people do consider their credit card information more private than their home address. But surely there are people like J.D. Salinger who less about the privacy of their credit card number (which is easily changeable) than their home address (which isn't). If someone finds Salinger's address and posts it on the Web, should Salinger be able to demand that Google de-index the page? Why should Google cater to the majority who want to keep their credit card number secret, but not to the minority who care more about keeping their address secret? Another commenter on Matt Cutts's blog post asked:
"hi. I have a question. My mom 'googled' herself and it shows some of her medical problems. She wants/needs these pages removed from search engines."
Again, why shouldn't that be considered at least as private as a credit card number?
And finally, even Google's decision to display an "offensive results" disclaimer, for some results but not for others, raises the same "Where do you draw the line?" questions as the issue of page removal. The Michelle Obama monkey picture gets a disclaimer. But search for 'george w bush' and the first row includes a photoshopped (I think!) image of Bush flipping off the press. Does that warrant a disclaimer as well? (Maybe that's considered less unfair because, even though the picture is fake, it does depict something that actually happened.) The first image result for "bristol palin" is a photo of her engaged in underage drinking — a real photo, but probably unfair to call it the single most relevant photo of her on the Web.
So while Google might consider credit cards and social security numbers and search engine spam to be on one side of a "bright line," and everything else is served up without alteration, I think the line is blurrier than that, for at least those three reasons: (a) credit cards and SSNs are less private than some other that things that Google serves up anyway; (b) Google has unambiguously removed some content that fell outside that bright line, as in the Chester's guide incident, and (c) they make other "slippery slope" judgment calls about search results all the time (as in the question of when to show the disclaimer). So I hope that Google someday comes out with a more complete answer to the question. What is their real policy on what they will remove? The Chester's guide incident — would they do that sort of thing if the same situation came up today, or have their rules changed? If they want to go really deep, then is there a general set of principles from which their rules follow — explaining why, for example, they treat credit card numbers as more private than sensitive medical information? (Google did not respond to my request for comment, either through official channels or the unofficial back channels of friends who work there.)
I hope Google gives an answer some day. Even just to say, "It's a classified internal policy and that's all we're going to tell you." But once and for all, the answer is not "Google doesn't remove content just because it's 'offensive' or 'harmful.'"
Meanwhile, a modest suggestion about the disclaimer displayed above the search results: Put it where people will actually see it, in a separate line below the ads, but above the search results. Right now the link to the disclaimer is displayed as one of three ads across the top, and people don't look at the ads. But hey, people do buy ads, so if you push the disclaimer down a bit where people will read it, you also free up space for 50% more ad revenue!
-
Yes, Google Does De-List Pages; But When?
Frequent Slashdot contributor Bennett Haselton writes "Google finds itself inserting a disclaimer once again above some offensive search results. But the disclaimer still leads many to believe (incorrectly) that Google doesn't tamper with search results even in cases of 'harmful' or 'offensive' material. We know that Google has in fact de-listed some pages at the request of offended parties. What is their real policy on the issue?" Read on for Bennet's essay.In 2004, when Google users discovered that the top search result for the word "Jew" was the anti-semitic site Jew Watch, Google ran a disclaimer in the space usually reserved for ads, explaining that their results only reflected the reality of link counts on the Web, and that they did not endorse any Web sites which appeared at the top of their listings. Now the disclaimer has been dusted off again, as the top result on Google Images for "Michelle Obama" is a picture of a monkey's face with Michelle's hairdo. (Ironically, it looks as if the original image would have fallen out of the rankings, if it hadn't been for a follow-up blog post about the controversy, which itself now comes up as the first result.)
I first heard about the controversy from Dennis Prager's column in which he takes a New York Times columnist to task, because the columnist complained about "racially offensive images of the first couple" that come up in Google searches. Prager was unable to find any examples from Googling "first couple" or "Michelle and Barack Obama pictures," so he concluded that the NYT columnist "wildly exaggerated, if not made up" his claims. I tried Google Image searches for "first couple," "Barack Obama," and some other terms, and I couldn't find anything controversial either. However, it only took 10 seconds to enter "first couple google images controversy" on the regular Google Web search and find multiple blog posts explaining what all the fuss was about. Back to Google 101 for Dennis.
Many of the blog posts refer to Google's disclaimer about not tampering with search results. Those on one side are urging Google to make an exception and "fix" the results, while others sagely observe that Google just reflects reality, it doesn't create it.
All of this punditry is starting from a premise that's wrong. Google has actually removed pages from their search results — not because the pages were illegal or because the webmasters were search engine spamming, but because of the page's "offensive" content. In the "Chester's Guide" incident, a councilman in Chester, England discovered that one of the search results for "chester guide" was a satirical page titled "Chester's guide to picking up little girls." Although the page itself was obviously just someone's idea of sick humor, a Chester city councilman (who admitted that he hadn't looked at the page, saying that the title told him everything he needed to know) urged Google to remove the page from their index. Google at first refused, but later manually blacklisted the page to prevent it from appearing in their search results.
Whether or not you think this was the right decision, probably depends on what you think is the purpose of Google. If Google's purpose is to return the most useful results, then it made sense to remove the link, as Danny Sullivan of Search Engine Watch argued at the time, since it almost certainly was not a useful result for people searching for "Chester Guide." On the other hand, if the primary purpose of Google is to reflect the reality of what pages on the Web feature certain words most prominently (combined with all the other factors that Google weighs, of course), then the results shouldn't be altered.
But more people should at least realize that it happened. The Google disclaimer doesn't precisely say that they never blacklist pages or modify search results ("Google reserves the right to address such requests individually"), but it seems to give most people the impression that that's the case. According to that crudest of Googling techniques for which novice searchers are so frequently lampooned, there appear to be about 400 times as many stories on the Web about the Google "Jew Watch" controversy (where Google stood their ground) as there are stores about the "Chester's Guide" incident (where Google caved).
And Google-number-three Matt Cutts posted on his blog back in March explaining why Google does not remove "offensive" pages from search results; over a hundred comments followed, debating the pros and cons of the position, but none of them mentioned the Chester incident or any other case where Google actually had removed pages except as a result of a court order. One isolated comment from "Anonymous" said:
This is not quite true. I know of at least one web site that was de-listed for containing illegal content and/or promoting illegal activity.
which may or may not have been a reference to the Chester Guide incident. And that was it.
Is this a lot of hay to be making over something that happened years ago? Well, for one thing, I doubt if it happened just once. Consider that the Chester Guide incident involved a public declaration of outrage by a city council, and a public statement from Google, and still hardly anyone knows that it ever happened. If other incidents occurred without those high-profile elements, it would be even harder to discover them now. We'll probably never know how many such incidents took place, unless someone sues Google (maybe the owner of a blacklisted website, or maybe the victim of a RipOffReport hatchet job wondering why that site hadn't been blacklisted long ago), subpoenas Google for a list of cases where pages were de-indexed, and publishes the list if it's not sealed by a court order.
But whether it was one time or a handful, consider that political candidates like Arnold Schwarzenegger and Al Franken got asked during their campaigns about things they did 20 years earlier, and it's fair to ask a candidate about their past, because it's the same person standing in front of you now. Why did you do that? Have you stopped? Why?
And in the big scheme of things, Google is probably more powerful than a single US senator or the governor of California. So, can't we ask? What are their real rules about page removal? Have those rules changed since the Chester's Guide controversy? Can they even tell us what their rules are, or do they consider it a trade secret?
It is well known, of course, that Google censors some results in their search engines branded for different markets like China and even in liberal democracies like Germany. But nobody would call that a slippery slope towards censorship in the US version of Google, because the censorship in the Chinese and German versions is done at the behest of the governments there. On the other hand, Google does admit that they will de-index pages which include credit card numbers or social security numbers (which are all too easy to find on the Web). This might not seem like a controversial position, but even this act of voluntary self-censorship may be dipping their toe in the water further than it seems. Most people do consider their credit card information more private than their home address. But surely there are people like J.D. Salinger who less about the privacy of their credit card number (which is easily changeable) than their home address (which isn't). If someone finds Salinger's address and posts it on the Web, should Salinger be able to demand that Google de-index the page? Why should Google cater to the majority who want to keep their credit card number secret, but not to the minority who care more about keeping their address secret? Another commenter on Matt Cutts's blog post asked:
"hi. I have a question. My mom 'googled' herself and it shows some of her medical problems. She wants/needs these pages removed from search engines."
Again, why shouldn't that be considered at least as private as a credit card number?
And finally, even Google's decision to display an "offensive results" disclaimer, for some results but not for others, raises the same "Where do you draw the line?" questions as the issue of page removal. The Michelle Obama monkey picture gets a disclaimer. But search for 'george w bush' and the first row includes a photoshopped (I think!) image of Bush flipping off the press. Does that warrant a disclaimer as well? (Maybe that's considered less unfair because, even though the picture is fake, it does depict something that actually happened.) The first image result for "bristol palin" is a photo of her engaged in underage drinking — a real photo, but probably unfair to call it the single most relevant photo of her on the Web.
So while Google might consider credit cards and social security numbers and search engine spam to be on one side of a "bright line," and everything else is served up without alteration, I think the line is blurrier than that, for at least those three reasons: (a) credit cards and SSNs are less private than some other that things that Google serves up anyway; (b) Google has unambiguously removed some content that fell outside that bright line, as in the Chester's guide incident, and (c) they make other "slippery slope" judgment calls about search results all the time (as in the question of when to show the disclaimer). So I hope that Google someday comes out with a more complete answer to the question. What is their real policy on what they will remove? The Chester's guide incident — would they do that sort of thing if the same situation came up today, or have their rules changed? If they want to go really deep, then is there a general set of principles from which their rules follow — explaining why, for example, they treat credit card numbers as more private than sensitive medical information? (Google did not respond to my request for comment, either through official channels or the unofficial back channels of friends who work there.)
I hope Google gives an answer some day. Even just to say, "It's a classified internal policy and that's all we're going to tell you." But once and for all, the answer is not "Google doesn't remove content just because it's 'offensive' or 'harmful.'"
Meanwhile, a modest suggestion about the disclaimer displayed above the search results: Put it where people will actually see it, in a separate line below the ads, but above the search results. Right now the link to the disclaimer is displayed as one of three ads across the top, and people don't look at the ads. But hey, people do buy ads, so if you push the disclaimer down a bit where people will read it, you also free up space for 50% more ad revenue!
-
Yes, Google Does De-List Pages; But When?
Frequent Slashdot contributor Bennett Haselton writes "Google finds itself inserting a disclaimer once again above some offensive search results. But the disclaimer still leads many to believe (incorrectly) that Google doesn't tamper with search results even in cases of 'harmful' or 'offensive' material. We know that Google has in fact de-listed some pages at the request of offended parties. What is their real policy on the issue?" Read on for Bennet's essay.In 2004, when Google users discovered that the top search result for the word "Jew" was the anti-semitic site Jew Watch, Google ran a disclaimer in the space usually reserved for ads, explaining that their results only reflected the reality of link counts on the Web, and that they did not endorse any Web sites which appeared at the top of their listings. Now the disclaimer has been dusted off again, as the top result on Google Images for "Michelle Obama" is a picture of a monkey's face with Michelle's hairdo. (Ironically, it looks as if the original image would have fallen out of the rankings, if it hadn't been for a follow-up blog post about the controversy, which itself now comes up as the first result.)
I first heard about the controversy from Dennis Prager's column in which he takes a New York Times columnist to task, because the columnist complained about "racially offensive images of the first couple" that come up in Google searches. Prager was unable to find any examples from Googling "first couple" or "Michelle and Barack Obama pictures," so he concluded that the NYT columnist "wildly exaggerated, if not made up" his claims. I tried Google Image searches for "first couple," "Barack Obama," and some other terms, and I couldn't find anything controversial either. However, it only took 10 seconds to enter "first couple google images controversy" on the regular Google Web search and find multiple blog posts explaining what all the fuss was about. Back to Google 101 for Dennis.
Many of the blog posts refer to Google's disclaimer about not tampering with search results. Those on one side are urging Google to make an exception and "fix" the results, while others sagely observe that Google just reflects reality, it doesn't create it.
All of this punditry is starting from a premise that's wrong. Google has actually removed pages from their search results — not because the pages were illegal or because the webmasters were search engine spamming, but because of the page's "offensive" content. In the "Chester's Guide" incident, a councilman in Chester, England discovered that one of the search results for "chester guide" was a satirical page titled "Chester's guide to picking up little girls." Although the page itself was obviously just someone's idea of sick humor, a Chester city councilman (who admitted that he hadn't looked at the page, saying that the title told him everything he needed to know) urged Google to remove the page from their index. Google at first refused, but later manually blacklisted the page to prevent it from appearing in their search results.
Whether or not you think this was the right decision, probably depends on what you think is the purpose of Google. If Google's purpose is to return the most useful results, then it made sense to remove the link, as Danny Sullivan of Search Engine Watch argued at the time, since it almost certainly was not a useful result for people searching for "Chester Guide." On the other hand, if the primary purpose of Google is to reflect the reality of what pages on the Web feature certain words most prominently (combined with all the other factors that Google weighs, of course), then the results shouldn't be altered.
But more people should at least realize that it happened. The Google disclaimer doesn't precisely say that they never blacklist pages or modify search results ("Google reserves the right to address such requests individually"), but it seems to give most people the impression that that's the case. According to that crudest of Googling techniques for which novice searchers are so frequently lampooned, there appear to be about 400 times as many stories on the Web about the Google "Jew Watch" controversy (where Google stood their ground) as there are stores about the "Chester's Guide" incident (where Google caved).
And Google-number-three Matt Cutts posted on his blog back in March explaining why Google does not remove "offensive" pages from search results; over a hundred comments followed, debating the pros and cons of the position, but none of them mentioned the Chester incident or any other case where Google actually had removed pages except as a result of a court order. One isolated comment from "Anonymous" said:
This is not quite true. I know of at least one web site that was de-listed for containing illegal content and/or promoting illegal activity.
which may or may not have been a reference to the Chester Guide incident. And that was it.
Is this a lot of hay to be making over something that happened years ago? Well, for one thing, I doubt if it happened just once. Consider that the Chester Guide incident involved a public declaration of outrage by a city council, and a public statement from Google, and still hardly anyone knows that it ever happened. If other incidents occurred without those high-profile elements, it would be even harder to discover them now. We'll probably never know how many such incidents took place, unless someone sues Google (maybe the owner of a blacklisted website, or maybe the victim of a RipOffReport hatchet job wondering why that site hadn't been blacklisted long ago), subpoenas Google for a list of cases where pages were de-indexed, and publishes the list if it's not sealed by a court order.
But whether it was one time or a handful, consider that political candidates like Arnold Schwarzenegger and Al Franken got asked during their campaigns about things they did 20 years earlier, and it's fair to ask a candidate about their past, because it's the same person standing in front of you now. Why did you do that? Have you stopped? Why?
And in the big scheme of things, Google is probably more powerful than a single US senator or the governor of California. So, can't we ask? What are their real rules about page removal? Have those rules changed since the Chester's Guide controversy? Can they even tell us what their rules are, or do they consider it a trade secret?
It is well known, of course, that Google censors some results in their search engines branded for different markets like China and even in liberal democracies like Germany. But nobody would call that a slippery slope towards censorship in the US version of Google, because the censorship in the Chinese and German versions is done at the behest of the governments there. On the other hand, Google does admit that they will de-index pages which include credit card numbers or social security numbers (which are all too easy to find on the Web). This might not seem like a controversial position, but even this act of voluntary self-censorship may be dipping their toe in the water further than it seems. Most people do consider their credit card information more private than their home address. But surely there are people like J.D. Salinger who less about the privacy of their credit card number (which is easily changeable) than their home address (which isn't). If someone finds Salinger's address and posts it on the Web, should Salinger be able to demand that Google de-index the page? Why should Google cater to the majority who want to keep their credit card number secret, but not to the minority who care more about keeping their address secret? Another commenter on Matt Cutts's blog post asked:
"hi. I have a question. My mom 'googled' herself and it shows some of her medical problems. She wants/needs these pages removed from search engines."
Again, why shouldn't that be considered at least as private as a credit card number?
And finally, even Google's decision to display an "offensive results" disclaimer, for some results but not for others, raises the same "Where do you draw the line?" questions as the issue of page removal. The Michelle Obama monkey picture gets a disclaimer. But search for 'george w bush' and the first row includes a photoshopped (I think!) image of Bush flipping off the press. Does that warrant a disclaimer as well? (Maybe that's considered less unfair because, even though the picture is fake, it does depict something that actually happened.) The first image result for "bristol palin" is a photo of her engaged in underage drinking — a real photo, but probably unfair to call it the single most relevant photo of her on the Web.
So while Google might consider credit cards and social security numbers and search engine spam to be on one side of a "bright line," and everything else is served up without alteration, I think the line is blurrier than that, for at least those three reasons: (a) credit cards and SSNs are less private than some other that things that Google serves up anyway; (b) Google has unambiguously removed some content that fell outside that bright line, as in the Chester's guide incident, and (c) they make other "slippery slope" judgment calls about search results all the time (as in the question of when to show the disclaimer). So I hope that Google someday comes out with a more complete answer to the question. What is their real policy on what they will remove? The Chester's guide incident — would they do that sort of thing if the same situation came up today, or have their rules changed? If they want to go really deep, then is there a general set of principles from which their rules follow — explaining why, for example, they treat credit card numbers as more private than sensitive medical information? (Google did not respond to my request for comment, either through official channels or the unofficial back channels of friends who work there.)
I hope Google gives an answer some day. Even just to say, "It's a classified internal policy and that's all we're going to tell you." But once and for all, the answer is not "Google doesn't remove content just because it's 'offensive' or 'harmful.'"
Meanwhile, a modest suggestion about the disclaimer displayed above the search results: Put it where people will actually see it, in a separate line below the ads, but above the search results. Right now the link to the disclaimer is displayed as one of three ads across the top, and people don't look at the ads. But hey, people do buy ads, so if you push the disclaimer down a bit where people will read it, you also free up space for 50% more ad revenue!
-
Yes, Google Does De-List Pages; But When?
Frequent Slashdot contributor Bennett Haselton writes "Google finds itself inserting a disclaimer once again above some offensive search results. But the disclaimer still leads many to believe (incorrectly) that Google doesn't tamper with search results even in cases of 'harmful' or 'offensive' material. We know that Google has in fact de-listed some pages at the request of offended parties. What is their real policy on the issue?" Read on for Bennet's essay.In 2004, when Google users discovered that the top search result for the word "Jew" was the anti-semitic site Jew Watch, Google ran a disclaimer in the space usually reserved for ads, explaining that their results only reflected the reality of link counts on the Web, and that they did not endorse any Web sites which appeared at the top of their listings. Now the disclaimer has been dusted off again, as the top result on Google Images for "Michelle Obama" is a picture of a monkey's face with Michelle's hairdo. (Ironically, it looks as if the original image would have fallen out of the rankings, if it hadn't been for a follow-up blog post about the controversy, which itself now comes up as the first result.)
I first heard about the controversy from Dennis Prager's column in which he takes a New York Times columnist to task, because the columnist complained about "racially offensive images of the first couple" that come up in Google searches. Prager was unable to find any examples from Googling "first couple" or "Michelle and Barack Obama pictures," so he concluded that the NYT columnist "wildly exaggerated, if not made up" his claims. I tried Google Image searches for "first couple," "Barack Obama," and some other terms, and I couldn't find anything controversial either. However, it only took 10 seconds to enter "first couple google images controversy" on the regular Google Web search and find multiple blog posts explaining what all the fuss was about. Back to Google 101 for Dennis.
Many of the blog posts refer to Google's disclaimer about not tampering with search results. Those on one side are urging Google to make an exception and "fix" the results, while others sagely observe that Google just reflects reality, it doesn't create it.
All of this punditry is starting from a premise that's wrong. Google has actually removed pages from their search results — not because the pages were illegal or because the webmasters were search engine spamming, but because of the page's "offensive" content. In the "Chester's Guide" incident, a councilman in Chester, England discovered that one of the search results for "chester guide" was a satirical page titled "Chester's guide to picking up little girls." Although the page itself was obviously just someone's idea of sick humor, a Chester city councilman (who admitted that he hadn't looked at the page, saying that the title told him everything he needed to know) urged Google to remove the page from their index. Google at first refused, but later manually blacklisted the page to prevent it from appearing in their search results.
Whether or not you think this was the right decision, probably depends on what you think is the purpose of Google. If Google's purpose is to return the most useful results, then it made sense to remove the link, as Danny Sullivan of Search Engine Watch argued at the time, since it almost certainly was not a useful result for people searching for "Chester Guide." On the other hand, if the primary purpose of Google is to reflect the reality of what pages on the Web feature certain words most prominently (combined with all the other factors that Google weighs, of course), then the results shouldn't be altered.
But more people should at least realize that it happened. The Google disclaimer doesn't precisely say that they never blacklist pages or modify search results ("Google reserves the right to address such requests individually"), but it seems to give most people the impression that that's the case. According to that crudest of Googling techniques for which novice searchers are so frequently lampooned, there appear to be about 400 times as many stories on the Web about the Google "Jew Watch" controversy (where Google stood their ground) as there are stores about the "Chester's Guide" incident (where Google caved).
And Google-number-three Matt Cutts posted on his blog back in March explaining why Google does not remove "offensive" pages from search results; over a hundred comments followed, debating the pros and cons of the position, but none of them mentioned the Chester incident or any other case where Google actually had removed pages except as a result of a court order. One isolated comment from "Anonymous" said:
This is not quite true. I know of at least one web site that was de-listed for containing illegal content and/or promoting illegal activity.
which may or may not have been a reference to the Chester Guide incident. And that was it.
Is this a lot of hay to be making over something that happened years ago? Well, for one thing, I doubt if it happened just once. Consider that the Chester Guide incident involved a public declaration of outrage by a city council, and a public statement from Google, and still hardly anyone knows that it ever happened. If other incidents occurred without those high-profile elements, it would be even harder to discover them now. We'll probably never know how many such incidents took place, unless someone sues Google (maybe the owner of a blacklisted website, or maybe the victim of a RipOffReport hatchet job wondering why that site hadn't been blacklisted long ago), subpoenas Google for a list of cases where pages were de-indexed, and publishes the list if it's not sealed by a court order.
But whether it was one time or a handful, consider that political candidates like Arnold Schwarzenegger and Al Franken got asked during their campaigns about things they did 20 years earlier, and it's fair to ask a candidate about their past, because it's the same person standing in front of you now. Why did you do that? Have you stopped? Why?
And in the big scheme of things, Google is probably more powerful than a single US senator or the governor of California. So, can't we ask? What are their real rules about page removal? Have those rules changed since the Chester's Guide controversy? Can they even tell us what their rules are, or do they consider it a trade secret?
It is well known, of course, that Google censors some results in their search engines branded for different markets like China and even in liberal democracies like Germany. But nobody would call that a slippery slope towards censorship in the US version of Google, because the censorship in the Chinese and German versions is done at the behest of the governments there. On the other hand, Google does admit that they will de-index pages which include credit card numbers or social security numbers (which are all too easy to find on the Web). This might not seem like a controversial position, but even this act of voluntary self-censorship may be dipping their toe in the water further than it seems. Most people do consider their credit card information more private than their home address. But surely there are people like J.D. Salinger who less about the privacy of their credit card number (which is easily changeable) than their home address (which isn't). If someone finds Salinger's address and posts it on the Web, should Salinger be able to demand that Google de-index the page? Why should Google cater to the majority who want to keep their credit card number secret, but not to the minority who care more about keeping their address secret? Another commenter on Matt Cutts's blog post asked:
"hi. I have a question. My mom 'googled' herself and it shows some of her medical problems. She wants/needs these pages removed from search engines."
Again, why shouldn't that be considered at least as private as a credit card number?
And finally, even Google's decision to display an "offensive results" disclaimer, for some results but not for others, raises the same "Where do you draw the line?" questions as the issue of page removal. The Michelle Obama monkey picture gets a disclaimer. But search for 'george w bush' and the first row includes a photoshopped (I think!) image of Bush flipping off the press. Does that warrant a disclaimer as well? (Maybe that's considered less unfair because, even though the picture is fake, it does depict something that actually happened.) The first image result for "bristol palin" is a photo of her engaged in underage drinking — a real photo, but probably unfair to call it the single most relevant photo of her on the Web.
So while Google might consider credit cards and social security numbers and search engine spam to be on one side of a "bright line," and everything else is served up without alteration, I think the line is blurrier than that, for at least those three reasons: (a) credit cards and SSNs are less private than some other that things that Google serves up anyway; (b) Google has unambiguously removed some content that fell outside that bright line, as in the Chester's guide incident, and (c) they make other "slippery slope" judgment calls about search results all the time (as in the question of when to show the disclaimer). So I hope that Google someday comes out with a more complete answer to the question. What is their real policy on what they will remove? The Chester's guide incident — would they do that sort of thing if the same situation came up today, or have their rules changed? If they want to go really deep, then is there a general set of principles from which their rules follow — explaining why, for example, they treat credit card numbers as more private than sensitive medical information? (Google did not respond to my request for comment, either through official channels or the unofficial back channels of friends who work there.)
I hope Google gives an answer some day. Even just to say, "It's a classified internal policy and that's all we're going to tell you." But once and for all, the answer is not "Google doesn't remove content just because it's 'offensive' or 'harmful.'"
Meanwhile, a modest suggestion about the disclaimer displayed above the search results: Put it where people will actually see it, in a separate line below the ads, but above the search results. Right now the link to the disclaimer is displayed as one of three ads across the top, and people don't look at the ads. But hey, people do buy ads, so if you push the disclaimer down a bit where people will read it, you also free up space for 50% more ad revenue!
-
Censorship By Glut
Frequent Slashdot contributor Bennett Haselton writes "A 2006 paper by Matthew Salganik, Peter Dodds and Duncan Watts, about the patterns that users follow in choosing and recommending songs to each other on a music download site, may be the key to understanding the most effective form of "censorship" that still exists in mostly-free countries like the US It also explains why your great ideas haven't made you famous, while lower-wattage bulbs always seem to find a platform to spout off their ideas (and you can keep your smart remarks to yourself)." Read on for the rest of Bennett's take on why the effects of peer ratings on a music download site go a long way towards explaining how good ideas can effectively be "censored" even in a country with no formal political censorship.
In a country where you're free to say almost anything in the political arena, I think the only real censorship of good ideas is what you could call "censorship by glut". If you had a brilliant, absolutely airtight argument that we should do something -- indict President Bush (or Barack Obama), or send foreign investment to Chechnya, or let kids vote -- but you weren't an established writer or well-known blogger, how much of a chance do you think your argument would have against the glut of Web rants and other pieces of writing out there? Especially if your argument required people to read it and think about it for at least an hour? Perhaps your situation could be compared to that of a brilliantly talented band submitting a song for Matthew Salganik's experiment.
What Salganik and his co-authors did was recruit users through advertisements on Bolt.com (skewing toward a teen demographic) to sign up for a free music download site. Users would be able to listen to full-length songs and then decide whether or not to download the song for free. Some users were randomly divided into eight artificial "worlds" in which, while a user was listening to a song, they could see the number of times that the song had been downloaded by other users in the same world -- but only by other users within their own world, not counting the downloads by users in other worlds. The test was to see whether certain songs could become popular in some worlds while languishing in others, despite the fact that all groups consisted of randomly assigned populations that all had equal access to the same songs. The experiment also attempted to measure the "merit" of individual songs by assigning some users to an "independent" group, where they could listen to songs and choose whether to download them, but without seeing the number of times the song had been downloaded by anyone else; the merit of the song was defined as the number of times that users in the independent group decided to download the song after listening to it. Experimenters looked at whether the merit of the song had any effect on the popularity levels it achieved in the eight other "worlds".
The authors summed it up: "In general, the 'best' songs never do very badly, and the 'worst' songs never do extremely well, but almost any other result is possible." They also noted that in the "social influence" worlds where users could see each others' downloads, increasing download numbers had a snowball effect that widened the difference between the successful songs and the unsuccessful: "We found that all eight social influence worlds exhibit greater inequality -- meaning popular songs are more popular and unpopular songs are less popular -- than the world in which individuals make decisions independently." Figures 3(A) and 3(C) in the paper show that the relationship between a song's merit and its success in any given world -- while not completely random -- is tenuous. And if you're a talented musician and you want to get really depressed about your prospects of hitting the big time, Figures 3(B) and 3(D) show the relationship between a song's measured merit and its actual number of sales in the real world. (Although those graphs may cheer you up if you're a struggling musician who hasn't made it big yet -- maybe it's not you, it's just the roll of the dice.)
As the Richard Thaler and Cass Sunstein put it in their all-around fascinating book Nudge , where I first read about the Salganik study:In many domains people are tempted to think, after the fact, that an outcome was entirely predictable, and that the success of a musician, an actor, an author, or a politician was inevitable in light of his or her skills and characteristics. Beware of that temptation. Small interventions and even coincidences, at a key stage, can produce large variations in the outcome. Today's hot singer is probably indistinguishable from dozens and even hundreds of equally talented performers whose names you've never heard. We can go further. Most of today's governors are hard to distinguish from dozens or even hundreds of politicians whose candidacies badly fizzled.
Is the blogosphere, or the "marketplace of ideas" in general, any different? If a random sample of bloggers were rated based on some independent measure of merit -- for example, independent ratings from a random sampling of blog readers, who were looking at the bloggers' writing samples for the first time, analogous to users in Salganik's "independent" world -- and then correlate that with the bloggers' traffic or some other measure of success, it's not hard to imagine the results would be similar to those of the 8-worlds experiment: the best often rise to the top, the very worst rarely do, but success in the vast middle would be close to random. In fact, while music listeners would have no logical reason to like a song just because others did, users in the blogosphere and other public forums would have several rational reasons to cluster around writers who are already popular: (1) errors are more likely to have been spotted and pointed out by someone else; (2) as an extension of that, others are more likely to have provided comments and other value-added content; (3) if you are the first person to spot an error, it's more important on a popular blog to point out the error and stop the misinformation from spreading, than on a minor blog that nobody has ever heard of. So the "snowball effect" of popularity in the blogosphere would be even more pronounced.
Then why do so many people believe in what Thaler and Sunstein call the "inevitability" of success based on merit, in domains like music, politics, and writing? I think it's because the belief is what scientists call an unfalsifiable one -- if the "best" acts are assumed to be the ones that end up on the top of the pile, then the marketplace has always sorted the "best" content to the top, by definition. Since the definition is circular, the premise could never be disproved by any amount of counter-evidence -- even if an act that used to be popular, suddenly falls under the radar, that could be seen as "proof" that they lost whatever magic touch they used to have, not as evidence of the arbitrariness of the market! The only disproof would be an artificial experiment like Salganik's, showing that once you get beyond a certain threshold of quality, commercial success has little relationship to independently measured merit -- but such experiments, which in Salganik's case required the cooperation of over 14,000 users, don't come along very often. And as long as most people don't realize how arbitrary the existing marketplaces are, there isn't enough demand to justify building a system that could work better -- indeed, to even justify asking the question of whether a system could be designed that would work better.
And that, I think, is how "censorship by glut" really works. It's not just the sheer amount of written content that censors small voices -- if you happen to know about a particular writer that you consider a fount of wisdom, then the existence of a billion other Web pages won't stop you from reading that writer's content. And it's not as if there aren't plenty of people who realize that success can be highly arbitrary. The problem is that as long as most people assume that the existing marketplace of ideas does a good job of sorting the best content to the top, then they'll be more inclined to stay with the most popular news sites and blogs, and even the minority who know that it's largely a lottery, will have no effective way of finding the best content among everything else, so they'll end up sticking with the most popular sites as well. Worse, as a secondary effect, most people with something useful to contribute won't even bother, if they don't already have a large built-in audience. I know plenty of people who could write insightful essays about social and technological issues, essays that would give most readers a new perspective such that they would definitely say afterwards: "That was worth my time to read it." But it wouldn't be worth it to the writers, because they know that their content isn't going to get magically sorted into its deserved place in the hierarchy.
(My own favorite blog that nobody's ever heard of is Seth Finkelstein's InfoThought, which is usually logical and insightful and is only about 25% of the time about how "nobody ever reads this blog, so what's the point". His Guardian columns are also good and usually don't have that subtext, perhaps because it's considered impolite to use a newspaper's column-inches (column-centimeters?) to complain that you have no voice.)
So can this problem be avoided, or is inequality and arbitrariness just a permanent part of the marketplace for content and ideas? You could create an artificial world that would sort user-submitted content according to some other algorithm -- and even if it didn't give good writers the fame that they theoretically deserved in the larger world, it might still provide them with enough of an audience within the artificial universe, to make it worth their time to keep writing. One option would be to use Salganik's "independence" world model, where users would read content without being able to see the ratings that other people had given to it, or without even seeing recommendations from similarly-minded friends within the system. The trouble is that without any information about what other readers liked, without any starting point to sort good content from bad content, it may not be worth the reader's time to read through all the dreck to find the occasional buried treasure. I believe about as strongly as a person can believe, that the existing marketplace for content is far from meritocratic, for example that there are probably thousands of songs on iTunes that I've never heard of but would nonetheless love -- but even I don't spend time listening to the 30-second clips of random songs on iTunes, because it takes too long to find the stuff I would like.
But I submit there is a solution -- a variant of an argument that I've suggested for stopping cheating on Digg, or building Wikia search into a meritocratic search engine, or helping the best writers rise to the top on Google Knol. The solution is sorting based on ratings from a random sample of users. The remainder of this speculation will be very theoretical, and will at times seem like a Rube-Goldberg approach to what should be a simple problem. But at each juncture, the complications to the algorithm are motivated by an argument that anything simpler would not work. At many points along the way, it will be tempting to throw up one's hands and say, "Why go to all this trouble, the existing system works well enough." But this statement is hard to quantify with any actual evidence -- unless you're just using the circular definition above, that whatever rises to the top is automatically the "best".
For music listeners, the gist of the algorithm is: When an artist submits a new song in the alt-rock category for example, the song is distributed to a random sample of 20 users who have indicated an interest in that genre. If the average rating from those users is high enough, the song gets recommended to all of the site's users who are interested in alt-rock. If the average rating is not high enough, then the artist receives a notification, perhaps with a list of comments from the listeners suggesting what to improve. As long as the initial random sample of users is large enough that the average rating is indicative of what the rest of the site's alt-rock fans would think, the good content will get to be enjoyed by all of the site's alt-rock customers, while the bad content would fizzle after only wasting the time of 20 people. If it turns out that a random selection of 20 users are typically too lazy to rate the songs that are submitted to them, you could even make artists submit $10 to have their songs rated by the focus group, and pay each of the 20 raters $0.50 each for their trouble. Artists can't withhold payment as revenge for a bad rating, so the average ratings should still be proportional to the song's actual quality.
At this point, you might object that this system suffers from the same unfalsifiable, circular reasoning as the belief that the marketplace rewards the "best" content, if the best content is the content that wins in the marketplace. If I define the "best" content to be the content that gets the highest average score in a random focus group, then of course this algorithm sorts the best content to the top, because that's how "best" was defined! But this system does actually have a non-trivial property: If you implement the system in multiple separate "worlds" (similar to those that Salganik created), then provided your focus groups are large enough to provide representative random samples, the same content should rise to the top in each of the worlds, unlike the results in Salganik's experiment.
This actually wouldn't be the case if the initial focus groups were not big enough -- then random variations in a few voters' opinions could cause many songs to succeed in one world and fail in another. So it's a non-trivial property that is not automatically true, and would not be true if you made an error in designing the system, like making the focus groups too small. But the larger the size of the random sample, the smaller the variance in the expected value of the average of their ratings, and the greater agreement you would expect between the results from different worlds.
As Salganik pointed out to me, this system does under-reward songs that might require repeated listenings over time to gain an appreciation of their qualities. But even this, strictly speaking, can be modeled in exchange for cash -- I'll pay 20 users $2 each if they listen to my song once today, once in three days, and once again a week after that (the site could stream the song to them to provide at least some likelihood that the users weren't cheating). This assumes some things, such as that repeated exposure has the same growing-on-you effect even if the exposure is forced -- but in the real world, songs often grow on you from repeated listenings that are "forced" anyway, if they're played in the doctor's office or on the radio when you don't bother to change the channel. And this might be more complicated than necessary -- often when a song grows on you, it at least interests you enough the first time you hear it, that you'd give it a positive rating on the first listen, which is all that the site requires for the song's success.
However, if you try to adapt this trick to a meritocracy for written content, you run into different problems. With a song, if you poll a random sample of users, the odds are very small that anyone being polled will be a vested interest in the success of the song, like one of the band members or one of the song's producers (assuming the population of users is large enough, and the song's producers have not been able to create a huge number of "sockpuppet" accounts to manipulate the voting). So you can assume the ratings will be free of any prior bias. But with a political post, for example, if you write a pro-Bush or anti-Bush essay, it's quite likely that among a random sample of users, there will be people who are biased to vote up (or vote down) any post that has anything good to say about the President. The essays voted to the top may not be the best-written ones, but simply the ones that pander to the most popularly held opinions.
But if the "best" essays are not the ones that receive the highest percentage of positive votes, even when polling a random sample of independent users -- which I was advocating as the gold standard for measuring merit -- then how do you define what makes the "best" essays, anyway? There are many possible answers, but I suggest: A necessary condition for being among the "best" essays would be to convince the most people of something that they didn't believe before, without resorting to tricks such as blatantly fabricating statistics or attributing made-up quotes. This is not a sufficient condition for merit -- maybe the point of view that you're convincing people of, is still wrong -- but I submit that if you're not at least changing some people's minds, then there's no point. An essay that changes a lot of people's minds in a random focus group, is usually worth reading, if only to see why it has that effect.
Unfortunately, this doesn't suggest a better way to poll users about the merit of an essay, because if you ask users, "Were you a Bush supporter before reading this essay?" and "Were you a Bush supporter afterwards?", Bush supporters are eventually going to figure out that the way to give the essay a high score on the mind-changing scale, would be to (falsely) say that they were not a Bush supporter before reading the essay, but they were one afterwards. So you'd still end up rewarding the essays that reinforce pre-existing opinions instead of the ones that change people's minds.
From here the counter-measures and counter-counter-measures get increasingly complicated. For each category of essays that a user wants to rate, such as Bush opinion pieces, you could require new users to enter their current opinion: either pro-Bush or anti-Bush. Then if they were asked to rate a pro-Bush essay, they would only be able to vote that the essay "changed their minds" by switching their registered opinion from "anti-Bush" to "pro-Bush". But Bush supporters could sign up initially as anti-Bush, just in the hopes of being part of a random focus group so they could cast their mind-changing vote for a Bush essay by changing their registration to "pro-Bush"! However, each user would only be able to do that once -- or do you allow users, after they've switched from anti-Bush to pro-Bush, to "reload" by spontaneously switching back to anti-Bush for no reason at all, so they're all set to cast a mind-changing vote for the next pro-Bush essay? Or would they only be allowed to switch back to anti-Bush, by casting a mind-changing vote as part of a random focus group for an anti-Bush essay -- thus giving a boost to an anti-Bush screed, as part of the price they pay for the next vote they cast for a pro-Bush piece? Then users could still game the system, by switching to "anti-Bush" when casting a vote for a very poorly written anti-Bush essay that they don't think anybody else will vote for anyway, and then switching back to "pro-Bush" only for the good essays that have a shot, hoping that their votes will coalesce around the decently-written pro-Bush essays and push them to the front page...
Am I over-thinking this? I submit this is an area where there's been too much under-thinking. Haven't we all been tempted to believe that the marketplace of ideas -- not to mention bands, blog posts, and business ventures -- efficiently sorts content to the place in the hierarchy of rewards that it deserves, without having any real evidence for this, except the circular definition of "quality" as being proportional to success? And the more people believe this, the more that marginalized voices will effectively be censored, even when they have something brilliant to contribute. We should at least think about ways that we could do better. Or else, prove logically that it can't be done (a logical proof can only approximate the real world, but it could show that such a pure meritocracy would be very improbable, or wouldn't work well). However I think the ideas above make it seem unlikely that a meritocracy is logically impossible. Maybe they're a step in the right direction. Maybe someone else's ideas would be better. The important thing is that a meritocratic algorithm be judged by something other than a circular definition, which simply decrees by fiat that the winning content is the best. -
The Knol Hypothesis
Frequent Slashdot contributor Bennett Haselton sends in his latest, which begins like this and continues behind the link. "When Google's VP of Engineering announced their proposed Knol project, where users can submit articles on different subjects and share in the AdSense revenue from the article pages, he didn't mention "Wikipedia," but practically everyone else did who blogged about it. Here's what I think will happen, if Knol is implemented according to the plan: Even though it won't technically be a "Wikipedia fork," it will quickly become equivalent to one, with a "gold rush" of users copying content from Wikipedia to Knol articles hoping for a piece of the AdSense dollars. But I submit this will be a good thing, especially if bona fide experts in different fields join the gold rush as well and start signing their names to articles that they've vetted."
First, I've been saying for a while that someone should fork Wikipedia and start assigning "ownership" of articles to credentialed experts where possible, so that an article can be cited as a source that has been vetted by a recognized individual, and to guard against vandalism. Citizendium does something like this, but started from the ground up rather than fork Wikipedia. I argued that they should fork as much as possible from Wikipedia (having experts "bless" the content in the process); the project's official reason for not doing this was that authors are more motivated when starting with a clean slate than when taking over someone else's article. True, we all know the energizing feeling of a clean slate compared to the sluggish feeling of taking over a 50%-completed project with all of its flaws and compromises, but the "energizing feeling" often doesn't make up for the advantages of having 50% of the work already done for you (which is, in a nutshell, the only reason people ever finish 50%-completed projects instead of starting over!).
So could some other Wikipedia fork achieve the same thing? Programmer/blogger and Guardian columnist Seth Finkelstein, a frequent Wikipedia critic, has pointed out that other sites such as http://veropedia.com/ have tried to build a "verified" version of Wikipedia. "But," he writes, "it doesn't work for many reasons:
1) Maintenance
2) Nobody knows the site exists, or uses it.
3) Google will kill the site's ranking, because of "duplicate content"
4) Roughly 99% of Wikipedia's value is the Google-rank it has, and sites trying to copy its content don't have — or get — that Google-rank.
All true. But Knol has a shot at solving all of these problems. #1 should be mitigated if users earn money for maintaining articles — and besides, many articles like "Abraham Lincoln" won't need much maintenance anyway. #2 should not be an issue since it's a Google project. #3 and #4 depend on how Google lists Knol pages in its search results. The VP's blog post says only,
"Our job in Search Quality will be to rank the knols appropriately when they appear in Google search results. We are quite experienced with ranking web pages, and we feel confident that we will be up to the challenge."
Of course the question on everyone's minds, not answered directly by those sentences, is whether Knol pages will get any special treatment in search rankings. Google would probably be criticized if they manipulated the results outright. But they might achieve the same result indirectly — for example, having a tab across the top of their search results page for "Knol results," along with the tabs for Web, images, and news. Or if Knol results get killed for "duplicate content," Google might (legitimately) consider this a bug and tweak their duplicate-detection algorithm. Thus Knol would have the same advantage in Google that Microsoft's Media Player has on Windows: The operating system doesn't favor Media Player directly, but compatibility problems with Media Player will always get fixed first (while the RealPlayer people have to watch their programs get broken by Windows upgrades). One way or another, it's pretty certain that Knol results are not going to be "unfindable" on Google.
Now, I'm sure Knol will not formally fork Wikipedia. I wouldn't see any problem with them doing that, but it would be too controversial, after the VP announced it without ever mentioning "Wikipedia," and with Google already dealing with speculation that they're only creating Knol to complete with Wikipedia in their own search results. But with users having cash incentives to copy content from Wikipedia, probably most of the content would get replicated very quickly, and I would be surprised if many users didn't start writing scripts to robo-copy as much content from Wikipedia as possible.
Then you get to the point where experts start improving it. If the first couple of entries on "Physics" are just the robo-copied Wikipedia version, "signed" by users that nobody has ever heard of, this is barely an improvement over the unsigned article on Wikipedia itself. But then only one Physics professor in the entire world has to think it's worth their while to read the standard Wikipedia article, make any necessary corrections, and sign their name to it on Knol — and now you have a version that has been vetted by a credentialed expert, increasing its value many times to people who want to cite it as a source, or who want a higher degree of confidence that it's accurate. (Hopefully Knol will allow authors to confirm their e-mail addresses and display them — in an image, presumably, to stop them being scraped by spammers. This will allow professors to prove that they really have faculty .edu addresses and enhance the credibility of their articles, something I suggested for Citizendium.)
So, some criticisms of Wikipedia would not apply to Knol. Author Nick Carr has written of Wikipedia,
"Certainly, it's useful - I regularly consult it to get a quick gloss on a subject. But at a factual level it's unreliable, and the writing is often appalling. I wouldn't depend on it as a source, and I certainly wouldn't recommend it to a student writing a research paper."
When I asked if he would recommend Knol for the same purpose, he was more optimistic:
"Probably. Since a Knol would be written by an identifiable person at an identifiable point in time, I don't see why you wouldn't treat it, in doing research, in a similar way that you'd treat, say, an article by that person. Obviously, you'd need to judge the writer's expertise and authority when deciding whether or not to draw on his or her work, which becomes somewhat more problematic where no editorial or peer-review system applies, as in Knol."
This is where I think the value of a professor's .edu e-mail address comes in, which can at least establish a writer's authority in their subject. I asked Seth Finkelstein whether he would recommend Knol in those same circumstances (verified professor's .edu address, etc.), and his take was, "Of course I would, but you loaded the question in a way so as to remove any problem from it." Well, yeah. I just happen to think Knol actually could remove those problems.
Then there was a little-noticed phrase in Google's blog post that suggests another area where Knol could improve over Wikipedia: the inclusion of "how-to-fix-it instructions." Given that people often need how-to instructions a lot more badly than they need encyclopedia articles, it's surprising that there hasn't been an attempt to standardize around a "Wikipedia of how-to's." Perhaps it's because the Web itself actually does pretty well for that — type in the text of some error message, and you'll usually get some hits on support forums where people ran into the same problem. The trouble is that the ranking of search results depends on the popularity of the site, not on whether the thread ended with someone posting a solution to the problem, so you might have to read through a lot of search results to find an answer. And if you're an expert who happens to know how to do or fix something, there's not much incentive for you to post a page about it (even with AdSense ads), because your page will get buried in the search results beneath all the support forums discussing the same question, even if your post is more concise and useful. Some gurus like Dave Taylor and Leo Notenboom have written so many how-to articles that their own sites have risen through the Google rankings, so if they write a how-to article about something, it will get read (which, of course, creates an incentive for them to write more of them). But for a new expert just starting to write how-to articles, it would take a long time to reach that critical mass.
Knol, however, creates an incentive for experts to start posting how-to-fix-it advice and start reaping the rewards right away, since your how-to articles are just as easy to find under a given subject as anyone else's. Your earnings would start out small as you began to write articles, but they would rise in proportion to the number of articles you wrote, and you wouldn't have to slog along writing for no reward like a typical blogger or site creator, hoping to hit "critical mass" some day. You'd find out early on what the reward would be (financial and otherwise) for the work you were doing, and could decide if you wanted to continue.
Actually, the possibility of "instant rewards" does depend on how Knol articles are ranked against each other within a given topic. The Google blog post says, "For many topics, there will likely be competing knols on the same subject," and, "Knols will include strong community tools. People will be able to submit comments, questions, edits, additional content, and so on. Anyone will be able to rate a knol or write a review of it." Presumably the top-rated articles on a given topic will be displayed first by default, so I'm making the assumption that good articles really will get sorted to the top. But if there are already 50 articles on some topic, even if you know you can write a better one, how do you know it would rise to the top of the pile? If 10 people rate your article a 9, and all the other articles have been rated by 100 people each and got an average rating of a 7, then yours should still be listed as the highest in terms of average rating. But how do you get even those first 10 people to see your article? You could invite your friends, but then how do you stop anyone from gaming the system by inviting their friends and asking them all to rate their article a 10?
I'd written about this in the context of whether Wikia Search might try to solve these problems by allowing users to vote on search results, if they could prevent people from gaming the system. That was basically just me thinking out loud that something like that would be cool, before Wikia Search announced any specifics, and I haven't heard that Wikia is trying anything like that. But now that Google has stated that they will use voting and ranking systems in Knol, the question is how to reward new authors while preventing cheating. I suggested some ideas in an article about how to stop cheating and vote-buying on digg. One idea was that you could have a section on the page that showed people links to different articles at random, so that users couldn't self-select on what articles were shown to them, and if those randomly selected users followed the links and voted on the articles, count only those votes in determining the true "rating" of an article. (This is what HotOrNot does for people's picture ratings.) Even if few people rated those articles, the ratings that were collected, would be representative of real users, and not the horde of friends that you'd sent to rate your article. If that did not prove popular enough, then you could give authors the option to pay random users to rate their articles — as long as there was no way for authors to tie payment to higher ratings, the ratings would average out to reflect the article quality, and could be used to sort articles based on their actual merits.
So, I'd like to think that someone in the Googleplex is reading everything I write, but it's probably just a case where great nerds think alike. I wrote in Feb 07 that I thought Citizendium should allow authors to put their name next to articles, both for the "name up in lights" incentives factor and to enhance the article's credibility, and now Knol is going to do that (not to mention throwing in money as well). The same month I wrote that someone should build a search engine that groups together user-submitted articles under different topics, and provides a means for newly submitted articles to rise through the ranks as a result of user votes, and it sounds like Knol will attempt that too. Then in April 07 I wrote about the ways that you could prevent cheating in such a system, and even though Knol hasn't talked about what they will do to address that problem, they're almost certainly thinking about it, and have probably come up with some of the same ideas.
So let's do a test to find out if Google is reading these articles. There's one area where Wikipedia would beat Knol, and that is that everything on Wikipedia can be redistributed for free. That's something really special, and it's the one part of the Wikipedia hype that I actually buy into. I don't really care that Wikipedia articles were created as part of a "worldwide collaborative effort" unless that helps to achieve the goal of being useful. But Wikipedia, for all its flaws, represents the first time in human history that we have a compendium of a huge amount of human knowledge that can be copied freely, that literally belongs to the world, and because it's duplicated in so many places, it can literally never be taken away. That part of the hype really is true, and is quite heady when you think about it.
Google Knol has not declared this as one of their goals; a Knol article might not be freely distributable. When a proprietary project is hosted on a private site, there's always the risk that the company will pull the plug on it. They probably won't pull off the content offline, but they might shut the service down to stop new content from being added, the way Google did with Google Answers. Yes, Knol authors will retain ownership of their writings, so they could try to regroup and continue the project somewhere else, but it would be a huge mess to try and contact all of the authors and get their permission to copy all of their articles to the new location. As currently planned, Knol doesn't "belong the world," and Google never promised not to take it away.
So, I think that Google Knol should include a feature whereby authors can flag their articles as being freely distributable under the same terms as Wikipedia articles. (Any author who copied an article from Wikipedia and submitted it, would be required to set this flag, because under the terms of "copyleft", you can't copy something that's freely copyable and then try to stop others from copying it!) Then a user who wanted a copylefted, freely distributable article, could limit their search to articles that have this flag set. This would give Knol the best of both worlds: if the author of the top-ranked article did not wish for it to be freely redistributable, then they wouldn't put it on Wikipedia, but they could make it available on Knol, and users could choose either the top-ranked copylefted article or the top-ranked article overall, depending on what they wanted. If the best article on a given subject also happened to be flagged freely distributable, then so much the better.
Maybe the Knol people have had this idea already. But even so, if they end up implementing it, then I'm starting right away on articles about how Google should implement Google Anti-Censorware, Google Site Hijack Prevention, Google Security Compensation, and Google Sergey And Larry Give Bennett Their Airplane. -
Boston Bans Boing Boing From City Wi-Fi
DrFlounder writes "The city of Boston has apparently blocked access to Boing Boing on the municipal Wi-Fi. This is possibly due to the popular blog's known Mooninite sympathies." Update: 4/22 13:11 GMT by KD : Seth Finkelstein did some research and posted an explanation of the blockage to his blog. "'Arbitrary and capricious' seems the relevant characterization." -
The DOJ's New Spin on Blocking Software
Bennett Haselton has writes "In recent arguments over the constitutionality of the Child Online Protection Act, both sides have argued over the efficiency of Internet blocking software. While COPA would prohibit commercial U.S. websites from publishing freely available material that is "harmful to minors", the ACLU has argued that blocking software is a far more effective alternative, since among other things it can block porn sites located overseas, non-commercial websites, and p2p programs, all of which are beyond the reach of COPA. On the other hand, we had the surreal experience of watching the Department of Justice lawyer arguing in favor of a censorship law by saying that the blocking software alternative was unfair to children -- because it blocked too much legitimate material." The rest of Bennett's essay follows."For example," said DOJ attorney Eric Beane during opening arguments, "one filter even blocked a website promoting a marathon to raise funds for breast cancer research. Part of the CIA's World Fact Book was blocked. And a page with an ACLU calendar. [Blocking software blocks] a significant portion of other materials on the World Wide Web, materials that in many cases are necessary for a child to complete his homework." (Opening arguments transcript, p. 37.) As someone who has been publishing critiques of blocking software for years, I read those words and felt like cheering, despite the fact that I'm sitting in the other side's fan section for this match. (Beane is right, but he's missing the point, which is that whatever problems exist with blocking software, are minor compared to the problems with COPA -- because blocking software raises no constitutional issues when it's used by a private party in their own house, whereas COPA affects everyone in the U.S.)
The irony, of course, is that three years ago, in the trial over the similarly-named Children's Internet Protection Act (CIPA) which required blocking software in all schools and libraries that receive federal funds, it was the ACLU pointing out the flaws in blocking software and the Department of Justice claiming that blocking software was accurate and effective.
At first it would seem that both sides are now guilty of flip-flopping. But reviewing what was said then and what was said now, my conclusion is that the ACLU did nothing more than shift their focus to a different set of facts, while the government did contradict themselves. And the source of this seeming flip-flop actually comes down to something pretty simple: two different ways of stating one set of numbers.
Now before going further I can't resist saying that I think the whole debate over "harmful to minors" material is pretty silly, because I don't think the pro-censorship side has ever put forth a reason why they think that pictures of naked people, or even people having sex with each other, are harmful to people under 18. I disagree with some people on matters like abortion and the death penalty, but I at least think they have some facts on their side; but I don't know of any facts supporting people who think that pornography is dangerous. Why is a woman's nipple harmful but a man's nipple isn't? How are the majority of high school students who have already had sex anyway, supposed to be harmed by pictures of other people having sex? And apart from the logical paradoxes, the pervasiveness of the Internet has now given us empirical data too: virtually all minors have now have access to anything they want to get on the Internet (either at home, or by sneaking to a friend's house), and where's the evidence that adolescents' brains have been hormonally turned to mush any more than they always have been?
But for the remainder of the discussion, suppose you're addressing people who believe that nudity and sexual material really are harmful to people under 18. (In any case, the judges probably believe it, and even if they don't, they're bound by legal precedents that assume as much.) The question is how accurately blocking software achieves this goal.
Blocking software has two types of error rates: underblocking (failure to block porn sites) and overblocking (blocking of non-pornographic sites). Underblocking errors are usually expressed one way: the percentage of porn sites in a given sample that are not blocked. But overblocking errors can be stated in two ways: the percentage of non-porn sites that are blocked, or the percentage of blocked sites that are not pornographic. (There are borderline cases like nude art sites, but it turns out they're not common enough to affect the margin of error much; the vast majority of sites are either clearly porn or clearly not.)
The key is that if you want the overblocking rate to sound low, you talk about the percentage of non-porn sites that are blocked. If you want it to sound high, you talk about the percentage of blocked sites that are non-porn.
For example, in the 2003 Supreme Court arguments over CIPA, Department of Justice attorney Theodore Olson downplayed the error rates of blocking software by saying:
"But even if it's tens of thousands of the -- of the 2 billion pages of material that is on the Internet, we're talking about one two-hundredths of 1 percent, even if it's 100,000, of materials would be blocked."
Here he's referring to the percentage of non-porn sites that are filtered. Attorney Paul Smith, arguing against the law, countered:"And so we have -- on these lists is a proportion, a huge proportion, perhaps 25, perhaps 50 percent of the sites that are blocked that are not illegal even for children."
and:"And the evidence is that there's about 11 million websites on the Internet, in --in the accessible part of the Internet and that 100,000 of those are the sexually explicit ones and that the --there are at least tens of thousands more that are on the list. So it's --the Government also says in their brief that about one percent of the Internet is over- blocked, which would be about 100,000 sites. So it is a substantial percentage. It is also a substantial amount. And most importantly, it's a very large percentage of what they're blocking is not what they intend to block."
-- that is, talking about the percentage of blocked sites that were non-pornographic. Both sides cited the same figure (100,000 non-pornographic sites blocked, apparently referring to an average across all blocking programs) -- but that same number could be seen as an "error rate" of either one hundredth of one percent, or 50%, depending on which formula you use.Then in this year's COPA trial, the ACLU called CMU professor Lorrie Faith Cranor who testified that in tests that she reviewed,
"[blocking software programs] correctly blocked an average of approximately 92 percent of objectionable content. And they incorrectly blocked an average of 4 percent of content not matching the test criteria."
(Oct. 24th transcript, p. 57.) Back to talking about the percentage of non-porn sites that are blocked -- which, again, when you put it that way, sounds low. On the other hand, although I couldn't find exact numbers cited by the DOJ's lawyers on the number of sites that were incorrectly blocked, in the portions of his opening argument quoted above, Eric Beane focused on the sad fact of the sites that were blocked -- not the fact that they comprised only a tiny fraction of sites on the Web. The two sides simply swapped formulas.As for Peacefire's own studies over the years of blocking software error rates, one of the legitimate criticisms that could be made about our efforts was that we focused almost exclusively on the second number, the percentage of blocked sites that were non-porn. If you were interested in how blocking software actually affects the surfing experience of minors who are forced to use it, perhaps you would focus more on the first number, the percentage of non-porn sites that are blocked. Perhaps, you might say, that as an organization addressing the blocking software issue specifically from a minors' rights point of view, we really should have focused on that number quite a bit! But I did get a bit preoccupied with playing "gotcha" with the blocking companies, focusing on the percentage of blocked sites that were obvious mistakes, because it was frankly too much fun publicizing the absurdly high error rates of their programs, which belied the claims made by most blocking companies that all sites on their blacklist were examined by a human at their company before being added. (Although it seems to have done some good -- as far as I know, no blocking company is making that claim about their product today.)
The error rates were indeed absurdly high; we took a sample of the first 1,000 .com domains in an alphabetical list, ran them through several programs, and found that of the sites blocked, between 20% and 80% (!) were errors. (The median error rate was about 50%, which corresponds to the figure given by Paul Smith in the CIPA trial oral arguments quoted above.) This surprised even critics of blocking software, and skeptics complained that we must have made mistakes or simply fudged the numbers. (The whole point of using the first 1,000 .com domains was that if we had used a random sample and gotten error rates like that, we could have been accused of "stacking the deck" and using a fake random sample that was loaded with known errors and not truly random.) Years later, it came out that the companies whose products we'd tested, had been following a policy that if they found an objectionable site on a given IP address, all sites on that IP would be blocked, on the theory that hosting companies often group porn sites together on the same machine. Trouble was, while this may have often been true for bona fide porn sites, it was not true for most sites that featured just an incidental shot of someone's bare breasts or a large amount of profanity -- but this would also be enough to get all sites blocked at a given IP. So the 80% error rate was about what you'd expect after all.
You might think that a product with an 80% error rate could never survive in the marketplace, but consider who was buying the software. On the one hand, you had schools and companies buying the programs -- but they didn't care whether it worked so much as they cared about being able to show, for liability reasons, that they did something. On the other hand, you had parents who really did care about keeping porn off their computer -- but how many parents really did any thorough testing of the product, other than making sure it blocks the obvious sites like Playboy.com? A serious test could take days. Their kids are the only ones who would end up doing any thorough "testing" of the product, and if they found a way around it, it's not likely that they would tell their parents. With no market pressure to fix problems, an 80% error rate wasn't really surprising.
But even the most vocal critics of blocking software only pointed out that blocking software sometimes blocked sites about plumbing, or soccer, or aluminum siding; we never claimed that most of those sites would be blocked. Even with our high numbers of wrongly blocked sites, if they had been expressed as a percentage of non-porn sites that are blocked, they would have still sounded like a "low error rate".
The moral is, always keep track of what the "error rate" refers to in these debates. By moving around a few variables in a formula, the Department of Justice was able to go from saying in 2003 that blocking software was minimally intrusive, to making a speech in 2006 that made blocking software sound so tragically limiting that you could practically hear the violins playing. (I know, people who live in glass houses... *ahem*)
And what about the ACLU? If the Department of Justice is guilty of flip-flopping, from saying in 2003 that blocking software is a reasonable and narrowly tailored solution, to saying in 2006 that it's clumsy, ineffective, and overbroad, is the ACLU guilty of flip-flopping in the opposite direction?
Actually, the ACLU's position has always been consistent: blocking software has First Amendment problems when used in a school or library, due to overblocking and underblocking errors, but if used in the home it is still a lot more effective than a law like COPA, which would score pathetically on the same scale. As ACLU attorney Chris Hansen stated in opening arguments:
"COPA does not reach the 50% of all speech that is overseas... Filters are the most effective. Almost all of the filters that [expert witness] Mr. Mewett tested were at least 95% effective. Think about the 5% ineffectiveness compared to where we start with COPA being 50% ineffective..."
(Opening arguments, p. 22. Note: Chris Hansen has confirmed that the official transcript is wrong; it has him saying "35%" instead of "95%", which wouldn't make any sense.) As for overbreadth, COPA would criminalize speech by adults, intended for adults, something that no blocking program could ever do -- and as for minimizing collateral damage to innocent sites, does anyone think that even if COPA is upheld, parents will throw out their blocking software?Even though the ACLU focused on different statistics in the two trials, in both cases they were focusing on the numbers that were relevant to the issue. When talking about constitutional problems with blocking software in schools and libraries, the percentage of blocked sites that are incorrectly blocked, is important, because it's their First Amendment rights that are at issue. The DOJ lawyer talking about all the sites that weren't blocked, was missing the point. If your site is being blocked, it hardly matters to you that for every blocked site there are hundreds that are not. "Hey, your site is not accessible, but don't worry, your competitors' sites are!"
On the other hand, when talking about the use of blocking software in the home, the publisher's First Amendment rights are not at issue; the issues that most parents would care about, are how effective it is, and whether most clean sites are still accessible. Well of course most of them are. Blocking software is not that bad.
Confused? The option to just stop making a big deal out of porn on the Internet is looking better all the time, isn't it?
-
Information Preservation and Data Havens?
tiltowait asks: "An interesting story on LISNews.com this morning about savvy U.S. students photocopying textbooks in Mexico then returning them for refunds got me thinking about data havens. There's already few places on the web where you can exploit countries having different copyright durations and eligibility. On the flip side, there's restrictions such as broadcast blackouts and country-wide firewalls. But just as the rich can use of international tax loopholes and in light of the recent file-sharing victory, are there any projects out there, beyond the P2P networks, to distribute possibly-protected information by any means necessary? For example, your company may already outsource labor, but what about an off-site backup in case of an FBI raid?" -
JibJab Sues for Fair Use of Right to Parody
An anonymous reader writes "A few days ago, Slashdot mentioned that JibJab was threatened by a copyright lawsuit. Well, it looks like JibJab decided to sue first with the help of the EFF. Lots more info here." (Here's the Bloomberg News article.) Update: 07/31 20:43 GMT by T : Seth Finkelstein has posted the court info on his website. -
Librarian of Congress Posts DMCA Exemptions
MrNerdHair writes "The Librarian of Congress has posted a list of exemptions from the DMCA (also obtainable in PDF here.) Works falling in four 'classes' may be considered exempt from Section 1201 of the DMCA's prohibition against 'circumvention of a technological measure which effectively controls access to a work.' Among the list are blacklists of sites used in programs such as NetNanny and cracks to bypass dongles on abandonware. All in all, a very interesting read ..." Not just interesting: as Robin Gross writes, "Unfortunately, the ruling leaves the vast majority of consumers unable to access their own property, such as skipping commercials on DVDs, playing CDs in their PCs, and reading eBooks on PDA's without violating the DMCA." Update: 10/29 15:19 GMT by T : Take a look at Seth Finkelstein's site for an idea of how being pushy can sometimes be helpful; Finkelstein has loudly pushed for the importance of DMCA exemptions, including in Congressional testimony. -
Slashback: Lamo, Trilogy, Searching
Slashback tonight brings updates on the recent Google hiccup, LookSmart and the FBI's note-snooping in the Adrian Lamo case, as well as (at long last!) a list of the theaters whose seats will soon be smooshed for far longer than usual under the weight of those dedicated enough to sit through 10 hours of Lord of the Rings. Read on below for the details.Microsoft thinks LookSmart looks less smart. securitas writes "Internet search company LookSmart was dropped by Microsoft's MSN service today. MSN has decided not to extend its licensing contract with LookSmart beyond January 2004. The news is devastating for LookSmart since, 'Microsoft accounted for approximately 65 percent of listings revenues, and all of LookSmart's licensing revenue in the second quarter of 2003,' according to a company press release not listed on LookSmart's site. The move comes after LookSmart recently launched its own Overture-style pay-per-click service and indicates Microsoft is close to launching its new search engine technology designed to unseat Google for the search crown. All of this is against the backdrop of acquisitions by rival Yahoo. More coverage at SearchEngineWatch and a Reuters mirror at CNN Money."
They could have fixed this if they'd googled for an answer ... powerg3 writes "This follow-up, explains the Google wackiness posted yesterday. Here's the quote from the Google Weblog: '...when a spam result comes up in a search, Google not only blocks the spam, but every result after it. This means that for searches where spam results manage to rise to the top, very few -- sometimes zero -- results will be returned....It's pretty amazing that such a serious bug made it past Google's tests. It will be interesting to see how quickly it's fixed.'"
Pardon me, mum, can I borrow your hard drive? AndreL writes "The Guardian has an update about the BBC's digital archive plans. They're considering using P2P technology to avoid bandwidth bottlenecks. The bad news: because of technical, financial, and legal problems nothing will happen until 2006 at the earliest."
Please arrive in costume if at all. KTecumseh writes "The list of theaters showing the extended editions of LOTR as been revealed. You can check out the list at the official website, and before you look, pray that you live somewhere close by to take advantage of this once-in-a-lifetime experience. For those that can not make the full 10-hour saga, they are also showing the first two extended additions on different dates, but who wants to miss out on an entire theater of sweaty LOTR fans."
Shamus Arrigan asks plaintively "There is no mention of these ticket sales in any other country. Does anyone know when and where these tickets will be sold at? (Canada especially)"
Wait, are you fellas press? Dangnabbit! ccnull writes "Good news from the inquest against hacker Adrian Lamo. According to a paragraph in a Washington Post column (buried about 3/4 of the way down the story), the FBI appears to be backing off from pursuing reporters' notes in the case. Relevant quote: 'A Justice Department official says the FBI agent "acted out of turn" by not seeking approval from the U.S. attorney's office in Manhattan and Attorney General John Ashcroft's press office. "The agent did not follow standard procedures," the official says. "We're just not going to pursue it. It is the policy of the Justice Department to exhaust all other means before seeking information from members of the media."'"
Eh, what's a few orders of magnitude? Grant hayes writes: "It seems the decimal point in the Mono story you ran is being a bit ambitious. We should be reading Mono 0.28, not Mono 2.8. Check the link below as well as links there to other Mono resources; I see 0.28 throughout." Here's the Mono site -- guilty as charged. Thanks for the correction.
-
Verisign Typosquatter Explorer
jelyon quotes Seth Finkelstein's website "I have written a program " Verisign Typosquatter Explorer" in order to examine [the Verisign] suggestions [for mistyped domains]. Future data may be analyzed as interest permits. Note tests with some domains seem to return results which are not constant, i.e. differences when the program is run repeatedly. This is not a program bug. Reloading the Verisign page also changes which squat-suggested domains are displayed. I don't believe it's an advertising rotation, but the behavior is similar to that practice." -
Dissecting Localized Google Censorship
carpe_noctem writes "Linuxsecurity.com has a link to a rather interesting story regarding Google's use of localized censorship. While not much information is given from the political side of why Google might be censoring information likely to annoy certain governments, it certainly isn't the first time Google has come under fire for censoring results on account of external pressures. Makes one wonder how many pages get filtered out around the world." -
The Great Firewall of China - Samples of Filtered Sites
Loligo writes "Harvard University's Berkman Center for Internet & Society has released a study listing some of the sites filtered by Chinese internet connections. Sites about Taiwan are maybe understandable, but Red Lobster?" We've mentioned the ongoing Berkman study before; one of their interesting findings is that the list of blocked sites is a moving target, and some sites are blocked only intermittently. Here are summaries from The New York Times and MSNBC, by way of The Censorware Project. Update: 12/04 21:03 GMT by T : Seth Finkelstein points to his report "Searching Through the Great Firewall of China," which "describes a simple technique which can be used with some search engines to bypass censorware bans on searching for forbidden words. Particular emphasis is placed on the situation of the Great Firewall Of China." -
SmartFilter: Way Too Extreme
Another report on SmartFilter by Seth Finkelstein (here was last month's). He's written some software to decrypt the software's blacklist of forbidden sites, and has analyzed what he found. The list of blocked newsgroups is fascinating: sci.archaeology as occult, and comp.org.eff.talk as criminal, for example. He's found "extreme or obscene" sites like hotrails.com ("extreme sports" rollerblading on "naked metal"), gcsextreme.com (custom-built computers for the "extreme gamer," unfortunately at a domain name with both "sex" and "extreme" in it) and extreme-offroad.com (same deal). Their music-critic skills need work too, as they block InsaneClownPosse.com, Tupac.com, Marilyn Manson, and even Chumbawamba's Web site. Every one of these and many more are blocked as "Extreme," which puts them in the same category as photos of mutilated dead bodies, bizarre hard-core pornography and child pornography.His discussion of the legal risks of decrypting these blacklists is fascinating too, and (as he likes to say) "a topic in itself." He would like to open up the source to his SmartFilter-decryption tool but feels the legal risk is too high. How sad is that?
Here's Secure Computing's definition of the "extreme" category, and the examples they give ("Pixman's Vault of Porn Pix", "Bizarre & Maximum Perversion").
You can confirm Seth's findings using Secure Computing's own SmartFilterWhere. It asks for your name and phone number; you have my permission to make some up. As of December 7, at 9:45 PM EST, that CGI operates with a Control List updated on December 5 and confirms all of Seth's results that I tried. By the time you read this, they may have quickly fixed all the errors he published, loaded in an up-to-the-minute Control List, and proudly announced that their software is now perfect.
Until the next report.
-
SmartFilter: Way Too Extreme
Another report on SmartFilter by Seth Finkelstein (here was last month's). He's written some software to decrypt the software's blacklist of forbidden sites, and has analyzed what he found. The list of blocked newsgroups is fascinating: sci.archaeology as occult, and comp.org.eff.talk as criminal, for example. He's found "extreme or obscene" sites like hotrails.com ("extreme sports" rollerblading on "naked metal"), gcsextreme.com (custom-built computers for the "extreme gamer," unfortunately at a domain name with both "sex" and "extreme" in it) and extreme-offroad.com (same deal). Their music-critic skills need work too, as they block InsaneClownPosse.com, Tupac.com, Marilyn Manson, and even Chumbawamba's Web site. Every one of these and many more are blocked as "Extreme," which puts them in the same category as photos of mutilated dead bodies, bizarre hard-core pornography and child pornography.His discussion of the legal risks of decrypting these blacklists is fascinating too, and (as he likes to say) "a topic in itself." He would like to open up the source to his SmartFilter-decryption tool but feels the legal risk is too high. How sad is that?
Here's Secure Computing's definition of the "extreme" category, and the examples they give ("Pixman's Vault of Porn Pix", "Bizarre & Maximum Perversion").
You can confirm Seth's findings using Secure Computing's own SmartFilterWhere. It asks for your name and phone number; you have my permission to make some up. As of December 7, at 9:45 PM EST, that CGI operates with a Control List updated on December 5 and confirms all of Seth's results that I tried. By the time you read this, they may have quickly fixed all the errors he published, loaded in an up-to-the-minute Control List, and proudly announced that their software is now perfect.
Until the next report.
-
SmartFilter's Greatest Evils
Seth Finkelstein has taken a look at what gets blocked by censorware in the most categories. What would you think there is on the web that qualifies as sex, drugs, crime, gambling, sports, news, religion, art, travel, hate, gross and fun and games? Oh, and some of these sites are useful in research too. Give up? -
SmartFilter's Greatest Evils
Seth Finkelstein has taken a look at what gets blocked by censorware in the most categories. What would you think there is on the web that qualifies as sex, drugs, crime, gambling, sports, news, religion, art, travel, hate, gross and fun and games? Oh, and some of these sites are useful in research too. Give up?
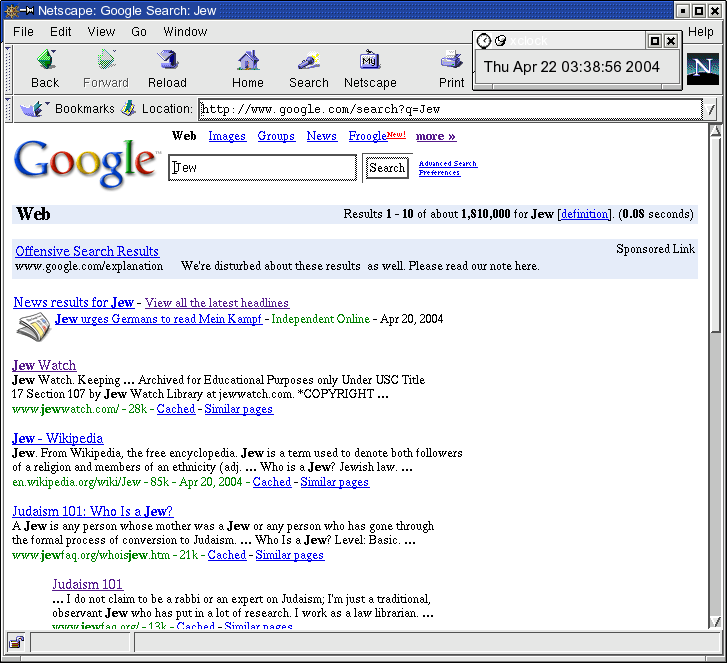{kind=link}
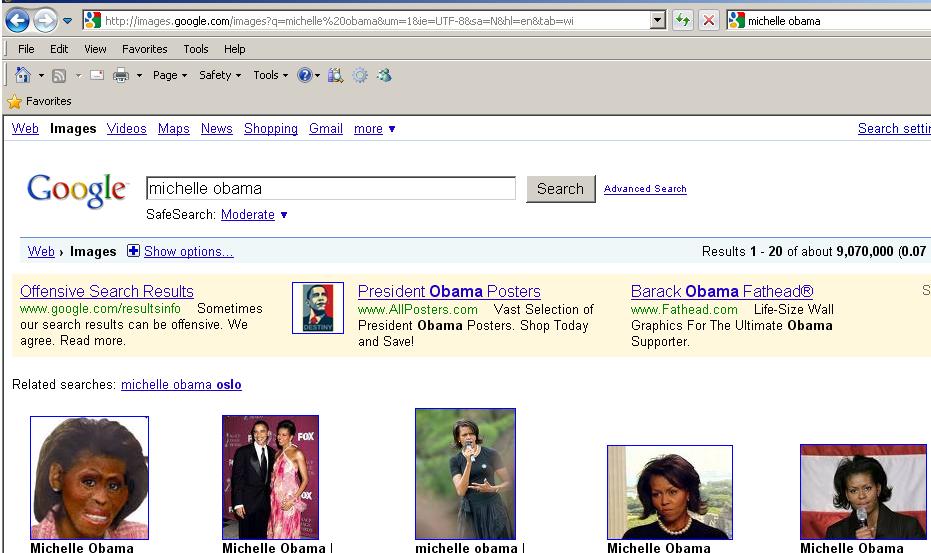{kind=link}
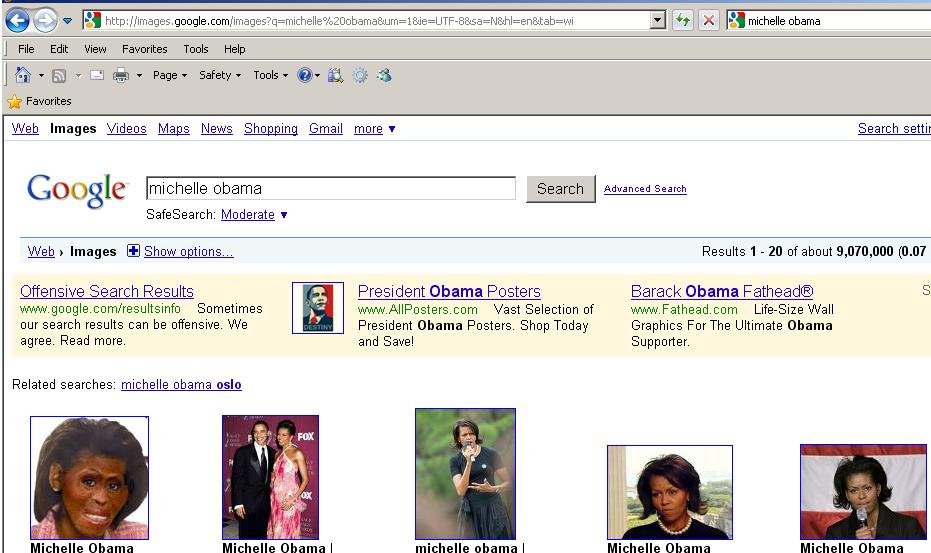{kind=link}