 Slashdot Mirror
Slashdot Mirror
Domain: daemonology.net
Stories and comments across the archive that link to daemonology.net.
Comments · 91
-
Re:About hyperthreading
And yes, I can see this could cause problems regarding timing if you can cause a pipeline stall based on a condition you want to test in the other thread on the same core. It'll be hard though. Maybe too hard to justify disabling HT altogether. Providing a switch to turn it off in case an exploit is discovered would be more wise I think.
The same mindset was what brought us Spectre in the first place. And I imagine it'd be very easy to pin your malicious thread to a specific core to do timing attacks against especially since pipeline stalls would make a very good test pattern to match against potential keys (as different keys create different sbox shuffles which create different patterns of memory accesses). Hell, there were hyper-threading attacks back in 2005.
Waiting for exploits to occur and leaving it to users to guard against them retroactively is precisely the opposite of the mindset of OpenBSD. So, no, the 10-20% gain is not worth the risk. If you think differently, run a different OS without the meltdown patch while you're at it.
-
notability hole
Even if you pay only a fraction of your time on security news, you probably already know Mikko Hypponen.
Nope. It was only recently (about a year ago) that I started to keep a formal list of prominent people in the security sector and, until five minutes ago, he was not there. It was the mosh pit of DNS and SSL security that finally drove me to it. To be honest, it was also the somewhat volatile Thomas H. Ptacek who drove me to it. Here's Colin Percival's rather decisive rebuttal to an ill-considered post by Ptacek.
Interestingly, Ptacek's original post, "Colin's Very Important Knob" is nowhere to be found on the internet. Since then, I've seen them engaging in pleasant, but opinionated exchanges. Normally, you can get a quick sense of who hates whom, but with security it's more like the way certain animals share a kill: with cheeks shredded and bleeding. No hard feelings. They might even be brothers.
Even if you pay only a fraction of your time on security news
Hmm. The eyeball economy is strong in this one.
-
Re:actually had this on my list today
The unofficial official FreeBSD security posture: two layers, where the outer layer has a singular purpose in life.
Like many system administrators, I used to restrict access to port tcp/22 on most of my servers based on source IP address; this provided some protection from "zero-day" exploits against OpenSSH, as well as eliminating the annoying "log spam" caused by brute force attacks. This worked fine as long as I always connected from the same location, but heading off to conferences meant that I needed to either tunnel SSH connections over other SSH connections or make temporary changes to my firewall rules.
Yeah. I used to have my SSH available on my public IP but finally got sick of getting emailed security loss that were a mile long with login attempts from Asian and Arabian countries I'd never been to. It was convenient being able to SCP files and everything without a hassle, but it wasn't worth the security risk.
Now, I just have our private access only and have to connect to my OpenVPN server first. Haven't gotten a single failed login attempt notification since. It's just really lame that it's come to this. You simply cannot have more than a bare minimum of ports open to the public or they WILL try to hack you.
-
actually had this on my list today
The unofficial official FreeBSD security posture: two layers, where the outer layer has a singular purpose in life.
Like many system administrators, I used to restrict access to port tcp/22 on most of my servers based on source IP address; this provided some protection from "zero-day" exploits against OpenSSH, as well as eliminating the annoying "log spam" caused by brute force attacks. This worked fine as long as I always connected from the same location, but heading off to conferences meant that I needed to either tunnel SSH connections over other SSH connections or make temporary changes to my firewall rules.
-
Non USA, client-side encryption: Tarsnap.
Pitty they are all in USA, any that are NON usa based?
Tarsnap, by Colin Percival (author of the scrypt algorithm).
It's based in Canada and, although the slices of data are stored on Amazon S3 (USA), the actual data-encryption and key handling is done on the opensource source client (which is audited a lot, thanks to a bug bounty by the author).
Specially, the kind of mismanagement that happened to TFA's Author is impossible with tarsnap.
Access and the various key which control who has access to what are controlled by the client. The admin (in this case: Colin Percival himself) can't do much without the keys which aren't available to him (they are stored client-side). The only thing which goes from/to the server are encrypted packets of data.Tarsnap is a bit less userfriendly for quick-sharing of files (what TFA's Author uses specifically the box.com account).
But on the other hand, tarsnap is perfect for periodical backups/snapshots (with deduplication) of the critical folders with critical information (authors gives dropbox and skydrive as exemples of share where critical informations is backed-up: work documents, financial data, medical records, etc.). Those would have been much more problematic if control was given to the wrong person, as the author mentions (for example: financial data ending in wrong hands would be a treasure trove of data for identity stealing. And if this data get erased by mistake, the author would be on trouble in case of IRS audit).
But that's impossible with scheme where the control is done using crypto keys, instead of a status in a database somewhere.
(Tarsnap data can't be made accessible to someone else. In fact, it can't even be made again accessible to you if you lost the keys. No keys, no anything). -
EC2 AMIs available
FreeBSD 9.0-RELEASE machine images for Amazon EC2 are available for m1.large and larger instance types: http://www.daemonology.net/freebsd-on-ec2/
-
Re:Better analogy: imported rats, not farmed
Aha, found it:
What does $1265 of bugs look like
Looks like this wasn't a slashdot article, maybe it should be -
Re:FreeBSD vps "hot migration"
Before even remotely considering jails on FreeBSD, I would recommend people read about a serious bug that is affecting a company of 140+ servers with kernel panics. Kernel developers are actively trying to figure out what the root cause is. This statement by a kernel developer says it all, and justifies why you will find no jails on any of the systems I manage.
Likewise, before even remotely considering VirtualBox on FreeBSD, I would recommend people read about a serious bug that affects the network stack and resource (memory) allocation for data transfers; the thread continues here. One of the reporters confirms VirtualBox is responsible. Reporters did not state if the issue was limited to applications within VirtualBox or if the entire system is affected, but it is implied that it affects only applications within VirtualBox. The workaround proposed by another user has severe consequences to the entire system (not just within VB). No kernel developer has commented or stepped up to the plate.
So if you're going to consider virtualization, consider using Linux or Windows -- or better yet something like VMware ESXi. Even Xen on FreeBSD is not ready for prime-time (review the list of issues, all of which are major).
Over the years I have learned that people who advocate FreeBSD often pay little-to-no-attention to the mailing lists, which provide great insight to just how behind-the-times FreeBSD is when compared to other offerings. Does FreeBSD suck? No, but it does suck more in some regards than Linux or OpenSolaris, while less in others. TL;DR - before considering FreeBSD, read mailing lists (-stable, -fs, -net, and -questions are the main 4) and look for repeatedly-reported issues. You might be surprised.
-
Cryptographic Right Answers (from C. Percival)
I'm surprised no one pointed out this link already: http://www.daemonology.net/blog/2009-06-11-cryptographic-right-answers.html
-
Re:FreeBSD Xen support
FreeBSD had dom0 support a few years ago, but it bit-rotted. If you want it, then I can point you at someone who is taking donations to finance the work. Or you can run NetBSD or Solaris in dom0 and FreeBSD in your domUs.
-
Re:Jumping the gun...
I should also add that one link the submitter didn't include was instructions for upgrading to FreeBSD 8.0-RELEASE from a previous release: http://www.daemonology.net/blog/2009-07-11-freebsd-update-to-8.0-beta1.html (obviously, apply s/8.0-BETA1/8.0-RELEASE/ to the instructions).
Before anyone asks, yes, that link is on my personal website -- but no, I'm not just posting it here to drive traffic in my direction. That link is going to be in the official release announcement too.
-
Re:Practical?
> I'm not sure how practical it is for any "programmer on the streets" to pay attention to this sort of thing.
These "any programmer on the street" guys hopefully never implement anything in the vicinity of crypto code.
You do not need to read the papers. Reading something like http://www.daemonology.net/blog/2009-06-11-cryptographic-right-answers.html -- if you happen to trust Colin Percival -- should be enough, if you do not try to be creative in what you use.
What is so bad about considering MD5 broken and make design choices because of that? Better than the other way around, if you are not in the field. How much more expensive is it to verify an MD5 and an SHA256 hash instead of MD5 only -- for many practical application, it is irrelevant. So why not do it?
-
binary diff
If you're not familiar with the process of binary diff (I wasn't) there's a paper linked from the article that explains some about bsdiff:
http://www.daemonology.net/papers/bsdiff.pdf
Wayback from 2007/07/09:
http://web.archive.org/web/20070709234208/http://www.daemonology.net/papers/bsdiff.pdf -
Re:"Migrate their applications to hyperthreading?"
hyper-threading is subject to certain security problems that are not present in multiprocessing. Security researchers have noted that it is possible to peek at encryption keys in memory within the HT environment. See http://www.daemonology.net/hyperthreading-considered-harmful/
-
Re:This one always surprises people for some reaso
You can thank BSD...
http://www.eecs.berkeley.edu/Pubs/TechRpts/1983/5392.html
Another useful BSD utility is here...
http://www.daemonology.net/depenguinator/
-
Re:Wow
It doesn't have to be that way. Here's some free advertizing for a fellow FreeBSD developer: TarSnap offers high-grade encryption over the wire and on the storage, incremental backups, and it also uses Amazon S3.
-
TarSnap
From the BSD camp (or at least one of the developers), there's TarSnap, which offers very high encryption and confidentiality, and also incremental backups (via snapshotting).
-
I had the same problem...
After looking at the available options, I decided that there was nothing which met my criteria for convenience, efficiency, and security. So I decided to create my own.
I'm looking for beta testers: http://www.daemonology.net/blog/2008-05-06-tarsnap-beta-testing.html
-
Re:I'll bite
I believe the correct procedure is to install this helper utility first.
-
Re:Huh??
You're probably right, but "zip" might do a stellar job on the patch file which is the binary difference of the VM vs. a vanilla VM immediately before installing the media.
bsdiff (yes, that is the correct link, I didn't pick the domain name, just Google "binary diff" to check) doesn't seem quite right for creating the patch file, considering its memory requirements, but I'm sure it wouldn't be that hard to work something up... -
Re:What's wrong with version control?
CVS rename:
ssh repository
cd
mv foo,v bar,v
(done)
Can also create symlinks to share code between different projects, and preserves all of history. Not transparent, but it's available and it works.
CVS obliterate dates back to RCS and is done with:
cvs admin -o 1.1 (for specific version) , or
man it. SVN is still too immature if it can't do this.
Efficiency of storing binaries is very inconsequential when storage is free these days. Not only that, but efficiency of delta'ing varies and wasteful in time (lookup bsdiff) so why bother? And with the obliterate option, it makes the issue moot, and SVN unusable for binary CM and deployments.
I can access everything from CVS over ssh and VPN tunnels just fine from anywhere in the world. I don't really see a need for a complicated HTTP overhead although it can be nice, but basically says there's a no-trust relationship going on.
I just wish there CVS would maybe uses BerkeleyDB or something faster for the file db in backend so tagging isn't so slow, handles file histories over 4GB better (isn't there a better way than a full copy/replace of the -
Re:Ha! I did it!
Don't fret. Go make use of Colin Percival's binary updates system to perform a binary upgrade. You'll be running 6.2-RELEASE in no time at all.
-
Availability
The release announcement will not be available for a couple of hours. Slashdot jumped the gun as usual.
Torrents are available.
A script for upgrading FreeBSD 6.1 systems is available. -
OhGodPleaseNo
Code re-use is a great idea. Free software is a great idea. Taken together, and to an extreme, they can cause problems, particularly where security is concerned. What happens when someone finds a security flaw? How can you contact the people who are reusing your code if you have no idea who they are?
To take a personal example, my delta compression code, which I wrote for FreeBSD, is now being used by Apple and Mozilla to distribute updates; I've talked to their developers, and if I find a security flaw in this code (very unlikely, considering how simple it is), I'll be able to inform them and make sure they get the fix. On the other hand, I know developers from several Linux distributions have been looking at using my code, but I'm not sure if they're actually using it; and searching on Google reveals dozens of other people who are using (or at very least talking about using) this code.
Putting together software by scavenging code from all over the Internet is like eating out of a garbage dump: Some of what you get is good and some of what you get is bad; but when there's a nation-wide recall of contaminated spinach, you'll have no idea if what you're eating is going to kill you. -
My experienceA couple of weeks ago I did 'the interview loop' at that leading search engine. I had already told my recruiter that there wasn't any point asking me about 200-level material, and aside from one silly question about topological sorting my phone interviewer respected that. When I arrived for my on-site interviews, several interviewers apologized about being required to ask really easy questions. They asked their questions; I provided my answers; they asked why my solution wasn't the same as their solution; I explained that my solution was asymptotically faster; and we moved on to more interesting discussions.
Having not interviewed at that leading online retailer, I don't know if the situation is the same there; but my impression at that leading search engine was that my interviewers were very quick to recognize that I was more qualified than they were and to adapt their interviewing appropriately. -
Re:Incremental patch?
Because the downloaded file contains the differences between the binaries, and the updater leaves the rest of the binary file as it was.
See http://wiki.mozilla.org/Software_Update:MAR and http://www.daemonology.net/bsdiff/ for more. -
Re:Incremental patch?
-
Re:Tax payer waste...
Because even your proposed kernel could be easily modified (http://www.daemonology.net/bsdiff/).
Because your BIOS could be modified, and such modifications could be undetectable to any OS.
HIBT? Probably. HAND.
-
Re:FUD?
That's where this article gets a little sketchy.
When the processor begins to overheat or encounters other conditions that could threaten the motherboard, the computer interrupts its normal operation, momentarily freezes and stores its activity,
Ok, fine.
Every computer that runs on x86 chip architecture may be vulnerable to this attack
Wait. How did we get here?
Let's go through this, again. Intel Pentium 4s are hot. No surprise there. They enter special modes when overheating that may introduce a security vulnerability. Fine. How does this cross over to AMD and Via chips again? AMD and Via processors don't have special modes like that. If system heat becomes critical they will simply shut the system down flat out. On a Pentium 4, overheating is not entirely unexpected, particularly on the high edge of the clock speeds. On an AMD or Via, overheating is a major failure condition, probably caused by a heatsink falling off.
So, how are all x86 chips vulnerable, exactly? (Incidentally, between this and this, AMD is really looking to be a much safer deal, not to mention faster, cooler, more power efficient, etc.) -
How about bsdiff/patch and some scripts?
This is the technique used by portsnap; basically you generate binary diffs from a known starting point, and the client keeps track of what new patches it needs to keep in sync. Since you're just serving static files, scaling it should be as easy and cheap as it gets.
rsync is highly general purpose; your servers will end up generating hashes for every n-bytes of every file for every client, which is a lot more heavyweight than just serving patches you generate once. SubVersion may be more effecient since it should know something about the files it's checked out previously, but it's still going to end up dynamically generating diffs between whatever versions each client has and the latest; this likely gets worse if your clients aren't tracking HEAD.
Also note that a custom solution can likely get away with a single tag file detailing the latest patches; rsync and svn are going to be scanning their directory trees religiously. Both you and your users will probably appreciate a single GET to a small file on a webserver than a load of CPU use and disk thrashing. -
NOT FUNNY!! Re:Reboots
That's not funny.
I think the folks who suffer with Windows are used to rebooting for all sorts of reasons. E.g. IE runs too slow, my app just crashed, I need to install a new program, something is not working,
Due to their inability to admin their own machine, some resort to throwing it out and trying again, with new hardware.
I think it is the Unix admins who have the fetish for the no-reboot. Or perhaps a single, precisely done reboot, to remotely bring up a machine with an entirely new OS.
Similary, folks who use windows think they need anti-spyware, anti-virus, extra-special firewall crap --- because they think there's no way a computer can withstand the tide of crap without extra-special help. It is just impossible to imagine that an OS could withstand it all.
Lately it seems that hardware companies are in the game -- e.g. Intel processors with features designed to make up for the deficiencies of Ballmer's bunch in Redmond. -
Re:No New mod.
No. diff doesn't work like that. You want xdelta. (bsdiff claims to be better, but I've never used it).
-
Re:From TechReport with actually useful info
The on-die L2 cache will be shared between the two cores, and Intel says the relative bandwidth per core will be higher than its current chips. L2 cache size is widely scalable to different sizes for different products. The L1 caches will remain separate and tied to a specific core, but the CPU will be able to transfer data directly from one core's L1 cache to another.
So in other words, they haven't learned at all, it seems. With the major security flaws in Hyperthreading (including the flaws in the L1/L2 cache design), I'm not surprised they've pulled it from the chips for now.
When things don't work and you can't fix them, pull it out. Microsoft should take a tip here and start pulling out the insecure parts of their OS. Oh wait, that might leave a blank drive instead.
-
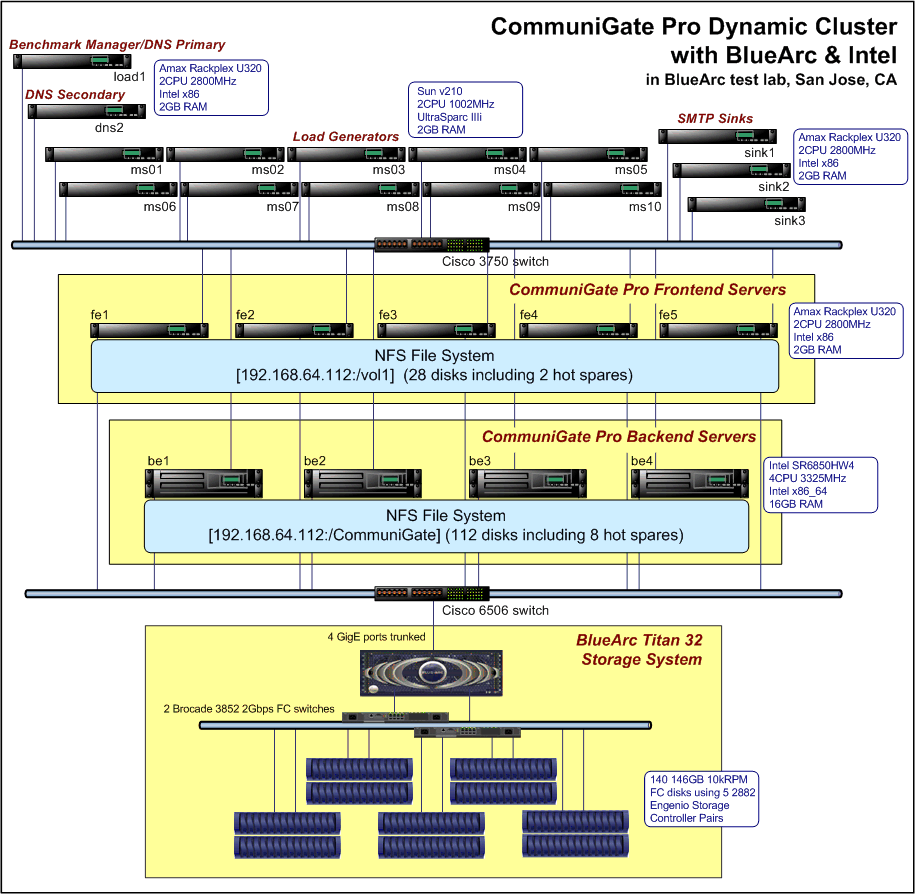
The tester responds...
Just thought I'd add a few details and address some of the questions here. My name is Thom O'Connor and work for CommuniGate Systems (CGS), and was the one who put together and ran these tests - you can (mostly) verify this by looking at the comments in the source on the results page.
First off, on the SPECmail test itself. SPECmail is a standardized test (the only one I'm aware of for email) that attempts to closely regulate a level playing field for measuring email performance. It is critical to understand that this is not just measuring SMTP. The 30 million message a day text is a little vague, but it is important that this includes a distribution of delivery, relayed, and retrieved email. Sure, anyone can just relay many millions of messages an hour.
SPECmail does POP and SMTP, so the test measures not just MTA behaviour but also local delivery and then retrieval of the messages. The SPECmail test also uses Quality of Service (QOS) measurements such that a message injected via SMTP to the system MTAs (the CommuniGate Pro Frontend servers in this diagram) must then be delivered locally into the users' account, then be retrieved within 60 seconds. Satisfying the QOS criteria during the benchmark is often the most difficult part.
So, SPECmail itself just does POP and SMTP, which is a little 1990s I agree, but SPEC is coming out with a SPECimap test in the near future, and CGS is also very interested in seeing a SPEC VoIP/SIP test for measuring CommuniGate Pro's Real-Time capabilities.
A few others questions I've seen raised here:
1. The CommuniGate Pro Dynamic Cluster described in this test is fully and completely appropriate for production use in all aspects. In fact, if you're running a 2+ million user ISP on a CommuniGate Pro Dynamic Cluster, we'd recommend you to use these results as a guide for your architecture (although load balancers should be added to the gateway point for all inbound connections). In fact, CGS has ISP customers running architectures which match the layout of the described system almost exactly. All systems in the Cluster service all accounts - you could lose 4 Frontend Servers and 3 Backend Servers, and all users could still access their email (albeit with decreased capacity).
2. HyperThreading was disabled in the BIOS because the downloadable Solaris 10 x86 operating system would not (yet?) support the Intel x86_64 Potomoc chipset properly. That said, on top of the recent security vulnerabilities on the topic, we have also discovered miscellaneous threading and even NFS issues related to having HyperThreading enabled on Linux 2.6, FreeBSD 5.4, and Solaris 10 x86 systems.
3. On NFS...NFS is used safely and securely in this test. The integrity of data storage is one of the major criteria that the SPEC organization closely evaluates when reviewing a SPECmail submittal. Obviously, there are many ways to cheat and/or cut corners using Solid State Disks, unsafe RAM for message queueing, and other techniques that you would never want to use on your production message system. However, the test described here was performed using a standard (albeit excellent) BlueArc Titan Storage System with write caching only in NRRAM and using proper mount options and layout for security, redundancy, and data integrity.
Hope this clears up any misconceptions. Obviously, I'm clearly biased about the work here, but assembling and then passing a SPECmail test of this size is a gigantic effort. If anyone thinks -
Re:What about updates?
I am doing my MSc thesis on patching and have actually just written a paper on this entitled 'Patching for low bandwidth communities'. It is focused on South Africa as that is were I live.
It discusses a few methods, namely:
1) Making patches smaller
2) Reducing the number of patches
3) Increasing bandwith
There are a few ideas under each heading a quick summary of some of them can be found here. Binary patching is definately a good idea and is already being used effectivley in FreeBSD and Windows.
Although, running some variant of stable and just getting security patches doesn't require much bandwidth. My Debian sarge/stable distro requires smallish updates about twice a week. -
Re:What about updates?
IIRC the latest Suse already uses binary diffs for updating.
Not unless it has changed recently. Suse's approach always used to be "well, out of this package of two hundred files, only these ten have changed, so we'll send out a cut-down package with only those ten files instead of including all two hundred". This is certainly an improvement over the RedHat and Debian approach (which sends out complete packages, including duplicates of unmodified files), but is far worse than using actual binary diffs, which can provide another 50-fold reduction in bandwidth.
My favourite statistic about the usefulness of good binary diffs: All of the binary diffs needed to update a two-year-old copy of FreeBSD to patch all known security issues fit quite easily onto a 3.5" floppy disk. -
Re:There's a lot to like
Now that there is a push to support binary updates, my last major complaint has been addressed.
You mean officially? Because binary updates are already available:
http://www.daemonology.net/freebsd-update/ -
Re:OSS Spreading
Your post suggests another variation
1) Write VBS virus that installs peanut linux
2) Make amazingly large zombie server farm
3) ???
4) Profit
Probably not as easy as Depenguinator http://www.daemonology.net/depenguinator/, but still entertaining. -
LiarsQuoth the article:
We respond immediately to the initial vulnerability report and provide the researcher with contact names, e-mail addresses and phone numbers. We make it clear we want to work closely with the researcher to pinpoint the problem and get it fixed. We commit to providing [researchers] with a progress report on the Microsoft investigation every time they ask for one
My experience directly contradicts this on all points.
When I reported the hyperthreading security flaw to Microsoft, I was provided with the first name of the person who was responsible for dealing with it ("Christopher"), but I was not provided with his last name, phone number, or any e-mail address (apart from the generic secure@microsoft.com address which I used to report the problem). Later the issue was transferred to "Brian" -- again, no last name, no email address, and no phone number.
Over the following two months, I heard from three independent third parties that Microsoft was "very concerned" about this issue, and had "several people" looking at it; but they never made it clear that they wanted to work closely with me -- in fact, they ignored all my attempts at co-operation.
Finally, prior to releasing my paper, I sent several emails to Microsoft asking about their progress and asking for a vendor statement for my web site; again, they did not respond. -
Re:No hzperthreading shame that
Is there any further links to details about the problem
http://www.daemonology.net/hyperthreading-consider ed-harmful/
The vunerability seems to only concern itself with the implementation of hyperthreading , though it is rather vauge -
At least Linus.......has a job. Naturally this guy would disagree with Linus. He's got nothing else to do. I, too, would strongly disagree if someone casually dismissed the past three months of my life.
- Where do you work? I'm unemployed. For the past three months, I've spent almost all of my time working on this security flaw -- investigating how serious it was, contacting all of the affected vendors, explaining how this should be fixed, et cetera. I simply haven't had time to go out and get a job -- and I decided that making sure that this issue was properly reported and fixed was far more important than earning some money.
-
Paper released
Well, here it is. http://www.daemonology.net/papers/htt.pdf
-
The paper is now online...
... see
http://www.daemonology.net/papers/htt.pdf
He describes an attack on the RSA secret key in an OpenSSL system. By knowing how OpenSSL performs modulus arithmetic, he is able to distinguish many bits of p and q in the modulus by observing L1 cache hits and misses in a simultaneously running process. Assembler code is provided... -
Details now given.
Well, I just read the paper, and I applaud Colin on several levels. First off, the theory of the attack is rock-solid and well-written. Secondly, he describes very implementable OS work-arounds, crypto library fixes, and finally chip design corrections which will totally eliminate the security hole.
This is one of the best thought out, best written papers of its kind that I have read in my over thirty years of work in the engineering field. -
Colin Percival's Paper Now Online
Here's the much awaited paper from Colin:
http://www.daemonology.net/papers/htt.pdf -
Re:Where's the details?
He posted them on his site a bit ago http://www.daemonology.net/papers/htt.pdf (Warning PDF)
-
My take on the paper...
The paper is here http://www.daemonology.net/papers/htt.pdf and I've skimmed it.
My takeaway is that if a process knows another thread is calculating an SSL key, it can get an advantage in figuring out the SSL key.
It won't "get" the actual key, but with sufficient "bits" of info, the calculation can be rendered fairly trivial.
I'm not familiar with these types of security reports, but let me say that to me, it sounds much like saying that with a careful analysis of the LEDs on the front of my IMSAI 8080 my private data may be revealed.
There seems to be so many other things that feed into this vulnerability (like, a minimal number of processes running, knowing the code is being executed, that the thread and the "cracker" software run on different "logical" CPUs at the same time, etc...) that this is a very, very, small issue - damn near purely theoretical.
If the author can say, "Run this code on your server, calculate an SSL key, and this piece of code will reveal your SSL key" then we have a real vulnerability. As I read it, the author is saying "Run this code, calculate an SSL key, and you may be able to infer a percentage of the bits that comprise your SSL key".
I will repeat, I only skimmed the paper, and I'm not familiar with these types of reports, but that is what I walked away with - if I am wrong, I invite the correction. -
Paper
Link from KernelTrap
-
The paper is now available
The paper is now available at:
http://www.daemonology.net/papers/htt.pdf -
L2 covert channel without shared memory possible
after reading his paper at http://www.daemonology.net/papers/htt.pdf i think his point is that with htt enabled it's possible to have a covert channel between threads/processes with _shared memory_. that's not specific for htt and page-sharing threads - several months ago i wrote a covert channel implementation for arbitrary processes over a (non-htt) pentium 4 l2 cache that _do not share_ any memory pages. i am not going to make that code public.
disclaimer: this post is just supposed to be a small "fuck you, we were already using that technology and we even have a superior implementation!" to the so-called security expert community.
{kind=link}