 Slashdot Mirror
Slashdot Mirror
Domain: mturk.com
Stories and comments across the archive that link to mturk.com.
Stories · 14
-
Most People Would Give Lab-Grown Meat a Try, New Survey Reveals (sciencealert.com)
Clive Phillips and Matti Wilks report via ScienceAlert: In a recent survey, published this month in PLOS One, we investigated the views of people in the United States, a country with one of the largest appetites for meat and an equally large appetite for adopting new technologies. A total of 673 people responded to the survey, done online via Amazon Mechanical Turk, in which they were given information about in vitro meat (IVM) and asked questions about their attitudes to it. Although most people (65 percent), and particularly males, were willing to try IVM, only about a third said they would use it regularly or as a replacement for farmed meat. But many people were undecided: 26 percent were unsure if they would use it as a replacement for farmed meat and 31 percent unsure if they would eat it regularly. This suggests there is scope to persuade consumers that they should convert to IVM if a suitable product is available. As an indication of this potential, 53 percent said it was seen as preferable to soy substitutes. The biggest concerns were about IVM's taste and lack of appeal, particularly in the case of meats seen as healthy, such as fish and chicken, where only two-thirds of people that normally ate them said that they would if it was produced by in vitro methods. By contrast, 72 percent of people who normally eat beef and pig products would still do so if they were produced as IVM. -
Big Talk About Small Samples
Bennett Haselton writes: My last article garnered some objections from readers saying that the sample sizes were too small to draw meaningful conclusions. (36 out of 47 survey-takers, or 77%, said that a picture of a black woman breast-feeding was inappropriate; while in a different group, 38 out of 54 survey-takers, or 70%, said that a picture of a white woman breast-feeding was inappropriate in the same context.) My conclusion was that, even on the basis of a relatively small sample, the evidence was strongly against a "huge" gap in the rates at which the surveyed population would consider the two pictures to be inappropriate. I stand by that, but it's worth presenting the math to support that conclusion, because I think the surveys are valuable tools when you understand what you can and cannot demonstrate with a small sample. (Basically, a small sample can present only weak evidence as to what the population average is, but you can confidently demonstrate what it is not.) Keep reading to see what Bennett has to say.The smallest sample I've ever used to make an argument was when I submitted some legal briefs, each no longer than five pages, in the anti-spam cases that I'd been filing in Washington State small claims court. Since I suspected the judges were not taking the cases seriously, I filed the briefs with the third and fourth pages stuck together in the center, by a tiny thread of paper joining the back of the third page to the front of the fourth page. (If someone were to turn the pages and actually readthe brief, the thread would break.) I did something similar in six different cases, and when the motions were all rejected, I went to the courthouse to look at the paper motions still in the file. In three out of six cases, the judge had rejected the motion without reading it first.
Now, the point was not to make any accurate estimation of the actual proportion, in the total population of small claims court judges, who would reject a brief in an anti-spam case without reading it. There's no basis for saying that the proportion of such judges is close to 50%. But we can still probably reject any contention that the proportion of such judges is very low. If only 10% of judges were rejecting motions without reading them, then there is only about a 1.4% chance of taking a random sample of six rejected motions and finding that in three or more cases, the judge did not read the motion. Even if 20% of judges were doing so, for an event with a probability of p=0.20 you would still only see it occur in three out of six cases, about 8.2% of the time. (If an event has probability p, the exact probability of that event occuring three or more times in six trials is given by 20*(p^3)*((1-p)^3) + 15*(p^4)*((1-p)^2) + 6*(p^5)*((1-p)^1) + 1*(p^6)*((1-p)^0).) So we can say that the proportion of such judges is quite probably more than 20%. I did this repeatedly because even after I had "caught" the first judge, I wanted to head off any objection that this was just an isolated case of rare behavior.
And, as always, it's important not to generalize too much about the behavior whose probability we're estimating. I don't think that 20% or more of judges, even in small claims court, are throwing most types of cases without reading or listening to the arguments. My impression was that most judges see view small claims court as a place to redress injustices, and that they see anti-spam and anti-telemarketer plaintiffs as just trying to "make money" at it, so they take those suits less seriously. I disagreed with this stance because (1) anti-spam plaintiffs usually really have been harmed and are not just "whining about one email" which they are trying to "cash in" (I still get so much spam that it interferes somewhat with the operation of my server and with my ability to get through my daily email); and (2) the law is intended after all as a deterrent, with disproportionate damages in order to discourage spammers from spamming in the first place. However, the charitable reading of the results is to assume that judges are merely biased against anti-spam plaintiffs -- but at least they probably don't treat all cases as casually as they treat anti-spam suits!
Back to the issue of small samples. My previous article was prompted by an editorial about the online response that had been elicited by two different photos -- one showing a black woman breastfeeding, and a nearly identical photo showing a white woman breastfeeding. The author asserted that the photos had received vastly different responses, which she attributed to racism. I presented a survey to a sample if users recruited from Amazon's Mechanical Turk, randomly showed each survey-taker one of the two photos, and asked:
Our academic department has asked everyone to submit a "fun" photo of themselves, so that our photos can be displayed together on the department home page. One of our employees submitted a photo that has caused some internal debate about whether the photo is inappropriate. I wanted to do a poll to get the opinion of a random sample of Internet users of different backgrounds.
Do you think this is an appropriate picture to be used in a photo collection on our academic department home page?Out of 47 respondents who saw the black woman's photo, 36 of them (77%) said it was inappropriate. Out of 54 respondents who saw the white woman's photo, 38 of them (70%) said it was inappropriate.
As before, these samples are to small to say precisely what the relevant proportions in the background populations are, but we can probably reject certain statements about the populations -- for example, that the percentage of users offended by the black woman's photo is 20 percentage points higher than the percentage of users offended by the white woman's photo. This is where the counterintuitive part comes in. Suppose that in the background population, 81% of respondents would find the black woman's photo offensive, but only 61% would be offended by the white woman's photo. What are the odds of getting 77% or less "yes that's offensive" responses from a sample of 47 users shown the black woman's photo, and getting 70% or more "yes that's offensive" responses from a sample of 54 users shown the white woman's photo? It doesn't sound unlikely at all, because the percentages are quite close to the originals -- but you can verify, either with statistical calculations or with a quickly written computer program, that the odds are only about 2.5%.
Two main factors contribute to this counterintuitive result. First, even with a sample size of a few dozen, the frequency of an event starts to tend very closely to the frequency in the background population (if 80% of your population has some trait, and you take a sample of size 50, there's about a 95% chance that the number with that trait in your population will be between 34 and 46). Second, to find the odds of seeing both of these deviations at the same time (deviating from an assumed 81% in the background population down to 77% in the first sample, and deviating from an assumed 61% in the background population up to 70% in the second sample), you have to mutiply the probabilities of these two unlikely events. The probability of the first deviation is about 19%, the probability of the second is about 13%, and so the probability of them both occurring is about 2.5%.
The reason I calculated the odds of getting 77% or less "offended" responses for the black woman's photo while also getting 70% or more "offended" responses for the white woman's photo, is that in calculating the "unlikeliness" of a statistical result, it's customary to calculate the odds of getting "this result or a more extreme one". For example, suppose you want to know if a company's hiring process is gender-balanced (assuming a 50/50 gender split in the population), and you notice that in a random sample of 100 recent hires, 61 were men. You wouldn't ask "What are the odds of there being exactly 61 men in this sample?", because the odds of getting any particular number, are small. You'd ask, "What are the odds of getting this result or a more extreme one -- i.e. the odds of getting 61 or more men out of a random sample of 100, if the population were truly gender-balanced? As this calculation tool shows, the odds are only about 1.7%.
Similarly, in the case of the two populations being measured, the author of the original editorial hypothesized that there was some significant gap between the percentages of the population that were offended by the two photos, which I arbitrarily assumed to be 20 percentage points. Under that assumption, showing the two pictures to two different groups and having them be offended at similar rates, is the unexpected, "extreme" result, and the closer the rates are to each other, the more extreme the result is. That's why I calculated "77% of less" for the first group vs. "70% or more" for the second group.
And out of the pairs of numbers that I tested which were separated by 20 percentage points, 81% and 61% were the numbers which made the given result the least unlikely. 80/60 and 79/59 give odds of about 2.5% and 2.4%; 82/62 and 83/63 give odds of 2.4% and 2.2%.
You can do the statistical calculations directly, but in case you won't believe it unless you see the results unfold with your own eyes, you can run this perl script, which iterates through a million trials of the experiment, counting the number of times that the unexpected result occurs.
Why did I assume a 20-point gap? That was the most subjective leap that I made. Looking through the original editorial, I figured that on the basis of inflammatory statements like
"Only one woman was called 'adorable' by the media and portrayed with girlish innocence, and it wasn't the black one. It never is."
and
"The contrast in headlines is so stark, it deserves to be examined" [I assume here she meant the contrast in responses]
the author meant to imply a difference in people's attitudes that was at least that large. But the results suggest that it isn't.
For all of this effort, of course, I could have just expanded the original experiment to a sample of several hundred and mollified some people's concerns. But I wanted to argue for what you can show, even with small samples, because I would like to try (and would like others to try) similar experiments in the future, and do not think people should be discouraged if they can't afford to pay a thousand Amazon Mechanical Turk workers to take their survey. I paid my 100 respondents $0.25 each; naturally, one experiment I'd like to do soon is to figure out what's the lowest I can get away with paying them.
-
Debunking a Viral Internet Post About Breastfeeding Racism
Bennett Haselton writes: A editorial with 24,000 Facebook shares highlights the differences in public reaction to two nearly identical breastfeeding photos, one showing a black woman and one showing a white woman, each breastfeeding an infant. The editorial decries the outrage provoked by the black woman's photo compared to the mild reaction elicited by the white woman's photo, and attributes the difference to racism. I tried an experiment using Amazon's Mechanical Turk to test that theory. Read on to see the kind of results Bennett found.You can see the side-by-side pictures in the November 10 editorial by Ruby Hamad. My first thought, upon seeing the pictures, was that this is not a controlled experiment -- the woman on the left is breastfeeding in public, while the woman on the right is breastfeeding against a blank wall inside a presumably private room. While I think breastfeeding in public should be completely normalized, it's not the same thing as breastfeeding in private, and so that might have accounted for the difference in reactions, if there was any.
My second thought was that the data on people's reactions was not collected in a systematic way. According to the editorial, the black photo of the black mother, Karlesha Thurman, was posted on the Facebook page Black Women Do Breastfeed, and "[w]hile Karlesha received many supportive comments, the backlash was so severe, she eventually deleted the photo." The photo of the Australian woman, Jacci Sharkey, was posted by the University of the Sunshine Coast on their Facebook page, where it received 275,000 Facebook "likes", but also, according to the editorial, "more than a few detractors, proving that breastfeeding in public is (still!) a contentious issue for women of all races." There's no apples-to-apples comparison gauging people's reactions to the two photos under similar conditions.
But just because the methodology was imprecise, doesn't mean that the underlying phenomenon might not be real. Maybe Internet users really do have different gut reactions to pictures of black women and white women breastfeeding.
One quick way to get a rough answer is Amazon's Mechanical Turk service, where you can pay legions of workers some small amount of money per person to complete some menial task that can't be automated by a computer. I've used it dozens of times for surveys (such as gauging whether people would strongly prefer slideout keyboard phones) and for amateur psychological experiments (including one experiment which suggested that people who answered a math problem correctly were more likely to disagree with an attorney general's dubious legal argument). So I created a poll on Mechanical Turk, limited to U.S. users and with a payout of 25 cents for each person who answered. The poll asked:
Our academic department has asked everyone to submit a "fun" photo of themselves, so that our photos can be displayed together on the department home page. One of our employees submitted a photo that has caused some internal debate about whether the photo is inappropriate. I wanted to do a poll to get the opinion of a random sample of Internet users of different backgrounds.
Do you think this is an appropriate picture to be used in a photo collection on our academic department home page?Since the original photos had been published in different contexts anyway, I tried to find a middle ground for the wording of the survey question, to emphasize that the photos were going to be published in a "fun" setting, but still integrated into the women's professional environments. The survey-takers were then (randomly) shown either the black woman's photo or the white woman's photo, and answered "Yes, the image is fine" or "No, the image is inappropriate". Then respondents were asked to fill in their age, gender, ethnicity, and education level.
(One thing that I've found with all of my previous surveys on Mechanical Turk, is that there is strong evidence that survey-takers are not answering randomly. Strong correlations often occur where you would expect them to -- for example, in a survey about what are the greatest causes of global strife, the same people tend to select "Energy shortages" and "Environmental damage" above other options, whereas another subgroup will tend to select both "Atheism" and "Decline of traditional values". And any survey where I've added a textbox for users to enter "more thoughts", most users enter something reasonably thoughtful which corresponds to the multiple-choice answers they've selected. Formal research by the psychologist Samuel Gosling has similarly found that Internet surveys can be useful for psychological research and are not plagued with bot-responders or random answers. So I'm working under that assumption.)
The results: Out of 47 respondents who saw the black girl's picture, 36 said the image was inappropriate (77%). Out of 54 respondents who saw the white girl's picture, 38 said the image was inappropriate (70%). For such a small sample, that's not enough to definitively say whether the small difference is due to random chance, or due to small differences in opinion in the population being surveyed. What it does show, even with such a small sample, is that in the underlying population there's almost certainly no huge gap between people's opinions of black women vs. white women breastfeeding in photos.
In both surveys, both male and female respondents voted the photos "inappropriate" with about the same frequency. For the black woman's photo, 22 out of 26 men (86%) and 14 out of 21 women (67%) voted the photo inappropriate; for the white woman's photo, 19 out of 30 men (63%) and 19 out of 24 women (79%) voted it inappropriate. There also didn't appear to be any correlation between the age of the respondents and their responses. (You can view the breakdown of answers in terms of respondent demographics here for the black woman's picture and here for the white woman's picture; the crummy layout is because I just copied-and-pasted the output from my own custom-written survey-taking tool, where I usually just view the results for myself.) As for the gap between black and white survey-takers, in the case of the black woman's photo, 24 out of 34 white survey-takers (70%) and 5 out of 6 black survey-takers (83%) voted it inappropriate, while for the white woman's photo, 25 out of 36 white survey-takers (69%) and 4 out of 4 (100%) of black survey-takers voted it inappropriate -- but those discrepancies probably don't mean much, since the population of self-identified black respondents was too small in both cases to draw any conclusions.
Even with small samples, though, I would argue that this is a better way to answer the question of latent racism than to draw fuzzy conclusions based on the trolling comments posted on a Facebook photo. My guess is that even if there was an underlying difference in the frequency of negative comments posted to the two photos, part of it could have been due to the photo being posted in a Facebook group titled "Black Women Do Breastfeed", a group name that is practically begging for trolls to wait for a chance to try and provoke an outraged response. The white woman's photo, on the other hand, was posted on the University of the Sunshine Coast Facebook page, which is not the kind of place that maladjusted nitwits hang out trying to start a flame war. And for the trolls who did post on the white woman's photo, their natural inclination would be to make some immature comment about b00bs; whereas for the trolls posting on the black woman's photo, the easiest cheap shot would be to make it about race. But that doesn't mean that there is actually a racially motivated difference in people's reactions to the photos.
Besides, if you want to use Facebook to raise awareness of racism, there are properly controlled scientific experiments that have demonstrated the extent of prejudice, such as the infamous 2003 resume callback experiment which showed that resumes with white-sounding names on them received about 50% more callbacks than resumes with black-sounding names. A viral story with 24,000 Facebook shares, about two isolated incidents under different circumstances, is not necessarily evidence of racism. It might be. But you have to do some kind of controlled experiment to check first.
-
Lots Of People Really Want Slideout-Keyboard Phones: Where Are They?
Bennett Haselton writes: I can't stand switching from a slideout-keyboard phone to a touchscreen phone, and my own informal online survey found a slight majority of people who prefer slideout keyboards even more than I do. Why will no carrier make them available, at any price, except occasionally as the crummiest low-end phones in the store? Bennett's been asking around, of store managers and users, and arrives at even more perplexing questions. Read on, below.In my rant about the sucky LG Optimus phone that I got from T-Mobile, I admitted that I stuck with it anyway and let them keep my money, because I couldn't stand switching away from the slideout keyboard on the phone. Same reason that I kept the Stratosphere from Verizon for so long, despite the other features of that phone sucking too. But after failing to find even one true smartphone with a slideout keyboard after visiting the local AT&T, Verizon, Sprint and T-Mobile stores, I started to wonder if I was just an old fud who couldn't get with the times.
(The slideout keyboards are usually called "QWERTY keyboards" in the marketing, but I'm using "slideout keyboard" in order to distinguish them from phones like Blackberries that have a physical QWERTY keyboard and screen all on the outer surface of the phone, since that forces the keyboard and the screen to be much smaller.)
Slideout keyboards have always felt more natural to me in a couple of ways. You can let your finger or thumb center on the correct key, and then press the key in a separate action, resulting in far fewer typos then if you're required to land your fingertip on the correct spot on the screen. (Fewer typos also means you can turn off autocorrect and worry about fewer idiotic auto-corrections.) A slide-out keyboard also makes it easier to hold the phone in a relaxed grip -- with the keyboard out, you can rest the phone on your other fingers while using your thumb to keep it in place, rather than having to grip the phone around the edges with your fingers to keep the screen uncovered. The relaxed thumb-centered grip makes it much easier to tilt the phone at different angles and even hold above your head without dropping it (handy for the first texts you answer before getting out of bed), all while hardly having to tense your fingers at all.
I mentioned this to the Sprint sales guy and he shook his head and said, "Oh, no, everybody wants touchscreen phones now." When I mentioned later to the AT&T store manager that I felt I must be in a shrinking minority, he said that he preferred slide-out keyboards, most other people preferred slide-out keyboards, and the industry was just moving away from them regardless. Who was right? Skeptical as ever about people's claims that they've "heard lots of people saying so-and-so," I posted a survey on Amazon's Mechanical Turk ( which I have used in the past for all kinds of weird stuff), seeking out respondents who had used both a phone with a slideout keyboard and a phone with a virtual keyboard, and asking which one they preferred, and why.
Out of 49 respondents, 27 said they preferred slideout keyboards and 22 said they preferred virtual keyboards. And I know the Internet survey-takers weren't just clicking answers at random, because most of them gave details as to the reason for their preference (even though this was not enforced by the survey form). Obviously that's too small of a sample to be very precise about the percentage of users that prefer slide-out keyboards (apart from the fact that Mechanical Turk users are unrepresentative of the general population in several ways), but it does mean that the near-extinction of slideout-keyboard phones in retail stores is probably not in proportion to what people actually want.
You can download the raw survey data here; some of the highlights from people who said they preferred slideouts:
"I preferred using an actual keyboard because I can actually feel the keys. After my hands get used to the keyboard, I could type very fast. Using a virtual one is much harder because you don't actually feel the keys you are typing."
"I can put my fingers on the actual keys just like a typewriter and know they won't slip off and hit the wrong key. I was heartbroken when then got rid of almost all qwerty keyboards in the new phones. They are now almost impossible to find."
"The slide-out keyboard offers more accuracy and feedback than a virtual keyboard. I can easily tell if I'm pressing the wrong letter key on a physical keyboard than a virtual one. I also prefer my keyboard to be off of the screen so I can easily see what I'm typing."
"I think its easier to type on a slide out keyboard. With the virtual ones I'm always spending half the time correcting the mistakes."
"I preferred slide-out keyboards because you could actually feel the crevices that separate each letter on the keyboard, and this allowed you to type much more efficiently. There's just something more beautiful and human about physically touching something rather than using the heat in your fingers to make unreal letters type on a screen."
On the other side of the aisle, the most common reasons that people gave for preferring virtual keyboards were that slideouts were too flimsy or bulky:
"Virtual keyboards are sturdier than slide out keyboards."
"The decreased overall weight of the device due to the lack of physical keyboard is the biggest benefit to me. Plus the added benefit is that virtual keyboard technology has come a long way in the last few years and offers unique features such as swiping words whereas a physical keyboard still limits you to typing and switching between buttons and the screen in order to select or correct words."
"A virtual keyboard is faster and less cumbersome than a slide out keyboard."
"I liked the tactile feeling of the slide out keyboard. I found the keyboard slide to be more bulky however. I like the virtual keyboard because it allows me to use a larger amount of screen space on my phone when I am not typing. You can also do cool keyboard gestures with the virtual keyboard, such as sliding the finger to type. The virtual keyboard also has an auto correct feature built in which is handy. My old slide out keyboard phone was cool at the time but lacks the features modern virtual keyboard have. Also, real keyboards make clicky noises, which can prevent you from sending texts out under your desk during meetings, haha."
(That last guy's right -- I've been out of the workforce long enough that I forgot you can't get away with texting in a meeting on a slideout, unless other people in the room are covering your noise by "taking notes" typing on their laptops.)
So - not everyone wants slideout keyboards, but a lot of people really, really want them, and the stores refuse to stock them. What gives?
The AT&T store manager simply said that they were more expensive to make, and people return them more often because they break more easily. Well of course it makes sense that the extra component costs more, but it seemed counterintuitive that the slideout keyboards are usually only found on the cheapest phones in the store (which don't qualify as true smartphones). It's odd for an expensive extra component to be found only in the cheapest models of a product line, as if Ford had announced that their self-parking technology would only come bundled with the Fiesta.
More importantly, it seems strange that a more expensive or even a more fragile component, cannot be made available at any price when so many people want it. If it costs more, surely they could just charge more. I'd pay at least an extra $100-$200 for a phone with a slideout keyboard (which is more than the entire retail cost of a dumbphone with a slideout keyboard, so the price increase on a real phone should be less than that). If it makes the phone more fragile and more likely to be returned, surely that could just be reflected in a higher monthly "insurance" fee to cover the cost of exchanging damaged phones (which is only about $5 per month anyway). Is this another example of market failure, even in a competitive industry? It's easy for Facebook to force changes down our throats, since we have nowhere else to go, but how did Verizon, AT&T, T-Mobile and Sprint all end up abandoning such a sizable portion of their customers, even while locked in a cutthroat battle with each other?
Maybe this can be the next big thing that T-Mobile does to differentiate themselves from everybody else (like when they broke ranks and decided to sell all phones at retail price with no long-term contracts) -- everybody knows their network is spottier, but it's usable, and if they're doing one thing right that you really care about, and everyone else is doing it wrong, that's reason enough to switch. Their pink-shirted CEO certainly likes making waves with his colorful metaphors about the other carriers screwing you over. If T-Mobile sold me a real phone with a slideout keyboard, I'm sure I'd stay with them for years, even though yesterday the rain (a fairly common phenomenon here in Bellevue, where T-Mobile U.S. is headquartered) caused the reception on the phone to go from 4G to 2G and then down to "G," which I didn't even know was a thing.
-
The Best Parking Apps You've Never Heard Of and Why You Haven't
Bennett Haselton writes "If you read no further, use either the BestParking or ParkMe app to search all nearby parking garages for the cheapest spot, based on the time you're arriving and leaving. I'm interested in the question of why so few people know about these apps, how is it that they've been partially crowded out by other 'parking apps' that are much less useful, and why our marketplace for ideas and intellectual properly is still so inefficient." Read below to see what Bennett has to say.I casually asked a couple of my friends in Seattle -- where street parking is often unavailable, and parking garages vary widely in price -- if they'd ever heard of an app that would let them find the cheapest available parking garage, based on the time they wanted to enter and the time they planned on leaving. (Street parking is usually cheaper if you can find it, but the app would be useful for times that you can't find any.) Most of my friends said that they'd never heard of such an app, but they'd definitely use one if it existed. I also looked up parking apps on Google but the small subset that I randomly tried out, didn't do what I needed. So I thought about writing a "Somebody-with-more-time-than-me-should-go-and-do-this-thing" article, similar to the ride-swapping piece, when one of my friends casually mentioned the BestParking app.
Well, I tried it and it worked. (Lest I be accused of undue favoritism, ParkMe does the same thing just as well, although I didn't find it until later.) In both apps, you bring up a map centered on your current location, or scroll the map to where you plan on looking for parking later. You enter the time that you'll be entering and leaving, and the app shows a map with each parking garage represented by an icon showing the dollar amount that it will cost to park for that time. Without these apps, comparing rates is an annoyingly complex process to do by hand, in a crowded city like Seattle with many garages with different rates (and different times when their "evening rates" kick in -- usually 5 PM, but ranging from 4 to 7 PM), but the apps factor all of that in to give you the cheapest garage for the given time range. You can tap the individual garage icons for more information (if you plan on returning by 11 PM but you're not sure, you'd probably prefer a 24-hour garage instead of one that locks up at midnight). Also, if you're sitting at your computer and you already know the neighborhood where you'll be parking later, you can do the same search on each of their websites. (Although if you are on your phone, please don't do this from a moving car, duh. In Seattle there are plenty of 3-minute spots where you can pull over and do a search.)
So, I've been quite happy with both apps -- but I thought it was interesting that almost none of my friends had ever heard of them. I threw a quick survey up on Amazon's Mechanical Turk website, which I've used before for crowdsourced surveys and other experiments. I polled 50 people, offering them 25 cents apiece to answer these questions:
Would you use these apps? Section A: Parking garage app
Suppose a website and/or smartphone app existed where you could specify a neighborhood of a city, and enter a start and end time for when you wanted to park, and the app would automatically find the cheapest parking garage for that time range (assuming its too hard to find street parking).
1. Are you aware of any such apps/websites that already exist? If yes, whats the name of the app? (No need to do a web search -- only answer "Yes" if you already know of such an app or website.)
2. Would you use such an app/website if it existed? (Or, if youre aware of such an app that already exists, do you use it?)
Yes/No Section B: Spare room rental app
Suppose a website and/or smartphone app existed where you could list a room in your house as a temporary rental, and visitors to your city could rent it out for a single night, or more.
3. Are you aware of any such apps/websites that already exist? If yes, whats the name of the app? (No need to do a web search -- only answer "Yes" if you already know of such an app or website.)
4. Would you use such an app/website if it existed? (Or, if youre aware of such an app that already exists, do you use it?)
Yes/No
The second section, about a spare room rental app, was thrown in as a control in the experiment -- I knew the answer to that question (AirBnB), and I thought a large portion of the survey-takers would too, so I wanted to make sure they weren't just filling out the survey with blow-off answers to get the 25 cents as fast as possible.
Of the 50 people who filled out the survey, 14 of them said they had heard of using AirBnB, Couchsurfing, or Craigslist for the purpose of renting out a room or finding one to rent (almost all of them mentioned AirBnB specifically). But of the same 50 respondents, only two of them mentioned any parking apps that they had heard of, and only one of them mentioned one of the two that I'd found which actually worked. (The other person mentioned an app called ParkWhiz, which, when I tested it out, only displayed one $17 parking garage in a neighborhood where I know of several $5 garages, which BestParking and ParkMe did list correctly.)
This seems to confirm the anecdotal evidence from my survey of my Seattle friends -- there is a great deficiency in awareness of these apps, relative to how useful people would find them if they knew about them.
So how is it that people are finding -- or not finding -- these apps? In a Google search for "parking app", the first result was an ad for ParkWhiz. BestParking and ParkMe did show up in the results, but so did another one called Parker, as well as a Mashable article by Kate Freeman listing "7 City Parking Apps to Save You Time, Money and Gas". Of the apps listed in the article, the only city-specific one that worked in Seattle (PrimoSpot) has been discontinued, and of the non-city-specific ones, only Parker is still around. (The article doesn't even mention BestParking or ParkMe, although I don't know if they existed when it was written.) Finally, a friend in my survey told me about an app called Parkopedia, which has over 100,000 downloads on Google Play (the same as BestParking, and more than ParkMe).
So even if it did occur to you to look for a parking-garage-finding app, the problem is that if you randomly picked one of the five most popular parking apps (BestParking, Parker, ParkMe, Parkopedia, and ParkWhiz), you might accidentally pick one of the three out of five that is a fail:
-
ParkWhiz, as noted above, only showed one $17 garage in a neighborhood full of other, cheaper garages.
-
Both ParkMe and Parkopedia display their results as a map with an icon marking each parking garage -- but with no price information. Simply having a map of parking garage locations isn't too useful, since you could get that by searching Google Maps for "parking" anyway. In both apps, you can click on parking garage icons to bring up a window showing their rates, but in Parker most of the listed garages just said "Contact facility for current rates". Parkopedia did usually display the rates for different garages -- but it's a pain to click on each of a dozen parking garage icons looking for the cheapest one. A typical area of downtown Seattle will have one garage where you can park for $5 for the evening, surrounded by garages where parking costs $10 or more, but Parkopedia doesn't make it easy to find it. And neither app lets you specify a start and end time for your parking so that you can find the cheapest garage for that time range.
So it seems odd that according to the Google Play store, Parkopedia has more downloads than ParkMe (100,000+ vs 50,000+), even though ParkMe seems a lot more useful. Meanwhile ParkWhiz, the one that found only one overpriced parking garage in a neighborhood full of cheaper ones, has fewer downloads but a slightly higher star rating in the app store than ParkMe. Of course in my parking-app survey of friends and Mechanical Turk users, the far-and-a-way winner was simply not knowing that any of these apps existed at all.
And here's why it matters to you even if you ride a granola-powered bike to work: I think this is a confirming instance of what I've been arguing for years, that the marketplace for ideas, inventions, and intellectual property is far less efficient than most people think it is. Every day a huge amount of human capital is squandered by people trying to jostle their competitors out of Google search results, or even just trying to raise the capital to advertise their products to people who would find them extremely useful, but will never find out about it if the venture capitalists don't come through with the money to advertise it. All of that is time and effort that could have instead gone towards making the products better.
I've suggested an algorithm based on "random-sample voting" as an antidote to some of these market inefficiencies, such as stopping people from buying votes on Digg, promoting the best ideas on Obama's "We The People" petition website, or even deciding whether J.K. Rowling is the world's greatest author or just lucky. Basically, in each scenario, the competing entities -- whether apps, or songs, or ideas for improving U.S. government policy -- would be rated by a sufficiently large random sample of qualified raters. ("Qualified raters" might mean economists in the case of the White House policy-petition website, or it might mean music consumers in the case of an algorithm to find the best new songs.) Each entity would receive an average rating from those raters, and then the entities with the highest average rating would be the ones promoted to the widest audience (at the top of Google search results, for example). It sounds deceptively simple, but it's far less amenable to "gaming the system", because you can't rope in your friends to vote for your app, or pay voters to rate you highly on Digg. The only way to win in this system is to make your song, idea, or app, the best that it can be -- which means your human capital is being channeled productively, instead of being wasted hiring an SEO company to try and knock your competition out of the top spot on Google.
If competition between parking apps worked this way, then all the current users of Parker, ParkWhiz and Parkopedia, would switch to BestParking and ParkMe, saving themselves a lot of hassle in the process, and those second-rate apps would have never even gotten on the ground unless they got their act together and implemented the same features. More broadly, if competition in the marketplace of ideas worked this way, then there wouldn't be so many users who really wish they could have an app like this, without realizing that the apps exist!
One striking thing about looking at a map of downtown parking garages, is how wildly the rates vary from each other, with $15 garages situated right next to the $5 ones. In theory, in a competitive marketplace, such rates should stabilize around a single price, for goods that are roughly comparable. But the $10 lots do still manage to get some customers who don't know any better, because it's just not practical to criss-cross a grid of several dozen city blocks looking for the cheapest garage. BestParking and ParkMe help people deal with this inefficient marketplace. So it's ironic that they're being held back by a marketplace for ideas that operates just as inefficiently in its own way.
-
-
Crowdsourcing Confirms: Websites Inaccessible on Comcast
Bennett Haselton writes with a bit of online detective work done with a little help from some (internet-distributed) friends: "A website that was temporarily inaccessible on my Comcast Internet connection (but accessible to my friends on other providers) led me to investigate further. Using a perl script, I found a sampling of websites that were inaccessible on Comcast (hostnames not resolving on DNS) but were working on other networks. Then I used Amazon Mechanical Turk to pay volunteers 25 cents apiece to check if they could access the website, and confirmed that (most) Comcast users were blocked from accessing it while users on other providers were not. The number of individual websites similarly inaccessible on Comcast could potentially be in the millions." Read on for the details.My first clue came when a friend of mine set up the website http://www.helpmatt.org/ and asked her friends to donate. I said the website appeared to be down; they replied back that it was working fine for other people — and I narrowed it down to Comcast DNS servers not resolving the hostname www.helpmatt.org correctly. When I accessed the same website over my Frontier DSL connection, it worked. (I had recently signed up for Comcast cable Internet to save money over DSL, but I kept my DSL connection "just in case" something went wrong. At the time, I thought maybe I was being paranoid -- how hard could it be for a cable company to just run a straight Internet connection to my house and not screw anything up? Hollow laugh.)
I put out an informal survey to my Comcast-using friends, and a few of them said they couldn't access the website either. Still, I thought, this wasn't enough evidence that it was Comcast's fault; maybe the hostname was only resolving intermittently, and just by sheer coincidence it happened to be up when all of my non-Comcast-using friends tried it? I was about to do a more formal experiment, and recruit a larger sample of testers through Amazon Mechanical Turk to test whether the site was inaccessible to other Comcast users, when the problem spontaneously fixed itself and suddenly the website became accessible 100% of the time to everyone.
But, my curiosity had been piqued. Was there something wrong with Comcast's DNS servers -- whether deliberate or not -- that was causing other websites not to resolve correctly? I wrote a perl script to take a sample of websites -- part of the same list that I had used to find websites that were mis-blocked as 'pornography' by Smartfilter — and attempt to resolve them using both Comcast's main DNS server (75.75.75.75) and one of Google's public DNS servers (8.8.8.8). (You won't be able to do this experiment yourself unless you have a Comcast Internet connection, because while Google's DNS servers accept queries from anywhere, Comcast's DNS servers will refuse queries from any IP address not assigned to one of their customers.)
The script ran through a few hundred hostnames and flagged anything that failed to resolve on Comcast but resolved correctly on Google, although most of these were false positives caused by Comcast's DNS servers being temporarily unresponsive. But after running through the list of false-positives repeatedly, I found the first website that consistently failed to resolve on my Comcast Internet connection while resolving on Google: http://www.021yy.org/.
The website is for a second-hand furniture store in Shanghai; I have no idea what the domain "021yy.org" has to do with the business. (Perhaps the IP address that the domain name resolves to used to be occupied by a different website, and that IP address was inherited by the furniture store but the old hostname still points to it.) The hostname www.021yy.org resolves to the IP address 116.251.210.33 (for *ahem* non-Comcast users, that is), which according to the Asia Pacific Network Information Centre is part of a block of IP addresses assigned to a hosting company in Singapore. I'm not blocked from accessing the IP address of the website over Comcast; I can ping and send web requests to the IP address 116.251.210.33 with no problem. Only the hostname fails to resolve. (I can still access the site by using a VPN or a proxy server.)
So, I created a survey on Amazon Mechanical Turk, asking people three questions:
- Can you access the website http://www.021yy.org/?
- If you can't access the site, what error message does your browser give you?
- What provider are you using?
and offered 25 cents to every user who filled out the survey, up to a maximum of 50 people. Amazon Mechanical Turk, if you've never used it before, lets you create low-payment tasks and outsource them to a crowd of workers. Like any simple and powerful tool, it can be used for purposes that the original creators probably never imagined (presumably including this experiment), and someday I'd like to look into the most creative and bizarre things people have done with it. (Although, in this case, it seems like the site may not have done a great job of matching this task with available workers. Only 20 people filled out my survey in the 24 hours after I created it -- surely, out of all the available Mechanical Turk workers, there were more than 20 people who would have been interested in doing a simple website accessiblity check for 25 cents?)
20 unique users filled out the survey and reported:
- Out of the 14 non-Comcast users, 100% of them were able to access the site.
- Out of 6 Comcast users, 4 of them were blocked from accessing the site, and reported errors symptomatic of DNS failures ("Oops! Google Chrome could not find www.021yy.org" or "Server not found. Firefox can't find the server at www.021yy.org").
Even with such a small sample, that's enough to conclude that it's not a coincidence. (The real question is how two out of those six Comcast users were able to access the site at all. Maybe they're in a region of the country that's assigned different DNS servers. If I did the survey again, I'd ask people to include where they were living.)
So Comcast users -- at least some of them, probably most of them -- are blocked from accessing certain websites, which are perfectly accessible to users on other providers. I "only" had to test a few hundred domain names before finding one that would consistently fail to resolve on Comcast while resolving successfully on other companies' nameservers. With hundreds of millions of distinct websites "out there," if the same proportion holds, that would suggest that there about a million or more websites similarly affected. And that's not even counting all the other sites — like helpmatt.org, and also including some of the sites in my sample — which apparently resolve 100% of the time on other providers while sometimes failing to resolve on Comcast, but where the failure was not consistent enough to use them as a test case for the Mechanical Turk survey.
Unlike, say, the kerfuffle over Comcast threatening to de-prioritize content delivery from websites that don't pay them a fee, it's unlikely that Comcast is meddling with traffic intentionally here (especially since the sites' IP addresses are not blocked). It's more of a demonstration that if a company is sufficiently big and if it's sufficiently hard to prove that a problem is being caused on their end, the problem can exist for a long time without being solved. I called Comcast tech support after I discovered that sites were blocked on their network but not on other providers, and said that the problem really needed to be brought to the attention of the higher-ups, but tech support was adamant that it was impossible for a member of the public to reach anybody higher up than the call center.
Even if the number of affected sites is huge, at least it's only a small percentage of websites — I did have to run my script on a few hundred sites before I found one that appeared to be resolving on other DNS servers but not on Comcast. But that likely would have provided scant comfort to my friends who set up the helpmatt.org site, when they were urging people to visit the site and donate, and 25% of potential visitors were unable to reach the page. When it's your website, it's kind of a big deal.
-
Crowdsourcing Confirms: Websites Inaccessible on Comcast
Bennett Haselton writes with a bit of online detective work done with a little help from some (internet-distributed) friends: "A website that was temporarily inaccessible on my Comcast Internet connection (but accessible to my friends on other providers) led me to investigate further. Using a perl script, I found a sampling of websites that were inaccessible on Comcast (hostnames not resolving on DNS) but were working on other networks. Then I used Amazon Mechanical Turk to pay volunteers 25 cents apiece to check if they could access the website, and confirmed that (most) Comcast users were blocked from accessing it while users on other providers were not. The number of individual websites similarly inaccessible on Comcast could potentially be in the millions." Read on for the details.My first clue came when a friend of mine set up the website http://www.helpmatt.org/ and asked her friends to donate. I said the website appeared to be down; they replied back that it was working fine for other people — and I narrowed it down to Comcast DNS servers not resolving the hostname www.helpmatt.org correctly. When I accessed the same website over my Frontier DSL connection, it worked. (I had recently signed up for Comcast cable Internet to save money over DSL, but I kept my DSL connection "just in case" something went wrong. At the time, I thought maybe I was being paranoid -- how hard could it be for a cable company to just run a straight Internet connection to my house and not screw anything up? Hollow laugh.)
I put out an informal survey to my Comcast-using friends, and a few of them said they couldn't access the website either. Still, I thought, this wasn't enough evidence that it was Comcast's fault; maybe the hostname was only resolving intermittently, and just by sheer coincidence it happened to be up when all of my non-Comcast-using friends tried it? I was about to do a more formal experiment, and recruit a larger sample of testers through Amazon Mechanical Turk to test whether the site was inaccessible to other Comcast users, when the problem spontaneously fixed itself and suddenly the website became accessible 100% of the time to everyone.
But, my curiosity had been piqued. Was there something wrong with Comcast's DNS servers -- whether deliberate or not -- that was causing other websites not to resolve correctly? I wrote a perl script to take a sample of websites -- part of the same list that I had used to find websites that were mis-blocked as 'pornography' by Smartfilter — and attempt to resolve them using both Comcast's main DNS server (75.75.75.75) and one of Google's public DNS servers (8.8.8.8). (You won't be able to do this experiment yourself unless you have a Comcast Internet connection, because while Google's DNS servers accept queries from anywhere, Comcast's DNS servers will refuse queries from any IP address not assigned to one of their customers.)
The script ran through a few hundred hostnames and flagged anything that failed to resolve on Comcast but resolved correctly on Google, although most of these were false positives caused by Comcast's DNS servers being temporarily unresponsive. But after running through the list of false-positives repeatedly, I found the first website that consistently failed to resolve on my Comcast Internet connection while resolving on Google: http://www.021yy.org/.
The website is for a second-hand furniture store in Shanghai; I have no idea what the domain "021yy.org" has to do with the business. (Perhaps the IP address that the domain name resolves to used to be occupied by a different website, and that IP address was inherited by the furniture store but the old hostname still points to it.) The hostname www.021yy.org resolves to the IP address 116.251.210.33 (for *ahem* non-Comcast users, that is), which according to the Asia Pacific Network Information Centre is part of a block of IP addresses assigned to a hosting company in Singapore. I'm not blocked from accessing the IP address of the website over Comcast; I can ping and send web requests to the IP address 116.251.210.33 with no problem. Only the hostname fails to resolve. (I can still access the site by using a VPN or a proxy server.)
So, I created a survey on Amazon Mechanical Turk, asking people three questions:
- Can you access the website http://www.021yy.org/?
- If you can't access the site, what error message does your browser give you?
- What provider are you using?
and offered 25 cents to every user who filled out the survey, up to a maximum of 50 people. Amazon Mechanical Turk, if you've never used it before, lets you create low-payment tasks and outsource them to a crowd of workers. Like any simple and powerful tool, it can be used for purposes that the original creators probably never imagined (presumably including this experiment), and someday I'd like to look into the most creative and bizarre things people have done with it. (Although, in this case, it seems like the site may not have done a great job of matching this task with available workers. Only 20 people filled out my survey in the 24 hours after I created it -- surely, out of all the available Mechanical Turk workers, there were more than 20 people who would have been interested in doing a simple website accessiblity check for 25 cents?)
20 unique users filled out the survey and reported:
- Out of the 14 non-Comcast users, 100% of them were able to access the site.
- Out of 6 Comcast users, 4 of them were blocked from accessing the site, and reported errors symptomatic of DNS failures ("Oops! Google Chrome could not find www.021yy.org" or "Server not found. Firefox can't find the server at www.021yy.org").
Even with such a small sample, that's enough to conclude that it's not a coincidence. (The real question is how two out of those six Comcast users were able to access the site at all. Maybe they're in a region of the country that's assigned different DNS servers. If I did the survey again, I'd ask people to include where they were living.)
So Comcast users -- at least some of them, probably most of them -- are blocked from accessing certain websites, which are perfectly accessible to users on other providers. I "only" had to test a few hundred domain names before finding one that would consistently fail to resolve on Comcast while resolving successfully on other companies' nameservers. With hundreds of millions of distinct websites "out there," if the same proportion holds, that would suggest that there about a million or more websites similarly affected. And that's not even counting all the other sites — like helpmatt.org, and also including some of the sites in my sample — which apparently resolve 100% of the time on other providers while sometimes failing to resolve on Comcast, but where the failure was not consistent enough to use them as a test case for the Mechanical Turk survey.
Unlike, say, the kerfuffle over Comcast threatening to de-prioritize content delivery from websites that don't pay them a fee, it's unlikely that Comcast is meddling with traffic intentionally here (especially since the sites' IP addresses are not blocked). It's more of a demonstration that if a company is sufficiently big and if it's sufficiently hard to prove that a problem is being caused on their end, the problem can exist for a long time without being solved. I called Comcast tech support after I discovered that sites were blocked on their network but not on other providers, and said that the problem really needed to be brought to the attention of the higher-ups, but tech support was adamant that it was impossible for a member of the public to reach anybody higher up than the call center.
Even if the number of affected sites is huge, at least it's only a small percentage of websites — I did have to run my script on a few hundred sites before I found one that appeared to be resolving on other DNS servers but not on Comcast. But that likely would have provided scant comfort to my friends who set up the helpmatt.org site, when they were urging people to visit the site and donate, and 25% of potential visitors were unable to reach the page. When it's your website, it's kind of a big deal.
-
The Mathletes and the Miley Photoshop
Frequent Slashdot contributor Bennett Haselton's essay this week is about "A Tennessee man is arrested for possessing a picture of Miley Cyrus's face superimposed on a nude woman's body. In a survey that I posted on the Web, a majority of respondents said the man violated the law -- except for respondents who say they were good at math in school, who as a group answered the survey differently from everyone else." Continue on to see how.On June 24, a Tennessee man was arrested for possessing photos that showed the faces of three underage girls, including Miley Cyrus, superimposed onto the nude bodies of adult women. Assistant District Attorney Dave Denny said of the arrest, "When you have the face of a small child affixed to a nude body of a mature woman, it's going to be the state's position that this is for sexual gratification and that this is simulated sexual activity." The phrase "simulated sexual activity" apparently refers to a Tennessee sex crimes law which states in part: "It is unlawful for any person to knowingly possess material that includes a minor engaged in simulated sexual activity that is patently offensive."
Assuming this is the crime that the D.A. plans to charge him with, to me it seems obvious that the defendant didn't violate the law as written. For one thing, if the nude women in the pictures were just standing there (and neither the article nor the D.A.'s statement suggests otherwise), then there was no "sexual activity" in the photos of any kind, real or simulated. But even if the nude adult women in the photos had been engaged in sexual activity (even just striking a mildly sexy pose), the law still would not apply, because the law requires an actual minor to actually be engaged in something, even if that "something" is simulated sexual activity. So if a video showed a real minor that appeared to be masturbating or having sex with someone in a manner that was "patently offensive", that could violate the law. (Hopefully the "patently offensive" clause would exclude artistic movies like The Tin Drum, although that defense has not always worked.) But if the girls' faces were simply cut and pasted onto the bodies of the women in the photos, then the minors in question were not "engaged in" anything. The D.A. appears to have confused "material that includes a minor engaged in simulated sexual activity" with "material that simulates a minor engaged in sexual activity". And the D.A.'s statement that "this is for sexual gratification and that this is simulated sexual activity" — clearly implying that the pictures are for sexual gratification and therefore this is "simulated sexual activity" — is ridiculous. The defendant probably used pictures of Miley with her clothes on for "sexual gratification" — does that make the photos "simulated sexual activity"? (Dave Denny's office did not respond to my request for comment.)
But I was more interested in a different question: What would people in a survey think about whether the defendant violated the law? And, would people who are good at math, answer the question differently from everyone else? And would those people answer the question differently from people who are good at, say, English composition?
That might seem like an odd twist to put on it. But if you can show that a certain answer correlates with mathematical ability, that indicates something special about that answer. And if you can show that that answer appeals to people with math skills, but not to people with English/writing/composition skills, then that indicates something interesting not just about that answer, but about mathematical ability as well, as opposed to writing ability. Whether that answer is "right" or "wrong" (or whether you think those terms are even meaningful for a legal opinion), it is a fact, not an opinion, that people with self-reported higher math skills are more likely to pick that as the correct choice.
By contrast, when the D.A. makes a public statement about the criminality of the defendant's actions, the implication is that we should give some weight to his statements because of his qualifications, such as being a member of the bar. But if we were to ask other bar members to decide independently of each other whether the defendant committed a crime, would they converge on the same answer? If not, then why should we listen to him, as opposed to someone else with the same credentials? When an expert cites their credentials in support of an opinion, if it's not true that other experts with the same credentials would back them up on that opinion, I don't think people realize the extent to which there is no there there.
So in the survey, I described the man's alleged actions and the Tennessee statute, and asked people if they thought he had violated the law. I also asked respondents to rate their math skills as "Excellent"/"Very good"/"Good"/"Fair"/"Poor" and to rate their English/composition skills as "Excellent"/"Very good"/"Good"/"Fair"/"Poor". The survey was posted on the Amazon Mechanical Turk site, where you can post "tasks" for people to complete in exchange for small payments of, say, 25 cents apiece. Some companies use this for grunt work (like hiring people to review user-submitted profile photos to make sure they don't contain nudity), but I use the site mainly to conduct surveys.
I think it's unlikely that the Mechanical Turk users are a representative cross-section of the population, but I use it more to find significant relative differences between demographic groups. If 60% of women on the site answer a question one way and 80% of men answer it the other way, that probably suggests that in a real cross-sectional survey of the population, men and women would largely disagree on the answer as well. (The alternative would be that the kind of men and women who use Mechanical Turk are predisposed to answer the question differently along gender lines in a way that average men and women are not, but that seems unlikely.)
For this survey, I offered users 25 cents apiece for completing this survey and collected 127 responses. The results in a nutshell:
- About two-thirds of all respondents (85 out of 127) said that the man did violate the law.
- However, among the respondents who rated their own math skills as "Excellent", only 44% (12 out of 27) said he violated the law, and 56% (15 out of 27) said that he did not. Out of all ten ability groupings (five different ability groupings for math, from "Excellent" to "Poor", and five for English), this was the only group where a majority said that the defendant didn't violate the statute.
- Respondents who self-rated their English/composition skills as "Excellent", were also more likely than average to vote that the man did not violate the law, but a majority of them still voted that he did.
These results are significant at the 99% level, which you can check using an online statistical significance calculator. In other words, despite the modest sample size, the answers given by the respondents with self-rated "excellent" math skills are so starkly different from everyone else's, that there's less than a 1 in 100 chance that the difference is due to coincidence. Almost certainly, something about mathematical ability is correlated with a person's likelihood of giving the "not guilty" answer. (At this point I'm going to give in to my bias and hereinafter refer to that as the "right answer.")
Furthermore, while respondents with "excellent" English/composition skills were also more likely than average to get the right answer (a difference that is also significant at the 99% level, given the collected data), they were considerably less likely to do so, than the users with self-reported "excellent" math skills (again, significant at the 99% level). I tabulated all the responses.
If I could afford to pay a larger sample, I would investigate whether the effect of "excellent" English/composition skills disappears entirely when you control for math skills. In other words, it's possible that the people with excellent English/composition skills were more likely than average to get the right answer, but only insofar as their English/composition skills were correlated with excellent math ability — and maybe people with "excellent" English/composition skills, but only average math ability, score no better than the average respondents.
One thing that jumps out at me: Even though 44% of the 27 people with "excellent" math skills said the man did violate the law, when you look at the 58 people who self-reported "very good" math skills, 74% of them said he violated the law. This would appear to confound my original hypothesis that good math skills lead people to converge on the correct answer. But I suspect that many people with self-reported "very good" math grades were probably just good students who studied hard and did the practice problems and got good grades in math, but without necessarily having the insight that makes someone an "excellent" math student. Without that insight, there was no reason to expect them to be better than average at answering a question that has no resemblance to their textbook's practice problems.
In fact, I suspect that many of the people who self-reported their math skills as "excellent", and who still answered "yes" to the question of whether the man violated the law, probably fell into that studious-but-not-insightful category as well. It would be interesting to test whether if you required respondents to actually answer a math question — not a standard textbook question, but a tricky question that required people to demonstrate an understanding of what is actually going on — if the correlation between correctly answering that question, and "correctly" answering the legal question, is even stronger.
But what I think is even more important than the correlation of the correct answer with "excellent" math ability, was the significantly lower correlation of the correct answer with "excellent" English skills. I've been saying for years that you can use excellent prose to defend an illogical idea, or you can use poorly crafted prose to defend a good idea, and so if you care about the quality of an idea and its impact on the real world, you have to look at the substance of an argument, not the style. Economics professor Steven Landsburg writes in his forthcoming philosophy book The Big Questions,
The bane of a college professor's existence is the student who has been taught in a writing course that there is such a thing as good writing, independent of having something to say. Students turn in well-organized grammatically correct prose, with the occasional stylistic flourish in lieu of any logical argument, and don't understand why they've earned grades of zero.
I call such people "vocabulemics", who seem to think the purpose of a discussion is to vomit up as many SAT vocab prep words as possible, rather than to form a coherent point. I've tried, and I can't think of any coherent point that could be made in order to argue that the Miley photoshopper really did violate the Tennessee law.
If you're still unconvinced by the results of a survey of mathletes, consider that they do match up well with the comments provided to me by Mark Rasch, a lawyer and computer security specialist with Secure IT Experts and the former head of the Department of Justice Computer Crimes Unit:
First, an image of a minor engaged in simulated sexual activity is not the same as a simulated minor engaged in sexual activity... In other words, if you posed actual minors, nude, and made it look like they were having sex, it would be a crime, even though there was no "actual" sexual activity. In most other contexts, when the legislature says "simulated sexual activity" they mean real people engaged in what appears to be sex. The government is trying to apply this theory to real sex but simulated minors. I don't think that passes statutory muster.. its not what the statute prohibits... Under that rationale, if you had, for example, a picture of two dogs mating, and glued pictures of kids on the dogs faces, this would be "simulated sexual activity" but would not be prosecutable. Where do you draw the line? Under federal law, you typically draw the line at the use and posing of real kids.
Depending on how you look at it, you may think that this opinion from credentialed expert Mr. Rasch, vindicates the opinion of the math aficionados who voted that the defendant did not violate the law. I think it's the other way around — the fact that this answer was correlated in the survey responses with mathematical ability, vindicates the opinion of Mr. Rasch.
-
Belkin's Amazon Rep Paying For Fake Online Reviews
remove office writes "I recently discovered that Belkin's lead online sales rep, Michael Bayard, has been secretly paying internet users to review his company's products favorably on Amazon.com and other websites like Newegg, whether or not they've ever used the devices. Bayard instructed the people he was paying to 'Write as if you own the product and are using it... Mark any other negative reviews as "not helpful" once you post yours.' Ironically, he was using Amazon's own Mechanical Turk service to hire his fraudsters. Did he honestly think he wouldn't get caught? Are Slashdotters aware of other examples of other such blatant astroturfing on behalf of a large tech company like Belkin?" -
Paying People to Argue With You
Bennett Haselton has written in with an essay on a strange experiment on-line. He starts When you first hear about Amazon.com's "Mechanical Turk" service, which allows "requesters" to pay "Turk workers" a few pennies to complete some task which is hard to automate but easy for humans, what's the first application that comes to your mind? The system has been discussed previously on Slashdot, but I'll bet a week's wages for a Mechanical Turk worker ($1.45, according to one of them) that I was the first person who used it to pay people to write rebuttals to one of my arguments. Keep reading unless you want to fight about it.The interesting result was that some of the rebuttals were quite insightful, and resulted in me making changes to the argument that I would make if I had to present it again. Judging by the literacy and intelligence of some of the respondents, most of them probably wouldn't need Mechanical Turk as a source of income, so I assume most of them fit the profile of this Salon.com writer and are doing it just for fun. Hell, you can find enough people on UseNet and Slashdot who will argue with you just for free.
But there were a few reasons I found this preferable to the conventional ways of gathering interesting rebuttals to your own reasoning. If you send out a sample argument to all of your e-mail buddies, you will probably get some useful replies, but they may start to think you're a little weird for asking them to evaluate your thought processes, especially if you do it over and over. Post an opinion on UseNet or Slashdot, and you may have to wade through a lot of crap to find the useful responses (while others may consider your post to be part of the crap that they have to wade through). And in both cases, there's the potential embarrassment of what you're asking for -- the risk of seeming so uncertain about your own opinions that you want other people to check your work for you. (I actually think that being uncertain about your own beliefs is a virtue, but it doesn't seem to be one that our culture prizes very highly.) Using Mechanical Turk addresses most of these problems; even though you're still admitting to total strangers that you might be wrong and asking them to shoot you down if they can, at least the evidence of your insecurity won't turn up when your next employer or Internet date does a Google search for your name. ("Damn it, I want a man who doesn't question his bumper stickers!")
So, while I didn't find it useful enough that I would run every opinion through the Mechanical Turk machinery to see what feedback I could get from it (I'm not paying a bunch of them to proofread this article), I did like enough to recommend it to people for certain arguments in certain settings. The main kinds of arguments that I would try out on the Mechanical Turk service would be about abstract philosophical or moral questions on issues that have been around forever, like abortion or the death penalty -- topics so explosive that you'd risk making your friends very uncomfortable if you test-marketed your arguments on them, and which would seem almost rude to post about in a public forum because the debate topics have been around for so very, very long. But on Mechanical Turk, $1 is apparently enough to get people to ignore the awkwardness and the exhaustedness of the topic and to focus on what you ask.
And what was the argument that I used to test it out? Perhaps the geek crowd will feel more sympathy with this than the general public does. Basically it was that the conventional wisdom behind allowing adults to smoke, but banning cigarettes for people under 18, is wrong. Either you can believe that smoking should be permitted for everybody, or that it should be banned for everybody, but there is no consistent set of assumptions that could lead you to conclude that smoking should be banned for people under 18 but allowed for everyone else. You have two groups of people under consideration -- people under 18 who smoke, and people over 18 who smoke. What possible reason could there be for wanting to protect the health of the people in the first group, but not the people in the second group?
The problem with the conventional reason for smoking age restrictions -- "Younger people have worse judgment, so they are more likely to smoke" -- is that if this is true, all that means is that the first group of people will be proportionally larger, relative to the total population of people in their age range. But even after that assumption, you're still left with two groups of people, who exhibit the same continued bad judgment with regard to smoking cigarettes. Treating the two groups differently, is a bit like saying we should have lighter sentences for female murderers than for male murderers, just because men are more likely to commit murder.
And yet this conclusion did give me pause, so this is a classic example of an argument where you'd want someone to check your work. Off I went to create a Human Intelligence Task (HIT) on Mechanical Turk simply asking people to read the argument and respond. In the first round, most responders missed what I thought was the point of the argument, and responded with some variation of "Minors are more likely to smoke because they have worse judgment", without addressing the question of why the two groups of smokers should be treated differently. A few people responded with variations of "We've always done it that way" (referring to similar restrictions on alcohol, pornography, etc.); fair enough, it just reminded me that if I asked the question again I'd have to say I didn't consider any argument valid that boiled down to "We've always done it that way".
But then came some more interesting responses. One worker replied that I was wrong to assume that the effects of a cigarette were "the same" on adults and minors because cigarette smoke has been shown to be more damaging to developing tissues. OK, that was worth a dollar. On the other hand, that just means that there is some number N cigarettes that would be just as harmful to an adult, as 1 cigarette would be to a minor, so you're still left without a consistent reason for why you'd let the adult buy those N cigarettes but prevent the minor from buying 1 cigarette. Then another user called me out on the opening line of my original argument, "There is no reason to ban cigarettes for minors but not for adults." He said, quite correctly, that I had only attempted to debunk the most commonly given reason, but it was wrong to conclude that there was no such reason.
So, this led me to another idea for how to present an argument and solicit feedback on Mechanical Turk: in the form of a series of mathematically precise statements, each one following from the previous ones. The new HIT was to ask users if they disagreed with the conclusion, and if they disagreed, then to identify the first statement that they disagreed with. The idea was that each statement would follow logically from the ones before it, so identifying any statement as the "first" one that they disagreed with, would be tantamount to a self-contradictory paradox.
Now, whether or not you want to use this format when running an argument past the Turk workers, depends on what your goal is. If you want to really find out if your own argument is valid, then breaking it down mathematically is one approach. On the other hand, if you already believe your own argument, and you're just trying to find the most persuasive way of phrasing it, then you may not learn anything useful by breaking it down into a series of mathematical steps, because that's probably not going to be the format of our final persuasive essay.
Anyway, the new mathematical format of the argument was (slightly reworked from what I posted on Amazon):
- Government should ban smoking by people under 18, because of the harmful health effects.
- If that's true for the entire group of underage smokers, then it's also true for each individual smoker under 18. In other words, even if only one person under 18 smoked in the entire country, it would still be justified for the government to ban them from smoking.
- Whatever bad health effects are caused by the average person under 18 smoking 1 cigarette, there is some number N cigarettes that would cause the same bad health effects in the average adult who smoked them.
- If banning 1 person under 18 from smoking 1 cigarette is justified (even if they were the last smoker on Earth), and the health effects would be the same for an average adult who smoked N cigarettes, then banning 1 adult from smoking those N cigarettes would also be justified (again, even if they were the last smoker on Earth).
- If banning 1 person over 18 from smoking would be justified, then the same logic would apply to every person over 18, which would imply banning smoking for all people over 18.
- Hence, if you believe that smoking should be banned for people under 18, then the same logic would lead to a ban on smoking for people over 18 as well.
The response from a lot of workers who responded to this HIT was that... I lost them. Each of them identified the first statement in the list that they disagreed with, as required by the HIT, but many commented that the whole thing was phrased confusingly. There was no clear winner for the first statement that people disagreed with, but several people picked #3 and #4, arguing some version of "People under 18 have less developed judgment." (I still say that doesn't matter, because you're talking about comparing a person under 18 who smokes, with a person over 18 who smokes, and their judgment in both cases is the same, etc.) So this particular experiment failed -- it didn't make it easier to persuade people by formulating the argument as a series of steps, and it also didn't lead to any agreement on what was the Achilles' Heel of the argument itself.
However I think the general idea, of using Mechanical Turk to find sparring partners, may be useful to a lot of people. If you were interested in publishing some kind of persuasive argument, you could use an Amazon HIT to have readers compare several different versions of the same argument and identify the one that they thought was most convincing. If you were feeling more philosophical and simply wanted to know if your argument was correct, you could pay people to look for flaws in it (and here is where the mathematical phrasing could come in handy). If you're crafting an argument for public consumption, you could even have HIT workers build up your argument for you -- start with a position and have them come up with reasons supporting that position -- although to me that feels like a cheapening of the debate process that crosses the line, because you're not even trying to reason your way to a conclusion, instead starting with the conclusion you want and then working backwards (not that this isn't what a lot of debaters do anyway!). My own interest would be to see next if certain types of arguments are more likely to persuade people who are more mathematically inclined (by asking respondents to indicate how well they did at math in school). Perhaps arguments with flowery language are more likely to appeal to people who were English majors, while arguments spelled out as a series of logical steps are more likely to appeal to people who look at things in a mathematical way (also known as the "real" or "right" way of looking at things).
Maybe my preference for the controlled, user-reimbursed process of "debating" that is enabled by Mechanical Turk, has to do with a lifelong focus on bottom-line results: Decide what the result is, and judge the process by how well it brings about that result. I don't think debate and discussion should be like soccer, valued for the fun and the exercise; I think a good debate should actually get somewhere, persuading the participants or the listeners of a new point of view that builds on their old one, or else the debate has failed. If paying HIT workers kills the "spirit" of a good debate but helps achieve the goal, then so much the better. On the other hand, we'll never run out of people who enjoy the process of debating and arguing for its own sake, and will continue to debate things into the ground without anybody paying them. Hey look, here come some of them now!...
-
Help Find Steve Fossett
An anonymous reader invites us to join in the hunt for the missing Steve Fossett using Amazon's Mechanical Turk. DigitalGlobe, one of Google's imaging partners, has acquired new high-resolution satellite imagery of the area where Fossett disappeared on Monday. The public can now go through this imagery and quickly flag any images that might contain Fossett's plane. Flagged images will receive further review by search and rescue experts. -
Citizen Journalism Expert Jay Rosen Answers Your Questions
We posted Jay Rosen's Call for Questions on September 25. Here are his answers, into which he's obviously put plenty of time and thought. This is a "must read" for anyone interested in the growing "citizen journalism" movement either as a writer/editor or as an audience member -- and please note that Rosen and many others say, over and over, that one of the major shifts in the news media, especially online, is that there is no longer any need to be one or the other instead of both.
1) Where do you see newspapers' role in this?
by Stick_Fig
First off, my credentials: I'm the former employee of an experimental newspaper, Bluffton Today, located in Bluffton, South Carolina. It's an exciting place, let me tell you. The focus has been on reverse publishing but at the same time tempering blogs with traditional journalism. The staff still writes articles; they still edit heavily. They use the web only to the degree where it doesn't dip into libel and slander and builds on its strengths. My question to you is, do you think Bluffton is on the right track? It felt like, in the 15 months I was there, they definitely were, but I'm a biased party. I left thinking, "If only newspapers did more of this..." I know what I'm betting the farm on in my career, and it isn't tired, boring, traditional journalism. It isn't the straight and narrow of blogs, either. Rather, I feel that it's important to look at both sides and find how they can work together, because God knows there's some 60-year-old editor somewhere who won't look at Bluffton as anything more than a gimmick. I'm gonna be that guy in the newsroom fighting the good fight to get more untraditional voices into the the paper in more places than the editorial page.
Rosen:
Bluffton Today (Bluffton, SC is near Hilton Head Island) did several things that were important to try in 2005. They said the editorial engine would be the online edition; it would "produce" the printed paper. This is the opposite of how newspapers did things for the first ten years of their Web lives. They just re-purposed the content from the print edition, and called that an "online newspaper."
By reversing what's primary in production you change head sets in the newsroom because a professional newsroom engineers everything--including the talents of its employees--around the production ordeal. The "daily miracle" it was once called, because making the newspaper required such a fantastic act of just-in-time coordination. Many things had to be routinized for the miracle to occur. (Including ideas about journalism and the user's place in it.)
Steve Yelvington of Morris Digital Works, who worked on the Bluffton Today site, called it an "inversion" because content would flow from the Web to print rather than vice versa. The editorial engine should be the more interactive one, in which more of the community can participate. The goal was a virtuous circle. "Community conversation feeds professional journalism. Journalism feeds conversation. And around, and around." I think there is something to that idea.
How well it works is for people in Bluffton to address. I like that Bluffton Today tried to go Lessig on the news industry. It ditched the read only platform and re-built on read/write. Yelvington said at the launch: "Everyone gets a blog. Not just staffers, but everyone in the community. LeMonde (France) and the Mail and Guardian (South Africa) are doing this, too." Giving everyone a blog may be an obvious idea. But it's a different track. "Everyone gets a photo gallery. Everyone can contribute events to a shared public community calendar...." The site was built on Drupal technology. It had free classifieds. It was different.
If the experience of doing Bluffton Today has tempered some of that initial boldness, that's as it should be. I'm not surprised that the staff still writes articles; they still edit heavily. A web-to-print, highly-interactive, low barrier to entry, read-write, everyone-contributes newspaper is still a daily production headache. Articles, photos, headlines, and ads have to come together. Unedited, the site would have almost no value, although it can have unedited parts with high value.
"It isn't tired, boring, traditional journalism. It isn't the straight and narrow of blogs, either. It's important to look at both sides..." I agree with that, Stick. My new adventure, NewAssignment.Net, is a hybrid site for that reason. (Pros and amateurs collaborate on reporting projects.) In January of 2005 I wrote Bloggers vs. Journalists is Over for the same reason.
Bluffton today was a first wave attempt at innovation. Today initiatives like that face some second wave facts. Bringing capacity online does not itself create activity, so if you're counting on user activity, you better come with more than nifty new capacity. Create more writers and suddenly you may need more editors. "The conversation feeds journalism, journalism feeds the conversation" is a powerful idea, but we are several steps away from knowing how it works to create a live, intelligent filter in the newsroom.
There's just a long way to go. But yeah, you were on the right track working for those guys. Deeply so.
2) How to Get More Respect
by NewYorkCountryLawyer
I am convinced that online media have made a huge contribution to getting out the truth when the corporate media are seeking to suppress the truth. While there are a growing number of people aware of this phenomenon, reports in the 'blogosphere' just do not get the same respect and currency received by reports in the 'major' or 'corporate' media. What do we, as a community, need to do to enhance the respect internet journalists receive in the world at large?
Rosen:
Well, "suppressing" the truth is not how I see the failures of modern journalism, or of our current press. I think it's bigger than that.
Bob Woodward, who is in the news this week, is at the top of the reporting game, an industry unto himself. In two books, Bush at War and Plan of Attack, he failed to tell the truth about the Bush White House because his methods were not up to the obstacle they met: an administration that had broken through all the reality checks normally placed on a president and his closest aides. One by one these measures came under abnormal stress. The policy-making process used by presidents got subverted. The normal channels for sounding out opinion were just disowned. The intelligence community came under extreme stress when asked to supply facts for a decision already made.
A Congress controlled by the same party was expected to go along, which meant accepting the president's definition of reality. Oversight got evacuated. The normal tensions with the press were driven deeper: keep them back, keep them out, tell them nothing, tear them down. If someone does break a story from inside you immediately punish and isolate anyone who spoke to the reporter. You make them disown their words. You make them repent.
This is the story Woodward missed because he got inside it, so to speak. Ron Suskind, one of the few in Washington who did not miss that story, called it "the retreat from empiricism." To me, it's the big narrative yet to come out about the Bush White House. Attack Without a Plan was too crazy to be credible to Woodward. So he wrote Plan of Attack instead. I haven't read his new book yet, just the reviews and excerpts. But from early accounts, State of Denial is his attempt to get back the ground he lost, despite having the best access.
Woodward didn't "suppress" the story. Rather, he couldn't imagine it. Those are the kinds of failures that interest me. Sometimes things are suppressed. Often, the truth eludes professional journalism because no one thought to look for it. I welcome your question, What do we, as a community, need to do to enhance the respect internet journalists receive in the world at large? My first answer is: we have to look for it.
You know how, when you've really mastered something and there's a news account of it, the news story will invariable get several (basic) things wrong? Eliminate the several things and respect will rise. If you want to inform the world of something, grok it before you rock it is a good simple rule.
Correct ourselves early and often. Correct the reporting in the major media, early and often. Fact check your own ass first, then your neighbor's. We should major in transparency; the "major" media will take a minor in that. Diversity of outlook in the reporters ultimately improves the reporting. The blogosphere has advantages there, especially as it does more reporting.
I think we have to accept that Big Media, which isn't going anywhere, is society's default legitimacy-distribution machine. But that doesn't mean it works well. The machine itself can lose legitimacy without exactly falling apart. If you're an upstart publisher of news and you suck at it, Big Media will try to ignore you. If you're an upstart publisher of news and you're really good at it, Big Media will try to ignore you. Then when you assume the shape of a writes-itself story--first bloggers to go to the political conventions!--Big Media will over-cover you, spreading a small bit of understanding over lots and lots of stories. Six months later it's time to debunk the trend they missed, then over-hyped and finally misdescribed. It's not personal. It's protective. It's also cheaper than figuring out what's going on.
We can win a lot of points for Net journalism just by being the opposite of that.
3) What about mob-rule journalism?
by Chas
What sort of safeguards are in place to do fact-checking and prevent false/obviously slanted mob-rule style reports from being propagated as fact?
Rosen:
People hear phrases like "an experiment in open source reporting" and they see it immediately: What's open to the wisdom of the crowd is vulnerable to the actions of the mob. Wanting to be helpful, the volunteer may slant reports without realizing it. Through the portals marked "citizen," the paid operative can also go. How do you prevent all of that?
To me this is a puzzle with many pieces. It won't have one solution; it will take many overlapping systems working together. I can't tell you--yet--how we're going to build a fact-checking and verification system into NewAssignment.Net. But I can tell you that the site will fail without one, so we'll have to try to figure it out, with help from a lot of people. To simply pass along unchecked reports received from strangers over the Net would be fantastically dumb. To discount the possibility of people trying to game the system would be dumb, too; the more successful the site is, the more probable the gaming is. Not to mention spam, duplication, all kinds of junk.
What sort of safeguards are in place? Here are my answers so far. You tell me what is missing or cracked in this foundation:
One: The editors are full time on it. Assignments flow through editors several times before they are published by NewAssignment.Net. That's the pro-am way. It's an editor's job not to be gamed, not to publish bum facts. Everything that goes out has the editor's name on it. It's not an answer to everything--this reliance on "good editors"--but it's a proven system, a simple one, and a start.
Two: Users Self-Police. I'm not sure "community" is the right word for the eventual users of New Assignment. People use that term too loosely, in my opinion. But if NewAssignment.Net develops a base of active, loyal and intelligent users, it's not unreasonable that they can help police the site, especially if they understand that verifiying information and preventing fraud are basic to everything we're trying to do. And so a second answer, after editors, is a culture among users: catch errors, catch mistakes, catch fraud and manipulation. A mob mentality has to be met by something stronger; if you attract the right kind of users, that can happen. It would be foolish to think it will just because you're counting on it.
Three: Given enough eyeballs, all facts can be checked. I think there is every chance of developing a special subgroup of users who are effective fact checkers of the larger base of contributors, including new and casual contributors. One thing we are definitely going to do is see whether retired journalists and ex-journalists will volunteer to work with other natural born sticklers and operate our fact-checking system, which not only has to work, but eventually be better than industry standard. I don't know yet what that system will look like, or how systematic it will be. One of my advisers is interested in this puzzle and working on some ideas, assisted by a professional fact checker who emailed me offering to help. That's how we are going to solve this. Social scientists call it "muddling through."
Four: The site itself has to make verification easy. I mean in the way it is built and meant to operate. For example, editors have to be able to sort the raw from the initially verified from the double checked. This is one of the challenges for the developers of the New Assignment site, which will be Chapter Three. It's a new partnership--here's an about page for them--formed by Zack Rosen, who is my nephew, one of the originators of Dean Space and the co-founder of CivicSpace on the Drupal platform; and Josh Koenig, a co-founder of DeanSpace who started Music for America, a non-profit. They are both Drupal developers, active in that community. The third partner is Matt Cheney, who is trained as a librarian and worked as a researcher at National Center for SuperComputing Applications.
They're going to build the site with open source tools. Josh Koenig has a post up about the New Assignment project. It promises an Open Practice model: "posting tutorials, video screen casts, interviews, and write ups as our own work progresses and as we research others." Verification and fact-checking have to become open practices themselves. The developers understand that.
Five: The one percent rule.. Experience suggests a small slice of users will do most of the volunteer work. According to the one percent rule in social media, which is more of a tendency than a law, "if you get a group of 100 people online then one will create content, 10 will 'interact' with it (commenting or offering improvements) and the other 89 will just view it." This bears on the verification puzzle because we're not talking about "checking" vast hordes of people. If regular contributors provide most of the contributions, their reputations for reliability can accumulate at the site. In a well-designed system that will happen.
Six: How have others solved the problem? You tell me: has creating a reliable system of volunteer contributors ever been faced before on the Web? Did it prove unsolvable? I would expect NewAssignment.Net to look at prior cases first and find the key lessons.
4) Money
by truthsearch
Do you believe that as money flows into civic journalism that it'll change the equation? Obviously there are some people who's primary goal is to become famous and/or make money through more open journalism. Will the large community of contributors flush out those with less altruistic intentions? I guess I'm really asking will civic journalism be self-correcting as it gets bigger? Or is there a way it may become just as corrupted as much of the current mainstream professional journalism?
Rosen:
I doubt there's any incorruptible system, just different kinds of pressures, with greater and lesser freedoms for the journalists involved. We can certainly hope for a self-correcting system, but it's not likely to happen on its own.
There's nothing wrong with seeking recognition for great work. People who want to be become famous or make a salary through the more open forms in Net journalism aren't the enemy. Not at all. But they are going to have to work with users under conditions that build trust and permit collaboration. It's hard for me to see how the bad actors will succeed at that, but I am not discounting it, either.
Here's a site called Sportingo. It says it's a "new type of sports media company," which is "focused on telling the story from the fans' perspective." Users can write articles, which will be "professionally edited." They can rate and comment on articles written by peers.
Sportingo will own all the content published on the site. There are no plans to pay contributors. The company is for-profit. Tal Rozow, the marketing manager, told me that that "Sportingo authors aiming for a professional writing career will be able to benefit from having by-lines appearing on our website." He said he's confident that a strong network of independent sports writers will emerge at the site, and maybe that will happen. But I'm not sure it's a system designed to build trust among all the players involved.
Everyone I have consulted about open source projects of any kind has stressed one thing over and over: the importance of understanding what would motivate people to contribute to the gift economy of the project. You have to get that right, they say. Ultimately I believe a non-profit foundation is a more secure one. If there are profits and they are extracted by the owners, not distributed to co-creators; that's a problem. If there are profits and they go into doing more and better journalism, that's different.
5) What's wrong with other extant examples?
by crush
I'm assuming that you evaluated and rejected some of the other high-profile citizen journalism outfits that predate the founding of your own project. Off my head I can think of:
* The Indymedia network is one of the longest standing examples of an attempt to have a large citizen journalist network.
* The Pacifica Network (especially the Democracy Now show)
* The New Standard
What was it that you found lacking in the above and why did you decide to start a new project instead of reforming and adapting one of the above? Do you think that your decision to accept corporate sponsorship (which is rejected by the Pacifica Network) will see your organization's focus inevitably drift toward the anodyne ineffectiveness of e.g. NPR?
(And of course, how could I forget WikiNews?)
Rosen:
There's nothing "wrong" with these prior examples. I admire them all. I was especially pleased to see that the New Standard met its do-or-die fundraising goal last week. That site is an experiment with reader-supported, totally independent, strenuously-factual reporting. High standards of verification are meant to prevail. I think the New Standard has a lot in common with professional journalism, except it rejects the political economy of commercial news media entirely. It's run as a collective among those who do the work. I am thrilled that it will remain around, because we need to try lots of solutions to how to fund serious reporting. Just as I'm thrilled that Independent Media Center and its collectives around the world keep humming. I agree with Chris Anderson that what blogging begat--citizen journalism--Indy Media begat, too.
I didn't "evaluate and reject" the New Standard, Indy Media, Pacifica and Wiki News. Nor is it my place to decide they need fixing. They don't. The people who founded those organizations deserve a lot of credit for creating something new and daring-- and genuinely alternative. They inspired me. So did lots of others. (New West, for example, or Witness.org.) NewAssignment.Net is really about a single proposition: that if journalists and networks of users can report stuff together that neither could easily do alone, the public sphere will benefit and the site will build trust. I think there's room for that.
My decision to accept $100,000 from Reuters means we'll have an editor who can test the possibilities in networked journalism, as Jeff Jarvis calls it. My job is to make sure that Reuters has no influence on that person. The company has said it will have no editorial control, and no claim on the content. I agree: it won't. I think we can persuade users that it works as advertised. But people are free to draw their own conclusions about what the gift means, and I'm sure they will.
6) Plagiarism and Ethics?
by goombah99
Lately there's been a few incidents of Plagiarism in the news, not to mention some wholesale ethical breaches of faked stories (e.g. Blair at the NY times and "a million Little pieces"). But the thing is, the reason those are news is that they are both exceptional and something that is specifically drummed in to any professional journalist not to do. Indeed, breaking this taboo is probably even more of a sin to the the fellow journalists than to the general public because of this entrenched ethic.
Yet we know that on college campuses, where we can measure the phenomenon, plagiarism is comparatively rampant. So evidently the common man cannot restrain himself.
It seems to me this is a serious issue for any new journalism form with a low barrier to entry and a high degree of anonymity for the author. How does this ethos get enforced in such a realm?
A related question is the ethical division of commentary and news. We know that's become a problem in the media for some outlets where management has a thumb on the content. But the traditional news organs, especially newspapers, still refrain for the most part. Indeed, the NY times just went so far as to remove the typeset justification from any article that contained any sort of analysis or opinion, reserving the justified typesetting for only traditional factual journalism stories so the difference is apparent to the reader from the start. How do we reinforce that ethos in the untrained journalist?
Rosen:
When people plagiarize they do it for a particular self-interested reason: to meet a deadline, get an unwanted task out of the way, get their full time salary with limited work. These motivations will probably be rarer in the New Assignment model. Why volunteer for a project only to cheat at it?
"The common man cannot restrain himself." Sorry, I don't trust that kind of language. Beyond that making stuff up is not a way to develop a base of users on the Web; people aren't that dumb! You speak of a "low barrier to entry and a high degree of anonymity for the author." But for most users the higher the anonymity factor for the author, the higher the barrier of trust.
What some people can't seem to get over is that other people can say any damn thing they want on the Internet! How can you trust any of it? is their natural reaction to all open systems. Closed systems--and professional journalism is one--develop trust in one way. Open systems have to do it a much different way. Expecting one to look like the other is unreasonable.
We aren't going to learn much about this puzzle by asking how the "common man" can be trained to imitate his betters in the news media. I refer you to sociologist Raymond Williams, who once said, "There are no masses, there are only ways of seeing people as masses." It is these ways of seeing that are retrograde. But they show up in the most surprising places.
7) Scale
by FuturePastNow
First, I'll admit that I haven't read much about citizen journalism other than Jeff Jarvis' [buzzmachine.com], but as a non-blogger thinking of getting in to it, I was wondering:
Much of the discussion seems to be about getting out from under the control of "gatekeepers" like publishers and media owners. Yet, while the internet is less concerned with money, it has its own form of currency: popularity, in the form of the link.
Doesn't this just turn the highest-traffic sites into new gatekeepers? Especially as the number of blogs increases, the gap between "rich" and "poor" expands?
I suppose what I'm really asking is, it's hard enough to get noticed today- how will someone just starting out get noticed ten years from now?
Rosen:
Ten years from now? Jeez, I have no idea what the world of media access will be like then. But anyone who is just starting out in self-publishing should consult Clay Shirky's Power Laws, Weblogs, and Inequality, so as not to become prematurely disillusioned by discovering its truths later on.
Certainly there are new gatekeepers. (Slashdot itself is one. But does it work the same way the old system did?) Traffic-wise, there's still rich and poor. (But is this list as static as that one?) Hierarchies have not gone away. (And who said they would?) Inequality has not disappeared. (But did you really think it could?)
You still have to fight to be noticed, good work can still go unnoticed. Life online is not entirely fair, or completely different. There's a new attention economy to replace the old. The sooner we reconcile ourselves to these common sense conclusions, the easier it will be to see what is actually different today.
Here are some things that stand out for me: Amateurs have joined professionals and they own a part of "the press." An audience that was once connected "up" to Big Media but not across to each other is now connected both ways. The cost for like-minded people to locate each other and collaborate has fallen dramatically. The tools of media production have been widely distributed, and broad distribution of content is no longer impossible for small, upstart producers. For professionals, they're not required to affiliate with Big Media in order to operate as a journalist, though most will. They can be stand alones and independents. The people formerly known as the audience (as I call them) are now a productive force to be reckoned with, and Big Media has just started that reckoning. The Net has new ways of distributing attention, which have taken their place alongside the old.
Still, there's a long way to go before we can say that our media system has been made more democratic, responsive and responsible.
8) What impact would this have on national elections?
by StressGuy
The Electoral process seems to be more of a "marketing contest" and marketing takes bags and bags of money. There's commercial time, signs, billboards, radio, etc. Let's face it, a commercial is, at most 90 seconds to tell me why I should vote for you - hardly enough time. So, all we see are glittering generalities or, all to often, "don't vote for the other guy" spots.
If "Citizen Journalism" takes off, do you see this as a way that candidates without the massive financial resources normally required to sustain a traditional campaign could actually compete? Could this make the "third party candidates" a credible threat? Could this actually serve to "level the playing field"?
Rosen:
We should be cautious here. I think the most we can say is that a system that was almost entirely closed and self-sustaining--in which a handful of people raised the money, took the polls, handled the candidates, made the ads, narrated the campaign and talked about the candidates on TV--has been disrupted. The people who ran it are not as confident as they once were in their ability to manage things and get the outcomes they want. Their party has been crashed, but it's not "over." Nor is it "ours."
It's possible that insurgent candidacies--not backed by current players in the system--will have an easier time of it in the years ahead, just as insurgent news providers have more of an opening now. That's as far as I would go on the leveled field.
9) Dilution of Protection
by ObsessiveMathsFreak
How long before corporations and wealthy individuals start employing goons, lawyers and wiretaps, a la HP, to threaten and intimidate citizen journalists with no real legal recourse? If faced with this, should a citizen journalist just back off and let the guilty win? How can the protections now enjoyed by the fourth estate be extended to citizen journalism without diluting them?
Rosen:
As a matter of law and public policy, I think "fourth estate" protections should focus on significant acts of journalism, not people in pre-fab categories or the kind of organization that surrounds the giver of news. All those who are engaged in the act of informing a broader public of what's going on deserve to be under the First Amendment umbrella that protects the press. The press itself is composed of amateur and professional wings.
But that's no answer to goons with lawyers who threaten to sue. Citizen journalists are definitely vulnerable there, which makes you realize why we have big media organizations in the first place. We have to be more creative. Robert Cox, head of the Media Bloggers Association (I am a founding member of the group) has shown that "an orchestrated campaign by bloggers to defend a fellow blogger in what appears to be a frivolous lawsuit" can work. That's encouraging but not a complete answer, either. Legal intimidation will happen, and I'm sure there will be times when the bad guys will win.
10) Blogging
by From A Far Away Land
When asking a primary source for information, I find that telling them I'm doing so to create a report on my blog tends to make them clam up, or continue to be unwilling to provide information that ought to be publicly available. What technique or phrases should I use to convince the interviewee that I both have a legitimate use for their information, and the right to obtain it?
Rosen:
Sometimes you have a right to obtain information from a primary source. Sometimes it's not a matter of your rights but their decision to recognize you and cooperate. If search costs are high for making an informed decision about whether to trust a blogger who shows up with questions, sources will seek to reduce costs by using reputation and even stereotype (bloggers: ugh) as proxies.
I don't think there's a proper technique or a magic phrase that will solve this problem. There's only one solution I can see. Send the guy the URL for the "about" section of your site. That page ought to persuade potential sources that legitimate use will be made of their information. It should tell them what you are up to, and why. The site itself, the reporting and commentary there, is the best reason any source has to cooperate. Ah, but how do you convince them to take the time and look?
There's at least one way. Break a story so that the source's world is talking about it and next time around the source will speak to you-- and go to your About page. I asked Dean Wright of Reuters what the biggest obstacle for NewAssignment.Net will be when it launches. "The same one that the more minor players in the mainstream media have: getting your calls returned," he said. "Then when you complete a project and publish, you may find that other media outlets are reluctant to pick up your stories." The only answer to that is "do some compelling projects that cannot be ignored."
NewAssignment.Net will try to take that advice. It will do stories developed by users into assignments that are given to journalists. It could also do stories developed by journalists and divided into parts for users to assign themselves. (Mechanical Turk meets the Center for Public Integrity.) I hope it will do stories where teams of users and journalists figure out the division of labor together.
Sometimes the network will be the knowledge producer, the journalist the enabler. Other times the journalist will be the producer, and the network the enabler. Pro-am journalism is not inherently better than am-pro. Amateur users could in some cases do it all themselves, with editors watching and giving the green light in stages. Different combinations beg to be tried. It's unwise to say in advance that we know how it will work, or that it can't. -
Amazon's Mechanical Turk
rscoggin writes "Amazon.com has a new program that wants you to 'Complete simple tasks that people do better than computers. And, get paid for it.' (example: 'Is there a pizza parlour in this photograph?'). For each task you complete you get a small payment, usually ranging from a few cents to a little under a dollar. It's named the Amazon Mechanical Turk after a famous hoax from the 19th century. Kill time and get paid in tiny increments to boot!" Similar to Google Answers, there seems to be a reliability ratings system and some incentives. -
Amazon's Mechanical Turk
rscoggin writes "Amazon.com has a new program that wants you to 'Complete simple tasks that people do better than computers. And, get paid for it.' (example: 'Is there a pizza parlour in this photograph?'). For each task you complete you get a small payment, usually ranging from a few cents to a little under a dollar. It's named the Amazon Mechanical Turk after a famous hoax from the 19th century. Kill time and get paid in tiny increments to boot!" Similar to Google Answers, there seems to be a reliability ratings system and some incentives.
{kind=link}
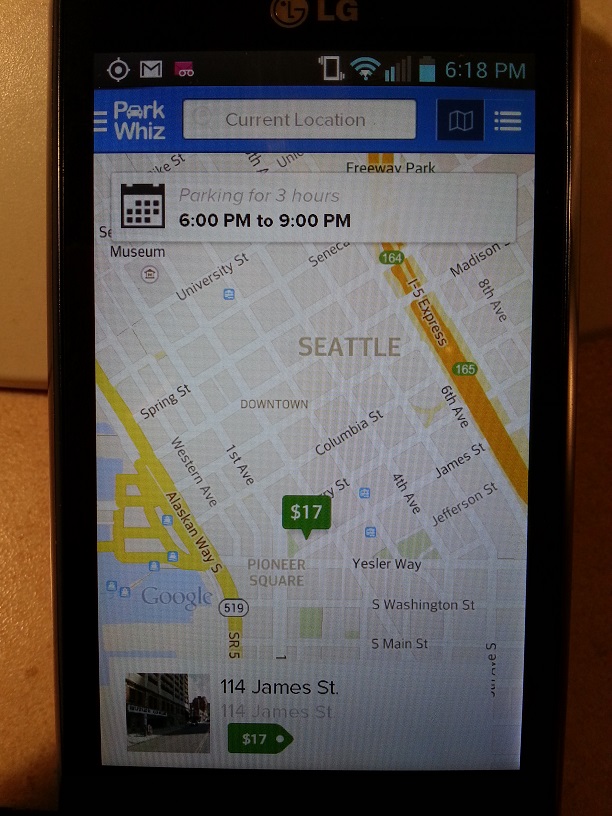{kind=link}