 Slashdot Mirror
Slashdot Mirror
Domain: usenix.org
Stories and comments across the archive that link to usenix.org.
Comments · 571
-
Data Remanence in Semiconductor Devices
-
Exactly the kind of articles IT people DON'T need
The people who write these articles are stupid and contribute stupidity to IT in general.
1) Apple calls these beefier models "server-class" drives; you may also see terms like "RAID edition"
There is simply no data to back this up. The vendors themselves do NOT do sufficient testing to make these claims ergo Apple can not make these claims. This parallels the so-called better failure rates of SCSI/FC 'enterprise' drives and consumer SATA drives. In the FAST paper by Schroeder we see the following quote.
". . . we observe little difference in replacement rates between SCSI, FC and SATA drives, . . .
2) Firmware - the closest thing to an argument here is "may prevent Server Monitor from being able to report on the drive's health"
3) Carrier - "Apple also told me that the rubber grommets that hold the drive to the ADM carrier are chosen specifically to match each drive's vibrational characteristics."
This leaves out the most important thing. "So what" - ok if the drives vibrational characteristics are not matched what happens. Is it significant? Where is the data to say so?
4) Extensive testing - Essentially arguing that Apple does burn-in testing (which you could easily do yourself) however...again from the FAST paper:
"Contrary to common and proposed models, hard drive replacement rates do not enter steady state after the first year of operation. Instead replacement rates seem to steadily increase over time."
Drives act like mechanical devices NOT electronic devices.
In general - have you EVER read an article with so many "may"'s and "possibly"'s? There's very little here that could be risk assessed (giving some kind of probability of some consequence) - which means it USELESS as advice. The parts that actually IMPLY some kind of probability/consequence are not well supported by the studies with the largest sample sizes.
-
Re:Here we go again
Here is the original study: http://www.usenix.org/events/fast07/tech/schroeder/schroeder_html/index.html I can see why the DailyTech link I sent you might have been confusing.
-
Re:NX and ASLR
Both NX flag and ASLR are present Leopard. For a number of compatibility reasons they are not implemented as extensively as they are on other systems, but it's disingenuous to say Mac OS X doesn't have them.
If you go look at Jordan Hubbard's From the Server Room to Your Pocket presentation:
http://www.usenix.org/event/lisa08/tech/hubbard_talk.pdf
or listen to it:
http://www.usenix.org/media/events/lisa08/tech/mp3/hubbard.mp3
you'd realize that Charlie Miller is milking his 15 min of fame for all they are worth with his incendiary comments - basically trolling for publicity. -
Re:NX and ASLR
Both NX flag and ASLR are present Leopard. For a number of compatibility reasons they are not implemented as extensively as they are on other systems, but it's disingenuous to say Mac OS X doesn't have them.
If you go look at Jordan Hubbard's From the Server Room to Your Pocket presentation:
http://www.usenix.org/event/lisa08/tech/hubbard_talk.pdf
or listen to it:
http://www.usenix.org/media/events/lisa08/tech/mp3/hubbard.mp3
you'd realize that Charlie Miller is milking his 15 min of fame for all they are worth with his incendiary comments - basically trolling for publicity. -
Don't bet you won't get two drives failing...Why RAID 5 stops working in 2009.
Also after a disk failure, there is significant correlation of a second failure (failures are not independent - some risk analyses presume they are): Usenix: Disk failures in the real world.
Also I wouldn't ignore anecdotes that the rebuild process thrashes disks hard and can cause a second failure (or that the rebuild can take longer than you thought).
-
Re:You can already do this ...
Sorry, you are totally wrong. The monolith kernel is not the operating system. Microkernel alone is not the operating system. Do not mistake different kernel structures to be same as "one kernel". or to be the operating system.
That is the whole problem on GNU/Linux vs Linux debate because people does not understand what an operating system does.
Linux is monolith kernel and not a complete operating system. GNU/Linux is an operating system. All GNU tools can not run without the kernel, think what is running them? And the kernel will not work without the GNU tools, think of it like a symbiotic relationship. Most applications needs other applications and system libraries to run, not just the operating system. But this is irrelevant, like the following links.
http://www.usenix.org/publications/login/2006-04/openpdfs/herder.pdf
http://www.topology.org/human/?a=/linux/lingl.htmlThe GNU/Linux is nothing more than due recognition for an equally important part of the operating system.
But hey! Why to call it GNU/Linux but not Linux/GNU/Apache/Xorg/KDE/Firefox/Javascript/Slashdot OS? Ok, I know this is one of the most stupid things written on Slashdot, obviously you don't need Apache for the computer to operate, but you do need the GNU tools.
Oh, and I believe your computers power supply is part of power lines and so on part of power plant and so on part of nuclear reactor or other nature... So lets call it GNU/Life because without Life you can not have GNU! Ha Ha! just being a knob.
The Operating System is very small part of software system. It just manages (controls) the hardware and gives those resources for applications and controls those applications so they can live together and is able to interact with the user, which is where the GNU tools come in.... It is not so simple thing as Linux kernel but GNU/Linux.
-
Re:You can already do this ...
Sorry, you are totally wrong. The monolith kernel is the operating system. Microkernel alone is not operating system. Do not mistake different kernel structures to be same as "one kernel".
That is the whole problem on GNU/Linux vs Linux debate because people does not understand monolith vs micro structure.
Linux is monolith kernel and complete operating system. GNU/Linux is development platform. All GNU tools can not run without operating system, think what is running them? And most applications needs other applications and system libraries to run, not just the operating system. But all these other softwares needs an operating system to work, unless you write them to work on pure hardware but then you can not use them on other computers because the OS is not there to hide the complexity of hardware.
http://www.usenix.org/publications/login/2006-04/openpdfs/herder.pdf
http://www.topology.org/human/?a=/linux/lingl.htmlThe GNU/Linux is nothing more than political with big ego.
But hey! Why to call it GNU/Linux but not Linux/GNU/Apache/Xorg/KDE/Firefox/Javascript/Slashdot OS?
Oh, and I believe your computers power supply is part of power lines and so on part of power plant and so on part of nuclear reactor or other nature... So lets call it GNU/Life because without Life you can not have GNU!
The Operating System is very small part of software system. It just manages (controls) the hardware and gives those resources for applications and controls those applications so they can live together... It is not GNU/Linux but so simple thing as Linux kernel.
-
origin of urban myth
The source of the claim seems Gutmann's 1996 article: http://www.usenix.org/publications/library/proceedings/sec96/full_papers/gutmann/index.html where he says: "Data overwritten once or twice may be recovered by subtracting what is expected to be read from a storage location from what is actually read. Data which is overwritten an arbitrarily large number of times can still be recovered provided that the new data isn't written to the same location as the original data (for magnetic media), or that the recovery attempt is carried out fairly soon after the new data was written (for RAM)." It was challenged already in 2003 http://www.nber.org/sys-admin/overwritten-data-guttman.html where Feenberg writes: "Surveying all the references, I conclude that Gutmann's claim belongs in the category of urban legend." As usual, this story shows that individual claims have to be checked by independent parties. Even the claim that it can not be done.
-
Windows Integrity Mechanism
One of the reasons is that they are using something called "Windows Integrity Mechanism".
See mention at page 3 here.
Then read about the integrity mechanism here.
-
Re:Dumb question...
Hmm, on second thought after doing some more research it MIGHT matter:
CRC is somewhat expensive. 200-300 MB/s on a modern CPU looking into ways to optimize
SSE4 will have a CRC instruction (any poly)
linky(pdf)
Not sure what he means by CPU there, if he means core then it's not so bad (other than freaking expensive per core Oracle licensing), if that's per processor then that's very bad. Guess I might only be able to implement this on the new Shanghai beast we got last week or a new Corei7 Xeon system we will probably get next year once they are available. -
Re:Solid State Disks...
The current issue does not involve "page faults" related to ram vs disk swapping.
It concerns "page faults" related to cpu instruction cache vs regular memory swaps, so this "page fault" term as utilized previously in this discussion thread is antiquated:
"The gap between processor and memory speed continues to present a major performance bottleneck. Applications spend much of their
time waiting because of cache and TLB misses. For example, on the Intel Itanium 2 processor, the SPEC JBB2000 1 server bench-mark spends 54% of its cycles waiting for memory. While the majority of stalls are from data access, instruction related misses such as instruction cache misses, ITLB misses, and branch mispredictions also contribute. Zorn [18] notes that Word XP, Excel Xp, and Internet Explorer have large code working sets, and that much of the latency users perceive is caused by page faults fetching code." -
Re:XFS
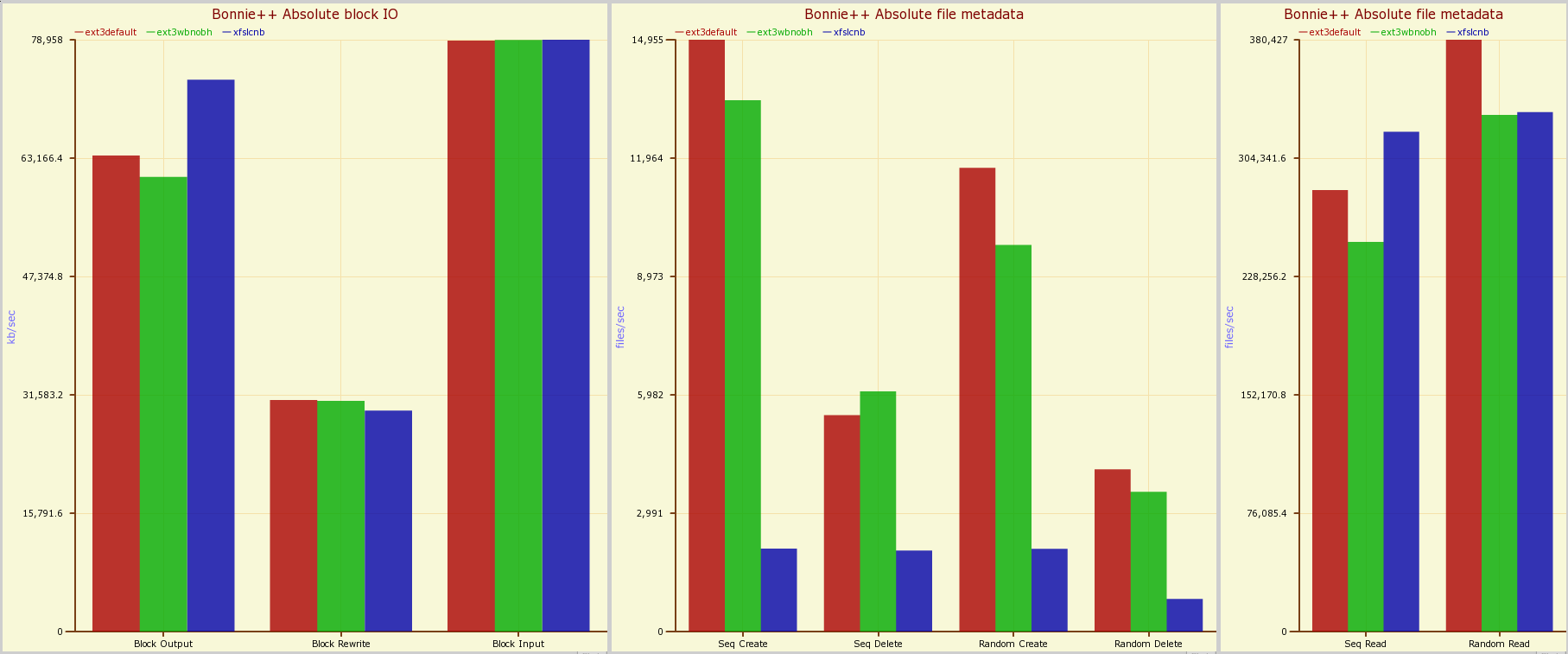
interesting. i'd never heard of these flash media filesystems before. i wonder how they compare to conventional filesystems, or why they weren't used in the Linux.com SSD benchmarks.
from these graphs it seems like ext3 performs quite well on SSD. but i can't find any benchmarks comparing any of the filesystems you listed. i did, however, come across this PDF released by Samsung, which shows some pretty interesting benchmark results for ext2, ext3, ext4, reiserfs, xfs, btrfs and nilfs. and in these tests nilfs comes out on top in almost all of the tests.
-
Re:still doing fs on top of RAID :-(
RAID is built on the assumption that any hard disk has checksumming built right in.
Too bad that assumption is wrong. Despite the ECC in disks, corruption still sneaks in.
http://www.usenix.org/event/fast08/tech/full_papers/bairavasundaram/bairavasundaram_html/index.html
To fix this you can use either ZFS-style integrated filesystem and RAID or 3Par/Xiotech/XIV-style chunk RAID with checksums and unmap bad parts of the disk.
-
Re:Not quite, but just as funny:
http://www.usenix.org/events/lisa00/gilfix.html
Won best paper award that year istr.
-
Malware will make this moot
Whether it be a rules designed to stop folks from stealing media, violating their monthly transfer cap, or even using a competitor's VoIP package, they are all susceptible to malware attacks. Given an interesting enough malware that doesn't seek to steal your data, but rather use you as a conduit, we all finally have plausible deniability.
Every time they get into this, there is an assumption that I am in complete control of my hardware and software. History has clearly shown that even with tightly-controlled systems, including those with TPM (Click to read about cracking TPM), a compromise is easy for a determined individual with even limited cracking skills. And what if there's malicious hardware (Click Here for PDF)? Anything can happen.
We may have the hardware sitting on our desk, but every security guy will tell you that physical access is everything. They'll probably try and turn my computer into a multitouch kiosk, but they'll leave a USB or serial port open on the back for bootstrapping. They may dumb computers down, but somebody has to be smart enough to build them, and some will be left to write malware that allows not so honest folk to channel their black market traffic through otherwise unsuspecting innocents who will take the fall for the infraction.
Do this a few times and courts around the globe will rule the laws an unenforcable leaving us with more trash computers and companies with too much power to see into our private lives, which is what this is partly about anyways.
Go ahead, Britain. Keep leading the way.
-
Re:Are you kidding?
The monolith kernel is the OS. Microkernel tries to make more stable OS by moving as much OS parts to userland as possible.
http://www.usenix.org/publications/login/2006-04/openpdfs/herder.pdf
http://www.amazon.com/gp/reader/0130313580/ref=sib_dp_pt/103-7158569-1619062#reader-link
Monolith kernel is the old way building a OS. Microkernel is the "new" way for building a OS.
But you might be those who believe that OS is that what has desktop, icons, wallpapers etc. And openoffice, Firefox and Gimp are parts of OS?
-
Re:Why not ZFS?
In btrfs, data structures have "back references", and the fsck can be used while the filesystem is mounted.
Welcome to the party!
Sincerely, FreeBSD 5.0 - 2001
-
Re:NetBSD?
NetBSD has a SYN cache instead of using SYN cookies to deal with SYN flood attacks. The difference may be enough to prevent the attack on the SYN cookie mechanism from working. The differences are discussed in this article, which I'll admit up front that I have not read.
-
old science
Reminds my of Brian Kernighan's 1995 Usenix Tcl/Tk conference paper, Experience with Tcl/Tk for Scientific and Engineering Visualization.
-
Re:How useful is DNSSEC w/o top-level signed?
I've been told that DNSSEC is basically just a proof of concept when it's done on a single TLD, not providing much real security. [...] If so, then when your ISP queries one of the thirteen root servers for the
That would be my exact understanding as well.
The details are these: Every node in the DNS tree has a key pair. Everybody knows the public key of the root. Every response to a request contains an answer, and a signature on that answer. As an additional request, you can ask for public keys too.
So, here's the scenario for going to whitehouse.gov, assuming full deployment of DNSSEC:
- Ask root for whitehouse.gov
- Receive IP of nameserver for
- Ask
- Receive IP of whitehouse.gov [check sig]. Also,
- Connect, now you know where to go
This secures step 4. Step 2 is still not secured. Paul Vixie has given some good talks on DNSSEC and everything else that's wrong with the interwebs
-
Re:Do many companies really do EFM recovery?
Well this article is a response to Gutmann's Usenix paper where apparently everyone got the idea that STM could be used in a cleanroom to get data off a drive that has been overwritten. The response is written by someone at the National Bureau of Economic Research so who knows what qualifies them to write about this, but if you read it he does seem to have done his homework. He claims that Gutmann's paper isn't true and it's evidence doesn't pan out. I'm not really qualified to tell and I'm not sure how much drive technology which you mention changes the issue from 1996 when Gutmann wrote his paper.
In any case this Bureau of economic research guy claims no one can do EFM recovery so that's his opinion on the title question above. And you and the GP post both make good points that this is certainly extreme paranoid level even if someone could do that type of recovery. You'd have to have some awfully important data to protect. So even though the contest is indeed a farce as others have pointed out, they do make a good point that dd'ing zeros is good enough for anything but extremely important data. -
Re:Woah
I strongly doubt they allocate that much space (as you claim) for spare sectors.
From what I see it's a small percentage - maybe at most thousands of spare sectors for hundreds of million sectors.
Just a google for complaints shows that people are already in serious trouble when their drive starts using hundreds of spare sectors.
Thus I think my current policy is safer.
As for SCSI vs SATA there is evidence that the failure rates are not significantly different (at least for recent drives):
http://labs.google.com/papers/disk_failures.html
http://www.usenix.org/events/fast07/tech/schroeder/schroeder_html/index.html
It'll be interesting if you have evidence that says otherwise.
-
Or DTS
Or given that TI is mentioned, maybe it's more likely to be about Rubin et.al's attack on TI's Digital Signature Transponder. See Security Analysis of a Cryptographically-Enabled RFID Device (paper) and/or article.
-
Article in latest ;login:
There was a very interesting research article about DenseAP, which tries to solve this problem, in the latest issue of
-
Re:Cyberparanoia
I know you're just trying to be funny, but allow me still to (hopefully) educate some of your readers.
If anyone was wiretapping and using reasonably well-designed equipment, you wouldn't hear clicks, since clicks can be avoided. I think "high-impedance circuitry" was the phrase used to justify that claim.
Also, if the wiretappers are playing by the rules, you can just press C on your phone (or play back two tones with the corresponding frequencies but less amplitude than your phone does) to shut down the recording equipment at the other end.
Source: Matt Blaze, http://www.usenix.org/events/lisa05/tech/mp3/blaze.mp3, http://www.usenix.org/events/lisa05/tech/.
Interesting to know, if you plan on being wiretapped. What's also interesting to know is that wiretapping equipment is (usually) illegal to posses, yet can be bought from law enforcement agencies on ebay
-
Re:Cyberparanoia
I know you're just trying to be funny, but allow me still to (hopefully) educate some of your readers.
If anyone was wiretapping and using reasonably well-designed equipment, you wouldn't hear clicks, since clicks can be avoided. I think "high-impedance circuitry" was the phrase used to justify that claim.
Also, if the wiretappers are playing by the rules, you can just press C on your phone (or play back two tones with the corresponding frequencies but less amplitude than your phone does) to shut down the recording equipment at the other end.
Source: Matt Blaze, http://www.usenix.org/events/lisa05/tech/mp3/blaze.mp3, http://www.usenix.org/events/lisa05/tech/.
Interesting to know, if you plan on being wiretapped. What's also interesting to know is that wiretapping equipment is (usually) illegal to posses, yet can be bought from law enforcement agencies on ebay
-
Re:I don't understand
Plus 14 bits of port number (i.e. where in the 48k-64k range it is)
Oops, yes. My bad. Sequentially incrementing port numbers != predictable starting port. To be fair it was early and I was hung over
and 32 bits of IP address. Really.
Think about it: if you have to guess at the transaction ID, that means that you are in a position where you can't see the stub resolver's queries, so you are also not seeing what IP those queries are being sent to or what source ports have been used.
The IP address might be guessable. If you're going to the effort of targeting stub resolvers in the first place, it might not be too much extra effort to whois the IP address and guess the names of the ISP's caching resolvers. (The only situation I can really see this sort of effort being worthwhile is where, say, a particular ISP habitually supplies a particular gateway device, which turns out to have NAT/firewall flaws allowing packet injection into the local network.)
With a recursive resolver using a single port, an attacker can discover and deduce everything but the transaction ID without doing anything but getting the target to resolve some names, while that is simply not the case with a stub resolver.
I'm still not convinced it's impossible, but I'm pretty sure it wouldn't be worth making the effort. There are almost certainly bigger issues.
Regarding DNS design: short of net-wide DNSSEC rollout (ha! We'll see IPv6 transition first..), a medium-term approach might be to start with the assumption that we can't be 100% sure that any individual answer is genuine, but that we can be pretty sure that a sequence of successful spoofing attempts is extremely unlikely. How do we re-engineer caching resolver behaviour (caches are the key target, because of the cascade effect of a successful poisoning on end users) to minimize the amount of trust we place in a single reply packet?
Paul Vixie made some suggestions back in '95 (see 7.2: "What We Would Like To Fix
I'll admit my grasp on this is a little fuzzy around the edges, I haven't had much experience with DNS guts in the past (I'm hoping Dan Kaminsky's explanation will include some analysis which might clear the waters for me.) The issue as far as I can see it is that the additional RRs, which were originally only needed to solve one specific problem (glue for zone delegation), have been used as a general mechanism to prime caches (e.g. when doing MX record lookups), and so nobody wants to tighten up the processing behaviour of the caching resolvers.
I don't know whether this sort of effort is worth it, a jump to DNSSEC might actually be simpler, and the source port randomization is a good fix for the moment. Network speeds will continue to get faster, however, and I'm sure some people will continue to put nameservers behind NATs that eliminate source port randomness. Also, flaws will presumably continue to be found in random number generators. A bit of further thought might be wise before the next issue crops up..
-
Re:vaporware
Sadly, the Berkeley DB authors are trying to do a similar stunt with a 'provenance aware' file system. (There's a Usenix paper on it at http://www.usenix.org/event/fast05/wips/slides/seltzer.pdf).
Fortunately, since Oracle bought SleepyCat software, Berkeley DB seems to be going the way of the Atari 2600.
-
Re:Here's the whole post
(BTW, feel free to drop this conversation if you're fed up with dealing with the hard of thinking and - by this time of the evening - slightly inebriated.)
Of course Mallory's response listed an A record for CXOPQ.VICTIM.COM
At this point, we should already be querying (what we think is) an authoritative server. If we're being returned an A record, and not an NS record, why would we process any glue? I thought Paul Vixie fixed this 13 years ago:
http://www.usenix.org/publications/library/proceedings/security95/full_papers/vixie.txt (see section 5.3, "Irrelevant Answers")
The A record returned wouldn't be authoritative, it'd be the same kind of answer that the DNS cache would receive from its parent DNS, or what the end-user's computer would receive from its DNS cache.
But at this point, we should be expecting an authoritative answer for CXOPQ.VICTIM.COM, or a referral with glue, but not a non NS record with glue, surely? Mallory's racing with the authoritative server for the domain we're trying to query..
If you went and asked the authority for confirmation for that address, then there's no reason for the DNS cache.
We're not talking about attacks on stub resolvers
Incidentally, assuming my understanding is close, even if section 5.3 of the Vixie paper hasn't been implemented sufficiently rigorously to prevent this attack (and obviously it hasn't, or there would be no panic), section 7.2 ("What we would like to do
-
Re:Most EPIC fail, Windows Vista?That is entirely correct. AESEC makes the claim that: "GEMSOS is the only general-purpose kernel in the world rated Class A1: Verified Protection by the National Security Agency."
The other place you want to check is the paper on security kernels. This describes how to reach A1 (CC7) without having to prove the entire OS.
-
or download the pdf
-
Re:Astro Turf
Doesn't Microsoft employ "bloggers" to seed pro MS babble to Web sites like Slashdot? Just sayin'...
If you're going to troll, it might be a good idea RTFA beforehand so that you don't make a fool of yourself. Two examples:
Erm, for the record they also cover applications created by MS Research, using MS technologies - e.g. one called MapCruncher, which runs/ran on IIS. See 5 Application Design and Flash Crowd Experiences. Another examples include SQL Server, but the article's pretty much technology agnostic, on the whole...
We were surprised that our web server had failed to keep up with the request stream until we realized the dataset was many times larger... The next day, we published our maps to Amazon S3, and had no further performance problems.
In all, a very interesting article. I didn't get much or any MS-centric chest-thumping from it.
-
Amen, brother...
Here are a few things that have helped me out:
- The big one: go to LISA. It can be tough convincing the boss to send their one-and-only IT guy, but it's an incredibly exciting environment. You'll learn lots, you'll meet lots, and you'll get to rub shoulders with people doing incredible things -- and people in the same boat you are.
- If you can't go to LISA, start reading their proceedings. They've just opened up everything to the public (previously you had to wait a year if you weren't a member), and there are some incredible gems to be found. The MP3s from LISA '07 weren't as good as being there would have been (sob), but they're still damned good.
- You should still get a membership in SAGE. Subscribe to the mailing lists,
get a subscription to
- Look around for professional organizations to join, or other
opportunities. There's a sysadmin group at the university where I
work; there's also a committee trying to figure out what the
university's IT strategy should be for the next 5-10 years. I've been
lucky enough to be involved with both, and they're interesting. Sure,
I run a small shop, but I've rubbed shoulders with (well, envied from
across the room
- Start your own techy/sysadmin conference, a la LUGRadio Live. No, LUGRadio Live isn't particularly sysadmin-oriented, but I have the strong impression that the organizers just decided they wanted to hold their own conference, and they did. And if you look at the schedule for their US conference, it's got a damned impressive list of presenters. (I'm considering starting a sysadmin conference next summer in Vancouver, BC...anyone interested?)
- Other sources of info: Planet Sysadmin (disclaimer: they've got my blog in there), ONLamp, and your local LUG.
Hope this helps!
-
Amen, brother...
Here are a few things that have helped me out:
- The big one: go to LISA. It can be tough convincing the boss to send their one-and-only IT guy, but it's an incredibly exciting environment. You'll learn lots, you'll meet lots, and you'll get to rub shoulders with people doing incredible things -- and people in the same boat you are.
- If you can't go to LISA, start reading their proceedings. They've just opened up everything to the public (previously you had to wait a year if you weren't a member), and there are some incredible gems to be found. The MP3s from LISA '07 weren't as good as being there would have been (sob), but they're still damned good.
- You should still get a membership in SAGE. Subscribe to the mailing lists,
get a subscription to
- Look around for professional organizations to join, or other
opportunities. There's a sysadmin group at the university where I
work; there's also a committee trying to figure out what the
university's IT strategy should be for the next 5-10 years. I've been
lucky enough to be involved with both, and they're interesting. Sure,
I run a small shop, but I've rubbed shoulders with (well, envied from
across the room
- Start your own techy/sysadmin conference, a la LUGRadio Live. No, LUGRadio Live isn't particularly sysadmin-oriented, but I have the strong impression that the organizers just decided they wanted to hold their own conference, and they did. And if you look at the schedule for their US conference, it's got a damned impressive list of presenters. (I'm considering starting a sysadmin conference next summer in Vancouver, BC...anyone interested?)
- Other sources of info: Planet Sysadmin (disclaimer: they've got my blog in there), ONLamp, and your local LUG.
Hope this helps!
-
Amen, brother...
Here are a few things that have helped me out:
- The big one: go to LISA. It can be tough convincing the boss to send their one-and-only IT guy, but it's an incredibly exciting environment. You'll learn lots, you'll meet lots, and you'll get to rub shoulders with people doing incredible things -- and people in the same boat you are.
- If you can't go to LISA, start reading their proceedings. They've just opened up everything to the public (previously you had to wait a year if you weren't a member), and there are some incredible gems to be found. The MP3s from LISA '07 weren't as good as being there would have been (sob), but they're still damned good.
- You should still get a membership in SAGE. Subscribe to the mailing lists,
get a subscription to
- Look around for professional organizations to join, or other
opportunities. There's a sysadmin group at the university where I
work; there's also a committee trying to figure out what the
university's IT strategy should be for the next 5-10 years. I've been
lucky enough to be involved with both, and they're interesting. Sure,
I run a small shop, but I've rubbed shoulders with (well, envied from
across the room
- Start your own techy/sysadmin conference, a la LUGRadio Live. No, LUGRadio Live isn't particularly sysadmin-oriented, but I have the strong impression that the organizers just decided they wanted to hold their own conference, and they did. And if you look at the schedule for their US conference, it's got a damned impressive list of presenters. (I'm considering starting a sysadmin conference next summer in Vancouver, BC...anyone interested?)
- Other sources of info: Planet Sysadmin (disclaimer: they've got my blog in there), ONLamp, and your local LUG.
Hope this helps!
-
Re:Why. . ?
They do, and write countermeasure papers like this one. That paper is about how to break the communications network (basically flooding it) - the next step for the Storm authors is to switch to another peer-to-peer network that's more resilient, and then the investigators find another bug, and the arms race continues.
Ultimately, the only way to shortcut the race is to keep the code from being executed, on the assumption that people aren't going to want to have the bot on their computers. Unfortunately, this is going to require heavy retooling of security systems (to lower the chance that bugs can be exploitable, and to let users know exactly what the program they're trying to execute/install wants to do).
To get back from that digression, the big deal is that it uses peer-to-peer and that so many people have fallen for it. AV companies (and other reverse engineers) do look at the code, but they can only react, hence the arms race. -
Re:Something like that is already in use
There is an article about the Blast-o-Mat in the December 2006 issue of the USENIX magazine.
-
Re:Something like that is already in use
There is an article about the Blast-o-Mat in the December 2006 issue of the USENIX magazine.
-
usenix paper on "IMC" - Illinois Malicious CPU
http://www.usenix.org/event/leet08/tech/full_papers/king/king_html/
describes the real-world cases where this has already been done, and demonstrates - DEMONSTRATES - that surprisingly little integrated circuitry modification is required. -
Crypto-gram "malicious CPUs" - technical paper
-
Hard drives fail much more often than claimed
The big issue is that you cannot take the word of hard drive manufacturers about drives' reliability at a face value. Google's study (PDF) and CMU's study show much higher real-life HDD failure rates than you would get from manufacturers' MTBF claims. RAID 1 or higher is not the full solution - multiple failures, controller failures or data corruption can still occur. Your drives will most often fail without any warning.
-
Re:It's not Really...
Actually, the paper presented at the conference
http://www.usenix.org/event/leet08/tech/full_papers/holz/holz_html/mentions that the fracturing attack does not work. The Storm botnet currently only 2 things.
1. It sends spam e-mails if it receives a file in a spam template format with another file containing a list of addresses.
2. It commits a denial-of-service attack against a host if it receives a different templated file.
What the researchers are proposing is to become a sender and to send out floods of blank files faster than the actual operators can send out their real files. As a result, the hosts are too busy downloading the 2200 phony files to get around to the 1 real one.
The time it takes for all the network nodes to get around to the real file eliminates the power of the botnet, reducing its effectiveness to that of a few machines even if it contains tens of thousands.
-
This was already covered, and more...
... at the Usenix leet conference covered by slashdot.
Go look through the articles... some of them rock. The technical knowledge of these guys, how they dismantled storm, etc is amazing. -
Re:What about filling it up?Unless 10 PB (petabytes) means something other than what I think (10,000 terabytes), where did they get the $4700 number? I even read their definition of static cost (You have to go up a few paragraphs) and I still don't know.
Table 3: Comparison of system and operational costs for 10 PB of storage. All costs are in thousands of dollars and reflect common configurations. Operational costs were calculated assuming energy costs of $0.20/kWh (including cooling costs).
Does $4.7 million sound a bit more realistic?
-
What about filling it up?Since TFA talks about 2 & 3 MB/sec throughput rates...
How long will this array take to fill up the first time around? A 10 PB storage system could be built for about $4700 with an annual operational cost (power for running and cooling the system) of about $50. Unless 10 PB (petabytes) means something other than what I think (10,000 terabytes), where did they get the $4700 number?
I even read their definition of static cost (You have to go up a few paragraphs) and I still don't know. -
Ironic to see this
Mere days after having stumbled upon http://www.cse.ucsd.edu/users/swanson/WACI-VI/docs/08_slides.pdf There is a whitepaper out there by King and company describing indepth the breaks in our retail chain. ICS shipped from overseas etc, and how they are used in high level places where security is tight but these items could use little modification to provide a virtual back door that would almost never be found. Here is the abstract document. http://www.usenix.org/event/leet08/tech/full_papers/king/king.pdf
-
Another paper on "Malicious Hardware"
How about this one: Designing and Implementing Malicious Hardware? Now that people are figuring out how to deal with Storm, we may have to start worrying about bogus ICs that will be designed to allow your computer to be compromised easily. Damn! Interesting, though. It was awarded "Best Paper".
-
wrong link
correct link is http://www.usenix.org/event/leet08/tech/
-
Broken Link on front page
It should be http://www.usenix.org/event/leet08/tech/
{kind=link}