 Slashdot Mirror
Slashdot Mirror
Domain: blogspot.com
Stories and comments across the archive that link to blogspot.com.
Stories · 3,021
-
NRC Releases Audio of Fukushima Disaster
mdsolar writes "The Nuclear Regulatory Commission today released transcripts and audio recordings made at the NRC Operations Center during last year's meltdown at the Fukushima Daiichi Nuclear Power Plant in Japan. The release of these audio recordings comes at the request of the public radio program 'BURN: An Energy Journal,' and its host Alex Chadwick. The recordings show the inside workings of the U.S. government's highest level efforts to understand and deal with the unfolding nuclear crisis as the reactors meltdown. In the course of a week, the NRC is repeatedly alarmed that the situation may turn even more catastrophic. The NRC emergency staff discusses what to do — and what the consequences may be — as it learns that reactor containment safeguards are failing, and that spent fuel pools are boiling away their cooling water, and in one case perhaps catching fire." -
How Mailinator Compresses Its Email Stream By 90%
An anonymous reader writes "Paul Tyma, creator of Mailinator, writes about a greedy algorithm to analyze the huge amount of email Mailinator receives and finds ways to reduce its memory footprint by 90%. Quoting: 'I grabbed a few hundred megs of the Mailinator stream and ran it through several compressors. Mostly just stuff I had on hand 7z, bzip, gzip, etc. Venerable zip reduced the file by 63%. Not bad. Then I tried the LZMA/2 algorithm (7z) which got it down by 85%! Well. OK! Article is over! Everyone out! 85% is good enough. Actually — there were two problems with that result. One was that, LZMA, like many compression algorithms build their dictionary based on a fixed dataset. As it compresses it builds a dictionary of common sequences and improves and uses that dictionary to compress everything thereafter. That works great on static files — but Mailinator is not a static file. Its a big, honking, several gigabyte cache of ever changing email. If I compressed a million emails, and then some user wanted to read email #502,922 — I'd have to "seek" through the preceding half-million or so to build the dictionary in order to decompress it. That's probably not feasible.'" -
A Rant Against Splash Screens
An anonymous reader writes "This controversial post by Adobe's Kas Thomas asks if splash screens are just a sign of program bloat and callous disregard for users. It suggests that big programs should launch instantly (or appear to), perhaps by running against an instance in the cloud while the local instance finishes loading. Users of cell phones and tablets are accustomed to apps being instantly available. This is the new standard for performance, the author argues. Nothing short of it will do, any more." -
Man Digs Out Basement Using Radio Controlled Toy Tractors
Phurge pointed out a story about a man with a fleet of remote control toys and a lot of patience. "Excavating a basement using professional machinery is nothing new but doing it with radio controlled (RC) scaled models is something unheard of. Welcome to the little big world of Joe, from Saskatchewan, Canada. For the past 7 years, Joe has been digging out his basement at an average annual rate of 8 to 9 cubic feet using nothing more than RC tractors and trucks. And we're talking about the whole nine yards here — he starts by transporting the excavator on an RC truck to the basement, unloads it, digs and uses other trucks to transfer the dirt up to the ground through a spiral ramp! He even has a miniature rock crusher! 'I feel quite fortunate to have stumbled onto this basement excavation idea, it's been a great past time to date dreaming up new ideas to tackle different projects along the way,' Joe wrote on the Scale4x4rc forums where he also posted pictures and videos of his feat." -
Is Santorum's "Google Problem" a Google Problem?
theodp writes "Fortune contributor Dan Mitchell argues that GOP presidential candidate Rick Santorum's 'Google problem' isn't Google's problem at all. 'The fact that searching for 'santorum' puts the profane, anti-Rick Santorum site SpreadingSantorum.com (NSFW) at the top of Google's search results,' insists Mitchell, 'is not an example of a "Google bomb," despite the widespread use of that term to describe the result.' In the same camp is Search Engine Land's Danny Sullivan, who also says that Santorum has a search engine problem, not a Google problem. 'It's just that everyone fixates on Google,' Sullivan adds. Which is perhaps to be expected, since Google is the King of Search and also has ties to SpreadingSantorum creator Dan Savage, having featured the sex-advice columnist in Google's The-web-is-what-you-make-of-it Chrome ad campaign (for Savage's admirable It Gets Better Project, not SpreadingSantorum). So, considering Google's vaunted search quality guidelines, is some kind of change in order? Sullivan, while making it clear he opposes Santorum's views, nonetheless suggests Google is long overdue to implement a disclaimer for the 'Santorum' search results. 'They are going to confuse some people,' he explains, 'who will assume Google's trying to advance a political agenda with its search results.'" -
It's Not All Waste: The Complicated Life of Surplus Electronics In Africa
retroworks writes "Today's Science Daily reports on 5 new UN studies of used computer and electronics management in Africa. The studies find that about 85% of surplus electronics imports are reused, not discarded. Most of the goods pictured in 'primitive e-waste' articles were domestically generated and have been in use, or reused, for years. Africa's technology lifecycle for displays is 2-3 times the productive use cycle in OECD nations. Still, EU bans the trade of used technology to Africa, Interpol has describes 'most' African computer importers as 'criminals,' and U.S. bill HR2284 would do the same. Can Africa 'leapfrog' to newer and better tech? Or are geeks and fixers the appropriate technology for 83% of the world (non-OECD's population)? " -
Why the Number of O's In LOL Matter On YouTube
karthikmns writes "It turns out that Google uses the number of o's in a lol to weigh how funny a video is. In a blog post Google explains how they came up with an algorithm to gauge a video's comedic potential. So if you want to watch funnier videos, make sure to add some extra o's or help them by visiting their Comedy Slam and voting." -
NRC Emails Reveal Confusion In Aftermath of Fukushima
mdsolar writes "The Washington Post is reporting on the NRC response to the Fukushima disaster. Aspects include an abusive relationship with Steven Chu, a secret database on fuel pool fires that was not shared, and a Washington Two Step on Vermont Yankee. Pretty sordid." The NRC website has a bunch of documents relating to their response and attempts to consult the Japanese government (it might take a few months to work through). On a related note, The Bulletin of Atomic Scientists ran a retrospect on the nuclear situation in 2011. -
Capitol Records Motion To Enjoin ReDigi Denied
NewYorkCountryLawyer writes "The motion by Capitol Records for a preliminary injunction against used digital music marketplace ReDigi has been denied. After hearing almost two hours of oral argument by attorneys for both sides, Judge Richard J. Sullivan ruled from the bench (PDF), holding that plaintiff had failed to show 'irreparable harm.'" -
Capitol Records Motion To Enjoin ReDigi Denied
NewYorkCountryLawyer writes "The motion by Capitol Records for a preliminary injunction against used digital music marketplace ReDigi has been denied. After hearing almost two hours of oral argument by attorneys for both sides, Judge Richard J. Sullivan ruled from the bench (PDF), holding that plaintiff had failed to show 'irreparable harm.'" -
Google Releases Chrome For Android Beta
An anonymous reader writes "Today Google announced the availability of a beta version of its Chrome browser for Android. Unfortunately, it's limited to Android 4.0 (Ice Cream Sandwich) devices. Google is trying to keep Chrome fast and easy to use, and part of that involved redesigning tabs so they work more naturally with touchscreens. 'You can flip or swipe between an unlimited number of tabs using intuitive gestures, as if you're holding a deck of cards in the palm of your hands, each one a new window to the web.' They've also including synchronization functionality that allows you to move from desktop browsing to phone or tablet browsing and pick up right where you left off." -
Google Starts Scanning Android Apps
eldavojohn writes "A recent blog post has Android developers talking about Google finally scanning third party applications for malware. Oddly enough, Google claims this service (codenamed 'Bouncer') has been active for some time: 'The service has been looking for malicious apps in Market for a while now, and between the first and second halves of 2011, we saw a 40% decrease in the number of potentially-malicious downloads from Android Market. This drop occurred at the same time that companies who market and sell anti-malware and security software have been reporting that malicious applications are on the rise.' So it appears that they allow the software to be sold even before it is scanned and it also appears that no one has been bitten by a false positive from this software. Apparently Bouncer is not as oppressive as Apple's solution although given recent news its effectiveness must be questioned. Have any readers had their apps flagged or pulled by Bouncer?" -
Google Asks Court Not To Enjoin ReDigi
NewYorkCountryLawyer writes "Google has sought leave to submit an amicus curiae brief against Capitol Records' preliminary injunction motion in Capitol Records v. ReDigi. In their letter seeking pre-motion conference or permission to file (PDF) Google argued that '[t]he continued vitality of the cloud computing industry — which constituted an estimated 41 billion dollar global market in 2010 — depends in large part on a few key legal principles that the preliminary injunction motion implicates.' Among them, Google argued, is the fact that mp3 files either are not 'material objects' and therefore not subject to the distribution right articulated in 17 USC 106(3) for 'copies and phonorecords,' or they are material objects and therefore subject to the 'first sale' exception to the distribution right articulated in 17 USC 109, but they can't be — as Capitol Records contends — material objects under one and not the other." -
ITC Throws Out B&N Antitrust Claims Against MS
N!NJA writes with an excerpt from a post by Florian Mueller: "Barnes & Noble's primary line of defense against Microsoft's allegations of patent infringement by the bookseller's Android-based devices has collapsed in its entirety. An Administrative Law Judge at the ITC today granted a Microsoft motion to dismiss, even ahead of the evidentiary trial that will start next Monday (February 6), Barnes & Noble's 'patent misuse' defense against Microsoft. [...] Prior to the ALJ, the ITC staff — or more precisely, the Office of Unfair Import Investigations (OUII), which participates in many investigations as a third party representing the public interest — already supported Microsoft's motion all the way. The OUII basically concluded that even if all of what Barnes & Noble said about Microsoft's use of patents against Android was accurate, it would fall far short of the legal requirements for a patent misuse defense." -
Gates Paying Murdoch For System To Track U.S. Kids' School Progress
theodp writes "Discussing U.S. education in his 2012 Annual Letter, Bill Gates notes the importance of 'tools and services [that] have the added benefit of providing amazing visibility into how each individual student is progressing, and generating lots of useful data that teachers can use to improve their own effectiveness.' Well, Bill is certainly putting his millions where his mouth is. The Gates Foundation has ponied up $76.5 million for a controversial student data tracking initiative that's engaged Rupert Murdoch's Wireless Generation to 'build the open software that will allow states to access a shared, performance-driven marketplace of free and premium tools and content.' If you live in CO, IL, NC, NY, MA, LA, GA, or DE, it's coming soon to a public school near you." -
New Spark Tablet To Come Loaded With KDE's Active Plasma Interface
mpol writes "KDE's Plasma Active introduced last Saturday its own 7" tablet. According to Aaron J. Seigo, 'It's the first tablet computer that comes with Plasma Active pre-installed.' The Spark, with its 7" screen, is built around a Cortex A9 with a Mali-400-gpu, 512MB RAM and an SD-card slot. It will have a 800x480 screen resolution and will cost around 200 Euro. It is actually a rebrand of the Zenithink ZT-180 C71, which comes with Android by default. On a personal note, Aaron J. Seigo will no longer be sponsored by Qt Development Frameworks to work on Qt and KDE. He will, however, stay involved with KDE and Free Software, he says." -
ReDigi Defends Used Digital Music Market
NewYorkCountryLawyer writes "ReDigi has fired back, opposing Capitol Records's motion for a preliminary injunction. In his opposition declaration, ReDigi's CTO Larry Rudolph explains in detail (PDF) how the technology employed by ReDigi's used digital music marketplace effects transfer of a music file without copying, but by modifying the record locator in an 'atomic transaction,' and how it verifies that only a single instance of a unique file can enter the ReDigi cloud system. ReDigi's opposition papers also point out plaintiff's own admissions that mp3 files are not 'material objects' or 'phonorecords' under the Copyright Act, and therefore not subject to the Copyright Act's distribution right, and defend ReDigi's used digital music marketplace and cloud storage system (PDF) on a number of grounds, including the First Sale exception to the distribution right applicable to a 'particular' copy, the Essential Step exception to the distribution right applicable to a copy essential to the running of a computer program, and Fair Use space shifting." -
ReDigi Defends Used Digital Music Market
NewYorkCountryLawyer writes "ReDigi has fired back, opposing Capitol Records's motion for a preliminary injunction. In his opposition declaration, ReDigi's CTO Larry Rudolph explains in detail (PDF) how the technology employed by ReDigi's used digital music marketplace effects transfer of a music file without copying, but by modifying the record locator in an 'atomic transaction,' and how it verifies that only a single instance of a unique file can enter the ReDigi cloud system. ReDigi's opposition papers also point out plaintiff's own admissions that mp3 files are not 'material objects' or 'phonorecords' under the Copyright Act, and therefore not subject to the Copyright Act's distribution right, and defend ReDigi's used digital music marketplace and cloud storage system (PDF) on a number of grounds, including the First Sale exception to the distribution right applicable to a 'particular' copy, the Essential Step exception to the distribution right applicable to a copy essential to the running of a computer program, and Fair Use space shifting." -
Close Approach By Asteroid 2012 BX34
An anonymous reader writes with news that asteroid 2012 BX34, 11 meters wide, is in the process of passing within 60,000km of Earth — about a fifth of the distance between the Earth and the Moon. At that size, the asteroid would pose no danger even if it hit the Earth's atmosphere. -
KDE 4.8 Released
jrepin writes "The KDE community has released version 4.8 of their Free and open source software bundle. The new version provides many new features, improved stability, and increased performance. Highlights for Plasma Workspaces include window manager optimizations, the redesign of power management, and integration with Activities. The first Qt Quick-based Plasma widgets have entered the default installation of Plasma Desktop, with more to follow in future releases. KDE applications released today include Dolphin file manager with its new display engine, ..., and KDE Telepathy reaching its first beta milestone. New features for Marble virtual globe keep arriving, among these are: Elevation Profile, satellite tracking, and Krunner integration. The KDE Platform provides the foundation for KDE software. KDE software is more stable than ever before. In addition to stability improvements and bugfixes, Platform 4.8 provides better tools for building fluid and touch-friendly user interfaces, integrates with other systems' password saving mechanisms and lays the base for more powerful interaction with other people using the new KDE Telepathy framework." -
Google Consolidates Privacy Policies Across Services
parallel_prankster writes "The Washington Post reported Tuesday that Google will require users to allow the company to follow their activities across e-mail, search, YouTube, and other services; a radical shift in strategy that is expected to invite greater scrutiny of its privacy and competitive practices. The information will enable Google to develop a fuller picture of how people use its growing empire of Web sites. Consumers will have no choice but to accept the changes. The policy will take effect March 1 and will also impact Android mobile phone users. 'If you're signed in, we may combine information you've provided from one service with information from other services,' Alma Whitten, Google's director of privacy, product, and engineering, wrote in a blog post." The angle of the Washington Post article is a bit negative; Google sees this as consolidating an absurd number of privacy policies for its various services into a single, unified document. Reader McGruber adds: "Donald E. Graham, the Washington Post's chairman and CEO, joined Facebook's Board of Directors in January 2009. Curiously, the Washington Post article neglects to disclose that." -
Pirate Party Releases Book of Pirate Politics
ktetch-pirate writes "If the SOPA/PIPA blackouts were a wakeup call to many people, then the U.S. Pirate Party has released a book that might help explain some of the issues. The book covers issues such as Corporate Personhood, the 4th Amendment, the history of copyright, and how DRM laws are made. There are even cartoons from Nina Paley throughout to add a bit of humor. DRM-free eBook versions are available to download from the book's site, or you can buy a paperback edition from Amazon for ten bucks." The book is under the CC BY-NC-SA, and features essays from the likes of Lawrence Lessig and Rick Falkvinge. -
Carl Malamud Answers: Goading the Government To Make Public Data Public
You asked Carl Malamud about his experiences and hopes in the gargantuan project he's undertaken to prod the U.S. government into scanning archived documents, and to make public access (rather than availability only through special dispensation) the default for newly created, timely government data. (Malamud points out that if you have comments on what the government should be focusing on preserving, and how they should go about it, the National Archives would like to read them.) Below find answers with a mix of heartening and disheartening information about how the vast project is progressing.
LoC?
by an Anonymous Reader
So how many GB/TB is a Library of Congress? :)
Or, more seriously, how big are you estimating? Are you using raw scans or some sort of compression (JPG, PNG, etc)? What resolution are you using? Do you vary the resolution depending on the document?
What sort of meta data are you putting in?
CM: The reason John Podesta and I suggested a Federal Scanning Commission in our letter at YesWeScan.Org is we really don't know how big the holdings of the government are. I can tell you that the Library of Congress is about 32 million cataloged books (a significant increase from the 6,487 books Thomas Jefferson donated to get them started). But, this is about more than books, it is about paper records, microfilmed technical papers, video, audio, photographs, and much more.
The scale is fairly vast. The Smithsonian has 137 million objects, including about 13 million images. David Ferriero, the Archivist of the United States estimates he has over 10 billion pages of text documents, 7.2 million maps, and 40 million photographs including everything from past census records to presidential dinner menus, and that includes about 7.5 million motion pictures and sound recordings. The Government Printing Office distributes their documents to the Federal Depository Library Program, and that includes over 60 million pages of collections including the Official Journals of Government such as the Federal Register. That's just scratching the surface, and we recommended a Federal Scanning Commission to begin the process of understanding what we have (and what is worth digitizing).
As to standards? There are lots of pretty good standards on how to digitize. NARA, Library of Congress, GPO all spec out document scans at 400 dpi, for example. For photographs, moving images, and other objects, there are some pretty good and pretty detailed standards at www.digitizationguidelines.gov. I know Brewster Kahle's operation and my own tend to work off those specifications (in fact Brewster does quite a bit of scanning for the government).
As to compression? Well, I've found people tend to overcompress things. That said, sometimes the initial quality isn't that great, so a 600 dpi uncompressed scan would be silly in some cases. But, for photographs I try very hard to keep the TIFF images around and not rely on JPEG. Likewise, for audio it is really nice to keep a nice 48 khz version of your file around if you can simply because if you screw up the compression maybe somebody else can do a better job in a few years. Disk space is relatively cheap, so that isn't the barrier it used to be. For video, I rip MPEG2 at whatever it is on a DVD, when I'm actually digitizing I try to get the video bitrate up to 8-10 mbps when ripping a Betacam or Umatic. Some people think that is overkill, but I'd rather be safe than sorry.
Metadata? Well, you got to have it or you're not going to get very far when it comes to access. Many librarians have made perfect the enemy of the good when it comes to metadata and have resisted any attempt at digitization because we don't have the very best metadata we might have. I'm more in the camp of scan what you have and get as much of the metadata as you can into it. For example, we have 3,200 1000-page volumes of briefs from the 9th Circuit of the U.S. Court of Appeals. We didn't have good metadata, but we had the Internet Archive scan them anyway. Then, after we got our PDF files, I shipped those off to a double-key team in India and they broke the briefs up into individual documents and typed the metadata into a spreadsheet for me, which we hope to release soon.
My point is that sometimes you can shoehorn the metadata in after the fact or you can use a variety of techniques to pull the metadata out of the documents (e.g., smart OCR). In theory, you can use crowdsourcing to get the metadata, but so far I've not had a lot of luck persuading thousands of people to spend their time doing that kind of work. A captcha is a quick thing to do and is between you and something you want, whereas entering metadata in for videos or documents is one of those civic duty things that everybody thinks everybody else should be doing.
Total size? Brewster says a book is about 400 Mbytes (though he's very quick to point out that you could put the words in all the books in the library into a terabyte and if you're distributing PDFs, you can easily throw 130,000 full-color, searchable PDFs onto a 4 TB drive). But, you were probably asking about raw data. Here's some raw numbers:
32 million books at 400 Mbytes each is 12.8 petabytes 50 million photos at 150 Mbytes each is 7.5 petabytes 10 billion pieces of paper ("records") at 100 Kbytes each is 1 petabyte 20 years of video at 8 mbps is only 630 Tbytes.
(Somebody check my math?)
If you're talking a decade-long federal digitization initiative, we're looking at well south of 50 petabytes, which seems pretty doable in this day and age!
Can the rare books collections be digitized?
by autophile
Three closely related questions about the rare books collections at the Library of Congress:
1. I know there is some kind of effort going on to digitize the rare books collections, but can it be sped up? There are many high-quality low-cost archival book scanners out there (such as the ones developed at diybookscanner.org).
2. It gets really annoying to have to receive paper copies of books when copies are requested. Why not DVDs of high-quality images?
3. Why is there no outreach by the LoC to smaller, cheaper book scanning efforts? The Internet Archive, DIYBookscanner.org, and Decapod all come to mind.
CM: In reverse order. I don't know why we aren't distributing and decentralizing our scanning efforts. The Internet Archive is a heavy-duty production shop and they do an amazing job, as do folks like Google Books and the folks digitizing things the Mormon Church. But, there are a bunch of DIY solutions and it would be really nice if we could get more people pitching in. The biggest problem on distributing the digitization efforts is quality control. I know when it comes to ripping video, I can easily teach other people how to grab an MPEG2 off a DVD, but when it comes to things like digitizing a Betacam, that takes some training. But, we're all trainable and I wish we could all do more.
Getting back paper copies of books and papers when they're doing a copy anyway is just plain dumb. Likewise with things like FOIA results. John Podesta testified before the Senate about FOIA and said if an agency answers a FOIA request, they should also post their result online so others can see it. That seems pretty obvious.
As far as digitizing rare book collections, there are some amazing pockets throughout the government but there is no real coordination and there certainly is no effort to scan at scale or to come up with a realistic national digitization strategy. That is why we called on the White House to lead the effort. Within the Library of Congress there are some amazing collections, but if you look around to places like the National Agricultural Library or the National Library of Medicine or the libraries in the service academies you'll find lots more. Some have argued that digitizing rare books is silly because the audience is just a few academics, but I can tell you from my own experience helping host the network site for the Archimedes Palimpsest that when you make this kind of information available, there is an amazing long tail.
If you scan it, they will come. And, to answer your question, if we all scan it, they will come much sooner.
Real time legislation drafting
by kerskine
Would it be possible to implement a system that would allow real-time and continuous review of legislation while it's being drafted? Much has been made over the past three years about legislation being available for review before voting by the House or Senate. The final draft for review usually is huge PDF that makes it near impossible for citizens, interest groups, and the media to thoroughly analysis in time.
CM: You want to see the sausage being made not just buy the hot dog! I'll comment on the U.S. Congress since that's the system I know best. Thomas is a pretty good system if you happen to be stuck in 1994. It does have all the amendments and the actions and the various stages that legislation go through. But, it isn't real time, more like "pretty quick." As Van Jacobson once quipped, "Same day service in a nanosecond world." And, Thomas isn't really machine processable, it is final form, usually formatted ASCII text (shades of NROFF!). People like Josh Tauberer who built GovTrack.US have spent considerable time crawling those systems and trying to get the data into regularized formats and make it available to others to reuse via APIs, but that isn't the same as exposing the inner working of the sausage factory.
Majority Leader Cantor's staff has been pushing a system to make the raw data all available in XML from the Clerk's office and I think that is a very promising initiative which hopefully will bear fruit. (They're having a February 2 conference to discuss their plans if you are interested. I have no idea if it will be streamed for those of who aren't Inside the Beltway and I don't know their schedule for moving past conferences and into production.)
Congress is a pretty complicated beast. I know some folks like Sean McGrath have had better luck with some of the state legislatures. The problem is you need to dig deep into the inner working of a legislature. In the Congress, that means you're changing things like authoring tools that are used in the Clerk's office and by all the staff members, so you have to be careful or you get a bunch of really angry Congressman yelling at you because their staff can't crank out the flavor-of-the-week in the form of a bill or amendment.
There's also a bit of an issue of will. My work with the Congress to put hearings on-line showed that you could take the official transcripts of a hearing and use those to generate closed captions on the video. All you need is the official transcript of the hearing, but in order to get those I had to execute a special Memorandum of Understanding with the House Oversight Committee. Other committees guard their transcripts jealously and won't let them out for several when. When I started processing a bunch of historical videos we purchased from C-SPAN, I went to the Government Printing Office and found that many committees never deliver their transcripts, even a decade after the fact!
How to keep track of legislative activity about open access?
by oneiros27
Recently in the federal register, there were two calls for comments about access to data and research from federally funded research:
http://federalregister.gov/a/2011-28623 [federalregister.gov] http://federalregister.gov/a/2011-28621 [federalregister.gov]
I didn't hear about these until ~4 weeks after the original announcement, and with the holidays, it was too late to try to get the societies I'm involved with to prepare and vote on official statements. Are there any places where people can get/post notices of these sorts of things so that we can stay informed and try to help influence policies?
CM: The Federal Register is getting a lot better now that it is a much more open system. The idea of "Federal Register 2.0" was a paper I wrote for the Obama transition, so it is an issue I've tracked pretty closely and frankly, I've been amazed at how much better it is now. What they did is instead of selling the raw data feed for the Federal Register for $17,000/year, they went from SGML to XML and then released the data in bulk for free. A few guys out in San Francisco were looking for something to do to enter a contest and they took that bulk data and dreamed up GovPulse.US. That was such a better version of the Federal Register that the Office of the Federal Register switched the official site over to their open source platform. My point is the tools are there to do better notification mechanisms, and I'm sure the government would welcome somebody grabbing the GovPulse.US code out of Github and making it even better.
That's the technical answer. But, the substantive answer is that there is a huge boatload of stuff in the Federal Register and it is pretty hard to figure out what to pay attention to. I also missed that particular call for comment, and I've even missed several Requests for Information coming out of places I try and pay attention to, like the White House's Office of Science and Technology Policy. And, I do this stuff full-time! Perhaps better targeted notification mechanisms are the answer. Maybe it is a social media solution, where you pay attention to things your friends are paying attention to. I hope the answer is not that the only way to pay attention is to be employed with a beltway bandit which can afford hundreds of minions that do nothing but pay attention to Washington. Indeed, there are some very fancy for-pay services from folks like Congressional Quarterly and Bloomberg that cost an arm and a leg, but I can't help but think there has to be a better way that is also open.
What do you think of corporate partnerships?
by mhh5
I'd like to know what you think about corporate partnerships in the process to get public data released. (I'm not sure if Google Patents existed before the USPTO released its databases.) Do corporations that get involved in the process tend to make the process better without question, or are there tradeoffs in some areas because the corporations always want to help but then try to retain a proprietary version of the data for themselves?
CM: The theory is that the government gets some kind of valuable service (like digitization) that the government wouldn't get otherwise so it is a "win-win." But, the reality is all too often the government gets snookered and what we do is give some corporation exclusive access to some pot of data and the government doesn't get much of anything. The deal between Amazon and the National Archives was a good example of that kind of a private fence around the public domain. With a help from Boing Boing, I started systematically purchasing those public domain videos and re-releasing them in the wild. I have no problem with Amazon selling public domain video, I just hate it when they get a de facto or a contractual exclusive. (My testimony before Congress on this subject is here.)
There are lots of other examples of government getting snookered. For example, the Government Accountability Office let Thomson West get access to 60 million or so pages of federal legislative histories. At great cost to the government, they were all packed up and dispatched to West which digitized them all and then sent them back to the government. West now sells access to his amazing database. What did the government get for it's trouble? A few logins for GAO staffers. Even members of Congress need to pay to access the database! (We have an interesting paper trail on this issue.)
I'm glad you brought up the Google Patent system because I was personally involved in making that happen and I can tell you that this one is totally legit. Jon Orwant is the lead developer on this for Google and I played a small part in helping convince the White House and the Patent Office they ought to give Jon access to their data (the heavy lifting on that deal was by Beth Noveck who was the Deputy CTO at the time). Google makes all the data they got from the Patent Office available for bulk access with no strings attached. I can vouch for that because I did a mirror of their system. Last I heard Google was sending out anywhere from 1 to 10 terabytes of data PER DAY to external sources and even normally very critical folks who work in this arena have been really happy.
The big problem in the Patent Office is their computing infrastructure is a real catastrophe. Their power plant is over 95% capacity (e.g., plug in a computer, bring the building down!) and even though the Under Secretary knew that selling DVD subscriptions was silly, he wasn't able to switch over to an FTP service. He cut the deal with Google Patent and it worked out well for the government, for Google, and for everybody else.
What's the difference between the Google deal and the Amazon deal? In the case of the Amazon and GAO/West deals, the government lawyers did all the negotiating and they were totally outsmarted by some sharks in industry. But, when government has people like Under Secretary Kappos and Beth Noveck doing the negotiating, these things can work out just fine. The key is government should partner with people who want to do public service, not people who want to service the public.
Encouraging Governments?
by theNAM666
In a city such as Nashville, things as basic as business ownership and property records are not available online. In states such as New Jersey, public records such as basic corporate filings (officers, operating address/address for service of process) are accessible only for a fee.
What concrete actions can citizens confronting such situations, take to encourage accessibility and accountability?
CM: I find you need a carrot and a stick to make this stuff happen, especially at the local level. Folks like Everyblock.Com and CodeForAmerica.Org have done great working prying some of these databases loose, but there is still lots to do.
The first thing you should do is pick up the phone (or pick up your email client) and write/call the people who run the system. Ask them if you can have access to the data. Sometimes, it is as simple as that.
Other times, though, it isn't quite as simple since they want the money (or they want the control or they think this should be done by "private industry" by which they mean some buddy who is a contractor). The nice thing about any government system is somebody usually has oversight responsibilities. So, the next step is to find a city council member of state legislator who has oversight on the agency in question and ask them.
Again, life isn't usually that simple, but sometimes you win! If you can't get anywhere that way, what I usually end up doing is basically competing with the government system. Build a proxy system like RECAPtheLaw.Org did to recycle paid documents. Or, get a sponsor and buy a reasonable number of docs and build a web site that looks like it is going to be a real production system.
Then, go back again and ask. Maybe if you have eyeballs or at least have a nice web site, that is enough to get the government moving. But, if that doesn't do the job, you may have no choice but to compete with them for real, which of course requires a big commitment in time and energy and not everybody can do that. I know in the case of the Patent Office, I started pestering them in 1993, including several times when I spent 6-figure sums purchasing their data, and it still took until 2011 to crack that nut.
The real trick is focus/obsession. Pick one thing you really care about and just keep pestering them until you crack it open. If you're surfing from one opengov problem to another, showing up for a 1-day hackathon then moving on to something else, you're not going to get anywhere. Pick something real and make it your thing.
Privately Owned, Copyrighted Law
by AdamnSelene
I think I have read that the law itself cannot be copyrighted and it should be possible to make it available available to everyone. But as a techie who drafts standards and specifications, I was wondering about how far this goes--especially since Congress recently proposed enacting some of our standards into law. (They decided not to, but they read some parts into the committee records as they debated.) Can you still accomplish your project if a governmental body adopts (or considers adopting) a privately owned, copyrighted technical reference manual or set of safety standards as administrative law (or regulations that carry the force of law)? Or would such obstacles keep you from being able to digitize all of the government's laws (and archives of proposed laws)?
CM: The idea that the law has no copyright is a fundamental part of the American system of government. That applies to states and municipalities as well. The basic decision is Wheaton v. Peters from 1834 but that decision has been reaffirmed over and over. The law is sacred in the American system. You can't have equal protection under the law or due process under the law if there is a poll tax on access to justice.
When we get to a privately developed standards however, it turns into a very interesting issue. The basic mechanism is called Incorporation by Reference. The government will take some external document (such as a model building code) and incorporate the entire text to make it the law of the land. A guy named Peter Veeck was responsible for a landmark decision in 2002 when he published the Texas Building Code which was an incorporation of a privately-developed and very expensive model code. The court ruled that while the model code had copyright, the law of the land did not.
Based on the Veeck decision, my group went and posted many of the public safety codes enacted by the states. We started by purchasing model codes, finding the incorporating legislation, and concatenating the two pieces together and posting the resulting PDFs. More recently, we've done some extensive reworking of the California public safety codes, known as Title 24, converting the entire text into valid XHTML, recoding the graphics as SVG graphics, the formulas as MathML, and regenerating the PDF documents as nicely typeset documents instead of low-quality scans. You can see this work on the web but it is also available as Google Code project.
The federal government also uses this mechanism intensively, with over 2,000 standards incorporated into the Code of Federal Regulations. This is non-trivial stuff, things like all the OSHA safety regulations. The issue was recently considered by a federal group called the Administrative Conference of the U.S. which basically rolled over and endorsed the idea that it is ok for important parts of the law to cost money. (Read EFF's protest letter if you want a good critique of what they did.)
I'm not necessarily saying that government should be able to appropriate any privately-developed standard and make it available. And, I'm not necessarily saying you want OSHA bureaucrats drafting the standards. But, I do think the big standards establishment and the government regulators have cut a deal that results in the law not being available and the costs forked off on private citizens and small business with extortionate monopoly prices. I just paid $847 for a 48-page safety standard from Underwriters Labs and $60 for 2-page safety standard from the Society of Automotive Engineers, both of which are mandated by law in the CFR. They do need money to run their operations, but let me just point out that in 2009 the 501(c)(3) nonprofit Underwriters Labs paid their CEO $2,138,984 and the nonprofit SAE paid their CEO $412,578.
Ancestry.com
by An Anonymous Reader
What is your opinion about websites like Ancestry.com which make use of public records and charge a subscription fee for access? What is the incentive for the government to migrate old documents into digital form when services like these exist? Do you think Ancestry.com should be a 501(c)(3)?
CM: I'm not a big fan of for-profit corporations that have a business model of monetizing the public domain. I'm fine if they exist and fine if they make billions of dollars, but if they are the only game in town they've taken something that belongs to all of us and and turned it into their private property.
The government got snookered on the Ancestry.Com deal. They could have insisted that the raw data be available in bulk for anybody else to use. The folks that approach the government to cut these sweetheart deals argue that is unreasonable because they need a "return on investment" and the argue that if they don't get the return on investment they won't do the deal (and by extension nobody else will do the deal).
But, government can argue much harder! For example, instead of negotiating some exclusive thing with Ancestry.Com, how come they didn't ask the Internet Archive to grab the data? Or put together something creative with a couple of foundations that would pay for the digitization in return for the kind of payback the foundations like to see (e.g., good press, photo opportunity with the President, or other tools of the trade)?
You asked if Ancestry.Com should be a 501(c)(3)? Not all nonprofits do something that I think which should be an essential part of their mission, which is allow others to compete with them. I believe providing open access to all data ought to be a precondition to getting nonprofit status (an idea that Gil Elbaz has been pushing for quite some time). A good example of a nonprofit that builds walls is Guidestar which wants to be the place where you go for all your nonprofit information. The IRS should be making all Form 990 returns of nonprofits available in bulk for anybody to use, which would knock the bottom out of Guidestar's attempts to build walls and force them to stay innovative and provide value.
Pacer Problems
by onyxruby
How much difficulty do you anticipate in getting and publishing records in Pacer? If there's one system that should be free it the decisions that our courts make and yet you are charged by the page just to view the results. Are you concerned about a court taking an unkind view on your archiving what is in Pacer?
CM: PACER is an abomination. Do they take a dim view of our efforts? Well, the Administrative Office of the U.S. Courts reacted so strongly to our efforts to make their data available that they called the FBI on Aaron Swartz and cancelled the only meaningful public access system they had, which consisted of one terminal in each of 17 public libraries around the country. In this era of rapidly decreasing costs, they just boosted their access charges from 8 cents a page to 10 cents a page, arguing that this is a bargain compared to 25 cents a page for a copy machine.
What I find so disturbing about PACER is that when we did get 20 million pages of docs, we were able to conduct a comprehensive analysis of privacy violations in the courts, an analysis that led to a nice thank-you letter from the Judicial Conference and changes in their privacy rules. In other words, only when public interest groups got access to the data did we begin to address privacy issues. Public access is not just about pro se prisoners defending themselves from a jail cell, which is the view of many in the Administrative Office of the Courts. Public access is about attempts like ours (and many other folks) to make our system of justice function better. When we say we are "an empire of laws not a nation of men" that means we write down what we are doing in our courts so that it is no longer the arbitrary decisions of individuals. The paper trail is there so we can make sure the system is functioning properly. When you limit that access to those that only have a Gold Card, you pervert democracy and you pervert justice.
This principle that access to justice shouldn't hide behind a cash register goes back to the Greeks. Theseus in Euripedes' Suppliants said "when there are no public laws, one man holds power by keeping the law all for himself, and there is no more equality. But when the laws are written, the weak man and the rich man have equal justice." The PACER system is justice for the rich man.
Steve Schultze and the team at Princeton did a lot of the heavy lifting on this issue, including the very nice RECAPtheLaw.Org system they built. They've also done a lot of financial analysis that shows that the courts are not only recovering their costs for operating the expensive PACER system, they're making a huge profit (to the tune of $100 million/year) and using their excess profits to do things like buy big-screen TVs in direct violation of the E-Government act.
The basic problem on PACER is the Judicial Conference has delegated the issue to a few techie judges who think what they've built is something great. But, PACER is a hairball of bad PERL code and the result has not served the judges, the bar, or the American people very well. My only hope is that eventually, the Judicial Conference will see that their information technology is 30 years behind the rest of the Internet and feel ashamed at the travesty they have wrought. Until then, we have RECAP.
If you're interested in the issue, a couple of resources to look at are the PACER paper trail and a bit of a rant that I delivered at the Gov 2.0 summit.
How to visualize opened data?
by hardwarejunkie9
The amount of information you're trying to free is entirely staggering and consists, largely, of tables of numbers. These numbers are incredibly significant, but people generally can't see them.
After you free all of this information and make it available to the public (as it should be), then what? What do you expect for the public to do with these numbers? Tables of information are not nearly as useful as graphs. This data needs to be seen, but, more importantly, it needs to be understood.
Do you have any ideas for how to disseminate this information? Perhaps a team-up with someone like gapminder.org's Hans Rosling might be particularly valuable for all of us.
CM: Actually, most of the data I'm looking at is not tables of numbers, it is video, images, textual documents, technical papers, maps, and books.
But, I definitely get what you're saying and there are a lot of numbers. For example, the IRS Form 990s should be structured data instead of PDF documents, so extracting the data from the mass of paper is the initial challenge. There are lots of other examples of this kind of initial extraction, getting what were printed paper docs into structured data. There are some interesting tools, such as OCRopus which does layout analysis, but there needs to be much more. One of the reason we called for a Federal Scanning Commission is that we think there is a lot of directed R&D that could not only scale up mass digitization but could also work on the important value-added of extraction of structured data and handling some of the tricky issues like detecting the presence of Social Security Numbers.
Once you have the data, as you say, then what? I'm a big fan of the idea that the government starts by providing bulk data, then they provide an API, and then maybe they also build web sites and apps and other things along with everybody else out there. That's a 3-part hierarchy that Ed Felten and some of his students developed and it should be a law that applies to all government information systems that are externally facing.
The issue here is that all too often people look at a problem like "digitize all government information" and they want to see the whole stack of the solution from one place. But, I think you can do a layered approach and count on the fact that there is always somebody smarter out there and our job is to reduce the barriers to entry. So, how would I visualize the data? I have no idea, but I'd make damned sure that folks like Martin Wattenberg at Many Eyes and Hans Rosling at Gapminder knew the data was out there and then I'd sit back and be amazed at whatever they come up with. How's that for pushing the problem downstream?
Why is data access so hard?
by CanHasDIY
Can you provide any explanation as to why it is so difficult and cost-prohibitive to obtain records from the government, especially considering the abundance of laws requiring government compliance with requests for information (AKA "Sunshine Laws")?
Is it simply a matter of government employee ineptitude, or have you found evidence of a more nefarious rationale?
CM: I get that question a lot. Why would a member of Congress take deliberate steps to stop public hearings from being available? Why would a court administrator deliberately restrict access to public court documents? Usually the answer is, as Heinlein said, "you have attributed conditions to villainy that simply result from stupidity." When I'm explaining why something is so broken on a big government system, my usual answer is that there are a lot of people still stuck in the 1970s and 1980s, when information dissemination was really, really hard and it took men in white lab coats and computers the size of freight trains to process data. In other words, the problem with a lot of folks who are government gatekeepers is they just don't get the Internet and they don't get computers. In fact, usually when some senior bureaucrat is throwing stones at me, you can find younger staffers working for them rolling their eyes.
That's an optimistic view, and if I'm right things will get better. But, I'm often wrong on my predictions of the future. (I was the guy who saw TimBL demo the web in 1992 and thought to myself "interesting, but it won't scale.")
But, there is also some more nefarious stuff happening, often the accumulation of power by being able to cut exclusive deals with contractor buddies. If your life in government consists of receiving emissaries from Lockheed Martin, maybe you think you're making everybody happy by letting them build you a $1 billion computer system. Often, you think your problems are so unique that the $1 billion solution is the only answer.
And, in some cases, as we've seen from numerous GAO reports, Inspector General reports, Congressional hearings, and newspaper articles, there are some really evil people out there who think the public domain and the government is their personal business opportunity. Looting the federal government is the kind of civic crime that ranks right up there in my book with stealing cookies from Girl Scouts and selling fake medicines to sick people.
Who is the worst?
by TheBrez
Which government agency is the worst to get information from?
CM: I don't know who the worst are (there's a lot of competition for that slot), but the ones that piss me off the most are the ones that should know better.
Public.Resource.Org is a really small operation. I'm the only staff member. My part-time sysadmin is @mdkail who is pretty busy with his day job as CIO at NetFlix. My ISP is Jim Martin and his team at ISC who are kind of busy running the F-Root. My office net is supported by the amazing systems team at O'Reilly which rents me office space at below-market rates.
I'll grant you government would have a tough time getting that kind of help. But, I'm a one-man shop and we run the 4th most popular U.S. government video channel on YouTube, we're the source for a lot of the on-line presence of the U.S. Court of Appeals, and we've supported efforts for the U.S. Congress, the White House, and the National Archives. If we can do this out of Northern California, couldn't the vast resources of the federal government in Washington, D.C. do a whole lot better than they're doing now?
For me, my current bete noir is the U.S. Congress. We got half-way through processing their archives of video from congressional hearings, publishing about 31 terabytes of data. Then, a couple of staffers decided this was a bad idea and pulled the rug out from under us. They actually decided it was a bad idea to publish video from public congressional hearings.
Like any agency, Congress is a mixed bag. We had tons of support from Darrell Issa, for example, and ran a very successful pilot project for him for a year. We talked to all sorts of people on committees and in the various agencies that support the Congress. But, at the end of the day, a couple of staff members were able to decide that the public archive shouldn't be public and they terminated our project. (If you have some time, you might like to read our rather surreal paper trail.)
So, rather than the worst, I think we need to look for the most shameful, the ones that have the privilege and the power and could easily do better. I know it is in vogue to throw stones at government in general and Washington in particular, but there are times when government can be so useful and so awe inspiring it takes your breath away. Government can be that shining city on the hill but we all have to take an active part in our government to keep those lights shining bright. -
Google Updates Algorithm To Punish Websites With Excessive Ads
hypnosec writes "Google has decided to take punitive actions against those websites that flood the top of their web pages with ads due to which the visitors have to scroll down to finally view the relevant contents on the page. According to Google, this type of layouts annoys the users and thus the web search company will be penalizing those websites through search results. The company disclosed this on its blog. According to Google over the top ads is not good for user experience and thus such websites might not get high ranking on Google web search." -
Google Kills More Services, Open Sources Sky Map
alphadogg writes "Google is continuing to weed out its services and on Friday announced it will shut down Picnik, Google Message Continuity and Needlebase and make changes to some other services. Google acquired Seattle-based Picnik in 2010, saying it would integrate the photo editing service with its own Picasa. 'We're retiring the service on April 19, 2012, so the Picnik team can continue creating photo-editing magic across Google products,' Dave Girouard, vice president of product management for Google, wrote in a blog post Friday." A positive change to come out of this is that Google is open-sourcing Sky Map, and will be collaborating with Carnegie Mellon University to continue development. -
Google Kills More Services, Open Sources Sky Map
alphadogg writes "Google is continuing to weed out its services and on Friday announced it will shut down Picnik, Google Message Continuity and Needlebase and make changes to some other services. Google acquired Seattle-based Picnik in 2010, saying it would integrate the photo editing service with its own Picasa. 'We're retiring the service on April 19, 2012, so the Picnik team can continue creating photo-editing magic across Google products,' Dave Girouard, vice president of product management for Google, wrote in a blog post Friday." A positive change to come out of this is that Google is open-sourcing Sky Map, and will be collaborating with Carnegie Mellon University to continue development. -
Endoscopic Exam of Fukushima Reactor
mdsolar writes with this excerpt from the Sydney Morning Herald: "Radiation-blurred images taken inside one of Japan's tsunami-hit nuclear reactors show steam, unidentified parts and rusty metal surfaces scarred by 10 months of exposure to heat and humidity. The photos — the first inside-look since the disaster — showed none of the reactor's melted fuel or its cooling water but confirmed stable temperatures and showed no major ruptures caused by the earthquake last March, said Junichi Matsumoto, spokesman for plant operator Tokyo Electric Power Company." Here's a video. -
Ask Slashdot: What Can You Do About SOPA and PIPA?
Wednesday is here, and with it sites around the internet are going under temporary blackout to protest two pieces of legislation currently making their way through the U.S. Congress: the Stop Online Piracy Act (SOPA) and the Protect-IP Act (PIPA). Wikipedia, reddit, the Free Software Foundation, Google, the Electronic Frontier Foundation, imgur, Mozilla, and many others have all made major changes to their sites or shut down altogether in protest. These sites, as well as technology experts (PDF) around the world and everyone here at Slashdot, think SOPA and PIPA pose unacceptable risks to freedom of speech and the uncensored nature of the internet. The purpose of the protests is to educate people — to let them know this legislation will damage websites you use and enjoy every day, despite being unrelated to the stated purpose of both bills. So, we ask you: what can you do to stop SOPA and PIPA? You may have heard the House has shelved SOPA, and that President Obama has pledged not to pass it as-is, but the MPAA and SOPA-sponsor Lamar Smith (R-TX) are trying to brush off the protests as a stunt, and Smith has announced markup for the bill will resume in February. Meanwhile, PIPA is still present in the Senate, and it remains a threat. Read on for more about why these bills are bad news, and how to contact your representative to let them know it.
Note: This will be the last story we post today until 6pm EST in protest of SOPA. Why is it bad?
The Stop Online Piracy Act is H.R.3261, and the Protect-IP Act is S.968.
The intent of both pieces of legislation is to combat online piracy, giving the Attorney General and the Department of Justice power to block domain name services and demand that links be stripped from sites not involved in piracy. The problem is that the legislation, as written, is vague and overly-broad. For one thing, it classifies internet sites as "foreign" or "domestic" based entirely on their domain name. A site hosted abroad like Wikileaks.org could be classified as "domestic" because the .org TLD is registered through a U.S. authority. By defining it as "domestic," Wikileaks would then fall under the jurisdiction of U.S. laws. Other provisions are worded even more poorly: in Section 103, SOPA lays out the definition for a "foreign infringing site" as one where "the owner or operator of such Internet site is committing or facilitating the commission of criminal violations punishable under [provisions relating to counterfeiting and copyright infringement]." The problematic word is facilitating, as it opens the door to condemning sites that simply link to other sites.
The most obvious implication of this is that search engines would suddenly be responsible for monitoring and policing everything they index. Google indexed its trillionth concurrent URL in 2008. Can you imagine how many people it would take to double check all of them for infringing content? But the job wouldn't end at simply looking at them — Google would have to continually monitor them. Google would also have to somehow keep track of the billions of new sites that spring up daily, many of which would be trying to avoid close scrutiny. Of course, it's an impossible task, so there would need to be automated solutions. Automation being imperfect, it would leave us with false positives. Or perhaps sites would need to be "approved" to be listed. Either way, we'd then be dealing with censorship on a massive scale, and the infringing sites themselves would continue to pop up.
But the problems don't end there; in fact, SOPA defines "Internet search engine" as a service that "searches, crawls, categorizes, or indexes information or Web sites available elsewhere on the Internet" and links to them. That's pretty much what we do here at Slashdot. It's also something the fine folks at Wikipedia and reddit do on a regular basis. The strength of all three sites is that they're heavily dependent on user-generated content. Every day at Slashdot, readers deposit hundreds and hundreds of links into our submissions bin. Thousands of comments are made daily. We have a system to surface the good content, but the chaff still exists. If we suddenly had a mandate to retroactively filter out all the links to potentially copyright-infringing sites in our database, we wouldn't have many options. We're talking about reviewing hundreds of thousands of submissions, and every comment on 117,000+ stories. And we're far from the biggest site around — imagine social networks needing to police their content, and all the privacy issues that would raise.
Small sites and new sites would be hurt, too. A website isn't a single, discrete entity that exists on its own. A new company starting up a site would have to worry about its webhost, registrar, content provider, ISP, etc. The legislation would also raise significant financial obstacles. New companies need investments, and that would be much less likely (PDF) if the company could be held liable for content uploaded by users. On top of that, if the site was unable to live up to the vague standards set by the government and the entertainment industry, they could be on the receiving end of a lawsuit, which would be expensive to fight even if they won (and such laws would never, ever be abused). It's hard to conceptualize the internet without noting its unrivaled growth, and SOPA/PIPA would surely stifle it.
This legislation hits near and dear to the hearts of many Slashdotters; if SOPA/PIPA pass, IT staff for companies small and large are going to have their hands full making sure they aren't opening themselves to legal action or government intervention. Mailing lists, used commonly and extensively among open source software projects, would be endangered. Code repositories would need be scoured for infringing content; the bill allows for the strangling of revenue sources if its anti-infringement rules aren't being met. VPN and proxy services become only questionably legal. The very nature of the open source community — as the EFF puts it, "decentralized, voluntary, international" — is not compatible with the burdens placed on internet sites by SOPA and PIPA.
What can we do?
So, what can we do about it? There are two big things: contact your representative, and spread the word. Slashdot readers, on the whole, are more technically-minded than the average internet user, so you're all in a position to share your wisdom with the less internet-savvy people in your life, and get them to contact their representative, too. Here's some useful information for doing so:
Propublica has a list of all SOPA/PIPA supporters and opponents.
Here is the Senate contact list and the House contact list.
You can also use the EFF's form-letter, the Stop American Censorship form-letter, or sign Google's petition.
If you don't live in the U.S., you can petition the State Department. (And yes, you have a dog in this fight.)
SOPAStrike has a list of companies participating in the protest, and this crowd-sourced Google Doc tracks companies that support the legislation. Tell those companies what you think.
Further reading: Wikipedia has left their SOPA and PIPA pages up. The EFF has a series of articles explaining in more depth what is wrong with the bills. Here are some protest letters written to Congress from human rights groups, law professors, and internet companies.
Go forth and educate. -
Ask Slashdot: What Can You Do About SOPA and PIPA?
Wednesday is here, and with it sites around the internet are going under temporary blackout to protest two pieces of legislation currently making their way through the U.S. Congress: the Stop Online Piracy Act (SOPA) and the Protect-IP Act (PIPA). Wikipedia, reddit, the Free Software Foundation, Google, the Electronic Frontier Foundation, imgur, Mozilla, and many others have all made major changes to their sites or shut down altogether in protest. These sites, as well as technology experts (PDF) around the world and everyone here at Slashdot, think SOPA and PIPA pose unacceptable risks to freedom of speech and the uncensored nature of the internet. The purpose of the protests is to educate people — to let them know this legislation will damage websites you use and enjoy every day, despite being unrelated to the stated purpose of both bills. So, we ask you: what can you do to stop SOPA and PIPA? You may have heard the House has shelved SOPA, and that President Obama has pledged not to pass it as-is, but the MPAA and SOPA-sponsor Lamar Smith (R-TX) are trying to brush off the protests as a stunt, and Smith has announced markup for the bill will resume in February. Meanwhile, PIPA is still present in the Senate, and it remains a threat. Read on for more about why these bills are bad news, and how to contact your representative to let them know it.
Note: This will be the last story we post today until 6pm EST in protest of SOPA. Why is it bad?
The Stop Online Piracy Act is H.R.3261, and the Protect-IP Act is S.968.
The intent of both pieces of legislation is to combat online piracy, giving the Attorney General and the Department of Justice power to block domain name services and demand that links be stripped from sites not involved in piracy. The problem is that the legislation, as written, is vague and overly-broad. For one thing, it classifies internet sites as "foreign" or "domestic" based entirely on their domain name. A site hosted abroad like Wikileaks.org could be classified as "domestic" because the .org TLD is registered through a U.S. authority. By defining it as "domestic," Wikileaks would then fall under the jurisdiction of U.S. laws. Other provisions are worded even more poorly: in Section 103, SOPA lays out the definition for a "foreign infringing site" as one where "the owner or operator of such Internet site is committing or facilitating the commission of criminal violations punishable under [provisions relating to counterfeiting and copyright infringement]." The problematic word is facilitating, as it opens the door to condemning sites that simply link to other sites.
The most obvious implication of this is that search engines would suddenly be responsible for monitoring and policing everything they index. Google indexed its trillionth concurrent URL in 2008. Can you imagine how many people it would take to double check all of them for infringing content? But the job wouldn't end at simply looking at them — Google would have to continually monitor them. Google would also have to somehow keep track of the billions of new sites that spring up daily, many of which would be trying to avoid close scrutiny. Of course, it's an impossible task, so there would need to be automated solutions. Automation being imperfect, it would leave us with false positives. Or perhaps sites would need to be "approved" to be listed. Either way, we'd then be dealing with censorship on a massive scale, and the infringing sites themselves would continue to pop up.
But the problems don't end there; in fact, SOPA defines "Internet search engine" as a service that "searches, crawls, categorizes, or indexes information or Web sites available elsewhere on the Internet" and links to them. That's pretty much what we do here at Slashdot. It's also something the fine folks at Wikipedia and reddit do on a regular basis. The strength of all three sites is that they're heavily dependent on user-generated content. Every day at Slashdot, readers deposit hundreds and hundreds of links into our submissions bin. Thousands of comments are made daily. We have a system to surface the good content, but the chaff still exists. If we suddenly had a mandate to retroactively filter out all the links to potentially copyright-infringing sites in our database, we wouldn't have many options. We're talking about reviewing hundreds of thousands of submissions, and every comment on 117,000+ stories. And we're far from the biggest site around — imagine social networks needing to police their content, and all the privacy issues that would raise.
Small sites and new sites would be hurt, too. A website isn't a single, discrete entity that exists on its own. A new company starting up a site would have to worry about its webhost, registrar, content provider, ISP, etc. The legislation would also raise significant financial obstacles. New companies need investments, and that would be much less likely (PDF) if the company could be held liable for content uploaded by users. On top of that, if the site was unable to live up to the vague standards set by the government and the entertainment industry, they could be on the receiving end of a lawsuit, which would be expensive to fight even if they won (and such laws would never, ever be abused). It's hard to conceptualize the internet without noting its unrivaled growth, and SOPA/PIPA would surely stifle it.
This legislation hits near and dear to the hearts of many Slashdotters; if SOPA/PIPA pass, IT staff for companies small and large are going to have their hands full making sure they aren't opening themselves to legal action or government intervention. Mailing lists, used commonly and extensively among open source software projects, would be endangered. Code repositories would need be scoured for infringing content; the bill allows for the strangling of revenue sources if its anti-infringement rules aren't being met. VPN and proxy services become only questionably legal. The very nature of the open source community — as the EFF puts it, "decentralized, voluntary, international" — is not compatible with the burdens placed on internet sites by SOPA and PIPA.
What can we do?
So, what can we do about it? There are two big things: contact your representative, and spread the word. Slashdot readers, on the whole, are more technically-minded than the average internet user, so you're all in a position to share your wisdom with the less internet-savvy people in your life, and get them to contact their representative, too. Here's some useful information for doing so:
Propublica has a list of all SOPA/PIPA supporters and opponents.
Here is the Senate contact list and the House contact list.
You can also use the EFF's form-letter, the Stop American Censorship form-letter, or sign Google's petition.
If you don't live in the U.S., you can petition the State Department. (And yes, you have a dog in this fight.)
SOPAStrike has a list of companies participating in the protest, and this crowd-sourced Google Doc tracks companies that support the legislation. Tell those companies what you think.
Further reading: Wikipedia has left their SOPA and PIPA pages up. The EFF has a series of articles explaining in more depth what is wrong with the bills. Here are some protest letters written to Congress from human rights groups, law professors, and internet companies.
Go forth and educate. -
June 6 Is World IPv6 Day 2012: This Time For Keeps
An anonymous reader writes "On 8 June 2011 many companies (big and small) enabled IPv6 to their main web sites by published AAAA records; 24 hours later, almost all of them disabled it after the test was done. This year, on June 6th, many of those same companies (Google, Bing, Facebook) will be enabling IPv6 again, but this time there won't be any going back. In addition to content providers, several ISPs are also participating: Comcast, AT&T, XS4ALL, KDDI, and others. CDNs Akamai and Limelight are on board, as well as network equipment manufacturers Cisco and D-Link. Is the chicken-and-egg problem of IPv6 finally, slowly coming to an end?" -
Radioactive Concrete From Fukushima Found In New Construction
mdsolar writes "The Japanese government is investigating how radioactive concrete ended up in a new apartment complex in the Fukushima Prefecture, housing evacuees from a town near the crippled nuclear plant. The contamination was first discovered when dosimeter readings of children in the city of Nihonmatsu, roughly 40 miles from the reactors at Fuksuhima Dai-ichi, revealed a high school student had been exposed to 1.62 millisieverts in a span of three months, well above the annual 1 millisievert limit the government has established for safety reasons." -
Google TV 2.0 Review, Tweaks, and Screenshots
DeviceGuru writes "Google and its Google TV 2.0 partners made quite a splash at CES this week. As a followup, this detailed blog post at DeviceGuru reviews Google TV 2.0's features, specs, apps, and flexible new user interface, and shows how you can add customized folders and shortcuts to the home screen for accessing hundreds of favorite apps and websites within a couple of mouse clicks." -
Google Giving Google TV Another Shot
MrSeb writes with a piece on Google's renewed push for Google TV adoption. From the article: "In spite of a mediocre launch caused by an overpriced device and low consumer adoption, Mountain View is attempting to breathe life into Google TV in the way of a major marketing push at CES 2012. By announcing partnerships with companies like Marvell and LG, and an effort to cut costs by switching to ARM architecture, Google is hoping to finally achieve the mass adoption it has been hoping for with the service. Is this a case of too little, too late?" -
Newspaper Articles Not Copyrightable In Slovakia
Yenya writes "In Slovakia, newspaper articles can be freely aggregated and archived, and are not worth copyright protection. The district court in Bratislava, Slovakia, stated in the case between news publishing house Ecopress and a news monitoring company Storin, that while the news articles manifests traces of creativity, it is not enough to be considered worth protecting the authors rights (English translation)." -
Where Were the Robots In Fukushima Crisis?
mdsolar writes "When the huge Fukushima nuclear disaster first started, many on Slashdot were calling for robots to come to the rescue. This is the story of why our overlords were caught napping. Not to worry though, ¥1 billion has been allocated to correct the robot problem. They will be properly welcomed." -
Why Fuel Efficiency Advances Haven't Translated To Better Gas Mileage
greenrainbow tips an article about a research paper from an MIT economist that attempts to explain why technological advances in fuel efficiency haven't led to substantially better gas mileage for the average driver. Quoting: "Thus if Americans today were driving cars of the same size and power that were typical in 1980, the country’s fleet of autos would have jumped from an average of about 23 miles per gallon (mpg) to roughly 37 mpg, well above the current average of around 27 mpg. Instead, Knittel says, 'Most of that technological progress has gone into [compensating for] weight and horsepower.' ... Indeed, Knittel asserts, given consumer preferences in autos, larger changes in fleet-wide gas mileage will occur only when policies change, too. 'It’s the policymakers’ responsibility to create a structure that leads to these technologies being put toward fuel economy,' he says. Among environmental policy analysts, the notion of a surcharge on fuel is widely supported. 'I think 98 percent of economists would say that we need higher gas taxes,' Knittel says." -
Holo Theme Is Now Mandatory For Android Devices
tripleevenfall writes in about the new theme changes in Android 4.0. From the article: "Starting with Android 4.0, support for the 'Holo' theme will be mandatory for phones and tablets that have the Android Market installed. Holo is the stock Android theme, known for its sharp angles, thin lines and blue hue. Third-party developers can now create apps and widgets using the default Android aesthetic, knowing that's how it'll look on every major Ice Cream Sandwich device that has the Android Market. " This is not banning custom themes; instead it is merely giving developers a consistent theme that is guaranteed to be installed if they want a consistent look across all devices. There are even a few improvements to the style protocol to help developers deal with dark and light themes. -
The Semantic Line Interface
First time accepted submitter yuriyg_ua writes "[The] semantic line interface may combine features of both command line and graphical interface, which would allow even more complex applications than we have seen before." The idea is that the layer underlying user interfaces should define the semantic relations between data enabling the UI to provide better contextual information. Kind of a modern version of the CLIM presentation system. -
Google Health's Lifeline Runs Out
turing0 writes "As a former bioinformatics researcher and CTO I have some sad news to start 2012 with. Though I am sure not a surprise to the Slashdot crowd, it appears we — or our demographic — made up more than 75% of the Google Health userbase. Today marks the end of Google Health. (Also see this post for the official Google announcement and lame excuse for the reasoning behind this myopic decision.) The decision of Google to end this excellent service is a fantastic example of what can represent the downside of cloud services for individuals and enterprises. The cloud is great when and while your desired application is present — assuming it's secure and robust — but you are at the mercy of the provider for longevity." (Read more, below.) turing0 continues: "I am surprised to see Google abandoning Google Health just when we can see the benefit to personal health when micro sensors such as the Nike Plus and Jawbone's UP bracelet are entering the market. Greater amounts of personal health data can be gathered now via smartphone and then turned into valuable preventative as well as useful diagnostic medical information.
Shuttering Google Health is a surprising and short-sighted decision on Google's behalf, IMHO. Perhaps closing the Google Health service is not 'Evil' per se — but given the immense magnitude of financial resources at Google I cannot believe Google Health will make a decimal place of impact on Google's operating costs. Services like Google Health are a fantastic public relations tool as well as an amazing potential source of raw scientific data if nothing else.
In closing, it's very funny to note Google suggests Google Health users migrate GH data to the Microsoft Health Vault. Hopefully some Web service other than Health Vault will rise from the ashes of Google Health. The real benefit in terms of Google being a custodian of my health and wellness records via Google Health was that Google as a corporation is considered a trustworthy intermediary by most users and health care professionals. Now I am not so sure; perhaps it's time to re-claim my email ..." -
Vision and Sound From the Ideally Bare Numeric Impression giZmo
jones_supa writes "Ville 'viznut' Heikkilä presents us with an interesting project. 'As demonstrated by the video, IBNIZ (Ideally Bare Numeric Impression giZmo) is a virtual machine and a programming language that generates video and audio from very short strings of code. Technically, it is a two-stack machine somewhat similar to Forth, but with the major exception that the stack is cyclical and also used at an output buffer.' The main goal of IBNIZ is to provide a new platform for the demoscene. Something that would have the potential to displace MS-DOS as the primary platform for sub-256-byte productions." -
Actual Damages For 1 Download = Cost of a 1 License
NewYorkCountryLawyer writes "In Real View v 20-20 Technologies, it was held that the actual copyright infringement damages for a single unauthorized download of a computer program was the lost license fee that would have been charged. The judge, in the District Court of Massachusetts, granted remittitur, reducing the jury's verdict from $1,370,590.00 to $4200 unless the plaintiff seeks a new trial. Something tells me the plaintiff will seek a new trial." -
Actual Damages For 1 Download = Cost of a 1 License
NewYorkCountryLawyer writes "In Real View v 20-20 Technologies, it was held that the actual copyright infringement damages for a single unauthorized download of a computer program was the lost license fee that would have been charged. The judge, in the District Court of Massachusetts, granted remittitur, reducing the jury's verdict from $1,370,590.00 to $4200 unless the plaintiff seeks a new trial. Something tells me the plaintiff will seek a new trial." -
Court Rules Website Immune From Suit For Defamatory Posting
NewYorkCountryLawyer writes "RipoffReport.com contained an admittedly defamatory posting, by one of its users, about a person who operated a Florida corporation providing addiction treatment services. Although the site was asked by the poster herself to remove the post, it refused. A Florida appeals court has ruled that the site is absolutely immune from suit (pdf), and cannot even be directed to remove the offending post, since under the Communications Decency Act (47 USC 230) 'no cause of action may be brought' against a provider of an "interactive computer service" based upon information provided by a 3rd party." -
Report Condemns Japan's Response To Nuclear Accident
mdsolar sends this quote from an article at the NY Times: "From inspectors who abandoned the Fukushima Daiichi nuclear power plant as it succumbed to disaster to a delay in disclosing radiation leaks, Japan's response to the nuclear accident caused by the March tsunami fell tragically short, a government-appointed investigative panel said on Monday. ... In particular, an erroneous assumption that an emergency cooling system was working led to an hours-long delay in finding alternative ways to draw cooling water to the plant, the report said. All the while, the system was not working, and the uranium fuel rods at the cores were starting to melt." -
Warner Bros Sued For Pirating Louis Vuitton Trademark
NewYorkCountryLawyer writes "You have to love a case where Warner Brothers, copyright maximalist extraordinaire, gets sued for 'piracy,' in this case for using a knock-off Louis Vuitton bag in a recent movie. This lawsuit has been described as 'awkward' for Warner; I have to agree with that characterization. Louis Vuitton's 22-page complaint (PDF) alleges that Warner Bros. had knowledge that the bag was a knock-off, but went ahead and used it anyway. Apparently Warner Bros. takes IP rights seriously only when its own IP rights are involved." -
The Chinese Town Where Old Christmas Lights Go
retroworks writes "Shanghai based reporter Adam Minter visits where recycled Christmas Tree lighting goes in China. Visiting Shijao, the town known as the Mecca for Christmas tree light recycling, he finds good news. The recycling practices in China have really cleaned up. Plastic casings, which were once burned, are now recycled into shoe soles in a wet process. Minter concludes that even if you try to recycle your wire in the U.S., the special equipment and processes for Christmas light recycling have been perfected in China 'to the benefit of the environment, and pocketbooks, in both countries.'" -
Taliban Seizes and Burns PCs, Cell Phones To Stop Obscenity
retroworks writes "As translated from Central Asia Online, Cellular News reports that militants from South Waziristan set ablaze about 300 cellular phones and a number of computers in Wana because the devices were allegedly used to spread obscene materials. Prior to taking the action, they gave everyone fair warning with 'leaflets.' 300 cell phones down, 5 or 6 billion to go. -
Apple Wins Injunction Banning Import of HTC Devices
Newly accepted submitter squish18 writes "All Things D reports that Apple has won an injunction banning the import of some HTC phones starting in April 2012. The ruling by the ITC stems from two claims of the '647 patent concerning software used to enter personal data in mobile devices. It is interesting to note that the ITC has also reversed previous rulings regarding regarding infringement of two other '647 claims, as well as patent '263 claims." It looks like Apple's victory is relatively minor. They lost claims on all patents except for one, and HTC/Google can work on implementing similar functionality in a non-infringing way. -
Moxie Marlinspike Answers Your Questions
A few weeks ago you asked security guru Moxie Marlinspike about all manner of security issues, being searched at the border, and how to come up with a good online name. He's graciously answered a number of your inquiries which you will find below. Who writes your paychecks?
SirGarlon
From your Web site it looks like you've worn a number of hats. How do you mainly earn your living by penetration testing, developing software as a contractor, or what? Or do you have a day job? (I won't ask where). Do you have any advice for software engineers seeking an independent career?
I was the CTO at WhisperSystems, which was just acquired by Twitter. In the past, I've done both contract and full-time software engineering work, and I've worked on boats and as a delivery captain. I've also spent a considerable amount of time being broke and living without money.
I don't think I have any particularly sage advice for software engineers looking to go independent, so I'll answer a different question: on a somewhat regular basis now, I receive inquiries from young people coming out of high-school or college, asking me what they should do to get started in their software or security career. My most common response is "don't do it." Or at least, not right now.
I think the biggest thing young people fail to realize is the interminable nature of a career. As a young person in the global north, your whole life is generally marked by periods with definite beginnings and endings: elementary school is 5 years, middle school is 3 years, high-school is 4 years. It's significant because when you're in high-school and hating the indignity of it all, there is at least a definite endpoint that you can look forward to. But if you're coming out of that, you might not fully comprehend that when you start a career, you're expected to do that... for the rest of your *life*! Don't be too anxious to jump into that, because it's not as different as what's come before as you might think.
A friend of mine recently quipped "most people working in software discovered technology before they discovered themselves." There are so many people in the industry working on projects without a real personal narrative as to *why* they're doing them, other than the intrinsic feeling that solving technical problems is fulfilling. There is a whole entrepreneurial scene in the Bay Area right now; I can understand the draw of building things, but the level of self-seriousness that people bring to something like a "customer loyalty" startup baffles me. Honestly, it's simply not true that this stuff is "changing the world," so don't be too concerned about missing out if you don't jump in as quickly as you can.
Please, don't spend your late teens or early twenties in front of your computer at a startup. If you're a young person, I think the very best thing you could do is get together with a group of friends and commit to a one year experiment in which the substantial part of your life will be focused on discovery and not be dedicated to wage work -- however that looks for you. Get an instrument, learn three chords, and go on tour; find a derelict boat and cross an ocean; hitchhike to Alaska; build a fleet of dirigibles; construct a UAV that will engage with the emerging local police UAVs; whatever -- but make it count.
security and society
xappax
In addition to being a very sharp security researcher, you seem to have a strong interest in issues of social and political control. What emerging security trends do you see as being most important or helpful for authoritarians (at home and abroad)? What security trends are most important for anti-establishment movements?
I'll mention a few things I think about:
1) A lot has been said from people like Clay Shirky about the horizontalizing effect of the internet. And while it's true that platforms have emerged on the internet which make horizontal coordination and communication possible, what's often glossed over is that the infrastructure of the internet itself is actually extremely hierarchical. I know this seems obvious, but it's not something that comes up in the dialog about this stuff very often. It's worth remembering that this is how things are currently structured, and that the dreams of the Clay Shirkies of the world can never be fully realized as long as that's true; especially since those in control of the infrastructure seem to be taking increasing notice of that fact.
2) It's also just more of what we've been seeing for years: the economics of "information capitalism" have created a world where data is for the most part unsellable, driving businesses towards surveillance and profiling of their users for targeted advertising as the only means of obtaining revenue. Perhaps this isn't so bad in itself, but it puts us in a dangerous position, because it means the data is there for the (very efficient) taking. This becomes a magnet for governments and attackers.
3) Security vulnerabilities have become more difficult to find and exploit. Rather than making things "secure," however, it's shifted the balance of who has access to these vulnerabilities. There are still plenty of dumb sqli bugs out there, but more and more it's shaping up to mean that those with the most money and resources will have access to the exploits, while everyone else will be vulnerable to them. Which is not the way I'd like to see it.
Hardware for the traveling hacker?
capnkr
I'd be interested to know more about the hardware and/or platform you use on a daily/regular basis to do your work/research. I would assume that with your 'itinerant' lifestyle you have had to make choices and compromises in this area. IIRC, you "temporarily bought" ;) a laptop to edit Hold Fast, but that isn't something you do on a regular basis is it? Are there any suggestions/tips/tricks about hardware or methods that you'd care to share for the traveling hacker with the above in mind?
As an aside - Thanks for all the good work and entertaining tales! :) Been using that Capt's license much lately?
I secretly hate technology, so I actually have a mostly boring setup. I just run Linux on a laptop, which I replace about every eight years. I'm pretty stubborn about making a laptop last; the one I have now has cooling problems, so every time I do a long compile I have to find an ice pack to put under it. In some small way, it probably makes me feel like my computer is accomplishing something really difficult.
Every once in a while I'll need to do something creative if my setup isn't cutting it. So yeah, it's true that I edited Hold Fast on a nice machine with a 14 day return policy. =)
These days I can't travel internationally without CBP wanting to search (or failing that, confiscate) my electronics on my return to the US. So I just don't travel with them if I'm leaving the country.
As for the captain's license, I still get out every now and then, but rarely make deliveries. There's an anarchist yacht clubb convergence happening in Guatemala at the end of February.
WhisperCore
dark_requiem
I really like the idea behind WhisperCore. The problem, as I see it, is that it's only available for two devices, and the Android source is updated regularly, making it difficult to keep WhisperCore up to date with the latest version of Android. Also, there are a wide variety of existing ROMs, each sporting its own array of features, but WhisperCore is the only one focusing on full-device encryption and a quality firewall interface. Given that security is becoming more critical on mobile devices, I would love to see WhisperCore's functionality integrated into every ROM. Have you given any consideration to integrating the WhisperCore project into an existing community such as CyanogenMod, or opening the source to build a community around WhisperCore? It would definitely help with making it available on more devices.
WhisperSystems was acquired by Twitter recently, so the answer to this question has changed a little for us. In general, though, we never saw WhisperCore as something that could be a pervasive aftermarket solution. We made it available on the Nexus devices with an aftermarket installer because we wanted to give something free to the security community and those devices make it easier with unlocked bootloaders. However, the bulk of our distribution efforts were spent trying to get the software through OEM channels, so that it would just appear on new devices.
CyanogenMod has done an excellent job of supporting a wide range of devices, but as you note, they are only able to do this because it's an open source project with enough volunteers to deal with all of the proprietary integration, build, and test issues. They only get access to the source after Google does public drops (that is to say, long after the rest of the industry does), and the device vagaries are endless. WhisperCore was a commercial product focused on the enterprise security market, and that market isn't particularly interested in reflashing ROMs onto their employee's phones. We were simply making it available in that form so that individuals could benefit from our work, but it wasn't our main focus. The other integration problem with CyanogenMod is that they are not a security-focused community, and have actually done a number of things to reduce the security of the platform (which is a shame, since the bar was low to begin with). So the interests of our user bases are fairly distinct, and actually in conflict on some important points.
WhisperCore - why not OSS?
nullchar
Are there business or technical reasons you do not want to open the source code for WhisperCore or any of the sub-projects like WhisperMonitor?
Same reason most enterprise software vendors' products aren't OSS, harder to sell software that way. =)
CarrierIQ nnet
Does Whisper Monitor stop CarrierIQ as well?
Haven't tested it, but it should. That said, it doesn't come with WhisperCore, so it seems unlikely that you'd encounter it on a device with WhisperMonitor.
Thoughts on TLS-SRP as a partial solution?
WaffleMonster
Most secure sites we normally depend on require you to establish an account. Rather than sending our passwords in the "clear" over SSL as everyone is foolishly doing today couldn't part of this problem be solved using trust previously established between you and the site in the form of mutually authenticated credentials?
The best case example would be an online banking site first requiring you to physically come into the office with proper ID. There would no longer be any need for this bank to need to trust or use any third party.
TLS-SRP RFCs have already been written, SSL stacks used by all popular browsers already patched with support... obviously this does not fully eliminate the need for trusted third parties.
I think these types of approaches are interesting for things like SSH, IMAPS, and SMTPS. The way that webapps tend to be architected and deployed, however, makes this tricky.
of trust versus online consensus
DamnStupidElf
PGP provides a model for partial trust in a public key based on the trust placed in signers of that key. I think a similar model would work much better for SSL certificates than either the current forest of fully trusted root CAs or projects like Convergence because it would allow long term trust in entities instead of merely the ephemeral keys used for SSL connections while also providing offline security and the ability to separate the keys used for privacy and identification.
If I wanted to validate the hypothetically secure https://slashdot.org/ I would be happy seeing an SSL certificate signed by Geeknet's PGP key (assuming they cared enough to be in the strong set), but even happier if it was also signed by a couple certificate authorities and some other folks in the strong set. I would assign partial trust to each of the certificate authorities' root certificates and use PGP to measure the partial trust of other signatures and set a threshold for the security of any SSL site, perhaps requiring "full trust" for automatic acceptance of an SSL certificate, a warning for marginal trust, and a bigger warning for anything less.
One of the primary advantages is separation of privacy and identification; the private key for identifying an entity would only be used to sign SSL certificates, reducing the likelihood of an attacker compromising an identity certificate. Notaries, as in Convergence, would simply be entities who sign a large number of SSL certificates after verifying the owner's identity through the existing trust network. The advantage for notaries is that they would not need to keep their private keys online and would only serve signatures. SSL sites could also just include the signatures in the initial SSL/TLS exchange, shifting bandwidth costs to the entities that benefit from the signatures. Site owners could also pre-distribute new SSL keys to certificate authorities and notaries to obtain signatures similar to the way that the existing PKI works, without relying on projects like Convergence to correctly identify a legitimate key change through heuristics.
The biggest advantage is a much more robust framework for trusting the privacy and identify of web sites. The likelihood of obtaining fraudulent SSL certificates signed by enough entities to achieve full trust is much lower than the likelihood of compromising a single fully trusted root CA or tricking a Convergence-style network into trusting a fraudulent SSL certificate by DNS poisoning or other methods.
Do you think this is a workable and, if so, good idea?
The MonkeySphere project is working on something quite similar to your proposal. Personally, I always have trouble with suggestions for bringing the "web of trust" to some new context, because I never found it workable in the context it was invented for. I use PGP more consistently for email than almost anyone else I know, and the truth is that I almost never find a new key with signatures that are meaningful to me.
While there are organizations and individuals I trust, there aren't thousands of them, and probably not even hundreds of them. I think that trust agility is essential to any solution moving forward, but as I see it trust agility requires two things:
1) The trust relationship has to be initiated by the client.
2) A trust decision can be easily revised at any time.
I don't believe that using WoT style signatures meets these requirements, at least in their most obvious form. In the WoT model, if I look up a certificate, I don't have any influence over who's chosen to sign it. I'm given the signatures I'm given, and that's that. If I decide to make it work by trusting some entity that has made it a habit to sign a bunch of certificates, untrusting them becomes difficult, because maybe the entity I'd really like to trust hasn't signed as many. And if it's a matter of manually evaluating the signatures I'm given for any site I visit, that sounds pretty unpalatable to me.
All that said, this idea is not incompatible with Convergence. Just build a MonkeySphere notary backend, and it'll plug right in alongside any other notary strategies you'd like to simultaneously query from your client. I anticipate that it would give you a lot of "stand aside" votes for the foreseeable future, however.
Is everyone just re-inventing _parts_ of the WoT?
Sloppy
It seemed to me that what Perspectives notaries do, as expressed in OpenPGP-speak, is act as sophisticated Robot CA. (Is this wrong?) Is a Convergence notary "merely" a more sophisticated Robot CA, or does it provide information which couldn't be represented in a Web of Trust?
Well, I dunno, on some level I think all knowledge can be expressed as simile through any particular domain of knowledge. It's important to remember that a Convergence notary isn't bound to any particular validation technique, meaning that not all notaries will use network perspective. I prefer to think of notaries as SSL Certificate Authorities with an inverted trust relationship. They're pretty similar, but rather than the server initiating the trust relationship, it's the client. It's a subtle but powerful change.
bootstrapping -- notary trust
Onymous Coward
Do you see the matter of how users come to trust the notaries themselves as a concern? What methods do you see for assuring users that a list of notaries is in fact recommended by a given party? I see notaries distributed with the Convergence plug-in (is the distribution signed?), but doubtlessly that's not meant as a steady-state solution as it does not promote trust agility.
Have you considered notary list configuration based on "subscriptions" a l AdBlock lists. For example, if the EFF periodically published a signed "EFF Trusted Notaries" list, as one of a number of organizations doing so?
And how much is a working web of trust required for this? Do you feel there is one?
Right now installing Convergence is a leap of faith, as is true for most software. I'm being intentionally inflammatory by making a point of not distributing it over SSL, because if you're installing it, you don't have it to validate your SSL connection yet. Once you have it, however, all updates are signed.
I don't actually see pre-distributed lists of trusted notaries as anathema to trust agility, however. It's nice for a user to be able to select who they trust, but it's also essential that browser vendors can revise those defaults as well. Right now that's not the case, and it means that a browser vendor's entire user base suffers.
I would like to imagine that one day browsers will ship with Convergence support built in, and that it will come with a list of default notaries that the browser has curated. If one of those notaries starts acting in bad faith, the browser can remove them. If you as a user would like to make different trust decisions, they can do that as well.
Notary subscription lists are a good idea. You can kind of do this with the HA Notary bundles right now, but it'd be better to break them out into a meta-bundle. In any case, the bundle auto-update logic is in there, so it wouldn't be too difficult (git pull requests gladly accepted!).
Switch from Perspectives?
Burz
I'm already using the Perspectives extension (and not sure what benefit I'm getting from that)... Why should I switch from Perspectives to Convergence?
Convergence is obviously inspired by Perspectives, but slightly more generalized (not tied to network perspective), and designed to address what I felt were shortcomings in the Perspectives protocol. The biggest differences are browser integration, notary lag, and privacy.
Perspectives doesn't work for any of the CSS/JS/Image content on a page load, only the initial GET. It will suffer from notary lag since it requires notaries to regularly poll target sites. And you'll leak your entire browsing history to notaries.
Choice of name?
Alioth
Completely unrelated to your work, but the name "Moxie Marlinspike" sounds wonderful. It's obvious why you chose "Marlinspike", after all as a sailor it's an object that you may have found useful (and it's not that uncommon to have a last name that is a tool or a trade). But the first name you chose - why did you choose it? Looking around for references to Moxie the most prominent one is for one of the earliest carbonated beverages sold in the world, which doesn't sound too probable as an origin.
Apparently the etymology of the word "moxie" is thought to originate with the soda, although there is some indication that it might have been a word from a native American language that meant "dark water." I actually know another person named Moxie in the Bay Area, and someone got us a six pack of Moxie Cola to split once. I couldn't even finish one!
I'd estimate that in roughly 1/3rd of the cases where I introduce myself to someone, they ask whether Moxie is my "real name." There are a few interesting things about this to me. First, apparently we're all so used to a limited pantheon of possible names that anything outside of it must be "not real." And second, that when people say "real," it seems that what they actually mean is "legal."
What's interesting to me about the corpus of "real sounding" names is that they're mostly drawn from the bible. The name my parents put on my birth certificate is "Matthew." For as long as I can remember, however, people have called me Moxie Marlinspike. There's obviously a story there, but it's actually not that interesting. In the end, it's just what stuck. I don't switch back to Matthew, however, because it's a biblical name. I'm not that inspired by the stories from the bible, so it feels counter-intuitive for me to literally identify with them. So while many people find my name "strange," what's more bemusing to me is that many of those same people *also* don't find the stories of the bible to be the major inspiration of their lives, and yet continue to be walking endorsements for them with every handshake.
The notion of "realness as legality" is interesting to me because it seems like it should be possible for reality to extend beyond whatever is defined by law, yet this seems to be the litmus in most people's minds. If I have a name which literally everyone in my life since childhood has known me by, it seems to me that this should be the definition of "reality," not whether the government (who, by contrast, has a pretty cold and distant relationship with me as far as acquaintances go) agrees. -
Technical Details Behind the LAN-Party Optimized House
New submitter Temporal writes "Yesterday, Slashdot reported on my LAN-party optimized house. But, lacking from the internet at that time were key technical details: How do I boot 12 machines off a single shared disk? What software do I use? What does my network infrastructure look like? Why do I have such terrible furniture? Is that Gabe Newell on the couch? The answer is a combination of Linux, PXE boot, gPXE, NBD/iSCSI, and LVM snapshots running on generic hardware over generic gigabit ethernet. I have even had several successful LAN parties with a pure-Linux setup, using WINE."
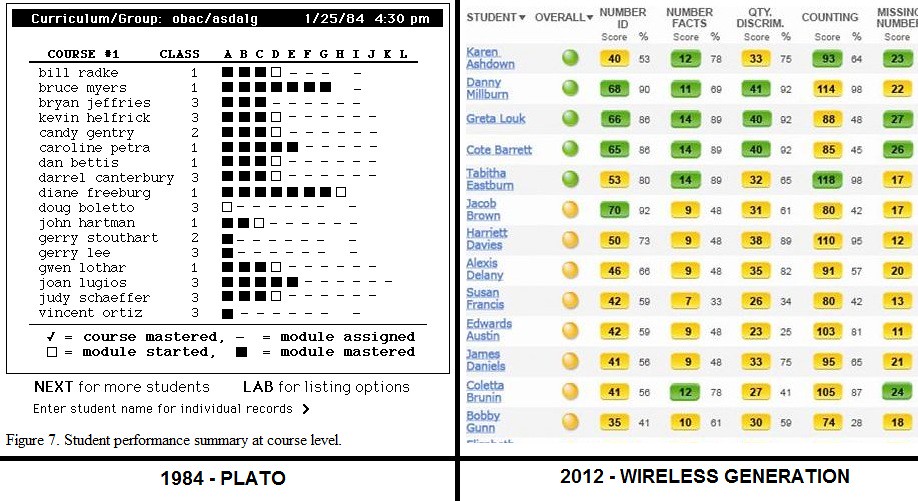{kind=link}