 Slashdot Mirror
Slashdot Mirror
Domain: oreilly.com
Stories and comments across the archive that link to oreilly.com.
Stories · 651
-
Critiquing Claims of an Open Source Jobs Boom
snydeq writes "InfoWorld's Bill Snyder examines what appears to be an open source job market boom, as evidenced by a recent O'Reilly Report. According to the study, 5 to 15 percent of all IT openings call for open source software skills, and with overall IT job cuts expected for 2009, 'the recession may be pushing budget-strapped IT execs to examine low-cost alternatives to commercial software,' Snyder writes. But are enterprises truly shifting to open source, or are they simply seeking to augment the work of staff already steeped in proprietary software? The study's methodology leaves too much room for interpretation, Savio Rodrigues retorts. 'That's why the 5% to 15% really doesn't sit well with me,' Rodrigues writes. 'I suspect that larger companies are looking for developers with a mix of experience with proprietary and open source products, tools and frameworks,' as opposed to those who would work with open source for 90 percent of the work day." -
VectorLinux SOHO 5.9 Deluxe Reviewed
An anonymous reader writes with a link to Caitlyn Martin's review of the Slackware-based Vector Linux SOHO 5.9 Deluxe: "I've read past reviews by other reviewers describing Vector Linux as 'better Slackware than Slackware' or 'what Slackware should be' and I always felt that was a bit of a stretch. With this release it isn't a stretch. You get all the reliability and stability of Slackware, better performance than vanilla Slack (at least on my hardware) and the features and most of the conveniences users of distributions touted as user friendly have come to expect." -
The Software Behind the Mars Phoenix Lander
chromatic writes "Imagine managing a million lines of code to send over seven hundred pounds of equipment millions of miles through space to land safely on Mars and perform dozens of experiments. You have C, 128 MB of RAM, and very few opportunities to retry if you get it wrong. O'Reilly News interviewed Peter Gluck, project software engineer for NASA's Mars Phoenix Lander, about the process of writing software and managing these constraints — and why you're unlikely to see the source code to the project any time soon." -
Web 2.0: A Strategy Guide
lamaditx writes "There is a good chance that you have heard about "Web 2.0" — the buzz-word coined by Tim O'Reilly in 2005. You will find several reviews of books about this topic on Slashdot. These cover mainly technical aspects of implementation whereas this book introduces the strategical thinking behind the whole Web 2.0 movement... Web 2.0 is so much more than the technology.' The table of contents is available from O'Reilly, together with a chapter preview. The book does not come with any extras but includes the usual free 45 days access to the book on Safari. When reading a book I usually flip through it quickly to get an impression for it, in this case there are three things which I noted right away." Keep reading for the rest of Adrian's review. Web 2.0: A Strategy Guide author Amy Shuen and Simon St. Laurent (editor) pages 266 publisher O'Reilly Media , Inc. rating 10 reviewer Adrian Lambeck ISBN 978-0-596-52996-3 summary Business thinking and strategies behind successful Web 2.0 implementations First, I was drawn by the the foreword by Tim O'Reilly. Since I have read his article about Web 2.0 back then I came to the conclusion that the strategy guide is a kind of successor. The next think I was looking at is information about the author. Amy Shuen concentrates on business models and teaches entrepreneurship, strategy, and venture finance on major business schools around the world. Amy is currently a Professor of Management Practice at the "China Europe International Business School" (CEIBS).
Secondly I noticed that there are a lot of footnotes on every page which reference other publications that fit the current topic. This is perfect if you want to drill into the details about a specific issue or lack some background knowledge.
The last thing I notice are the really big "End Notes" which spread across 40 pages and the bibliography which consists of 22 pages. This means that around a quarter of the book is additional information. I am pretty sure this fact is due to the academic roots of Amy Shuen and I think it is appropriate for this kind of guide. Actually this is what I expect from a guide — it should guide me through the topic and summarize the overall picture.
After flipping through the book I started reading it — and couldn't stop. I had to travel to Munich the other day — I boarded the plane with nothing else but the book and my boarding pass. I received the book on Thursday and finished reading it on Saturday.
Reading this book is fun for several reasons. I hate authors that put graphics into their books and don't provide you with additional information. That is not the case in this book, all the graphics are easily read (the only exception is a picture on page 5). Most graphics, functions, and screenshots are self explanatory. From my own experience I know it is not easy to find the right mixture between too much detail and too little.
Another important point are the numerous case studies in every chapter. Of course they do not include all information and details but they emphasize the theoretical point and provide you with a good feeling about the business case. Reading these kind of "historical" stories also adds some life to the book. Even though I have written a paper about Google's Page Rank algorithm and therefore a rough understanding of it, I learned many details about the competition between Google and GoTo (later known as Overture) that I did not know. It also teaches you that the effortless looking success of a company like Google involved tough times in the past. Running the Web 2.0 track is not always that easy as it looks like.
Talking about the big names: This book is interesting for anybody involved in a Web 2.0 (or escaping Web 1.0 ;-) ) environment no matter if you are working in a big, small, or start-up company. Amy stresses this point several times as she points out "Your business probably isn't Facebook, LinkedIn, or even something that looks much like them".
So how are you be able to transfer the knowledge you gained from the book to your own Web 2.0 concept? Amy to the rescue. Each chapter ends with a "Lessons Learned" section to summarize the most important points. After that she provides you with a section "Questions to Ask" which cover strategic and tactical issues with these tools at hand. The last chapter will also support you to "apply Web 2.0 strategic thinking to your business". Maybe you are writing a business plan or a project proposal to get your idea started. The last chapter will help.
In the end I would like to talk about the rating I am assigning to this book. I rated it as 10 which means it is "excellent" or one might call it a "classic work". I have not talked much about the content of the book because I did not want to provide you with a plain summary. I expect this book to become one of the "must-read" in business as well as technical classes since more and more business models will evolve in a Web 2.0 environment. Another reason is the well explained and easy to read writing style. Technical terminology is kept to a minimum thus not requiring a lot of prior knowledge.
Adrian Lambeck is a master student in "Information and Media Technologies" in Germany and thinks about starting his own (Web 2.0 ?) business.
You can purchase Web 2.0: A Strategy Guide from amazon.com. Slashdot welcomes readers' book reviews -- to see your own review here, read the book review guidelines, then visit the submission page. -
Head First C#
Michael J. Ross writes "For computer programmers who do not have a solid understanding of object-oriented programming (OOP), learning the C# programming language can be rather challenging, even if they have experience with C or C++, which at least would give them a head start over non-C programmers. Any developer in this situation may well want to begin the learning process with a book that aims to teach both OOP and C# in as gentle a manner as possible, with plenty of patient explanations and illustrative diagrams — such as those found in the book Head First C# by Andrew Stellman and Jennifer Greene." Read below for the rest of Michael's review. Head First C# author Andrew Stellman and Jennifer Greene pages 778 publisher O'Reilly Media rating 7/10 reviewer Michael J. Ross with Greg Hanson ISBN 0596514824 summary A heavily illustrated intro to object-oriented programming and C# Published by O'Reilly Media on 26 November 2007, under the ISBNs 0596514824 and 978-0596514822, Head First C# is one in a series of "Brain-Friendly Guides." The introduction to this particular book discusses how the series attempts to present the concepts and technical material in a way that is far more intellectually compelling and memorable than the approach currently taken by most books. Some of their guiding principles include: making things visual, oftentimes using novel and even outlandish diagrams; using a casual and conversational style; engaging the reader through exercises and questions; and spicing up the discussions with humor.
On the book's Web page, readers will find links to download the book's sample code, participate in a forum dedicated to the book, register their copy of the book, read and submit any errata (of which there are many), and submit a reader review and read those of other readers.
The book's material is organized into 15 chapters, covering the topics in a progressive order that would probably be most helpful for the inexperienced developer: the advantages to programming visual applications in C# and the Microsoft Visual Studio integrated development environment (IDE); building a simple application to get started; the C# code produced by Visual Studio; basic C# language constructs; an introduction to objects and their components; data types, including arrays and references, and how C# allows you to work with them; protecting an object's data from unintended access, through encapsulation; extending classes through inheritance and subclasses; finding and using class interfaces, and the advantages of doing so; storing data in arrays, lists, and dictionaries; saving data in files and directories, as well as working with file streams and serialization; exceptions and debugging techniques; event handling; how to build complex applications; creating user interfaces with controls and graphics; object destruction and garbage collection; and connecting your C# programs to databases using LINQ. Interspersed throughout the book are three C# labs, which encourage the reader to put into practice their new programming skills, and thus better internalize the ideas of OOP and C# covered in the chapters preceding each lab. The lab applications comprise a racetrack simulator, a simple adventure game, and a re-creation of Space Invaders.
When they see this book for the first time, some prospective readers may be overwhelmed by its size, clocking in at 778 pages. Yet a sizable portion of those pages will read faster than those of the typical programming book, largely due to all of the diagrams and whitespace, which really help to break up the material and make it more digestible. However, what many might perceive to be a strength of the book, could be seen as a weakness by others. In fact, if the unnecessary diagrams and redundant material were to be removed from the book, it might end up only half its current size. But this may only be a deterrent for people who are carrying this book around, or who tend to be impatient and wish to get right to the point of any book they are reading, or who may be upset by the extra trees chopped down to double the number of pages (the book does not appear to have been printed on recycled paper).
Despite Head First C# being clearly intended as an introductory book to object-oriented programming in general, and C# in particular, the target audience especially may be frustrated by all of the errata and other sources of confusion that they will encounter. This is especially true when readers are doing their best to implement all of the sample applications, and struggling when, for instance, the code does not match the figure provided, or even the code on another page. For example, on page 50, the authors instruct the reader to drag a new PictureBox onto a new form, but readers will probably struggle to figure out where to drag it from. On page 105, the authors instruct the reader to flip back and look through the code, to fill in some class diagrams, but they don't clarify what code should be considered. Readers' comments on the online bookseller sites, list far more similar problems. In fact, that there are so many technical errors in this book is quite remarkable given that the technical review team comprised no fewer than 14 individuals! How could so many eyeballs miss so much?
The authors make a real point of reviewing material explained earlier, which generally is an effective approach for this type of book. But the repetition sometimes becomes excessive — enough to annoy even the greenest novice. For example, on page 445, we find the question: "Okay, I still don't get it. Sorry. Why are there so many different kinds of exceptions, again?"
On the other hand, the book has some real strengths, including those mentioned above for making the material more approachable. In particular, when the reader becomes accustomed to the visual style of presenting concepts, he or she will probably find it a faster approach to learning the ideas. Admittedly, veteran developers may still prefer the more narrative style of conventional programming books — especially when they encounter rather convoluted diagrams, such as that on page 292. Yet the illustrations are particularly potent for explaining interfaces, as done in Chapter 7.
Although the book will be of most value to newer programmers, experienced C# programmers will find topics of interest and perhaps even some language details and analysis that they have never previously encountered. For instance, some of the questions posed in the sections titled "there are no Dumb Questions," could be valuable — such as the comparison of File versus FileInfo, and when to use one over the other. Also, some of the utilities could help the reader for future development, such as the hex dumper program on page 432.
Sadly, Head First C# is weighed down by excessive redundancy and an errata-to-number-of-technical-reviewers ratio possibly unequaled by any other programming book. Yet, for any programmer new to object orientation and C#, this introductory book should prove an extremely comprehensible and reader-friendly resource.
Michael J. Ross is a Web developer, writer, and freelance editor. Contributor Greg Hanson is a C# programmer in Fort Collins, Colorado.
You can purchase Head First C# from amazon.com. Slashdot welcomes readers' book reviews -- to see your own review here, read the book review guidelines, then visit the submission page. -
Building the Green Data Center
blackbearnh writes "O'Reilly News talked to Bill Coleman, former founder of BEA and current founder and CEO of Cassett Corporation, about the challenges involved in building more energy-efficient data centers. Coleman's company is trying to change the way resources in the data center are used, by more efficiently leveraging virtualization to utilize servers to a higher degree. In the interview, Coleman touches on this topic, but spends most of his time discussing how modern data centers grossly overcool and overdeploy hardware, leading to abysmal levels of efficiency." -
Building the Green Data Center
blackbearnh writes "O'Reilly News talked to Bill Coleman, former founder of BEA and current founder and CEO of Cassett Corporation, about the challenges involved in building more energy-efficient data centers. Coleman's company is trying to change the way resources in the data center are used, by more efficiently leveraging virtualization to utilize servers to a higher degree. In the interview, Coleman touches on this topic, but spends most of his time discussing how modern data centers grossly overcool and overdeploy hardware, leading to abysmal levels of efficiency." -
O'Reilly To Release DRM-free Ebooks In July
andrewsavikas writes "Starting in July, O'Reilly Media will pilot select books as DRM-free ebook bundles (PDF, EPUB, and Kindle-compatible Mobipocket) priced at or below the cover price of the book. David Pogue comments on the pilot in the wake of his own recent dustup about ebooks and piracy, covered previously on Slashdot." -
O'Reilly To Release DRM-free Ebooks In July
andrewsavikas writes "Starting in July, O'Reilly Media will pilot select books as DRM-free ebook bundles (PDF, EPUB, and Kindle-compatible Mobipocket) priced at or below the cover price of the book. David Pogue comments on the pilot in the wake of his own recent dustup about ebooks and piracy, covered previously on Slashdot." -
Inside the Internet Archives
blackbearnh writes "O'Reilly Media is running an interview with Gordon Mohr, Chief Technologist for the Internet Archive (archive.org). If you've ever wondered how pages are selected for archiving, or just how they manage such a huge quantity of data, the answers are here. The interview also touches on the problems of intellectual property in archives, archiving the Internet in a post Web 2.0 world, and the potential vulnerabilities exposed by archiving web sites that may include security exploits." -
Inside the Internet Archives
blackbearnh writes "O'Reilly Media is running an interview with Gordon Mohr, Chief Technologist for the Internet Archive (archive.org). If you've ever wondered how pages are selected for archiving, or just how they manage such a huge quantity of data, the answers are here. The interview also touches on the problems of intellectual property in archives, archiving the Internet in a post Web 2.0 world, and the potential vulnerabilities exposed by archiving web sites that may include security exploits." -
Bezos Buries Patent Office in Paper
theodp writes "On June 2nd, almost two-and-half years after the USPTO initiated a reexamination of Amazon CEO Jeff Bezos' 1-Click Patent, Amazon dumped another load of documents on the USPTO Examiner assigned to the case, asking for consideration of the 185 or so listed references and 'favorable action.' Peter Calveley, the LOTR actor whose do-it-yourself legal effort prompted the reexam, notes that he was cc'ed on 20 kg of documents that Amazon sent earlier to the USPTO as it tried to stave off last October's nonfinal rejection of all but 5 of Amazon's 26 1-Click patent claims. So much for Bezos' 2000 pledge of 'less work for the overworked Patent and Trademark Office.'" -
Brian Aker On the Future of Databases
blackbearnh recommends an interview with MySQL Director of Technology Brian Aker that O'Reilly Media is running. Aker talks about the merger of MySQL with Sun, the challenges of designing databases for a SOA world, and what the next decade will bring as far as changes to traditional database architecture. Audio is also available. From the interview: "I think there's two things right now that are pushing the changes... The first thing that's going to push the basic old OLCP transactional database world, which... really hasn't [changed] in some time now — is really a change in the number of cores and the move to solid state disks because a lot of the... concept around database is the idea that you don't have access to enough memory. Your disk is slow, can't do random reads very well, and you maybe have one, maybe eight processors but... you look at some of the upper-end hardware and the mini-core stuff,... and you're almost looking at kind of an array of processing that you're doing; you've got access to so many processors. And well the whole story of trying to optimize... around the problem of random I/O being expensive, well that's not that big of a deal when you actually have solid state disks. So that's one whole area I think that will... cause a rethinking in... the standard Jim Gray relational database design." -
Brian Aker On the Future of Databases
blackbearnh recommends an interview with MySQL Director of Technology Brian Aker that O'Reilly Media is running. Aker talks about the merger of MySQL with Sun, the challenges of designing databases for a SOA world, and what the next decade will bring as far as changes to traditional database architecture. Audio is also available. From the interview: "I think there's two things right now that are pushing the changes... The first thing that's going to push the basic old OLCP transactional database world, which... really hasn't [changed] in some time now — is really a change in the number of cores and the move to solid state disks because a lot of the... concept around database is the idea that you don't have access to enough memory. Your disk is slow, can't do random reads very well, and you maybe have one, maybe eight processors but... you look at some of the upper-end hardware and the mini-core stuff,... and you're almost looking at kind of an array of processing that you're doing; you've got access to so many processors. And well the whole story of trying to optimize... around the problem of random I/O being expensive, well that's not that big of a deal when you actually have solid state disks. So that's one whole area I think that will... cause a rethinking in... the standard Jim Gray relational database design." -
Full Disclosure and Why Vendors Hate It
An anonymous reader writes "Well known iPhone hacker Jonathan Zdziarski gave a talk at O'Reilly's Ignite Boston 3 this week in which he called for the iPhone hacking community to embrace full disclosure and stop keeping secrets that were leading to the iPhone's demise. He has followed up with an article about full disclosure and why vendors hate it. He argues that vendor-only disclosure protects the vendors and not the consumer, and that vendors easily abuse this to downplay privacy concerns while continuing to sell insecure products. In contrast, he paints full disclosure as a capitalist means to keep the vendor accountable, and describes how public outcry can be one of the best motivating factors to get a vulnerability addressed." -
MySQL Reverses Decision On Closed Source
krow writes "I am very happy to be announcing that MySQL will be forgoing close sourcing portions of the MySQL Server. Kaj has the official statement in his blog. No portion of the server will be closed source including backup, encryption, or any storage engines we ship. To quote Kaj 'The encryption and compression backup features will be open source.' This is a change from what was previously posted here on Slashdot. I've posted some additional thoughts on my own blog concerning how we keep open source from becoming crippleware. Word has it that we will also have a panel at this year's OSCON discussing this topic. Contrary to the previous Slashdot discussion, this shows Sun's continued commitment to Open Source." -
Call For Open Source Awards 2008 Nominations
chromatic writes "Google and O'Reilly have published the Call For Open Source Awards 2008 Nominations. These awards, given at OSCON 2008, recognize individual contributors who have demonstrated exceptional leadership, creativity, and collaboration in the development of open source software. The nomination process is open to the entire open source community, and nominations close on May 15. Here's your chance to sing the praises of previously unsung hackers." -
Call For Open Source Awards 2008 Nominations
chromatic writes "Google and O'Reilly have published the Call For Open Source Awards 2008 Nominations. These awards, given at OSCON 2008, recognize individual contributors who have demonstrated exceptional leadership, creativity, and collaboration in the development of open source software. The nomination process is open to the entire open source community, and nominations close on May 15. Here's your chance to sing the praises of previously unsung hackers." -
An IM Patent for the iPhone?
Ian Lamont writes "Apple has filed a patent for IM on portable devices, which could mean that it's getting ready to launch an IM client for the iPhone. The filing is titled 'Portable Electronic Device for Instant Messaging', and covers methods for sending, receiving, and viewing ongoing conversations. The proposed GUI is similar to Apple's current interface for SMS. As for why iChat wasn't enabled for the iPhone earlier, there's some interesting background and analysis here, which also includes a discussion of AIM for the iPhone. IM also came up in the discussions last year about the most-wanted features in iPhone 2.0." -
Regular Expression Pocket Reference
Michael J. Ross writes "When software developers need to manipulate text programmatically — such as finding all substrings within some text that match a particular pattern — the most concise and flexible solution is to use "regular expressions," which are strings of characters and symbols that can look anything but regular. Nonetheless, they can be invaluable for locating text that matches a pattern (the "expression"), and optionally replacing the matched text with new text. Regular expressions have proven so popular that they have been incorporated into most if not all major programming languages and editors, and even at least one Web server. But each one implements regular expressions in its own way — which is reason enough for programmers to appreciate the latest edition of Regular Expression Pocket Reference, by Tony Stubblebine." Read below for the rest of Michael's review. Regular Expression Pocket Reference, Second Edition author Tony Stubblebine pages 126 publisher O'Reilly Media rating 9/10 reviewer Michael J. Ross ISBN 0596514271 summary A pithy guide to regular expressions in many languages. The second edition of the book was published by O'Reilly Media on 18 July 2007, under the ISBNs 0596514271 and 978-0596514273. On the book's Web page, the publisher makes available the book's table of contents and index, as well as links for providing feedback and any errata. As of this writing, there are no unconfirmed errata (those submitted by readers but not yet checked by the author to see whether they are valid), and no confirmed ones, either. In fact, in my review of the first edition, published in 2004, it was noted that there were no unconfirmed errata, despite the book being out for some time prior to that review. The most likely explanation is that the author — in addition to any technical reviewers — did a thorough job of checking all of the regular expressions in the book, along with the sample code that make use of them. These efforts have paid off with the apparent absence of any errors in this new edition — something unseen in any other technical book with which I am familiar.
Before discussing this particular book, it may be of value to briefly discuss the essential concept of regular expressions, for the benefit of any readers who are not familiar with them. As noted earlier, a regular expression (frequently termed a "regex") is a string of characters intended for matching substrings in a block of text. A regex pattern can match literally, such as the pattern "book" matching both "book" and "bookshelf." A pattern can also use special characters and character combinations — often termed metasymbols and metasequences — such as \w to indicate a single word character (A-Z, a-z, 0-9, or '_'). Thus, the regex "b\w\wk" would match "book," but not "brook."
Here is a simple example to show the use of regexes in code, written in Perl: The statement "$text =~ m/book/;" would find the first instance of the string "book" inside the scalar variable $text, which presumably contains some text. To substitute all instances of the string with the word "publication," you could use the statement "$text =~ s/book/publication/g;" ('g' for globally search) or use "$text =~ s/bo{2}k/publication/g;". In this simplistic example, the second statement makes use of a quantifier, {2}, indicating two of the preceding letter.
These examples employ only one metacharacter (\w) and one quantifier ({2}). The total number of metacharacters, metasymbols, quantifiers, character classes, and assertions (to say nothing of capturing, clustering, and alternation) that are available, in most regex-enabled languages, is tremendous. However, the same cannot be said for the readability of all but the simplest regular expressions — especially lengthy ones not improved by whitespace and comments. As a consequence, when using regexes in their code, many programmers find themselves repeatedly consulting reference materials that do not focus on regular expressions. These resources comprise convoluted Perl books, incomplete tutorials on the Internet, and confusing discussions in technical newsgroups. For too many years, there was no published book providing the details of regexes for the various languages that utilize them, in addition to a clear explanation of how to use regexes wisely.
Fortunately, O'Reilly Media offers two titles in hopes of meeting that need: Mastering Regular Expressions, by Jeffrey Friedl, and Regular Expression Pocket Reference, by Tony Stubblebine. In several respects, the books are related — particularly in that Stubblebine bases his slender monograph upon Friedl's larger and more extensive title, justifiably characterized by Stubblebine as "the definitive work on the subject." In addition, Stubblebine's book follows the structure of Friedl's book, and contains page references to the same. Another major difference is that Regular Expression Pocket Reference is, just as the title indicates, for reference purposes only, and not intended as a tutorial.
At first glance, it is clear that Stubblebine's book packs a great deal of information into its modest 126 pages. That may partly be a result of the terseness of most, if not all, of the regular expression syntax; a metasymbol of more than two characters would be considered long-winded! Yet the high information density is likely also due to the manner in which Stubblebine has distilled the operators and rules, as well as the meaning and usage thereof, down to the bare bones. But this does not imply that the book is bereft of examples. Most of the sections contain at least one, and sometimes several, code fragments that illustrate the regex elements under discussion.
The book begins with a brief introduction to regexes and pattern matching, followed by an even briefer cookbook section, with Perl-style regexes for a dozen commonly-needed tasks, e.g., validating dates. The bulk of the book's material is divided into 11 sections, each one devoted to the usage of regexes within a particular language, application, or library: Perl 5.8, Java,.NET and C#, PHP, Python, Ruby, JavaScript, PCRE, the Apache Web server, the vi programmer's editor, and shell tools.
Each of these sections begins with a brief overview of how regexes fit into the overall language covered in that section. Following this is a subsection listing all of the supported metacharacters, with a summary of their meanings, in tabular format. In most cases, this is followed by a subsection showing the usage of those metacharacters — either in the form of operators or pattern-matching functions, depending upon how regular expressions are used within that language. Next is a subsection providing several examples, which is often the first material that most programmers turn to when trying to quickly figure out how to use one aspect of a language. Each section concludes with a short listing of other resources related to regexes for that particular language.
There are no glaring problems in this book, and I can only assume that all of the regular expressions themselves have been tested by the author and by previous readers. However, there is a minor weakness that should be pointed out, and could be corrected in the next edition. In most of the sections' examples, Stubblebine wisely formats the code so that every left brace ("{") is on the same line as the beginning of the statement that uses that brace, and each closing brace ("}") is lined up directly underneath the first character of the statement. This format saves space and makes it easier to match up the statement with its corresponding close brace. However, in the.NET / C# and PCRE library sections, the open braces consume their own lines, and also are indented inconsistently, as are the close braces, which makes the code less readable, as well as less consistent among the sections.
Some readers may fault the book's sparse index. Admittedly, an inadequate index in any sizable programming book can make it difficult if not impossible to find what one is looking for. As a result, one ends up flipping through the book's pages hoping to luckily spot the desired topic. This is the rather unpleasant method to which a reader must resort when a technical book has no index, or one that is inadequate — which is far too often the case. Stubblebine's index offers only several dozen entries for all the letters of the alphabet, and only two symbols. Some readers might demand that all of the metacharacters and metasequences be listed in the index, so they can be found even faster than otherwise. But given the large number of metacharacters and metasequences, as well as method names, module functions, and everything else relevant, creating an exhaustive index would almost double the size of the book, and be largely redundant with the language-specific sections. Within each language, there is typically a limited enough number of pages that scanning through them to find a particular topic, would not be onerous. On the other hand, some of the index's inclusions and omissions are odd. For instance, two symbols are listed, and yet no others; why bother with those two? Also, a few key concepts are missing, such as grouping and capturing.
Yet aside from these minor blemishes, Regular Expression Pocket Reference is a concise, well-written, and information-rich resource that should be kept on hand by any busy software developer.
Michael J. Ross is a Web developer, writer, and freelance editor.
You can purchase Regular Expression Pocket Reference, Second Edition from amazon.com. Slashdot welcomes readers' book reviews -- to see your own review here, read the book review guidelines, then visit the submission page. -
What Will Come of the FCC Comcast Hearing
The FCC held its hearing on network neutrality and Comcast today at Harvard. One commentator not afraid to predict what will come of it is O'Reilly's Andy Orem, who writes: "The mere announcement of an FCC hearing on 'broadband network management practices' was a notch in the gun of network neutrality advocates. Yet to a large extent, the panelists and speakers were like petitioners who are denied access to the king and can only bring their complaints to the gardeners who decorate the paths outside his gate. What we'll end up getting is a formal endorsement of non-discrimination as a policy that Internet providers must follow, leading to continual FCC review of current practices by telecom and cable companies." -
1.8 Million US Court Rulings Now Online
I Don't Believe in Imaginary Property writes "For a long time now, lawyers and any serious law students have been bound to paid services like LexusNexis for access to case law, but that is slowly changing. Carl Malamud has posted free electronic copies of every U.S. Supreme Court decision and Court of Appeals ruling since 1950, 1.8 million rulings in all, online for free. While the rulings themselves have long been government works not subject to copyright, courts still charge several cents per page for copies and they're inconvenient to access, so lawyers usually turn to legal publishers which are more expensive but more convenient, providing helpful things like notes about related cases, summaries of the holdings, and information about if and when the case was overturned. This free database is not Carl's first, either. He convinced the SEC to provide EDGAR, and helped get both the Smithsonian and Congressional hearings online." -
Semantic Web Getting Real
BlueSalamander writes "Tim O'Reilly just did an interview with Devin Wenig, the CEO-designate of Reuters. With no great enthusiasm I started to read yet another interview on how the semantic web was going to make everything great for everybody. Wenig made some good points about the end of the latency wars in news and the beginning of the battle for automatically detecting linkages and connections in the news. Smart news, not just fast news. Great stuff — but just more words? Nope — a little searching revealed that Reuters just opened access to their corporate semantic technology crown jewels. For free. For anyone. Their Calais API lets you turn unstructured text into a formal RDF graph in about one second. I ran about 5,000 documents through it and played with a subset of them in RDF-Gravity. The results were impressive overall. Is this the start of the semantic web getting real? When big names and big money start to act, not just talk, it may be time to pay attention. Semantic applications anyone? The foundation appears to be here." -
USPTO Reaffirms 1-Click Claims 'Old And Obvious'
theodp writes "After USPTO Examiner Mark A. Fadok rejected Amazon CEO Jeff Bezos' 1-Click Patent claims as 'old and obvious,' Amazon canceled and refiled its 1-Click claims in a continuation application as it requested an Oral Appeal, a move that smacked of a good old-fashioned stalling tactic. But the move may have backfired, as Fadok has just completed his review of the continuation app and concluded that all of the refiled 1-Click claims should be rejected, providing explanations of why the Board of Patent Appeals was wrong to reverse his earlier decision after listening to Amazon's lawyers in September. In October, USPTO Examiner Matthew C. Graham rejected most of the 1-Click claims as part of the reexam requested by LOTR actor Peter Calveley, a decision that attorneys for Amazon are currently trying to work around with some creative wordsmithing. Can't see how all of this means 'less work for the overworked Patent and Trademark Office.'" -
Mars Rover Technology Used to Make Better Maps
Cal writes "An article on the O'Reilly Radar site discusses a new street mapping technology by a company in Berkeley called earthmine. They are using technology developed by the Jet Propulsion Lab for the Mars Exploration Rover missions for reconstructing three-dimensional data of the street-scape. 'The licensed software and algorithms are used to create a 3D representation of the local terrain, allowing autonomous routing of the MERs through the Martian environment. earthmine has combined this JPL technology with its unique, capture hardware and web delivery technology to deliver 3D data with unprecedented density and accuracy.'" -
CSS Pocket Reference
Michael J. Ross writes "For Web developers who appreciate the value of separating Web content from its presentation, Cascading Style Sheets (CSS) has proved a godsend, because it allows all of the styling of a Web site to be organized in CSS files separate from the site's semantic content, in HTML files (possibly dynamically generated). Yet to make this styling power possible, CSS must incorporate a long list of syntax elements, including hundreds of selectors, properties, and values. Thus it can be quite handy for the developer to have on hand a concise summary of CSS, such as the CSS Pocket Reference, authored by Eric A. Meyer." Read on for the rest of Michael's review. CSS Pocket Reference, 3rd Edition author Eric A. Meyer pages 168 publisher O'Reilly Media rating 8/10 reviewer Michael J. Ross ISBN 0596515057 summary A concise reference book for CSS. The book was published by O'Reilly Media on 5 October 2007, under the ISBNs 0596515057 and 978-0596515058. CSS itself has evolved along with other Web technologies, and this book is now in its third edition, having been updated to reflect the ongoing changes in CSS; the book now covers CSS2 and CSS2.1. On the book's Web page, O'Reilly offers an online table of contents, as well as ways for the visitor to view and submit errata (none as of this writing) and reviews for the book. Unlike most technical publishers, O'Reilly now makes available previews of their books' contents, in the form of a table of contents with links to the first few paragraphs of each section, including tables and illustrations.
Despite the growth in the number of elements in CSS, and the attention paid to each one of them by the author of CSS Pocket Reference, the book is still small enough to fit in a pocket, at only 168 pages. The book's material is organized into 18 unnumbered sections, preceded by some notes on the book's typographical conventions, and followed by an essential index. The bulk of the material is found in the Property Reference section. Other sections explain how to add styles to HTML and XHTML pages; CSS rule structure and style precedence, including inheritance and the cascade; element classification and display roles; visual layout; rules on floating and positioning; and table layout. Subsequent sections cover CSS value types and units, and selectors, including some of the newest additions to CSS, such as the adjacent sibling selector and the language attribute selector. Just before getting into the details on properties, Eric Meyer discusses pseudo-classes and pseudo-elements, which have made it possible for Web developers to create rather robust and attractive site navigation using CSS exclusively, without any need to resort to images and JavaScript for rollover effects and other navigation eye candy.
For each element of CSS that is covered in all of the sections mentioned above, the types of information presented to the reader can vary, depending upon the category of element. But they generally include the element's possible values, a default value, what elements it can apply to, whether it is inherited, its computed value, a brief description of the element, at least one example illustrating its usage, what browsers support it, and oftentimes a note on its usage. Consequently, this new edition of the book, like its predecessors, should prove more than adequate for most CSS reference needs.
As with any computer book, there are several ways in which this one could be improved. Any reader using the book to look up a particular element, has two possible ways of doing so: They could first consult the index, and, assuming the element is listed there, go straight to the page indicated. But most readers, knowing that the elements in each section are listed alphabetically, will probably open up the book near the front or the back, and begin flipping backward or forward, respectively, hoping to spot the element of interest as quickly as possible, given its alphabetical ordering. That individual will likely immediately spot an obvious problem with the book: The pages have no running titles (the words that indicate the first element discussed on that page, and typically listed at the very top of each page). Inclusion of such running titles in the next edition of the book, would make it much faster to use.
Another valuable addition would be some sort of table listing all of the CSS elements and their level of support within the most commonly used Web browsers and, in the case of Internet Explorer, the most commonly used versions of the browser. Also, on page 48 of the book, at the beginning of the Property Reference section, it has a subhead of "Visual Media," which suggests that there are other subheads within that section, for other media types; but I was unable to find any.
All of these problems concern the publisher's choice of material. My last criticism concerns the layout of that material in the print version of the book. Because this diminutive volume has narrow pages, and they are tightly glued together in the binding, it is imperative that the publisher of such a book provide plenty of white space in the inner margins (those closest to the binding), so the reader does not have to crack open the book too much in order to read the text closest to the binding. Repeatedly opening up the book far enough to read those inmost words, will over time weaken and eventually destroy the binding. In contrast, a small reference book like this has no need for much outer margin. Sadly, O'Reilly got it backwards with this volume, with relatively wide and useless outer margins, and inadequate inner margins.
Aside from the aforementioned flaws — all of which can be remedied in the future — CSS Pocket Reference is a compact and neatly organized gem of a book, packed with information of value to busy Web programmers.
Michael J. Ross is a Web developer, writer, and freelance editor.
You can purchase CSS Pocket Reference, 3rd Edition from amazon.com. Slashdot welcomes readers' book reviews -- to see your own review here, read the book review guidelines, then visit the submission page. -
Patent Reformers O'Reilly, Bezos Mum on 1-Click
theodp writes "Brought together 7 years ago by a threatened boycott over Amazon's 1-Click patent, Tim O'Reilly and Jeff Bezos vowed to reform the U.S. patent system. So in The Register's Open Season podcast (@12:25), Andrew Orlowski finds it very ironic that news of a victory by LOTR choreographer Peter Calveley against Bezos' 1-Click patent broke as O'Reilly was once again busy trotting out Amazon-tied speakers to headline a Web 2.0 conference, this one sponsored by Fenwick & West, the prestigious law firm bested by Calveley. Orlowski notes that O'Reilly, who now counts Bezos among his investors, was oddly silent for a self-described software patent protester, especially one who once vowed to torpedo 1-Click. Equally untalkative was Bezos, who deflected questions on the damage done by Calveley's DIY legal effort, telling a Wall Street analyst to 'refer to our public filings' (although nothing on the subject appears in the 8-K and 10-Q filings). One last dose of irony — in explaining the prior art he used to reject the 1-Click claims, a USPTO Examiner cited the very same TV remote control patent that was deemed to be unsuitable in a 1-Click prior art contest run by the O'Reilly and Bezos-bankrolled BountyQuest (just last year, Amazon testified to Congress that the contest failed to find prior art for Bezos' patent)." -
High Performance Web Sites
Michael J. Ross writes "Every Internet user's impressions of a Web site is greatly affected by how quickly that site's pages are presented to the user, relative to their expectations — regardless of whether they have a broadband or narrowband connection. Web developers often assume that most page-loading performance problems originate on the back-end, and thus the developers have little control over performance on the front-end, i.e., directly in the visitor's browser. But Steve Souders, head of site performance at Yahoo, argues otherwise in his book, High Performance Web Sites: Essential Knowledge for Frontend Engineers." Read on for the rest of Michael's review. High Performance Web Sites author Steve Souders pages 168 publisher O'Reilly Media rating 9/10 reviewer Michael J. Ross ISBN 0596529309 summary 14 rules for faster Web pages The typical Web developer — particularly one well-versed in database programming — might believe that the bulk of a Web page's response time is consumed in delivering the HTML document from the Web server, and in performing other back-end tasks, such as querying a database for the values presented in the page. But the author quantitatively demonstrates that — at least for what are arguably the top 10 sites — less than 20 percent of the total response time is consumed by downloading the HTML document. Consequently, more than 80 percent of the response time is spent on front-end processing — specifically, downloading all of the components other than the HTML document itself. In turn, cutting that front-end load in half would improve the total response time by more than 40 percent. At first glance, this may seem insignificant, given how few seconds or even deciseconds it takes for the typical Web page to appear using broadband. But any delays, even a fraction of a second, accumulate in reducing the satisfaction of the user. Likewise, improved site performance not only benefits the site visitor, in terms of faster page loading, but also the site owner, with reduced bandwidth costs and happier site visitors.
Creators and maintainers of Web sites of all sizes should thus take a strong interest in the advice provided by "Chief Performance Yahoo!," in the 14 rules for improving Web site performance that he has learned in the trenches. High Performance Web Sites was published on 11 September 2007, by O'Reilly Media, under the ISBNs 0596529309 and 978-0596529307. As with all of their other titles, the publisher provides a page for the book, where visitors can purchase or register a copy of the book, or read online versions of its table of contents, index, and a sample chapter, "Rule 4: Gzip Components" (Chapter 4), as a PDF file. In addition, visitors can read or contribute reviews of the book, as well as errata — of which there are none, as of this writing. O'Reilly's site also hosts a video titled "High Performance Web Sites: 14 Rules for Faster Pages," in which the author talks about his site performance best practices.
The bulk of the book's information is contained in 14 chapters, with each one corresponding to one of the performance rules. Preceding this material are two chapters on the importance of front-end performance, and an overview of HTTP. Together these form a well-chosen springboard for launching into the performance rules. In an additional and last chapter, "Deconstructing 10 Top Sites," the author analyzes the performance of 10 major Web sites, including his own, Yahoo, to provide real-world examples of how the implementation of his performance rules could make a dramatic difference in the response times of those sites. These test results and his analysis are preceded by a discussion of page weight, response times, YSlow grading, and details on how he performed the testing. Naturally, if and when a reader peruses those sites, checking their performance at the time, the owners of those sites may have fixed most if not all of the performance problems pointed out by Steve Souders. If they have not, then they have no excuse, if only because of the publication of this book.
Each chapter begins with a brief introduction to whatever particular performance problem is addressed by that chapter's rule. Subsequent sections provide more technical detail, including the extent of the problem found on the previously mentioned 10 top Web sites. The author then explains how the rule in question solves the problem, with test results to back up the claims. For some of the rules, alternative solutions are presented, as well as the pros and cons of implementing his suggestions. For instance, in his coverage of JavaScript minification, he examines the potential downsides to this practice, including increased code maintenance costs. Every chapter ends with a restatement of the rule.
The book is a quick read compared to most technical books, and not just due to its relatively small size (168 pages), but also the writing style. Admittedly, this may be partly the result of O'Reilly's in-house and perhaps outsource editors — oftentimes the unsung heroes of publishing enterprises. This book is also valuable in that it offers the candid perspective of a Web performance expert, who never loses sight of the importance of the end-user experience. (My favorite phrase in the book, on page 38, is: "...the HTML page is the progress indicator.")
The ease of implementing the rules varies greatly. Most developers would have no difficulty putting into practice the admonition to make CSS and JavaScript files external, but would likely find it far more challenging, for instance, to use a content delivery network, if their budget puts it out of reach. In fact, differences in difficulty levels will be most apparent to the reader when he or she finishes Chapter 1 (on making fewer HTTP requests, which is straightforward) and begins reading Chapter 2 (content delivery networks).
In the book's final chapter, Steve Souders critiques the top 10 sites used as examples throughout the book, evaluating them for performance and specifically how they could improve that through the implementation of his 14 rules. In critiquing the Web site of his employer, he apparently pulls no punches — though few are needed, because the site ranks high in performance versus the others, as does Google. Such objectivity is appreciated.
For Web developers who would like to test the performance of the Web sites for which they are responsible, the author mentions in his final chapter the five primary tools that he used for evaluating the top 10 Web sites for the book, and, presumably, used for the work that he and his team do at Yahoo. These include YSlow, a tool that he created himself. Also, in Chapter 5, he briefly mentions another of his tools, sleep.cgi, a freely available Perl script that tests how delayed components affect Web pages.
As with any book, this one is not perfect — nor is any work. In Chapter 1, the author could make more clear the distinction between function and file modularization, as otherwise his discussion could confuse inexperienced programmers. In Chapter 10, the author explores the gains to be made from minifying JavaScript code, but fails to do the same for HTML files, or even explain the absence of this coverage — though he does briefly discuss minifying CSS. Lastly, the redundant restatement of the rules at the end of every chapter, can be eliminated — if only in keeping with the spirit of improving performance and efficiency by reducing reader workload.
Yet these weaknesses are inconsequential and easily fixable. The author's core ideas are clearly explained; the performance improvements are demonstrated; the book's production is excellent. High Performance Web Sites is highly recommended to all Web developers seriously interested in improving their site visitors' experiences.
Michael J. Ross is a Web developer, freelance writer, and the editor of PristinePlanet.com's free newsletter.
You can purchase High Performance Web Sites from amazon.com. Slashdot welcomes readers' book reviews -- to see your own review here, read the book review guidelines, then visit the submission page. -
Major Linux Hardware Donor Is a CNN "Hero"
christian.einfeldt writes "James Burgett of the Alameda County Computer Resource Center calls himself a 'tattooed freak' and a recovering drug addict, but CNN is calling him a hero (video) for diverting tons of computers from landfills, installing Ubuntu Linux on them, and giving them out to schools, non-profits, and poor people. Burgett's filmed interview is currently leading a CNN contest among videos of 'ordinary people' whom CNN considers everyday heroes, narrowly edging out the video of a man who is saving gorillas from extinction. In his interview, Burgett points out that the people working for him are also recovering drug addicts or recovering mental illness patients." Update: 10/02 23:46 GMT by KD : Reader stefanlasiewski posted a journal article describing how, bewilderingly, the state of California is threatening to shut down Burgett's ACCRC. -
Beautiful Code Interview
An anonymous reader writes "Safari Books Online has just posted an interview with Andy Oram and Greg Wilson, the two editors who put together the recent O'Reilly book, Beautiful Code. "Beautiful Code" features 33 different case studies about challenging coding scenarios from some of today's most high-profile developers and OS project leaders. There's also a new Beautiful Code web site based on the book where many of the authors are blogging about their work and coding practices." -
Amazon S3 is Patent-Pending
theodp writes "If your startup is counting on a copycat service to emerge for Amazon S3 disaster recovery, you might want to start thinking about a Plan C. On Thursday, the USPTO disclosed that Amazon wants a patent for its Distributed storage system with web services client interface invention, aka Amazon Simple Storage Service." -
Faster and Open Access to Scientific Results
Tim O'Reilly has a post about how the prominent scholarly journal Nature has recently launched an open-access service for pre-publication research and presentations. In Nature Precedings, all content is released under a Creative Commons Attribution License, and can be commented and voted on. The service will cover research in biology, chemistry, and earth science, much like arXiv.org does for physics, mathematics, and computer science. -
A Look at BSD Rootkits
blackbearnh writes "Windows has a reputation for being easily exploited by rootkits, but just because you're using Linux or BSD doesn't mean you're safe from infection. In an interview on O'Reilly's ONLamp site, Joseph Kong (author of Designing BSD Rootkits ), talks about how to build and defend against Rootkits under BSD. 'I know a lot of people who refer to rootkits and rootkit-detectors as being in a big game of cat and mouse. However, it's really more like follow the leader — with rootkit authors always being the leader. Kind of grim, but that's really how it is. Until someone reveals how a specific (or certain class of) rootkit works, nobody thinks about protecting that part of the system. And when they do, the rootkit authors just find a way around it. This is what I meant earlier when I said rootkit hunting is hard — as you really have to validate the integrity of the entire system.'" -
Google Debuts Street View and Mapplets
Today at the O'Reilly Where 2.0 Conference Google unveiled two new map features. An O'Reilly blogger describes Street View, which uses 360-degree street-level video from Immersive Media to enable neighborhood walk-throughs in (for now) a few selected areas. The other new feature is Mapplets, which let you embed Google Maps mashups in any Web page. Much more coverage is linked from TechMeme. -
MySQL Stored Procedure Programming
Michael J. Ross writes "MySQL may be the most popular open source relational database management system (RDBMS) in the world, but during the first decade of its existence, it lacked support for stored programs, i.e., store procedures, functions, and triggers. The major commercial RDBMS vendors — including Oracle, IBM, and Microsoft — could point to this deficiency as reason enough to choose their proprietary systems over MySQL or any other open source system, such as PostgreSQL. But with the release of MySQL version 5.0, in October 2005, the "little database engine that could" dramatically improved its position against the competition. The most comprehensive discussion of these new capabilities is in the book MySQL Stored Procedure Programming." Read below for the rest of Michael's review MySQL Stored Procedure Programming author Guy Harrison and Steven Feuerstein pages 636 publisher O'Reilly Media rating 9 reviewer Michael J. Ross ISBN 0596100892 summary A comprehensive guide to developing MySQL stored procedures, functions, and triggers.
Written by Guy Harrison and Steven Feuerstein, and published by O'Reilly Media in March 2006 under the ISBNs 0596100892 and 978-0596100896, this book is the first one to offer database programmers a full discussion of the syntax, usage, and optimization of MySQL stored procedures, stored functions, and triggers — which the authors wisely refer to collectively as "stored programs," to simplify the manuscript. Even a year after the introduction of these new capabilities in MySQL, they have received remarkably little coverage by book publishers. Admittedly, there are three such chapters in MySQL Administrator's Guide and Language Reference (2nd Edition), written by some of the developers of MySQL, and published by MySQL Press. Yet this latter book — even though published a month after O'Reilly's — devotes fewer than 50 pages to stored programs, and the material is not in the printed book itself, but in the "MySQL Language Reference" part, on the accompanying CD. That material, in conjunction with the online reference documentation, may be sufficient for the more simple stored program development needs. But for any MySQL developer who wishes to understand in-depth how to make the most of this new functionality in version 5.0, they will likely need a much more substantial treatment — and that's exactly what Harrison and Feuerstein have created.
The authors are generous in both the technical information and development advice that they offer. The book's material spans 636 pages, organized into 23 chapters, grouped into four parts, followed by an index. The first part, "Stored Programming Fundamentals," provides an introduction and then a tutorial, both taking a broad view of MySQL stored programs. The remaining four chapters cover language fundamentals; blocks, conditional statements, and iterative programming; SQL; and error handling. The book's second part, "Stored Program Construction," may be considered the heart of the book, because its five chapters present the details of creating stored programs in general, using transaction management, using MySQL's built-in functions, and creating one's own stored functions, as well as triggers. The third part, "Using MySQL Stored Programs and Applications," explains some of the advantages and disadvantages of stored programs, and then illustrates how to call those stored programs from source code written in any one of five different programming languages: PHP, Java, Perl, Python, and Microsoft.NET. In the fourth and final part, "Optimizing Stored Programs," the authors focus on the security and tuning of stored programs, tuning SQL, optimizing the code, and optimizing the development process itself.
This is a substantial book, encompassing a great deal of technical as well as advisory information. Consequently, no review such as this can hope to describe or critically comment upon every section of every chapter of every part. Yet the overall quality and utility of the manuscript can be discerned simply by choosing just one of the aforesaid Web programming languages, and writing some code in that language to call some MySQL stored procedures and functions, to get results from a test database — and developing all of this code while relying solely upon the book under review. Creating some simple stored procedures, and calling them from some PHP and Perl scripts, demonstrated to me that MySQL Stored Procedure Programming contains more than enough coverage of the topics to be an invaluable guide in developing the most common functionality that a programmer would need to implement.
The book appears to have very few aspects or specific sections in need of improvement. The discussion of variable scoping, in Chapter 4, is too cursory (no database pun intended). In terms of the book's sample code, I found countless cases of inconsistency of formatting — specifically, operators such as "||" and "=" being jammed up against their adjacent elements, without any whitespace to improve readability. These minor flaws could be easily remedied in the next edition. Some programming books make similar mistakes, but throughout their text, which is even worse. Fortunately, most of the code in this book is neatly formatted, and the variable and program names are generally descriptive enough.
Some of the book's material could have been left out without great loss — thereby reducing the book's size, weight, and presumably price. The two chapters on basic and advanced SQL tuning contain techniques and recommendations covered with equal skill in other MySQL books, and were not needed in this one. On the other hand, sloppy developers who churn out lamentable code might argue that the last chapter, which focuses on best programming practices, could also be excised; but those are the very individuals who need those recommendations the most.
Fortunately, the few weaknesses in the book are completely overwhelmed by its positive qualities, of which there are many. The coverage of the topics is quite extensive, but without the repetition often seen in many other technical books of this size. The explanations are written with clarity, and provide enough detail for any experienced database programmer to understand the general concepts, as well as the specific details. The sample code effectively illustrates the ideas presented in the narration. The font, layout, organization, and fold-flat binding of this book, all make it a joy to read — as is characteristic of many of O'Reilly's titles.
Moreover, any programming book that manages to lighten the load of the reader by offering a touch of humor here and there, cannot be all bad. Steven Feuerstein is the author of several well-regarded books on Oracle, and it was nice to see him poke some fun at the database heavyweight, in his choice of sample code to demonstrate the my_replace() function: my_replace( 'We love the Oracle server', 'Oracle', 'MySQL').
The prospective reader who would like to learn more about this book, can consult its Web page on O'Reilly's site. There they will find both short and full descriptions, confirmed and unconfirmed errata, a link for writing a reader review, an online table of contents and index, and a sample chapter (number 6, "Error Handling"), in PDF format. In addition, the visitor can download all of the sample code in the book (562 files) and the sample database, as a mysqldump file.
Overall, MySQL Stored Procedure Programming is adeptly written, neatly organized, and exhaustive in its coverage of the topics. It is and likely will remain the premier printed resource for Web and database developers who want to learn how to create and optimize stored procedures, functions, and triggers within MySQL.
Michael J. Ross is a Web programmer, freelance writer, and the editor of PristinePlanet.com's free newsletter. He can be reached at www.ross.ws, hosted by SiteGround.
You can purchase MySQL Stored Procedure Programming from amazon.com. Slashdot welcomes readers' book reviews -- to see your own review here, read the book review guidelines, then visit the submission page. -
Amazon Goes Web 2.0 Wild to Defend 1-Click Patent
theodp writes "Six years ago, Jeff Bezos and Tim O'Reilly urged the masses to give-patent-reform-a-chance as Richard Stallman called for an Amazon boycott. On Monday, the pair will reunite to kick off O'Reilly's new Amazon-sponsored Web 2.0 Expo with A Conversation with Jeff Bezos. Be interesting if the conversation turned to Amazon's ongoing battle against an actor's effort to topple Bezos' 1-Click patent, which The Register notes included dumping 58 lbs. of paperwork on the patent examiner, including dozens of articles from the oh-so-Web-2.0 Wikipedia, which the USPTO had already deemed an un acceptable source of information ('From a legal point of view, a Wiki citation is toilet paper,' quipped patent expert Greg Aharonian)." -
MySQL Pocket Reference
Michael J. Ross writes "MySQL database administrators and developers have several options for MySQL reference sources, though naturally none of them are ideal in all situations. The online MySQL documentation is extensive, but the most commonly needed nuggets are buried in its necessarily exhaustive contents. Third-party MySQL reference books can winnow out some of the rarely-used minutia, but they still encompass hundreds of pages, reflecting the complexity of the subject. For quickly looking up the most frequently used command syntax and other details, a MySQL user would usually be best served by a much more compact book, such as MySQL Pocket Reference." Read below for the rest of Michael's review. MySQL Pocket Reference author George Reese pages 96 publisher O'Reilly rating 9 reviewer Michael J. Ross ISBN 059600446X summary Great for quickly looking up the most frequently used command syntax and other details of MySQL
Written by George Reese, this book was published by O'Reilly Media, in February 2003. It may span only 96 pages, and weigh only 3.2 ounces, but it packs a substantial amount of useful information into a diminutive form. The book's material is organized into several sections, covering MySQL installation, command-line tools, data types, SQL, operators, functions, and table types.
After presenting a quick introduction and some other housekeeping topics, the author briefly explains how to install, configure, and start up MySQL, as well as how to set the root password. This RDBMS includes a dozen command-line tools, and the author next provides the briefest of summaries for each one, and more details on the most commonly used one, mysql.
The next four sections compose the meat of the book, as they cover the MySQL data types, SQL query language, operators, and functions. Of all the aspects of any programming language or RDBMS, the one that frequently causes the most confusion — and for which a handy reference guide would be most appreciated — is the proper use of data types. In MySQL Pocket Reference, the author presents all of the MySQL data types, grouped into numerics, strings, dates, and complex types. For each data type, the author shows the declaration syntax, the storage space required, and the purpose of the data type.
MySQL version 4.0 supports ANSI SQL 92, as well as some proprietary extensions, which is true for most if not all substantial RDBMSs. Reese explains the case sensitivity of MySQL for various contexts; the use of literals, including escape sequences; the rules concerning identifier naming and aliasing; and how to insert comments in your code. Much more space is devoted to all of the MySQL commands, ranging from ALTER TABLE to USE. For each command, the reader is shown the syntax, including optional keywords, clauses, and other elements, as well as a generous number of illustrative examples.
The last three sections of the book cover operators (arithmetic, comparison, and logical), functions (aggregate and otherwise), and table types. The section on functions will likely get a lot of use from the average reader, as it is relatively easy to forget the name and parameter list of any function — particularly if it has not been used by the developer for some time, and is not present in the surrounding code.
Like any pocket reference book, this one is not intended to serve as a full reference source or as a MySQL tutorial — of which O'Reilly offers several. Rather, it is best used for quickly answering questions concerning command syntax, operator precedence, function parameter order, or any of the other MySQL language details that are not listed automatically by programming editors, nor otherwise immediately obvious. Yet despite its small size, this book contains information that may be unknown to even some of the most experienced MySQL administrators and programmers. For instance, I had no idea that 2007-04-00 is considered a valid date. (I only wish that my taxes were due on that day.)
O'Reilly Media has a Web page on their site that provides some additional resources related to this book. These include links for reading the reviews offered by other readers, submitting your own review, and checking the errata for the book, of which there are 20, as of this writing — 19 of which have been confirmed.
There appear to be only two flaws in this book. It lacks a list of MySQL reserved words, which is odd for a reference book. Also, the text on every page is set too close to the binding, thus compelling the reader to force open the book more than should be necessary, just to comfortably read the inmost ends of the lines of text. This could be easily fixed in a subsequent edition, by moving the text outwards approximately half a centimeter, since the outer margins are much wider than necessary.
Speaking of editions, because this first edition of the book appeared in early 2003, it covers up to version 4.0 of MySQL. One can only hope that a second edition will be made available at some point in the future, so that it can be brought up to date with all of the new additions to MySQL 5, which are substantial. These include cursors, stored procedures, triggers, and views.
Nonetheless, this first edition would be of value to anyone using MySQL. In essence, MySQL Pocket Reference is neatly organized, extremely portable, and packs much valuable information into a succinct format.
Michael J. Ross is a Web programmer, freelance writer, and the editor of PristinePlanet.com's free newsletter. He can be reached at www.ross.ws, hosted by SiteGround."
You can purchase MySQL Pocket Reference from amazon.com. Slashdot welcomes readers' book reviews -- to see your own review here, read the book review guidelines, then visit the submission page. -
MySQL Cookbook
Michael J. Ross writes "Of all the technical challenges faced by the typical experienced computer programmer, questions about syntax form a relatively small portion. This is especially true now that current coding editors and IDEs offer statement expansion and syntax checking. Rather, the most common type of technical challenge is understanding how to solve a specific data access or manipulation problem. Hence the growing popularity of programming "cookbooks," which are filled with "recipes," each comprising a concise statement of a focused problem, followed by a solution, with plenty of sample code to show how to implement it. For developers using the MySQL database system, the gold standard of such books is MySQL Cookbook, by Paul DuBois." Read below for the rest of Michael's review MySQL Cookbook author Paul DuBois pages 948 publisher O'Reilly Media rating 8 reviewer Michael J. Ross ISBN 059652708X summary A great book for developers using the MySQL database system
Published by O'Reilly Media, the second edition appeared in November 2006. This new edition has been updated for MySQL version 5.0. The publishers have a Web page devoted to the book, where the visitor can find both brief and full descriptions of the book, an online table of contents and index, a sample chapter (number 5, "Working with Strings") in PDF format, errata (none reported as of this writing), and a way to post your own review on the O'Reilly Web site. There are also links for purchasing the book, or reading an online version, in the Safari Bookshelf program.
The bulk of the book's material is divided among 20 chapters, covering a wide range of topics: Using the mysql Client Program; Writing MySQL-Based Programs; Selecting Data from Tables; Table Management; Working with Strings; Working with Dates and Times; Sorting Query Results; Generating Summaries; Obtaining and Using Metadata; Importing and Exporting Data; Generating and Using Sequences; Using Multiple Tables; Statistical Techniques; Handling Duplicates; Performing Transactions; Using Stored Procedures, Triggers, and Events; Introduction to MySQL on the Web; Incorporating Query Results into Web Pages; Processing Web Input with MySQL; Using MySQL-Based Web Session Management.
Most of these chapters contain a generous number of sections, each serving as a recipe for a specific problem within MySQL. Two of the chapters have only four such recipes, but most have a dozen or more, with a few of them boasting more than three dozen recipes. Each recipe begins with a brief problem statement, and usually an equally brief solution statement, followed by a much more lengthy discussion, which contains the actual explanation of the solution, the sample code, and the expected output of that code. Some of the sections conclude with a mention of related recipes that could also be consulted.
This book, like so many other programming cookbooks, is weakened by the practice of offering a "Solution" subsection that consists of only one or two sentences — so terse and high-level that it provides, for all practical purposes, no solution to the reader. The actual solution is found in the "Discussion" subsection, which follows. This practice makes no sense. Because both subsections address the problem solution, they should be combined into a single subsection, naturally labeled "Solution." It appears that the purpose of the current Solution statements is to provide a terse summary. If so, then it should be labeled as such, yet still included within the new Solution subsection.
Despite this illogical division of each solution into two subsections, the content of the problem solutions found in MySQL Cookbook should be quite valuable, for several reasons: Firstly, the author has chosen the sorts of problems, within each category, that the MySQL programmer would typically encounter. No doubt this is a consequence of Paul DuBois being the author of a number of MySQL books, as well as one of the earliest contributors to the online MySQL Reference Manual. Secondly, the solutions work, and have been demonstrated to do so. Thirdly, the writing style is straightforward, which is characteristic of O'Reilly's titles. Fourthly, all of the problem solutions contain sample code and its output, which not only demonstrate the validity of each solution (as noted in my second point), but also allows the reader to see how the solution works simply by reading the material, and not having to type in the sample code to get the output within their own development environment — assuming one is even at hand, when reading the book.
The bulk of MySQL-related code in use today, was created not just to be accessed within a database client program, such as mysql, but instead from interpreted programming languages — especially those used heavily on Web sites. This is one area where MySQL Cookbook really shines, because it contains a large amount of sample code in Perl, PHP, Python, Java, and even Ruby. That is not to say that every code sample in one language has corresponding samples for all of the other languages; that would undoubtedly make the book much longer than it currently is, and probably unwieldy. But in cases where all of the languages are capable of expressing brief solutions, then they are included.
Regardless of whether the reader chooses the print or online versions, there are roughly two ways to make use of this book. If a programmer wishes to significantly increase their knowledge of what MySQL can do for them, and also increase their comfort level with utilizing those capabilities, then they might elect to read the book from stem to stern. Given that this would involve reading over 900 pages, it would certainly take some time for the average developer, but arguably could be time well spent. At the other end of the spectrum, the reader might elect to peruse individual sections that look interesting — particularly if they are relevant to a current project. This approach is certainly doable, because each of the recipes is self-contained, without the cross-referencing seen in many non-recipe style books. Admittedly, there are some "See Also" sections, but they are relatively few in number, with largely optional information, and tend to simply enrich the book's presentation, rather than frustrating the reader by pointing to other areas of the book.
This new edition of MySQL Cookbook concludes with four appendices, and an index. The first appendix explains where to obtain the software for MySQL, the five API programming languages used in the book, and the Apache Web server. The second appendix shows how to execute programs written in those five interface languages, on the command line. The third appendix is a fairly substantial primer on Java Server Pages (JSP) and Tomcat, providing an overview of servlets and JSP, as well as how to install and set up a Tomcat server, the Tomcat directory structure, the basics of JSP pages, and more. The last appendix lists resources outside the book for MySQL and the five aforementioned languages.
Unlike far too many programming books on the market now, this book's index is generally quite thorough, which is essential for a work of this size (975 pages). The recipe titles in the table of contents, are detailed enough to make it possible for the reader to locate the appropriate recipe in the book for their particular problem — assuming the book addresses that problem — and are grouped by subject, making it easier to find related recipes, which oftentimes can provide insight into other problems that they do not address directly.
Despite the obvious effort that has gone into both editions of this book, there are still some areas for improvement, and most of them are related to the readability of the sample code. Admittedly, there are different schools of thought as to optimal coding style, including use of whitespace, the placement of braces, and other matters. This assessment can only be my own opinion, based upon years of reading other people's code. The sample code in MySQL Cookbook would be more readable if more whitespace were utilized to separate function and variable names from open and close parentheses. This is especially true for the SQL code and MySQL extensions, for which all of the keywords are in all uppercase. The code fragments and full programs written in the API languages — such as Perl and PHP — are more readable, though they sometimes suffer from nondescriptive variable names. One might argue that the aforesaid choices are needed to cut down on the space consumed by the code on the book's pages. But if that were true, then the author likely would not have wasted an entire line for each open brace. Last, and certainly not least for the programmer who would like to try out the author's sample code in their own environment, it is unfortunate and inexplicable as to why the sample code is not offered on the O'Reilly Web site for downloading.
All in all, MySQL Cookbook is a well-organized and neatly written work, which should be of tremendous value to any software developer trying to find proven solutions to common database programming problems.
Michael J. Ross is a Web consultant, freelance writer, and the editor of PristinePlanet.com's free newsletter. He can be reached at www.ross.ws, hosted by SiteGround.
You can purchase MySQL Cookbook from amazon.com. Slashdot welcomes readers' book reviews -- to see your own review here, read the book review guidelines, then visit the submission page. -
How Open is Open Source Really?
jg21 writes to tell us that several industry leaders have chimed in with a response to Nat Torkington's recent piece "Is 'Open Source' Now Completely Meaningless". In the original piece Torkington raised the question of whether the term "open source" had lost any meaning because of companies that use the label yet largly restrict user interaction. Sun's Simon Phpps chimed in by stating: "I see open source as a term relevant to the way communities function and I'd support the reunification of the terms 'Free' and 'open source' around the concept of Free software being developed in open source communities. On that basis it's not dead." -
Amazon Using Patent Reform to Strengthen 1-Click
theodp writes "As some predicted, lawyers for Amazon.com have recently submitted 1-Click prior art solicited by Tim O'Reilly under the auspices of Jeff Bezos' patent reform effort to the USPTO, soliciting a 'favorable action' that would help bulletproof the patent. Last June, an Amazon lobbyist referred to deficiencies with the same prior art as he tried to convince Congress that 1-Click was novel, prompting Rep. Howard Berman to call BS." -
Amazon Using Patent Reform to Strengthen 1-Click
theodp writes "As some predicted, lawyers for Amazon.com have recently submitted 1-Click prior art solicited by Tim O'Reilly under the auspices of Jeff Bezos' patent reform effort to the USPTO, soliciting a 'favorable action' that would help bulletproof the patent. Last June, an Amazon lobbyist referred to deficiencies with the same prior art as he tried to convince Congress that 1-Click was novel, prompting Rep. Howard Berman to call BS." -
Yahoo Pipes
ahab_2001 writes "Yahoo has introduced a new product called Pipes. It seems to be a GUI-based interface for building applications that aggregate RSS feeds and other services, creating Web-based apps from various sources, and publishing those apps. Sounds very cool. TechCrunch has a decent write-up, and Tim O'Reilly is all over it. The site was down for a few hours and is just back up. Has anybody tried this?" From the TechCrunch article: "Pipes is... akin to a shell scripting environment for the web rather than just a simple conduit between applications." -
Linux Kernel Devs Offer Free Driver Development
schwaang writes "Linux Kernel hacker Greg Kroah-Hartman, author of Linux Kernel in a Nutshell has posted an epic announcement on his blog. This could portend increased device compatibility for Linux users, higher-quality drivers, and fewer non-free binary blobs." From the announcement: "[T]he Linux kernel community is offering all companies free Linux driver development... All that is needed is some kind of specification that describes how your device works, or the email address of an engineer that is willing to answer questions every once in a while. If your company is worried about NDA issues surrounding your device's specifications, we have arranged a program... in order to properly assure that all needed NDA requirements are fulfilled. Now your developers will have more time to work on drivers for all of the other operating systems out there, and you can add 'supported on Linux' to your product's marketing material." -
CSS: The Definitive Guide
Michael J. Ross writes "Every Web developer knows that Cascading Style Sheets (CSS) makes it possible to separate the contents of Web pages from the styling of the elements on those pages. This in turn confers tremendous advantages, such as allowing site-wide changes of appearance to be made just once, in a single stylesheet file, rather than in all of the pages containing the affected elements. The syntax and proper usage of CSS is not as simple as implied by many HTML/CSS books, most of which fail to provide enough detail as to how CSS is applied to page elements. Web developers relying upon these books soon find themselves hitting those limits, and becoming frustrated when trying to debug Web pages. CSS: The Definitive Guide, authored by CSS expert Eric A. Meyer, aims to fill that gap." Read on for the rest of Michael's review. CSS: The Definitive Guide author Eric A. Meyer pages 536 publisher O'Reilly Media rating 9 reviewer Michael J. Ross ISBN 0596527330 summary A comprehensive CSS reference guide.
Published by O'Reilly Media in November 2006, this title is now in its third edition. The first edition appeared in May 2000, and the second in January 2004 — with each one establishing the book as an immediate favorite among hard-core Web programmers. Each revision brought it up to date with the evolution of CSS as a standard, its support among the most popular Web browsers, and its usage within the Web development community. This latest edition covers CSS2 and CSS2.1, but does not include the CSS3 modules, including those that have reached Candidate Recommendation status, because their implementation is largely incomplete among most of the browsers.
Web veteran Eric Meyer presents the book's material in a methodical manner, starting with an overview of CSS's purpose and advantages, and quickly moving into the details of the technology: selectors, structure, inheritance, values, units, fonts, text properties, visual formatting, padding, borders, margins, colors, backgrounds, floating, positioning, tables, lists, and generated content (e.g., bullets of unordered lists). The last two chapters address user interface styles (system fonts and colors, cursors, and outlines) and non-screen media (such as paged and aural content). The book's 536 pages are organized into a total of 14 chapters and three appendices. The first appendix is a complete CSS property reference, spanning more than 40 pages, with visual, page, and aural properties grouped separately. For each property, Meyer explains its purpose, its valid values, the initial value, what elements it applies to, whether it is inherited, its computed value, and additional notes (if any). The second appendix is a reference for the selectors, pseudo classes, and pseudo elements. The third and final appendix is much shorter than the first two, but no less interesting, as it discusses a sample HTML 4 stylesheet, which is presented in the CSS2.1 specification as the recommended style sheet for developers to use.
As with all of their other titles, O'Reilly Media offers a Web page devoted to this book, where visitors will find links to online versions of the book cover, table of contents, index, registration form, reader reviews, and errata (of which there are none, as of this writing). In addition, the page has offers to receive a volume discount, and to read the book online as part of O'Reilly's Safari service.
Anyone who is considering purchasing this book might initially be concerned by the dearth of feedback on the Web sites of the publisher and the major online booksellers — in the form of few reader comments, and no reported errata. The prospective reader may wrongly conclude that this indicates a lack of interest in the book, and thus it must be unpopular — probably for good reason. But just the opposite is true, as demonstrated by the book's sales rank on Amazon.com alone: #4631, as of this writing. Unlike far too many of the other HTML/CSS books available, this one does not engender scathing reviews by customers angry with the books' shoddy writing and sloppy mistakes. Rather, Meyer's contribution is the type of solid reference book that the discerning Web developer will quietly place on their desk or bookshelf, within easy and frequent reach — possibly displacing a dog-eared first or second edition of the same title. Furthermore, the absence of errata should suggest that most if not all kinks have been worked out of the book, and not that the book is failing to receive careful readings.
CSS: The Definitive Guide benefits not just from its multiple revisions, but also from Eric Meyer's clear and complete writing style. Unlike his more advanced books, this one is far more approachable, making it possible for the reader to easily jump into the midst of any topic and quickly pick up the thread — as is essential for any technical reference work. The theoretical discussions and the sample code demonstrate his abundant experience in using CSS in the real world, discovering or verifying its idiosyncrasies, and pushing it to its limits. Most of the critical visual and positioning topics are well illustrated with diagrams and sample output, few of which are weakened by the lack of color in the grayscale figures. Last and certainly not least, readers should be pleased that the book's material has been updated for Internet Explorer 7, which promises to fix many inexcusable problems in earlier versions of the browser.
Rarely does one come across a programming book that has no significant flaws, and will likely become a favorite resource for developers everywhere. CSS: The Definitive Guide is a comprehensive, well-written, and welcome addition to the library of any Web developer who wishes to understand and utilize CSS better.
Michael J. Ross is a Web consultant, freelance writer, and the editor of PristinePlanet.com's free newsletter. He can be reached at www.ross.ws, hosted by SiteGround.
You can purchase CSS: The Definitive Guide from bn.com. Slashdot welcomes readers' book reviews -- to see your own review here, read the book review guidelines, then visit the submission page. -
Small Form Factor PCs
JoshuaBenuck writes "Make Projects: Small Form Factor PCs provides detailed step-by-step instructions on building a variety of small form factor systems, starting from the larger ones (about the size of a shoe box) and working its way down to the smallest (which is about the size of a pack of gum). It includes instructions on creating a digital audio jukebox, digital video recorder, wireless network range extender, home network gateway, network monitor, portable firewall, cheap Wi-Fi SSH client, and a Bluetooth LED sign." Read on for the rest of Joshua's review. Make Projects: Small Form Factor PCs author Duane Wessels, Matthew Weaver pages 232 publisher rating 8 reviewer Joshua Benuck ISBN summary A detailed step-by-step instructions on building a variety of small form factor systems
First off, this is a PDF that, as far as I can tell, is only available from oreilly's website. Most of the projects in the book will require at least $300 dollars to complete.
If you who don't know why you would want to use a small form factor PC there is a good discussion of why you might want to consider using one in the introduction along with a list of some of the currently available small form factor PCs. You'll need to keep in mind that some of the systems mentioned would be more commonly referred to as embedded systems so the authors have expanded the definition of what 'small form factor PC' means. Not all of the systems mentioned are used in one of the projects in the book so if you get bored or are looking for another small system to play with, this may be a good resource.
The remaining chapters deal with projects that each use one of the systems mentioned in the introduction. The chapter headings show a picture of the finished product, a list of needed components, a bar showing the time it will take, and a rating of difficulty from 'easy' to 'difficult'. The bars and pictures provide a quick indication of what you are getting yourself into with one glaring exception; they do not tell you how much money you'll need to sink into the project. In order to find this information you'll need to go back to the introduction and read through the paragraph that tells you about the system used in the chapter.
This is followed by an overview of what is going to be built and which system was chosen for the implementation along with a description of its unique characteristics that made it a good fit for the project. A lot of emphasis is put on the power consumption of the various components. They even measure it at startup, shutdown, and during normal operations. This is used to make a couple of power and cooling design decisions.
If you're like me, you don't like when your systems makes a lot of noise (Especially ones that aren't supposed to look like they have a computer in them). This book gives a good overview on what to look for when building a system that you want to be as quiet as possible. They mention whether the system can get away with passive cooling (e.g. no fans) and they show some very non-conventional ways to reduce the noise production of a system (such as hanging a hard drive from wires within an enclosure).
The step-by-step instructions on assembling the hardware components of the systems include plenty of good quality pictures that should make it easy to follow along with the various projects. The pictures are about a third the width of the page which I feel is a good size. They are crisp, clear, and add to the discussion of the topic at hand.
If you are an experienced Linux or BSD user you'll probably be able to skim most of the step-by-step operating system installation instructions. If you are new to Linux and BSD the steps should help you find your way to project completion. Just don't expect the book to have all of the answers all of the time. I feel it is impossible for one book to contain the answers to all the questions that someone new to this area may have. That said, I think this book does an admirable job at giving you what you need to succeed.
Littered throughout the text are various warnings, other options, and lessons learned which I found to be valuable. Some of these include mistakes the authors made (such as using a WinTV-Go card instead of a higher model with a built-in MPEG decoder), using a CF Card Reader if you are unable to use NFS to transfer files to a system that uses a Compact Flash card, and numerous other practical tidbits that should serve to save you some frustration when trying to do the projects on your own.
You don't have to use the hardware platforms or components recommended in this book to gain benefit from its contents. I've used the instructions on setting up the Linux Infrared Remote Control (lirc) project to help with an Iguanaworks USB Infrared Transceiver (a device that sends and receives infrared signals) while the authors used an Irman receiver. The MythTV box I've setup uses Ubuntu Linux instead of Gentoo Linux and uses a spare system instead of the Shuttle XPC used in the book. I found the instructions in the book to be indispensable as I worked through this.
I've never done a case mod before, but I like the idea of being able to hide away a computer in something that looks like a decoration. There is a detailed explanation of how the authors used an old antique radio as a cover for their digital jukebox. I enjoyed the discussion of the various places they could put the power supply, infrared receiver, and other design considerations. It really gave me a feel for what types of questions I'll need to answer as I do a case mod myself.
That leads me to what I think is the biggest strength of this book. It is the very conversational way in which the authors tell you what they did, why they did it, and what they could have done. Along the way they provide links for further information, and search terms that can help you learn more about the topic at hand. The book is packed with information that is up-to-date, accurate, valuable, and easy-to-read.
That said, some of the information will lose value over time. For example, the specific gumstix computer that was used does not appear to be available anymore. This is probably a good thing since the authors had to make some adjustments to get the 200 Mhz Bluetooth enabled version to work. I mention it only to point out that the information on the specific systems and the other instructions will lose value over time. It is impossible to future proof a work likes this.
The projects in this book opened my mind to a whole new world of what is possible with small systems. I haven't had a chance to purchase of the specific systems mentioned, but the information on setting up the various software and hardware components has already proven the book's worth. I look forward to one day getting my hands on the systems mentioned so I can gain the full advantage that small form factors provide. So if you don't mind spending $300+ to play with some a small form factor PC or you love to tinker with networking, or multimedia applications then you might want to give this book a try. I certainly don't regret it.
Slashdot welcomes readers' book reviews -- to see your own review here, read the book review guidelines, then visit the submission page. -
SQL Hacks
Scott Walters writes "Many of the recipes in SQL Hacks will improve the SQL you write day to day, and many will give you the confidence to attempt much more involved tasks with SQL. Other recipes will rarely if ever be needed, but make for a entertaining and education reading in a similar way that "worse case survival scenario" books do — SQL is pitted against the most difficult analysis tasks just as survival scenario books pit humans against pavement and lions. SQL Hacks fits well in the Hacks series, which raises the bar on advanced books by offering large, eclectic sets of tricks for problems that an unambitious person (a non-hacker) wouldn't ever push technology hard enough to run into. Put another way, the questions answered in a good Hacks book are ones that would get a "good question" comment rather than a an "RTFM!" response. It does a good job continuing where O'Reilly's SQL Cookbook left off, which is always difficult with two books written at slightly different times by different authors. Still, it's harder to review a Hacks book than a Learning book as, with hacks, the sky is the limit, and the reader will always find herself wishing for more. To this end, I hope O'Reilly continues to publish newer editions of their various Hacks books, drawing in more and more content in each edition, and identifying recipes that might better serve in the Cookbook counterpart." Read the rest of Scott's review. SQL Hacks author Andrew Cumming & Gordon Russell pages 386 publisher O'Reilly & Associates rating 7 reviewer Scott Walters ISBN 0-596-52799-3 summary Tips & Tools for Digging into Your Data
SQL Hacks skips most of the tutelage and shows you very specific ways for doing specific chores, with more explanation of how to adapt it than theory behind it. Most hacks have database specific information for the five databases the book tackles, and many hacks are inherently different on each system, making them completely different solutions to the same problem. Those five databases are Microsoft Access, Microsoft SQL Server, MySQL, Oracle, and PostgresSQL; most of the ideas require work to adapt or are completely specific to the database system, so I wouldn't suggest straying from this supported set. The authors did their homework, and SQL Hack's strengths are the depth, detail, and level of knowledge with which each database system is covered, and the book's willingness to get down and gritty. There's never an impression that juicy details were omitted because the authors didn't want to expend the effort to pick a colleague's brain or hunt down a factoid that never got documented elsewhere. Learning how to create indices on functions with multiple arguments in Postgres was worth more than the "hack" it was a footnote in. This dedication carriers over to screen shots showing how something is done in Microsoft Access directly opposite Unix shell pipelines between grep, perl, and the SQL command shell. Most books, including mine, are a bit awkward or vague on either Unix or Microsoft Windows, but the author's and contributor's experience on this one expertly covered platforms specific database topics. Besides just database systems and platforms, the authors challenged themselves to show how to securely and efficiently use the database interfaces of a set of languages: C#, Java, Perl, Python, and PHP. The polish shows, and you'll have absolute confidence that all of the tricks really are at your fingertips, regardless of your choice of operating system, database system, or programming language.
It gets bonus points for mentioning non-obvious types of input, such as cookies, that must be sanitized or sent through bound parameters, in its discussion of SQL injections. In the security department, it looks at SQL injections from three points of view: early on in the book, correct code is shown; later, SQL injections are shown from the point of view of the attacker, with several pages of strategies and scenarios for formulating attacks; and then from the point of view of the defender, who has to defang and avoid these scenarios — extra bonus points for this comprehensive treatment.
If you're looking for a quick buy/don't buy indication, then, by all means, buy it. That is, assuming that it's not intended to be your first or only SQL book. By it's own indication, it won't teach you the basics of database normalization, installation, and so forth. I would buy it as a second SQL book, though, after the fantastic 'The Practical SQL Handbook', as it's written to a much higher standard than most books, and gets things right, such as security, the intricacies of using a database to handle accounts, and transactions and shopping carts. The cover text promises lots of advanced hackery, but that's vague. "Pushing the limits of SQL"... "Solve puzzles using SQL"... "Manage users and audit the changes they make to the database".
Here are the major sections: SQL Fundamental; Joins, Unions, and Views; Text Handling; Date Handling; Number Crunching; Online Applications; Organizing Data; Storing Small Amounts of Data; Locking and Performance; Reporting; Users and Administration; and Wider Access.
Wider Access requires some explanation. It deals with locking down the various database systems to securely providing guest accounts, or, more generally, to limit damage in the case of an SQL injection attack or similar compromise.
With some well designed tables, SQL Hacks will show you quite a few tricks, some of them quote involved, quite non-obvious, and quite clever, to extract meaning from the data. You'll probably learn quite a few new types of reports you can do — intersecting ranges from different sets of data, outputting SVG pie charts, swapping rows and columns, finding medians, computing running totals, and computing running functions such as compound interest struck me as the most useful and got mental bookmarks.
I have two metrics for this book. The first metric is whether I'd buy it if I came across it in a book store, and that's a function of whether I'd have exhausted what it had to offer after an hour or so of furious skimming and intentionally picking out the best parts from the table of contents. Very few books make this cut for me.
The other metric is whether the authors did at least what I imagine I would have done were I writing it. This test is also a difficult one but builds in a great deal of forgiveness as my ideas are quite likely dumb ones.
I totally dig the cut-and-paste ASCII query results. The authors could have easily marked all of those up in DocBook and made it prettier but also alien compared to what you'll see at the computer. They're not ashamed of the SQL command shell, and they're not ashamed of SQL.
Many hacks have several examples, covering the problem with different constraints and end goals in mind.
Multi-platform, and thoroughly so. One moment, it's showing how to use XSLT tools from the command line on Microsoft Windows, and on the next page, there's a Unix shell pipeline with wget, xsltproc, and grep. Perl one-liners abound, and there are screen shots from Windows applications with instructions for navigating the menus and setting the needed options. You won't feel shortchanged for running the "wrong" platform.
When a powerful, modern SQL extension, such as replace, gets ratified by the standards committees, the authors let you know. Sidebars are spread around sharing the good news that sometime you might not have heard of before is portable. At the same time, some features are just fluff, and you're warned off of operations intentionally left out of the SQL92 standard.
Sometimes database systems have non-portable local extensions, such as MySQL's full-text indexing and SQLServer's XML handling features, and lots of these get motioned too, usually as variations on examples demonstrating the feature as a short-cut or simplification.
The treatment of security is first rate. The polish is top notch. Writing a book is a huge undertaking, and the economics of book publishing gives publishers little margin for advances. A book that reads like it's third release but is actually in its first can only be the product of an exceptional level of dedication by the authors.
Rarely, the authors do get tutorial-ish, but only a little, and I think it works: "Choose the right join style for your relationship" deals the difference between inner and outer joins, and whether records should be partially populated with nulls or omitted entirely when relations between tables can't be made for a record. Another section shows how to convert between subqueries and outer joins, and talks about when it's possible, and this serves as a sort of lesson in demonstrating the equivalencies between the two.
The "Hacks" format is similar to the "Cookbook" format. Both offer small, randomly-accessible (flip to it when you need it) examples of how to accomplish various tasks. In the traditional, MIT circles, a hack is piece of work that's either brilliant in its simple elegance or else brilliant in its expediency and simple effectiveness, and as such, is worthy of some esteem. It's also work that's custom for a particular scenario and has limited domain — in other words, it's a highly specialized fix or improvement. If a stock fix is applied systematically, that's mechanical, not clever. By this definition, showing users how to invoke their SQL monitor, or showing users how to decide whether to use an outer or inner join, are not hacks. Few of the recipes triggered this peeve, and they were early in the book, but including those few muddles the question of who the audience is, and lowers the standard for the Hacks series, endangering its basic premise. 'SQL Hacks' isn't alone in this sin; most of the Hacks books do it to some degree.
It was written by two professors at Napier University in Edinburgh, Scotland. The style, grammar, and presentation are perfectly fine — but only that. It's not a bone dry college text book, but it was written with a dedication to professionalism that can make a technical book tedious and will certainly keep it from becoming a classic. The literary power of Brooks, Hoare, or Wall is conspicuously absent.
Authors of Hacks books are at liberty to tap the experiences of the best and brightest of the field, and the best and brightest often have tricks just too strange, clever, or specialized to fit into any ordinary sort of text. I'd like to imagine that if I were charged with writing one of these, I'd have hundreds of contributors (I'm not likable, but I am persistent). Nothing against the contributors (two of them more than 20 years experience each), but why stop at three?
I said I had two benchmarks: whether I'd be likely to walk out of a bookstore with it if I had an hour alone with it to try to get my fill, and whether it touched on the subject that I thought it should.
Before cracking the cover, I stopped to ponder what would really impress me, and what I'd like to see. The Internal Functional Programming Competition had a puzzle solved by the contest winner using SQL. I'd like to see similar combinatronics and optimization problems solved using SQL. I'd like to see a good implementations of semi-infinite-strings, the text indexing data structure and algorithm that Google uses. I've done a version of this, but my implementation leaves something wanting. When reforming badly non-normalized databases, I've had to build a normalized database in parallel and populate it from queries on the non-normalized one. It would be interesting to hear how other people approach that problem, and what I can learn from them. There are other jobs that I've tackled and managed despite never having been prepared for. Renumber a display_order priority on records in response to the user adjusting or reassigning priorities. Trees using self-joining tables is something more people should be exposed to, especially when presented with non-normalized data.
There was no semi-infinite-string implementation, but the book showed how to build full-text indexes the optimal way for each database, using built-in full-text indices and optional add-on modules offering full-text indexing. The renumbering example took the more general form of running-totals computations. There were a few examples of self-joining data, and one tree example visualized the structure. Normalizing data had tricks, including some with views, and it showed how to use Cartesian joins to do combinatronics problems. So, aside form one sort-of, the authors nailed my entire wish list. That's amazing — I've never had that happen before, actually.
The highest endorsement a book can earn from me (a cheapskate, who already has a good deal of knowledge from working the industry for ten years) is getting bought on a random trip to the bookstore where I hadn't been looking for or intending to buy anything, and paying full price on top of that. Books that are surprising, riveting, and so packed with information that I couldn't possibly copy all of the best parts down and exhaust it in an hour or two are the ones that get purchased in this manner. I have 'SQL Hacks' in my hot little hands here at home, so this benchmark is now synthetic, but... I'm somewhat undecided, and not sure whether I would or wouldn't walk out with it. More likely, I'd just put it on my wishlist and pick it up later, for a discount (I'm a cheapskate, remember). If you don't know how to do more than half of the things listed in the table of contents, most certainly buy it. If you find yourself frequently working with SQL and constantly face new problems, buy it. If you find yourself still learning SQL and wanting a variety of examples, buy it. If you're shopping for a handful of good SQL books, buy it.
On a scale of stuff laying around the house, I give it 7 gold stars, half a box of binder clips, some AA batteries, and a bottle of really good soy sauce.
You can purchase SQL Hacks from bn.com. Slashdot welcomes readers' book reviews -- to see your own review here, read the book review guidelines, then visit the submission page. -
'Web 2.0' Most Popular Wikipedia Entry
theodp writes "It came as no surprise to Tim O'Reilly that Nielsen BuzzMetrics found 'Web 2.0' the most cited Wikipedia article of the year (as measured by blog mentions). After all, says Tim, 'the Wikipedia article on Web 2.0 is indeed pretty darn good.' IIRC, the Web 2.0 Trademark Scandal was also good for a citation or two. BTW, the material in the article crediting O'Reilly & Co. with originating the term 'Web 2.0' was first contributed by '209.204.147.33', which is coincidentally an O'Reilly IP address." -
Google Deprecates SOAP API
Michi writes "Brady Forrest at O'Reilly Radar reports that Google has deprecated their SOAP API; they aren't giving out any new SOAP Search API keys. Nelson Minar (the original author of the Google SOAP API) argues that this move is motivated by business reasons rather than technical ones. Does this mark the beginning of the end for SOAP or for ubiquitous middleware in general?" Forrest's post quotes developer Paul Bausch: "This is such a bad move because the Google API was the canonical example of how web services work. Not only is Google Hacks based on this API, but hundreds of other books and online examples use the Google API to show how to incorporate content from another site into a 3rd party application." -
CSS Cookbook
Michael J. Ross writes "Anyone involved with the coding of Web sites likely knows that Cascading Style Sheets (CSS) should be used for styling the content of their sites' pages — setting text sizes and fonts, setting background colors, sizing margins, positioning images, and more. CSS allows the Web developer to specify the visual appearance of the site, separately from the HTML, and thus to be able to make changes in the future within a single stylesheet, rather than hunting through the HTML and modifying every occurrence of each affected element. The benefits of CSS are many, but so too can be the frustrations when the developer turns for help to CSS books heavy on theory and light on practical explanations. For every Web site 'cook' feeling the heat in their cyber kitchen, there is an ingredient that can help: CSS Cookbook." Read the rest of Michael's review, CSS Cookbook author Christopher Schmitt pages 538 publisher O'Reilly Media rating 8 reviewer Michael J. Ross ISBN 0596005768 summary Practical solutions to common CSS challenges
Written by award-winning Web designer Christopher Schmitt, this book is published by O'Reilly Media, under the ISBN 0596005768, and is in its second edition, having been updated for Internet Explorer 7 and Firefox 1.5. The book has its own Web page on the publisher's site, offering the book's table of contents, the index, Appendix D ("Styling of Form Elements," in PDF format), and links for reading and submitting book reviews/comments, as well as reading and reporting errata (there are none, as of this writing).
The book's 538 pages are organized into 12 chapters, which cover the major areas of interest to the Web developer: CSS overview, typography, images, page elements, lists, links and navigation, forms, tables, page layouts, printable pages, hacks and workarounds, and design considerations. Appendix A briefly describes some of the better online CSS resources, including tutorials, design guides, discussion groups, technical references, and tools, such as the W3C validators. The next two appendices cover CSS 2.1 properties, proprietary extensions, selectors, pseudo-classes, and pseudo-elements.
The fourth and last appendix, on the styling of form elements, details how 20 CSS properties affect eight form elements, as displayed within Windows Internet Explorer 5, 5.5, 6, and 7; Mac Safari 2; Windows and Mac Firefox 1.5; Windows and Mac Netscape Navigator 7.2; and Opera 8.5. The form elements considered are: checkboxes, file upload elements, radio buttons, text fields, multiple options, select elements, submit buttons, and text areas. The author does not explain exactly what page elements are meant by "File Upload" (at the beginning of the appendix) or "File Input" (the actual section title). Presumably he is referring to the file display field and Browse button, and not the file locator dialog box, which is determined by the browser and operating system. More importantly, he does not explain what is meant by "multiple options" nor "select elements," and neither term is listed in the book's index. Future editions of the book would benefit by beginning every element's section with an example, showing the code as well as the element's appearance on a Web page. Despite this obvious omission, this appendix could prove a godsend to anyone concerned with how these various types of elements are affected by CSS within these eight major browser versions. As noted earlier, the appendix can be downloaded for free.
HTML/CSS books generally fall into two broad categories: Introductory books are usually sufficient for beginners, because they cover the basics. But they are typically useless to the veteran developer who is struggling to understand why Internet Explorer is mucking up yet another page that looks fine in Firefox, Opera, and Safari — and how to work around the problem. Advanced books assume that the reader already has a relatively solid understanding of the technologies, and uses that basis as a foundation from which to explore sophisticated design techniques. But even those books prove inadequate for the developer who is simply wondering how to best use pure CSS to do such presumably straightforward tasks as positioning some images horizontally, with small captions centered underneath each one. In fact, many of those advanced books seem to have little interest in clearly explaining how the reader can do what the author has done, largely because the sample projects and their source listings are too long and involved, thus burying the critical HTML and CSS in pages of code.
There is clearly a great need for one or more HTML/CSS books aimed at the developer who already understands the basics, and wants to apply that knowledge for building robust Web pages, all while following defensible best practices. The O'Reilly "Cookbook" titles are intended to fill that gap, by presenting the material in the form of recipes, each comprising a brief statement of the problem to be solved, a summary of the solution, and a discussion of the solution's details. Oftentimes additional resources are referenced, in a "Sea Also" subsection, which might have one or more links to relevant Web sites. The discussion subsections usually have sample code, in addition to a figure showing the code's output.
Possibly the greatest benefits of the cookbook format, is that it forces the author to clearly state the purpose of each section, and then to get right to the point of how to achieve that purpose. This prevents the meandering seen in many of the advanced design books, which is the main reason why they can be so frustrating for the developer who wants to quickly find out how to perform a specific task on a Web page, such as the image positioning task mentioned earlier. Possibly the biggest downside to the cookbook format is that it results in contrived problem statements, such as the very first one in CSS Cookbook: "Problem — You want to use CSS in your web pages." Is that truly a problem? Is it not much more a goal or task, than some sort of problematic difficulty?
Yet aside from any misleading subsection titling, the recipe format does cause any (largely) expository material in a technical book to get chopped up into somewhat artificial pieces. It is more noticeable in the first chapter of this particular book, titled "General," in which Schmitt explains the fundamentals of CSS: selectors, classes and IDs, properties, the box model, style sheets, comments, shorthand properties, floating images, absolute and relative positioning, and using CSS with the more common page development tools. As the author gets into more advanced topics — for which individual subsections can stand more on their own — the recipe format works fine. One advantage is that the section titles end up being detailed enough that the reader can, in most cases, quickly find the relevant section to address their needs.
Overall, this book is a fine addition to O'Reilly's growing list of programming titles. However, like all books, it is not perfect. It does not cover all of the more common tasks that the average Web programmer might want to accomplish — but it does hit the bulk of them. Sadly, all of the figures in the book are in black and white, including those displaying colors on the sample Web pages. Shades of gray are just not optimal. Fortunately, in most cases, the crux of the technique is discernible. In addition, the sample code has too many instances where layout is achieved using tables, and not pure CSS. Lastly, the book's index — similar to that of so many other technical books nowadays — could certainly use some beefing up. After all, if the reader cannot find the desired material using the table of contents, the index is their last hope, before resorting to time-wasting page flipping.
In terms of HTML and CSS information, the topics are well chosen, and the coverage of browser hacks and workarounds is excellent. Also, the most critical parts of the code are helpfully bolded. For those readers completely unfamiliar with JavaScript, it is used only where unavoidable. The book's material is neatly presented, and the author's writing style is straightforward and approachable.
On balance, CSS Cookbook is to be recommended to any developer looking for a CSS guide that is concise, clearly written, well-illustrated, and addresses the most common challenges in building Web pages.
Michael J. Ross is a computer consultant, freelance writer, and the editor of PristinePlanet.com's free newsletter. He can be reached at www.ross.ws, hosted by SiteGround.
You can purchase CSS Cookbook from bn.com. Slashdot welcomes readers' book reviews -- to see your own review here, read the book review guidelines, then visit the submission page. -
CSS Cookbook
Michael J. Ross writes "Anyone involved with the coding of Web sites likely knows that Cascading Style Sheets (CSS) should be used for styling the content of their sites' pages — setting text sizes and fonts, setting background colors, sizing margins, positioning images, and more. CSS allows the Web developer to specify the visual appearance of the site, separately from the HTML, and thus to be able to make changes in the future within a single stylesheet, rather than hunting through the HTML and modifying every occurrence of each affected element. The benefits of CSS are many, but so too can be the frustrations when the developer turns for help to CSS books heavy on theory and light on practical explanations. For every Web site 'cook' feeling the heat in their cyber kitchen, there is an ingredient that can help: CSS Cookbook." Read the rest of Michael's review, CSS Cookbook author Christopher Schmitt pages 538 publisher O'Reilly Media rating 8 reviewer Michael J. Ross ISBN 0596005768 summary Practical solutions to common CSS challenges
Written by award-winning Web designer Christopher Schmitt, this book is published by O'Reilly Media, under the ISBN 0596005768, and is in its second edition, having been updated for Internet Explorer 7 and Firefox 1.5. The book has its own Web page on the publisher's site, offering the book's table of contents, the index, Appendix D ("Styling of Form Elements," in PDF format), and links for reading and submitting book reviews/comments, as well as reading and reporting errata (there are none, as of this writing).
The book's 538 pages are organized into 12 chapters, which cover the major areas of interest to the Web developer: CSS overview, typography, images, page elements, lists, links and navigation, forms, tables, page layouts, printable pages, hacks and workarounds, and design considerations. Appendix A briefly describes some of the better online CSS resources, including tutorials, design guides, discussion groups, technical references, and tools, such as the W3C validators. The next two appendices cover CSS 2.1 properties, proprietary extensions, selectors, pseudo-classes, and pseudo-elements.
The fourth and last appendix, on the styling of form elements, details how 20 CSS properties affect eight form elements, as displayed within Windows Internet Explorer 5, 5.5, 6, and 7; Mac Safari 2; Windows and Mac Firefox 1.5; Windows and Mac Netscape Navigator 7.2; and Opera 8.5. The form elements considered are: checkboxes, file upload elements, radio buttons, text fields, multiple options, select elements, submit buttons, and text areas. The author does not explain exactly what page elements are meant by "File Upload" (at the beginning of the appendix) or "File Input" (the actual section title). Presumably he is referring to the file display field and Browse button, and not the file locator dialog box, which is determined by the browser and operating system. More importantly, he does not explain what is meant by "multiple options" nor "select elements," and neither term is listed in the book's index. Future editions of the book would benefit by beginning every element's section with an example, showing the code as well as the element's appearance on a Web page. Despite this obvious omission, this appendix could prove a godsend to anyone concerned with how these various types of elements are affected by CSS within these eight major browser versions. As noted earlier, the appendix can be downloaded for free.
HTML/CSS books generally fall into two broad categories: Introductory books are usually sufficient for beginners, because they cover the basics. But they are typically useless to the veteran developer who is struggling to understand why Internet Explorer is mucking up yet another page that looks fine in Firefox, Opera, and Safari — and how to work around the problem. Advanced books assume that the reader already has a relatively solid understanding of the technologies, and uses that basis as a foundation from which to explore sophisticated design techniques. But even those books prove inadequate for the developer who is simply wondering how to best use pure CSS to do such presumably straightforward tasks as positioning some images horizontally, with small captions centered underneath each one. In fact, many of those advanced books seem to have little interest in clearly explaining how the reader can do what the author has done, largely because the sample projects and their source listings are too long and involved, thus burying the critical HTML and CSS in pages of code.
There is clearly a great need for one or more HTML/CSS books aimed at the developer who already understands the basics, and wants to apply that knowledge for building robust Web pages, all while following defensible best practices. The O'Reilly "Cookbook" titles are intended to fill that gap, by presenting the material in the form of recipes, each comprising a brief statement of the problem to be solved, a summary of the solution, and a discussion of the solution's details. Oftentimes additional resources are referenced, in a "Sea Also" subsection, which might have one or more links to relevant Web sites. The discussion subsections usually have sample code, in addition to a figure showing the code's output.
Possibly the greatest benefits of the cookbook format, is that it forces the author to clearly state the purpose of each section, and then to get right to the point of how to achieve that purpose. This prevents the meandering seen in many of the advanced design books, which is the main reason why they can be so frustrating for the developer who wants to quickly find out how to perform a specific task on a Web page, such as the image positioning task mentioned earlier. Possibly the biggest downside to the cookbook format is that it results in contrived problem statements, such as the very first one in CSS Cookbook: "Problem — You want to use CSS in your web pages." Is that truly a problem? Is it not much more a goal or task, than some sort of problematic difficulty?
Yet aside from any misleading subsection titling, the recipe format does cause any (largely) expository material in a technical book to get chopped up into somewhat artificial pieces. It is more noticeable in the first chapter of this particular book, titled "General," in which Schmitt explains the fundamentals of CSS: selectors, classes and IDs, properties, the box model, style sheets, comments, shorthand properties, floating images, absolute and relative positioning, and using CSS with the more common page development tools. As the author gets into more advanced topics — for which individual subsections can stand more on their own — the recipe format works fine. One advantage is that the section titles end up being detailed enough that the reader can, in most cases, quickly find the relevant section to address their needs.
Overall, this book is a fine addition to O'Reilly's growing list of programming titles. However, like all books, it is not perfect. It does not cover all of the more common tasks that the average Web programmer might want to accomplish — but it does hit the bulk of them. Sadly, all of the figures in the book are in black and white, including those displaying colors on the sample Web pages. Shades of gray are just not optimal. Fortunately, in most cases, the crux of the technique is discernible. In addition, the sample code has too many instances where layout is achieved using tables, and not pure CSS. Lastly, the book's index — similar to that of so many other technical books nowadays — could certainly use some beefing up. After all, if the reader cannot find the desired material using the table of contents, the index is their last hope, before resorting to time-wasting page flipping.
In terms of HTML and CSS information, the topics are well chosen, and the coverage of browser hacks and workarounds is excellent. Also, the most critical parts of the code are helpfully bolded. For those readers completely unfamiliar with JavaScript, it is used only where unavoidable. The book's material is neatly presented, and the author's writing style is straightforward and approachable.
On balance, CSS Cookbook is to be recommended to any developer looking for a CSS guide that is concise, clearly written, well-illustrated, and addresses the most common challenges in building Web pages.
Michael J. Ross is a computer consultant, freelance writer, and the editor of PristinePlanet.com's free newsletter. He can be reached at www.ross.ws, hosted by SiteGround.
You can purchase CSS Cookbook from bn.com. Slashdot welcomes readers' book reviews -- to see your own review here, read the book review guidelines, then visit the submission page.
{kind=link}
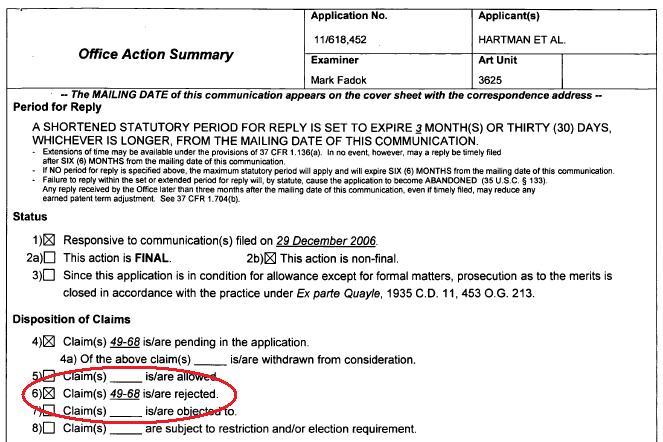{kind=link}
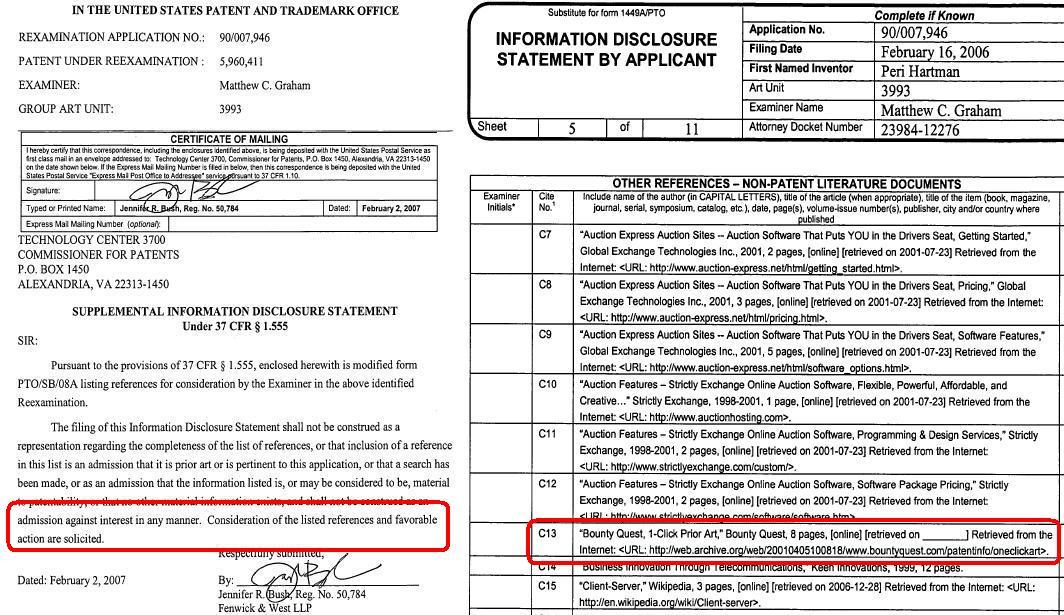{kind=link}