 Slashdot Mirror
Slashdot Mirror
Domain: spatula-city.org
Stories and comments across the archive that link to spatula-city.org.
Comments · 98
-
Re:OMG Ponies
-
Re:Probably optimizing for larger numbers
Well, I just compared the vectorized implementation to the simple tail-call optimized version (ie. reduced to a simple loop) that GCC 4.4 produced.
The vectorized version was a paltry 6% faster on my box, measured across 65,536 iterations. (My machine is a AMD Phenom X4, 3.4GHz.)
So, it is faster, but not by a meaningful amount, and probably not enough faster to justify the hilarious code size increase.
-
Re:Probably optimizing for larger numbers
Well, I just compared the vectorized implementation to the simple tail-call optimized version (ie. reduced to a simple loop) that GCC 4.4 produced.
The vectorized version was a paltry 6% faster on my box, measured across 65,536 iterations. (My machine is a AMD Phenom X4, 3.4GHz.)
So, it is faster, but not by a meaningful amount, and probably not enough faster to justify the hilarious code size increase.
-
Vectorized factorials!
One amusing thing I discovered is that GCC 4.8.0 will actually unroll and vectorize this simple factorial function: Just look at that output!
-
Vectorized factorials!
One amusing thing I discovered is that GCC 4.8.0 will actually unroll and vectorize this simple factorial function: Just look at that output!
-
Re:Oh F*CK That!
Seriously. That fucking sucks. I've been on this site a while ("Look Mom, he has a 4 digit user id"), and that is by far the crappiest design I've seen.
Even OMG Ponies?
-
Re:As the Slashdot Front Page Said at One Time...
Hey, folks, where's the screenshots at? Here's mine...
-
Re:0.000000312 kph is XXX in scale speed?
Like this.
-
Re:Model M
Children, children! You goll-darned whippersnappers with your "ATs" and 3.5" so-called "floppies" need to respect your elders! Why, I has me here my original XT keyboard, and I likes it!
-
Re:OMG..
For the nostalgic, I saved a screen cap...
-
Re:What's it like in Japan? Will this cause change
From what I remember, during time changes or other corrections, they'd shift the minute hand's gear to match the second hand until the clocks displayed the right time. The shift-in and shift-out happened right at the 12 o'clock position.
As a result, the motor still ran at the same rate, and at no point did any hand move faster than 6 degrees/second. Nonetheless, the displayed time would advance at 60x normal rate.
It's the kind of thing that could be handled with a simple shifting mechanism that changed which gear drove the minute hand. Even simpler than VTEC.
-
Re:Taxpayer money to build out Big Business Backbo
Well, seeing as I work on the chips that go into the base stations, at least I and my coworkers benefit from this. And then there's all the people actually installing and maintaining the towers, etc. Not all of the money gets used like this.
Of course, I haven't seen a good argument for what the economic benefits of widely deployed broadband might be. Sure, everyone can now stream YouTube videos at higher definition. But in terms of basic economic benefit, even if you have fairly slow (by today's standards) Internet access, you still can access online retailers, news, government web sites, etc. You just don't get all the shiny baubles.
I surfed the web over a shared 14.4kbps dialup link once upon a time. It wasn't great, and would be unbearable with many of today's ad-laden websites. But, with AdBlock and FlashBlock, 56kbps modems are at least workable, if not great.
-
Introducing NASACAR
Oh boy, won't this be fun? Artist's conception...
-
Arrrrr! They be pirates, matey!
Avast! They even get their own button on the pirate keyboard!
-
Re:What is it?
I was thinking the exact same thing. With a few choice search and replace steps, this could almost be a review for anything! I gather it has something to do with education, given the references to educators and students.
Looking at this from the perspective of $PROFESSION, I can see this publication being used in two main ways. $PROFESSIONALS can dip in and out of the publication to cement their understanding and it can also be used in formulating support for $USERS who are using $PRODUCT for the first time. For both of these purposes, the authors' previous experience of writing instructional text for technology shines through, with flowing informal writing that is easy to digest and a logical stepped approach to introducing each of the key features. Use of screenshots is intelligently done and you are provided with questions to test your understanding within every chapter. I particularly liked the 'Have a go hero' sections provided throughout the book, which are designed to encourage deeper investigation by the reader.
Just a wee bit of background would have made the review more relevant, and less like this..
-
403?
You mean, 403 is not forbidden?
-
Ha ha!
What about Falcon 7?
-
Re:Some kind of...
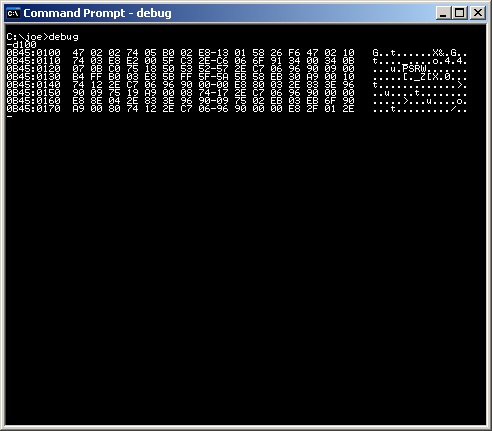
Bullshit. I agree that the 0x prefix specifies that the digits that follow it are in hexadecimal. It does NOT specify the encoding of the data in the bits. For example, the hexadecimal string 0x3F800000 is the single precision IEEE floating point value '1.0', rendered as a hexadecimal string. Try it out and see.
Binary coded decimal is just that: A binary coding scheme for decimal values. How you render the binary string for human readability purposes is up to you! That's just the same as writing "one million two hundred thirty four thousand five hundred sixty seven and eighty nine hundreths" as 1,234,567.89 or 1234567.89 or 1.234.567,89 (in parts of the world that use periods and commas the opposite of the way the US does).
I suggest you've never seen an actual memory dump from a real computer, have you? Here's one I took just now on my Windows box. Which of these values are integers, floating point values, x86 opcodes or BCD values? Memory dumps don't indicate, because the memory itself doesn't know! Once it's in memory it's all just bits!
-
Re:Touch typing is irrelevant
I never made a conscious effort to find the home row keys with F/J. But, I realized I was doing it when I sat down at an older Mac and suddenly couldn't type. See, Apple had put the nubs for the home row on D and K instead of F and J, since apparently the middle finger is slightly more sensitive than the index. (My Platinum Apple IIe in the other room also has it on D/K.) Only later Macs moved it to match PCs.
What a shock it was. I never realized I was making use of that feature until it bit me in the arse!
For those that doubt me, I happened to still have that keyboard in my garage, and I just took some pictures of its aberrant finger bumps. You can see them here and here. A picture of the complete keyboard is here. I was sad when OS/X came out and the ADB keyboards stopped working properly. (IIRC, it kept inserting extra space characters or something. I forget now. All I know is that it was annoying to the point of being unusable, which was sad, because those were decent keyboards. And yes, that keyboard needs a cleaning. Sitting in the garage for several years has definitely yellowed whatever finger residue was on it to something rather obvious and gross.)
-
Re:Touch typing is irrelevant
I never made a conscious effort to find the home row keys with F/J. But, I realized I was doing it when I sat down at an older Mac and suddenly couldn't type. See, Apple had put the nubs for the home row on D and K instead of F and J, since apparently the middle finger is slightly more sensitive than the index. (My Platinum Apple IIe in the other room also has it on D/K.) Only later Macs moved it to match PCs.
What a shock it was. I never realized I was making use of that feature until it bit me in the arse!
For those that doubt me, I happened to still have that keyboard in my garage, and I just took some pictures of its aberrant finger bumps. You can see them here and here. A picture of the complete keyboard is here. I was sad when OS/X came out and the ADB keyboards stopped working properly. (IIRC, it kept inserting extra space characters or something. I forget now. All I know is that it was annoying to the point of being unusable, which was sad, because those were decent keyboards. And yes, that keyboard needs a cleaning. Sitting in the garage for several years has definitely yellowed whatever finger residue was on it to something rather obvious and gross.)
-
Re:Touch typing is irrelevant
I never made a conscious effort to find the home row keys with F/J. But, I realized I was doing it when I sat down at an older Mac and suddenly couldn't type. See, Apple had put the nubs for the home row on D and K instead of F and J, since apparently the middle finger is slightly more sensitive than the index. (My Platinum Apple IIe in the other room also has it on D/K.) Only later Macs moved it to match PCs.
What a shock it was. I never realized I was making use of that feature until it bit me in the arse!
For those that doubt me, I happened to still have that keyboard in my garage, and I just took some pictures of its aberrant finger bumps. You can see them here and here. A picture of the complete keyboard is here. I was sad when OS/X came out and the ADB keyboards stopped working properly. (IIRC, it kept inserting extra space characters or something. I forget now. All I know is that it was annoying to the point of being unusable, which was sad, because those were decent keyboards. And yes, that keyboard needs a cleaning. Sitting in the garage for several years has definitely yellowed whatever finger residue was on it to something rather obvious and gross.)
-
Re:Seems kinda low-spec as a starting point
I have one of MikroElektronika's boards. It hasn't been a perfect experience, but it got me started quickly. You can see some of my Mad Scientist stuff here. I used the dsPIC33 to emulate video game cartridges in software.
-
Re:Seems kinda low-spec as a starting point
Ah, I see. I guess I'm accustomed to writing for microcontrollers, so I never saw that as a barrier. I've even done a design with a related PIC part (PIC16 instead of PIC32), which is why I wondered about the specs on this PICaxe.
If it were me making this sort of laptop, I'd just write my "OS" in C and compile with GCC and be on my merry way.
--Joe
-
Re:Meetings are BS
You might like this then.
-
Re:Authentic is the wrong word
Have you listened to the Extended Dance Remix?
-
Re:deliver on your promises?
Not exactly, on a couple counts. Word has it (and I don't know if it's true or computer folklore) that Woz assembled Integer BASIC by hand. That is, it's written in assembly code, but the wasn't assembled by a computer.
What we have available to us are the Apple I and Apple II Integer BASIC program images. (Cassette dump for the Apple I, ROM dump for the Apple II.) These are the machine code images for the two programs. They can be disassembled to show us the instructions, but that doesn't tell us anything about the intent of those instructions. Any additional comments, labels, etc. are lost in the assembly process. One would have to reverse engineer the code to determine its intent and function.
Here's an example of assembly source code with all its comments intact. In contrast, here's an example of assembly code that's been reverse engineered (only partially, though) from a disassembly. As you can see, there's lots of question marks and half-explanations. Variables and functions don't have names--there are only raw location addresses. Much harder to work with and understand.
If he were to post source code, I wouldn't be at all surprised if it were scans of old notebooks. I also wouldn't be surprised if the source is lost to the sands of time. I'd hope that later versions (such as the Apple II version) did benefit from machine assembly, and so the source might be found in electronic form somewhere, or maybe a printout.
-
Re:Learn C and Python
*shrug* When I'm debugging my own code, the readability matters most to me. When I check in the debugged code, I'll have removed my temporary debugging statements. That's the whole point of temporary debug statements that are easy to remove.
If some debug code is more permanent, then yes, I indent it with everything else for precisely the reason you mention. Go take a look in that same file I posted above for instances of calls to "dprintf".
The temporary debug statements (the ones that were in column 0) in that file are a fluke. I had hacked in a feature (saving voice samples) and accidentally checked in some debug statements that should have been deleted or turned into actual status messages. (That's why I don't have more examples to show, since they don't persist. I have plenty more examples of "permanent debug" statments indented with the code.) The fact these temporary statements are in column 0 makes them stick out similarly to "// XXX: FIXME" or "// XXX: DEBUG", but it's clearer that they're meant to be deleted on sight.
-
Re:Learn C and Python
I count myself among those who don't like Python's syntactically significant whitespace. In my particular case, I use a particular programming idiom that I use when debugging code. I put temporary debug statements in column 0 of my code, purposefully, so that they stick out like a sore thumb and are easily found and removed later. They're "out of band" over there.
You can see some examples in this code. I had left in some "jzp_printf" calls in some code I added for saving voice samples to disk. You can see those near the top.
That idiom works in multiple languages, but it doesn't work in Python. Of course, it shouldn't be hard to write a translator that translates { } style blocks into Python translation as a preprocessing step.
-
Re:Non-Obvious & Novel?
No assumption made. Taco said this in the summary: "The next mail comes from a lady who doesn't mind clicking on things, in fact she loves it. If she had her way, everyone would have carpal tunnel syndrome." Maybe she should meet Mayor Quimby.
-
Re:Make it tastier
-
Re:How funnty that this comes 51 minutes after
-
Re:This is horrible
Because, you know, you're being forced to read these posts against your will.
-
Re:Sounds reasonable
What a novel concept! If I don't Google myself, I will never show up on any searches! I think there may be prior art.
-
Re:Unbelievable
-
Re:Very interesting
Slightly OT, but will it decode this copy of Pirate Adventure?
-
Re:Alternative tools
Probably the most elaborate scheme I've seen so far is the Mattel Electronics Keyboard Component. It encodes everything into blocks of 32 10-bit words, each protected by a 5-bit detect-2-correct-1 Hamming code. The 32 words are then re-interleaved as 15 32-bit words. Each 32-bit word gets prefixed with a 5-bit framing header. That's prefixed by a block of zeros and a special 64-bit sync pattern per block. (I believe the whole sync structure was about 256 bits long.) The whole shebang is then Manchester encoded and put out to tape. Furthermore, the drive had a carrier-detect signal that it supplied in addition to the Manchester decoded bits.
The net result is a fairly robust protocol. Because the 32 data words were interleaved, dropout errors would get spread among multiple words. Thus, a burst error would show up only as 1 or 2 bit errors in each individual word. In addition, if a given word shows up as non-correctable, it was sometimes recoverable by flipping bits based on where the carrier was lost and trying again.
Other nifty aspects of its design: There was an additional pre-header on blocks that was recorded at (I think) 1/3rd the normal carrier frequency. This allowed the drive to detect interesting headers while fast-forwarding or rewinding. Since the drive was computer controlled, it allowed for fully automatic operation, including hardware seeks.
What was the bit rate? Well, I believe the raw bit rate for data bits coming off the tape was about 3000 bps. Factoring in encoding overhead, though, I'd say the final throughput was less than half that. A quick calculation suggests a nominal throughput around 1200 baud, give or take.
--Joe
-
Re:Yellow on Blue
It's weird, but I do better with light text on a dark background when coding, and vice versa with documents and technical web pages most of the time. Casual content is more flexible. That said, it also matters what sort of display you're using as to what has the best fatigue properties, and that can bring other factors into play such as refresh rate and font.
Regardless of whether you prefer dark on light vs. light on dark, CRTs really want nice, thick fonts, particularly if you're at high resolution. This probably is a function of the shadow mask dot pitch, the "glowing spot" aspect of phosphor, and limitations of display bandwidth in the cable and in the electron guns. Large regions of bright colors really send a lot of light at your eyes. At too low of a refresh rate, this can be very fatiguing. I'd say that gives the edge to light text on dark backgrounds for many purposes, especially coding. Still, dark on light has a special place for me for documents that will mostly be printed. I think I tend to stare intently at screen more when I code than when I read/scan prose, which may explain the difference.
With projectors, I think it depends on the projector and the environment. I've noticed our DLP-based projectors at work are tuned for dark text on a light background. It shows up pretty well and is readable throughout the room. Bring up an xterm with light on dark and it's just a muddled morass. Thus, for these projectors, there really is Only One Way. Also, said projectors seem fairly sensitive to matching their desired refresh rate and resolution if you don't want synchronization noise. (At least in our case, where we're using analog VGA connections 99% of the time when passing the ol' VGA cable around the room to laptops of various ages.)
With an LCD, particularly with a DVI cable, you have neither cable bandwidth nor scanning bandwidth issues to deal with. You also don't have the flicker problems of a CRT. Now the choice of light vs. dark background is much more dependent on personal taste. Here, I cleave to my own bias I stated at the beginning.
In all cases, contrast is king. I use white or bright green on black for my xterms, and prefer black on white for things like documents (such as the many technical PDFs I might download and print). For casual content, such as my home page or blog, I don't mind going light on dark though. Actually, my Intellivision page picked a "bright neons on dark" theme mainly for the retro aspect more than the readability. It's still fairly readable though, IMHO.
--Joe -
Re:NO IT DOES NOT
I used that example because it was a simple example that came easily to mind. Non-engineers can look at it and know immediately that the two are talking about the same thing, but still see that the two approaches to describing the material are completely different. The second law itself isn't too surprising, and the example is familiar, so the likelihood a random person can map the first text to an example is still pretty high. What happens, though, when you get to a topic that is less intuitive?
Most of us have a model for "hot things in a room-temp room cool down" and "cold things in a room-temp room warm up." My coffee cools and my ice cream melts. But what about topics for which we might not have a pre-existing model? I know when I first went into the course, I had just an under-developed notion of what entropy was about from physics class, and no clue what enthalpy was all about, for instance. Heap on there all sorts of other new terminology, and it gets pretty overwhelming. I did learn it, but it took quite some work. Looking back at the text, it doesn't look quite so thick now. But it still wasn't nearly as approachable as it might be. I think the only reason I got a B in that course is that I did have pre-existing models for some things, and that I put a lot of effort into at least somewhat understanding the rest.
In my VLSI class, I ended up sticking around in the class just long enough to learn a few basic concepts—how to decompose a logic function into transistors, how to ratio inverters to drive large loads, and what design rules are all about—and I taught myself the rest. I never bought the textbook, skipped most of the lectures, and pretty much taught myself the rest of what I needed to know. Why? The book was over-priced and about the length of a greeting card. The professor himself couldn't answer questions that weren't in his notes. So I did teach myself. As a result, I had one of the few working projects in the class. That said, I wonder how much more I might've gotten out of the class had it been run a bit more competently?
I won't even touch diff-eq texts. Mine was ok, but I've seen some that had all of 3 words in them and the rest were symbols. My textbook for Prolog was similar. Since I'm not well versed in mathematical symbology, to me it's effectively hieroglyphics.
In the end, I agree with you that a big part of engineering school is learning how to learn. I've told that to countless people, including the aforementioned girlfriend when she was at the peak of questioning her switch from journalism to ME. (She did graduate magna cum laude as an ME.) I use only a fraction of the actual topics I learned in my engineering degree program. But, I also learned what it takes for me to tackle a large, ill defined problem, including organizing my thoughts, researching the relevant fields, and building up a solution. I don't expect to be spoonfed anything, but I do get frustrated at unnecessary road blocks. I ended up with a 3.6 engineering GPA, and I'm pretty certain that wasn't due to grade inflation, judging by the number of folks that dropped out. (~120 students in EE 101, but ~35 at graduation.) It would have been higher if I didn't dick around my first two years.
Another class that I did very well in was my technical writing class. I think this is what informs my rant the most. It's possible to take a complex topic and express it clearly, with minimal forward references, to an audience which is unfamiliar with the topic. It's possible to do this without loss of fidelity. But, it takes considerable time and skill on the part of the presenter. It's also possible to take a simple topic and express it unclearly, making it seem incomprehensible to all but those who take the time to decipher what you've written. When you've got 14 to 17 credit hours of solid engineering curricula, much of this text get
-
Re:"senior voice expert"?
Consult Negativland for implementation details
(And remember, he was the voice of Shaggy in Scooby Doo, too...)
--Joe -
Re:I agree
I was talking to my wife about this just the other day, as she cursed and dismissed another handful of needy dialogs from Windows. Basically, Windows is like a little 3 year old, running up and shoving in your face whatever doodle it just made. "See mommy? A sheep!" "That's very nice dear. Mommy's trying to work." Or, occasionally "Uhoh, I made a poopie." "Oh dear..."
Unfortunately, Linux has started to go in that direction. For instance, on Ubuntu Feisty Fawn, when I run the update manager, all of its pop-ups steal my keyboard focus. WTF? I already told you to do the update—you don't need to pop up and steal my keyboard focus to let me know you've managed to connect to the repository, and again once you've started installing the packages, and yet again when you're complete so I can dismiss you. Just go away and do it, and alert me if something goes wrong. I don't need an "Everything is OK" alarm.
Does Gutsy fix this, or am I going to have to blow the dust off of olvwm and run apt from a cron job?
And before I get pounced on as a troll, I'm referring to my main system. It's only ever run Linux. I've built three systems in this particular case, and all three of them have been Linux and Linux only from the first boot, stretching back about 4 or 5 years for this box. The box before it came with Windows 95 (pre-OSR2), which I dual booted mainly to verify that Intellivision emulator Windows and DOS ports ran correctly. (I dropped the DOS port some time ago.)
--Joe -
Re:5 watts is good, can be better
I *think* this may be the drive.
Flip to page 13 and read along with me:
- Start up: 4.5W
- Idle: 0.65W
- Low Power Active: 1.65W
- Seek: 2.25W
- Read / Write: 2W
- Standby: 0.25W
- Sleep: 0.1W
-
I have another theory entirely.
...except for the minor detail that 65535 is 0xFFFF...
That said, my 32-bit print routine for a 16-bit CPU actually works by printing two 16 bit numbers, with a slight hack to the 16-bit routine to allow it to print numbers in the range 65536 - 99999 for the lower 5 digits. It does this by dividing the 32-bit number by, you guessed it, 100000. It then prints the quotient and the remainder. It has to do some extra legwork, though, to get the leading zeros right across the two words, and I think it's there that the code went south if they're using a technique similar to mine.
I'm guessing what happened here is that there's an off-by-1 error in a comparison somewhere (i.e. ">= 65535" instead of "> 65535"), and the 32-bit quotient/remainder print routine kicks in. Since the number is already smaller than 100000, it probably hits a fall-thru case where the quotient is assumed to be 1, and there's no remainder, hence it printing 100000.
For reference, here's that assembly code I mentioned: prnum32.asm and prnum16.asm
--Joe -
I have another theory entirely.
...except for the minor detail that 65535 is 0xFFFF...
That said, my 32-bit print routine for a 16-bit CPU actually works by printing two 16 bit numbers, with a slight hack to the 16-bit routine to allow it to print numbers in the range 65536 - 99999 for the lower 5 digits. It does this by dividing the 32-bit number by, you guessed it, 100000. It then prints the quotient and the remainder. It has to do some extra legwork, though, to get the leading zeros right across the two words, and I think it's there that the code went south if they're using a technique similar to mine.
I'm guessing what happened here is that there's an off-by-1 error in a comparison somewhere (i.e. ">= 65535" instead of "> 65535"), and the 32-bit quotient/remainder print routine kicks in. Since the number is already smaller than 100000, it probably hits a fall-thru case where the quotient is assumed to be 1, and there's no remainder, hence it printing 100000.
For reference, here's that assembly code I mentioned: prnum32.asm and prnum16.asm
--Joe -
Re:"Full generation behind"?
This is not entirely true. Although I agree overall with what you're saying, core logic transistors scale much worse than cache as the manufacturing process decreases in size.
Fair enough. That said, it's not the transistors so much as it is the wires that don't scale well. I'll warn you: I'm not a physical designer, I'm just an architect. The one and only cookie I directly designed and baked was in 2 micron. That said, I'm aware of the trends.
There could be a couple reasons AMD throws more logic at the problem than RAM:
- At an older technology node, the optimal RAM/logic split may be different.
- Their RAM technology may be more susceptible to defects (e.g. less redundancy).
- They favor shorter latencies over higher overall capacity.
- Related to the previous bullet: They may have higher latency for the same capacity (although their large L1s tend to suggest otherwise).
Indeed, the latency argument is probably the most interesting one. It's seemed to me that the biggest advantage AMD has held over Intel in the previous generation was due to keeping latencies down. The generous L1s, the exclusive cache protocol (where L2 is essentially a ginormous victim buffer and misses allocate directly in L1), and the integrated memory controller are all focused on latency. Lower latencies == more instructions issuing together == more instruction level parallelism. And in branchy code, it means less time branch-to-branch.
Pentium 4 was focused on throughput and bandwidth, and lost on pointer chasing and branching. Huge L2 line sizes, and the high-bandwidth, high-latency RDRAM interface... all that focused on streaming, not on more general workloads. It killed them on the bread and butter generic stuff. Intel finally woke up to that when it shifted over to Pentium M from Pentium 4, and you can see how well they learned by the time you get to Core 2.
Bust out the popcorn, this'll be fun to watch.
--Joe -
Re:Really?
Might I suggest that the engineers may have insisted very thoroughly to others that they were designing for 90 days, but really they were designing for much longer. Might I suggest this essay: Exaggerate with Extreme Prejudice.
--Joe -
Re:Bad programmers need more than 80 columns
I agree for the bulk of code. If you have something tabular with many columns, you can go wider than 80 pretty quick, but not lose comprehension, mainly because each column is much narrower than 80 and that's the unit of importance: column width.
To stay in the 80-column limit for tables requires lots of abbreviations, which works against comprehension. I have some tables I wrote in here and here and here that *just* fit in 80, and really wanted to be wider.
--Joe -
Re:Bad programmers need more than 80 columns
I agree for the bulk of code. If you have something tabular with many columns, you can go wider than 80 pretty quick, but not lose comprehension, mainly because each column is much narrower than 80 and that's the unit of importance: column width.
To stay in the 80-column limit for tables requires lots of abbreviations, which works against comprehension. I have some tables I wrote in here and here and here that *just* fit in 80, and really wanted to be wider.
--Joe -
Re:Bad programmers need more than 80 columns
I agree for the bulk of code. If you have something tabular with many columns, you can go wider than 80 pretty quick, but not lose comprehension, mainly because each column is much narrower than 80 and that's the unit of importance: column width.
To stay in the 80-column limit for tables requires lots of abbreviations, which works against comprehension. I have some tables I wrote in here and here and here that *just* fit in 80, and really wanted to be wider.
--Joe -
Re:I'm a compulsive commenter.
Oh, believe me, on more capable assemblers for larger architectures, I do that sort of thing. I use symbolic names when possible. Here's a dot product kernel more along the lines of what I write when I'm writing for a "big" machine.
For this tiny, ancient machine, the assembler is a hold-over from 16-bit DOS. You could almost call it a toy assembler. There are only 6 general purpose registers, and they're not *quite* general purpose. Shift instructions only work with R0-R3, indirect addressing only works on R1 - R5, with R4 and R5 auto-incrementing. JSR return addresses can only go in R4, R5 or R6. (I don't count R6 as a general purpose register as it is the stack pointer, though most instructions can operate on it.)
My point is, for a tiny machine, it only works against you to name your registers symbolically. Imagine doing this for the 6502, which has one accumulator, A, and two index registers, X and Y. In fact, the register name is built into the opcode.
Oh, and I do use labels. I don't hard-code offsets unless it's called for.
--Joe -
I'm a compulsive commenter.
And it's saved me and others countless time, I'm certain. When it comes to C code I comment similarly to how the article suggests. It's fairly obvious. For example, consider this code. There's some tricky stuff involved in correctly emulating the controller inputs for the Intellivision, and the bulk of the comments revolve around explaining the trickiness.
That said, when I code assembly language, I tend to comment nearly every line. Why? Unlike C code, most assembly statements aren't very descriptive. For instance, "MVI@ R4, R0" means "read whatever R4 points to into R0." Ok, but what might R4 be pointing to? What kind of thing are you reading? What are you trying to accomplish? Imagine if you wrote your C code so that all pointers were named p and q, and all other variables were named i, j, k, a, b, and c. That's what assembly's often like. So, I use short per-line comments (or sometimes per group-of-lines comments) to add that missing information. Here's an example from Space Patrol. (In this particular example I also was counting cycles, due to the performance critical nature of the code. That's an entirely different story.)
All I can say is that comments like these have saved my ass more than once.
--Joe
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}