 Slashdot Mirror
Slashdot Mirror
Domain: w3.org
Stories and comments across the archive that link to w3.org.
Comments · 6,785
-
Re:For those who are too lazy to do some digging..
Thanks muchly for the link. I'm sure they will receive a number of interesting comments.
BTW, can I sue for them assaulting my eyeballs by looking at their gawd awful site/html/etc.?
I think this guy would have a pretty good case to sue them out of oblivion...:-)
http://www.w3.org/People/Berners-Lee/
There oughta be a law...
It's criminal...
Thanks, I'll be here all week... -
Not surprising
If my site had HTML this horrid, I wouldn't want people to look at it either.
-
Invalid HTML
W3C says that the page isn't valid HTML - does that invalidate their claim?
-
Re:Just what I want -
"we need standards before we get browsers, not browsers that generate standards."
No probs, check it out: HTML 4.01 Specification -
H-tagsOne of my GFs clients constantly refers to something called "H-Tags".
A pair of H-tags mark the start and end of each heading element. If your document already has worthwhile text, you should put meaningful section names into properly nested heading elements. This will allow user agents, especially browsers for media types other than screen and robotic user agents operated by search engines, to discover and make use of the structure of your document. See Web Content Accessibility Guidelines: Structural Grouping to learn how to set up your clients the H-tag.
Incidentally, WCAG is probably one of the most effective SEO guides that I've ever read.
-
Re:This guy clearly doesn't know HTML
title is also an attribute and that's probably the sense he meant it in, considering that it was paired with alt.
-
Re:how hard can this be?
It's not all that hard, but you do cut out a lot of functionality if you follow the guidelines (e.g. no asynchronous javascript calls returning data).
-
Fourteenth AmendmentIsn't it written into the constitution that its illegal to discriminate? Whose Constitution? In the United States, the Fourteenth Amendment prohibits states from "deny[ing] to any person within its jurisdiction the equal protection of the laws." But what is "protection" and what is a handout? And can states delegate this requirement for "protection" to businesses within their borders? The wording of the Constitution leaves this up to the sociopolitical climate. What elements enable disabled users to make better use of a site and what create barriers to use? Here are a few I can think of; see WCAG for details:
- Use of structural markup (h1, h2, h3, h4, strong, em) instead of presentational markup (font, some uses of table) helps. Structural markup lets you specify different CSS for different kinds of media, such as screen, print, TV, and handheld computers, and if your organization is large enough to have the money to cater specifically to blind people, you can have someone make CSS for speech.
- Make sure that your site can still be navigated (even if it doesn't look the way the branding people want) if none of the data referenced by img or object elements actually loads. And make sure that the replacement text for an img or object element is kept up to date.
- Strictly, the preceding point means sites done in SWF need a parallel site done in HTML. (I can't afford retail Adobe Flash software at the moment to verify how well Flash accessibility works.)
- Make sure that your CSS has enough luma contrast between text and backgrounds and that any background image is paired with a comparable solid background color.
- Test increasing the font size in Firefox and IE, and make sure that the layout doesn't break and that the font size actually changes. (You should test in Opera too, but I mention Fx and IE because Opera's zoom is an entirely different process.)
-
Re:stupid & frivolious
whos next? are they going to sue automobile manufacturers because they dont make automobiles with accessibility for blind drivers?
There is no magic wand to make a blind person capable of safely driving a car. There are a number of fairly resonable guidelines that give disabled persons with assistive technologies a fighting chance of using your website. Better still, many of these guidelines are firmly in the "what's not to like?" category for non-disabled users - e.g. not abusing Flash, allowing end-users to adjust the window and font size, using standards-complient HTML... These have been around for years - any half-competent web designer should be aware of them and (as with any good rules) at least think before breaking them.
Now, whether these should be mandated by government is a bit more tricky - but since some firms seem quite happy to piss off even the able-bodied majority with annoying site designs, expecting them to voluntarily cater for minorities seems a bit optimistic.
The main problem is when technically ignorant bureaucrats (esp. govenment clients) "gold plate" the guidelines and treat them as black & white rules that must all be blindly (er...) obeyed (e.g. no Flash ever even when there is a good case for an inteactive applet or a failure to recognise that CSS is only marginally fit for purpose).
The other problem is that any well intentioned law will be perverted as long as it offers fallible Human Beings and their lawyers the possibility of windfall payouts.
-
Errata for sample chapter: gzip vs. deflate
I started reading the first chapter and I was surprised when I read the following paragraph:
Gzip is currently the most popular and effective compression method. It is a free for- mat (i.e., unencumbered by patents or other restrictions) developed by the GNU project and standardized by RFC 1952. The only other compression format you're likely to see is deflate, but it's slightly less effective and much less popular. In fact, I have seen only one site that uses deflate: msn.com. Browsers that support deflate also support gzip, but several browsers that support gzip do not support deflate, so gzip is the preferred method of compression.
Unfortunately, it looks like the author does not know what he is talking about, since gzip is based on the deflate algorithm. It is likely that the author did not even look at RFC 1952 because this is stated clearly in the abstract:
This specification defines a lossless compressed data format that is
compatible with the widely used GZIP utility. The format includes a
cyclic redundancy check value for detecting data corruption. The
format presently uses the DEFLATE method of compression but can be
easily extended to use other compression methods. The format can be
implemented readily in a manner not covered by patents.If you look at the HTTP/1.1 definition, you will see that section 3.5 specifies the meanings of the compression types "gzip" and "deflate":
- gzip An encoding format produced by the file compression program "gzip" (GNU zip) as described in RFC 1952.
- deflate The "zlib" format defined in RFC 1950 in combination with the "deflate" compression mechanism described in RFC 1951.
In fact, it is unfortunate that the HTTP/1.1 RFC used the name "deflate" for this content coding, because it would have been more appropriate to name it "zlib". And both "gzip" and "zlib" are based on the deflate algorithm, as you can easily see if you take a quick look at RFC 1952 (gzip) and RFC 1950 (zlib). Both of them have a flag CM for the compression method, and the only one that is defined is CM=8 for the deflate method (RFC 1951). So the HTTP/1.1 RFC is a bit confusing, but a quick look at the corresponding RFCs for gzip and zlib can clear up that confusion easily.
The difference between gzip and zlib (deflate) are minimal. The gzip file header can be a few bytes longer because it includes the file modification time, optional extra fields, the original file name and a file comment. Note that none of these fields are useful for HTTP transfers, because the same information is already included in the HTTP headers (except for the optional comment, which is ignored anyway).
So the statement in the sample chapter saying that deflate (zlib) "is slightly less effective" than gzip is just wrong. It is actually the opposite: the zlib header would be a few bytes shorter than the gzip header. No, the main difference between both formats is that gzip (the format) is more popular because gzip (the program) is popular. And you can easily use the gzip program to pre-compress the static contents on your server so that it does not have to do it on-the-fly all the time. It would be much better if the author would re-write that paragraph and not make it sound like the formats are significantly different when they are based on the same algorithm. Also, the reference to the effectiveness of one or the other is misleading.
-
Re:Head of site performance at Yahoo, huh?
-
Head of site performance at Yahoo, huh?
-
Head of site performance at Yahoo, huh?
-
Microformats that gracefully degradeIn my opinion, <i> should never be used, as it is a formating tag and adds no meaning to the document.
Without attributes, you'd be right. But I can see one use of presentational elements, in a document that uses a microformat within HTML or otherwise uses features of HTML and CSS that not all user agents support. You might want a particular kind of inline element to gracefully degrade to italics in the legacy visual user agents used by a sizable population. For example, <i lang="x-tokipona">nimi mute</i> would mark the words nimi mute as being in toki pona (semantically) and in italics that signify a foreign language (presentationally). Though the same effect could be achieved with a span element and CSS attribute selectors, the still-widely-deployed Internet Explorer 6 doesn't recognize CSS attribute selectors at all, and IE7 still doesn't apply multiple attribute selectors. We are still in the Transition.
But will it blend? And how did we get from Blender to this?
-
"Standards"
ODF has already been accepted as an ISO standard, and is already supported by all of the following groups:
http://www.odfalliance.org/members.php#viewall
Fascinating how a group all about "standards" can't put together a standards-compliant Web page:
http://validator.w3.org/check?uri=http://www.odfalliance.org/members.php
Failed validation, 815 Errors (150kB page)
gewg_ -
W3C Security FAQ disagrees
Lincoln Stein, the author of CGI.pm and GD.pm and a few books, and the co-author of the WWW Security FAQs, wrote a tool called sbox that is used for securely running untrusted CGI scripts. And sbox does use the chroot() system call (in addition to other security measures) to confine the process to the CGI script owner's home directory.
Also, from the aforementioned FAQ: "You can't make your server completely safe, but you can increase its security significantly in a Unix environment by running it in a chroot environment."
So, the words, "chroot is not and never has been a security tool" are simply wrong. Unless you are willing to argue that Lincoln Stein belongs to "incompetent people implementing security solutions" and that W3C publishes bullshit on their web site.
-
W3C Security FAQ disagrees
Lincoln Stein, the author of CGI.pm and GD.pm and a few books, and the co-author of the WWW Security FAQs, wrote a tool called sbox that is used for securely running untrusted CGI scripts. And sbox does use the chroot() system call (in addition to other security measures) to confine the process to the CGI script owner's home directory.
Also, from the aforementioned FAQ: "You can't make your server completely safe, but you can increase its security significantly in a Unix environment by running it in a chroot environment."
So, the words, "chroot is not and never has been a security tool" are simply wrong. Unless you are willing to argue that Lincoln Stein belongs to "incompetent people implementing security solutions" and that W3C publishes bullshit on their web site.
-
Re:User-Agent not reliable anyway
It is part of the guidelines/agreement for
http://mtld.mobi/domain/policies/compliance
http://www.w3.org/TR/mobile-bp/
http://ready.mobi/results.jsp?uri=http%3A%2F%2Fsmlpx.mobi&locale=en_EN
I don't know if the boot has been put in yet for non-compliance, but I hope it is.
The best practices guide referenced specifies page weight, default media types, etc.
Rgds
Damon -
Re:Not having to download the entire HTML
The solution would be the Accept header. Just add a parameter like a media type. Of course clients and servers need to understand such a parameter, but it wouldn't be hard to add.
-
Re:Supporting materialsThe SOAP/XML specifications in the WS-* family of specs use something people often call "pseudo-schema". Look at WS-Eventing for example. Section 2.1 describes this notational convention. And here is an example of how it is used to describe the "subscribe" SOAP message defined by the spec (section 3.1):
<s:Envelope
<s:Header
<wsa:Action>
http://schemas.xmlsoap.org/ws/2004/08/eventing/Subscribe
</wsa:Action>
</s:Header>
<s:Body
<wse:Subscribe
<wse:EndTo>endpoint-reference</wse:EndTo> ?
<wse:Delivery Mode="xs:anyURI"? >xs:any</wse:Delivery>
<wse:Expires>[xs:dateTime | xs:duration]</wse:Expires> ?
<wse:Filter Dialect="xs:anyURI"? > xs:any </wse:Filter> ?
</wse:Subscribe>
</s:Body>
</s:Envelope>
And then it uses an XPath-like syntax to point elements and attributes out and describe them, as in:
If a SOAP Action URI is used in the binding for SOAP, the value indicated herein MUST be used for that URI.
It's a very readable way to document and even people who normally only read examples have no problem parsing this. Smart developers on the receiving side code to this and don't bother with the XSD. People who are slaved to their XSD to Java tools have to use the XSD and end up in a world of pain. -
That's only true because...
That's only true because the W3C and the browser people aren't interested in helping make things more secure.
I've been proposing the following for _years_:
http://www.google.com/search?num=100&hl=en&safe=off&q=%22Tag+to+disable+unwanted+features%22
http://lists.w3.org/Archives/Public/www-html/2002May/0021.html
http://www.mail-archive.com/mozilla-security@mozilla.org/msg01448.html
http://lists.w3.org/Archives/Public/www-html/2007Aug/0008.html
It will help. But I'm no longer going to bother explaining in detail how anymore (read the links if you're interested). Since:
0) I already tried many times
1) Nobody who can do anything about it really cares or is listening
2) On the bright side, it means more money in the IT security business. $$$
I'm just saying a) yes, something can actually be done to make things better. And it isn't just Google's fault or a Mozilla or IE problem, and b) "I told you so"
People who say we only need good server side filtering are stupid and/or ignorant. In the real world the web browsers don't parse everything the same way. So how is your server side filtering going to cover all the cases? The attacker just needs one exploitable "discrepancy" and they're in.
Of course my proposal won't fix everything, but just because brakes don't prevent all car crashes doesn't mean we don't need brakes and we should just tell drivers to drive better and avoid crashes (or just raise "security exceptions" if stuff happens -
That's only true because...
That's only true because the W3C and the browser people aren't interested in helping make things more secure.
I've been proposing the following for _years_:
http://www.google.com/search?num=100&hl=en&safe=off&q=%22Tag+to+disable+unwanted+features%22
http://lists.w3.org/Archives/Public/www-html/2002May/0021.html
http://www.mail-archive.com/mozilla-security@mozilla.org/msg01448.html
http://lists.w3.org/Archives/Public/www-html/2007Aug/0008.html
It will help. But I'm no longer going to bother explaining in detail how anymore (read the links if you're interested). Since:
0) I already tried many times
1) Nobody who can do anything about it really cares or is listening
2) On the bright side, it means more money in the IT security business. $$$
I'm just saying a) yes, something can actually be done to make things better. And it isn't just Google's fault or a Mozilla or IE problem, and b) "I told you so"
People who say we only need good server side filtering are stupid and/or ignorant. In the real world the web browsers don't parse everything the same way. So how is your server side filtering going to cover all the cases? The attacker just needs one exploitable "discrepancy" and they're in.
Of course my proposal won't fix everything, but just because brakes don't prevent all car crashes doesn't mean we don't need brakes and we should just tell drivers to drive better and avoid crashes (or just raise "security exceptions" if stuff happens -
Re:(I'm the author of the article) - Please read:
I presume that they are serving XHTML as text/html to Internet Explorer since application/xhtml+xml does not work correctly in it. Your recommendations seem reasonable otherwise unless there is something that forces them to use XHTML 1.1 rather than XHTML 1.0. I should note that according to http://www.w3.org/TR/xhtml-media-types/#summary, serving XHTML 1.1 as text/html is a "SHOULD NOT" rather than a "MUST NOT", so they can continue to serve the document as text/html without breaking standards outright.
-
Re:Plays well with others
http://validator.w3.org/check?uri=http%3A%2F%2Fblogs.msdn.com%2Fbrian_jones%2Farchive%2F2007%2F01%2F25%2Foffice-xml-formats-1998-2006.aspx&charset=(detect+automatically)&doctype=Inline&group=0
Result: Failed validation, 132 Errors . That is how much they care about standards.
That is a "Blog", text/graphics only, coming from Microsoft they don't have to put ads all over the place.
That really shows MS attitude. -
Re:More than one side to this one...
Technologies like Flash and AJAX and all the other technologies surrounding and supporting them can add a great deal of value to a website, but only if done correctly.
I agree - and the most important part of doing it correctly is Ensure that pages are accessible even when newer technologies are not supported or are turned off .
Like JavaScript. You might excuse something as complex as Google Maps for requiring javascript: instead they made the effort and it works without it. So how can sites like Monster.com need JavaScript to submit a simple form? Without even a nice warning message in noscript tags?
AJAX and Flash done right can add extra features and improve the site - Ask.com has done a lot of that. But it's the fact that it still works without the latest and greatest technologies which ensures that everyone - including those 1 in 20 people without JavaScript - can enjoy the site. -
Re:Nutcases
Uhhh...
http://www.w3.org/People/Berners-Lee/
"In 1989 he invented the World Wide Web, an internet-based hypermedia initiative for global information sharing while at CERN, the European Particle Physics Laboratory."
and BTW, the Chinese invented rockets and the Germans perfected them. I can't seem to find a definitive link for who invented computers but I think some British guy named Babbage may have had something to do with it... -
Re:iframes...
Would it then require some hack to make sure that the inline style doesn't override any stylesheets you've created?
No, not a hack, just good use of the cascading order.The iframe used on bankofindia.com had "style='visibility:hidden;'".
I'd rather eliminate it with display: none!important;, although getting rid of it entirely with a filtering proxy is much more secure.Unless I'm mistaken, even if you had custom stylesheets applied to every page you visit the inline CSS would still rule... right?
That's right--unless you use !important rules which (applied in a user style sheet) always take precedence. -
Re:iframes...
Would it then require some hack to make sure that the inline style doesn't override any stylesheets you've created?
No, not a hack, just good use of the cascading order.The iframe used on bankofindia.com had "style='visibility:hidden;'".
I'd rather eliminate it with display: none!important;, although getting rid of it entirely with a filtering proxy is much more secure.Unless I'm mistaken, even if you had custom stylesheets applied to every page you visit the inline CSS would still rule... right?
That's right--unless you use !important rules which (applied in a user style sheet) always take precedence. -
Re:Please educate & inform me...
A question for you: What is it about OS X that makes it good for audio/video/graphic work? That's your assertion, so I assume you have at least of some reason to believe it.
If you're confused as to why some choose OS X then I would suggest doing some research into the features that made NEXTSTEP a compelling Unix Desktop and workstation in the 90s. For instance:
- Why Tim Berners-Lee chose NEXTSTEP as the platform on which to develop the world's first Web Browser and Web Server.
- Why id Software chose NEXTSTEP to develop their landmark Doom and Quake games for the PC.
- What's compelling about NEXTSTEP/Cocoa APIs, Interface Builder, and what influence did Objective-C have on Java?
- Why were Linux users so enthusiastic about NEXTSTEP-derived window managers, such as WindowMaker and AfterStep? What lead to the development of GNUStep?
That's NEXTSTEP.
Now, say you chose NEXTSTEP as the basis for your perfect operating system and desktop environment. You get to keep all of the good design decisions, throw away or refactor all of the bad design decisions, and do it without any backward compatibility restrictions. What you end up with is OS X.
But why an Apple laptop? Here's why: I can open up a bunch of SSH and X11 sessions to a remote server over wi-fi, close the lid and throw it in my back-pack, go eat lunch, come back and open the lid, and all of my remote X11 apps and sessions are still alive. OS X just works damn well on Apple's laptop hardware.
-
Re:MehEven if you don't agree with software patents in principle, patents that introduce a new technology tend to expire before the technology matures enough to become profitable.
BS. While that might make since in the physical world, it's completely inappropriate for software. For example, Tim Berners-Lee published a working description of the Web in March 1989. From my (admittedly amateur) interpretation of patent law, had he patented the concept on the same date he published that proposal, we'd still have two years to wait before it was possible to write an unencumbered web browser.
In what way could that be rationally justified? Although he made a leap to tie the pre-existing pieces together, how why would he deserve a 20 year monopoly on it? And since patents were meant for the betterment of society, how would you and I have benefitted from not having the web for the last 18 years (reasonably assuming that a proprietary version wouldn't have caught on long-term)? Other than not being able to waste time reading Slashdot at work, that is.
-
next-previous Site Navigation still in SeaMonkey
Something I do miss are the "next-previous" functions of the NeXT browser. Current browsers only permit you to follow a link and then to run back and forth over the path you took ("back" and "forward"). The NeXT browser had the additional function of following the next link of the previous page ("next"). That allowed me to make a page which was a list of pages to be looked at and then to walk that "path" with a click per page.
I think he's talking about <link rel="next/previous/contents"> in the head.
SeaMonkey has View > Show/Hide > Site Navigation Bar that shows buttons in the navigation for this. It's not in Firefox, though there's a Site navigation extension.
-
Re:They should buy this
Not only does your website look broken in Firefox, it really is broken. Way to make a good first impression.
-
Re:Web 2.0 developers have betrayed us all
> AJAX is only useful because people are trying to use HTTP and HTML in ways that HTTP and HTML weren't meant to be used.
Using non idempotent GET / HEAD methods is poor programming but the purpose of HTTP is to share data using these methods http://www.w3.org/Protocols/rfc2616/rfc2616-sec9.h tml
HTTPXmlRequests should use those methods as described. It's not the fault of the technology,
HTML/CSS is a display technology, I'm not sure how using it to display things is abuse of its intent.
These flaws don't need XmlHttprequest, is also likely to be a vector -
MySQL's source is as open as before
To all Slashdotters,
Your comments are appreciated and we take your input seriously. Just to make sure that all facts are correct: we have not closed the source. MySQL continues to be GPL as before.
We have only made a change in relation to binaries. Community binaries are available as before, MySQL Enterprise binaries are provided to our customers. We are highly grateful both for those who count themselves as users and those who count themselves as customers. And the binaries are produced from GPL source code so of course you are all in your full rights to modify, compile, redistribute etc. as before.
The rapid innovation rate in and around MySQL is very much a reasult of the product being licensed under the GPL. Look for instance at MySQL Cluster and MySQL Proxy which are innovations from us, or at the SPASQL modification made by Eric Prud'hommeaux: http://www.w3.org/2005/05/22-SPARQL-MySQL/XTech
I look forward to more of your comments and suggestions.
Marten Mickos, CEO, MySQL AB -
Re:what happened to xhtml?
> XHTML2 would handle errors the way XML parsers are supposed to:
> by shutting down and throwing up an "Non-conforming document" error.
At least it would do this for documents that declared themselves to be XHTML 2. The problem with HTML 5 is it requires no unique document declaration (simply ) and this spec and DOM are meant to apply to any web document ever made, or that ever will be made.
If all the browsers implement HTML5 rules as it appears they will be, we'll be stuck with these rules for a long time. The emphasis on backwards compatibility keeps us from changing anything that ever was, no matter how screwy it is.
Unless they change their minds, break their own rules and redefine tags like they have done with the tag. Then whatever the future brings will change the meaning of your old code. There is no way to say "this is HTML4 and this other document is HTML5". You think you'd like to use a doctype for this, but the working group has decided that they are useless. http://www.w3.org/html/wg/html5/#the-doctype. -
Re:Excellent!
-- XHTML is allowed under the HTML 5 spec, which they call XHTML 5 --
Is this some kind of SGML lobby ploy to induce confusion between HTML and future versions of the actual XHTML standard?
-
Re:Announcing
No support for markup of mathematics in HTML? So what's this then http://www.w3.org/Math/? It even works in Mozilla http://www.mozilla.org/projects/mathml/.
-
Re:Excellent!
a certain browser vendor that has 90% of the market is notably absent from this venture.
That's not really true, since Microsoft is present in the HTML WG which is now working on HTML 5, and Chris Wilson is a co-chair of the group. They have been extremely quiet in the group so far, though.
-
Re:So do tags ever deprecate?
There are plenty of deprecated tags in HTML4 for instance.
People keep using them because W3C never bothers to explain what they were deprecated by
This is not true. The HTML 4.01 specification includes numerous explanations of what should be used instead of deprecated element types and attributes. I quote from the specification:
However, since style sheets offer more powerful presentation mechanisms, the World Wide Web Consortium will eventually phase out many of HTML's presentation elements and attributes. Throughout the specification elements and attributes at risk are marked as "deprecated". They are accompanied by examples of how to achieve the same effects with other elements or style sheets.
This specification includes examples that illustrate how to avoid using deprecated elements. In most cases these depend on user agent support for style sheets. In general, authors should use style sheets to achieve stylistic and formatting effects rather than HTML presentational attributes.
For example, in the part of the specification that describes font styles, examples are given to show you how to style text with CSS instead. If you haven't seen the explanations, then you just aren't looking.
-
Re:Excellent!
The whole point of a semantic tag is that it is machine parsable. A script that is interpreting the page will know what parts of the page is the article, which parts are the navigation, which parts are the advertisements, and so on.
But you don't need new tags for that. You could just come up with a standardized list of attributes for common uses. XHTML2 uses a new attribute, "role", to accomplish this, for example. So the standard defined a list of common ROLEs (like, say, "role=navigation" or "role=advertisement"), you could have, say:
<div role="advertisement">Buy Crelm Toothpaste!</div>
... and get the same effect as an ADVERTISEMENT tag, and at the same time make it easier to extend the list of defined elements in the future (since you could just extend the list of ROLEs, and not have to re-do the whole spec).
The HTML WG is considering a similar mechanism, only using the CLASS attribute instead of ROLE. Personally I think that's a bad idea, since CLASS carries style information, not semantic information, and there's probably already a ton of documents out there using, say,
<div class="navigation">
... and their owners are gonna be really surprised when browsers suddenly start parsing those classes in new and unexpected ways.
-
ummm .... MENU is not a new tag ...
"I welcome new tags like datagrid and menu"
The MENU tag has been part of the spec since the earlest html drafts.
Several tags are being "repurposed" or "overloaded". MENU is one of them. Read the discussion in TFA on the DIALOG tag for how definition lists are being re-worked.
-
Re:what happened to xhtml?
Yes. Kind of.
There are currently to Working Groups in the W3C working on markup -- the XHTML working group, and the HTML working group. These are separate entities with separate memberships and separate processes.
XHTML was originally intended to be the successor to HTML. But a couple of things that happened after XHTML1 "shipped" caused that to be re-evaluated:
- The whole point of XHTML was that moving to XML syntax would open up new possibilities for user-agents: not just browsers (whose lives would be simplified by not having to deal with "tag soup" anymore"), but applications that would take advantage of already knowing XML to do cool stuff with the web. Only that never really happened; and because Microsoft wasn't on board, browser vendors still had to parse the "tag soup" anyway.
- The XHTML Working Group went off the deep end and announced that XHTML2 would handle errors the way XML parsers are supposed to: by shutting down and throwing up an "Non-conforming document" error. Needless to say, this is not how the Web works today, and it threw a scare into millions of Web publishers who incorporate third-party content that they have no control over (like, say, ads) in their sites. They also proposed major changes to the syntax of XHTML2 versus XHTML1 to clean it up and make it more logical; which sounds great until you realize that now you have to teach those millions of web publishers a whole new syntax or their sites break.
When it became clear that continuing down the XHTML path promised tons of heartburn for publishers and user-agent developers without much reward in return, people started thinking that maybe rebooting the HTML specification process wouldn't be such a bad thing. The W3C picked up the WHATWG's independent "HTML5" spec as a starting point, and that's where we are today: XHTML is for people who are comfortable with radical changes between versions of the spec and Draconian error processing; HTML is for people who want backwards compatibility and less strict parsing.
-
Re:what happened to xhtml?
Yes. Kind of.
There are currently to Working Groups in the W3C working on markup -- the XHTML working group, and the HTML working group. These are separate entities with separate memberships and separate processes.
XHTML was originally intended to be the successor to HTML. But a couple of things that happened after XHTML1 "shipped" caused that to be re-evaluated:
- The whole point of XHTML was that moving to XML syntax would open up new possibilities for user-agents: not just browsers (whose lives would be simplified by not having to deal with "tag soup" anymore"), but applications that would take advantage of already knowing XML to do cool stuff with the web. Only that never really happened; and because Microsoft wasn't on board, browser vendors still had to parse the "tag soup" anyway.
- The XHTML Working Group went off the deep end and announced that XHTML2 would handle errors the way XML parsers are supposed to: by shutting down and throwing up an "Non-conforming document" error. Needless to say, this is not how the Web works today, and it threw a scare into millions of Web publishers who incorporate third-party content that they have no control over (like, say, ads) in their sites. They also proposed major changes to the syntax of XHTML2 versus XHTML1 to clean it up and make it more logical; which sounds great until you realize that now you have to teach those millions of web publishers a whole new syntax or their sites break.
When it became clear that continuing down the XHTML path promised tons of heartburn for publishers and user-agent developers without much reward in return, people started thinking that maybe rebooting the HTML specification process wouldn't be such a bad thing. The W3C picked up the WHATWG's independent "HTML5" spec as a starting point, and that's where we are today: XHTML is for people who are comfortable with radical changes between versions of the spec and Draconian error processing; HTML is for people who want backwards compatibility and less strict parsing.
-
Re:XHTML/HTML divergence
HTML5 is being developed hand-in-hand with XHTML5, which is merely the XML serialization of HTML5. Don't worry. You don't have to give up <br
That being said, I do believe that CSS still has fundamental problems that not even CSS3 seems to be solving, such as taking into consideration the growing use of HTML as an application framework rather than a document framework. The most notable issue of this would be the inability to center an object vertically in a viewport without Javascript to determine its size, which is a klutzy hack at best. The float: and clear: primitives, as you mention, are also comparatively weak (since you can't just float an element, have text flow around it, AND position it vertically), though CSS3 is introducing a Multi-column layout module. There are other issues too, but I can't pull them off the top of my head at this time.
-
Re:Huh?
Cascading Style Sheet docs recommend specifying multiple fonts for exactly this reason, suggesting that you use one of the generic font family names last as a fallback (serif, sans-serif, cursive, fantasy, or monospace).
-
Blind Costs. GNU/Linux UI Last Longer.
It's amazing how people can be so blind to the TCO of Windoze:
There are a lot of extra costs and little have to do with Linux but selling a product in an area where there is little demmand.
Now you understand the man's frustration with Vista. Really. Every few years M$ changes their UI without substantial changes to anything else. Vista is the most radical change since 3.1 to 95, yet people like you just take that cost for granted.
With GNU/Linux, on the other hand, you have a choice of UIs and they remain the same over decades. Have you ever seen the first web browser, made in 1990? Compare that interface to Window Maker or AfterStep, which have been stable for almost as long and is still available to those who want it. Those are only the beginning of your choices and they all work well together.
-
Re:Ziff Davis is teh suxx
Not talking any intarweb 2.0 here Homer... I'm talking about the internet standards.
http://w3.org/ -
In Soviet .....
In Soviet CSS...
Colour is spelled "color".
And I bet Sir Tim doesn't give a FF....
(heh heh! I finally got to use Soviet and CSS together!)
-
Re:First web browser
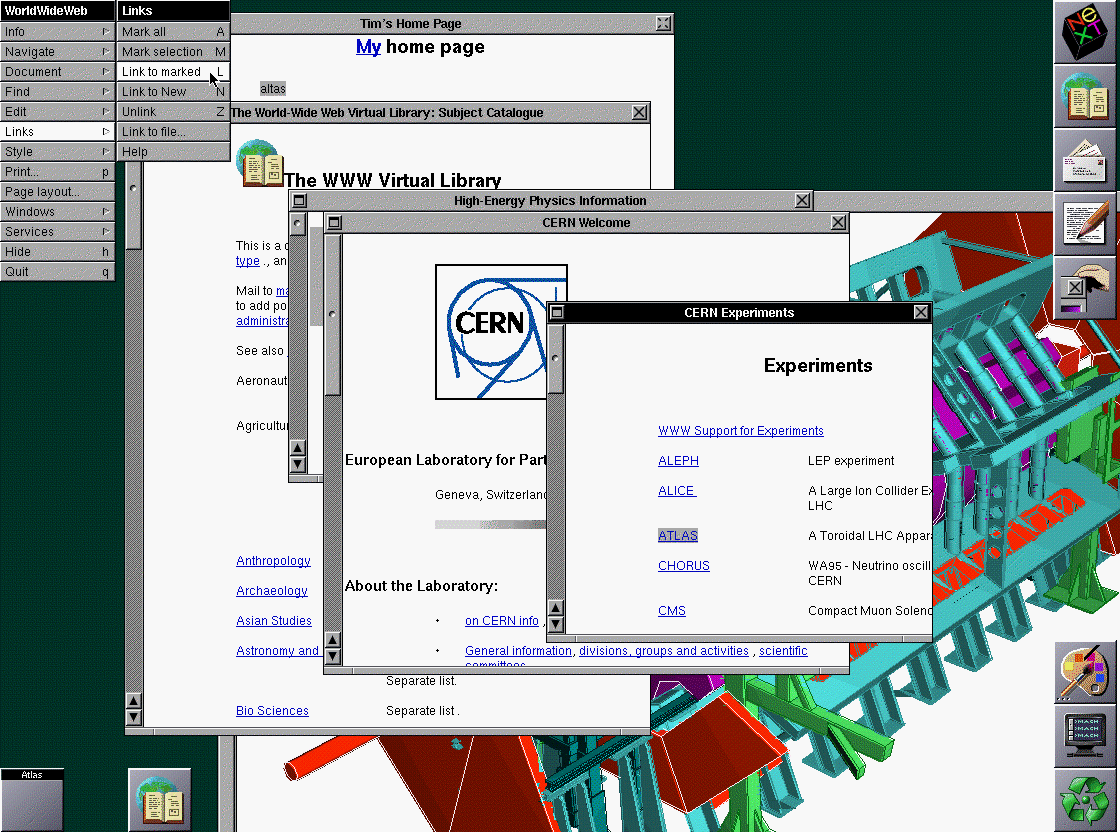
The very first web browser (called WorldWideWeb) was developed on a NeXT by Tim Berners-Lee.
-
Re:The u tag?not all HTML is intended to be read by ignorant users. But don't rely on this too much, as not only do a lot of people in a lot of markets lack experience with the web, but also some people have congenital or acquired cognitive disabilities. Excluding such people unnecessarily could cause problems with accessibility guidelines if your application is required by law or contract to be accessible.
{kind=link}