 Slashdot Mirror
Slashdot Mirror
Domain: w3.org
Stories and comments across the archive that link to w3.org.
Comments · 6,785
-
Re:Why history will remember Andreesen, not Clark
Everyone stands on the shoulders of other giants. Let's give Marc and Eric some credit;
You're right. But I disagree when you write that Berners-Lee's browser had "no GUI controls beyond a scroll bar"... In fact it was not only a GUI browser but even a GUI html editor, and the page you're commenting on explains how to make a link using the NeXT menus on the left. Or see this page:"WorldWideWeb was a graphical point-and-click browser with mode-free editing and link creation. It used style sheets, and multiple fonts, sizes, and justification styles. It would download and display linked images, diagrams, sounds animations and movies from anything in the large NeXTStep standard repertoire."
He continues with a link to the original source code, BTW. I wonder if anyone has been able to compile this lately. Could it be patched to run on GNUstep (or even Mac OS X -- compare this)? Now that'd be fun. -
Re:Why history will remember Andreesen, not Clark
his browser (which he did not invent, but merely polished the creation of Tim Berners-Lee) (...)
Out of curiosity, were you around on the Internet in 1993-1994? Marc was the lead developer who came up with this incredibly addictive toy (...) It was really the first piece of software that blended three elements: hypertext information retrieval, GUI ease-of-use, and layering that on the worldwide Internet infrastructure (...) Don't underestimate that GUI component, which was Marc's main contribution (...)
You may have been around, but I guess you weren't using Berners-Lee's original, graphical browser.
-
Re:Doesn't this sound realistic?
since the first graphical browser wasn't released until late 1993
Actually, the first web browser was written in 1990. It only ran on NeXT, however. And yes, it was graphical too.
For a great first-hand account of the history of the World Wide Web, read Weaving the Web by Tim Berners-Lee (the inventor of the Web, and the first web browser). -
Re:Doesn't this sound realistic?
since the first graphical browser wasn't released until late 1993
Actually, the first web browser was written in 1990. It only ran on NeXT, however. And yes, it was graphical too.
For a great first-hand account of the history of the World Wide Web, read Weaving the Web by Tim Berners-Lee (the inventor of the Web, and the first web browser). -
Re:OPEN Patents!
I have been thinking of a similar idea. What would be the potential for taking an HP like approach to Free patents. HP claims patents on some W3C technologies, and requires reciprocal royalty free licenses from all implementers, as mentioned in section 3.4 of the W3C Patent Policy. To what extent could this be used in a similar manner to what Ralph Levian is doing to break the back of software patents altogether?
In particular, I'm thinking of object oriented patterns, which are the building blocks of an enormous portion of modern software. A well documented pattern contains much of the same information as a patent application - motivation, solution, variations, etc. Suppose, for example, a patent on the facade pattern. Require reciprocal RF licenses on any software patent used in conjunction with an implementation of facade. A few dozen powerful patterns could affect an enormous portion of patent encumbered software. -
Re:Micropayments
Micropayments have seemed like such a good idea for so long, why hasn't it happened yet?
...maybe because we need a good way to make people pay without filling creditcard forms all the time. P3P doesn't really seem like the way to go. We need micropayments to be neat and easy, otherwise people won't bother. Filling out a credatcard form today is way too complicated. If I could do that just one time and trust my software to keep it secret and keep it safe, then I would be willing to use micropayments.
-
Re:Why?
"You can't imagine how amusing it is to see you use both terms without a trace of sarcasm." Oh! You are absolutely right. Gosh was I being SUCH a silly ass !!! I should be lashed for being the mongoloid that I am! I should've known how efective posting messages on a site is at conveying sarcasm...It has absolutely nothing to do with the subtlties of inflection or tone of voice or facial expression or clever use of html.
-
IDE?
IDE disks? IDE disks? What the bloody hell are IDE disks?
When I were a lad, we 'ad to use 8 inch floppies.
8 inch floppies? You were lucky.
Cut to the Four Yorkshiremen sketch. Is there anyone else here who remembers Phoenix? -
Re:The Web is DeadMicrosoft wants to replace the World Wide Web (Tim Berners-Lee's WWW) with it's own network running under
- Death of the Browser? (on Microsoft's site) and
- The Return of Client/Server -- or, at Least, Rich Clients
But first go see how Debate foams over SOAP 1.2 in the W3C working groups for XML, SOAP and Web Services.
It seems that Roy Fielding, one of the key architects of HTTP and a member of the W3C TAG (Technical Architecture Group), which essentially defines the principles of Web architecture inside the W3C, pointed out that the SOAP specification broke universally-accepted WWW protocols and would be unlikely to succeed. At the same time Fielding and others have pointed out that Web Services can easily be implemented today including all desired security and authentication by using current WWW protocols and by judicious use of what he calls a REST Architecture, a subset of the current WWW architecture.
Microsoft's plan is unlikely to work: the members of the involved working groups have realized that failure of SOAP to be consistent with WWW will doom it to failure because of the additional complexity and lack of scalability that would entail.
See also- Paul Prescod's Home Page and especially the section "HTTP and REST" wherein he elucidates the subtleties of REST and how SOAP breaks the WWW. Prescod is one of the most vociferous and well-written supporters of the REST architectural style in the W3C working groups.
- A REST Tutorial for Roger Costello's brief but excellent introduction to Roy Fielding's REST and why it will be the basis for any viable Web Services architecture.
- Visit the REST Wiki to relax in an oasis of ideas that explains how Web Services can be implemented today in a manner
- not as complex as the proprietary vendors and current and pending specifications of SOAP appear to require,
- using the technology and tools you already know.
- not as complex as the proprietary vendors and current and pending specifications of SOAP appear to require,
Finally, dive into the waters of the oasis and wash the SOAP off of your soul. Now pure of heart, make a pilgrimage to Tim Berners-Lee's Design Issues for the World Wide Web where you can
- re-examine the issues of the WWW,
- renew your commitment to doing things "the right way",
- revive your passion for excellence and
- remind yourself that indeed, sometimes "less is more."
- Death of the Browser? (on Microsoft's site) and
-
Image description language...Pan seems like M$'s latest attempt to again catch up to the Open Source community. For way cool graphics that you can animate, script against, port to any platform and easily manipulate in your code try SVG (scaleable vector graphics) It is also supported by adobe. This is an xml based standard that is easy to use, easy to manipulate, and offers the best of flash plus named vector graphics.
For more information see W3C's SVG web site
for useage of SVG see: The Apache batik project
There is also an excelent O'Reilly book by J. David Eisenberg
If you truly want to be on the cutting edge of graphics then you should look into SVG.
Sgis
"Truth is a personal pronoun." (john 14:4)
-
Re:Text comparison.
Hey, it worked in Moz. How was I supposed to know?
Do what every self-respecting web designer does and validate the HTML on pages you generate. Then your pages will have a much greater chance of working correctly in every browser. -
Re:I am not impressed
You missed a line:
while I agree that there are too many cases of webpage developers stressing design over content, there are other cases where the design augments the content
thanks for the link:
Tables should not be used purely as a means to layout document content as this may present problems when rendering to non-visual media
In addition, 70% of my NS users are on 4.x or below, which poorly handles CSS. IMHO, the Web is not for presenting data in the most textish format possible (though Nielsen won't agree with me ^_^), but to get a message to the users, all users, and not lose details because of variations in the browser. -
Re:I am not impressed
"here's a page with a masthead, nav, footer, and we've built it all into a table"
Its not the browsers fault at all that web developers are using the wrong constructs. Tables are for presenting tabular data, not layout. Stylesheets are to be used for laying out content.
Your argument falls flat purely because you insist on using tables for purposes it was not intended for.
NS can have trouble with 1 pixel high table cells
What's a one-pixel high table cell adding to the value and context of the content -- nothing.
Why would someone have a table cell one pixel high for displaying tabular data? If you need a pixel extra for your padding, use a stylesheet.
Using CSS to suggest a layout is a standard technique. The tools are there to create the layouts you need - use them. -
Re:You've got the right vision...
a sig(TM)
a Cooler Sig
this sig Copyright © 2002 Anonymous Coward
Siggy Soggy, Siggy Soggy, Hoi! Hoi! Hoi!® is a registered trademark of The Nerd Show
HTML entities...
Learn them.
Live them.
Love them. -
Re:stoopid validator
Went to this w3 validator, and ran it on www.washington.edu. Gives a LOT of stupid errors, such as saying the tag was never opened (yes, is there).
A lot of errors are a result of earlier problems, in your case for starters, the link element is incorrectly terminated with a / (you have specified HTML4.01 Transitional, not any XHTML flavour).
W3 Link element spec
Not much point specifying one HTML recommendation and following another! -
Re:Well yes .. but ...
there should be a standard on what to do with badly formed HTML too.
There is such a standard for XML:
Validating and non-validating processors alike must report violations of this specification's well-formedness constraints in the content of the document entity and any other parsed entities that they read.
I suspect it's there because of the reasons you mentioned.
-
Standards and ReccomendationsThe W3C issues recommendations. They are not a standards organization, such as ISO, ECMA, or ANSI. Many companies, particularly those doing government business, are required to follow specs issued from standards bodies. HTML is OK, becasue of ISO/IEC 15445:1998(E). XHTML is not a standard; neither is XML, except as particular applications of SGML.
I tried creating a web page that used the ISO HTML DOCTYPE declaration:
<!DOCTYPE HTML PUBLIC "ISO/IEC 15445:1998//DTD HyperText Markup Language//EN">
The W3C validator page complained about it: Fatal Error: unrecognized {{DOCTYPE}}; unable to check documentIt seems standards are not so standard.
-
Re:Slashdot
Ummm, not
Actually, it's amazing how few websites anywhere validate as correct HTML. We're not talking style here, but basic syntax. Since browsers don't enforce strict coding, web designers can output faulty code and get away with it.
-
Re:I am not impressed
These "web standards" people, however, seem to be using a font size a step down from standard for the main text on their page. Why?
Probably because (according to their stylesheet) they intend the main text to be displayed using the ubiquitous Georgia font and Georgia has a high aspect value, making it look "too big" when the default font-size is used.
See the W3C CSS spec (scroll down a bit):
For example, the popular font Verdana has an aspect value of 0.58; when Verdana's font size 100 units, its x-height is 58 units. For comparison, Times New Roman has an aspect value of 0.46. Verdana will therefore tend to remain legible at smaller sizes than Times New Roman. Conversely, Verdana will often look 'too big' if substituted for Times New Roman at a chosen size.
Arien
-
Standard HTML
Maybe Slashdot could get the hint!
-
No errors!
Great! this is actually one of the few sites that passes the w3 (x)html validator!
Check it too. -
No errors!
Great! this is actually one of the few sites that passes the w3 (x)html validator!
Check it too. -
Re:Make it user-friendly.
I usually find that mozilla doesn't render sites like that poperly because they are in fact not web sites at all.
Very true. If the W3C HTML Validator says "No errors found!" it's HTML — otherwise it's not. Unfortunately most of those clueless webmasters' bosses don't even know that there's such a thing as The World Wide Web Consortium. It's always a Good Thing to send emails to the higher management of companies with broken websites (not to their webmasters as they will probably ignore them) kindly informing that "your website is broken and however it may look good on your computer, it does't work for some people with different configuration (like myself and many of my friends) and you lose part of your customers." Speak to their wallets.
-
Re:Make it user-friendly.
I usually find that mozilla doesn't render sites like that poperly because they are in fact not web sites at all.
Very true. If the W3C HTML Validator says "No errors found!" it's HTML — otherwise it's not. Unfortunately most of those clueless webmasters' bosses don't even know that there's such a thing as The World Wide Web Consortium. It's always a Good Thing to send emails to the higher management of companies with broken websites (not to their webmasters as they will probably ignore them) kindly informing that "your website is broken and however it may look good on your computer, it does't work for some people with different configuration (like myself and many of my friends) and you lose part of your customers." Speak to their wallets.
-
Re:Make it user-friendly.
I usually find that mozilla doesn't render sites like that poperly because they are in fact not web sites at all.
Very true. If the W3C HTML Validator says "No errors found!" it's HTML — otherwise it's not. Unfortunately most of those clueless webmasters' bosses don't even know that there's such a thing as The World Wide Web Consortium. It's always a Good Thing to send emails to the higher management of companies with broken websites (not to their webmasters as they will probably ignore them) kindly informing that "your website is broken and however it may look good on your computer, it does't work for some people with different configuration (like myself and many of my friends) and you lose part of your customers." Speak to their wallets.
-
Re:C-Nut review is narrow minded
-
Re:It's so slow
Moz just seems to 'think' about every action a while first.
umm.. computers don't think. People do.
So, I guess in this age of eye-candy, Mozilla is king ("ooh look-skins!").
There's a lot more going on there than pretty skins bro, ever hear of web standards? Didn't think so. Here's a couple of hints for ya.
w3.org
webstandards browser upgrade
Webstandards
While yer at it, you may wanna validate some of those pages you surf in NS4.
Did you know what people have been writing webpages with CSS for the past few years?
Back to NS4 and waiting for Mozilla 2.
Thats it, I am finally using some DOM sniff code and routing all the 4.0 browser people to AOL, where they belong. -
Re:It's so slow
Moz just seems to 'think' about every action a while first.
umm.. computers don't think. People do.
So, I guess in this age of eye-candy, Mozilla is king ("ooh look-skins!").
There's a lot more going on there than pretty skins bro, ever hear of web standards? Didn't think so. Here's a couple of hints for ya.
w3.org
webstandards browser upgrade
Webstandards
While yer at it, you may wanna validate some of those pages you surf in NS4.
Did you know what people have been writing webpages with CSS for the past few years?
Back to NS4 and waiting for Mozilla 2.
Thats it, I am finally using some DOM sniff code and routing all the 4.0 browser people to AOL, where they belong. -
Re:Sometimes this is not IE's fault
Hmmm... I underwent some similar (analogous) experiences using CSS floats and text-HTML-ing on my linux box, periodically checking with Mozilla and the W3C Validator; it was all standards-compliant (heck, half the CSS codes I learned off the spec).
I leaned back with satisfaction, only to find that MSIE still hasn't implemented (OK, fine, no MSIE I saw tried in any way to display) CSS fixed boxes. Actually, if you load up the W3C CSS page itself, on Mozilla, the navbar floats semi-transparently, the way it's supposed to, but on MSIE, it sits there, creating the impression that the W3C has bad web site designers.
A friend of mine kept nudging me and telling me how great MSIE CSS support was, and when I showed him the page along with the spec, he spent a half-hour searching for my non-existent coding error...
-
Re:Make it user-friendly.
I usually find that mozilla doesn't render sites like that poperly because they are in fact not web sites at all.
Ooh, semantics. Oh great Internet dictionary, what is a web site?
A Web site (we prefer the two words rather than Website) is a collection of Web files on a particular subject that includes a beginning file called a home page. -- from TechTarget
A set of interconnected webpages, usually including a homepage, generally located on the same server, and prepared and maintained as a collection of information by a person, group, or organization. -- from the American Heritage Dictionary
I'm sorry, I don't see any preaching about what is and what isn't a "Web file." You say that only "The W3C does" specify what is and isn't an HTML file. That's true: they have a validator which can tell you whether a web page is valid HTML. You and I both know that most of the highly-trafficked sites on the web aren't valid HTML. CNN.com isn't valid HTML. Yahoo! isn't valid HTML 4.01 Transitional. Of course, even Slashdot isn't valid HTML. Should these not be considered web sites? Well, they all render just fine in Mozilla, so by your definition they're fine and dandy.
Mozilla doesn't render all of the web's documents correctly. Neither does IE. However, IE is the de facto standard now, so most usability testing focuses on IE accessibility. Slashdot users such as yourself love to spout sour grapes about how such-and-such site doesn't render with Mozilla, but so what? No amount of whining will change that. If I told my professors that I couldn't research a site because it wouldn't work in Mozilla, they'd tell me, "That's nice. You fail."
The web would be a nicer place if everyone wrote standards-compliant HTML, but everyone doesn't. You can't whine about it. Just deal with it.
-
Re:Make it user-friendly.
I usually find that mozilla doesn't render sites like that poperly because they are in fact not web sites at all.
Ooh, semantics. Oh great Internet dictionary, what is a web site?
A Web site (we prefer the two words rather than Website) is a collection of Web files on a particular subject that includes a beginning file called a home page. -- from TechTarget
A set of interconnected webpages, usually including a homepage, generally located on the same server, and prepared and maintained as a collection of information by a person, group, or organization. -- from the American Heritage Dictionary
I'm sorry, I don't see any preaching about what is and what isn't a "Web file." You say that only "The W3C does" specify what is and isn't an HTML file. That's true: they have a validator which can tell you whether a web page is valid HTML. You and I both know that most of the highly-trafficked sites on the web aren't valid HTML. CNN.com isn't valid HTML. Yahoo! isn't valid HTML 4.01 Transitional. Of course, even Slashdot isn't valid HTML. Should these not be considered web sites? Well, they all render just fine in Mozilla, so by your definition they're fine and dandy.
Mozilla doesn't render all of the web's documents correctly. Neither does IE. However, IE is the de facto standard now, so most usability testing focuses on IE accessibility. Slashdot users such as yourself love to spout sour grapes about how such-and-such site doesn't render with Mozilla, but so what? No amount of whining will change that. If I told my professors that I couldn't research a site because it wouldn't work in Mozilla, they'd tell me, "That's nice. You fail."
The web would be a nicer place if everyone wrote standards-compliant HTML, but everyone doesn't. You can't whine about it. Just deal with it.
-
Re:Make it user-friendly.
I usually find that mozilla doesn't render sites like that poperly because they are in fact not web sites at all.
Ooh, semantics. Oh great Internet dictionary, what is a web site?
A Web site (we prefer the two words rather than Website) is a collection of Web files on a particular subject that includes a beginning file called a home page. -- from TechTarget
A set of interconnected webpages, usually including a homepage, generally located on the same server, and prepared and maintained as a collection of information by a person, group, or organization. -- from the American Heritage Dictionary
I'm sorry, I don't see any preaching about what is and what isn't a "Web file." You say that only "The W3C does" specify what is and isn't an HTML file. That's true: they have a validator which can tell you whether a web page is valid HTML. You and I both know that most of the highly-trafficked sites on the web aren't valid HTML. CNN.com isn't valid HTML. Yahoo! isn't valid HTML 4.01 Transitional. Of course, even Slashdot isn't valid HTML. Should these not be considered web sites? Well, they all render just fine in Mozilla, so by your definition they're fine and dandy.
Mozilla doesn't render all of the web's documents correctly. Neither does IE. However, IE is the de facto standard now, so most usability testing focuses on IE accessibility. Slashdot users such as yourself love to spout sour grapes about how such-and-such site doesn't render with Mozilla, but so what? No amount of whining will change that. If I told my professors that I couldn't research a site because it wouldn't work in Mozilla, they'd tell me, "That's nice. You fail."
The web would be a nicer place if everyone wrote standards-compliant HTML, but everyone doesn't. You can't whine about it. Just deal with it.
-
Re:Make it user-friendly.
I usually find that mozilla doesn't render sites like that poperly because they are in fact not web sites at all.
Ooh, semantics. Oh great Internet dictionary, what is a web site?
A Web site (we prefer the two words rather than Website) is a collection of Web files on a particular subject that includes a beginning file called a home page. -- from TechTarget
A set of interconnected webpages, usually including a homepage, generally located on the same server, and prepared and maintained as a collection of information by a person, group, or organization. -- from the American Heritage Dictionary
I'm sorry, I don't see any preaching about what is and what isn't a "Web file." You say that only "The W3C does" specify what is and isn't an HTML file. That's true: they have a validator which can tell you whether a web page is valid HTML. You and I both know that most of the highly-trafficked sites on the web aren't valid HTML. CNN.com isn't valid HTML. Yahoo! isn't valid HTML 4.01 Transitional. Of course, even Slashdot isn't valid HTML. Should these not be considered web sites? Well, they all render just fine in Mozilla, so by your definition they're fine and dandy.
Mozilla doesn't render all of the web's documents correctly. Neither does IE. However, IE is the de facto standard now, so most usability testing focuses on IE accessibility. Slashdot users such as yourself love to spout sour grapes about how such-and-such site doesn't render with Mozilla, but so what? No amount of whining will change that. If I told my professors that I couldn't research a site because it wouldn't work in Mozilla, they'd tell me, "That's nice. You fail."
The web would be a nicer place if everyone wrote standards-compliant HTML, but everyone doesn't. You can't whine about it. Just deal with it.
-
Re:This is not realisticSadly, I have to agree with your point. While us geeks know the difference between HTML 4.0 compliant and IE 5.x+ compliant, the average user does not. That's too bad. But there are too many people out there (commercial web designers as well) that take advantage of some of the features that IE has implemented. Last time I said that, people jumped all over me...but to the end user, if browser X does something that browser Y and Z don't do...it's a feature (from a marketing point of view anyhow...and what runs the world? Marketing).
Anyhow, a friend of mine pointed out a back-alley solution to the situation that has, unfortunately, become a reality. At install time (and as a toggle after install), it would be pretty educating to the joe-web-user to actually have an option in which you can choose how pages are rendered:
How would you like Mozilla to render web pages?
Render pages following the Microsoft standards
Render pages following the more widely accepted HTML standards promoted by the World Wide Web Consortium
If nothing else, such a scheme would be a bit of an eye opener, and maybe pick up a few more web designers -- maybe we'd even grow a few more purists. I imagine that Netscape wouldn't want to do this as they don't want to draw on a law suit. But an open source project like Mozilla could pull it off.
The problem is as it always is: Lack of Education ruins quality and puts money in the pockets of the greedy (aka, MS).
-
So how do you define "web page"?
what mathers in the end is
What does this have to do with Eminem (aka Marshall Mathers)?
does this web page load.
First, before you can have a web page load, you have to have a web page to begin with. If you put some content up on AOL's proprietary system, would it be a "web page"? Does Flash served up through HTTP count as a "web page"? And if you made some content available through HTTP in Microsoft's proprietary mark-up language (which happens to look similar to HTML), would it also count as a "web page"?
There has to be some definition of a "web page". You may choose "web page" as it's defined by the documentation on MSDN, with VBScript, ActiveX, and the like. I'd rather define "web page" using the W3C specification of HTML and related technologies (CSS, ECMAScript, DOM, PNG, etc).
now that would be a good way for all of you whiners saying that IE is bugriden to prove to the world that you are better than Microsoft and implement their features correctly
And end up in court for violating patents owned by Microsoft Corporation. Microsoft's latest patent licenses specifically exclude any software licensed under the GNU GPL (part of the tri-license covering most of Mozilla).
-
Re:Not bad at all.
I'm sorry but your asking for too much. IE already supports non "IE-Style" layers. It's called CSS1. It's fully implemented on both IE5.5+ and NS6+ (Mozilla, etc)... Same goes for scripting objects. Both support (more or less) the Document Object Model standard.. DOM1. As for Image alignment. The "align" property is deprecated, you should be using style sheets by now. See W3.ORG.
-
Re:What's worse?
Logic check: "Don't use the browser that most websites are designed for!"
How about: The web is designed to operate on a standard protocol. Web sites designed for a specific browser, instead of being done according to standards, are missing the point. -
Re:IE often HAS to be your browser of choice
"Well, I see the problem...."
So do I.
You are using tables to layout your webpages when you are supposed to use style sheets. -
Yes, you can put form elems in tables
W3 validators say I can't put form elements in tables!!!! Hello?
You can put form elements in tables. What you probably did was hose up the element nesting by placing your FORM inside of your TABLE. If you look closely at the validator output, it will tell you where you hosed your nesting.
If you inspect the HTML 4 Transitional Document Type Definition, you would see that FORM elements may contain %flow; content -- which includes both inline elements and block elements like tables. So if you want to do it right, place your TABLE inside of your FORM, not the other way around, and then place the form elements inside the appropriate table elements.
Easy as pie.
-
Re:IE monopolyNo, we don't want companies to decide what the standards are. That's why we have open standards.
Your comparison is also terrible and not relevant in the least.
-
Re:Release quality
Right now it is kind of hard to develop browser skins, XUL apps, and even web content for a browser that has major changes every week. Now we can finally develop content that can last on this browser.
You shouldn't develop web content for Mozilla any more than you should develop web content for Internet Explorer. You should be writing to the established standards. I'm a fairly recent convert to Mozilla (started with 1.0RC1) and have seen too many pages that don't render properly because they were written to deal with IE's idiosyncracies. A web full of pages that do the same with Mozilla would be no better.
-
Standards?>> It's too late to affect de-facto standards
That's funny.. Mozilla isn't trying to change the standards. Get this... it's actually FOLLOWING THEM!
Wow! What a concept.
>>The only major problem I have with it is that plugins are very hard to install (on Win2K) compared to IE.
Yeah... and no fun security exploits to play with =(
-
Re:What's next for XML?
and a query language
XML Query for when qpath isn't enough
-
RDF schema and OntologyXML schema and Namespaces help to control syntax. And only syntax
Tired from semantical hard-coding? Try RDF-schema and ontologies.
-
Re:XML bad choice for this problem setRDF is XML. RDF is a perfect format for graph presentation.
- Here are some links for further education:
- RGML (RDF Graph Modeling Language)
- (RDF) Model and Syntax Specification
- The DARPA Agent Markup Language
-
Re:What's next for XML?
XEXPR - A Scripting Language for XML
Read and weep. -
Wow! Slashdotted Already?
This article explores the ins and outs of XML namespaces and their ramifications on a number of XML technologies that support namespaces. What follows is a shortened version of my first Extreme XML column.
Overview of XML NamespacesAs XML usage on the Internet became more widespread, the benefits of being able to create markup vocabularies that could be combined and reused similarly to how software modules are combined and reused became increasingly important. If a well defined markup vocabulary for describing coin collections, program configuration files, or fast food restaurant menus already existed, then reusing it made more sense than designing one from scratch. Combining multiple existing vocabularies to create new vocabularies whose whole was greater than the sum of its parts also became a feature that users of XML began to require.
However, the likelihood of identical markup, specifically XML elements and attributes, from different vocabularies with different semantics ending up in the same document became a problem. The very extensibility of XML and the fact that its usage had already become widespread across the Internet precluded simply specifying reserved elements or attribute names as the solution to this problem.
The goal of the W3C XML namespaces recommendation was to create a mechanism in which elements and attributes within an XML document that were from different markup vocabularies could be unambiguously identified and combined without processing problems ensuing. The XML namespaces recommendation provided a method for partitioning various items within an XML document based on processing requirements without placing undue restrictions on how these items should be named. For instance, elements named <template>, <output>, and <stylesheet> can occur in an XSLT stylesheet without there being ambiguity as to whether they are transformation directives or potential output of the transformation.
An XML namespace is a collection of names, identified by a Uniform Resource Identifier (URI) reference, which are used in XML documents as element and attribute names.
Namespace DeclarationsA namespace declaration is typically used to map a namespace URI to a specific prefix. The scope of the prefix-namespace mapping is that of the element that the namespace declaration occurs on as well as all its children. An attribute declaration that begins with the prefix xmlns: is a namespace declaration. The value of such an attribute declaration should be a namespace URI which is the namespace name.
Here is an example of an XML document where the root element contains a namespace declaration that maps the prefix bk to the namespace name urn:xmlns:25hoursaday-com:bookstore and its child element contains an inventory element that contains a namespace declaration that maps the prefix inv to the namespace name urn:xmlns:25hoursaday-com:inventory-tracking.
<bk:bookstore xmlns:bk="urn:xmlns:25hoursaday-com:bookstore">
<bk:book>
<bk:title>Lord of the Rings</bk:title>
<bk:author>J.R.R. Tolkien</bk:author>
<inv:inventory status="in-stock" isbn="0345340426"
xmlns:inv="urn:xmlns:25hoursaday-com:inventory-tra cking"
</bk:book>
</bk:bookstore>
In the above example, the scope of the namespace declaration for the urn:xmlns:25hoursaday-com:bookstore namespace name is the entire bk:bookstore element, while that of the urn:xmlns:25hoursaday-com:inventory-tracking is the inv:inventory element. Namespace aware processors can process items from both namespaces independently of each other, which leads to the ability to do multi-layered processing of XML documents. For instance, RDDL documents are valid XHTML documents that can be rendered by a Web browser but also contain information using elements from the http://www.rddl.org namespace that can be used to locate machine readable resources about the members of an XML namespace.
It should be noted that by definition the prefix xml is bound to the XML namespace name and this special namespace is automatically predeclared with document scope in every well-formed XML document.
Default NamespacesThe previous section on namespace declarations is not entirely complete because it leaves out default namespaces. A default namespace declaration is an attribute declaration that has the name xmlns and its value is the namespace URI that is the namespace name.
A default namespace declaration specifies that every unprefixed element name in its scope be from the declaring namespace. Below is the bookstore example utilizing a default namespace instead of a prefix-namespace mapping.
<bookstore xmlns="urn:xmlns:25hoursaday-com:bookstore">
<book>
<title>Lord of the Rings</bk:title>
<author>J.R.R. Tolkien</bk:author>
<inv:inventory status="in-stock" isbn="0345340426"
xmlns:inv="urn:xmlns:25hoursaday-com:inventory-tra cking"
</book>
</bookstore>
All the elements in the above example except for the inv:inventory element belong to the urn:xmlns:25hoursaday-com:bookstore namespace. The primary purpose of default namespaces is to reduce the verbosity of XML documents that utilize namespaces. However, using default namespaces instead of utilizing explicitly mapped prefixes for element names can be confusing because it is not obvious that the elements in the document are namespace scoped.
Also, unlike regular namespace declarations, default namespace declarations can be undeclared by setting the value of the xmlns attribute to the empty string. Undeclaring default namespace declarations is a practice that should be avoided because it may lead to a document that has unprefixed names that belong to a namespace in one part of the document, but don't in another. For example, in the document below only the bookstore element is from the urn:xmlns:25hoursaday-com:bookstore while the other unprefixed elements have no namespace name.
<bookstore xmlns="urn:xmlns:25hoursaday-com:bookstore">
<book xmlns="">
<title>Lord of the Rings</bk:title>
<author>J.R.R. Tolkien</bk:author>
<inv:inventory status="in-stock" isbn="0345340426"
xmlns:inv="urn:xmlns:25hoursaday-com:inventory-tra cking"
</book>
</bookstore>
This practice should be avoided because it leads to extremely confusing situations for readers of the XML document. For more information on undeclaring namespace declarations, see the section on Namespaces Future.
Qualified and Expanded NamesA qualified name, also known as a QName, is an XML name called the local name optionally preceded by another XML name called the prefix and a colon (':') character. The XML names used as the prefix and the local name must match the NCName production, which means that they must not contain a colon character. The prefix of a qualified name must have been mapped to a namespace URI through an in-scope namespace declaration mapping the prefix to the namespace URI. A qualified name can be used as either an attribute or element name.
Although QNames are important mnemonic guides to determining what namespace the elements and attributes within a document are derived from, they are rarely important to XML aware processors. For example, the following three XML documents would be treated identically by a range of XML technologies including, of course, XML schema validators.
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:complexType id="123" name="fooType"/>
</xs:schema>
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<xsd:complexType id="123" name="fooType"/>
</xsd:schema>
<schema xmlns="http://www.w3.org/2001/XMLSchema">
<complexType id="123" name="fooType"/>
</schema>
The W3C XML Path Language recommendation describes an expanded name as a pair consisting of a namespace name and a local name. A universal name is an alternate term coined by James Clark to describe the same concept. A universal name consists of a namespace name in curly braces and a local name. Namespaces tend to make more sense to people when viewed through the lens of universal names. Here are the three XML documents from the previous example with the QNames replaced by universal names. Note that the syntax below is not valid XML syntax.
<{http://www.w3.org/2001/XMLSchema}schema>&n bsp;
<{http://www.w3.org/2001/XMLSchema}complexType id="123" name="fooType"/>
</{http://www.w3.org/2001/XMLSchema}schema>
<{http://www.w3.org/2001/XMLSchema}schema>&n bsp;
<{http://www.w3.org/2001/XMLSchema}complexType id="123" name="fooType"/>
</{http://www.w3.org/2001/XMLSchema}schema>
<{http://www.w3.org/2001/XMLSchema}schema>&n bsp;
<{http://www.w3.org/2001/XMLSchema}complexType id="123" name="fooType"/>
</{http://www.w3.org/2001/XMLSchema}schema>
To many XML applications, the universal name of the elements and attributes in an XML document are what is important, and not the values of the prefixes used in specific QNames. The primary reason the Namespaces in XML recommendation does not take the expanded name approach to specifying namespaces is due to its verbosity. Instead, prefix mappings and default namespaces are provided to save us all from developing carpal tunnel syndrome from typing namespace URIs endlessly.
Namespaces and AttributesNamespace declarations do not apply to attributes unless the attribute's name is prefixed. In the XML document shown below the title attribute belongs to the bk:book element and has no namespace while the bk:title attribute has urn:xmlns:25hoursaday-com:bookstore as its namespace name. Note that even though both attributes have the same local name the document is well formed.
<bk:bookstore xmlns:bk="urn:xmlns:25hoursaday-com:bookstore">
<bk:book title="Lord of the Rings, Book 3" bk:title="Return of the King"/>
</bk:bookstore>
In the following example, the title attribute still has no namespace and belongs the book element even though there is a default namespace specified. In other words, attributes cannot inherit the default namespace.
<bookstore xmlns="urn:xmlns:25hoursaday-com:bookstore">
<book title="Lord of the Rings, Book 3"
</bookstore>
Namespace URIsA namespace name is a Uniform Resource Identifier (URI) as specified in RFC 2396. A URI is either a Uniform Resource Locators (URLs) or a Uniform Resource Names (URNs). URLs are used to specify the location of resources on the Internet, while URNs are supposed to be persistent, location-independent identifiers for information resources. Namespace names are considered to be identical only if they are the same character for character (case-sensitive). The primary justification for using URIs as namespace names is that they already provide a mechanism for specifying globally unique identities.
The XML namespaces recommendation states that namespace names are only to act as unique identifiers and do not have to actually identify network retrievable resources. This has led to much confusion amongst authors and users of XML documents, especially since the usage of HTTP based URLs as namespace names has grown in popularity. Because many applications convert such URIs to hyperlinks, it is irritating to many users that these "links" do not lead to Web pages or other network retrievable resource. I remember one user who likened it to being given a fake phone number in a social situation.
One solution to avoid confusing users is to use a namespace-naming schema that does not imply network retrievability of the resource. I personally use the urn:xmlns: scheme for this purpose and create namespace names similar to urn:xmlns:25hoursaday-com when authoring XML documents for personal use. The problem with homegrown namespace URIs is that they may run counter to the intent of the Names in XML recommendation by not being globally unique. I get around the globally unique requirement by using my personal domain name http://www.25hoursaday.com as part of the namespace URI.
Another solution is to leave a network retrievable resource at the URI that is the namespace name, such as is done with the XSLT and RDDL namespaces. Typically, such URIs are actually HTTP URLs. A good way to name such URLs is by using the format favored by the W3C, which is as follows:
http://my.domain.example.org/product/[year/month][ / rea]
See the section on Namespaces and Versioning for more information on using similarly structured namespace names as a versioning mechanism.
DOM, XPath, and the XML Information Set on NamespacesThe W3C has defined a number of technologies that provide a data model for XML documents. These data models are generally in agreement, but sometimes differ in how they treat various edge cases due to historic reasons. Treatment of XML namespaces and namespace declarations is an example of an edge case that is treated differently in the three primary data models that exist as W3C recommendations. The three data models are the XPath data model, the Document Object Model (DOM), and the XML information set.
The XML information set (XML infoset) is an abstract description of the data in an XML document and can be considered to be the primary data model for an XML document. The XPath data model is a tree-based model that is traversed when querying an XML document and is similar to the XML information set. The DOM precedes both data models but is also similar to both data models in a number of ways. Both the DOM and the XPath data model can be considered to be interpretations of the XML infoset.
Namespaces in the Document Object Model (DOM)The XML namespace section of the DOM Level 3 specification considers namespace declarations to be regular attribute nodes that have http://www.w3.org/2000/xmlns/ as their namespace name and xmlns as their prefix or qualified name.
Elements and attributes in the DOM have a namespace name that cannot be altered after they have been created regardless of whether their location within the document changes or not.
Namespaces in the XPath Data ModelThe W3C XPath recommendation does not consider namespace declarations to be attribute nodes and does not provide access to them in that capacity. Instead, in XPath every element in an XML document has a number of namespace nodes that can be retrieved using the XPath namespace navigation axis.
Each element in the document has a unique set of namespace nodes for each namespace declaration in scope for that particular element. Namespace nodes are unique to each element in that namespace. Thus namespace nodes for two different elements that represent the same namespace declaration are not identical.
Namespaces in the XML Information SetThe XML infoset recommendation considers namespace declarations to be attribute information items.
In addition, similar to the XPath data model, each element information item in an XML document's information set has a namespace information item for each namespace that is in scope for the element.
XPath, XSLT and NamespacesThe W3C XML Path Language also known as XPath is used to address parts of an XML document and is used in a number of W3C XML technologies including XSLT, XPointer, XML Schema, and DOM Level 3. XPath uses a hierarchical addressing mechanism similar to that used in file systems and URLs to retrieve pieces of an XML document. XPath supports rudimentary manipulation of strings, numbers, and Booleans.
XPath and NamespacesThe XPath data model treats an XML document as a tree of nodes, such as element, attribute, and text nodes, where the name of each node is a combination of its local name and its namespace name (that is, its universal or expanded name).
For element and attribute nodes without namespaces, performing XPath queries is fairly straightforward. The following program, which can be used to query XML documents using the command line, shall be used to demonstrate the impact of namespaces on XPath queries.
using System.Xml.XPath;
using System.Xml;
using System;
using System.IO;
class XPathQuery{
public static string PrintError(Exception e, string errStr){
if(e == null)
return errStr;
else
return PrintError(e.InnerException, errStr + e.Message );
}
public static void Main(string[] args){
if((args.Length == 0) || (args.Length % 2)!= 0){
Console.WriteLine("Usage: xpathquery source query <zero or more
prefix and namespace pairs>");
return;
}
try{
XmlDocument doc = new XmlDocument();
doc.Load(args[0]);
XmlNamespaceManager nsMgr = new XmlNamespaceManager(doc.NameTable);
for(int i=2; i < args.Length; i+= 2)
nsMgr.AddNamespace(args[i], args[i + 1]);
XmlNodeList nodes = doc.SelectNodes(args[1], nsMgr);
foreach(XmlNode node in nodes)
Console.WriteLine(node.OuterXml + "\n\n");
}catch(XmlException xmle){
Console.WriteLine("ERROR: XML Parse error occured because " +
PrintError(xmle, null));
}catch(FileNotFoundException fnfe){
Console.WriteLine("ERROR: " + PrintError(fnfe, null));
}catch(XPathException xpath){
Console.WriteLine("ERROR: The following error occured while querying
the document: "
&n bsp; + PrintError(xpath, null));
}catch(Exception e){
Console.WriteLine("UNEXPECTED ERROR" + PrintError(e, null));
}
}
}
Given the following XML document that does not declare any namespaces, queries are fairly straightforward as seen in the examples following the code.
<?xml version="1.0" encoding="utf-8" ?>
<bookstore>
<book genre="autobiography">
<title>The Autobiography of Benjamin Franklin</title>
<author>
<first-name>Benjamin</first-name>
<last-name>Franklin</last-name>
</author>
<price>8.99</price>
</book>
<book genre="novel">
<title>The Confidence Man</title>
<author>
<first-name>Herman</first-name>
<last-name>Melville</last-name>
</author>
<price>11.99</price>
</book>
</bookstore>
Example 1xpathquery.exe bookstore.xml
Selects all the title elements that are children of the book element whose parent is the bookstore element, which returns:
<title>The Autobiography of Benjamin Franklin</title>
<title>The Confidence Man</title>xpathquery.exe bookstore.xml
Select all the genre attributes in the document and returns:
genre="autobiography"
genre="novel"xpathquery.exe bookstore.xml
Selects all the titles where the author's first name is "Herman" and returns:
<title>The Confidence Man</title>
However, once namespaces are added to the mix, things are no longer as simple. The file below is identical to the original file except for the addition of namespaces and one attribute to one of the book elements.
<bookstore xmlns="urn:xmlns:25hoursaday-com:bookstore">
<book genre="autobiography">
<title>The Autobiography of Benjamin Franklin</title>
<author>
<first-name>Benjamin</first-name>
<last-name>Franklin</last-name>
</author>
<price>8.99</price>
</book>
<bk:book genre="novel" bk:genre="fiction"
xmlns:bk="urn:xmlns:25hoursaday-com:bookstore">
<bk:title>The Confidence Man</bk:title>
<bk:author>
<bk:first-name>Herman</bk:first-name>
<bk:last-name>Melville</bk:last-name>
</bk:author>
<bk:price>11.99</bk:price>
</bk:book>
</bookstore>
Note that the default namespace is in scope for the whole XML document, while the namespace declaration that maps the prefix bk to the namespace name urn:xmlns:25hoursaday-com:bookstore is in scope for the second book element only. Example 2
xpathquery.exe bookstore.xml
Selects all the title elements that are children of the book element whose parent is the bookstore element, which returns NO RESULTS.
xpathquery.exe bookstore.xml
Selects all the genre attributes in the document and returns:
genre="autobiography"
genre="novel"
xpathquery.exe bookstore.xml
Selects all the titles where the author's first name is "Herman," which returns NO RESULTS.
The first query returns no results because unprefixed names in an XPath query apply to elements or attributes with no namespace. There are no bookstore, book, or title elements in the target document that have no namespace. The second query returns all attribute nodes that have no namespace. Although namespace declarations are in scope for both attribute nodes returned by the query, they have no namespace because namespace declarations do not apply to attributes with unprefixed names. The third query returns no results for the same reasons the first query returns no results.
The way to perform namespace-aware XPath queries is to provide a prefix to namespace mapping to the XPath engine, then use those prefixes in the query. The prefixes provided do not need to be the same as the namespace to prefix mappings in the target document, and they must be non-empty prefixes. Example 3
xpathquery.exe bookstore.xml
Select all the title elements that are children of the book element whose parent is the bookstore element and returns the following:
<title xmlns="urn:xmlns:25hoursaday-com:bookstore">The Autobiography of Benjamin Franklin</title>
<bk:title xmlns:bk="urn:xmlns:25hoursaday-com:bookstore"> The Confidence Man</bk:title>xpathquery.exe bookstore.xml
Selects all the genre attributes from the "urn:xmlns:25hoursaday-com:bookstore" namespace in the document that returns:
bk:genre="fiction"xpathquery.exe bookstore.xml
Selects all the titles where the author's first name is "Herman" and returns:
<bk:title xmlns:bk="urn:xmlns:25hoursaday-com:bookstore"> The Confidence Man</bk:title>
Note This last example is the same as the previous examples but rewritten to be namespace aware.
For more information on using XPath, read Aaron Skonnard's article Addressing Infosets with XPath and view the examples at the ZVON.org XPath tutorial.
XSLT and NamespacesThe W3C XSL transformations (XSLT) recommendation describes an XML-based language for transforming XML documents into other XML documents. XSLT transformations, also known as XML style sheets, utilize patterns (XPath) to match aspects of the target document. Upon matching nodes in the target document, templates that specify the output of a successful match can be instantiated and used to transform the document.
Support for namespaces is tightly integrated into XSLT, especially since XPath is used for matching nodes in the source document. Using namespaces in your XPath expressions inside XSLT is much easier than using the DOM.
The example that follows contains:
A program for use in executing transforms from the command line.
An XSLT stylesheet that prints all the title elements from the urn:xmlns:25hoursaday-com:bookstore namespace in the source XML document when run against the bookstore document from the urn:xmlns:25hoursaday-com:bookstore namespace.
The resulting output. Program Imports System.Xml.Xsl
-
Wow! Slashdotted Already?
This article explores the ins and outs of XML namespaces and their ramifications on a number of XML technologies that support namespaces. What follows is a shortened version of my first Extreme XML column.
Overview of XML NamespacesAs XML usage on the Internet became more widespread, the benefits of being able to create markup vocabularies that could be combined and reused similarly to how software modules are combined and reused became increasingly important. If a well defined markup vocabulary for describing coin collections, program configuration files, or fast food restaurant menus already existed, then reusing it made more sense than designing one from scratch. Combining multiple existing vocabularies to create new vocabularies whose whole was greater than the sum of its parts also became a feature that users of XML began to require.
However, the likelihood of identical markup, specifically XML elements and attributes, from different vocabularies with different semantics ending up in the same document became a problem. The very extensibility of XML and the fact that its usage had already become widespread across the Internet precluded simply specifying reserved elements or attribute names as the solution to this problem.
The goal of the W3C XML namespaces recommendation was to create a mechanism in which elements and attributes within an XML document that were from different markup vocabularies could be unambiguously identified and combined without processing problems ensuing. The XML namespaces recommendation provided a method for partitioning various items within an XML document based on processing requirements without placing undue restrictions on how these items should be named. For instance, elements named <template>, <output>, and <stylesheet> can occur in an XSLT stylesheet without there being ambiguity as to whether they are transformation directives or potential output of the transformation.
An XML namespace is a collection of names, identified by a Uniform Resource Identifier (URI) reference, which are used in XML documents as element and attribute names.
Namespace DeclarationsA namespace declaration is typically used to map a namespace URI to a specific prefix. The scope of the prefix-namespace mapping is that of the element that the namespace declaration occurs on as well as all its children. An attribute declaration that begins with the prefix xmlns: is a namespace declaration. The value of such an attribute declaration should be a namespace URI which is the namespace name.
Here is an example of an XML document where the root element contains a namespace declaration that maps the prefix bk to the namespace name urn:xmlns:25hoursaday-com:bookstore and its child element contains an inventory element that contains a namespace declaration that maps the prefix inv to the namespace name urn:xmlns:25hoursaday-com:inventory-tracking.
<bk:bookstore xmlns:bk="urn:xmlns:25hoursaday-com:bookstore">
<bk:book>
<bk:title>Lord of the Rings</bk:title>
<bk:author>J.R.R. Tolkien</bk:author>
<inv:inventory status="in-stock" isbn="0345340426"
xmlns:inv="urn:xmlns:25hoursaday-com:inventory-tra cking"
</bk:book>
</bk:bookstore>
In the above example, the scope of the namespace declaration for the urn:xmlns:25hoursaday-com:bookstore namespace name is the entire bk:bookstore element, while that of the urn:xmlns:25hoursaday-com:inventory-tracking is the inv:inventory element. Namespace aware processors can process items from both namespaces independently of each other, which leads to the ability to do multi-layered processing of XML documents. For instance, RDDL documents are valid XHTML documents that can be rendered by a Web browser but also contain information using elements from the http://www.rddl.org namespace that can be used to locate machine readable resources about the members of an XML namespace.
It should be noted that by definition the prefix xml is bound to the XML namespace name and this special namespace is automatically predeclared with document scope in every well-formed XML document.
Default NamespacesThe previous section on namespace declarations is not entirely complete because it leaves out default namespaces. A default namespace declaration is an attribute declaration that has the name xmlns and its value is the namespace URI that is the namespace name.
A default namespace declaration specifies that every unprefixed element name in its scope be from the declaring namespace. Below is the bookstore example utilizing a default namespace instead of a prefix-namespace mapping.
<bookstore xmlns="urn:xmlns:25hoursaday-com:bookstore">
<book>
<title>Lord of the Rings</bk:title>
<author>J.R.R. Tolkien</bk:author>
<inv:inventory status="in-stock" isbn="0345340426"
xmlns:inv="urn:xmlns:25hoursaday-com:inventory-tra cking"
</book>
</bookstore>
All the elements in the above example except for the inv:inventory element belong to the urn:xmlns:25hoursaday-com:bookstore namespace. The primary purpose of default namespaces is to reduce the verbosity of XML documents that utilize namespaces. However, using default namespaces instead of utilizing explicitly mapped prefixes for element names can be confusing because it is not obvious that the elements in the document are namespace scoped.
Also, unlike regular namespace declarations, default namespace declarations can be undeclared by setting the value of the xmlns attribute to the empty string. Undeclaring default namespace declarations is a practice that should be avoided because it may lead to a document that has unprefixed names that belong to a namespace in one part of the document, but don't in another. For example, in the document below only the bookstore element is from the urn:xmlns:25hoursaday-com:bookstore while the other unprefixed elements have no namespace name.
<bookstore xmlns="urn:xmlns:25hoursaday-com:bookstore">
<book xmlns="">
<title>Lord of the Rings</bk:title>
<author>J.R.R. Tolkien</bk:author>
<inv:inventory status="in-stock" isbn="0345340426"
xmlns:inv="urn:xmlns:25hoursaday-com:inventory-tra cking"
</book>
</bookstore>
This practice should be avoided because it leads to extremely confusing situations for readers of the XML document. For more information on undeclaring namespace declarations, see the section on Namespaces Future.
Qualified and Expanded NamesA qualified name, also known as a QName, is an XML name called the local name optionally preceded by another XML name called the prefix and a colon (':') character. The XML names used as the prefix and the local name must match the NCName production, which means that they must not contain a colon character. The prefix of a qualified name must have been mapped to a namespace URI through an in-scope namespace declaration mapping the prefix to the namespace URI. A qualified name can be used as either an attribute or element name.
Although QNames are important mnemonic guides to determining what namespace the elements and attributes within a document are derived from, they are rarely important to XML aware processors. For example, the following three XML documents would be treated identically by a range of XML technologies including, of course, XML schema validators.
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:complexType id="123" name="fooType"/>
</xs:schema>
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<xsd:complexType id="123" name="fooType"/>
</xsd:schema>
<schema xmlns="http://www.w3.org/2001/XMLSchema">
<complexType id="123" name="fooType"/>
</schema>
The W3C XML Path Language recommendation describes an expanded name as a pair consisting of a namespace name and a local name. A universal name is an alternate term coined by James Clark to describe the same concept. A universal name consists of a namespace name in curly braces and a local name. Namespaces tend to make more sense to people when viewed through the lens of universal names. Here are the three XML documents from the previous example with the QNames replaced by universal names. Note that the syntax below is not valid XML syntax.
<{http://www.w3.org/2001/XMLSchema}schema>&n bsp;
<{http://www.w3.org/2001/XMLSchema}complexType id="123" name="fooType"/>
</{http://www.w3.org/2001/XMLSchema}schema>
<{http://www.w3.org/2001/XMLSchema}schema>&n bsp;
<{http://www.w3.org/2001/XMLSchema}complexType id="123" name="fooType"/>
</{http://www.w3.org/2001/XMLSchema}schema>
<{http://www.w3.org/2001/XMLSchema}schema>&n bsp;
<{http://www.w3.org/2001/XMLSchema}complexType id="123" name="fooType"/>
</{http://www.w3.org/2001/XMLSchema}schema>
To many XML applications, the universal name of the elements and attributes in an XML document are what is important, and not the values of the prefixes used in specific QNames. The primary reason the Namespaces in XML recommendation does not take the expanded name approach to specifying namespaces is due to its verbosity. Instead, prefix mappings and default namespaces are provided to save us all from developing carpal tunnel syndrome from typing namespace URIs endlessly.
Namespaces and AttributesNamespace declarations do not apply to attributes unless the attribute's name is prefixed. In the XML document shown below the title attribute belongs to the bk:book element and has no namespace while the bk:title attribute has urn:xmlns:25hoursaday-com:bookstore as its namespace name. Note that even though both attributes have the same local name the document is well formed.
<bk:bookstore xmlns:bk="urn:xmlns:25hoursaday-com:bookstore">
<bk:book title="Lord of the Rings, Book 3" bk:title="Return of the King"/>
</bk:bookstore>
In the following example, the title attribute still has no namespace and belongs the book element even though there is a default namespace specified. In other words, attributes cannot inherit the default namespace.
<bookstore xmlns="urn:xmlns:25hoursaday-com:bookstore">
<book title="Lord of the Rings, Book 3"
</bookstore>
Namespace URIsA namespace name is a Uniform Resource Identifier (URI) as specified in RFC 2396. A URI is either a Uniform Resource Locators (URLs) or a Uniform Resource Names (URNs). URLs are used to specify the location of resources on the Internet, while URNs are supposed to be persistent, location-independent identifiers for information resources. Namespace names are considered to be identical only if they are the same character for character (case-sensitive). The primary justification for using URIs as namespace names is that they already provide a mechanism for specifying globally unique identities.
The XML namespaces recommendation states that namespace names are only to act as unique identifiers and do not have to actually identify network retrievable resources. This has led to much confusion amongst authors and users of XML documents, especially since the usage of HTTP based URLs as namespace names has grown in popularity. Because many applications convert such URIs to hyperlinks, it is irritating to many users that these "links" do not lead to Web pages or other network retrievable resource. I remember one user who likened it to being given a fake phone number in a social situation.
One solution to avoid confusing users is to use a namespace-naming schema that does not imply network retrievability of the resource. I personally use the urn:xmlns: scheme for this purpose and create namespace names similar to urn:xmlns:25hoursaday-com when authoring XML documents for personal use. The problem with homegrown namespace URIs is that they may run counter to the intent of the Names in XML recommendation by not being globally unique. I get around the globally unique requirement by using my personal domain name http://www.25hoursaday.com as part of the namespace URI.
Another solution is to leave a network retrievable resource at the URI that is the namespace name, such as is done with the XSLT and RDDL namespaces. Typically, such URIs are actually HTTP URLs. A good way to name such URLs is by using the format favored by the W3C, which is as follows:
http://my.domain.example.org/product/[year/month][ / rea]
See the section on Namespaces and Versioning for more information on using similarly structured namespace names as a versioning mechanism.
DOM, XPath, and the XML Information Set on NamespacesThe W3C has defined a number of technologies that provide a data model for XML documents. These data models are generally in agreement, but sometimes differ in how they treat various edge cases due to historic reasons. Treatment of XML namespaces and namespace declarations is an example of an edge case that is treated differently in the three primary data models that exist as W3C recommendations. The three data models are the XPath data model, the Document Object Model (DOM), and the XML information set.
The XML information set (XML infoset) is an abstract description of the data in an XML document and can be considered to be the primary data model for an XML document. The XPath data model is a tree-based model that is traversed when querying an XML document and is similar to the XML information set. The DOM precedes both data models but is also similar to both data models in a number of ways. Both the DOM and the XPath data model can be considered to be interpretations of the XML infoset.
Namespaces in the Document Object Model (DOM)The XML namespace section of the DOM Level 3 specification considers namespace declarations to be regular attribute nodes that have http://www.w3.org/2000/xmlns/ as their namespace name and xmlns as their prefix or qualified name.
Elements and attributes in the DOM have a namespace name that cannot be altered after they have been created regardless of whether their location within the document changes or not.
Namespaces in the XPath Data ModelThe W3C XPath recommendation does not consider namespace declarations to be attribute nodes and does not provide access to them in that capacity. Instead, in XPath every element in an XML document has a number of namespace nodes that can be retrieved using the XPath namespace navigation axis.
Each element in the document has a unique set of namespace nodes for each namespace declaration in scope for that particular element. Namespace nodes are unique to each element in that namespace. Thus namespace nodes for two different elements that represent the same namespace declaration are not identical.
Namespaces in the XML Information SetThe XML infoset recommendation considers namespace declarations to be attribute information items.
In addition, similar to the XPath data model, each element information item in an XML document's information set has a namespace information item for each namespace that is in scope for the element.
XPath, XSLT and NamespacesThe W3C XML Path Language also known as XPath is used to address parts of an XML document and is used in a number of W3C XML technologies including XSLT, XPointer, XML Schema, and DOM Level 3. XPath uses a hierarchical addressing mechanism similar to that used in file systems and URLs to retrieve pieces of an XML document. XPath supports rudimentary manipulation of strings, numbers, and Booleans.
XPath and NamespacesThe XPath data model treats an XML document as a tree of nodes, such as element, attribute, and text nodes, where the name of each node is a combination of its local name and its namespace name (that is, its universal or expanded name).
For element and attribute nodes without namespaces, performing XPath queries is fairly straightforward. The following program, which can be used to query XML documents using the command line, shall be used to demonstrate the impact of namespaces on XPath queries.
using System.Xml.XPath;
using System.Xml;
using System;
using System.IO;
class XPathQuery{
public static string PrintError(Exception e, string errStr){
if(e == null)
return errStr;
else
return PrintError(e.InnerException, errStr + e.Message );
}
public static void Main(string[] args){
if((args.Length == 0) || (args.Length % 2)!= 0){
Console.WriteLine("Usage: xpathquery source query <zero or more
prefix and namespace pairs>");
return;
}
try{
XmlDocument doc = new XmlDocument();
doc.Load(args[0]);
XmlNamespaceManager nsMgr = new XmlNamespaceManager(doc.NameTable);
for(int i=2; i < args.Length; i+= 2)
nsMgr.AddNamespace(args[i], args[i + 1]);
XmlNodeList nodes = doc.SelectNodes(args[1], nsMgr);
foreach(XmlNode node in nodes)
Console.WriteLine(node.OuterXml + "\n\n");
}catch(XmlException xmle){
Console.WriteLine("ERROR: XML Parse error occured because " +
PrintError(xmle, null));
}catch(FileNotFoundException fnfe){
Console.WriteLine("ERROR: " + PrintError(fnfe, null));
}catch(XPathException xpath){
Console.WriteLine("ERROR: The following error occured while querying
the document: "
&n bsp; + PrintError(xpath, null));
}catch(Exception e){
Console.WriteLine("UNEXPECTED ERROR" + PrintError(e, null));
}
}
}
Given the following XML document that does not declare any namespaces, queries are fairly straightforward as seen in the examples following the code.
<?xml version="1.0" encoding="utf-8" ?>
<bookstore>
<book genre="autobiography">
<title>The Autobiography of Benjamin Franklin</title>
<author>
<first-name>Benjamin</first-name>
<last-name>Franklin</last-name>
</author>
<price>8.99</price>
</book>
<book genre="novel">
<title>The Confidence Man</title>
<author>
<first-name>Herman</first-name>
<last-name>Melville</last-name>
</author>
<price>11.99</price>
</book>
</bookstore>
Example 1xpathquery.exe bookstore.xml
Selects all the title elements that are children of the book element whose parent is the bookstore element, which returns:
<title>The Autobiography of Benjamin Franklin</title>
<title>The Confidence Man</title>xpathquery.exe bookstore.xml
Select all the genre attributes in the document and returns:
genre="autobiography"
genre="novel"xpathquery.exe bookstore.xml
Selects all the titles where the author's first name is "Herman" and returns:
<title>The Confidence Man</title>
However, once namespaces are added to the mix, things are no longer as simple. The file below is identical to the original file except for the addition of namespaces and one attribute to one of the book elements.
<bookstore xmlns="urn:xmlns:25hoursaday-com:bookstore">
<book genre="autobiography">
<title>The Autobiography of Benjamin Franklin</title>
<author>
<first-name>Benjamin</first-name>
<last-name>Franklin</last-name>
</author>
<price>8.99</price>
</book>
<bk:book genre="novel" bk:genre="fiction"
xmlns:bk="urn:xmlns:25hoursaday-com:bookstore">
<bk:title>The Confidence Man</bk:title>
<bk:author>
<bk:first-name>Herman</bk:first-name>
<bk:last-name>Melville</bk:last-name>
</bk:author>
<bk:price>11.99</bk:price>
</bk:book>
</bookstore>
Note that the default namespace is in scope for the whole XML document, while the namespace declaration that maps the prefix bk to the namespace name urn:xmlns:25hoursaday-com:bookstore is in scope for the second book element only. Example 2
xpathquery.exe bookstore.xml
Selects all the title elements that are children of the book element whose parent is the bookstore element, which returns NO RESULTS.
xpathquery.exe bookstore.xml
Selects all the genre attributes in the document and returns:
genre="autobiography"
genre="novel"
xpathquery.exe bookstore.xml
Selects all the titles where the author's first name is "Herman," which returns NO RESULTS.
The first query returns no results because unprefixed names in an XPath query apply to elements or attributes with no namespace. There are no bookstore, book, or title elements in the target document that have no namespace. The second query returns all attribute nodes that have no namespace. Although namespace declarations are in scope for both attribute nodes returned by the query, they have no namespace because namespace declarations do not apply to attributes with unprefixed names. The third query returns no results for the same reasons the first query returns no results.
The way to perform namespace-aware XPath queries is to provide a prefix to namespace mapping to the XPath engine, then use those prefixes in the query. The prefixes provided do not need to be the same as the namespace to prefix mappings in the target document, and they must be non-empty prefixes. Example 3
xpathquery.exe bookstore.xml
Select all the title elements that are children of the book element whose parent is the bookstore element and returns the following:
<title xmlns="urn:xmlns:25hoursaday-com:bookstore">The Autobiography of Benjamin Franklin</title>
<bk:title xmlns:bk="urn:xmlns:25hoursaday-com:bookstore"> The Confidence Man</bk:title>xpathquery.exe bookstore.xml
Selects all the genre attributes from the "urn:xmlns:25hoursaday-com:bookstore" namespace in the document that returns:
bk:genre="fiction"xpathquery.exe bookstore.xml
Selects all the titles where the author's first name is "Herman" and returns:
<bk:title xmlns:bk="urn:xmlns:25hoursaday-com:bookstore"> The Confidence Man</bk:title>
Note This last example is the same as the previous examples but rewritten to be namespace aware.
For more information on using XPath, read Aaron Skonnard's article Addressing Infosets with XPath and view the examples at the ZVON.org XPath tutorial.
XSLT and NamespacesThe W3C XSL transformations (XSLT) recommendation describes an XML-based language for transforming XML documents into other XML documents. XSLT transformations, also known as XML style sheets, utilize patterns (XPath) to match aspects of the target document. Upon matching nodes in the target document, templates that specify the output of a successful match can be instantiated and used to transform the document.
Support for namespaces is tightly integrated into XSLT, especially since XPath is used for matching nodes in the source document. Using namespaces in your XPath expressions inside XSLT is much easier than using the DOM.
The example that follows contains:
A program for use in executing transforms from the command line.
An XSLT stylesheet that prints all the title elements from the urn:xmlns:25hoursaday-com:bookstore namespace in the source XML document when run against the bookstore document from the urn:xmlns:25hoursaday-com:bookstore namespace.
The resulting output. Program Imports System.Xml.Xsl
-
Wow! Slashdotted Already?
This article explores the ins and outs of XML namespaces and their ramifications on a number of XML technologies that support namespaces. What follows is a shortened version of my first Extreme XML column.
Overview of XML NamespacesAs XML usage on the Internet became more widespread, the benefits of being able to create markup vocabularies that could be combined and reused similarly to how software modules are combined and reused became increasingly important. If a well defined markup vocabulary for describing coin collections, program configuration files, or fast food restaurant menus already existed, then reusing it made more sense than designing one from scratch. Combining multiple existing vocabularies to create new vocabularies whose whole was greater than the sum of its parts also became a feature that users of XML began to require.
However, the likelihood of identical markup, specifically XML elements and attributes, from different vocabularies with different semantics ending up in the same document became a problem. The very extensibility of XML and the fact that its usage had already become widespread across the Internet precluded simply specifying reserved elements or attribute names as the solution to this problem.
The goal of the W3C XML namespaces recommendation was to create a mechanism in which elements and attributes within an XML document that were from different markup vocabularies could be unambiguously identified and combined without processing problems ensuing. The XML namespaces recommendation provided a method for partitioning various items within an XML document based on processing requirements without placing undue restrictions on how these items should be named. For instance, elements named <template>, <output>, and <stylesheet> can occur in an XSLT stylesheet without there being ambiguity as to whether they are transformation directives or potential output of the transformation.
An XML namespace is a collection of names, identified by a Uniform Resource Identifier (URI) reference, which are used in XML documents as element and attribute names.
Namespace DeclarationsA namespace declaration is typically used to map a namespace URI to a specific prefix. The scope of the prefix-namespace mapping is that of the element that the namespace declaration occurs on as well as all its children. An attribute declaration that begins with the prefix xmlns: is a namespace declaration. The value of such an attribute declaration should be a namespace URI which is the namespace name.
Here is an example of an XML document where the root element contains a namespace declaration that maps the prefix bk to the namespace name urn:xmlns:25hoursaday-com:bookstore and its child element contains an inventory element that contains a namespace declaration that maps the prefix inv to the namespace name urn:xmlns:25hoursaday-com:inventory-tracking.
<bk:bookstore xmlns:bk="urn:xmlns:25hoursaday-com:bookstore">
<bk:book>
<bk:title>Lord of the Rings</bk:title>
<bk:author>J.R.R. Tolkien</bk:author>
<inv:inventory status="in-stock" isbn="0345340426"
xmlns:inv="urn:xmlns:25hoursaday-com:inventory-tra cking"
</bk:book>
</bk:bookstore>
In the above example, the scope of the namespace declaration for the urn:xmlns:25hoursaday-com:bookstore namespace name is the entire bk:bookstore element, while that of the urn:xmlns:25hoursaday-com:inventory-tracking is the inv:inventory element. Namespace aware processors can process items from both namespaces independently of each other, which leads to the ability to do multi-layered processing of XML documents. For instance, RDDL documents are valid XHTML documents that can be rendered by a Web browser but also contain information using elements from the http://www.rddl.org namespace that can be used to locate machine readable resources about the members of an XML namespace.
It should be noted that by definition the prefix xml is bound to the XML namespace name and this special namespace is automatically predeclared with document scope in every well-formed XML document.
Default NamespacesThe previous section on namespace declarations is not entirely complete because it leaves out default namespaces. A default namespace declaration is an attribute declaration that has the name xmlns and its value is the namespace URI that is the namespace name.
A default namespace declaration specifies that every unprefixed element name in its scope be from the declaring namespace. Below is the bookstore example utilizing a default namespace instead of a prefix-namespace mapping.
<bookstore xmlns="urn:xmlns:25hoursaday-com:bookstore">
<book>
<title>Lord of the Rings</bk:title>
<author>J.R.R. Tolkien</bk:author>
<inv:inventory status="in-stock" isbn="0345340426"
xmlns:inv="urn:xmlns:25hoursaday-com:inventory-tra cking"
</book>
</bookstore>
All the elements in the above example except for the inv:inventory element belong to the urn:xmlns:25hoursaday-com:bookstore namespace. The primary purpose of default namespaces is to reduce the verbosity of XML documents that utilize namespaces. However, using default namespaces instead of utilizing explicitly mapped prefixes for element names can be confusing because it is not obvious that the elements in the document are namespace scoped.
Also, unlike regular namespace declarations, default namespace declarations can be undeclared by setting the value of the xmlns attribute to the empty string. Undeclaring default namespace declarations is a practice that should be avoided because it may lead to a document that has unprefixed names that belong to a namespace in one part of the document, but don't in another. For example, in the document below only the bookstore element is from the urn:xmlns:25hoursaday-com:bookstore while the other unprefixed elements have no namespace name.
<bookstore xmlns="urn:xmlns:25hoursaday-com:bookstore">
<book xmlns="">
<title>Lord of the Rings</bk:title>
<author>J.R.R. Tolkien</bk:author>
<inv:inventory status="in-stock" isbn="0345340426"
xmlns:inv="urn:xmlns:25hoursaday-com:inventory-tra cking"
</book>
</bookstore>
This practice should be avoided because it leads to extremely confusing situations for readers of the XML document. For more information on undeclaring namespace declarations, see the section on Namespaces Future.
Qualified and Expanded NamesA qualified name, also known as a QName, is an XML name called the local name optionally preceded by another XML name called the prefix and a colon (':') character. The XML names used as the prefix and the local name must match the NCName production, which means that they must not contain a colon character. The prefix of a qualified name must have been mapped to a namespace URI through an in-scope namespace declaration mapping the prefix to the namespace URI. A qualified name can be used as either an attribute or element name.
Although QNames are important mnemonic guides to determining what namespace the elements and attributes within a document are derived from, they are rarely important to XML aware processors. For example, the following three XML documents would be treated identically by a range of XML technologies including, of course, XML schema validators.
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:complexType id="123" name="fooType"/>
</xs:schema>
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<xsd:complexType id="123" name="fooType"/>
</xsd:schema>
<schema xmlns="http://www.w3.org/2001/XMLSchema">
<complexType id="123" name="fooType"/>
</schema>
The W3C XML Path Language recommendation describes an expanded name as a pair consisting of a namespace name and a local name. A universal name is an alternate term coined by James Clark to describe the same concept. A universal name consists of a namespace name in curly braces and a local name. Namespaces tend to make more sense to people when viewed through the lens of universal names. Here are the three XML documents from the previous example with the QNames replaced by universal names. Note that the syntax below is not valid XML syntax.
<{http://www.w3.org/2001/XMLSchema}schema>&n bsp;
<{http://www.w3.org/2001/XMLSchema}complexType id="123" name="fooType"/>
</{http://www.w3.org/2001/XMLSchema}schema>
<{http://www.w3.org/2001/XMLSchema}schema>&n bsp;
<{http://www.w3.org/2001/XMLSchema}complexType id="123" name="fooType"/>
</{http://www.w3.org/2001/XMLSchema}schema>
<{http://www.w3.org/2001/XMLSchema}schema>&n bsp;
<{http://www.w3.org/2001/XMLSchema}complexType id="123" name="fooType"/>
</{http://www.w3.org/2001/XMLSchema}schema>
To many XML applications, the universal name of the elements and attributes in an XML document are what is important, and not the values of the prefixes used in specific QNames. The primary reason the Namespaces in XML recommendation does not take the expanded name approach to specifying namespaces is due to its verbosity. Instead, prefix mappings and default namespaces are provided to save us all from developing carpal tunnel syndrome from typing namespace URIs endlessly.
Namespaces and AttributesNamespace declarations do not apply to attributes unless the attribute's name is prefixed. In the XML document shown below the title attribute belongs to the bk:book element and has no namespace while the bk:title attribute has urn:xmlns:25hoursaday-com:bookstore as its namespace name. Note that even though both attributes have the same local name the document is well formed.
<bk:bookstore xmlns:bk="urn:xmlns:25hoursaday-com:bookstore">
<bk:book title="Lord of the Rings, Book 3" bk:title="Return of the King"/>
</bk:bookstore>
In the following example, the title attribute still has no namespace and belongs the book element even though there is a default namespace specified. In other words, attributes cannot inherit the default namespace.
<bookstore xmlns="urn:xmlns:25hoursaday-com:bookstore">
<book title="Lord of the Rings, Book 3"
</bookstore>
Namespace URIsA namespace name is a Uniform Resource Identifier (URI) as specified in RFC 2396. A URI is either a Uniform Resource Locators (URLs) or a Uniform Resource Names (URNs). URLs are used to specify the location of resources on the Internet, while URNs are supposed to be persistent, location-independent identifiers for information resources. Namespace names are considered to be identical only if they are the same character for character (case-sensitive). The primary justification for using URIs as namespace names is that they already provide a mechanism for specifying globally unique identities.
The XML namespaces recommendation states that namespace names are only to act as unique identifiers and do not have to actually identify network retrievable resources. This has led to much confusion amongst authors and users of XML documents, especially since the usage of HTTP based URLs as namespace names has grown in popularity. Because many applications convert such URIs to hyperlinks, it is irritating to many users that these "links" do not lead to Web pages or other network retrievable resource. I remember one user who likened it to being given a fake phone number in a social situation.
One solution to avoid confusing users is to use a namespace-naming schema that does not imply network retrievability of the resource. I personally use the urn:xmlns: scheme for this purpose and create namespace names similar to urn:xmlns:25hoursaday-com when authoring XML documents for personal use. The problem with homegrown namespace URIs is that they may run counter to the intent of the Names in XML recommendation by not being globally unique. I get around the globally unique requirement by using my personal domain name http://www.25hoursaday.com as part of the namespace URI.
Another solution is to leave a network retrievable resource at the URI that is the namespace name, such as is done with the XSLT and RDDL namespaces. Typically, such URIs are actually HTTP URLs. A good way to name such URLs is by using the format favored by the W3C, which is as follows:
http://my.domain.example.org/product/[year/month][ / rea]
See the section on Namespaces and Versioning for more information on using similarly structured namespace names as a versioning mechanism.
DOM, XPath, and the XML Information Set on NamespacesThe W3C has defined a number of technologies that provide a data model for XML documents. These data models are generally in agreement, but sometimes differ in how they treat various edge cases due to historic reasons. Treatment of XML namespaces and namespace declarations is an example of an edge case that is treated differently in the three primary data models that exist as W3C recommendations. The three data models are the XPath data model, the Document Object Model (DOM), and the XML information set.
The XML information set (XML infoset) is an abstract description of the data in an XML document and can be considered to be the primary data model for an XML document. The XPath data model is a tree-based model that is traversed when querying an XML document and is similar to the XML information set. The DOM precedes both data models but is also similar to both data models in a number of ways. Both the DOM and the XPath data model can be considered to be interpretations of the XML infoset.
Namespaces in the Document Object Model (DOM)The XML namespace section of the DOM Level 3 specification considers namespace declarations to be regular attribute nodes that have http://www.w3.org/2000/xmlns/ as their namespace name and xmlns as their prefix or qualified name.
Elements and attributes in the DOM have a namespace name that cannot be altered after they have been created regardless of whether their location within the document changes or not.
Namespaces in the XPath Data ModelThe W3C XPath recommendation does not consider namespace declarations to be attribute nodes and does not provide access to them in that capacity. Instead, in XPath every element in an XML document has a number of namespace nodes that can be retrieved using the XPath namespace navigation axis.
Each element in the document has a unique set of namespace nodes for each namespace declaration in scope for that particular element. Namespace nodes are unique to each element in that namespace. Thus namespace nodes for two different elements that represent the same namespace declaration are not identical.
Namespaces in the XML Information SetThe XML infoset recommendation considers namespace declarations to be attribute information items.
In addition, similar to the XPath data model, each element information item in an XML document's information set has a namespace information item for each namespace that is in scope for the element.
XPath, XSLT and NamespacesThe W3C XML Path Language also known as XPath is used to address parts of an XML document and is used in a number of W3C XML technologies including XSLT, XPointer, XML Schema, and DOM Level 3. XPath uses a hierarchical addressing mechanism similar to that used in file systems and URLs to retrieve pieces of an XML document. XPath supports rudimentary manipulation of strings, numbers, and Booleans.
XPath and NamespacesThe XPath data model treats an XML document as a tree of nodes, such as element, attribute, and text nodes, where the name of each node is a combination of its local name and its namespace name (that is, its universal or expanded name).
For element and attribute nodes without namespaces, performing XPath queries is fairly straightforward. The following program, which can be used to query XML documents using the command line, shall be used to demonstrate the impact of namespaces on XPath queries.
using System.Xml.XPath;
using System.Xml;
using System;
using System.IO;
class XPathQuery{
public static string PrintError(Exception e, string errStr){
if(e == null)
return errStr;
else
return PrintError(e.InnerException, errStr + e.Message );
}
public static void Main(string[] args){
if((args.Length == 0) || (args.Length % 2)!= 0){
Console.WriteLine("Usage: xpathquery source query <zero or more
prefix and namespace pairs>");
return;
}
try{
XmlDocument doc = new XmlDocument();
doc.Load(args[0]);
XmlNamespaceManager nsMgr = new XmlNamespaceManager(doc.NameTable);
for(int i=2; i < args.Length; i+= 2)
nsMgr.AddNamespace(args[i], args[i + 1]);
XmlNodeList nodes = doc.SelectNodes(args[1], nsMgr);
foreach(XmlNode node in nodes)
Console.WriteLine(node.OuterXml + "\n\n");
}catch(XmlException xmle){
Console.WriteLine("ERROR: XML Parse error occured because " +
PrintError(xmle, null));
}catch(FileNotFoundException fnfe){
Console.WriteLine("ERROR: " + PrintError(fnfe, null));
}catch(XPathException xpath){
Console.WriteLine("ERROR: The following error occured while querying
the document: "
&n bsp; + PrintError(xpath, null));
}catch(Exception e){
Console.WriteLine("UNEXPECTED ERROR" + PrintError(e, null));
}
}
}
Given the following XML document that does not declare any namespaces, queries are fairly straightforward as seen in the examples following the code.
<?xml version="1.0" encoding="utf-8" ?>
<bookstore>
<book genre="autobiography">
<title>The Autobiography of Benjamin Franklin</title>
<author>
<first-name>Benjamin</first-name>
<last-name>Franklin</last-name>
</author>
<price>8.99</price>
</book>
<book genre="novel">
<title>The Confidence Man</title>
<author>
<first-name>Herman</first-name>
<last-name>Melville</last-name>
</author>
<price>11.99</price>
</book>
</bookstore>
Example 1xpathquery.exe bookstore.xml
Selects all the title elements that are children of the book element whose parent is the bookstore element, which returns:
<title>The Autobiography of Benjamin Franklin</title>
<title>The Confidence Man</title>xpathquery.exe bookstore.xml
Select all the genre attributes in the document and returns:
genre="autobiography"
genre="novel"xpathquery.exe bookstore.xml
Selects all the titles where the author's first name is "Herman" and returns:
<title>The Confidence Man</title>
However, once namespaces are added to the mix, things are no longer as simple. The file below is identical to the original file except for the addition of namespaces and one attribute to one of the book elements.
<bookstore xmlns="urn:xmlns:25hoursaday-com:bookstore">
<book genre="autobiography">
<title>The Autobiography of Benjamin Franklin</title>
<author>
<first-name>Benjamin</first-name>
<last-name>Franklin</last-name>
</author>
<price>8.99</price>
</book>
<bk:book genre="novel" bk:genre="fiction"
xmlns:bk="urn:xmlns:25hoursaday-com:bookstore">
<bk:title>The Confidence Man</bk:title>
<bk:author>
<bk:first-name>Herman</bk:first-name>
<bk:last-name>Melville</bk:last-name>
</bk:author>
<bk:price>11.99</bk:price>
</bk:book>
</bookstore>
Note that the default namespace is in scope for the whole XML document, while the namespace declaration that maps the prefix bk to the namespace name urn:xmlns:25hoursaday-com:bookstore is in scope for the second book element only. Example 2
xpathquery.exe bookstore.xml
Selects all the title elements that are children of the book element whose parent is the bookstore element, which returns NO RESULTS.
xpathquery.exe bookstore.xml
Selects all the genre attributes in the document and returns:
genre="autobiography"
genre="novel"
xpathquery.exe bookstore.xml
Selects all the titles where the author's first name is "Herman," which returns NO RESULTS.
The first query returns no results because unprefixed names in an XPath query apply to elements or attributes with no namespace. There are no bookstore, book, or title elements in the target document that have no namespace. The second query returns all attribute nodes that have no namespace. Although namespace declarations are in scope for both attribute nodes returned by the query, they have no namespace because namespace declarations do not apply to attributes with unprefixed names. The third query returns no results for the same reasons the first query returns no results.
The way to perform namespace-aware XPath queries is to provide a prefix to namespace mapping to the XPath engine, then use those prefixes in the query. The prefixes provided do not need to be the same as the namespace to prefix mappings in the target document, and they must be non-empty prefixes. Example 3
xpathquery.exe bookstore.xml
Select all the title elements that are children of the book element whose parent is the bookstore element and returns the following:
<title xmlns="urn:xmlns:25hoursaday-com:bookstore">The Autobiography of Benjamin Franklin</title>
<bk:title xmlns:bk="urn:xmlns:25hoursaday-com:bookstore"> The Confidence Man</bk:title>xpathquery.exe bookstore.xml
Selects all the genre attributes from the "urn:xmlns:25hoursaday-com:bookstore" namespace in the document that returns:
bk:genre="fiction"xpathquery.exe bookstore.xml
Selects all the titles where the author's first name is "Herman" and returns:
<bk:title xmlns:bk="urn:xmlns:25hoursaday-com:bookstore"> The Confidence Man</bk:title>
Note This last example is the same as the previous examples but rewritten to be namespace aware.
For more information on using XPath, read Aaron Skonnard's article Addressing Infosets with XPath and view the examples at the ZVON.org XPath tutorial.
XSLT and NamespacesThe W3C XSL transformations (XSLT) recommendation describes an XML-based language for transforming XML documents into other XML documents. XSLT transformations, also known as XML style sheets, utilize patterns (XPath) to match aspects of the target document. Upon matching nodes in the target document, templates that specify the output of a successful match can be instantiated and used to transform the document.
Support for namespaces is tightly integrated into XSLT, especially since XPath is used for matching nodes in the source document. Using namespaces in your XPath expressions inside XSLT is much easier than using the DOM.
The example that follows contains:
A program for use in executing transforms from the command line.
An XSLT stylesheet that prints all the title elements from the urn:xmlns:25hoursaday-com:bookstore namespace in the source XML document when run against the bookstore document from the urn:xmlns:25hoursaday-com:bookstore namespace.
The resulting output. Program Imports System.Xml.Xsl
-
Wow! Slashdotted Already?
This article explores the ins and outs of XML namespaces and their ramifications on a number of XML technologies that support namespaces. What follows is a shortened version of my first Extreme XML column.
Overview of XML NamespacesAs XML usage on the Internet became more widespread, the benefits of being able to create markup vocabularies that could be combined and reused similarly to how software modules are combined and reused became increasingly important. If a well defined markup vocabulary for describing coin collections, program configuration files, or fast food restaurant menus already existed, then reusing it made more sense than designing one from scratch. Combining multiple existing vocabularies to create new vocabularies whose whole was greater than the sum of its parts also became a feature that users of XML began to require.
However, the likelihood of identical markup, specifically XML elements and attributes, from different vocabularies with different semantics ending up in the same document became a problem. The very extensibility of XML and the fact that its usage had already become widespread across the Internet precluded simply specifying reserved elements or attribute names as the solution to this problem.
The goal of the W3C XML namespaces recommendation was to create a mechanism in which elements and attributes within an XML document that were from different markup vocabularies could be unambiguously identified and combined without processing problems ensuing. The XML namespaces recommendation provided a method for partitioning various items within an XML document based on processing requirements without placing undue restrictions on how these items should be named. For instance, elements named <template>, <output>, and <stylesheet> can occur in an XSLT stylesheet without there being ambiguity as to whether they are transformation directives or potential output of the transformation.
An XML namespace is a collection of names, identified by a Uniform Resource Identifier (URI) reference, which are used in XML documents as element and attribute names.
Namespace DeclarationsA namespace declaration is typically used to map a namespace URI to a specific prefix. The scope of the prefix-namespace mapping is that of the element that the namespace declaration occurs on as well as all its children. An attribute declaration that begins with the prefix xmlns: is a namespace declaration. The value of such an attribute declaration should be a namespace URI which is the namespace name.
Here is an example of an XML document where the root element contains a namespace declaration that maps the prefix bk to the namespace name urn:xmlns:25hoursaday-com:bookstore and its child element contains an inventory element that contains a namespace declaration that maps the prefix inv to the namespace name urn:xmlns:25hoursaday-com:inventory-tracking.
<bk:bookstore xmlns:bk="urn:xmlns:25hoursaday-com:bookstore">
<bk:book>
<bk:title>Lord of the Rings</bk:title>
<bk:author>J.R.R. Tolkien</bk:author>
<inv:inventory status="in-stock" isbn="0345340426"
xmlns:inv="urn:xmlns:25hoursaday-com:inventory-tra cking"
</bk:book>
</bk:bookstore>
In the above example, the scope of the namespace declaration for the urn:xmlns:25hoursaday-com:bookstore namespace name is the entire bk:bookstore element, while that of the urn:xmlns:25hoursaday-com:inventory-tracking is the inv:inventory element. Namespace aware processors can process items from both namespaces independently of each other, which leads to the ability to do multi-layered processing of XML documents. For instance, RDDL documents are valid XHTML documents that can be rendered by a Web browser but also contain information using elements from the http://www.rddl.org namespace that can be used to locate machine readable resources about the members of an XML namespace.
It should be noted that by definition the prefix xml is bound to the XML namespace name and this special namespace is automatically predeclared with document scope in every well-formed XML document.
Default NamespacesThe previous section on namespace declarations is not entirely complete because it leaves out default namespaces. A default namespace declaration is an attribute declaration that has the name xmlns and its value is the namespace URI that is the namespace name.
A default namespace declaration specifies that every unprefixed element name in its scope be from the declaring namespace. Below is the bookstore example utilizing a default namespace instead of a prefix-namespace mapping.
<bookstore xmlns="urn:xmlns:25hoursaday-com:bookstore">
<book>
<title>Lord of the Rings</bk:title>
<author>J.R.R. Tolkien</bk:author>
<inv:inventory status="in-stock" isbn="0345340426"
xmlns:inv="urn:xmlns:25hoursaday-com:inventory-tra cking"
</book>
</bookstore>
All the elements in the above example except for the inv:inventory element belong to the urn:xmlns:25hoursaday-com:bookstore namespace. The primary purpose of default namespaces is to reduce the verbosity of XML documents that utilize namespaces. However, using default namespaces instead of utilizing explicitly mapped prefixes for element names can be confusing because it is not obvious that the elements in the document are namespace scoped.
Also, unlike regular namespace declarations, default namespace declarations can be undeclared by setting the value of the xmlns attribute to the empty string. Undeclaring default namespace declarations is a practice that should be avoided because it may lead to a document that has unprefixed names that belong to a namespace in one part of the document, but don't in another. For example, in the document below only the bookstore element is from the urn:xmlns:25hoursaday-com:bookstore while the other unprefixed elements have no namespace name.
<bookstore xmlns="urn:xmlns:25hoursaday-com:bookstore">
<book xmlns="">
<title>Lord of the Rings</bk:title>
<author>J.R.R. Tolkien</bk:author>
<inv:inventory status="in-stock" isbn="0345340426"
xmlns:inv="urn:xmlns:25hoursaday-com:inventory-tra cking"
</book>
</bookstore>
This practice should be avoided because it leads to extremely confusing situations for readers of the XML document. For more information on undeclaring namespace declarations, see the section on Namespaces Future.
Qualified and Expanded NamesA qualified name, also known as a QName, is an XML name called the local name optionally preceded by another XML name called the prefix and a colon (':') character. The XML names used as the prefix and the local name must match the NCName production, which means that they must not contain a colon character. The prefix of a qualified name must have been mapped to a namespace URI through an in-scope namespace declaration mapping the prefix to the namespace URI. A qualified name can be used as either an attribute or element name.
Although QNames are important mnemonic guides to determining what namespace the elements and attributes within a document are derived from, they are rarely important to XML aware processors. For example, the following three XML documents would be treated identically by a range of XML technologies including, of course, XML schema validators.
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:complexType id="123" name="fooType"/>
</xs:schema>
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<xsd:complexType id="123" name="fooType"/>
</xsd:schema>
<schema xmlns="http://www.w3.org/2001/XMLSchema">
<complexType id="123" name="fooType"/>
</schema>
The W3C XML Path Language recommendation describes an expanded name as a pair consisting of a namespace name and a local name. A universal name is an alternate term coined by James Clark to describe the same concept. A universal name consists of a namespace name in curly braces and a local name. Namespaces tend to make more sense to people when viewed through the lens of universal names. Here are the three XML documents from the previous example with the QNames replaced by universal names. Note that the syntax below is not valid XML syntax.
<{http://www.w3.org/2001/XMLSchema}schema>&n bsp;
<{http://www.w3.org/2001/XMLSchema}complexType id="123" name="fooType"/>
</{http://www.w3.org/2001/XMLSchema}schema>
<{http://www.w3.org/2001/XMLSchema}schema>&n bsp;
<{http://www.w3.org/2001/XMLSchema}complexType id="123" name="fooType"/>
</{http://www.w3.org/2001/XMLSchema}schema>
<{http://www.w3.org/2001/XMLSchema}schema>&n bsp;
<{http://www.w3.org/2001/XMLSchema}complexType id="123" name="fooType"/>
</{http://www.w3.org/2001/XMLSchema}schema>
To many XML applications, the universal name of the elements and attributes in an XML document are what is important, and not the values of the prefixes used in specific QNames. The primary reason the Namespaces in XML recommendation does not take the expanded name approach to specifying namespaces is due to its verbosity. Instead, prefix mappings and default namespaces are provided to save us all from developing carpal tunnel syndrome from typing namespace URIs endlessly.
Namespaces and AttributesNamespace declarations do not apply to attributes unless the attribute's name is prefixed. In the XML document shown below the title attribute belongs to the bk:book element and has no namespace while the bk:title attribute has urn:xmlns:25hoursaday-com:bookstore as its namespace name. Note that even though both attributes have the same local name the document is well formed.
<bk:bookstore xmlns:bk="urn:xmlns:25hoursaday-com:bookstore">
<bk:book title="Lord of the Rings, Book 3" bk:title="Return of the King"/>
</bk:bookstore>
In the following example, the title attribute still has no namespace and belongs the book element even though there is a default namespace specified. In other words, attributes cannot inherit the default namespace.
<bookstore xmlns="urn:xmlns:25hoursaday-com:bookstore">
<book title="Lord of the Rings, Book 3"
</bookstore>
Namespace URIsA namespace name is a Uniform Resource Identifier (URI) as specified in RFC 2396. A URI is either a Uniform Resource Locators (URLs) or a Uniform Resource Names (URNs). URLs are used to specify the location of resources on the Internet, while URNs are supposed to be persistent, location-independent identifiers for information resources. Namespace names are considered to be identical only if they are the same character for character (case-sensitive). The primary justification for using URIs as namespace names is that they already provide a mechanism for specifying globally unique identities.
The XML namespaces recommendation states that namespace names are only to act as unique identifiers and do not have to actually identify network retrievable resources. This has led to much confusion amongst authors and users of XML documents, especially since the usage of HTTP based URLs as namespace names has grown in popularity. Because many applications convert such URIs to hyperlinks, it is irritating to many users that these "links" do not lead to Web pages or other network retrievable resource. I remember one user who likened it to being given a fake phone number in a social situation.
One solution to avoid confusing users is to use a namespace-naming schema that does not imply network retrievability of the resource. I personally use the urn:xmlns: scheme for this purpose and create namespace names similar to urn:xmlns:25hoursaday-com when authoring XML documents for personal use. The problem with homegrown namespace URIs is that they may run counter to the intent of the Names in XML recommendation by not being globally unique. I get around the globally unique requirement by using my personal domain name http://www.25hoursaday.com as part of the namespace URI.
Another solution is to leave a network retrievable resource at the URI that is the namespace name, such as is done with the XSLT and RDDL namespaces. Typically, such URIs are actually HTTP URLs. A good way to name such URLs is by using the format favored by the W3C, which is as follows:
http://my.domain.example.org/product/[year/month][ / rea]
See the section on Namespaces and Versioning for more information on using similarly structured namespace names as a versioning mechanism.
DOM, XPath, and the XML Information Set on NamespacesThe W3C has defined a number of technologies that provide a data model for XML documents. These data models are generally in agreement, but sometimes differ in how they treat various edge cases due to historic reasons. Treatment of XML namespaces and namespace declarations is an example of an edge case that is treated differently in the three primary data models that exist as W3C recommendations. The three data models are the XPath data model, the Document Object Model (DOM), and the XML information set.
The XML information set (XML infoset) is an abstract description of the data in an XML document and can be considered to be the primary data model for an XML document. The XPath data model is a tree-based model that is traversed when querying an XML document and is similar to the XML information set. The DOM precedes both data models but is also similar to both data models in a number of ways. Both the DOM and the XPath data model can be considered to be interpretations of the XML infoset.
Namespaces in the Document Object Model (DOM)The XML namespace section of the DOM Level 3 specification considers namespace declarations to be regular attribute nodes that have http://www.w3.org/2000/xmlns/ as their namespace name and xmlns as their prefix or qualified name.
Elements and attributes in the DOM have a namespace name that cannot be altered after they have been created regardless of whether their location within the document changes or not.
Namespaces in the XPath Data ModelThe W3C XPath recommendation does not consider namespace declarations to be attribute nodes and does not provide access to them in that capacity. Instead, in XPath every element in an XML document has a number of namespace nodes that can be retrieved using the XPath namespace navigation axis.
Each element in the document has a unique set of namespace nodes for each namespace declaration in scope for that particular element. Namespace nodes are unique to each element in that namespace. Thus namespace nodes for two different elements that represent the same namespace declaration are not identical.
Namespaces in the XML Information SetThe XML infoset recommendation considers namespace declarations to be attribute information items.
In addition, similar to the XPath data model, each element information item in an XML document's information set has a namespace information item for each namespace that is in scope for the element.
XPath, XSLT and NamespacesThe W3C XML Path Language also known as XPath is used to address parts of an XML document and is used in a number of W3C XML technologies including XSLT, XPointer, XML Schema, and DOM Level 3. XPath uses a hierarchical addressing mechanism similar to that used in file systems and URLs to retrieve pieces of an XML document. XPath supports rudimentary manipulation of strings, numbers, and Booleans.
XPath and NamespacesThe XPath data model treats an XML document as a tree of nodes, such as element, attribute, and text nodes, where the name of each node is a combination of its local name and its namespace name (that is, its universal or expanded name).
For element and attribute nodes without namespaces, performing XPath queries is fairly straightforward. The following program, which can be used to query XML documents using the command line, shall be used to demonstrate the impact of namespaces on XPath queries.
using System.Xml.XPath;
using System.Xml;
using System;
using System.IO;
class XPathQuery{
public static string PrintError(Exception e, string errStr){
if(e == null)
return errStr;
else
return PrintError(e.InnerException, errStr + e.Message );
}
public static void Main(string[] args){
if((args.Length == 0) || (args.Length % 2)!= 0){
Console.WriteLine("Usage: xpathquery source query <zero or more
prefix and namespace pairs>");
return;
}
try{
XmlDocument doc = new XmlDocument();
doc.Load(args[0]);
XmlNamespaceManager nsMgr = new XmlNamespaceManager(doc.NameTable);
for(int i=2; i < args.Length; i+= 2)
nsMgr.AddNamespace(args[i], args[i + 1]);
XmlNodeList nodes = doc.SelectNodes(args[1], nsMgr);
foreach(XmlNode node in nodes)
Console.WriteLine(node.OuterXml + "\n\n");
}catch(XmlException xmle){
Console.WriteLine("ERROR: XML Parse error occured because " +
PrintError(xmle, null));
}catch(FileNotFoundException fnfe){
Console.WriteLine("ERROR: " + PrintError(fnfe, null));
}catch(XPathException xpath){
Console.WriteLine("ERROR: The following error occured while querying
the document: "
&n bsp; + PrintError(xpath, null));
}catch(Exception e){
Console.WriteLine("UNEXPECTED ERROR" + PrintError(e, null));
}
}
}
Given the following XML document that does not declare any namespaces, queries are fairly straightforward as seen in the examples following the code.
<?xml version="1.0" encoding="utf-8" ?>
<bookstore>
<book genre="autobiography">
<title>The Autobiography of Benjamin Franklin</title>
<author>
<first-name>Benjamin</first-name>
<last-name>Franklin</last-name>
</author>
<price>8.99</price>
</book>
<book genre="novel">
<title>The Confidence Man</title>
<author>
<first-name>Herman</first-name>
<last-name>Melville</last-name>
</author>
<price>11.99</price>
</book>
</bookstore>
Example 1xpathquery.exe bookstore.xml
Selects all the title elements that are children of the book element whose parent is the bookstore element, which returns:
<title>The Autobiography of Benjamin Franklin</title>
<title>The Confidence Man</title>xpathquery.exe bookstore.xml
Select all the genre attributes in the document and returns:
genre="autobiography"
genre="novel"xpathquery.exe bookstore.xml
Selects all the titles where the author's first name is "Herman" and returns:
<title>The Confidence Man</title>
However, once namespaces are added to the mix, things are no longer as simple. The file below is identical to the original file except for the addition of namespaces and one attribute to one of the book elements.
<bookstore xmlns="urn:xmlns:25hoursaday-com:bookstore">
<book genre="autobiography">
<title>The Autobiography of Benjamin Franklin</title>
<author>
<first-name>Benjamin</first-name>
<last-name>Franklin</last-name>
</author>
<price>8.99</price>
</book>
<bk:book genre="novel" bk:genre="fiction"
xmlns:bk="urn:xmlns:25hoursaday-com:bookstore">
<bk:title>The Confidence Man</bk:title>
<bk:author>
<bk:first-name>Herman</bk:first-name>
<bk:last-name>Melville</bk:last-name>
</bk:author>
<bk:price>11.99</bk:price>
</bk:book>
</bookstore>
Note that the default namespace is in scope for the whole XML document, while the namespace declaration that maps the prefix bk to the namespace name urn:xmlns:25hoursaday-com:bookstore is in scope for the second book element only. Example 2
xpathquery.exe bookstore.xml
Selects all the title elements that are children of the book element whose parent is the bookstore element, which returns NO RESULTS.
xpathquery.exe bookstore.xml
Selects all the genre attributes in the document and returns:
genre="autobiography"
genre="novel"
xpathquery.exe bookstore.xml
Selects all the titles where the author's first name is "Herman," which returns NO RESULTS.
The first query returns no results because unprefixed names in an XPath query apply to elements or attributes with no namespace. There are no bookstore, book, or title elements in the target document that have no namespace. The second query returns all attribute nodes that have no namespace. Although namespace declarations are in scope for both attribute nodes returned by the query, they have no namespace because namespace declarations do not apply to attributes with unprefixed names. The third query returns no results for the same reasons the first query returns no results.
The way to perform namespace-aware XPath queries is to provide a prefix to namespace mapping to the XPath engine, then use those prefixes in the query. The prefixes provided do not need to be the same as the namespace to prefix mappings in the target document, and they must be non-empty prefixes. Example 3
xpathquery.exe bookstore.xml
Select all the title elements that are children of the book element whose parent is the bookstore element and returns the following:
<title xmlns="urn:xmlns:25hoursaday-com:bookstore">The Autobiography of Benjamin Franklin</title>
<bk:title xmlns:bk="urn:xmlns:25hoursaday-com:bookstore"> The Confidence Man</bk:title>xpathquery.exe bookstore.xml
Selects all the genre attributes from the "urn:xmlns:25hoursaday-com:bookstore" namespace in the document that returns:
bk:genre="fiction"xpathquery.exe bookstore.xml
Selects all the titles where the author's first name is "Herman" and returns:
<bk:title xmlns:bk="urn:xmlns:25hoursaday-com:bookstore"> The Confidence Man</bk:title>
Note This last example is the same as the previous examples but rewritten to be namespace aware.
For more information on using XPath, read Aaron Skonnard's article Addressing Infosets with XPath and view the examples at the ZVON.org XPath tutorial.
XSLT and NamespacesThe W3C XSL transformations (XSLT) recommendation describes an XML-based language for transforming XML documents into other XML documents. XSLT transformations, also known as XML style sheets, utilize patterns (XPath) to match aspects of the target document. Upon matching nodes in the target document, templates that specify the output of a successful match can be instantiated and used to transform the document.
Support for namespaces is tightly integrated into XSLT, especially since XPath is used for matching nodes in the source document. Using namespaces in your XPath expressions inside XSLT is much easier than using the DOM.
The example that follows contains:
A program for use in executing transforms from the command line.
An XSLT stylesheet that prints all the title elements from the urn:xmlns:25hoursaday-com:bookstore namespace in the source XML document when run against the bookstore document from the urn:xmlns:25hoursaday-com:bookstore namespace.
The resulting output. Program Imports System.Xml.Xsl
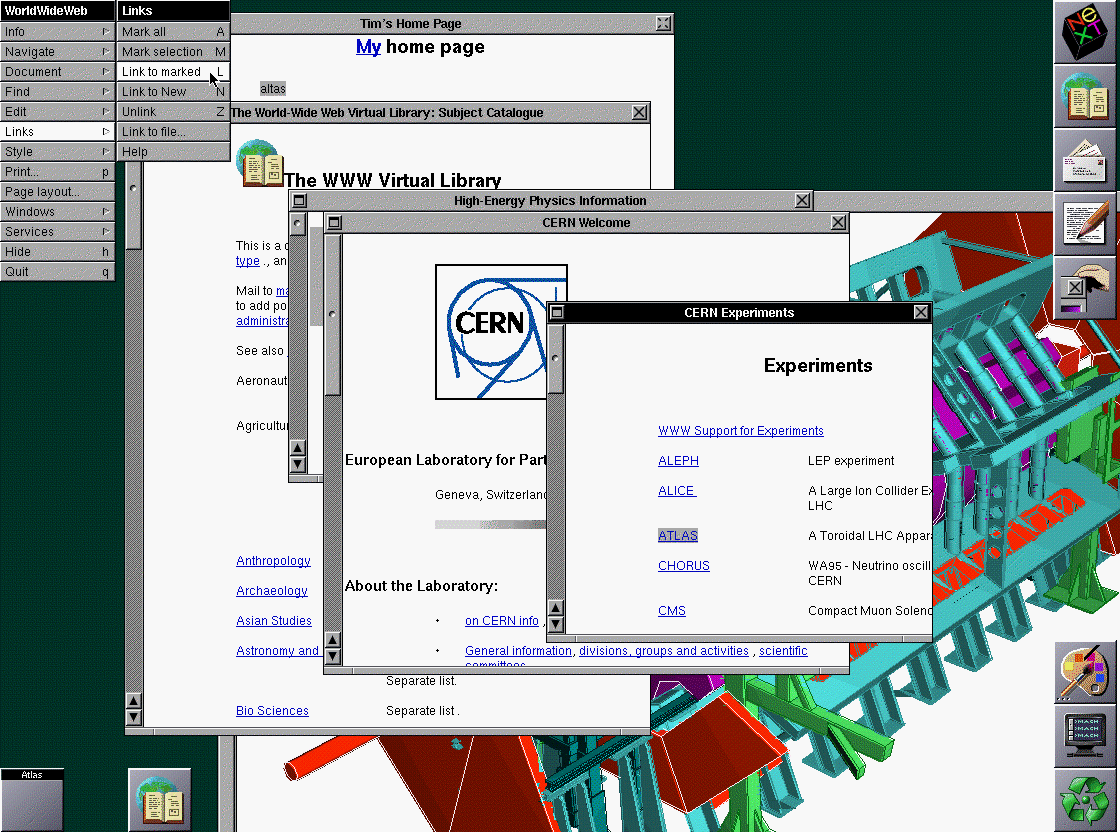{kind=link}