 Slashdot Mirror
Slashdot Mirror
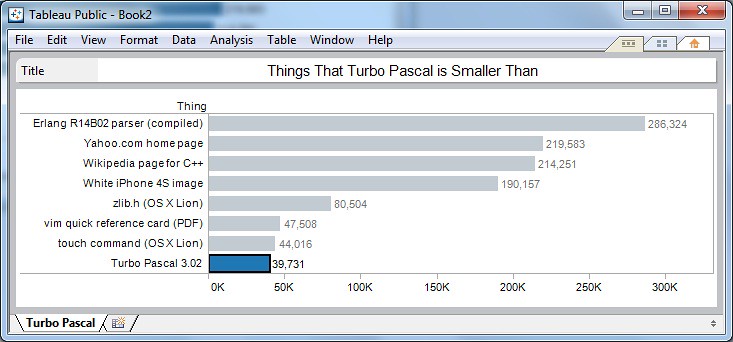
Things That Turbo Pascal Is Smaller Than
theodp writes "James Hague has compiled a short list of things that the circa-1986 Turbo Pascal 3 for MS-DOS is smaller than (chart). For starters, at 39,731 bytes, the entire Turbo Pascal 3.02 executable (compiler and IDE) makes it less than 1/4th the size of the image of the white iPhone 4S at apple.com (190,157 bytes), and less than 1/5th the size of the yahoo.com home page (219,583 bytes). Speaking of slim-and-trim software, Visicalc, the granddaddy of all spreadsheet software which celebrated its 32nd birthday this year, weighed in at a mere 29K."
{kind=link}
Visicalc was the first killer app as well. I remember people coming into the store and asking for Visicalc computers not knowing it was a program that ran on an Apple II.
When I think back to playing vast adventure games, like Below the Root, that amazingly fit on two sides of a 5.25" floppy, but the same game now would probably be written to take up a CD-ROM, even using the same graphics. Programmers have lost the ability to optimize.
I think they have the hability (some of them at least) but don't have the need or the time.
Sig? Heil
But under 'C' it felt somehow very natural and easy to understand, never had a problem with 'C' pointers, and data structures. R.I.P. DMR, your book really opened my eyes to the wonderful world of computing.
for the last time people, I am "frodo from middle eaRTH", not "middle eaST".
Back in my day we had Basic running on a 2K altair. Kids these days don't know the meaning of a kilobyte.
Some drink at the fountain of knowledge. Others just gargle.
Bytes are kind of weird. Can't they give these number in terms of Library of Congress?
More Twoson than Cupertino
First thing that comes to mind is: so what? This whole argument that smaller is better is crap. The reason that software is bigger these days is that it does more for you. How productive was the GUI for Turbo Pascal (it sucked), how good were the other tools that came with it (nonexistent), how fast were the release cycles (about the same as today). So with what people call bloat we get better tools that make us more productive thereby driving down the cost of software development.
Or to put it another way: if you really don't like bloat, when are you going to trade in your car and start driving to work in a hot wheels?
Why doesn't Slashdot ever get slashdotted?
The ability and the need (programmers of embedded systems may be an exception).
That and dedicated TV games, which commonly use an architecture not unlike that of the Nintendo Entertainment System. New games are still being developed for the NES, and many are roughly the size of Turbo Pascal or smaller.
Software grows to fill the available ram.
Code is always a tradeoff between codesize, development time and ram needed for execution. I'm fairly sure you can optimize code today to a point that would put those programs (which were optimized 'til they squeaked to squeeze out that last bit of performance) to shame, but why? What for? 30 years ago, needing a kilobyte of ram less was the make or break question. When drivers weighed in the 10kb range and you still calculated which ones you absolutely need to load for the programs you plan to run, where you turned off anything and everything to get those extra 2 kb to make the program run. Today, needing a few megabytes of ram more is no serious issue. And mostly because it just really doesn't matter anymore. Do you care whether that driver, that program, that tool needs a megabyte more to run? Do you cancel it because it does? No. Because it just doesn't matter.
We passed the point where "normal" people care about execution speed a while ago. Does it matter whether your spreadsheet needs 2 milliseconds longer to calculate the results? I mean, instead of 0.2 you now need 0.202 seconds, do you notice? Do you care? Today, you can waste processing time on animating cursors and create colorful file copy animations. Why bother with optimization?
Because, and that's the key here, optimizing code takes time. And that costs money. Why should anyone optimize code if there's really no need for it anymore? And it's not the "lazy programmers" or the studios that don't care about the customers. The customers don't care! And with good reason they don't. They do care about the program being delivered on time and for a reasonable price, but they don't care whether it needs a meg more of ram. Because it just friggin' doesn't matter anymore!
So yes, yes, programs back in the good ol' days were so much better organized and they used ram so much better, they had so much niftier tricks to conserve ram and processing time, but in the end, it just doesn't matter anymore today. You have more ram and processing power than your ordinary office program could ever use. Why bother with optimization?
We used to have a Bill of Rights. Now, with the rights gone, all we have left is the bill.
In my first job, I was responsible for developing a programming environment for a Pascal-like language that included a visual editor, interpreter and debugger. I remember my boss showing up in my office and showing me an ad he had cooked up, with big, bold lettering saying "Runs in 256 kB!"
As a young developer, it was one of the tougher moments in my life to admit that we were going to need a full 512 kB.
It was difficult living in a world where Turbo Pascal ran comfortably on a 64 kB machine.
How easily we overlook the difference between "bloated" and "quantity of useful information".
Just the words on this page (no markup, no graphics, and after a few comments) would have exceeded the capacity of your beloved 5-1/4 floppy. That's only the raw information, without bloat.
My first screen (a DECScope) had 12 lines x 80 columns each (I couldn't afford the 2K RAM that would have given me 24 x 80.) The screen I'm reading this on can display over 2 million RGB pixels. Calling things "bloat" is like telling me I should honor a display that's less than the size of the "close [X]" icon, because 12x80 isn't "bloat".
By the same twisted logic, Turbo Pascal itself was bloatware, and I thought it produced horribly slow and big code. Assemblers were where the real efficiency lay, and they were a lot smaller than 39K.
Nostalgia is fine. But leave it in the past.
John
Sorry, your post went a little south with the Vista debacle. Because MS had to fast track a recovery of a whole new architecture, the result was not optimized at all ... and netbooks got crushed. Windows 7 is more sensible because they did have time to snip out a lot of the junk code.
Currently we're disparaging the need for tight code, but give it one skipped cycle of Moore's law and suddenly the software side will have to take up the slack. Currently it's the mobile phones with their weaker processors that are preventing "dock your phone into a workstation shell" from being the universal desktop in your pocket.
I'd love it if someone managed to make a meme that Tight Code Stops Terrorists. Then watch the OS fly!
My first Journal Entry ever, in 8 years! http://slashdot.org/journal/365947/aphelion-scifi-fantasy-horror-poetry-webzine
OK, then let's try it on a Game Boy Advance, which has a 16 KiB BIOS. I wrote a simple terminal emulator plus font plus Hello World in C (or in C++ using only C features), and it compiled to less than 6000 bytes with no BIOS calls, and that's even without paying attention to optimization for space. But when I did the same using C++ of GNU libstdc++, the file bloated to over 180,000 bytes.
At 88,225 bytes, the image showing the comparison is also bigger. Oh the irony
> Kids these days don't know the meaning of a kilobyte.
Shouldn't that be a kibibyte?
Only if you enjoy choking on penises.
No, it most certainly should not. That forced nomenclature is worse than what it ostensibly tries to solve.
Turbo Pascal itself was bloatware, and I thought it produced horribly slow and big code.
Different memories here, and Wikipedia gives support: "The Turbo name alluded to the speed of compilation and of the executables produced. The edit/compile/run cycle was fast compared to other Pascal implementations because everything related to building the program was stored in RAM, and because it was a one-pass compiler written in assembly language. Compilation was very quick compared to that for other languages (even Borland's own later compilers for C),[citation needed] and programmer time was also saved since the program could be compiled and run from the IDE. The speed of these COM executable files was a revelation for developers whose only prior experience programming microcomputers was with interpreted BASIC or UCSD Pascal, which compiled to p-code."
CC.
TaijiQuan (Huang, 5 loosenings)
That 30 seconds of cursor blinking? The bootloader hack that you used to make your unlicensed copy of Windows 7 think that it's genuine is waiting for feedback from the bios. The 30 seconds is how long it takes to give up and continue booting. There are other/newer hacks that avoid that issue.
I agree. There is balance that needs to be struck here. If a developer is earning $40 to $50 per hour, is it worth it for him to spend more than 2 or 3 hours reducing the memory foot print of his application, by even 20%, when I can just slap an extra 4 gig in the server for about the same cost? Programmers do know how to optimize, in my example it is the use of their time.
That's your probelm, right there "attaching to a local domain". Windows does piles of things when attached to a domain it otherwise doesn't do. It seems slow, but most likely it is a bunch of network timeouts waiting for something that will never happen.
Quite simply proven really. Put in the wrong password on a non-domain computer, and it comes back instantly. Same on a domain computer, and time it. It first has to check to see if the domain controller is there, if there is a new password, and then fall back on the locally cached hash.
It is also constantly sending out device discovery information, publishing and receiving info about who has printers and such, and on startup this information has to be collated from scratch (or so the OS thinks).
You can look into administration a little and optimize your startup to stop doing some of these things, which I would recommend even if you don't care abount speed.
Turbo Pascal was pretty sweet, even though it came from Borland, and even if it was Pascal. It could compile 5,000 lines of code in the blink of the eye. Embedding assembly into it? No problem. It didn't care. The editor was supreme as well. Even when I stopped using TP, I still used the editor every day for a decade after the fact because it could do absolutely everything.
I'm not sure where all the hating is coming from, because TP did not generate hugely bloated executables. The only problem with it was that it eventually was discontinued, so special hacks like paspatch were required to patch TP compiled executables on the P II and higher to allow them to run.
It was actually closer to 512K with all of its dependencies, but it was damn fine.
My suspicion is/was that the RTL (run-time library) was hand-coded in assembly language and from .COM file sizes of stuff compiled with Turbo Pascal 3.0 that RTL ran maybe about 10-12K. That is, the Turbo Pascal image had the hand-coded RTL in the first 12 K of the image and the rest -- editor and Pascal compiler -- were written and compiled in Turbo Pascal and occupied the rest, which was about the size/scale of a simple editor and a Pascal compiler based on the complexity of source codes for those things that were "around." The cool thing, especially on dual floppy disk PCs, was that the 39K was everything, no overlays, no nothing else. The 12K RTL got plopped into the COM file compiled from your source codes.
The thing about it is that yeah, yeah, you had the limitations of Pascal, the Small memory model, 64K data segment, and Borland didn't even get the 8087 math coprocessor support right (inline instead of high-overhead function calls to a math library) until Turbo 4, which wasn't anywhere as kewl as Turbo 3 from the standpoint of compactness. But you could develop useful apps with this thing on a dual-floppy machine.
The other thing about this is the Pascal language. I had a conversation with a dude who was selling some 3rd party library for the Turbo Pascal ecosystem who expressed the view that hate the begin-end, hate the quirky use of semicolon as a statement "separator" instead of 'terminator", hate the bondage-and-discipline aspects (although the Turbo dialect of Pascal solved the fixed-length string problem and gave you enough overrides to the Pascal type safety to allow it to do anything C can), Pascal is the Ur Single-Pass Compiler language. I guess the Arch language of simple parsing at the expense of stupid looking source would be Lisp, but Pascal was close behind in terms of simple syntax and simple compiler implementations. Back in the day before we had Cray Y-MPs on our desk as we effectively do today, that compilation of large programs in the time of a sneeze instead of a long coffee break was a huge, huge productivity booster that made up for whatever people hated about Pascal.
So ol Nicky Wirth was a smart dude when he invented Pascal, and Anders Hejlsberg (Philippe Kahn was just the front man) was also a smart hacker in coming up with Turbo 3, and you have to give the man his propers in hackerdom. For what it is worth, Hejlsberg crossed over to the Dark Side and is credited as the Chief Architect behind the abortive Microsoft Java ecosystem J-somethingoranother from which came the good Visual Studio versions, C#, and all of that.
Blasphemy. My son's first project will be a paperclip computer. I have the original book and everything :)
http://lab16.wordpress.com/2009/01/29/paperclip-computer/
My Other Computer Is A Data General Nova III.
Cute, but I would argue that the concept of optimizing slow code after the fact is a prima facie thought crime. The biggest performance gains come from choosing the right algorithms in the design stage.
"It's almost as if the existence of faster CPUs and larger memory has enticed some to be extremely lazy"
Or just made them focus on getting stuff done rather than implementing optimisations no one will ever notice.
Oh, and your MacBook startup vs. your Windows startup? That's because Windows supports an ever changing set of hardware configurations and retains support for legacy software. Your MacBook has the luxury of retaining a relatively small set of hardware configurations and Apple being happy to chuck backwards compatibility out the Window.
Sure Windows is slower to boot up but it works on more hardware and has superior backwards compat. Sure your MacBook has poor backwards compat. for older Mac software and wont ever support some hardware configurations, but it's got a better startup time. Those are the tradeoffs you face with this sort of thing.
Surely you understand this though if you're an optimisation guru, that you know, it's all about tradoffs? Or perhaps if you're one of those that's all about optimisation whatever the cost in man hours and however negligible the benefits then you don't understand that it's all about picking the right balance.
So no, don't "MOD PARENT DOWN!!!". You have a rose tinted view of an era when all software was ultra-optimised by super non-lazy ninja programmers, I remember it more as an era where software still took longer to load and performed far more poorly than it does now, crashed far more often in far more fatal manners, had far more dangerous security flaws like root access exploits rather than just SQL injection exploits, and where usability was out the window as you had to spend hours configuring your system to even get it to run a game or whatever.
I don't think the past was really as rosy as you think.
Speaking of bloat, there's a humorously insightful article here about http://www.trygve.com/doomsday.html
Those WYSIWYG creators produce the most gawdawful code full of
My first Journal Entry ever, in 8 years! http://slashdot.org/journal/365947/aphelion-scifi-fantasy-horror-poetry-webzine
And that attitude is why we lost the phone and tablet markets. There was a time when Linux was perfect for older systems... the sort of specs that also happen to match up with new small platforms. But we got that 'screw em, let them buy a real computer' attitude and now /bin/touch on my Fedora 15 laptop is 60856 bytes. The little gadget in my XFCE tray to allow me to control the backlight is currently reporting 6200K in resident set. XFCE is supposed to be the 'lighter' alternative to the GNOME freak show. Ever wonder why Google passed all the userland by and made their own for Android? Well now you know and your attitude is what caused it.
Nokia was stupid enough to believe they could build small devices by reusing parts of the Linux desktop, they failed. Good grief, look how much bloat is in little things like esd or pulseaudio. Megabytes of resident set sitting around in case something wants to make a sound? In hardware that had as little as 64MB Ram (Nokia N770 tablet) that sort of resource misuse killed them.
There was a time when System V UNIX would run on machines with a MB or two of RAM, with terminals hanging off serial ports and a couple tens of megabytes of hard drive could run a retail operation.
Yes there is something to be said for trading developer time for hardware. The time to do that is vertical apps and other applications where the number of deployed systems is small compared to the developer hours available. In a mass deployed application the developers should be required to care a little more about what they are asking millions of users to throw away to the great God of the upgrade treadmill.
Democrat delenda est
Just the words on this page (no markup, no graphics, and after a few comments) would have exceeded the capacity of your beloved 5-1/4 floppy.
Huh? Have you read any documents that are 1.2 million characters long? There are about 2000 characters per page, in standard text. A plain text document that would fill a floppy would be about 600 pages long. Generously assuming that one comment is about one page of text, that's a lot of comments, somewhat substantially more than, "a few." Not so many complete threads on Slashdot get 600 comments.
So, no, your hyperbolic statement is incorrect.
Put my fist through my alarm clock with its ding-dong death inside my ear. - The Blackjacks.
Take a simple text editor from 10 years ago and compare it to a modern one. The modern one doesn't really do much more
The old editor supports only 8-bit encodings of left-to-right characters, which means English and a few other European languages. The new Pango-powered editor supports UTF-8, large character inventories, stacked diacritics, and bidirectional writing, which allows for every national language on the planet including Chinese, Arabic, and other official languages of emerging economies.
You could argue that software uses more memory and cpu-cycles, but apart from that how has quality decreased? Letting Java (or any other language/libraries) do stuff for you decreases the number of errors you make. Surely using a library is better than everyone writing their own string comparison algorithms? People make mistakes, for every n lines of code not written, a bug is averted.
You seem to hate Java but it's not that much slower than other languages such as C despite the 'bloat'. http://shootout.alioth.debian.org/
Are you trolling?
How? It resolves ambiguity.
It doesn't, because most people won't use a retarded name like 'kibibyte' or whatever the heck it is. So when Joe User says they have four gigabytes of RAM in their PC you still have to know that they mean four gigilobytes and not four billion bytes.
It's a dumb idea, the name sounds like some kind of metrosexual bar snack, and it's increased ambiguity because you no longer know what people mean when they say 'gigabyte'.
Then again, today's programmers would rather import the whole STL just to be able to use one String, rather than take 15 minutes to write their own class. (oops, they couldn't write one in 15 minutes ... oh well ...)
Now everyone is writing their own String class, you have to pay them for that effort. That 15 minutes may not seem like a lot, but if everyone is doing shit like that all the time, the costs will add up. Also, at some point you will want to interoperate with some third party library. Wouldn't it be great if there were some sort of standardized String class so you don't have to convert from your String to their (inevitably screwy) String class? Repeat this for many datastructures and third party tools and libraries.
Higher level languages didn't arise for the hell of it; if we needed to be worried about 128k of RAM, we'd still be writing code like we did in the old days. Now, we don't have to (minus certain domains), so why not trade space for time / money? We make all kinds of optimization trade offs already; ease of maintenance tends to not be one we often think of.
SSC
First, you only have to have ONE person in your org write that custom string class that does exactly what you want, no unpredictable side effects, no bloat.
That 15 minutes pays itself back almost immediately, both in easier debugging (less code to debug) and quicker compile times,
I wouldn't say it's less code to debug, but more, because now you have to maintain your string class.
Second, 3rd party libraries are always going to be a problem, but usually you just give them a pointer to (a copy of) the data structure, never to your class. No big deal. I null-terminated string (c-style string) is a null-terminated string. A string with the first n bytes giving the actual size (a pascal-style string, can also be used for BLOBs) is a string with the first n bytes giving the actual size. These are the two standard ways of modeling string data.
These are the standards, but Crazy Ass Corp Super Deluxe Hyper-whatever Library is going to do whatever you're not doing, and in a way that you can't just point to the internal C string. Never underestimate vendors: instead of your nice, 1960s style null terminated array of 1-byte characters, they're going to an array of 64-bit integers where they've packed in multiple 8-byte characters, but have decided to leave the last byte of each 64-bit integer as 0xFF for future use and they use EBDIC. Yes, this example is highly contrived and nonsensical, but never underestimate the inability of your colleagues to write software.
This doesn't even touch on the STL's various algorithms to e.g. loop over all characters in a string and perform a function. Again, it's easy to write it yourself, but the STL is written in a nice, general fashion that makes it easier to interoperate, makes it easier to understand what is going on, and doesn't require you to continuously reinvent the wheel. Yes, once you write your BetterString class, you can reuse it, but over time you will keep adding functionality to it until it becomes std::string, and your office on the other side of the country may not know and may have written their own, etc.
But you don't pay for it over and over again: your target audience is running machines with at least 512MB of RAM, very likely 1GB of RAM at least, and many will have at least 2GB of RAM. Saving, say, 100K of RAM by not using the well defined library string class is not a useful optimization, outside of more specialized problem domains. Outside of your underpowered embedded type systems or extreme high performance game with custom memory allocation or massively parallel real time trading application where each 0.000001 nanosecond of delay costs you trillions of dollars, that 100K is dwarfed by every other facet of your program for anything nontrivial. Grandpa's PDP-11 can't even run your target OS(es), why do we care that our program might be RAM-lean enough to fit in its memory?
SSC
Exactly: The *user* does the locking. Therefore the locking constructs are not in the STL, and therefore it cannot be bloated by them.
And the usage of "not thread safe" in the quoted text is strange: According to that logic an int is also not thread safe, because two threads cannot access it concurrently without locking.
The Tao of math: The numbers you can count are not the real numbers.
Think about this the entire image of pascal and dos would run in what we would consider to be 'minimum cpu cache' these days...
Oh. Maybe 3 years ago there was a comment in Slashdot where some guy said he was able to disconnect RAM of a running system on the fly and Windows 95 ran for a good while straight from the cache of a modern CPU. The core components did fit there.
So rather than lock on just a small section, if using the STL you end up having to go with more coarse-grained locks because otherwise subtle bugs emerge under load.
You honestly don't believe that handling thread synchronization at container/primitive level is the right thing to do, do you?
You honestly don't think it's good architecture even needing a lot of locking in parallel code, do you?
Coffee-driven development.
Desqview... thank you for bringing up such awful memories. I remember lusting after that stupid thing for so long, only to discard it about 20 minutes after installation.
OS/2 Warp ftw.
-Billco, Fnarg.com
It doesn't matter if vendors write the device drivers, the device drivers still have to interface with the OS and that means the OS providing services the drivers can interact with to, you know, do something useful.
Apple has no qualms about deprecating support for older or obscure hardware whilst Windows always does it's best to cope. Windows also supports hardware you see in industry which Apple would never dream of bothering to support. Both have their pros and cons - MacOS X is sleeker and faster as a result, but Windows is more widely compatible, this mirrors the fact Windows can be bought and installed on whatever hardware you want, but Apple maintains a strong grip over where it's OS can go.
Your example of Linux actually demonstrates the point, it lets you manage what you do and don't need loaded. This is why you've always historically had to fuck around recompiling the kernel, and nowadays, with kernel modules. The benefit is that you can tailor it to be fast for your needs, the cost is worse usability- many people don't have the skill or will to go fucking around with that for the sake of an extra minute or two startup time whilst they go make a coffee, to others however it's essential to their setup that systems boot as fast as possible and so it does matter. It's again about tradeoffs, Windows isn't slow just because Microsoft's devs don't understand optimisation like you believe is the case. When new versions of Windows are released and we hear bootup times have improved it's because they finally have actually been able to trim away some of the legacy cruft because it genuinely isn't needed anymore.
But as you clearly have no grasp of the topic at hand I guess I'll leave it there. There's no point arguing with people who just don't know wtf they're on about, but carry on anyway. You're one of those people, in your mind you're never wrong. Even though everyone around you is pointing out quite clearly why you are, all you can do to counter that is to continue to say things which demonstrate your lack of knowledge.