 Slashdot Mirror
Slashdot Mirror
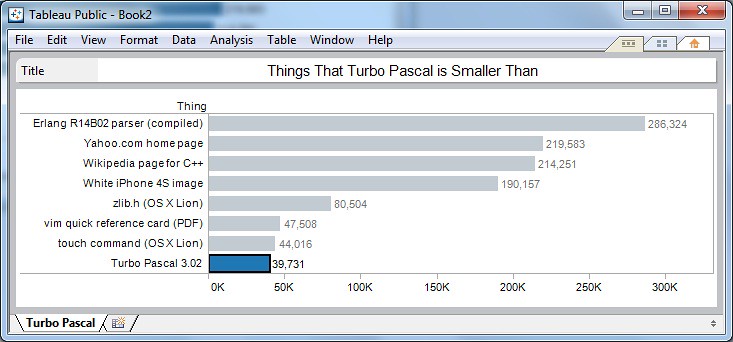
Things That Turbo Pascal Is Smaller Than
theodp writes "James Hague has compiled a short list of things that the circa-1986 Turbo Pascal 3 for MS-DOS is smaller than (chart). For starters, at 39,731 bytes, the entire Turbo Pascal 3.02 executable (compiler and IDE) makes it less than 1/4th the size of the image of the white iPhone 4S at apple.com (190,157 bytes), and less than 1/5th the size of the yahoo.com home page (219,583 bytes). Speaking of slim-and-trim software, Visicalc, the granddaddy of all spreadsheet software which celebrated its 32nd birthday this year, weighed in at a mere 29K."
{kind=link}
Visicalc was the first killer app as well. I remember people coming into the store and asking for Visicalc computers not knowing it was a program that ran on an Apple II.
When I think back to playing vast adventure games, like Below the Root, that amazingly fit on two sides of a 5.25" floppy, but the same game now would probably be written to take up a CD-ROM, even using the same graphics. Programmers have lost the ability to optimize.
I think they have the hability (some of them at least) but don't have the need or the time.
Sig? Heil
But under 'C' it felt somehow very natural and easy to understand, never had a problem with 'C' pointers, and data structures. R.I.P. DMR, your book really opened my eyes to the wonderful world of computing.
for the last time people, I am "frodo from middle eaRTH", not "middle eaST".
Programmers have lost the ability to optimize.
The ability and the need (programmers of embedded systems may be an exception). I think nothing of allocating an input buffer that is larger than the entire memory of the first machine I worked on (a z80 box with 2k memory).
Back in my day we had Basic running on a 2K altair. Kids these days don't know the meaning of a kilobyte.
Some drink at the fountain of knowledge. Others just gargle.
There was a time when you had to be very careful about the ram and the processing limitations.
You had to make sure you had enough space for your variables and make some weird stuff to get more done with less resources.
That's all gone now, hardware is relatively cheap so too little people care about optimizing the size of stuff.
Bytes are kind of weird. Can't they give these number in terms of Library of Congress?
More Twoson than Cupertino
First thing that comes to mind is: so what? This whole argument that smaller is better is crap. The reason that software is bigger these days is that it does more for you. How productive was the GUI for Turbo Pascal (it sucked), how good were the other tools that came with it (nonexistent), how fast were the release cycles (about the same as today). So with what people call bloat we get better tools that make us more productive thereby driving down the cost of software development.
Or to put it another way: if you really don't like bloat, when are you going to trade in your car and start driving to work in a hot wheels?
Why doesn't Slashdot ever get slashdotted?
Sure, these programs were small, but try to keep in perspective that they were leveraging the OS to get their compactness. It's kind of like saying a "Hello, World" GUI app is only 3 lines of code.... sure, 3 lines, plus 35 megs of library files running atop 1 gig of OS support. The .exe may only be 2k, but good luck getting that to do anything without serious support.
The ability and the need (programmers of embedded systems may be an exception).
That and dedicated TV games, which commonly use an architecture not unlike that of the Nintendo Entertainment System. New games are still being developed for the NES, and many are roughly the size of Turbo Pascal or smaller.
Good job. Posting obvious shit and getting on the main of Slashdot. I hope I'm not the only one who thinks this sort of comparison is absolutely pointless. Why are we even comparing executables to web pages or images?
Software grows to fill the available ram.
Code is always a tradeoff between codesize, development time and ram needed for execution. I'm fairly sure you can optimize code today to a point that would put those programs (which were optimized 'til they squeaked to squeeze out that last bit of performance) to shame, but why? What for? 30 years ago, needing a kilobyte of ram less was the make or break question. When drivers weighed in the 10kb range and you still calculated which ones you absolutely need to load for the programs you plan to run, where you turned off anything and everything to get those extra 2 kb to make the program run. Today, needing a few megabytes of ram more is no serious issue. And mostly because it just really doesn't matter anymore. Do you care whether that driver, that program, that tool needs a megabyte more to run? Do you cancel it because it does? No. Because it just doesn't matter.
We passed the point where "normal" people care about execution speed a while ago. Does it matter whether your spreadsheet needs 2 milliseconds longer to calculate the results? I mean, instead of 0.2 you now need 0.202 seconds, do you notice? Do you care? Today, you can waste processing time on animating cursors and create colorful file copy animations. Why bother with optimization?
Because, and that's the key here, optimizing code takes time. And that costs money. Why should anyone optimize code if there's really no need for it anymore? And it's not the "lazy programmers" or the studios that don't care about the customers. The customers don't care! And with good reason they don't. They do care about the program being delivered on time and for a reasonable price, but they don't care whether it needs a meg more of ram. Because it just friggin' doesn't matter anymore!
So yes, yes, programs back in the good ol' days were so much better organized and they used ram so much better, they had so much niftier tricks to conserve ram and processing time, but in the end, it just doesn't matter anymore today. You have more ram and processing power than your ordinary office program could ever use. Why bother with optimization?
We used to have a Bill of Rights. Now, with the rights gone, all we have left is the bill.
In my first job, I was responsible for developing a programming environment for a Pascal-like language that included a visual editor, interpreter and debugger. I remember my boss showing up in my office and showing me an ad he had cooked up, with big, bold lettering saying "Runs in 256 kB!"
As a young developer, it was one of the tougher moments in my life to admit that we were going to need a full 512 kB.
It was difficult living in a world where Turbo Pascal ran comfortably on a 64 kB machine.
Whats its value in pico-Wales? And, if loaded onto a Kindle, how much would it increase the devices weight in Bulgarian Funbags? http://www.theregister.co.uk/2007/08/24/vulture_central_standards/
> Programmers have lost the ability to optimize.
(which is very sad, I agree)
When I have children, they'll only have access to a C64 with a Retro Replay or possibly a Chameleon Cart. That way, they will learn how a computer actually works, unlike kids (those under the age of 30) today
39,731 is the exact number of milliseconds it takes to lose interest in an Apple fanboi blog.
Join the Slashcott! Feb 10 thru Feb 17!
How easily we overlook the difference between "bloated" and "quantity of useful information".
Just the words on this page (no markup, no graphics, and after a few comments) would have exceeded the capacity of your beloved 5-1/4 floppy. That's only the raw information, without bloat.
My first screen (a DECScope) had 12 lines x 80 columns each (I couldn't afford the 2K RAM that would have given me 24 x 80.) The screen I'm reading this on can display over 2 million RGB pixels. Calling things "bloat" is like telling me I should honor a display that's less than the size of the "close [X]" icon, because 12x80 isn't "bloat".
By the same twisted logic, Turbo Pascal itself was bloatware, and I thought it produced horribly slow and big code. Assemblers were where the real efficiency lay, and they were a lot smaller than 39K.
Nostalgia is fine. But leave it in the past.
John
Yes, it does stand to reason that something from 1986 is smaller than IMAGE files (yahoo's homepage, wiki's C++ page, PDFs, etc). That 256-bit color depth means we need 256 bits to define the colors after all.
Instead of comparing to PDFs, image files, and things written 30 years later, why not compare to contemporaries?
I would be tempted to call this s slashadvertisement, but they're not even advertising something. Where's the 'pointlesslyIdle' tag when we need it?
"Our goal each year should be to increase the number of goals we set for ourselves!"
No, they will learn how an obsolete computer works, if they even bother with it, which they almost assuredly will not.
Rest assured, you won't do that. Virtually every prediction of "when I have children" is usually just some excuse to pontificate about how other people raise their own kids, and every one of those falls by the wayside of practicality when the little bundles of joy actually arrive. You will compromise, because I bet in the end your 8-bit-forever principle isn't actually that important to you.
Oh, same rant goes for "I would fire any employee who ______". If you've never been a hiring manager, just keep it to yourself.
Sorry, your post went a little south with the Vista debacle. Because MS had to fast track a recovery of a whole new architecture, the result was not optimized at all ... and netbooks got crushed. Windows 7 is more sensible because they did have time to snip out a lot of the junk code.
Currently we're disparaging the need for tight code, but give it one skipped cycle of Moore's law and suddenly the software side will have to take up the slack. Currently it's the mobile phones with their weaker processors that are preventing "dock your phone into a workstation shell" from being the universal desktop in your pocket.
I'd love it if someone managed to make a meme that Tight Code Stops Terrorists. Then watch the OS fly!
My first Journal Entry ever, in 8 years! http://slashdot.org/journal/365947/aphelion-scifi-fantasy-horror-poetry-webzine
Loved TP back in the days, but marvelous as it was, was nothing compared with the miracle in few bytes that was Sidekick for DOS. Depending on how much things had into, was between 20 and 50k.
My second language was Turbo Pascal, after BASIC. I loved that language.. I was 12, trying to create games.. 320x200x256 raw graphics, stitched together with ASM. I actually created a photoshop type program to edited my "proprietary" raw image files.( I just added a larger header to regular raw graphics files) all in DOS with a Hyundai Super 286 AT 12Mhz 40 meg HD, 4 meg of ram and a 2400 baud modem.
Ad eundum quo nemo ante iit!
Just the words on this page (no markup, no graphics, and after a few comments) would have exceeded the capacity of your beloved 5-1/4 floppy. That's only the raw information, without bloat.
I dunno, sometimes there seems to be a lot of bloat even in the raw data around here.
Someone had to do it.
At 88,225 bytes, the image showing the comparison is also bigger. Oh the irony
ImageQuant was a c. 1986 scientific Windows 3.1 program for quantitative analysis of 2D images. It displayed 16-bit images in either grayscale or false color. Draw a box around any object and it could integrate the intensity within, subtracting the average background of the perimeter. You could draw a long box of any width and it would display the integrated intensities as a line graph, then you could graphically mark off each peak and it would integrate the intensities, with multiple choices for setting the baseline. Select any area of the graph, and it would expand to fill the window. It could also rotate the image. Not sure of the exact size, but it fit on a single floppy.
I think a more accurate comparison might be to ask why you need a Hummer to take your two kids to school when you can do it equally well in a Ford Focus which is half the size and probably 10 times as fuel efficient?
If there are in fact situations where one needs a Hummer or similar SUV, is it cheaper to fuel an SUV than to buy an additional small passenger car for trips that don't need the SUV?
> Kids these days don't know the meaning of a kilobyte.
Shouldn't that be a kibibyte?
Derive could do a lot of the symbolic math that Macsyma does as a single 5 1/4" floppy (360K?) DOS app in 1988. Awkward interface but useful for grad. physics.
Currently it's the mobile phones with their weaker processors that are preventing "dock your phone into a workstation shell" from being the universal desktop in your pocket.
Are you sure it's just the processor, or is it Apple's restrictions on what gets accepted into its App Store?
Obviously Your machine is poorly configured. My $400 Dell notebook starts Win7 in about 15 seconds.
But I just wrote a cheesy little demo app in C++ that reads an orbit file for a satellite, reads an ephemeris file for the same satellite and acts as a very simple http server so that it can be a network link to plot the current orbit and last-seen location of the satellite in Google earth. ps reports that it's using 16K of RAM. I wasn't going out of my way to make it small, though. There are lower hanging fruit to optimize than memory these days. Back in the day you didn't have a choice about fitting into the environment and had to make a lot of trade-offs to manage it. These days maybe you can allocate a few megabytes so you can keep a hash table in memory and eke out a bit more speed. Knowing what trade-offs to make and where you can optimize is still key. My cheesy little app would need to be a good bit bigger to be actually useful.
I'm trying to teach myself to set people on fire with my mind... Is it hot in here?
Using less space on main storage allows the use of an SSD instead of an HDD. Using less RAM saves the energy that would be used to manufacture the RAM, along with the energy that would be used to manufacture a new computer if an application requires more RAM than the computer has slots for.
Software quality has decreased due to programming languages that "make the programmers life easier" by "doing the hard things" for them.
-Memory allocation is hard, let java do it for you, at a price
-String comparison is hard, let java do it for you, at a price
-Graphics is hard, let java do it for you, at a price.
Java, it's thousands of "helper" libraries, classes, etc, all cause needless bloat.
Memory is "free" cpu cycles are "free and fast"..why bother choosing an appropriate sort/data model, simply let java/library X do it for you, at a small price.
Hint: lots of "small prices" quickly add up.
Only if you enjoy choking on penises.
Mod parent up.
I've been thinking the exact same thing.
I saw the comment where someone used some video game that fit two floppies back in in 198x as example of how programmers forgot how to optimize. Tell that to the developers of Rage (a game that comes on 3 DVDs) who manage to stream hundreds of megabytes of texture data at 60 frames per second.
No, it most certainly should not. That forced nomenclature is worse than what it ostensibly tries to solve.
Turbo Pascal itself was bloatware, and I thought it produced horribly slow and big code.
Different memories here, and Wikipedia gives support: "The Turbo name alluded to the speed of compilation and of the executables produced. The edit/compile/run cycle was fast compared to other Pascal implementations because everything related to building the program was stored in RAM, and because it was a one-pass compiler written in assembly language. Compilation was very quick compared to that for other languages (even Borland's own later compilers for C),[citation needed] and programmer time was also saved since the program could be compiled and run from the IDE. The speed of these COM executable files was a revelation for developers whose only prior experience programming microcomputers was with interpreted BASIC or UCSD Pascal, which compiled to p-code."
CC.
TaijiQuan (Huang, 5 loosenings)
I call BS. You can't even get through the BIOS bullshit on a Dell in 15 seconds.
It's the many, many little programs that litter your ram, from drivers for god knows what kind of freaky hardware you rarely if ever use, to "enhancements", and the omnipresent crud you get for free with every new Netbook.
Uninstalling unused programs helps, and it's the first thing I try when family members tell me a computer is running slow. But the fact remains that some programs won't run acceptably on a netbook or an old P4 PC even after I've uninstalled all that shit. I've seen applications fail to run because their forms are laid out for a monitor at least 768 pixels tall. I've seen Adobe Flash fail to keep up on Flash videos, and I've seen Firefox fail to keep up on HTML5 videos. I've seen native games fail to run because they aren't meant to scale down to the Dreamcast-class capability of an Intel GMA.
And because of its small size, Derive is still in use on TI-89 calculators.
If you call "installing Win7 by choosing the default options and attaching to a local domain" screwing it up, I guess I screwed up by choosing M$ products...
No, they will learn how an obsolete computer works, if they even bother with it, which they almost assuredly will not.
I have a cousin in high school who in his spare time develops video games for obsolete computers because making graphics for them is a lot easier than making graphics for a 3D engine.
Crazy. Even today I see review code where programmers have implemented exponential sorting algorithms. It's almost as if the existence of faster CPUs and larger memory has enticed some to be extremely lazy. But it's never enough for some. Example, my MacBook Air goes from "ding-chord!" to signed in and usable in about 15 seconds. For Windows 7 on the very same machine the number is about 3:30, including 30 seconds of watching a fucking white cursor blink on an otherwise black screen! What the hell is it trying to do?
Do programmers still implement sort algorithms? I thought whatever library/framework they're using took care of sorting for them?
Tell that to the developers of Rage (a game that comes on 3 DVDs) who manage to stream hundreds of megabytes of texture data at 60 frames per second.
Perhaps the point is that an art style that requires "stream[ing] hundreds of megabytes of texture data at 60 frames per second" isn't the only art style for a fun video game.
That 30 seconds of cursor blinking? The bootloader hack that you used to make your unlicensed copy of Windows 7 think that it's genuine is waiting for feedback from the bios. The 30 seconds is how long it takes to give up and continue booting. There are other/newer hacks that avoid that issue.
I remember using Turbo Pascal for my AI class - needed to write an Othello program. Originally wrote it on the CP/M version of Turbo Pascal, on a Coleco Adam - yes, a Coleco Adam. With dual cassette drives, dual disk drives and a parallel printer interface. Ported it over for final polish on the Zenith desktop PCs in the college lab. Professor gave me an A, couldn't beat the program.
Super Mario Bros. is 40 K. This means about 25 copies of it will fit in one M, and about 17,000 copies of it will fit in one CD.
Useful has to be taken in context - even if TP is lame by today's standards, it was state of the art for its time - gave you a competitive edge when you used it.
Was a time when a hand-axe was a prized tool because poorly sized or shaped rocks just couldn't get the job done as quickly.
That's what my friend and boss Wayne Holder said about Turbo Pascal when I demo'd it for him back when it first came out in the early 80s. It wasn't just that TP was vastly smaller than any other Pascal (C, FORTRAN, etc.) compiler out there, it's that it compiled much, much faster -- in some cases, an order or two of magnitude faster. ..bruce..
Bruce F. Webster (brucefwebster.com)
I agree. There is balance that needs to be struck here. If a developer is earning $40 to $50 per hour, is it worth it for him to spend more than 2 or 3 hours reducing the memory foot print of his application, by even 20%, when I can just slap an extra 4 gig in the server for about the same cost? Programmers do know how to optimize, in my example it is the use of their time.
That's your probelm, right there "attaching to a local domain". Windows does piles of things when attached to a domain it otherwise doesn't do. It seems slow, but most likely it is a bunch of network timeouts waiting for something that will never happen.
Quite simply proven really. Put in the wrong password on a non-domain computer, and it comes back instantly. Same on a domain computer, and time it. It first has to check to see if the domain controller is there, if there is a new password, and then fall back on the locally cached hash.
It is also constantly sending out device discovery information, publishing and receiving info about who has printers and such, and on startup this information has to be collated from scratch (or so the OS thinks).
You can look into administration a little and optimize your startup to stop doing some of these things, which I would recommend even if you don't care abount speed.
Turbo Pascal was pretty sweet, even though it came from Borland, and even if it was Pascal. It could compile 5,000 lines of code in the blink of the eye. Embedding assembly into it? No problem. It didn't care. The editor was supreme as well. Even when I stopped using TP, I still used the editor every day for a decade after the fact because it could do absolutely everything.
I'm not sure where all the hating is coming from, because TP did not generate hugely bloated executables. The only problem with it was that it eventually was discontinued, so special hacks like paspatch were required to patch TP compiled executables on the P II and higher to allow them to run.
It was actually closer to 512K with all of its dependencies, but it was damn fine.
There's always somebody who thinks they're smarter than the standard libraries. And you'll always get stuck fixing their "innovations."
Wrong. Valid, licensed, genuine, blah blah blah. Google "black screen blinking cursor"...
Obviously Your machine is poorly configured. My $400 Dell notebook starts Win7 in about 15 seconds.
Yeah, then you spend three minutes waiting for all the crap to load after you log in.
My suspicion is/was that the RTL (run-time library) was hand-coded in assembly language and from .COM file sizes of stuff compiled with Turbo Pascal 3.0 that RTL ran maybe about 10-12K. That is, the Turbo Pascal image had the hand-coded RTL in the first 12 K of the image and the rest -- editor and Pascal compiler -- were written and compiled in Turbo Pascal and occupied the rest, which was about the size/scale of a simple editor and a Pascal compiler based on the complexity of source codes for those things that were "around." The cool thing, especially on dual floppy disk PCs, was that the 39K was everything, no overlays, no nothing else. The 12K RTL got plopped into the COM file compiled from your source codes.
The thing about it is that yeah, yeah, you had the limitations of Pascal, the Small memory model, 64K data segment, and Borland didn't even get the 8087 math coprocessor support right (inline instead of high-overhead function calls to a math library) until Turbo 4, which wasn't anywhere as kewl as Turbo 3 from the standpoint of compactness. But you could develop useful apps with this thing on a dual-floppy machine.
The other thing about this is the Pascal language. I had a conversation with a dude who was selling some 3rd party library for the Turbo Pascal ecosystem who expressed the view that hate the begin-end, hate the quirky use of semicolon as a statement "separator" instead of 'terminator", hate the bondage-and-discipline aspects (although the Turbo dialect of Pascal solved the fixed-length string problem and gave you enough overrides to the Pascal type safety to allow it to do anything C can), Pascal is the Ur Single-Pass Compiler language. I guess the Arch language of simple parsing at the expense of stupid looking source would be Lisp, but Pascal was close behind in terms of simple syntax and simple compiler implementations. Back in the day before we had Cray Y-MPs on our desk as we effectively do today, that compilation of large programs in the time of a sneeze instead of a long coffee break was a huge, huge productivity booster that made up for whatever people hated about Pascal.
So ol Nicky Wirth was a smart dude when he invented Pascal, and Anders Hejlsberg (Philippe Kahn was just the front man) was also a smart hacker in coming up with Turbo 3, and you have to give the man his propers in hackerdom. For what it is worth, Hejlsberg crossed over to the Dark Side and is credited as the Chief Architect behind the abortive Microsoft Java ecosystem J-somethingoranother from which came the good Visual Studio versions, C#, and all of that.
They don't set out to implement a sort algorithm, they do it unknowingly. They don't recognize that the problem they are working on involves sort, but yes, generally any library/framework sorting call they could otherwise have made would have sufficed--and saved them a lot of time...
Blasphemy. My son's first project will be a paperclip computer. I have the original book and everything :)
http://lab16.wordpress.com/2009/01/29/paperclip-computer/
My Other Computer Is A Data General Nova III.
Waking from sleep does not count.
They don't set out to implement a sort algorithm, they do it unknowingly. They don't recognize that the problem they are working on involves sort, but yes, generally any library/framework sorting call they could otherwise have made would have sufficed--and saved them a lot of time...
Then the problem isn't that programmers never bother optimizing code, but that you work with bad programmers.
1. King Kong
2. Library of Congress
3. The moon
Wait, that's no moon...
Some do, but many don't even give it a thought or don't care. I'm not saying that programmers should be spending 50% of their time optimizing. Obviously there isn't a need to fit programs in 2K of RAM anymore, But some don't even give it a first thought and thus you wind up with Java programs that require 1GB of RAM simply for the purpose of moving files between folders (I'm not exaggerating).
It had a smart-linker too. The executables were actually smaller than that of Turbo C. IIRC, TP's Hello World weighed in at 3-4K while TC's weighed in at around 6-7K, even with all the size optimizations on, using the tiny memory model. Turbo Basic's Hello World weighed in at around 30K!
Turbo Pascal 3 was really minimalistic. Turbo Pascal 4, then 5 were really useful, like a webpage in a browser vs. a wget.
5.5 added all that object crud that confused me at the time (yay for Software Engineering in college).
My God, it's Full of Source!
OUTSIDE_IP=$(dig +short my.ip @outsideip.net)
How about comparing it to XE2 (the latest version) .. and Lazarus/FreePascal
Hivemind harvest in progress..
What's "BRD"?
Beta is broken and the link to classic doesn't work. Stop wasting our time or there won't be anybody left here.
Cute, but I would argue that the concept of optimizing slow code after the fact is a prima facie thought crime. The biggest performance gains come from choosing the right algorithms in the design stage.
"It's almost as if the existence of faster CPUs and larger memory has enticed some to be extremely lazy"
Or just made them focus on getting stuff done rather than implementing optimisations no one will ever notice.
Oh, and your MacBook startup vs. your Windows startup? That's because Windows supports an ever changing set of hardware configurations and retains support for legacy software. Your MacBook has the luxury of retaining a relatively small set of hardware configurations and Apple being happy to chuck backwards compatibility out the Window.
Sure Windows is slower to boot up but it works on more hardware and has superior backwards compat. Sure your MacBook has poor backwards compat. for older Mac software and wont ever support some hardware configurations, but it's got a better startup time. Those are the tradeoffs you face with this sort of thing.
Surely you understand this though if you're an optimisation guru, that you know, it's all about tradoffs? Or perhaps if you're one of those that's all about optimisation whatever the cost in man hours and however negligible the benefits then you don't understand that it's all about picking the right balance.
So no, don't "MOD PARENT DOWN!!!". You have a rose tinted view of an era when all software was ultra-optimised by super non-lazy ninja programmers, I remember it more as an era where software still took longer to load and performed far more poorly than it does now, crashed far more often in far more fatal manners, had far more dangerous security flaws like root access exploits rather than just SQL injection exploits, and where usability was out the window as you had to spend hours configuring your system to even get it to run a game or whatever.
I don't think the past was really as rosy as you think.
Where can I find this PC that is able to get through the BIOS bullshit in under 10 seconds? Note that my clocking of start up time goes from the moment you press the power button, until that time *after* you've logged in, that the system has stabilized such that it is ready for use.
Funny thing is, the best hardware I've ever used that gets the OS actually starting faster is the MacBook Air. There's no obnoxious net boot delay that can't be switched off, etc...
When I think back to playing vast adventure games, like Below the Root, that amazingly fit on two sides of a 5.25" floppy, but the same game now would probably be written to take up a CD-ROM, even using the same graphics. Programmers have lost the need to optimize.
FTFY
Apple isn't the only mobile phone around
There hasn't been any real Android-powered alternative to the iPod touch until last month when Samsung introduced the Galaxy Player.
By the same twisted logic, Turbo Pascal itself was bloatware, and I thought it produced horribly slow and big code. Assemblers were where the real efficiency lay, and they were a lot smaller than 39K.
Turbo Pascal optimized compilation speed and it did this partly by trading off optimizations for the executable, which is why it produced larger and slower code than other compilers. That said, as noted in the article, the compilation optimization was so extreme that it was faster than assemblers. This was worth the cost for developers.
I agree with your point to a certain extent. Comparing program sizes of today with program sizes from 1986 is just stupid. Programs do more now, and I wouldn't want to trade that for a smaller disk size or memory footprint. Hard drives and RAM are cheap now. That said, saying that not everything is bloat is a far cry from saying there's no bloat. Turbo Pascal was a heavily optimized program (just not optimized in the areas you mentioned, but that was a tradeoff they were aware of), and we just don't see people giving much thought to optimization of any kind these days. As an example, I tried out SpiderOak the other day, and no released product should ever have an interface that runs that slow, ever. There's no freaking excuse.
This is a pet peeve of mine. These days I'd fire any programmer who coded their own sorting algorithm. These days most languages have collections libraries with very efficient sorting algorithms that should meet 99.999% of business needs. Your business may be a unique snowflake so this wasn't necessarily targeted at you, but developers trying to write basic standard library stuff over again really irks me.
Check out my lame java blog at www.javachopshop.com
Speaking of bloat, there's a humorously insightful article here about http://www.trygve.com/doomsday.html
Those WYSIWYG creators produce the most gawdawful code full of
My first Journal Entry ever, in 8 years! http://slashdot.org/journal/365947/aphelion-scifi-fantasy-horror-poetry-webzine
MASM
What did it get you? The ability to write any kind of business, scientific or engineering software. For example, due to limitations of proprietary based construction scheduling and estimating systems at the time, I wrote better systems in TP used to schedule tens of millions of dollars of construction at a national lab over ten year period, and it was used even after I left.
"BOLD, revert, discuss cycle" refers to an editing process involving discussing each revert on an article's talk page. For example, if I were to make a good faith edit to "Turbo Pascal" on Wikipedia, and someone else disagreed with the edit and reverted it, I'd ask for an explanation of the revert on the talk page. But getting consensus for a change through this method takes a lot more time than newcomers are willing to put in (hence "babysit"), and one risks running into entrenched long-time editors who act like they own the article and use nitpicky interpretations of the policies and guidelines to rationalize reverting any edit not made by the article's unwritten "in-group" (hence "political BS").
And that attitude is why we lost the phone and tablet markets. There was a time when Linux was perfect for older systems... the sort of specs that also happen to match up with new small platforms. But we got that 'screw em, let them buy a real computer' attitude and now /bin/touch on my Fedora 15 laptop is 60856 bytes. The little gadget in my XFCE tray to allow me to control the backlight is currently reporting 6200K in resident set. XFCE is supposed to be the 'lighter' alternative to the GNOME freak show. Ever wonder why Google passed all the userland by and made their own for Android? Well now you know and your attitude is what caused it.
Nokia was stupid enough to believe they could build small devices by reusing parts of the Linux desktop, they failed. Good grief, look how much bloat is in little things like esd or pulseaudio. Megabytes of resident set sitting around in case something wants to make a sound? In hardware that had as little as 64MB Ram (Nokia N770 tablet) that sort of resource misuse killed them.
There was a time when System V UNIX would run on machines with a MB or two of RAM, with terminals hanging off serial ports and a couple tens of megabytes of hard drive could run a retail operation.
Yes there is something to be said for trading developer time for hardware. The time to do that is vertical apps and other applications where the number of deployed systems is small compared to the developer hours available. In a mass deployed application the developers should be required to care a little more about what they are asking millions of users to throw away to the great God of the upgrade treadmill.
Democrat delenda est
Old PCs should run with software from the same era.
Unless said software from the same era either has security holes that will never be patched or doesn't do what monopolistic organizations (such as a government or the only bank in town) expect all user agent software to be capable of nowadays. Not everybody has the disposable cash to be buying a new computer per member of the household every two years. At what rate should people reasonably expect to have to replace their computer in order to continue to interact with the rest of the world?
Just the words on this page (no markup, no graphics, and after a few comments) would have exceeded the capacity of your beloved 5-1/4 floppy.
This page, full markup: 138kb
This page, no markup: 53kb
This page, no markup, gzipped: 18kb
All of which would fit on a 5 1/4" floppy, even the kind that only hold 360kb.
In summary, people like you are the problem.
Well me too, but as I wrote in a follow-up post, they are not setting out the code up sorting. And even if they had the 0.001% case where they knew they needed a special case sorting algorithm, they could most probably do it right quite easily.
The problem is in not recognizing that sorting (or whatever) is at play, they are over-modularizing pieces building bottom-up and ignoring top-down etc.
Case in point, colleague codes something that looks kind of like a spreadsheet--two-dimensional matrix of text cells. It takes 12 minutes to render 20 columns Ã-- 80 rows. Design was based on generic cells--"you're a cell at column i, row j; go figure out what you need to do". This resulted, among other things, in >4 million calls to get the text of a cell (more complex than just reading a string). Yet there was no obvious inefficient code--no 5-level nested loops, etc. Colleague's response was to implement a cell-text cache to speed up the reading of the cells' texts--not to fix the obvious error in design that you shouldn't need to ask >4 million times for 1,600 cells...
For me Pascal syntax of pointers made more sense than C syntax. I started serious programming with Turbo/Borland Pascal and because the concept of pointers was so clear in Pascal, I was able to help my friends with their pointer problems in C. They had trouble understanding the concept of pointers, because C syntax was so confusing (eg. array and pointer are sometimes interchangeable, but sometimes they aren't).
I still sometimes use cdecl with complex definitions to make sure I have parsed/generated the C syntax correctly. However, pointer arithmetic was/is usually easier in C.
When I think back to playing vast adventure games, like Below the Root, that amazingly fit on two sides of a 5.25" floppy, but the same game now would probably be written to take up a CD-ROM, even using the same graphics
need to optimize. I can't believe we're actually bitching about living in times where computing resources are bountiful.
"I like to lick butts!" by MobileTatsu-NJG (#32700246) (Score:5, Informative)
Just the words on this page (no markup, no graphics, and after a few comments) would have exceeded the capacity of your beloved 5-1/4 floppy.
Huh? Have you read any documents that are 1.2 million characters long? There are about 2000 characters per page, in standard text. A plain text document that would fill a floppy would be about 600 pages long. Generously assuming that one comment is about one page of text, that's a lot of comments, somewhat substantially more than, "a few." Not so many complete threads on Slashdot get 600 comments.
So, no, your hyperbolic statement is incorrect.
Put my fist through my alarm clock with its ding-dong death inside my ear. - The Blackjacks.
I apologize for responding to my own post, but I mangled the HTML formatting. Here's what it was supposed to say:
When I think back to playing vast adventure games, like Below the Root, that amazingly fit on two sides of a 5.25" floppy, but the same game now would probably be written to take up a CD-ROM, even using the same graphics
Um, yeah, they'd fill up that otherwise useless disc with things like digitized sound files.
Programmers have lost the need to optimize. I can't believe we're actually bitching about living in times where computing resources are bountiful.
"I like to lick butts!" by MobileTatsu-NJG (#32700246) (Score:5, Informative)
One of my hobby programs does have a sort algorithm I wrote myself. It's a radix sort, unusual only in that it has to read it's data from disk and write back to disk too... because it can be asked to sort about thirty gig. My todo list includes 'rewrite it with a quicksort.'
How? It resolves ambiguity.
My Windows 7 Home Theater PC goes from Windows logo to login prompt in 5 seconds and is useable within another 5-10 seconds. I spend a lot more time waiting for the BIOS than I do for the OS. Of course that's also with a fast SSD. Before upgrading the hard drive it took several minutes to be useable.
This post is encrypted twice with ROT-13. Documenting or attempting to crack this encryption is illegal.
Take a simple text editor from 10 years ago and compare it to a modern one. The modern one doesn't really do much more
The old editor supports only 8-bit encodings of left-to-right characters, which means English and a few other European languages. The new Pango-powered editor supports UTF-8, large character inventories, stacked diacritics, and bidirectional writing, which allows for every national language on the planet including Chinese, Arabic, and other official languages of emerging economies.
Turbo Pascal 3 may have been quite limited (I don't think I have ever used TP 3), but the later versions of Turbo/Borland Pascal were really good IMHO.
They were insanely fast compilers even though the computers were quite slow, had nice integrated profilers, had object oriented libraries for writing windowed UI:s, help/documentation was really good and typically included small example programs to demonstrate how to use some function, it was easy to use Pascal with assembly language etc.
I haven't seen as developer friendly system since Borland Pascal. It was really easy to start learning programming using Borland Pascal, but it wasn't any toy system as you could write also large and complex programs.
Well, part of that problem is that QT is buggy, and poorly designed, compared to the libraries we used "back in the day" when every byte counted, and coders were acutely aware of that.
They should try coding on a minimal system (try "64k is enough") for a few months. There were operating systems that supported multiple users in 64k, and multiple graphical screens in 128k (and would run a dozen copies of flight sim, rogue, etc. in 512k).
Then again, today's programmers would rather import the whole STL just to be able to use one String, rather than take 15 minutes to write their own class. (oops, they couldn't write one in 15 minutes ... oh well ...)
I take offense to your under 30 comment. I was taking apart my Pentium 233mHz computer before I was 10. If think your problem with the youth is that those who want to use computers no longer have to know how they work to do what they want
All your 09 F9 11 02 9D 74 E3 5B D8 41 56 C5 63 56 88 C0 are belong to us
Again poor configuration. Why have you selected so much stuff to start up? Most of it isn't necessary. A properly configured windows machine can boot quite fast. First step is to get rid of the default windows installation and install windows from scratch, and not from a manufacturer recovery partition. It's kind of sad that MS works so hard to make a nice system, and all the manufacturers that make computers do such a good job of screwing it up.
Anthropic principle: We see the universe the way it is because if it were different we would not be here to see it.
I worked at Borland back around then and Ander et al just lived and breathed assembly language. I remember going to one of Ander's demo's and he's setting up the computer and projector. Something didn't seem right to him. Next thing he's running debug staring at a hex dump, pokes in some hex, and saves.
Turbo Pascal and Turbo C/C++ were great app's.
Ah, you too ran OS9 on a CoCo3. I ran a BBS on mine with a Disto Super Controller II wired up to a surplus 10MB Miniscribe + Adaptec MFM to SCSI adaptor. I'd make fun of the DOS Sysops who were proud of the fact they could run Desqview and try to use their PC while running a BBS. You could always tell though, because their system would crawl, hesitating for seconds on menu selections, etc, while doing so, yet mine was fully usable by a caller while I used the console. They had studly 386 machines with megabytes of RAM while I had a 1.8Mhz CPU and 512KB. The OS makes a big difference. And it still does.
No we don't want to go back there, low resolution graphics with a couple of colors is lame. Unicode is better than ASCII for most of the world's population, etc. But we can learn some lessons from the past. Go ahead and write a quick utility that people will use at most once a month in Python. Don't write a tool tray app that runs 24/7 in Python.
Democrat delenda est
Indeed it's probably a configuration issue. My now antique dell latitude d600 boots xp sp3 in 30 seconds. Firefox is up and running in 45 seconds, and that machine is quite old.
How? It resolves ambiguity.
It doesn't, because most people won't use a retarded name like 'kibibyte' or whatever the heck it is. So when Joe User says they have four gigabytes of RAM in their PC you still have to know that they mean four gigilobytes and not four billion bytes.
It's a dumb idea, the name sounds like some kind of metrosexual bar snack, and it's increased ambiguity because you no longer know what people mean when they say 'gigabyte'.
Cute, but I would argue that the concept of optimizing slow code after the fact is a prima facie thought crime. The biggest performance gains come from choosing the right algorithms in the design stage.
You would be arguing against a number of computer scientists; Donald Knuth, Michal Jackson, and a few more.
So, lets assume that means English words rather than 32 bit words. The rule-of-thumb for average word length is 5 characters, so lets say 6 to allow for a space or punctuation symbol.
That gives us 1000 words = 6000 characters = 6000 bytes of ASCII but, to be fair, that's wasting at least 1 bit per character, so you could easily reduce that to, say, 4000 bytes.
Now, 4000 bytes is 1333 pixels of 24 bit colour. Take the square root and that gives you a 36 x 36 pixel image, which gives you an image three-eighths of an inch square at the typical 96 ppi.
So, any image bigger than 3/8" square is officially a waste of space!
Ok, so you could use JPEG - but if you allow lossy compression for the picture yv gt t alw lssy cmpsn fr t wds 2.
In a survey of 100 programmers, 111111 thought that duck-typing was a good idea.
> Kids these days don't know the meaning of a kilobyte.
Shouldn't that be a kibibyte?
Kids these days don't know the meaning of that, either, but the reasons are different.
The road to tyranny has always been paved with claims of necessity.
The answer depends on the circumstances--total amount of driving, relative frequency of each sort of trip, availability of alternate means of transportation, etc. In New York neither makes sense--you take the subway or a taxi.
I live in a city of 300000 people in the Canadian prairies. Around here there's a tendency for a certain type of male to drive ludicrously large pickup trucks (F-350s and such) with gigantic fuel tanks in the bed. Originally this was because they worked in the oil fields and were driving out to well sites, but then I think it became a status symbol. As it stands, I suspect the majority of these vehicles will never leave pavement or haul anything more than a few sheets of drywall or plywood.
And that attitude is why we lost the phone and tablet markets.
No, it's not. The idea that anybody was just going to shoehorn apps designed for a desktop UI is why you lost the phone and tablet markets. Microsoft already taught you that.
"I like to lick butts!" by MobileTatsu-NJG (#32700246) (Score:5, Informative)
Until you get them involved with robotics and they're ready to move past the nxt controller.
I drank what? -- Socrates
Well my kid will have it tough. I'm only gonna give her a coin to flip. And it will have the same image on both sides!
I drank what? -- Socrates
My Macbook Pro gets to the login screen in Win7 in 36 seconds, and within 55 seconds I'm at a file explorer window. I'm pretty sure that the reason it's that slow is the network here.
Although I wouldn't rule out Microsoft silliness, I believe you have a configuration issue. I wonder if you're logging in to a domain like I am here.
"I like to lick butts!" by MobileTatsu-NJG (#32700246) (Score:5, Informative)
Then again, today's programmers would rather import the whole STL just to be able to use one String, rather than take 15 minutes to write their own class. (oops, they couldn't write one in 15 minutes ... oh well ...)
Now everyone is writing their own String class, you have to pay them for that effort. That 15 minutes may not seem like a lot, but if everyone is doing shit like that all the time, the costs will add up. Also, at some point you will want to interoperate with some third party library. Wouldn't it be great if there were some sort of standardized String class so you don't have to convert from your String to their (inevitably screwy) String class? Repeat this for many datastructures and third party tools and libraries.
Higher level languages didn't arise for the hell of it; if we needed to be worried about 128k of RAM, we'd still be writing code like we did in the old days. Now, we don't have to (minus certain domains), so why not trade space for time / money? We make all kinds of optimization trade offs already; ease of maintenance tends to not be one we often think of.
SSC
Posting because this piece of code deserves eternal Kudos:
1K ZX Chess
Full chess game implemented in 672 bytes.
"I bless every day that I continue to live, for every day is pure profit."
Classic computing urban legends... The Knuth quote he attributes to Tony Hoare is denied by Hoare himself, and still itself doesn't contradict my claim. "We should forget about small efficiencies ..."
I am NOT talking about small efficiencies (saving 2 bytes on the stack by reusing a variable in another context). I am talking about the MAJOR ones. Knuth et al is saying "don't lose sight of the big picture by focusing on minor things at the design stage". I am saying "don't screw up the big picture by ignoring performance considerations at the design stage (and assuming they can be corrected by 'tuning' at the end".
It may very well be a configuration issue, but it is Microsoft's issue, not mine! (Yes, domain...)
Is a single sided coin Turing-complete? It's gonna have a wicked truth table.
My Other Computer Is A Data General Nova III.
You didn't know what they meant before.
The 3-ring binder manual alone was a thing of beauty. And new drivers were as simple as editing a text file. Sure, the graphics were limited to 640x200x16 on an RGB monitor, but for its' time, it was miles ahead of both CGA and Hercules. (you *could* get 64 colors to display at once by swapping the palette repeatedly, for example, on each scan line, same as you could display multiple font sizes/colors and sort-of-graphics on a purely DOS text screen by playing with the character generator in real time a la the Clipper Toolkit 3.0).
Then again, there are still people putting out small usable operating systems written in assembler, such as menuetOS that fit on a single floppy.
This is the point where the guy comes by to complain about it taking 17 minutes to copy a 5 MB file on a Mac, right?
the preceding comment is my own and in no way reflects the opinion of the Joint Chiefs of Staff
segment:offset
You'd place a premium on code size too, if you had to deal with concepts such as the code segment, UMA and HMA.
The STL is exactly the wrong target here (and BTW, string is not part of the STL, its interface was "STLized" after the fact). The STL is completely made out of templates, and even if you include everything from it, the only thing which increases is the compile time (that one can massively increase, though). Only the parts you actually use get instantiated.
Having said that, using the STL on many different types can indeed increase your memory footprint because it generates new code for different types, in order to maximize speed. However, for most things few programmers write generic C code (with void pointers and functions to pass in) anyway, so for most things the code duplication would have been there anyway. It would just have been hand-duplicated (most likely copy&paste, maybe macros).
Note that a good STL implementation will factor out the type-independent parts so you get no "unnecessary" bloat. That is, it's not so much bloat, but optimizing speed over memory.
In short: If you speak about bloat, don't take the STL as example. Because the STL doesn't produce bloated code (assuming a reasonably good compiler, of course).
The Tao of math: The numbers you can count are not the real numbers.
Or just made them focus on getting stuff done rather than implementing optimisations no one will ever notice.
I see. You're of the "Ignore the problem" school of thought, just like the Firefox crew. If people don't allow you to that, ask them to just throw money at it.
Either way, this will never be resolved because there will never be software accountability.
Yes. What about when someone gets the bright idea to run 20 of these apps at the same time? Or someone wants to virtualize the host? RAM is fast but it isn't infinitely fast and if 4GB of data has to fly back and forth to the CPU that will add a lot of latency. It all depends on how critical the app is but then again if it isn't that critical you could probably find a random goon on rentacoder for $4/hr.
> No, it's not.
Um, Google didn't just toss GNOME/KDE/Qt/Gtk. They tossed the whole thing right down to replacing glibc because it was too bloated. If they just didn't like the LGPL they could have borrowed BSD's libc. It was the bloat.
Android is bloated by the standards of TP3 but it could actually load and run at an acceptable speed on the original Android phone, which is a feat that nothing based on recent the GNU or BSD software stacks could have done. Nokia did heroic things on the Maemo devices trying to get a Gtk and then a Qt based desktop based on the current plumbing (Gtk, gstreamer, esd, dbus, etc) and failed. Just launching the terminal app on an N770 was several seconds of thrashing. The browser was pretty much unusable.
I actually ran Netscape on a 486 with 8MB RAM and an 8bit colormapped X server and it was pretty responsive. Yes we gained truecolor, html5 and all those buzzwords in years since but should we really need a thousand times the computer (RAM, cycles, HDD, everything) to run Firefox on? That is the question we should be asking.
Democrat delenda est
Could be... I've never experienced that... If it's true, then Apple's got some crappy code too...
Agreed. People are so used to their being an API for everything and automatic garbage collection that they create a lot of garbage in their code and don't even realize it. Then they say something like: Java is really slow, or .Net ... pick the tech. Meanwhile it is no you are recursively creating copies of a large data structure on the heap every time you look up a new value :-) RAM/CPU is a cost people should measure to make sure that they are getting something out of the invested RAM in their app if it is anything other than a trivial app.
You're not getting my point. You won't be successful running your 486-friendly Netscape on your phone. It's not an issue of bloat, it just plain wasn't designed for it. The question you think you should be asking is just a way to keep circling the rat hole.
"I like to lick butts!" by MobileTatsu-NJG (#32700246) (Score:5, Informative)
First, you only have to have ONE person in your org write that custom string class that does exactly what you want, no unpredictable side effects, no bloat.
That 15 minutes pays itself back almost immediately, both in easier debugging (less code to debug) and quicker compile times,
Second, 3rd party libraries are always going to be a problem, but usually you just give them a pointer to (a copy of) the data structure, never to your class. No big deal. I null-terminated string (c-style string) is a null-terminated string. A string with the first n bytes giving the actual size (a pascal-style string, can also be used for BLOBs) is a string with the first n bytes giving the actual size. These are the two standard ways of modeling string data.
It's why we don't have operating systems written in perl.
Plus, someone who can do this sort of thing as a habit is probably going to be producing better code overall anyway.
On CP/M there was no room for bloat. Not much room for bloat on MSDOS. For a couple years I ran CP/M parallel with MSDOS. Had a couple of "do everything" program disks. Slowly MSDOS came up to speed. Now we live in the age of bloatware. Easier to maintain and modify I guess, but it lacks the elegance and speed that once existed.
It's not a matter of losing the ability to optimize, it's a matter of whether the trade-off in programmer time spent optimizing is going to be worth it when we now can easily throw more CPU and memory at a problem.
Since I can't tell them apart, I treat all ACs as the same person.
More often, they use languages which are not merely slow but outright retarded, though.
It's for sandboxing. A lot of environments commonly found on Internet-connected PCs discourage (IE 9's "not commonly downloaded") or even forbid (SRP/AppLocker) running downloaded executables, yet they allow SWF objects to execute in Flash Player.
Try using the STL with threads. It's fugly.
Removing all those calls to STL_LOCK and STL_UNLOCK was a big win. Re-writing the other containers so as not to use the STL was no big deal. It paid for itself just in compiler time savings, and made debugging so much easier.
The STL provides general-purpose functionality. Why bother when you can just whip out a specific-purpose class?
Well, what if there's *multiple* users on that system
That's an important consideration for server software, but for desktop software (graphical interactive software that isn't web-based), how would each user be using the software at once? Most PCs don't allow for multiple keyboards and mice, one for each user, and dedicated X terminals aren't popular anymore either.
How the heck did they implement a grammar parser and lexer in 40k, let alone a compiler?!?!?
I suck as a programmer.
https://www.accountkiller.com/removal-requested
Old P4 motherboards can be usually be cheaply upgraded to 1 GiB or 2 GiB of RAM. Many P3 motherboards cannot, many maxing out at half a GiB, especially those made before SDRAM became DDR.
I don't think that is why Linux lost. Linux IMHO lost on the netbooks because they couldn't get a simple debugged interface that small done quick. Far too many apps had assumed a big screen, and while everything was modifiable it wasn't easy or simple and in a timeframe of months,,, they just didn't make it.
I think it is uncool to praise RIM right now, but I think they were right about QNX being the right kernel for phones. They couldn't execute in time but they had the right choice as far as going with a RTOS with recovery, fast and a small footprint.
As far as userland.... First off XFCE is the 3rd biggest. It is just 10% of the size of KDE or Gnome. I haven't played with ROX much but that desktop is about the size of Windows 3.1, so ... there are still some Linux desktops that are small. LXDE is very popular, I have used it and it comes in at a few megs.
That's interesting. I have this "black screen blinking cursor" on my moms new computer. Takes a (felt) eternity before it switches to the Ubuntu logo and then boots in a blink of an eye. The system has an SSD system disk. I just guessed it was the BIOS being slow. I should really look deeper into that.
Ahhh...the great dumpster continuum. Many a free computer will be found there. -- sowth (748135)
I learned Pascal first as well. I never had a problem with pointers. Perhaps you merely had trouble the first time (Pascal) you were introduced to the concept and it made more sense the second time (C) you were introduced to the concept. Look at the following code, do you really see some conceptual difference? Could it really be that you did not understand the nature of a variable, or the nature of memory in general? At the time I understood that a variable is just a location in memory, that memory held numbers, and that numbers could be program code, variable, screen data, etc.
:= 42;
Pascal
var p: ^integer;
new(p);
p^
C
int *p;
p = (int *) malloc(sizeof(p));
*p = 42;
I agree with you. Of course Microsoft could help fix that by offering a clean version of windows for anyone with an OEM license....
It is a very old meme, the famous Kottke I-don't-want-a-holy-war-here post, and it was a 17 meg file, over 20 minutes. On an 8600 in 1998.
Don't blame me, I voted for Baltar.
To be honest, I think the reason the tablet and phone markets were "lost" (if they were/are) is NOT because of developers not optimizing, but because there wasn't a focus on the end-user experience.
Sure, reducing bloat will speed things up a little, but it's not just about speed and responsiveness. For example, look at Siri and the response from many in the android community:
"It's just a chat bot with speech recognition and the ability to work with other apps! Android has had all of those things forever!"
Then why weren't these things integrated into something useful for the end user if it's so obvious? Answer: Most android developers simply don't think like an end user or prioritize user experience much, much lower than it should be.
And it happens *repeatedly* - techie types keep forgetting that they're making tools for people to use, and that the people who are users rather than makers of tools don't want the same things makers want.
Bloat has little, if anything, to do with this whole thing.
And I do want to say, Apple does a pretty good job supporting the makers of tools as well - I develop smartphone apps, and my experience developing for iOS (and marketing my apps) has been vastly better than my experience developing for android. Again, it's the user experience - there's tons of support for iOS developers, there's good support for marketing and the business aspect, and even though the approval process can sometimes be bizarre, I will take selling via iTunes over the android marketplace anytime, and so will the vast majority of my paying customers.
Again, bloat isn't the issue. The geek in me wants to see more elegant solutions than "just throw more power at it" but I also know that ultimately that's not super relevant, ESPECIALLY as low power phone hardware is getting more and more powerful and any performance limitations are made less and less relevant.
Since I can't tell them apart, I treat all ACs as the same person.
First, you only have to have ONE person in your org write that custom string class that does exactly what you want, no unpredictable side effects, no bloat.
That 15 minutes pays itself back almost immediately, both in easier debugging (less code to debug) and quicker compile times,
I wouldn't say it's less code to debug, but more, because now you have to maintain your string class.
Second, 3rd party libraries are always going to be a problem, but usually you just give them a pointer to (a copy of) the data structure, never to your class. No big deal. I null-terminated string (c-style string) is a null-terminated string. A string with the first n bytes giving the actual size (a pascal-style string, can also be used for BLOBs) is a string with the first n bytes giving the actual size. These are the two standard ways of modeling string data.
These are the standards, but Crazy Ass Corp Super Deluxe Hyper-whatever Library is going to do whatever you're not doing, and in a way that you can't just point to the internal C string. Never underestimate vendors: instead of your nice, 1960s style null terminated array of 1-byte characters, they're going to an array of 64-bit integers where they've packed in multiple 8-byte characters, but have decided to leave the last byte of each 64-bit integer as 0xFF for future use and they use EBDIC. Yes, this example is highly contrived and nonsensical, but never underestimate the inability of your colleagues to write software.
This doesn't even touch on the STL's various algorithms to e.g. loop over all characters in a string and perform a function. Again, it's easy to write it yourself, but the STL is written in a nice, general fashion that makes it easier to interoperate, makes it easier to understand what is going on, and doesn't require you to continuously reinvent the wheel. Yes, once you write your BetterString class, you can reuse it, but over time you will keep adding functionality to it until it becomes std::string, and your office on the other side of the country may not know and may have written their own, etc.
But you don't pay for it over and over again: your target audience is running machines with at least 512MB of RAM, very likely 1GB of RAM at least, and many will have at least 2GB of RAM. Saving, say, 100K of RAM by not using the well defined library string class is not a useful optimization, outside of more specialized problem domains. Outside of your underpowered embedded type systems or extreme high performance game with custom memory allocation or massively parallel real time trading application where each 0.000001 nanosecond of delay costs you trillions of dollars, that 100K is dwarfed by every other facet of your program for anything nontrivial. Grandpa's PDP-11 can't even run your target OS(es), why do we care that our program might be RAM-lean enough to fit in its memory?
SSC
There's a difference between ruthlessly efficient code that squeezes every last drop out of the hardware vs. relatively efficient code that's good enough vs. what the fuck were these people thinking ridonkulously inefficient code that has so much extraneous cruft in it that it that it strains cutting edge hardware for even mundane tasks.
I agree that the ridiculously inefficient code shouldn't be allowed, but I don't think that ruthless efficiency as in the days of old is actually worth it at this point - in the olden days it was cheaper to be super efficient because hardware was expensive, now it isn't.
That said, I think any developer worth their salt should at least be familiar with optimization techniques so that when new platforms with more limited power become available (smaller devices than phones, etc.) they can be efficient. But it's not something that is worth it by and large for the vast majority of uses out there today.
Since I can't tell them apart, I treat all ACs as the same person.
Actually it's your sysadmin's issue. Go talk to him.
"I like to lick butts!" by MobileTatsu-NJG (#32700246) (Score:5, Informative)
When it comes to desktops, laptops and even small sets of servers, I'm agreeing. BUT I'd posit tight code matters now MORE than it did then; it just doesn't matter so much in desktops (or laptops and even newish smart phones) much any more. There are a lot of price-sensitive micro-controller devices in this world. It can also matter, perversely, in really large server farms. If you need to update 10,000 machines, it's nice if the update is relatively small. As for efficiency: if you can get by with 9,000 machines instead of 10,00 machines...that's an optimization worth doing.
Here are more examples of pointer arithmetic using Pascal (extensions).
Did you strip that executable?
Yes. Stripping is implicit in conversion from .elf to the actual executable format of the target platform (.gba) using objcopy. So that's over 180,000 bytes for a minimal iostream program using GNU libstdc++, with strip, with -Wl,-gc-sections.
As for adding functionality - you don't. You either create a separate independent class, or derive from that class, and add functionality. So again, not a big deal. Quick and lean, easy to maintain, and no hassle debugging in a multi-threaded environment.
As for your "why bother"? 400 threads+100threads+400threads (not a contrived example, but from real life, as in - "been there-done that"), each adding both the bloat of the STL and the unnecessary locking/unlocking (and getting rid of the SmartPtr class was also worth it, but that's another story) for a lousy string class is not trivial, not when compared to a couple hundred bytes extra per instance for a simple home-made class, and not compared to performance overhead.
It's funny - I spent something like $80 buying the TR1 hardcover documentation, and having read it 3 times, I *still* think it was $80 that was mostly a waste of money. (Not completely - it at least looks good on the shelf, but that's about it).
But you go ahead and keep using the STL. One person's garbage is another person's treasure, YMMV, it's like vi vs emacs, etc. There are probably valid reasons for going either way, depending on the resources available and the task at hand. If it's something you're only going to run once in a while, and performance isn't critical, use whatever floats your boat.
in the embedded world one tends to strip unused functions and debugging info to get the code size down.
So in embedded C++, what implementation of the C++ standard library tends to get used most often? I've been told GNU libstdc++ isn't the best choice in a size-sensitive static linking situation. Or maybe embedded programmers just tend to shun iostream; is that true?
Which implementation? Normally the STL should not need any threading constructs at all because it doesn't use shared data structures. Locking shared use of the same STL data structure is the user's job.
The Tao of math: The numbers you can count are not the real numbers.
My machine boots win7 pretty fast... but the worst startup offender is Windows Live Messenger. Man, that thing is bloated. And I'm using the 2010 version. The newer one has facebook integration and all sorts of useless shit.
Check the boot order in the BIOS - it's probably waiting for a CDROM or USB device to settle.
So managing a collection such as a thread_pool or gather/scatter array requires locking.
The bloat is coming from manufacturers that put a lot of unnecessary crap/features into their hardware/software. For example, the "phone home" feature, to get updates, or usage statistics. As a general rule, that is the stuff sucking up your system resources, not some developer's poor choice of a sorting algorithm. We shouldn't be wasteful with system resources, but as the original poster said, sometimes there is just no need, or time, to go through an optimization exercise to cut your memory footprint by small percent.
And another thing commonly blamed for "bloat" is simply using faster, more memory-intensive algorithms. If I can apply a 512MB data cache to an app to cut its runtime from 4 hours to 8 seconds, I'll do it in a heartbeat and without apologies. I also use memoization where appropriate, hash tables instead of lists when I'm going to have to search for keys a lot, and other data structures that spend some RAM to buy performance.
There are instances of real bloat out there, but RAM usage alone isn't any indication whatsoever of a sloppy codebase. Maybe the author just made design decisions that optimize for parameters other than saving ever bit.
Dewey, what part of this looks like authorities should be involved?
I did not imply that there is a hard and fast rule. You always need to consider how your program will be used. What I do mean is that I think it is alright for a developer to use his head when deciding how to spend their time (with advice and consent of senior developers). If your program is using 4 GB of RAM, and virtualization, or concurrent processing is likely, then spending a day to reduce your memory food print is a good idea. On the other hand, if your app is down in the 200 kb range, then a significant time spent may not be worth.
Also, I am not advocating a "get out of jail free" card to developers, just because hardware is cheap. In the mobile arena it isn't. I am just saying look at the bigger picture. The programmer writing a banking system to process thousands of transactions per second is going to have a different perspective that the programmer writing a web application that searches song lyrics.
Exactly: The *user* does the locking. Therefore the locking constructs are not in the STL, and therefore it cannot be bloated by them.
And the usage of "not thread safe" in the quoted text is strange: According to that logic an int is also not thread safe, because two threads cannot access it concurrently without locking.
The Tao of math: The numbers you can count are not the real numbers.
Go tell that to to the originators of the STL, SGI. They would disagree.
The boost STL documentation makes the point that it is NOT aimed for high performance
http://www.boost.org/doc/libs/1_43_0/libs/math/doc/sf_and_dist/html/math_toolkit/main_overview/perf_over.html
How do you like them executables, I got her PE header!
One of the first things I did... Set the SSD first. Didn't change a thing. I just wonder if it isn't grub that is trying to show its menu but doesn't output anything and waiting for a timeout. As I'm not all that often at my moms place, I can't check right now (well, I can login by ssh, but that won't give me real answers :-) ). My bet is something that delays grub for some reason. It boots, so it's no big deal... Still, annoying. It's very new hardware (Gigabyte GA-A75-D3H with AMD A6 CPU), and I have one other issue with the sound crackling under Ubuntu. Fixes I've found by Googling didn't fix the issue. Not a deal breaker, but annoying.
Ahhh...the great dumpster continuum. Many a free computer will be found there. -- sowth (748135)
Do you know why things have become so bloated?
1. Larger address spaces. That has nearly doubled code size. The 6502 used in the Apple II was 8-bit and could address only a 16bit space, 64K of memory. Instructions were much smaller. A 3 byte instruction (1 byte opcode plus a 2 byte address) could do a load/store anywhere in memory, and if that wasn't good enough, it had these "zero page" 2 byte instructions that accessed only the first 256 bytes of RAM. To do random access anywhere in a 32bit, 4G address space takes a 5 byte instruction. Now with RAM creeping over 4G, need even bigger addresses. The x86 architecture used this "segment" idea to work around it. A 32 bit address was split into 2 16 bit parts, with the high half in a "segment" register, and the low half in the instruction so that instructions could still be 3 bytes. But it was necessary to change segments constantly, so this idea didn't help much and sure made life rough for compiler designers. Borland C++ was notorious for bungling the handling of segments.
2. Bigger numbers. Used to have limits like 32767 all over the place on game scores, spread sheet cell numbers, and such. And there was the infamous Y2K bug. Now use of 32bit integers is standard, and 64bit integers are common. Doubles or quadruples the number of bytes needed for math.
3. GUIs. We went from terminal I/O with printf and friends to specifying dozens of options for window layouts, and keyboard and mouse event callbacks. Just dealing with typical resolutions forced the use of bigger numbers, as we went from 80x25 which fits in 1 byte each, to 640x480. Quite likely that some ancient terminal software cannot handle more than 256 columns. The big memory user is of course graphics. An XWindows "Hello World" program in xlib is insanely huge, at over 100 lines. Things have gotten better, but still nowhere near the 1 liner for terminal I/O. Even when a program can create a pop up window with one line of code, it still requires huge libraries.
4. Error checking and security. We don't live as dangerously as we used to. Can trim quite a bit of code if you don't check for buffer overruns, array bounds, numeric overflow, stack overflow, running out of memory, pointers out of range, etc.
And yes, less attention is given to memory usage. Not worth our time to sweat over a few bytes. But I wanted to point out that there are good reasons why code has increased in size, that it isn't all programmers being sloppy and wasteful. If Turbo Pascal 3 was recompiled for a 64bit machine, it would certainly be much larger than the original binary.
Intellectual Property is a monopolistic, selfish, and defective concept. It is "tyranny over the mind of man"
On Windows 7 I was able to download an OEM (not the manufacturer specific one) CD image for Windows 7 Home Premium, and use my Product Key directly. As far as I know, there are no special product keys in windows 7 that only work with a special disk from your manufacturer. Granted I had to go TPB to get that OEM image, but my key worked perfectly fine, and I have had no problems getting my computer to verify as genuine. Sure they could provide a way for people to download the CD, but I think they did pretty good this time around, not half as bad as XP, where your "key" would only work with manufacturer specific disks.
Anthropic principle: We see the universe the way it is because if it were different we would not be here to see it.
Now extend this to a string. Doing anything that depends on knowing the length of that string (searching, appending, prepending, swapping, reversing, COPYING, etc) needs to be locked. So you end up having to lock on a read because, well, it's the STL and you don't have the same guarantees as if you wrote your own. So rather than lock on just a small section, if using the STL you end up having to go with more coarse-grained locks because otherwise subtle bugs emerge under load.
The STL is not the optimal solution. You can use it, but for a multi-threaded app I won't. It's simply not worth it. That's not to say it's not worth it for YOU. After all, YMMV, you may not be the one stuck fixing something that works fine with 5 or 10 threads but not 500, or whatever.
And STL_LOCK and STL_UNLOCK have been part of stl_lock.h from SGI (the inventors of the STL) since 1998, so they ARE part of the STL by definition. More modern implementations may have replaced them, but the function is still the same - to ensure that only one thread at a time has access to critical parts. And now that we've moved to multiple cores, it's become an even bigger problem since we now have to lock across cores.
Try those "in4k"s without DirectX, OpenGL or Windows underneath.
I'm not sure why Turbo Pascal gets such a bad wrap with people. This isn't Visual Basic we're talking about here. Some really successful games were written in it. Anyone remember Legend of the Red Dragon, and every other BBS door game Seth Able ever wrote? Turbo Pascal. Lots of BBS games were written in that, as a matter of fact, because there were some very good serial/modem handling libraries available, and the bounds checking of the language made it much more stable to run on such a platform. Oppositely, one of the more well-known BBS games to be written in C, Exitilus, was notorious for its buggy and unstable code.
After I learned C, there was no going back despite my fondness for Pascal. But it still formed the foundation of programming practices for me and surely countless other people. The integrated help was absolutely priceless to my learning, because I would sometimes just spend long periods reading through all the different entries and see how features could benefit what I write. I learned of I/O ports and direct memory access to hardware that way, which greatly improved my understanding of how computers worked at the time. Aside from the helpful built-in bounds checking (which I believe could even be disabled for efficiency), there wasn't much performance loss, particularly when you accessed hardware directly rather than go through graphics libraries. It could be as powerful of a language as you wanted it to be, while still simple and intuitive enough for somebody's first Hello World program.
I'll stop fawning over it on my way down memory lane now. But I still feel it's a shame that we're at a period in computing where learning the fundamentals of the hardware for a beginner is completely lost under a spiderweb of APIs.
I've just gone through the book. That "computer" is fine, but it is a completely manual affair. I posit that all the lights and other stuff are a distraction, it'd be easier to do it on a well designed set of paper forms -- some for storing contents of memory and registers, some for performing individual operations. If all instructions are very simple, you can have one sheet where you write down clock cycle #, PC, value(s) at PC, values of inputs, work out the decode, work out output, and write that down. Any changes to ram etc. are then annotated on the ram/register sheet, perhaps with a column per each address so that you simply write down the newest value under the previous one. For tracing purposes, you could be writing clock# at which the value was written next to the value, that way your paperwork is a complete trace of execution and if there are errors you can see how they propagated and can fix them.
I think it'd be way more fun to build a very simple relay-based machine. You can still wire it point-to-point, and you can still use incandescent lamps for indicators :)
A successful API design takes a mixture of software design and pedagogy.
Setting the SSD first is not enough - if you don't boot from the other devices, actually disable them (or does your BIOS let you do that?) On my Intel board, I've disabled boot from floppy, boot from USB, boot from CDROM, etc... The BIOS won't wait for the devices to settle then. The POST on my board went from 15 seconds to 5 after I did the above.
I had the blinking cursor problem too until I did it, it's almost like the BIOS waits for all the damn devices to be ready before it boots...
Those are only 4k if you don't count the megabytes of libraries and drivers they require to run. Not to mention that they usually consume a ton of memory while running.
Mada mada dane.
> But some don't even give it a first thought and thus you wind up with Java programs that require 1GB of RAM simply for the purpose of moving files between folders (I'm not exaggerating).
That seems... unlikely. What was the name of this program?
Performance needs to be considered at the design stage
Considered, yes. But beyond obvious choices like quicksort vs. bubble sort, you need some profiling data to back the need for further optimization. Performance is also a tuning process. For example, I wrote a basic AI search a while back, and received a very optimized version of a scoring routine. I decided to implement a more generic algorithm at design time, though it was twice as slow. I deliberately made the tradeoff since I was able to implement Erw in an abstract base class, and write the specific problem in terms only of its constraints. I justified the slowdown by solving the generic class of problems, rather than worrying about top performance in the specific problem. And, in practice, this approach worked extremely well - the performance was near the top of the class.
I'm not sure why you're being so trollish about this topic. You're clearly competent, yet you write like a teenager. People might understand you better if you were more academic in your writing.
"Please describe the scientific nature of the 'whammy'" - Agent Scully
If someone says "gigabyte" you still don't know for certain if they mean the SI or the binary nomenclature. Similarly, apart from the binary nomenclature sounding like Del Monte dog snacks, it is esoteric enough in many settings that you still need clarification before you can trust that the person who said it really knew the difference and didn't just copy the notation from somewhere else without really understanding it. Had they laid all this out from the start it would have been great but the old system is so entrenched getting people to abandon it would be like asking people to stop calling expanded polystyrene Styrofoam. I treat both forms as ambiguous and in situations where it matters I'll still ask for the value in bytes before I allocate or access a buffer of that size.
Account -> Discussions -> Disable Sigs
I have a fatal personality flaw in that I treat people exactly at the same level they treat me.
I'm not even talking about quicksort vs. bubble sort. That's still a nuance. I'm talking about taking a step back to even *recognize* that sorting will be required and that sorting efficiency matters...
Borland Turbo C.
Don't know what it's overhead was, didn't matter, it did the job i needed.
And anyways, we are talking about DOS programs comparing them to modern Windows programs.
You have a UI and other crap built in with Windows that you had to do yourself in Turbo Pascal/C.
Memory managment? I know Turbo C didn't do it, so I doubt very much Turbo Pascal did.
ya, it had a smaller footprint, but it didn't have to do as much, unless you programmed it in.
But I do agree alot of software is pure bloat these days, and I figure it's because the dev's don't care. They got 16gb in their machines and they expect everyone else to be like them.
Be seeing you...
XD you must have broken something. Three minutes and a half? Either you have that installation really bogged down with random crap, or the MacBook Air is a really bad machine.
Oblivion Awaits
Interesting (and fucking stupid BIOS behaviour). I will try that out when I'm at mom's place. Won't be in a few, but I will keep it in mind. I hope it helps. Thanks in advance for your input.
Ahhh...the great dumpster continuum. Many a free computer will be found there. -- sowth (748135)
You can do sandboxing a whole lot faster than that 5-6 orders of magnitude slower than native.
And that's what Google Native Client is supposed to do. But I don't see it spreading anywhere outside Chrome, especially not to corporate-standard Internet Explorer.
It's definitely less, because a simple string class that only allocates a string buffer, appends to it, frees itself when it goes out of scope, and is guaranteed to always has a proper none-null value (even if it's only 1 byte, and that byte is itself null) is easy to "maintain". There's really no maintenance once it's done.
You have just described a string class that will result in heap fragmentation and performs horribly under multithreaded scenarios. Well done.
Furthermore, if you've spent less than an hour on this, I simply refuse to belive you have the functionality needed for real-life applications, especially not since such a core class should be fully unit tested and documented.
In other words, how much of your companys time have you wasted, and for what gain? Especially considering you'll have to pull in libc and libc++ anyway because 3rd party libraries depend on it? Not mentioning the overhead in converting back and forth between string representations?
(Note that I'm assuming standard environments here, not embedded systems.)
Coffee-driven development.
So rather than lock on just a small section, if using the STL you end up having to go with more coarse-grained locks because otherwise subtle bugs emerge under load.
You honestly don't believe that handling thread synchronization at container/primitive level is the right thing to do, do you?
You honestly don't think it's good architecture even needing a lot of locking in parallel code, do you?
Coffee-driven development.
I call BS. You can't even get through the BIOS bullshit on a Dell in 15 seconds.
Depends on the system, really. Apple systems have the advantage of using EFI instead of BIOS, which cuts out a lot of legacy crap. There's (u)EFI non-Apple PCs around as well, though, even if they're not widespread yet. And yes, Windows has been able to boot that way since at least Vista64.
I don't really get the obsession with boot time for PCs (whether they're going to run OS X, Linux, Windows or whatever) - I boot such devices relatively slowly, and use either standby or hibernate throughout the day.
Coffee-driven development.
Bloat. Ugly word. Conjures up visions of swollen corpses.
In the early 1990s, I had a 386 system which was loaded with 14MB of RAM. On this system, I had NFS server & client connected to numerous other boxes, OS/2 PM session (typically running PMDraw, Gnuplot, NewsReader/2, Gopher (later WebExplorer), and some CMD.EXE shells), both full screen and windowed Win-OS2 sessions (typically MS Word and suchlike), and an XFree86 session (I forget what it ran, but it was probably important) running simultaneously. In 14MB... and I thought that OS/2 was bloated at the time.
Going back a bit further, I ran classes using a PDP-8 which was loaded up with 16Kwords of memory (1 word = 12 bits). It was multi-user and multi-tasking, and the kids wrote programs in Focal over teletypes. These were all text-based interfaces, naturally, as there was a maximum of 4Kwords in the memory space of any program (including the compiler). Not much bloat, well written manuals documenting everything.
I better doze off in my wheelchair again, now, and drool some more. Otherwise I might reminisce on the multitasking real-time OS I helped write for 8085 systems in the early 1980s using 32KB ROM and 32KB RAM, and which got used quite a lot in industrial control systems (some of them were still running in 2005). Each station could only handle a couple of hundred analog control loops and a few hundred digital I/O with some ladder logic. Shit, they use a PC with a GB to do that nowadays.
The corpses from yesteryear generally look slim. It's the currently living systems that are swollen.
Those who can make you believe absurdities can make you commit atrocities. - Voltaire
Yes, actually, it is worth the time to shave 20% off the memory usage, because now that app can scale 25% larger [ 1 / ( 1 - 0.2 ) ]
Perhaps what we need is better tools to help identify opportunities for such optimization. We can do a lot of it using current profiling tools, but those don't run on production systems. It would be humbling to see exactly how many of those 64kb "just in case" string buffers actually get used to store a 2-byte Unicode character.
This is a big part of what made Pascal, and other compiled languages of the time, so damn fast. They didn't bother with the "just in case" scenarios, you want a string ? How big you need it, 2 bytes ? DONE! No epic stack protection needed, this string is 2 bytes long, end of story. See, I'll even store a 2 next to it so all the string functions can trivially check the size. C-style nul-terminated-strings-of-doom were implemented with the AnsiString class, which used a pointer on the heap and would happily let you poop all over it, like all good pointers should. It was also uber-fucking-slow compared to native fixed-length strings.
That's just one inconvenient thing modern languages have abstracted away. What used to cost about 15 clock cycles (in the 386 days, less now), was turned into a probably 2000-cycle recital of bounds checking, pointer dereferencing, cache invalidating, memory row hopping, resource hogging, cpu chugging boilerplate code.
-Billco, Fnarg.com
Desqview... thank you for bringing up such awful memories. I remember lusting after that stupid thing for so long, only to discard it about 20 minutes after installation.
OS/2 Warp ftw.
-Billco, Fnarg.com
A lot of people are saying "I would fire the guy who writes his own x function". That is sort of a valid statement, but you have to consider that is also 99% of the problem with bloat. Say for example I want to md5 something. I could pull in a basic MD5 algorithm, slow but functional in a few hundred bytes. Want it faster? Then add some tables. Or you can just go with the really fast one built into openssl. The problem is you just pulled in another 1M+ of code you have no need for. Sure demand paging then turn around and removes it, but the page table entries, linker fixups, etc are still being created. Multiply that by a hundred or so libraries any non trivial application is using and, pretty soon your looking at a base VM size of a few tens or hundreds of MB.
There is also a lot of hidden functionality in applications today. Consider Unicode capable string functions, network communications code, etc. This is part of the joy of phone/tablet development. You can create an application without all the crap and get away with it.
I described the most naive implementation possible, for simplicity. In reality, you normally alloc() a decent-sized chunk, and only realloc() as needed to grow. You can also use that technique to stuff multiple strings inside one chunk. This is an old technique, used by (eg) Borland back in 1995.
Believe what you want - once you've implemented the same basic functionality from scratch a few dozen times, it's not all that hard. Really.
For cstrings, there's NO overhead, even with multiple strings stuffed in a single alloc(), since you just pass a pointer to the head of the string, and when it hits the first embedded 0x00, it's good as far as strncmp, bsearch, etc are concerned.
I think the beef is that even importing that simple String clas results in a whole mess of dependencies tagging along for the ride, when all you wanted was a goddamned String. Compilers can only discard code that's not actually referenced, but the tendency is to have everything depend on everything, for the sake of some marginally useful feature that you may or may not use.
-Billco, Fnarg.com
No, because not all accesses require that the container be locked, whereas some accesses require that locking be done at a higher level to avoid deadlocks.
Also, I definitely do not believe in SmartPtrs, because they can always be eliminated by looking more closely at the problem. And lets face it - if you're coding in c, you have to go my way anyway, since the STL isn't even available (though you can still create your own "classes" - you just have to pass this explicitly as the first parameter, and you have to explicitly call any parents you want to inherit any functionality from - not a big deal).
Turbo Pascal was among the first languages/systems I ever coded in. Stunningly fast and capable in an age where Microsoft didn't have a clue, Borland went on from this to produce the Turbo Pascal for Mac (apparently now written out of Mac history - most people don't even know it existed, left Apple in its dust) which was similarly blindingly fast, Pascal for Windows (first Windows system I ever coded on, far better than the Microsoft offerings) and finally Delphi which wiped the floor of anything Microsoft produced on Windows for a decade - Visual Basic was truly pathetic in comparison.
But somewhere around Delphi 2 or 3 Borland started to loose its way. Sure it continued to be good up until Delphi 7 despite Microsoft progressively catching up, but then came the 'we don't want to be a software development company' fiasco of 'look we're Inprise, or look we're Borland again, oh look we want to sell **anything** but the best thing we ever produced'.
True Embarcadero do seem to have rescued Delphi somewhat, and it will probably have some sort of ongoing future, But back in he day Borland nearly owned the development space, and it though it away because it took it's eye off the ball and its vision faltered. Simply a tragedy.
That would be the good old Adaptec 4000A. I still have a few of those laying around. Near some Seagate and Micropolis MFM drives. Yeah, in a box with an ICD 256K MIO and an Atari 130XE for a BBS system. Ahhhhh, the good old days.
Programmers have lost the ability to optimize.
Or maybe they're optimizing for performance instead. They're often quite contradictory.
With harddisks in the TB's in size and running in several GB of RAM, executable size is hardly an issue nowadays. Including optimized paths for different CPU's/GPU's is a much more productive way to spend development time.
One has to wonder how much potential performance gain that old Turbo Pascal is lacking due to having to fit in a small executable size.
Slashdot social media options: AIM, ICQ, Yahoo, Jabber and Mobile Text. Why no MySpace?
Fun times the first time it actually worked!
On my (still working) 6809 GIMIX system:
I have almost a thousand programs on that system, including cross assemblers, languages, etc... it's very rare when one is larger than 16k. And that machine ROCKS. That's because the 6809 was hands-down the best 8 bit bus CPU ever crafted, and the GIMIX frame, with everything from motherboard to power connectors and sockets gold-plated, ferro-resonant power supply, awesome steel case... probably won't die in my lifetime.
Even if it does, I wrote a complete 6809/OS emulation (with permission from the OS authors and GIMIX themselves) and have all that software running on modern hardware, too, even the graphics. Fond memories. I developed a lot of hardware and software on that machine, particularly early arcade systems for Centuri, Bally-Midway, Arcade Engineering and Techstar, as well as early SSTV software for amateur radio. Those were fun days!
I've fallen off your lawn, and I can't get up.
One more thing: A class you write is something you can debug and maintain; classes in black box libraries aren't, and when you run into bugs in them, it's a huge problem. With your own class, you just fix it and move on. For me, that's the most important reason to avoid black box code and write my own. Bloat isn't much of an issue these days, but bugs are and always will be.
I've fallen off your lawn, and I can't get up.
Your math seems wrong. This page is currently 574KB of HTML. An Apple II 5-1/4 floppy could hold about 70 2K pages of text, 140KB.
Man, you really need that seminar!
Programmers have lost the _need_ to optimise for space in the general case. There's a difference.
You'll notice people generally no longer keep weeks or months worth of food in (or near) their houses, either. Same principle.
1.2 MB floppy disks? Wrong end of the decade. 5-1/4" disks of the era held 180kB (360 kb only if you were rich). The 350 comments on this page right now would have to average less than 515 characters each to fit, or about 85 words.
Don't argue ancient computing history with those of us who lived through it.
John
The very first computer class I took, the teacher had us emulate a computer using graph paper as memory/accumulators/stack, and ruled paper as storage.
I was thinking something a little more hands-on for my son. Relays are cool, but if you have big toggle switches and lights you can really see what's going on. I also have those old Radio Shack science fair electronics kits that were a blast - he'll have a lot of fun with those.
My Other Computer Is A Data General Nova III.
Given the OP's talk of "both sides", and a game that was for the Apple ][, my guess is he was talking about single-sided, 140k 5.25" floppies.
So still a bit bigger than just the text on this page, but not that far off.
Relays do not exclude toggle switches, but with the paperclip computer you had to execute everything by hand, there was no automation of any sort.
I think that you'd want something that's designed to visualize and allow manual overriding of any function block inside the CPU. Say you can be a manual accumulator while instruction decode and sequencing and memory is automated. Or you can be the instruction decoder. Or you can do every single thing.
Unless you really want a lot of clickety-clack, you could cheat a bit and design the UI on pc-boards, but have all the logic running on a small microcontroller. I'd think that memory and CPU state should be visible, so that there would be plenty of LEDs. The LEDs and switches and required large PC-boards will already cost a good bundle by themselves. Even if you don't want PCBs and wish to do point-to-point wiring, it'll take quite a lot of time to do it. And you better learn how to lace those wire bundles :)
There are cheap electromechanical relays (less than 1 USD each) but you'd still need quite a few of them. A fairly basic machine with, say, 256 bits of data memory/registers and most basic instruction set would still require about 1000 relays, and this still doesn't cover any code memory. Probably 512 bits of data+code storage is enough to cover the basics... It's not going to be cheap.
The paperclip version is, IMHO, a total waste of time. It'd be better, IMHO, to start with paper-based version, and code up something simple like drawing a bitmapped circle. Executing the code to draw a small circle that way (say 16 pixels across) by hand should take about an hour if you're good at mental math and can avoid mistakes. To make life easy, you can design it to have bit-addressable memory with row address and column address in separate registers.
A successful API design takes a mixture of software design and pedagogy.
It would be nice to code everything from scratch because of the control you have over bugs and performance, but it's not always very practical. The reason you use a black box library in the first place is so that you can save time by not having to reimplement all of it's functionality, which allows you to focus on coding the core functionality of your program (instead of first having to recreate a bunch of base classes). The library's developers also may have found solutions and/or optimizations which you may not have considered (because that functionality is their whole focus), they've already put the time into it's development so you don't have to.
The clash of honour calls, to stand when others fall.
Please. Don't argue ancient computing history with those of us who made it.
Below the Root was released in 1984. At that point in time, I was just getting my bachelor's degree. At MIT. In CS. Course VI. Lab for Computer Science. (I wrote 8-inch floppy drivers in high school for my father's company; I worked on Zork as an undergraduate.) 5-1/4 inch HD floppies were introduced the year I graduated. You are probably correct that "two sides of a 5-1/4 inch floppy" in 1984 were more likely to be 360k (single density). My analysis stands, however: at 2000 characters per page (which is generous), that would allow 180 pages per two sides of single density floppy. That's more than just a "few" comments.
So, again, your hyperbolic statement is false.
Put my fist through my alarm clock with its ding-dong death inside my ear. - The Blackjacks.
Relays do not exclude toggle switches, but with the paperclip computer you had to execute everything by hand, there was no automation of any sort.
Right, that's the point. Unless you wire up a light to either pole of a relay you don't know what state it's in. You can look at the accumulator of the paperclip computer and know immediately what's going on. The purpose isn't to build an even vaguely useful machine, but to figure out the nuts and bolts of how a computer works.
Besides, most of the fun of the paperclip computer is building it - hacking together stuff that was never meant to process data. Screwing bent paperclips into particle board and rigging a toilet tissue roll to store bits - the thing is ridiculous on it's face. I was considering automating data input by hooking up the drum to a water wheel wheel fed by a 2L pop bottle.
If we want to get a bit more advanced, as my sig suggests, I have a functioning Nova III in my basement that is programmed in the following manner:
1. Reset to clear registers
2. Initialize system and set pointer to first memory location
3. Enter first opcode/operand by toggling 16 switches on/off/off/on/off/off/off....
4. Increment memory pointer, repeat step 3 until done programming
Eventually you can load in enough code to bootstrap off the drive controller, but I don't have a working Shugart laying around :)
My Other Computer Is A Data General Nova III.
There's a lot of nostalgia in these postings (and on many similar threads) for something about programming that has been lost. Some of the nostalgia is for how hard we had to hurt ourselves to do anything back then, but I don't think that's the whole of the story. Nor do I think this is about size per se. I think something has been lost since the good old days of programming, and it may be more than one thing. I think maybe something has gone wrong.
I taught myself C from the blue-and-white book. (Did you know it levitates, if read by candlelight?) I had one of the original Compaqs with 256K of memory and two floppy drives (hard drives were a year or so in the future). I used the Lattice C compiler. I remember that I set aside 64K as a RAM disk...I think I used it to compile, and that when I really got going, I was swapping out three floppies constantly (it helped to hold one in my teeth). WordStar was my program editor. Heck, I even wrote one of those Mandelbrot image generators that Scientific American published the algorithm for back in the (late?) 80s. The joke was that the Compaq had a small greyscale monitor (actually green-scale)—and the whole point was to create an image with lots of pretty colors, but heck I had fun doing it. It ran for a week to generate one image.
One of the contrasts between the original C language and something like Java, or C++ is that C wasn't simple, but it was elegant. This is not a word you can even use in the same sentence with any of the names of the more recently developed languages. It's important to note that the relative modernity or antiquity of the language in question doesn't really have anything to do with it. For example, BASIC was never elegant, and there were software development environments that resembled straitjackets back in the 70s and 80s too: they were called "IBM shops". So why have we come full circle, and put the straitjackets back on programmers?
The answer I've gotten is that you simply can't have an artful programming environment when you're working on huge software projects: the demands of such projects require a strictly disciplined environment, and languages that take away all the sharp knives that coders could use to cut themselves—or others. Maybe that's so. But how many huge programming projects are successful? Why is there a constant flow of new languages and new programming methods (we could call them "fads")? Maybe people sense that we've gone wrong; if so, they may be looking in the wrong places for solutions.
Great men are almost always bad men--Lord Acton's Corollary
No, my VT-50's 12x80 terminal screen was indeed 12x80. It was an ASCII terminal that did not have dot addressable graphics. It did not even have a lower case font. It's not like it contained rows of pixels in an invisible buffer that were then transferred to the screen, the hardware continually rendered each row of characters a scan-line at a time.
And you've completely missed the point. The point is that while yesterday's hardware was extremely limited by today's standards, by the day-before-yesterday's standards it was still bigger, better, and faster. That Decscope could work at 9600 baud, and even though my acoustic modem was limited to 300 baud, it was still a big step up from the 110 baud ASR-33 Teletype, as it didn't require paper and ribbons. Would I have considered a program requiring a 24x80 display to be "bloated"? No, I'd have considered my hardware inadequate.
So do I care if Eclipse takes 139MB of RAM or 908MB (egads!) of virtual memory? Yes, it sticks in my craw a bit. But would I rather be without it? Hell no! That's like saying a dog's DNA is bloated, yet if I got rid of 90% of it I'd have an earthworm as a pet. It doesn't make sense.
Here's the other half of the argument. If it bothers you to run a 1GB executable, don't. I'm not forcing you to run Eclipse. Go resurrect a Pentium 100 with 64MB of RAM, and play nethack and run Turbo Pascal 1.0. Go wild and trade your DOS 6.3 for OS/2 2.1. Heck, buy an XVGA video adapter. Be happy with all the power that 1993 delivered to the home user. And then you can bitterly complain about bloated applications that you can't have. But as far as I can tell, you're probably not surfing Slashdot on such a treasured gem. Why not? Because you like using the power you have. You enjoy the benefits of the bloat you publicly decry.
Computing has advanced. Either embrace it or go live on the island of misfit PCs.
John
Faster, smaller code, way less bugs than Java. Granted no objects and the like. But it disappoints the hell out of me when I use Java, I don't get the speed or interface consistency that Sun touted so highly, and I get huge stack traces that are mostly useless. And in the end, programmers today have little clue what is actually happening under the covers- not just under Java's covers, but in the assembly code that makes the slow magic happen. And I won't event mention .NET...
Not true (in all cases anyway). I have a Dell L702x laptop which has a UEFI bios and it gets to the windows loading screen within a couple of seconds. When I first got it it was something which pleasantly surprised me so I still remember it. If they make UEFI more common on desktops I hope they add more options to it however because in the dell theres hardly anything there for the user to configure. I can't even set the num lock to boot off.
When I think back to playing vast adventure games, like Below the Root, that amazingly fit on two sides of a 5.25" floppy, but the same game now would probably be written to take up a CD-ROM, even using the same graphics. Programmers have lost the NEED to optimize.
FTFY
If you want a lot of effort with a lot more bang, then perhaps making your own transistors would be a thing to consider, from there you can make gates and stuff :)
A successful API design takes a mixture of software design and pedagogy.
Professor McCloud. What a great guy. Retired after my semester with him. He had a stack of manuals that went up to the ceiling. I was impressed. We had a nursing student in out class, and we all cracked up one day when she asked the equivocal word question : "What does 'invalid command' mean ?"
No, it most certainly should not. That forced nomenclature is worse than what it ostensibly tries to solve.
Forced nomenclature? You think everyone just up and decided that kilometer should mean 1,000 meters? All measurements are "forced nomenclature". You don't get to choose how much a meter is, and if 1,000 meters should be called a "hapimeter", so what does it matter if 1,000 meters is a kilometer, and 1,024 meters is a kibimeter? They're both arbitrary words that are both equally "forced nomenclature".
WARNING! This girl exceeds the MAXIMUM SAFE standards established by the FDA for BRATTINESS
It's why we don't have operating systems written in perl.
Phineas: Ferb, I think I know what we're going to do today!
If my comment didn't sound as good in your head as it did in mine, then I guess we all know who's to blame
Trust me, anyone pedantic enough to use binary prefix notation, will know what it means, and use it correctly.
How do I know this? Precisely for the reason you complain about: they sound silly using it.
WARNING! This girl exceeds the MAXIMUM SAFE standards established by the FDA for BRATTINESS
Size does matter because it churns the CPU cache and registers. Also if you are caching the crap then you have all the fun with cache coherency across instances of the app. So if you are dumb with your granularity you end up hitting all the data to find what has changed whenever you have a cache invalidation message or update.
..your momma.
I agree that the ridiculously inefficient code shouldn't be allowed, but I don't think that ruthless efficiency as in the days of old is actually worth it at this point - in the olden days it was cheaper to be super efficient because hardware was expensive, now it isn't.
What's more, a lot of that old "squeezing the last drop out of the hardware" stuff really meant exploiting tricks that would barely enable you to get the job done by the skin of your teeth, and everybody would marvel that you got it done at all. Those wow-factor programs amaze people with what they can do, but in the world of real software they're a problem because they are usually not in the slightest bit portable. And you don't even need to want to port to a different OS to want your software to be portable; what about when Macs switched from PowerPC to Intel? What about any incremental hardware improvement that obviates the need for your "squeezing the last drop" tricks? Outside the realm of embedded systems, which often don't/can't get upgraded, there really isn't much need for this kind of coding anymore. It should usually be discouraged, in fact.
Breakfast served all day!
First, you only have to have ONE person in your org write that custom string class that does exactly what you want, no unpredictable side effects, no bloat.
That 15 minutes pays itself back almost immediately, both in easier debugging (less code to debug) and quicker compile times,
As a person who's dealt with customized string classes, I can assure you that it's not 15 minutes, and it does not make less code to debug. If we're talking C here, it would make LARGER compile times (as you may or may not know, an existing string library would not need to be compiled, only linked, which is much quicker than compilation). Also, by definition, writing your own string class (or any of your own code for that matter) means more debugging - one doesn't need to debug an existing string library.
Just because the U.S. is a republic does not mean it is not a democracy. Democracy/republic are not mutually exclusive.
The problem is that the problem only exists in your mind. The kind of optimisations the GP is suggesting people should do make no difference noticable by a human nowadays.
I'm not sure what you're on about RE: Firefox, but it's performance issues aren't to do with this kind of low level optimisation - speed issues in applications nowadays are because of much higher level problems, like poorly architected software which can be solved with a refactor, not months of hand optimisations to try and tweak the tiniest bit of memory or a handful of CPU cycles out of an algorithm at best.
It doesn't matter if vendors write the device drivers, the device drivers still have to interface with the OS and that means the OS providing services the drivers can interact with to, you know, do something useful.
Apple has no qualms about deprecating support for older or obscure hardware whilst Windows always does it's best to cope. Windows also supports hardware you see in industry which Apple would never dream of bothering to support. Both have their pros and cons - MacOS X is sleeker and faster as a result, but Windows is more widely compatible, this mirrors the fact Windows can be bought and installed on whatever hardware you want, but Apple maintains a strong grip over where it's OS can go.
Your example of Linux actually demonstrates the point, it lets you manage what you do and don't need loaded. This is why you've always historically had to fuck around recompiling the kernel, and nowadays, with kernel modules. The benefit is that you can tailor it to be fast for your needs, the cost is worse usability- many people don't have the skill or will to go fucking around with that for the sake of an extra minute or two startup time whilst they go make a coffee, to others however it's essential to their setup that systems boot as fast as possible and so it does matter. It's again about tradeoffs, Windows isn't slow just because Microsoft's devs don't understand optimisation like you believe is the case. When new versions of Windows are released and we hear bootup times have improved it's because they finally have actually been able to trim away some of the legacy cruft because it genuinely isn't needed anymore.
But as you clearly have no grasp of the topic at hand I guess I'll leave it there. There's no point arguing with people who just don't know wtf they're on about, but carry on anyway. You're one of those people, in your mind you're never wrong. Even though everyone around you is pointing out quite clearly why you are, all you can do to counter that is to continue to say things which demonstrate your lack of knowledge.
I grew up with Turbo Pascal 3.01, in fact used only that from 1986 (when I was 9) until 1994 (when I finally got a "proper" PC);-) The idea that the entire development environment could easily fit on a 5.25" floppy was so awesome. Fully integrated, complete, fast, it was just fucking perfect.
Turbo Pascal brings together all the things that make software development awesome. Freedom, power, efficiency, elegancy, completeness. It was the culmination of Software Engineering and that made it a huge factor in me choosing to study Computer Science. Which was a good choice;-)
Unfortunately, there's not much available nowadays that equally elegant and awesome. It's all bloated crap now and the actual hardware it hidden behind an restrictive Operating System. So sad. Tonight, I'm going to dig up a 5.25" drive, find a floppy with Turbo Pascal on it and I'm going to create something awesome.
^KD
0x or or snor perron?!
Ah, you too ran OS9 on a CoCo3. I ran a BBS on mine with a Disto Super Controller II wired up to a surplus 10MB Miniscribe + Adaptec MFM to SCSI adaptor. I'd make fun of the DOS Sysops who were proud of the fact they could run Desqview and try to use their PC while running a BBS. You could always tell though, because their system would crawl, hesitating for seconds on menu selections, etc, while doing so, yet mine was fully usable by a caller while I used the console. They had studly 386 machines with megabytes of RAM while I had a 1.8Mhz CPU and 512KB. The OS makes a big difference. And it still does.
Would it be OK if I got off your lawn now?
To have a right to do a thing is not at all the same as to be right in doing it
Linux IMHO lost on the netbooks because they couldn't get a simple debugged interface that small done quick.
Linux lost out on netbooks because Microsoft reduced the price of Windows XP sufficiently to make the cost-saving fairly trivial (twenty pounds or so in the UK) and familiarity won out.
Getting past the initial "does it have Windows/Office on it" objection would have required a material price difference, and Windows just wasn't that much more expensive after MS's manoeuvre.
To have a right to do a thing is not at all the same as to be right in doing it
"What's more, a lot of that old "squeezing the last drop out of the hardware" stuff really meant exploiting tricks that would barely enable you to get the job done by the skin of your teeth, and everybody would marvel that you got it done at all. Those wow-factor programs amaze people with what they can do, ..."
There's something sad here - the old Wow Factor got me interested in computers, "back when it was all fresh and new". Maybe the modern software houses took over, it's been some time since I heard a Wow-type comment about new software. It's almost like all the delighted young hackers grew up and are burning out in their 40's at dull jobs.
Maybe if we looked again at topics that were indeed too hard 25 years ago, but this time we applied some Wow, we might get AI. - That is, if we want it.
My first Journal Entry ever, in 8 years! http://slashdot.org/journal/365947/aphelion-scifi-fantasy-horror-poetry-webzine
I take offense to your under 30 comment. I was taking apart my Pentium 233mHz computer before I was 10. If think your problem with the youth is that those who want to use computers no longer have to know how they work to do what they want
My daughter took apart an iPod when she was six. Ingeniously, it was combined with an experiment on gravity..
You get quite a bang when you throw one of these out of a first floor (UK) window onto concrete paving.
To have a right to do a thing is not at all the same as to be right in doing it
need to optimize. I can't believe we're actually bitching about living in times where computing resources are bountiful.
Yes, and that's why Microsoft Word takes 30 seconds to load, just like it did 20 years ago.
You are in a maze of twisty little passages, all alike.
Some people would still actually need them
If everybody who needs an SUV less often than once a fortnight stopped buying SUVs, automakers would probably use this as an opportunity to charge double because they would become a niche product not as subject to mass market price competition.
Gee, what a great example. So... played with any interpreted languages lately? Do you browse while doing work? Listen to music maybe?
Do you know at all what it was like to use a computer when programs were the size TFA talks about?
"I like to lick butts!" by MobileTatsu-NJG (#32700246) (Score:5, Informative)
I think the change came about because, back then, you could have a single individual do some really neat (and useful) stuff that would push the limited hardware beyond its limits. You also had nowhere near the number of people working on stuff then as you do now, so it was more possible for something really amazing to stand out rather than get lost in the crowd.
Nowadays it takes a team to design neat and practical stuff that has the potential to come anywhere near the limits of the hardware. For things a single individual or small group could make that would push the limits, like improved search algorithms or whatever, they wouldn't just be "neat tricks" but absolutely ground breaking.
For my money, I think the next area with real wow factor potential is going to be fabrication/3d printing. There are some really neat tricks going on - like printers capable of making most of the components necessary to build a copy of themselves, printers making organ tissue, food, circuits, etc. Some of those are really REALLY neat.
Since I can't tell them apart, I treat all ACs as the same person.
Oh how naive they are when they're young :-p
When you've been re-implementing the same basic classes for a couple of decades (custom strings, stacks, queues, linked lists, etc), doing it one more time, again customized to your current needs, is really no big deal.
It's not like you need to provide a whole slew of generic methods "just in case" and debug them.
Also, we're not talking c here, but c++ (implementing classes in c is also easily doable, but you have to remember to pass an explicit pointer to this as your first parameter, and manually call any parent classes rather than have the compiler do it for you to implement inheritance).
If people can't implement (or are afraid to implement) the basic classes that are everywhere, how much can you trust any class they DO implement?
Uhm. Good points, especially relative to Unicode, and especially on least-significant-byte-first systems like Linux on x86, or like MSWindows.
But, ...
Unicode is a kludge. A great kludge, and better than any available alternative, but a kludge nonetheless. So Unicode and UTF-8 or UTF-16 are not reasons for mpt considering characters to be integers.
One of these days we're going to wake up and realize that integers on a least-significant-byte-first CPU/run-time are not integers, and that is the other practical reason for trying to hide the encryption points from their integer representation.
True, characters are not 8 or 16 bit integers, and the "char" type in C, with it's tradition of byteness, is a misnomer. (wide char is not much of an improvement, in no small part because of the silliness with the initial implementations of Unicode being 16 bit encoding points.)
But encoding points are integers. Integral values, if you must, but they can be treated as integers, which is very fortunate, because we would not be able to use computers to work with characters otherwise.
Yeah, we use basic arithmetic in our libraries, because trying to use straight, linear character classification tables for Unicode would tend to cause cache thrashing in a serious way. (Not that table lookup is anything other than arithmetic.)
Computer memory is just fancy paper, CPUs just fancy pens with fancy erasers; the 'net is just a fancy backyard fence.
Or, in other words, sandboxed users. ... allow you to go digging around for answers in websites that pop those ridiculous smiley ads and warnings about your "Windows" being full of "viruses" and such in your face.
Computer memory is just fancy paper, CPUs just fancy pens with fancy erasers; the 'net is just a fancy backyard fence.
I've been coding on PCs since the days of DOS 2, so I do know what it was like.
I'm not sure what your point is.
You are in a maze of twisty little passages, all alike.
You don't get the point? Really?? Are you still using DOS?
"I like to lick butts!" by MobileTatsu-NJG (#32700246) (Score:5, Informative)
Sounds like something wrong happened. Reinstall Windows.
Of course, with software being so much more complicated these days, problems like these may happen sooner. Heck, the Apples at school are as fast as how you describe your install of Windows 7 to be.
I am not devoid of humor.
Certainly the price competition helped. I've heard rumors that they essentially gave it away. But I don't think it was just familiarity. In general netbook users had a better user experience under Windows XP. That was with Linux having had a year head start on implementing on netbooks. Given more focus the Linux experience should have been much much better, it wasn't.
Linux can be a low cost alternative which is not much worse than the Microsoft product, like Open Office is to MS Office.
Or Linux can be an overall better product at similar prices like Linux workstations & small servers were to Sun workstations / small servers.
You're missing the point of why people use smart pointers. Hint: It's not because the job couldn't be done in any other way. (... though, actually, I seem to remeber there being some dynamic programming algorithms which are fiendishly difficult to implement without garbage collection... or at least implementing your own version of garbage collection.)
HAND.
BTW, I'm serious, look for Jeri Ellsworth's videos on youtube.
A successful API design takes a mixture of software design and pedagogy.
Please. Don't argue ancient computing history with those of us who made it.
Touché! :-)
So, again, your hyperbolic statement is false.
This page has already far exceeded the capacity of those floppies. My statement may have been a slight exaggeration over the size of an average comment thread.
But this argument is completely off topic. The point is not that we are suffering some mysterious malady of bloat, it's that we're now using systems for vastly bigger and better things.
If counting too many bytes makes you sad, look at the lady next to you in the restaurant using her Facebook app. She doesn't care how many bytes it takes. Facebook doesn't care. They're each being satisfied by the product ( and one is getting rich.) If Facebook made money off of optimized code, it would change things. But they only make money off happy users, not tight code. If unoptimized code made the lady sad, it would change things. But as long as she can post, she won't care either.
There has to be incentive to drive change. The cost of maintenance is probably the highest factor. If bigger code is more maintainable, then code will be bigger. If a small footprint is driving your costs (a 2kb embedded controller in a toaster is cheaper than an 8kb chip) then bloat is the driving factor in keeping costs down, so efficiency rises in importance.
John
GNU Pascal makes very fat and slow binaries. And its not really compatible with turbo pascal.
Good there is freepascal, which is much better and more compatible.
One of the few things, where i wonder why GNU fucks up so hard.
This is what you said: "First, you only have to have ONE person in your org write that custom string class that does exactly what you want, no unpredictable side effects, no bloat. That 15 minutes pays itself back almost immediately, both in easier debugging (less code to debug) and quicker compile times"
You may be older than me, but I'm smart enough to know better than re-implementing string classes when you already have some that are already proven to be bug free - it's a bad idea. It is not a 15 minute process, and yes there can be unpredictable side effects and bloat. You've insinuated that you could do it in 15 minutes, but apparently you've been doing it for decades. In any case, no one could write a complete bug-free string class in 15 minutes which implements everything common to string classes, unless you've got it completely memorized and you type as fast as possible.
Regardless of the opinion of whether or not it's a good idea, it's no opinion on this matter: extra code which is compiled and not linked leads to slower compile times.
When you've been re-implementing the same basic classes for a couple of decades (custom strings, stacks, queues, linked lists, etc), doing it one more time, again customized to your current needs, is really no big deal.
HA! It took you 20+ years to debug your code! ;)
Also, we're not talking c here, but c++
Yeah I know, we were talking classes. C can mean C/C++.
If people can't implement (or are afraid to implement) the basic classes that are everywhere, how much can you trust any class they DO implement?
This is where you're waaaaay off. Whereas you seem to think people should implement basic classes that are everywhere, it is exactly the opposite: nobody in your organization should be re-writing the basic classes that are everywhere. They're already everywhere. It's a waste of time... you are going to have to debug and maintain code that you didn't have to before. It's a straw man's argument to claim it's a matter of trust or capability of that they can't write these classes.
Just because the U.S. is a republic does not mean it is not a democracy. Democracy/republic are not mutually exclusive.
Straw man argument. If all I need is a string class that can allocate, free, append, copy and replace strings, I don't need a string class that "implements everything common to string classes".
Also, in custom classes, you're guaranteed that ONLY the code you wrote is compiled and linked to, leading to quicker compiles, and also quicker loading (since there's less need for fix-ups at load time, unless you're already writing position-independent code).
The vast majority of cases are like that - you don't need a "kitchen sink" class, and including all that extra code just gives you more areas for bugs to surface.
Most programmers can't even do fizzbin (or bing, bang, boom, or whatever it's called today). When confronted with a problem, their first instinct is to "solve it with google". If you can't even implement a stack, a linked list, a string class, a queue, or any other basic structure, why should anyone trust you to be able to implement anything harder? These are basic skills for any c/c++ programmer. If you can't implement them, you're really not qualified for the job.
That people seem to think these are "hard" is rather mind-boggling. That it's somehow "wrong" to write the perfect solution for the current problem. 10% here, 5% there, 3% in another place, it eventually adds up. And in some cases, it's several orders of magnitude difference. Example: I implemented the same video routines in both c and assembler. The assembler routine was 200 times faster. Another example - disk reads using c and assembler - the assembler routine was over 50% faster than the drives' rated speed - and a lot smaller. Please don't knock it if you haven't really tried it, because there may come a day when you really need that extra margin that writing your own class provides.
Just because you can't justify it doesn't mean that there are no cases where it's justified.
Straw man argument. If all I need is a string class that can allocate, free, append, copy and replace strings, I don't need a string class that "implements everything common to string classes.
That wasn't a straw man argument, that WAS the argument. Those things you mentioned are the common string functions, not the kitchen sink of string functions. And you're absolutely incorrect, you're wrong as wrong can be.
There's two things that you're wrong about. First of all, the fact of the matter is that if you write custom code to be compiled, the compiler will have to compile it, then link it. Existing libraries don't have to be compiled, just linked. You said that it is faster build times for custom classes, and that's absolutely incorrect - it's slower.
Second, you stated that writing your own string classes leads to less debugging and maintenance and is only 15 minutes. This is also patently incorrect. If one writes their own code they have to debug it and maintain it - string libraries are already thoroughly debugged. 15 minutes is a comical number at best, and dangerous to a project at worse, for writing, testing, and debugging a string class. You literally would have to have it already memorized to implement everything (which you may very well have done, considering you've done it for so many decades) in order to type the methods that quickly, and then you would still need to test them.
You are also saying that it's better to implement your own strings because they need to do less than the library. That is an opinion that I won't bother continuing the conversation with, because honestly it depends on the situation. Finally, you're going off on an old person's rant about coding difficulty and your anecdotes on assembler. Completely unrelated to the conversation.
Just because you can't justify it doesn't mean that there are no cases where it's justified.
I didn't say anything about a case that wasn't justified (in fact I mentioned that sometimes it may be necessary depending on the situation). What I said was you are patently incorrect about faster build times, less bugs/time/maintenance about using existing libraries, and the 15 minute estimate.
Just because the U.S. is a republic does not mean it is not a democracy. Democracy/republic are not mutually exclusive.
And this has exactly what to do with mobile phones?
Not all mobile devices are phones. I was speaking of mobile devices running smartphone operating systems in general, not just those that happen to be phones.
Common functionality for string classes includes operator overloading, array-like accesses, copy constructors dealing with other objects, pointers to other objects, pointers to c-strings, midstring, substring, trim, index, rindex, cmp, ==, >=, <=, etc. That's a lot more functionality than the basics I wrote about (and if you later find you need it, you can always add it at that point).
Your post makes it clear that you are being willfully obdurate.
As for build times, remember that if you're using the STL (which was the example given), the compiler has to create the templated object at compile time. That's not just "oh, I only need to link to a library". But by the same token, there's no reason that any custom class I write can't be compiled once, and then just linked to, so what was your point again?
The question remains, if you can't write simple classes, why should anyone trust you with anything more complex? And why should anyone have to put up with code bloat, which was the original topic ...