 Slashdot Mirror
Slashdot Mirror
Domain: cmu.edu
Stories and comments across the archive that link to cmu.edu.
Comments · 2,977
-
Harder than we would wishPart of the problem is that distributed operating systems are much harder to do than we would wish (as are distributed applications). Napster isn't the answer, it's really just a specialized search engine combined with what boils down to a bunch of ftp servers.
Load balancing? Easy to write, hard to make work well. You need to compare the cost of migration to the benefits of balancing, and you need to make decisions based on partial and outdated information. Many early systems thrashed because everybody would migrate to the idle processor, which then became overloaded, so everybody migrated somewhere else, etc.
Speaking of migration, it's a mess. The only system I know of that implemented migration fully was Locus, out of UCLA. The trouble is that whenever a process has a dependency on or a hook into its environment, that connection must be migrated too. Open files, working directory, sockets, controlling tty, signals, process parent/child relationships, and many more details must be handled. Not fun, and the benefits turned out to be mostly minor (though I do recall writing a cool version of "find" that migrated itself to the machine that stored the current subtree as it ran).
The issue of supporting distributed applications is generally considered to be separate from writing a truly distributed OS. Most of what a distributed application needs can be provided by a good communications library. To some extent, we're still learning exactly what such a library should have. What about SETI@home is specialized to it, and what's universal? I don't think we've completely figured it out.
The following is a non-exhaustive list of major concerns and design issues that must be addressed in a distributed OS. We have fairly good solutions to some, but most have not yet been solved:
- Process control. How much process migration is a Good Thing? How do you decide what machine to use to start a process, and when do you decide to migrate it to another?
- Communication and synchronization. What facilities does a distributed application need? How do we make those easy to use?
- Reliability. How do we deal with the inevitable machine failures?
- Replication. What processes and data should be duplicated on different systems? Are you doing the replication for performance, for reliability, or both? How do you manage updates to replicated data? How do you keep replicated process synchronized?
- Lack of global knowledge. How do you make decisions based on partial information?
- Naming. What names to things have. Do you have a shared global namespace, or a private one? How do you resolve names? What do you do when people and objects move?
- Scalability. How does the system behave when the number of computers/users/programs jumps by a factor of 10 or 100? (This is a place where Napster doesn't do real well.)
- Compatibility. How do you support existing software? Do you run on only one kind of hardware, or many?
- Security. Who gets to run on what machine?
Finally, I should note that the list of projects at U of Arizona might appear to be complete, but it omits a lot of important projects. Four that jump to my mind are Locus and Ficus from UCLA (though the latter is more of a distributed filesystem than an OS), Coda from CMU (again a DFS, rather well-known to Linux folks), and of course the extremely important Network of Workstations work out of UC Berkeley, which led to Inktomi and Hotbot.
-
Harder than we would wishPart of the problem is that distributed operating systems are much harder to do than we would wish (as are distributed applications). Napster isn't the answer, it's really just a specialized search engine combined with what boils down to a bunch of ftp servers.
Load balancing? Easy to write, hard to make work well. You need to compare the cost of migration to the benefits of balancing, and you need to make decisions based on partial and outdated information. Many early systems thrashed because everybody would migrate to the idle processor, which then became overloaded, so everybody migrated somewhere else, etc.
Speaking of migration, it's a mess. The only system I know of that implemented migration fully was Locus, out of UCLA. The trouble is that whenever a process has a dependency on or a hook into its environment, that connection must be migrated too. Open files, working directory, sockets, controlling tty, signals, process parent/child relationships, and many more details must be handled. Not fun, and the benefits turned out to be mostly minor (though I do recall writing a cool version of "find" that migrated itself to the machine that stored the current subtree as it ran).
The issue of supporting distributed applications is generally considered to be separate from writing a truly distributed OS. Most of what a distributed application needs can be provided by a good communications library. To some extent, we're still learning exactly what such a library should have. What about SETI@home is specialized to it, and what's universal? I don't think we've completely figured it out.
The following is a non-exhaustive list of major concerns and design issues that must be addressed in a distributed OS. We have fairly good solutions to some, but most have not yet been solved:
- Process control. How much process migration is a Good Thing? How do you decide what machine to use to start a process, and when do you decide to migrate it to another?
- Communication and synchronization. What facilities does a distributed application need? How do we make those easy to use?
- Reliability. How do we deal with the inevitable machine failures?
- Replication. What processes and data should be duplicated on different systems? Are you doing the replication for performance, for reliability, or both? How do you manage updates to replicated data? How do you keep replicated process synchronized?
- Lack of global knowledge. How do you make decisions based on partial information?
- Naming. What names to things have. Do you have a shared global namespace, or a private one? How do you resolve names? What do you do when people and objects move?
- Scalability. How does the system behave when the number of computers/users/programs jumps by a factor of 10 or 100? (This is a place where Napster doesn't do real well.)
- Compatibility. How do you support existing software? Do you run on only one kind of hardware, or many?
- Security. Who gets to run on what machine?
Finally, I should note that the list of projects at U of Arizona might appear to be complete, but it omits a lot of important projects. Four that jump to my mind are Locus and Ficus from UCLA (though the latter is more of a distributed filesystem than an OS), Coda from CMU (again a DFS, rather well-known to Linux folks), and of course the extremely important Network of Workstations work out of UC Berkeley, which led to Inktomi and Hotbot.
-
For the link-impoverished:From the redhat-announce email:
With the support of volunteers ftp site administrators, Pinstripe is available from several mirrors. The following have complete copies of Pinstripe, please use a mirror close to you:
North Carolina, USA:
ftp://metalab. unc.edu/pub/Linux/distributions/redhat/beta/pinstr ipe/
http://metala b.unc.edu/pub/Linux/distributions/redhat/beta/pins tripe/California, USA:
ftp://ftp.sourc eforge.net/pub/mirrors/redhat/redhat/beta/pinstrip e/
http://ftp.sou rceforge.net/pub/mirrors/redhat/redhat/beta/pinstr ipe/California, USA:
ftp://ftp.kernel.org
http://www.kernel.o rg/pub/mirrors/redhat/redhat/beta/pinstripe/Connecticut, USA:
ftp://ftp.uselinux.org/pub/redhatIndiana, USA:
ftp://csociety-ftp.ecn
http://csociety-ftp.e cn.purdue.edu/pub/redhat/beta/pinstripe/Michigan, USA: ftp://mrhankey.bizserve.com/pub/linux/redhat/ftp.
r edhat.com/redhat/beta/pinstripe/New York, USA: ftp://ftp.ee.cornell.edu/p ub/linux/redhat/beta/pinstripe
Pennsylvania, USA: ftp
d hat/redhat/beta/pinstripe/Pennsylvania, USA: ftp://cronus.res. cmu.edu/pub/linux/ftp.redhat.com/beta/pinstripe/
Tennessee, USA: ftp://sunsite.utk.edu
http://sunsite.u tk.edu/ftp/pub/linux/redhat/redhat/beta/pinstripe/ Australia: ftp://mirror.aarnet.edu.au/pu b/redhat/beta/pinstripe/
http://mirror.aarnet.edu.au/ pub/redhat/beta/pinstripe/Germany: ftp://ftp.gmd.de/mirrors
Germany:
ftp://ftp.uni-bayreuth.d e/pub/linux/redhat/beta/pinstripe/
http://ftp.uni-bayreuthNorway: (ISO images only) ftp
d hat/redhat/beta/pinstripe/Peru: ftp://sajino.terra.com.p e/pub/linux/redhat/beta/pinstripe/
Japan: ftp://ftp.kddl abs.co.jp/Linux/packages/RedHat/redhat/beta/pinst
r ipe/ -
safe assembly language
'' Oh? I'm fairly sure machine code is
I'm sure you're thinking that you've got me beat, but in fact this is a great question!
The old, less-satisfying answer is that compilers are less likely to have bugs than the programs they're given. This is probably true (I don't recall any exploits due to compiler bugs, though to be fair I do recall some Java VM exploits).
The new exciting answer is: We use a type-safe subset of the target machine's assembly code.
In our TILT compiler for instance, we take ML code and put it through a series of transformations. At each transformation or optimization we also translate the types (a static proof that the program can't crash) until we get to machine language. This catches a lot of compiler bugs, and helps propagate safety properties to the raw code.
The result is that we have machine language which can pretty easily be checked for type-safety. This allows us to do some other cool things, like ship the proof along with the raw machine code, to be executed on someone else's machine. They don't have to trust us (just the proof), and it doesn't suffer sandboxing costs like java. Wow! Read about Proof Carrying Code .
The second answer isn't really usable today, except in theory. The first is absolutely practical, though. (even if it fails due to compiler bugs, we'd still cut down on a high percentage of errors -- and we'd only need to fix bugs in one place).
-
Use a Trusted OS.
Script kiddies don't have enough bandwidth to DoS a major provider, so they use rootkits to crack systems and then use the cracked system as a launchpad for their DDoS attacks, right? Well, maybe a solution is for companies to use a Trusted OS like Argus PitBull, Trusted BSD, (admittedly incomplete) OB1, Trusted Solaris, HP's virtual vault, or find a better match for yourself.
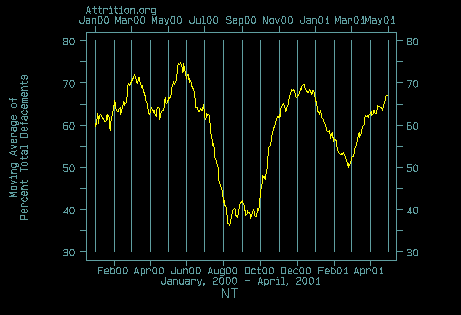
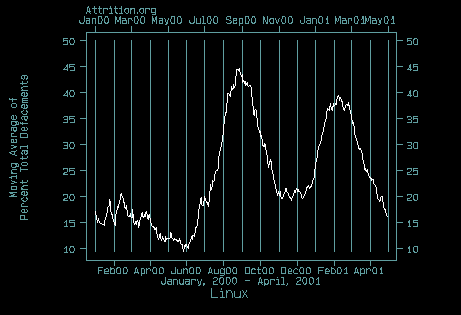
Why people use WinNT as a server platform is beyond me. Something like 65% of web-site defacements listed at Attrition.org are WinNT based. That's insane. Linux is something like 20%. I was very surprised at HOW MANY sites are hacked. The internet's infrastructure needs to be improved, sure. But how about securing your system properly?! Argus has even announced a Linux port for their products; it's the only TOS that I've seen even mention Linux. And, maybe someone should push the Linux Kernel developers to finish implementing the Capabilities and ACL stuff that at least partially exists in the kernel (or in patches); this would allow application coders to write non-suid programs that would still have some of the root capabilities (just the ones they need).
I'm not saying that the sys admins are to blame. These decisions are generally not simple technical ones. However, everyone needs to be educated about the products that are available to protect themselves and others (in the case of DDoS's). If you're a sys admin, educate yourself and pass it on to your boss. They may not get it, but you should at least try.
Just my $0.02.
$ flames > -
Re:TouretzkyDave has also suffered the wrath of the Scientologists by exposing their space aliens and e-meter really a tricked out multimeter.
While doing so he's done it in the guise of academic scholarly study - pointing out why the 1st amendment is important and why 'fair use' is needed for a free and open society
-
Re:TouretzkyDave has also suffered the wrath of the Scientologists by exposing their space aliens and e-meter really a tricked out multimeter.
While doing so he's done it in the guise of academic scholarly study - pointing out why the 1st amendment is important and why 'fair use' is needed for a free and open society
-
Re:Touretzky
I had Dr. Touretzky for an interesting class last semester at CMU, Intoduction to Artificial Neural Networks. Like everyone else, he was told to remove DeCSS from his web page, but didn't. Check out his Gallery of CSS Descramblers -- it's quite interesting and informative about the legal and moral issues involved, besides being a good resource if you want to understand how the descrambling actually works. He's obviously put a lot of time and effort into this issue.
-
Re:Touretzky
I had Dr. Touretzky for an interesting class last semester at CMU, Intoduction to Artificial Neural Networks. Like everyone else, he was told to remove DeCSS from his web page, but didn't. Check out his Gallery of CSS Descramblers -- it's quite interesting and informative about the legal and moral issues involved, besides being a good resource if you want to understand how the descrambling actually works. He's obviously put a lot of time and effort into this issue.
-
Re:Touretzky
I had Dr. Touretzky for an interesting class last semester at CMU, Intoduction to Artificial Neural Networks. Like everyone else, he was told to remove DeCSS from his web page, but didn't. Check out his Gallery of CSS Descramblers -- it's quite interesting and informative about the legal and moral issues involved, besides being a good resource if you want to understand how the descrambling actually works. He's obviously put a lot of time and effort into this issue.
-
Re:Those damn Germans
Computer Science Germans apparently are no different. What do they feed these guys?
Turkey. And lots of it. -
Touretzky testimony
Not available yet at 2600's site, which has trial transcripts through last Friday (or on Dr. Touretzky's home page, which I thought would be a logical next place to look). If anyone has any pointers to articles, etc., setting forth the substance of that testimony, I'd appreciate the same.
-
Touretzky
Touretzky is an interesting guy. I first heard of him while studying simulated neural networks. Definitely not a CS lightweight.
However, it may be appropriate to label him as an "activist" as well. On his Web page you'll find links to such things as his "Ethics and Etiquette in Scientific Research", deCSS, Cyber Patrol's filter list, and the latest poop on Scientology and Amway.
-- -
Re:Korea? wtf post mirrorsHere are some mirrors I've put up, served up fresh and hot from the NCNE GigaPOP at CMU: (file renamed to
http://www.cs.cmu.edu/afs/andrew/usr7/nstrom/www/
s tuff/beta.tar.gz
http://www.andrew.cmu.edu/~nstrom/stuff/beta.tar.g z
http://www.contrib.andrew.cmu.edu/~nstrom/stuff/be ta.tar.gz
Enjoy! -
Re:Korea? wtf post mirrorsHere are some mirrors I've put up, served up fresh and hot from the NCNE GigaPOP at CMU: (file renamed to
http://www.cs.cmu.edu/afs/andrew/usr7/nstrom/www/
s tuff/beta.tar.gz
http://www.andrew.cmu.edu/~nstrom/stuff/beta.tar.g z
http://www.contrib.andrew.cmu.edu/~nstrom/stuff/be ta.tar.gz
Enjoy! -
Re:Korea? wtf post mirrorsHere are some mirrors I've put up, served up fresh and hot from the NCNE GigaPOP at CMU: (file renamed to
http://www.cs.cmu.edu/afs/andrew/usr7/nstrom/www/
s tuff/beta.tar.gz
http://www.andrew.cmu.edu/~nstrom/stuff/beta.tar.g z
http://www.contrib.andrew.cmu.edu/~nstrom/stuff/be ta.tar.gz
Enjoy! -
Re:Korea? wtf post mirrorsHere are some mirrors I've put up, served up fresh and hot from the NCNE GigaPOP at CMU: (file renamed to
http://www.cs.cmu.edu/afs/andrew/usr7/nstrom/www/
s tuff/beta.tar.gz
http://www.andrew.cmu.edu/~nstrom/stuff/beta.tar.g z
http://www.contrib.andrew.cmu.edu/~nstrom/stuff/be ta.tar.gz
Enjoy! -
Re:more like.....Speaking of "wank-o-matic", there used to be free rotating porn at the pr0n-0-matic at http://auto.pron.org/, but they've apparently changed the pictures in their database to more... appropriate ones. Still a funny site, though. It used to be run by some CMU people -- check out the "development team" to see some fun being poked at the MIT Wearable Computing Team.
A similar setup exists (with a very interesting photo database) at http://www.stileproject.com/rnd/index.php3 . Oh, I should warn you -- don't go to that link unless you're seriously deranged.
-
VUI applications
Well, I see a lot of people talking about VUIs being good for people with disabilities, etc. This however is NOT the breadth of the voice interface application possibilities. The fact is, there are approximately 1000 times as many phones in this world as there are personal computers. THAT is where the speech recognition comes in. If you have not, go to tellmeor to Carnegie Mellon's site and try out the applications there. The potential is incredible when you think about it. Nuance software is capable, for instance, of voice verification with less than 2% false accept rates, and
-
Proof-Carrying Code
One cool application of this, which is likely to come back into fashion, is proof-carrying code. Here the programmer or compiler instruments his machine code with a proof that it meets some safety metrics (perhaps a list of library functions it's allowed to call, and type safety). The code can be transmitted to a client, who does not have to trust the provider. She only needs to trust the proof-verification code (which is a few pages of C). Network-distributed code now doesn't need sandboxing or certificates!
This of course is easier in languages with interesting type systems, which are usually functional. But the same ideas can be applied to traditional languages too.
More information: http://www.cs.cmu.edu/~petel/papers/ pcc/pcc.html . -
Some Applications
Here is a web server and network stack written in Standard ML:
There are at least two very large and complicated (and good) compilers for ML, written in ML.
Yes, applications usually need to perform IO, and so you can't write them in a purely functional language. But for an application where behind-the-scenes processing is a major part of the code (a compiler, for instance), functional languages can be and are often an excellent choice.
-
Why Functional Matters
I've always thought about submitting one of these "why not functional?" or "why not ML?" ask slashdots... but I think I know the answer.
My favorite functional language is ML (standard). It isn't "purely functional" like haskell (though we often write purely functional programs); it includes imperative features like assignment and arrays and IO, which are usually useful in real programs.
I work on an ML compiler here at CMU called TILT (which I'd like to think is one of the most advanced research compilers around), so I am sort of biased. But I also know what I'm talking about...
(Incidentally, the FoxNet Web Server is written entirely in standard ML, including the network stack (with ethernet, down to the hardware device driver)!)
Anyway, back to the question. Why does functional programming matter?
Programming functionally is closer to thinking in terms of math. Lots of algorithms and data structures are expressed more beautifully in a functional style. It's almost impossible to write gross hacks if you're programming functionally (most quick hacks actually turn out looking quite beautiful). Programming functionally has some direct advantages in this vein, and I find that I write better code faster when I write functionally. (I'll admit to hating it for a semester! But once I got used to it, I don't want to go back...)
There are some awesome features of most functional languages, most notably: Parametric Polymorphism and Higher Order Functions. (more rarely, such gems as functors and higher-order continuations (aka callcc; think a typed and higher-order setjmp). These all deserve their own posts to explain their incredible benefits. You are missing out if you've never written a program using these features.
But mostly, functional programming is useful for its indirect benefits. Let me explain some of these:
- Concurrency. Writing concurrent programs in a functional language is so much more natural. It's easier to avoid certain kinds of race conditions too, since you don't update variables in a functional language. SML/NJ has an awesome concurrencly package called CML .
- A powerful static type system and type safety. It's difficult to design a language (and many smart people have tried) that's imperative, type safe, and powerful. Features of functional languages like garbage collection and non-updatable values make it easier to define a language with a powerful type system. (in case you're still stuck in the 60s, type safety guarantees that your program CANNOT crash at runtime. No more uninitialized pointers, using memory after it's freed, bad casts, or other plagues of C++ programming).
A powerful static type system gets you a lot:
- Debugging. It's easier to find mistakes in your program. When I program in ML, I get a list of all the type errors in my program when I compile. I can go back and fix these before I have to run my program on test cases, etc. Debugging is so much easier. It's hard to explain how incredibly useful this is compared to programming in C++. Everyone who's used ML can attest to this fact: once your programs typecheck, they Just Work.
- Your programs run faster. Java has a somewhat more mature type system than C++ (it guarantees safety, for instance), but most of this is dynamic. That means all your objects are tagged, and these tags are checked frequently to make sure you're not doing anything wrong! There's no way the compiler can optimize these out; mistakes in the definition of the language (array subtyping) make tags necessary for type-safety. In ML, we don't have to tag values or check them at runtime. Yet we guarantee our programs run safely because we verify all of the types at compile-time!
- Compiler Technology Advances. Most research in programming languages and compilers these days is on languages with interesting type systems. We're seeing fewer and fewer improvements to C compilers, and lots of improvements on "advanced" programming languages. The type system allows you to make more optimizations, because the compiler has more information available to it. Some concrete examples:
Aliasing - a big problem for C/C++/Java compilers. If you've ever looked at the machine code they produce, you've seen this effect. "Why is it fetching that address again??"
Function Calls: Practically every C/C++ compiler treats functions as a black box. Languages with stronger type systems are able to optimize around function calls because much more information (types) are available.
Our TILT compiler that I mentioned earlier does something rather new: Each compilation phase transforms not only the program but its type. We keep the type information around even when we are dealing with assembly language! This enables us to perform some unprecedented optimizations.
- Machine independence. Making a type system usually means hiding away the details of the machine, and this usually means that the execution of your program is completely predictable. (Compare to C/C++ "undefined" behavior!) ML programs are extremely portable.
- Modularity. I was able to understand and start working on the (100,000 line+) TILT compiler in a matter of days rather than weeks because of ML's strong modularity features. The most interesting of these are:
Signature Ascription - This allows you to define abstract data types by naming a type and some operations on it (and their types). This is similar to header files in C (much more refined), but thanks to the type system, you can guarantee that the user can ONLY use your abstract data type the way you intended. They cannot cast, subclass, or use any other tricks to get at your datatype. (Some OO folks have solutions for this too, but they are not as elegant). This is awesome, because it helps you figure out where bugs are. I can attest that this really works; my project this summer is to change the way a very important module works... and so far, I have only experienced one observable effect of changing the representation!
Functors - This is somewhat like C++'s template system (but more refined); allowing you to write programs which operate on modules. (Ie, you give me a module which implements sets, and I'll give you back a module which implementes maps). This is very useful, and since all the work is done at compile-time, incurs no runtime cost.
- Proof-carrying code. You haven't seen this yet, but you will. What if you could download a program off the internet and run it, knowing that it won't do anything wrong? What if it wasn't subject to sandboxing (and slowdown) like Java apps? What if you didn't need to trust the source (certificats/signing)? Proof-carrying code carries a proof of its type-safety (and other safety metrics) with it; your computer verifies the proof and then runs the bare code! You can read more about this here .
Now here are some answers to the question of why not functional?
- RIGHT NOW, functional languages are slower (estimate 2x) than languages like C. Against a "modern" language like Java they fare rather well. Compiler technology is advancing and will fix this! I'd also argue that the other benefits (developer productivity, code maintainability) far outweigh the slowdown.
- Functional is weird for a lot of people. It took me at least 6 months to figure out why it was good, and I consider myself a pretty good hacker. Most people are more comfortable with imperative languages (at first...), possibly because that's usually their introduction to programming.
- There are not many commercial applications for functional programming yet (outside of Ericcson), and some people just program for money.
I would like to see the hacker types of the world pick up some new, interesting languages. Most of these languages don't have powerful marketing engines like Sun or Microsoft behind them, but hacker types are (usually) smart enough to see past that stuff!
-
Why Functional Matters
I've always thought about submitting one of these "why not functional?" or "why not ML?" ask slashdots... but I think I know the answer.
My favorite functional language is ML (standard). It isn't "purely functional" like haskell (though we often write purely functional programs); it includes imperative features like assignment and arrays and IO, which are usually useful in real programs.
I work on an ML compiler here at CMU called TILT (which I'd like to think is one of the most advanced research compilers around), so I am sort of biased. But I also know what I'm talking about...
(Incidentally, the FoxNet Web Server is written entirely in standard ML, including the network stack (with ethernet, down to the hardware device driver)!)
Anyway, back to the question. Why does functional programming matter?
Programming functionally is closer to thinking in terms of math. Lots of algorithms and data structures are expressed more beautifully in a functional style. It's almost impossible to write gross hacks if you're programming functionally (most quick hacks actually turn out looking quite beautiful). Programming functionally has some direct advantages in this vein, and I find that I write better code faster when I write functionally. (I'll admit to hating it for a semester! But once I got used to it, I don't want to go back...)
There are some awesome features of most functional languages, most notably: Parametric Polymorphism and Higher Order Functions. (more rarely, such gems as functors and higher-order continuations (aka callcc; think a typed and higher-order setjmp). These all deserve their own posts to explain their incredible benefits. You are missing out if you've never written a program using these features.
But mostly, functional programming is useful for its indirect benefits. Let me explain some of these:
- Concurrency. Writing concurrent programs in a functional language is so much more natural. It's easier to avoid certain kinds of race conditions too, since you don't update variables in a functional language. SML/NJ has an awesome concurrencly package called CML .
- A powerful static type system and type safety. It's difficult to design a language (and many smart people have tried) that's imperative, type safe, and powerful. Features of functional languages like garbage collection and non-updatable values make it easier to define a language with a powerful type system. (in case you're still stuck in the 60s, type safety guarantees that your program CANNOT crash at runtime. No more uninitialized pointers, using memory after it's freed, bad casts, or other plagues of C++ programming).
A powerful static type system gets you a lot:
- Debugging. It's easier to find mistakes in your program. When I program in ML, I get a list of all the type errors in my program when I compile. I can go back and fix these before I have to run my program on test cases, etc. Debugging is so much easier. It's hard to explain how incredibly useful this is compared to programming in C++. Everyone who's used ML can attest to this fact: once your programs typecheck, they Just Work.
- Your programs run faster. Java has a somewhat more mature type system than C++ (it guarantees safety, for instance), but most of this is dynamic. That means all your objects are tagged, and these tags are checked frequently to make sure you're not doing anything wrong! There's no way the compiler can optimize these out; mistakes in the definition of the language (array subtyping) make tags necessary for type-safety. In ML, we don't have to tag values or check them at runtime. Yet we guarantee our programs run safely because we verify all of the types at compile-time!
- Compiler Technology Advances. Most research in programming languages and compilers these days is on languages with interesting type systems. We're seeing fewer and fewer improvements to C compilers, and lots of improvements on "advanced" programming languages. The type system allows you to make more optimizations, because the compiler has more information available to it. Some concrete examples:
Aliasing - a big problem for C/C++/Java compilers. If you've ever looked at the machine code they produce, you've seen this effect. "Why is it fetching that address again??"
Function Calls: Practically every C/C++ compiler treats functions as a black box. Languages with stronger type systems are able to optimize around function calls because much more information (types) are available.
Our TILT compiler that I mentioned earlier does something rather new: Each compilation phase transforms not only the program but its type. We keep the type information around even when we are dealing with assembly language! This enables us to perform some unprecedented optimizations.
- Machine independence. Making a type system usually means hiding away the details of the machine, and this usually means that the execution of your program is completely predictable. (Compare to C/C++ "undefined" behavior!) ML programs are extremely portable.
- Modularity. I was able to understand and start working on the (100,000 line+) TILT compiler in a matter of days rather than weeks because of ML's strong modularity features. The most interesting of these are:
Signature Ascription - This allows you to define abstract data types by naming a type and some operations on it (and their types). This is similar to header files in C (much more refined), but thanks to the type system, you can guarantee that the user can ONLY use your abstract data type the way you intended. They cannot cast, subclass, or use any other tricks to get at your datatype. (Some OO folks have solutions for this too, but they are not as elegant). This is awesome, because it helps you figure out where bugs are. I can attest that this really works; my project this summer is to change the way a very important module works... and so far, I have only experienced one observable effect of changing the representation!
Functors - This is somewhat like C++'s template system (but more refined); allowing you to write programs which operate on modules. (Ie, you give me a module which implements sets, and I'll give you back a module which implementes maps). This is very useful, and since all the work is done at compile-time, incurs no runtime cost.
- Proof-carrying code. You haven't seen this yet, but you will. What if you could download a program off the internet and run it, knowing that it won't do anything wrong? What if it wasn't subject to sandboxing (and slowdown) like Java apps? What if you didn't need to trust the source (certificats/signing)? Proof-carrying code carries a proof of its type-safety (and other safety metrics) with it; your computer verifies the proof and then runs the bare code! You can read more about this here .
Now here are some answers to the question of why not functional?
- RIGHT NOW, functional languages are slower (estimate 2x) than languages like C. Against a "modern" language like Java they fare rather well. Compiler technology is advancing and will fix this! I'd also argue that the other benefits (developer productivity, code maintainability) far outweigh the slowdown.
- Functional is weird for a lot of people. It took me at least 6 months to figure out why it was good, and I consider myself a pretty good hacker. Most people are more comfortable with imperative languages (at first...), possibly because that's usually their introduction to programming.
- There are not many commercial applications for functional programming yet (outside of Ericcson), and some people just program for money.
I would like to see the hacker types of the world pick up some new, interesting languages. Most of these languages don't have powerful marketing engines like Sun or Microsoft behind them, but hacker types are (usually) smart enough to see past that stuff!
-
what about Coda (Intermezzo ??!)While I basically agree to all of what has been said here (LDAP, IMAP, network data...) I'm still wondering about the "Coda" choice for networked FS
First, don't get me wrong, I'm not against the idea at all and I do think that Coda is really great (on paper).
Second, I'm also surveying Coda's enhancements for more than 2 years now and I really think it's a great software with lots of people behind but my question really is : "can Coda achieve enough scalability and stability in order to be installed for 1000+ clients ?" (the FAQ and the latest changelog doesn't help me think it could handle 2500 clients without any problem at all...)Because frankly, when I hear all the feedback from different people using it 'in real life', it's not all so bright...
Besides, what about Intermezzo that is derived from Coda with most of it's features because of such "unforseen" scalability issue that were not planned back when the developement began... (appart from the fact that Intermezzo seems a little beta to me)
You can also find some good information concerning Coda/Intermezzo/NFSv4 here
As a conclusion, why not having one or more big editor (IBM, SGI, HP...) put some big bucks on the table in order to help any of these 2 projects being finalized through funds (SourceXchange, CoSource or any other way)
-
what about Coda (Intermezzo ??!)While I basically agree to all of what has been said here (LDAP, IMAP, network data...) I'm still wondering about the "Coda" choice for networked FS
First, don't get me wrong, I'm not against the idea at all and I do think that Coda is really great (on paper).
Second, I'm also surveying Coda's enhancements for more than 2 years now and I really think it's a great software with lots of people behind but my question really is : "can Coda achieve enough scalability and stability in order to be installed for 1000+ clients ?" (the FAQ and the latest changelog doesn't help me think it could handle 2500 clients without any problem at all...)Because frankly, when I hear all the feedback from different people using it 'in real life', it's not all so bright...
Besides, what about Intermezzo that is derived from Coda with most of it's features because of such "unforseen" scalability issue that were not planned back when the developement began... (appart from the fact that Intermezzo seems a little beta to me)
You can also find some good information concerning Coda/Intermezzo/NFSv4 here
As a conclusion, why not having one or more big editor (IBM, SGI, HP...) put some big bucks on the table in order to help any of these 2 projects being finalized through funds (SourceXchange, CoSource or any other way)
-
Maybe, maybe not...
Look at the F-16 and the fly-by-wire system...
Let's not forget that befor the *official* "Falcon" nickname, test pilotes refered to it as "lawn-dart" (100% true).
Systems based on interia and gyroscopes have been in use on commercial aircraft from the very beginning.
True, yet their calibration must be done in an extremly precise way. Their has been numerous reports of inertial aviation computer going of course, just because some ground crew were refulling the plane when the system was calibrated. That is also why inertail navigation is constantly rechecked against onboard star mapers.
My point beeing that, trying to calibrate such a thing on earth is already quite a problem, now just try and do the same on a planet we know very little about, a couple of million of miles away.
I'm really the first to say that we should put more funding into space exploration and Fundamental research. I'm sure, we can all imagine the 'commercial' spinoffs making an AI that can fly a chopper on some planet that's got a LAG of over an hour.
But I think that there is one thing that was not mentioned in the article, and that is the amount (or actually the lack) of data we have on Titan.
Look at the huge amount of trial and error testing that had to be done to get to valid helicopter design here no earth, where we can measure almost every variable that compose the complex notion of flying a rotating wing design. Even the prototype helicopter from Carnegie Mellon, uses technology that has been designed from, and for earth specs. BTW if you want to check out Carnegie Mellon's helicopter project, here is a link
If you want to have a look at a complex AI piloting an acutal spaceship, you can go and checkout the DeepSpace 1 prob. Which among other things is a real test bed for a lot of NASA's technology.
Murphy(c). -
It has its advantages, too
I have read over many of the posts here, and I have several comments. I have studided internet democracy, and have even written a paper about it, available here, although that paper introduces something far beyond just casting a vote thorugh the web.
A large portion of the posts are about how people who want to vote online are too lazy to actually get up and walk to the polling place. It's not about being lazy, it's about accessibility. Not all employers allow people to leave work to vote, or I was extremely sick at the time of the last election. For the events you can forsee in advance, we have mail-in absentee ballots in every state, but mailing is even *more* prone to fraud than internet voting.
The next category of posts are about how it is fraud, and as I address above, it is very easy to fake your identity at the polling place, and extremely easy to fake it through mail. The internet has the ability to make this much more secure, by using OTP or such. People trust thier banking to the internet, and most people value thier own money a lot more than the governments. (i'm not trying to start an economic argument, i'm just stating a fact)
The next category of posts say that less informed voters will vote. This is not true. Currently, many people vote who get their political news spoon-fed through MSNBC or their local nightly news. They get little information on local politicians and as such vote purely on party lines, or because their friend told them to. Access to the internet affords much greater access to information, and people would be prone to read about the candidates before clicking submit on their vote.
The final category of posts that I have witnessed is fear for anonymity. Again, the internet has much more ability to be anonymous. A system where you authenticate to one system, then vote to another, or where your id is converted into a hash value, then input into a hash table, which is then tallied at the end, or any number of other solutions can guarantee anonymnity a lot more than the guy sitting at the polling place.
Internet voting (and as i say in my paper, coupled with internet deliberation) has the ability to make societies more democratic and alleviate many of the problems with traditional voting. Of all places, I expect slashdot least to fear this technology, but to embrace it and brainstorm ways to make it work. I don't think the time has quite come, but within a few years, this is a very viable and beneficial system.
-Alison -
All Java solution at CMU
www.ini.cmu.edu/eclub is an all Java suite of telephony stuff developed by students at CMU as a masters thesis in the Information Networking Institute. Take a look.
-
Women in Computer Science
I honestly can't say that, from my experience (not very considerable since I'm only 17 and not even in college yet), women haven't had it too rough. At least not in the college admissions process. It seems to me as if colleges (using Carnegie Mellon, #1 in CS) are actually going after those few female future computer scientists. I would have loved to have gone to Carnegie Mellon for CS, but I was waitlisted, and when I was accepted, they couldn't reevaluate my financial package (I still would've had to pay almost $20,000), so I had to choose Case Western Reserve University. Women at CMU SCS (School of Computer Science) are not so rare anymore. They've increased from under 10% of the incoming class in 1995 to almost 40% of the incoming class of 2000. By the way, the national standard is under 10% of women gain engineering-related degrees, including CS. The article which I got my statistics from says that CMU is "bucking the national trend". Now, high school seniors, the last time I checked, can choose their own school. So CMU is somehow attracting far more women than they used to, and more importantly, far more women than the rest of the schools in America. They do this by some good methods: by the Women@SCS Support Group, set up to nurture women through their four years in the SCS. Men don't have this advantage, but I can see that discrimination might discourage the women...I guess. This is OK. But by offering an exclusive scholarship to women (and another exclusive scholarship to minorities, though that's semi-offtopic), they persuade women in by lowering their exhorbitant $34,000 yearly cost to a reasonable rate...for women. White males are only considered for one third of the available merit scholarships. Contrast this with women, who are considered for more, or all, if they're of minority racial background. This I have a problem with.
I'm reminded of a statement from a student at the Boston Latin School, one of the most competitive secondary schools in America, and somewhat diverse: "It should be merit only that gets us here, and merit only that lets us stay." That was bravely said by a female minority student. Obviously, it's still possible to be female and smart. Let's just realize that...and realize as well that I am against gender bias at a young age. This is the one place I'm not sure about. But if there are teachers out there telling the little girls, "Why don't you try sewing instead," when they pick up a keyboard, well they should be ready with a response, "My daddy told me that girls can do anything boys can do, and I think they can do it better." My point is, parents, if it wasn't common sense, tell your children that they can do anything, regardless of gender! And give them pride...so when somebody thinks they can't do it, and tries to tell them so, they know that they can, and they will "show them." That's how I was brought up. I'm afraid I can't lend an air of true authority to this story, as I'm just a white male. But I know if I was a girl, I wouldn't let anyone tell me what I could or couldn't do.
Links:
Pittsburgh Post-Gazette Article
Women@SCS -
Women in Computer Science
I honestly can't say that, from my experience (not very considerable since I'm only 17 and not even in college yet), women haven't had it too rough. At least not in the college admissions process. It seems to me as if colleges (using Carnegie Mellon, #1 in CS) are actually going after those few female future computer scientists. I would have loved to have gone to Carnegie Mellon for CS, but I was waitlisted, and when I was accepted, they couldn't reevaluate my financial package (I still would've had to pay almost $20,000), so I had to choose Case Western Reserve University. Women at CMU SCS (School of Computer Science) are not so rare anymore. They've increased from under 10% of the incoming class in 1995 to almost 40% of the incoming class of 2000. By the way, the national standard is under 10% of women gain engineering-related degrees, including CS. The article which I got my statistics from says that CMU is "bucking the national trend". Now, high school seniors, the last time I checked, can choose their own school. So CMU is somehow attracting far more women than they used to, and more importantly, far more women than the rest of the schools in America. They do this by some good methods: by the Women@SCS Support Group, set up to nurture women through their four years in the SCS. Men don't have this advantage, but I can see that discrimination might discourage the women...I guess. This is OK. But by offering an exclusive scholarship to women (and another exclusive scholarship to minorities, though that's semi-offtopic), they persuade women in by lowering their exhorbitant $34,000 yearly cost to a reasonable rate...for women. White males are only considered for one third of the available merit scholarships. Contrast this with women, who are considered for more, or all, if they're of minority racial background. This I have a problem with.
I'm reminded of a statement from a student at the Boston Latin School, one of the most competitive secondary schools in America, and somewhat diverse: "It should be merit only that gets us here, and merit only that lets us stay." That was bravely said by a female minority student. Obviously, it's still possible to be female and smart. Let's just realize that...and realize as well that I am against gender bias at a young age. This is the one place I'm not sure about. But if there are teachers out there telling the little girls, "Why don't you try sewing instead," when they pick up a keyboard, well they should be ready with a response, "My daddy told me that girls can do anything boys can do, and I think they can do it better." My point is, parents, if it wasn't common sense, tell your children that they can do anything, regardless of gender! And give them pride...so when somebody thinks they can't do it, and tries to tell them so, they know that they can, and they will "show them." That's how I was brought up. I'm afraid I can't lend an air of true authority to this story, as I'm just a white male. But I know if I was a girl, I wouldn't let anyone tell me what I could or couldn't do.
Links:
Pittsburgh Post-Gazette Article
Women@SCS -
CMU's Human Computer Interaction Institute
Check out this link to see what's going on at CMU's HCII. All sorts of wacky stuff...
-
What is a geek?
This page explains well what is a geek. Some of the most interesting tidbits where:
So yes, there are girl geeks, in chatrooms everywhere. In the fashion section of AOL. In a barbie discussion forum. Some might even be technically competent."But just what is a geek?" you ask. Well, I'll tell you. At least, I'll tell you my definition... which may be different from "general usage" of the term, webster's definition, and even the definition used by other geeks.
A geek is someone who spends time being "social" on a computer. This could mean chatting on irc or icb, playing multi-user games, posting to alt.sex.bondage.particle.physics, or even writing shareware. Someone who just uses their computer for work, but doesn't spend their free time "on line" is not a geek. Most geeks are technically adept and have a great love of computers, but not all geeks are programming wizards. Some just know enough unix to read mail and telnet out to their favorite MUD.
...
Geek can also be used as a verb. "To geek" is to sit online and read mail, news, chat, and otherwise waste time in front of a keyboard. This "geeking" often consumes many hours, even if the intention was to "just log in and check my mail." Some would say this time would be better spent being social in person or even just being curled up in a sunbeam.
-
Walking robotsThat Honda robot is a few years old, but it's still a great piece of work.
Honda has the advantage of being an industrial company with a good mechanical engineering R&D operation. To build something like that, you need more technicians and machinists than researchers. Most robotics labs in the US are in computer science departments, and with the exception of the Field Robotics Center at CMU, aren't organized to build good machinery on a reasonable schedule. DoD isn't throwing money at this problem any more; they did in the 1970s and 1980s, and didn't see much for their money.
The hardware component state of the art is actually pretty good, which wasn't true a decade ago. Early robotics researchers wasted too much time on building radio links, motor controllers, encoders, and similar parts. Now you can buy all that stuff. Getting enough compute power onboard is now the easy part. Rate gyros and accelerometers are now stock, low-cost items. CCD TV cameras are easily available. Laser rangefinders are still big, clunky, and overpriced, but depth from stereo vision, after thirty years of work, now works well in real time.
Controlling a legged robot is a tough problem, but there's been a fair amount of work on balance. I have a patent in that area myself. Most of the work on legged locomotion is now going into animation and games, but the results will be useful in the real world.
Nobody makes money from mobile robots, though. A few companies have tried, notably Denning Robotics and HelpMate, but not with success. The basic problem is that robots compete with cheap people, and aren't much faster.
-
SoccerMan, this thing is pretty scary! Exciting, though. That bit of footage about soccer is definitely some animatronic-dancing propaganda about the world "robocup" robot soccer competition. This competition focuses less on kinematics and more on autonomous teamplay (the robots are NOT controlled by humans during play, and don't communicate with each other electronically), so the robots look more like mice than mechanized spacemen (though CMU's team for one of the leagues last year used the Sony Aibo, so we're getting there!). There's some neat information and pictures here:
-
Re:Updated junkbuster blockfiles
Who the f**k moderated this 100% valid and relevant question as a troll?
There are some good sites out there for keeping your Junkbuster block lists up to date. Although I can't vouch personally for the following, here's what my blocklist has to say: (I actually got this file from the second link below. The comments below are from the block-list's author.)
# I got this from http://mind.learning.cs.cmu.edu/blockfile
# and changed it a little bit. Note that my junkbuster is compiled
# to understand full Posix regular expressions.
# Send suggestions to boldt (at) math.ucsb.edu.
# Home page: http://math-www.uni-paderborn.de/~axel/
# Other blockfiles are available elsewhere, try searching
# documents that mention "junkbuster" and are called "blocklist"
# altavista.digital.com/cgi-bin/query?pg=q&what=web& fmt=.&q=%2Bjunkbuster+%2Burl%3AblocklistHope that helps.
--Joe
-- -
Actually...
telnet clients use plain old TCP/IP, without any layers of abstraction on top (which is why you can telnet into a web server and make HTTP requests, even though HTTP is built on top of TCP/IP and not on top of your hypothetical "telnet" protocol--try it). As far as not reading the article goes... touché (although I don't think that allowing unencrypted telnet and ftp threatens the security of an entire network unless you're allowed to su to root via an unencrypted connection [thus transmitting the root password unencrypted], otherwise it'd just be a security hazard for individuals who chose not to use something like ssh or ktelnet). I'm sorry if you got the impression that I was passing myself off as an expert; this was not my intention. If you would like to do some research of your own on this subject, I suggest you start here, and take a look at the accompanying example code found here.
-
Actually...
telnet clients use plain old TCP/IP, without any layers of abstraction on top (which is why you can telnet into a web server and make HTTP requests, even though HTTP is built on top of TCP/IP and not on top of your hypothetical "telnet" protocol--try it). As far as not reading the article goes... touché (although I don't think that allowing unencrypted telnet and ftp threatens the security of an entire network unless you're allowed to su to root via an unencrypted connection [thus transmitting the root password unencrypted], otherwise it'd just be a security hazard for individuals who chose not to use something like ssh or ktelnet). I'm sorry if you got the impression that I was passing myself off as an expert; this was not my intention. If you would like to do some research of your own on this subject, I suggest you start here, and take a look at the accompanying example code found here.
-
Not bloody likely
They're not going to ban Telnet and FTP, and the article doesn't call for that. What the article is calling for is to ban the practice of unsecured Telnet and FTP, something highly advised at schools such as mine.
According to the article, many colleges don't set proper access restrictions on log files containing vital information, so those files may even be indexed when a user does a search on the school's web site. That's just stupid, as any admin can see. Furthermore, most students, even at privacy-minded schools like mine, don't bother with using encrypted Telnet or FTP sessions. They figure nobody's out to get them, and so they don't need to authenticate. My next-door neighbor, before getting effectively kicked out of the school, wound up sniffing all of the passwords of everyone on our subnet who even once logged in unencrypted. While he didn't use that data for malicious purposes, a more unscrupulous character could easily publish them.
-
Ah, the Noble Gargoyle..
Well, here's the obligatory Snow Crash reference.. but figured might as well mention a couple of other Wearable Computer stuff.. kinda reminds me of the stuff at CMU and the More Gargoyle-y MIT one. I personally think the MIT one is neater, but hey.
Also of interest is An article at Planet IT that delves into some of the same issues.
Yeah.
--- -
A little bit of reality...I've just spent a bit of time reading through the source code for this project. It's pretty crafty to make the PIC do this stuff.
I've seen a number of comments above where the poster has lept to the conclusion that this thing is comparable to a "real" web server, such as apache running on a unix platform.
The most important limitation that I can see in the code is that it only remembers information from the previously received packet, and it can only send a packet in response to receiving one, but can't retransmit on a timeout not having received an ACK. Calling this TCP is a streatch at best. It's certainly a long way from RFC-1122.
For example, consider the case where two clients attempt to access this little web server at the same time, which is not unlikely running the data pipe at 19200 baud, and having CTS inhibiting data flow in between every received byte, and during all data transmission. The remote IP address is overwritten as the second packet is received, causing all knowledge of the first connection to be lost. Most of that information will be regained when the first host sends another packet, but the point is that this little web server isn't going to work well with multiple connections at the same time, and probably won't work at all if the TCP retransmit is require because of any packet loss.
It is a neat project, and doing even this minimal tx follows rx without pre-connection state is some impressive code for such a small chip. Neat as it is, it just isn't a viable web server for any application where multiple clients may use it. It probably won't do well on networks that have packet loss, duplicated packet and the other not-so-common problems that come with the best-effort (but unreliable) IP datagram service.
And now for a shameless plug.... for the posters above who were talking about connecting a disk drive, here's a little project I did that connects a IDE hard drive to a 8051 microcontroller. Maybe it could be used with a PIC? My code is public domain, so it could be combined with a GPL'd project, like this little web server.
-
Re:Whats that got to do with it?
There have been efforts to blend mathematical algorithm provers with programming tools. Perhaps someone will succeed with something general enough to be able to review existing code.
There is some work being done on proof-carrying code, where the execution of a program can be tested for certain properties. See here for further info. -
Point of OrderWell, even if it mimics how neurons work in living, healthy, human brain tissue, we're still orders of magnitude away from human neural complexity. However (although the news release is really vague), making microprocessors behave like neurons in the first place was/is a big hurdle.
There was a conference at Stanford a while back (was mentioned here IIRC) on synthetic intelligence in general; all sorts of fun stuff was tossed out:
http://www.technetcast.co m/tnc_program.html?program_id=82
This quote (from John Holland) is particularly telling:First of all, each element in the central nervous system contacts somewhere between 1000-10,000 other elements in the central nervous system. [The] most complex machines that we build, typically the fan out - this contact rate - is on the order of 10. A close colleague of mine, Murray Gell-Mann [Ed.: Nobel Prize winner in Theoretical Physics; Distinguished Fellow, Co-Chairman of the Science Board, Santa Fe Institute, see website], is fond of saying, "when I go three orders of magnitude, I go to a new science." So here is one "three orders of magnitude" effect here.
So we're not quite there yet. Hans Moravec participated in the conference as well, and he has a fairly informative essay linked from his site entitled "When will computing hardware match the human brain?":
http://www.transhumanist.com/volum e 1/moravec.htm -
Re:Cleanliness vs. Performance.Okay, I'm thinking of it as code associated with a name space. However, when you have a function, you actually have a pointer to the memory where that code is, and a function call is simply a jump to those instructions. For example, In Linux: You call gethostbyname(). It calls a system trap which jumps to that code inside the kernel (or netoworking library or whatever.) That function then procedes to get the host name and return it.
that's almost exactly how it happens in Inferno too. the fact that the metaphor for the gethostbyname call looks like a file system really causes hardly any overhead. this is how it happens in inferno (and in plan 9 for that matter only there you need a trap to get out of user mode into supervisor mode):
first you open the file
In Inferno: You write something to a virtual file. The Inferno filesystem intercepts the write. It takes a look at what command you are trying to do, takes a look at the stuff you feed it (parameters) and then passes that info onto the networking code in the kernel via a function call. This step of having the kernel intercept the call and decode it is what introduces the overhead.
the kernel doesn't have to ``decode'' the call any more than a linux kernel does. yes, it has to verify that the file descriptor is valid (big deal, if (fd >=0 && fd <= fdgrp->maxfd)) it's the device driver itself that does the decoding of the request, and since in the case of gethostbyname() you're just mapping from a string anyway, there is no more overhead.
Also, since it is a virtual file, memory writes and reads have to be done than during a funciton call. All this is what introduces the overhead.
nope. inferno system calls do not make any copies of the data unless they have to. i just had a look at the relevant code, and the pathway between a user program doing write() and the device getting that call probably about 20 to 30 machine instructions executed. there is no real overhead compared to the traditional syscall interface.
BUT what you do get is consistency across all device interfaces. because gethostbyname() is not just a system call, but is part of the namespace, i can export that down any data connection. so, say i've got a little handheld device that has no tcp/ip stack, no DNS, nothing apart from some sort of serial driver and the Styx driver (which is very small), then i can connect it up to my desktop PC, import the network devices +
that applies to all inferno devices. the fact that the interface is an abstract one does not necessarily mean that it's inefficient. if you're interested, have a look at the plan 9 code (login 9fan, password glenda) that does the same thing. i think you'll find that the path from user program to system call implementation code compares favourably with most *NIXen.
the file abstraction in inferno is a wonderful thing - if you're using it, it means you don't have to write a specialised protocol for every new network service - if a service is running locally, it's efficient; if it's running remotely, the protocol work is done for you.
-
Re:Effective Solution
An interesting thing to look into is a research project called TOM at Carnegie Mellon University. It's goal is to convert all sorts of file formats from one to the other. I can't check it out to give more information because my firewall at work doesn't let unusual ports (it's served on 8001).
-
Starcraft Haikus a-go-go
For some StarCraft enlightenment I suggest you check out this page.
-
What else would the subject be?Can it not be so?
Slashdot Story on haiku
Self-fufilling post
Personally, the only two haiku I'm really proud of are on the Olestra/Olean Haiku page and are thus:
How did Zappa know?
'Voodoo Butter Underpants..'
Olestra vision.Olestra Facists;
They have tainted my Fritos!
Fudgie underwear... -
Re:I'll be first in line...
I think you'll end up being off by two orders of magnitude... I'm willing to bet it'll be within the next century:
http://www.frc.ri.cmu.edu/~hpm/project.archive/rob ot.papers/1991/Universal.Robot
http://www.transhumanist.com/volum e1/moravec.htm -
Re:You've only got yourselves to blame
Now, I'm sure that a lot of software that's used on college campuses has been pirated. Most of it was when I was in college a decade ago, so I doubt it's only gotten worse.
While I'd be lying if I told you that there was no such thing as piracy on campus, companies like Microsoft have noticed that students don't want to pay (directly) for their software. So they sign a campus-wide site license. At my university, just agreeing to a license agreement allows me to download Windows 2000, Office 2000, and lots of other software products. Of course, I can't copy them for people who aren't students, and after I graduate I am required to purchase legitimate licenses for all my software (cough).
But hey, it's something. Pay nothing for a copy of Office 2000, or pay $x for WordPerfect Office 2000. If you were a Starving College Student, what would you pick? -
It's the License, stupid
> People aren't allowed to drive really fast because
Because they went to the government and ASKED for a LICENSE to drive the GOVERNMENTS's vehicle.
Software License = You don't own the software.
Driver's License = You don't own the vehicle.
We ALREADY have the right to travel: http://www.cs.cmu.edu/~karl/gov t/driver/driver.html
You don't legally own your automobile unless you have the Manufacture Statement of Origin
( Sorry for the title, just trying to get attention -
Two LawsThere are the "laws of the land", and there are the "laws of the net", or RFC's. The way I see it, he didn't violate RFC 821, which specifies how SMTP works. Furthermore, I would claim that the sysops at Market Vision are somewhat negligent in having an open relay on the public internet.
Finally, given that SMTP makes no guarantees about the validity of the "From:" address, I see no reason (other than ignorance) for anyone to have any expectation of its validity. I don't know about the "law of the land" when it comes to fraud, but I would imagine that the recipient's expectation of validity plays an important role in proving fraud.
Disclaimers: IANAL, IANAS (Sysop).
{kind=link}
{kind=link}