 Slashdot Mirror
Slashdot Mirror
Domain: cwi.nl
Stories and comments across the archive that link to cwi.nl.
Comments · 71
-
Re:GOTO
If you read Dijkstra's original article, his objection to GOTO is rather specific, and his reasoning is slightly faulty in the case of interactive programs.
He talks about "coordinates" in the execution of a program, such as i,j inside two nested loops, that index the progress of the program's execution. Then he says:
"The unbridled use of the go to statement has an immediate consequence that it becomes terribly hard to find a meaningful set of coordinates in which to describe the process progress. Usually, people take into account as well the values of some well chosen variables, but this is out of the question because it is relative to the progress that the meaning of these values is to be understood!"
Here's the rub: not all programs have "progress". Interactive text adventures are effectively "infinite loops" according to halting theory. But we know them more as state machines, and the kind of state machine that ADVENT represents does indeed have a set of "well chosen variables" (the state, plus PC) which indicate the coordinates of the program in state space with no ambiguity. In this case, then, Dijkstra's reductionist argument against GOTO no longer applies, as it can be seen with perfect clarity what state the program is in, even after a GOTO has been executed, just by looking at the current state.
More generally, Dijkstra hasn't shown that for all variables, no interpretation can be made without knowing the progress. He has just argued that this is the case for some variables. If a large enough set of variables exists whose interpretation is independent of progress then his argument also no longer applies. This is the case, for instance, when all variables are global and no function calls are recursive.
-
GOTO is dead.We live in COMEFROM age.I wonder what Djikstra would say about the modern development API and the GUI. He railed against unstructured GOTO statements, back in 1968.
But the entire modern GUI API is based on "event driven" programming. Replete with "OnRightButtonDown()" , "OnWindowClose()"
So, no. We did not forget GOTO just because some authority figure railed against it. We replaced it with a better concepts like event loop, event dispatching, object orientation.
-
Count positions in the game of Go
Try to count the number of legal positions in the game of Go, as described on http://www.cwi.nl/~tromp/go/le... How much memory is available per machine?
-
Re:RISC is not the silver bullet
John Mashey, one of the MIPS architecture designers among many other things, has written a really good essay on RISC architectural choices.
He posted it to the comp.arch USENET group a few times; here's a copy of that post that renders in a monospace font so you can read the ASCII tables easily. [Google Groups' version makes the tables unreadable.]
The best rule of thumb I like to remember from that essay is that RISC architectures try to make exception handling simple; for example, they don't tend to use the MMU for data access more than once per instruction, because then you have multiple ways that the instruction can generate an exception. Other RISC choices can be seen as stemming from this rule, such as: - no variable-length string comparison/move instructions
Still applies to most if not all RISCs these days; x86 sort-of has that with some looping instructions.
- accesses to multibyte data are aligned so they can't cross page boundaries
Does any RISC architecture other than SPARC have that restriction these days? (I had the impression ARM just ignored the low-order bits with multi-byte loads and stores, but somebody indicated that's not true in recent versions of the architecture.)
- load/store architectures; this keeps MMU exceptions and ALU exceptions from ever being generated by the same instruction.
Still applies to most if not all RISCs these days; does not apply to x86, even in 64-bit mode.
-
Re:RISC is not the silver bullet
John Mashey, one of the MIPS architecture designers among many other things, has written a really good essay on RISC architectural choices.
He posted it to the comp.arch USENET group a few times; here's a copy of that post that renders in a monospace font so you can read the ASCII tables easily. [Google Groups' version makes the tables unreadable.]
The best rule of thumb I like to remember from that essay is that RISC architectures try to make exception handling simple; for example, they don't tend to use the MMU for data access more than once per instruction, because then you have multiple ways that the instruction can generate an exception. Other RISC choices can be seen as stemming from this rule, such as:
- no variable-length string comparison/move instructions
- accesses to multibyte data are aligned so they can't cross page boundaries
- load/store architectures; this keeps MMU exceptions and ALU exceptions from ever being generated by the same instruction.The more complex the exception handling requirements, the more you pay to implement those, either with more hardware, [which can imply more cost, or more power, or longer cycle time], or by giving up opportunities for parallelism because the exceptions get too hard to handle with many operations in flight. Even if an exception is rare compared to the common case, the implementation has to be able to handle it correctly...
-
Re:How do you cover an arrow...
In Indiana, Most of our Arrow lights are in this configuration or they are part of their own turn lane. Again, if you mistake what the light means you aren't paying attention because the placement of the light itself means something.
At any rate, most of the comments are spot on. If a driver is paying attention the the situation then they should be okay unless they are a total newby to the area or they are in a state of panic.
-
Memories of long ago...
I gave an impromptu talk at an EuroFOO conference 5 years ago about exactly this problem: http://homepages.cwi.nl/~jack/presentations/OpenSource-EuroFoo.pdf.
My feeling is that the basic problem is that, in open source, at most 5% of the people involved are non-programmers (read: non-geeks). And for most projects the number is probably exactly 0% of the people involved. for shareware projects it's close to 50% (half of the developer:-). For commercial projects it's somewhere in the range of 20% (small vendors) to 99% (Microsoft, big software houses).
The input of the non-geeks, while usually dismissed by us geeks as fluff, can be really, really important. Because their interested in such technical trivialities as documentation, ease of use, learning curves, market acceptance (and, yes, financial bottom line too). Those trivialities are important even to hardcore geeks when the software in question is just a tool you need to get the job done (as opposed to the labour of love you've been spending years of your life on). -
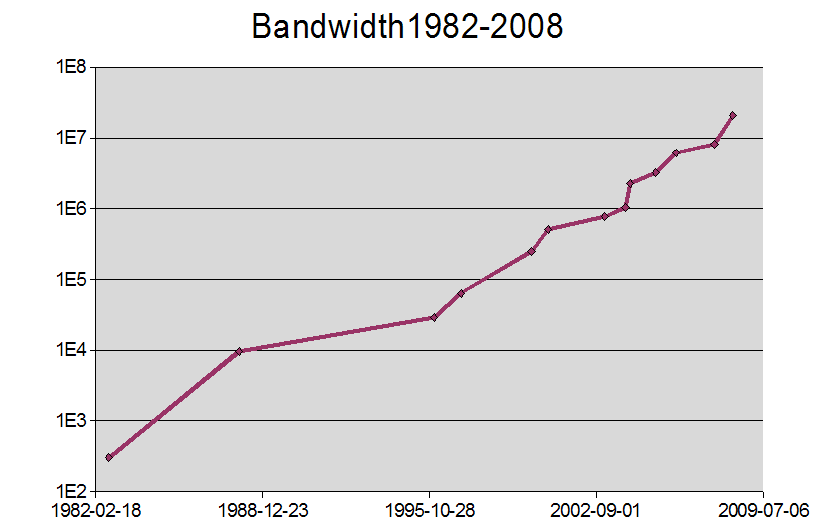
Re:Physical is still the best bandwidth
The problem is that while network bandwidth does not follow an exponential increase in bitrate over time, disc format capacity does. So this would suggest that the gap between online delivery and physical media is going to get larger, not smaller.
Now that's not true. I've only been online about 10 years and i can actually notice the exponential increase, something like this:
1999 56k
2003 256kbit
2004 512kbit
2005 1MBit
2006 2MBit
2007 4Mbit
2008 10MBit
At least, that's been my experience in the UK. Here's another diagram going from 1982(log scale, so it's exponential) -
Euphoria and ABC
-
BREAK RSA!!If you'd like to try your hand at breaking RSA composites, give this a whirl: GGNFS. There is another package from a research group in the Netherlands called CWI, which has a more gelled version of the Number Field Sieve.
CWI has ran their own attempts at various large composite numbers with their software, and it would be a good read. Since you're part of an Academic institution, you should be able to get access to their code. You could contact them through CWI's website if you want.
-
BREAK RSA!!If you'd like to try your hand at breaking RSA composites, give this a whirl: GGNFS. There is another package from a research group in the Netherlands called CWI, which has a more gelled version of the Number Field Sieve.
CWI has ran their own attempts at various large composite numbers with their software, and it would be a good read. Since you're part of an Academic institution, you should be able to get access to their code. You could contact them through CWI's website if you want.
-
MonetDB
It almost sounds like he is talking about MonetDB.
-
[Patent!] The only way to converge to freedom
The only way to guarantee convergence towards freedom, as well as allow unlimited incremental innovation, is to provide an instrument that causes you, like for GPL, keep the source free, to avoid stealing (as is done with GPL violations). In our case we are implementing a general business model Wish-IT® which will converge towards patent free products, that can be built upon by using incremental innovation for all future. To allow patents on products keeps the dystopia status quo, efficiently counteracting free competition. Our business model encourages competition.
There are plenty of business models whose gradient can be used, both to generate profit for the provider, as well as allow consumers to be part of the innovation process. Our model Wish-IT model is one of these, utilizing AI-methods to enable the consumer to be part of the innovation, acceptance, at least partial development and price tagging of the product. However, to guarantee that competition can be withheld in our case, the business model and the method itself is patented.
I spoke about this at an IP-symposium in Amsterdam 2005, where the title of my speach was: A patented method to fix the patent system. This implies that not all business method patents are evil. Some may benefit the society and increase competition, as I express in the brief abstract (all abstracts from meeting).
We have come quite far, although we need investors. If you know someone who want to be part of a global project for creating GPL like products. Get in touch. Also if you want to discuss more in details why this is beneficial both for the society, the companies involved and all consumers, get in touch!
Roland Orre, IT-researcher, consultant and entrepreneur -
[Patent!] The only way to converge to freedom
The only way to guarantee convergence towards freedom, as well as allow unlimited incremental innovation, is to provide an instrument that causes you, like for GPL, keep the source free, to avoid stealing (as is done with GPL violations). In our case we are implementing a general business model Wish-IT® which will converge towards patent free products, that can be built upon by using incremental innovation for all future. To allow patents on products keeps the dystopia status quo, efficiently counteracting free competition. Our business model encourages competition.
There are plenty of business models whose gradient can be used, both to generate profit for the provider, as well as allow consumers to be part of the innovation process. Our model Wish-IT model is one of these, utilizing AI-methods to enable the consumer to be part of the innovation, acceptance, at least partial development and price tagging of the product. However, to guarantee that competition can be withheld in our case, the business model and the method itself is patented.
I spoke about this at an IP-symposium in Amsterdam 2005, where the title of my speach was: A patented method to fix the patent system. This implies that not all business method patents are evil. Some may benefit the society and increase competition, as I express in the brief abstract (all abstracts from meeting).
We have come quite far, although we need investors. If you know someone who want to be part of a global project for creating GPL like products. Get in touch. Also if you want to discuss more in details why this is beneficial both for the society, the companies involved and all consumers, get in touch!
Roland Orre, IT-researcher, consultant and entrepreneur -
A patented method to fix the patent system
seems to be the only way then... (AI applied to business)
Presentation Oct 2005 http://www.cwi.nl/pr/CWIiB/2005/
A.I. -
A patented method to fix the patent system
seems to be the only way then... (AI applied to business)
Presentation Oct 2005 http://www.cwi.nl/pr/CWIiB/2005/
A.I. -
Re:Software art, yes, but...
I see what you are saying, and agree to a certain extend, but there is something about demoscene code that transcends pure craft. I don't know if it's art, but reading and understanding obscenely clever code can stimulate your emotions, or at the least, fill you with a sense wonder, something most art struggles to achieve.
That said, this is what I call programming as art: http://homepages.cwi.nl/~tromp/maze.html
Unfortunately, the Slashdot filter calls it "lame" and "junk", so I can't post it here. -
Re:Science curriculum
They will then turn to David Hume's classic argument that there is no reason whatsoever that anybody should trust the results of inductive reasoning (i.e. they will say that evolution can never really be proved).
One may rebut that pure mathematics, such as set theory, is not subject to that limitation; that all work in the the real world is based on induction on finite ordered sequence of data observations; and that it may be mathematically shown (see Vitanyi and Li and Wallace and Dowe [WARNING: Postscript file of heavy duty math]) that the simplest expressed explanation for a finite data will most probably be correctly predictive.
For some reason, I've yet to meet a religious fundamentalist who can understand any set theory work done after Goedel's time...much less come up with a coherent response. Possibly because they're not that big into education?
-
Mathematical consistency
if science is necessarily naturalistic, then how do we know that a naturalistic explanation like "big bang + evolution" is true, as opposed to a credible falsehood?
As the naturalistic explanation describes a greater diversity of the observed data compactly, it's more probably the truth. (See Minimum Description Length Induction, Bayesianism, and Kolmogorov Complexity", by Paul M. B. Vitányi and Ming Li [subscription PDF, free PS] for the math to prove this.) You can write the equations for all the most complicated models in physics (which describe pretty well all observed phenomena) and put them legibly on a one square meter poster, with the worst inconsistency being between quantum mechanics and relativistic gravity. The bible takes longer and presents more internal contradictions (or as the Catholic Church prefers to call them, "Mysteries of Faith").
This whole "falsification" thing seems a little two-edged to me. Please demonstrate that it cuts creationists but not evolutionists in light of "creationism as an attempt to falsify evolution".
Simple; falsification means that some hypothetical data might be found to prove the theory wrong. For example, Evolution (on Earth) might be proven false (and Intelligent Design true) by, say, the landing of UFO's and the appearance of the immortal alien designers who have been engineering the Earth's ecology for the past four billion years or so. "Yes, we've been doing this for entertainment. If you want, we can give you a courtesy copy of the 'Making Of' special to watch. We nearly went broke when the giant reptillians market went bust and have been struggling frantically to catch up with the competition ever since. One of our VP's for marketing has a possible comeback idea that he thinks will appeal to the same key demographic, though he won't say where he got it; your females won't need much modification, but the males of your species are going to need to grow a lot more tentacles over the next couple generations...."
Shortly before the collapse of civilization into a bad Hentai piece, the scientists admit that, yes, evolution is a crock, that whole thing (at least hearabouts) was "intelligently designed", allowing for the loose value of "intelligent" that "entertainment executive" gives us.
However, there is no* possible datum that might appear that would disprove their proposition "life was intelligently designed". It might become an observed fact (if they get really miraculously lucky), but it won't ever be a theory, because it's not falsifiable. Intelligent design isn't merely wrong, it isn't even wrong .
* I suppose the appearance of God announcing "Say, I thought I left an nice damp chunk of iron here; where'd all this wet carbon-based goo wandering about come from?" shortly before correcting the problem might change a few minds before wiping them out, but technically that doesn't rule out that the whole thing is one of Satan's practical jokes.
-
Sounds like a parallel MonetDB system
From the paper: The use-case scenario is to find mutual acquaintances between two people. More specifically, the query is as follows: give me a list of people known to both Tim Berners-Lee and Dave Beckett. If that's really all there is to it then there's nothing new here other than some acronyms. It may be interesting research but apart from the RDF syntax there is nothing new here worthty of the PR hype.
Fast queries over 7 billion triples may sound like a breakthrough but systems like http://monetdb.cwi.nl/projects/monetdb/MonetDB/Ver sion4/Documentation/mel/index.html have been able to do that kind of thing blindingly fast for many years. Once you store everything as a BAT (binary association table), 20-way joins that would choke an ordinary RDBMS become easy.
The weakness of MonetDB-like systems is generally that they don't do well in the face of OLTP style transactional update patterns. They are optimized for loading data once and reading many times, not dealing with a steady stream of queries and updates, and typically you have no choice but to resort to http://infolab.stanford.edu/~backrub/google.html style parallel index construction, which is most of what the technical report goes into. -
MonetDB does not need stealth
Vertica has indeed made the business/venture steps to
follow the MonetDB approach to exploit column-based stores
for large scale datawarehouse solutions.
Its science library provides many studies on the underlying
technology.
MonetDB has already build a business history in the
area of analytical CRM solutions available through SPSS.
In the area of datamining PROXIMITY is a leading
product for relational mining.
Not to mention the support for both SQL and XQuery
engine support. This all in the context of an open-source
community activity for several years.
See http://monetdb.cwi.nl/
http://monetdb.cwi.nl/projects/monetdb/Development /Credits/Partners/index.html -
MonetDB does not need stealth
Vertica has indeed made the business/venture steps to
follow the MonetDB approach to exploit column-based stores
for large scale datawarehouse solutions.
Its science library provides many studies on the underlying
technology.
MonetDB has already build a business history in the
area of analytical CRM solutions available through SPSS.
In the area of datamining PROXIMITY is a leading
product for relational mining.
Not to mention the support for both SQL and XQuery
engine support. This all in the context of an open-source
community activity for several years.
See http://monetdb.cwi.nl/
http://monetdb.cwi.nl/projects/monetdb/Development /Credits/Partners/index.html -
Given that...MonetDb, is similarly configured as a column oriented AND Open source, and appears to clean the clock of most of the major commercial and Open Source databases for huge data set queries, (see the benchmarks at axyana.com for an example), where is Vertica's market advantage supposed to be?
By which I am asking that while Vertica is obviously well-researched and well funded as a start up, MonetDB is well-researched, already benchmarked and available now.. So why would I wait to invest my time, energy, and $$ in a proprietary future product rather than the time and energy, etc. to develop market leadership in my chosen corporate area in the present? -
Re:My user concerns
Here is is a what a "emerge --search java" yields in gentoo:
* app-accessibility/java-access-bridge Latest version available: 1.6.0-r1 Latest version installed: [ Not Installed ] Size of files: 120 kB Homepage: http://developer.gnome.org/projects/gap/ Description: Gnome Java Accessibility Bridge License: LGPL-2 * app-emulation/emul-linux-x86-java [ Masked ] Latest version available: 1.6.0 Latest version installed: [ Not Installed ] Size of files: 61,248 kB Homepage: http://java.sun.com/j2se/1.6.0/ Description: 32bit version Sun's J2SE Development Kit License: dlj-1.1 * dev-java/ant-javamail Latest version available: 1.7.0 Latest version installed: [ Not Installed ] Size of files: 6,682 kB Homepage: http://ant.apache.org/ Description: Apache Ant's optional tasks depending on sun-javamail License: Apache-2.0 * dev-java/apple-java-extensions-bin Latest version available: 1.2-r1 Latest version installed: [ Not Installed ] Size of files: 3 kB Homepage: http://developer.apple.com/samplecode/AppleJavaExt ensions/AppleJavaExtensions.html Description: A pluggable jar of stub classes representing the new Apple eAWT and eIO APIs for Java 1.4 on Mac OS X. License: Apple * dev-java/aterm-java Latest version available: 1.6 Latest version installed: [ Not Installed ] Size of files: 93 kB Homepage: http://www.cwi.nl/htbin/sen1/twiki/bin/view/SEN1/A TermLibrary Description: Java library for ATerm exchange License: LGPL-2.1 * dev-java/blackdown-java3d-bin Latest version available: 1.3.1-r1 Latest version installed: [ Not Installed ] Size of files: 9,881 kB Homepage: http://www.blackdown.org/ Description: Java 3D Software Development Kit License: sun-bcla-java-vm * dev-java/cairo-java Latest version available: 1.0.5-r1 Latest version installed: [ Not Installed ] Size of files: 353 kB Homepage: http://java-gnome.sourceforge.net/ Description: Java bindings for cairo License: LGPL-2.1 * dev-java/glib-java Latest version available: 0.2.6-r1 Latest version installed: [ Not Installed ] Size of files: 323 kB Homepage: http://java-gnome.sourceforge.net/ Description: Java bindings for glib License: LGPL-2.1 * dev-java/gnu-javamail Latest version available: 1.0-r1 Latest version installed: [ Not Installed ] Size of files: 690 kB Homepage: http://www.gnu.org/software/classpathx/javamail/ Description: GNU implementation of the Javamail API License: GPL-2 * dev-java/java-config Latest version available: 2.0.31-r3 Latest version installed: 2.0.30 Size of files: 16 kB Homepage: http://www.gentoo.org/proj/en/java/ Description: Java environment configuration tool License: GPL-2 * dev-java/java-config-wrapper Latest version available: 0.12-r1 Latest version installed: 0.12 Size of files: 7 kB Homepage: http://www.gentoo.org/proj/en/java Description: Wrapper for java-config License: GPL-2 * dev-java/java-getopt Latest version available: 1.0.13 Latest -
every year, this must get re-explained
Okay, the 2006 "Explanation of Why IOCCC Is Not Just Ugly Code" is now underway.
The winning entries are pieces of art, not pieces of dung. They look like they should do one thing, but they do another. They arrange the code in a visually pleasing but maintenance-proof way. They choose some concept and take it to the absurd limit, all within a tiny amount of code.
My favorite past entry is John Tromp's maze generator. In seven lines of code, he produces random mazes. The variables are named M, A, Z, E instead of useful functional mnemonics. The source code is formatted to LOOK like a maze. And even in this maze which is the source code, the passages in the maze spell out the word 'maze.' This is not just putting a pig on the lipstick, this is making the pig look *good*.
-
Elecraft K2
It looks like it's about 20:1 for actual responses, so I'll add mine.
I built an Elecraft K2 (more pix). Mine looks pretty much like the one in the picture.
A couple of weeks ago I went to Amsterdam and used it on Saturday and Sunday and got my radio to signal to Bulgaria, Russia, Italy, Montenegro, Poland, and England. (OK, some of these were also with another kit, a handheld KX1, but it's smaller and took only a weekend to build; more info, magazine article with more pix) -
Re:Just in time...
Animation does have other uses you know, often to convey information that would be very difficult on a static page:
http://en.wikipedia.org/wiki/Barycenter
http://en.wikipedia.org/wiki/Wankel_engine
http://en.wikipedia.org/wiki/Guitar_moves
http://homepages.cwi.nl/~dik/english/traffic/signa ls/vl-v.html
As is most often the case, it's not the format that's the problem, it's what people use it for:
http://www.citilink.com/~grizzly/anigifs/itchy.gif -
Re:Good,
Firefox has been getting better of late it's true, but it still suffers from the common Open Source Project issue that the sexy visible eye-candy stuff gets priority over unexiting but essential background code.
I'm guessing you don't use a whole lot of F/OSS, do you? In most cases, the reverse is the biggest complaint. A lot of F/OSS has tons of great functionality, and you could really accomplish so much with it... if only it had a better interface.
Rather than try to word it myself, I'm going to quote from http://homepages.cwi.nl/~steven/vandf/2004.1-itch
Open Source software is produced by programmers. Programmers are very different from the general public (a far greater proportion of programmers are intuitives than in the general public, for instance). This means that when programmers produce open source software, since they are largely scratching their own itch, they will tend to produce the software for themselves, and in particular be perfectly content with the (programmer-oriented) user interface. - Steven Pemberton.. html -
MacPython
you can download and IDE(PythonIDE) and extras from MacPython
i'm in the same boat, i just got a powerbook for christmas and i downloaded the stuff last night, wanting to learn some python.
i had trouble with the install, all the latest stuff is for 10.3 and i've got 10.4. the wiki FAQ can get you up and going. also has a package manager and you can download PyObjC, which is a "bridge" (wrapper class?) so you can code in python and use cocoa elements. just getting my mac a week ago, i don't actually know what much of the above means, but thats where i'm heading. -
COBOL Moving Up On JavaCOBOL is quietly moving up on the WWW. See this link by Microsoftie Ralf Lammel to understand why. According to Lammel a Gartner study shows that
- 75% of all business data is processed in COBOL,
- There are between 180 billion and 200 billion
lines of COBOL code in use worldwide, and - 15% of all new applications (5 billion lines)
through 2005 will be in COBOL.
Every significant language vendor has a COBOL compiler but need not market it since demand is so high.
COBOL has two properties that make it the up-and-coming language for WWW development:
- fixed-length strings - no buffer overflows, no dynamic memory allocation, faster program loading, execution and clean-up, and
- fixed-point decimal math - COBOL is an accountant's wet dream and does exactly what accountants want.
- 75% of all business data is processed in COBOL,
-
Re:cdr cdr car?
OCCAM isn't that much older than Python (which borrowed the idea from ABC). Pythoneers like to point to a Knuth quotation from 1974:
"We will perhaps eventually be writing only small modules which are identified by name as they are used to build larger ones, so that devices like indentation, rather than delimiters, might become feasible for expressing local structure in the source language."
(but they sometimes miss the "only small parts" and "expressing local structure" parts when they do that...) -
... "DUJ" ???according to The World Standard"
but, but, you maybe are using a diff. set
-
Re:Maze of Code
If there's anyone reading this who doesn't recognise that rather famous example, here is the article the parent stole that code from. It's rather interesting, as it explains how the code was actually constructed, instead of just presenting it as a fait accompli.
-
Re:Not a fan of Go, try Hex
The rules to go are very clean if stated cleanly; see http://homepages.cwi.nl/~tromp/go.html
Sometimes people who have played only a game or two think that ko is an exception, but this is a misconception; in advanced strategy it is a fundamental rule that is considered in almost every important move. -
Re:how close are we to self forming dictionaries?
We are very close: My paper at http://www.cwi.nl/~paulv/papers/amdug.pdf shows a method to create a self-forming English-Spanish translation dictionary without using search results at all, just Google page counts and math. Comments welcome. -Rudi
-
Re:Play OriMazes in JavaScriptYes, the target piece (marked <-) has to be moved to the leftmost column.
The optimal solution takes 40 moves, so I have no idea where your 20 comes from:-(See also the paper I wrote about it at http://www.cwi.nl/~tromp/orimaze.html
-John
-
Play OriMazes in JavaScriptOrimazes are sliding block puzzles in disguise where the blocks are all unit size but limited to either horizontal or vertical movement. There is only one free spot, so sliding the blocks is equivalent to moving the free spot, which gives it the flavor of a maze.
The hardest 4x4 instance can be played at
http://www.cwi.nl/~tromp/oriscript4.html
while the hardest 5x5 instance is at
http://www.cwi.nl/~tromp/oriscript5.html-John
-
Play OriMazes in JavaScriptOrimazes are sliding block puzzles in disguise where the blocks are all unit size but limited to either horizontal or vertical movement. There is only one free spot, so sliding the blocks is equivalent to moving the free spot, which gives it the flavor of a maze.
The hardest 4x4 instance can be played at
http://www.cwi.nl/~tromp/oriscript4.html
while the hardest 5x5 instance is at
http://www.cwi.nl/~tromp/oriscript5.html-John
-
Re:types and ''natural'' programming
Well, ha ha, but most people I know who use powerful type systems don't actually use type debuggers.
Ok, I was being a little facetious, and I've never used a type debugger either. But I know that some people are pushing Haskell's type system pretty hard (eg, OOHaskell), and I think that some solution must be found for the notorious incomprehensible type errors before normal programmers can take advantage of things like this.
I do agree with the authors that "natural" problem-specific languages are useful for people who are not normally programmers (those people will increase in number dramatically, soon), but I disagree that this is an appropriate condition for the design of general-purpose languages.
The promise of embedded domain-specific languages is that you can create these friendly sub-languages within a sufficiently powerful general-purpose language. The casual programmer can stay within the sub-language, but the "real" language is right there when you need it.
-
Re:I just RTFA...
Covering 30 numbers per byte and precomputing all the bit-indices, one arrives at: http://www.cwi.nl/~tromp/pearls.html#sieve
-
Java:JVM != .NET:C#
-
Brewster KahleAlthough there were many great hackers at OSCON this year, I was personally most inspired by Brewster Kahle, the man behind the Internet Archive repository of public domain media content. He pointed out that there's no use in blaming The Corporations for trying to get as rich as possible; it's the job of society and government to channel that greed with an appropriate legal regime (e.g. copyright reform). There was a good parallel with the destructive railroad monopolies of the 19th century, finally curbed by the Sherman Act. He also praised the VLC media player and called for an open-source SMIL-based "video browser"; perhaps something like AMBULANT.
Some Portland kids called Feel(This)Films followed me around a bit and are hoping to release a short under a Creative Commons license; feel free to contact them if you have anything from the con to contribute.
-
Re:geteralization and compression are equivalent
This is probably the best I can do.
Whether you're finding exploitable patterns in discrete data or estimating a "function" for a block of pixels in an image to use in some kind of lossy compression, it's a form of generalization. It's one way of formulating a learning problem.
I can think of one very interesting project offhand, which uses compression coefficients to assess expected generalization accuracy.
(Ooh. I just found a paper on Compression-based Learning. That one looks like fun.)
Okay, I've been searching for about a half an hour now. I apologize that I haven't been able to find something that proves equivalence. (There's a guy in another lab that's really into this. Maybe he's got a paper on it.) You can think of it this way, intuitively: both compression and generalization seek a small number of bits to accurately describe a large number of bits.
(Huh. Maybe this dearth of papers on compression = generalization indicates that it's something I ought to look into for a new research direction... -
Re:Markup languages are still code.You're half right. It is a programming language, but it is a domain-specific language (DSL). DSL's are not always Turing-equivalant (which is what it takes for a language to bootstrap itself). Configuration files are an example of a limited kind of non-Turing-complete DSL's. Also called "little languages" by Brian Kernighan.
Crispin
----
Crispin Cowan, Ph.D.
CTO, Immunix Inc. -
Re:Me! Me! I've got the worst.
deallocating the middle third of it and still being able to access the data at either end
Really! That's cool!How about a language that lets you specify row or column major order for array storage
Sweet! I'll have to add that into my own matrix C++ classes.Then there's the use of the semi-colon as a statement separator
Ah! So much more logical. ';' is the binary operator for sequencing. I never understood the concept of ';' as a postfix operator that somehow didn't actually do anything but was needed to disambiguate the clearly incorrectly designed grammar.
Where do I get it?
PS Brainfuck is much overrated. It's just a straightforward register machine. I much prefer combinatory logic.
-
sorry (formatted properly and a few extra lines)
I've spent the last 5 years writing code. I've gone back to school to finish my degree. I hate writing code, but I enjoy mathematical logic. I like the rigour of foundational mathematics and theoretical CS.
Unfortunately, CS courses don't transfer well, and I don't feel like paying large ammounts to private school to finish non-major coursework (unfortunately I can't transfer non-major coursework in from another university at my old school).
I hate writing stupid code. I hate paying someone for the privilege of writing trivial classroom code. I'm working without the degree, so a math/physics double major with a minor in CS will work for me. Frankly, no one cares what your major was in IT. CS-based math courses (theory of computation|algorithms|discrete math) tend to lack rigour. My experience is that they often stop sort of proof. How can you study graph theory without proofs? Erdos and Dykstra are rolling over in their graves! CS is the one field you can teach yourself.
Do you want to be in IT or do you like applying computers to scientific problems? Frankly, physics, chemistry, and biology have computational subfields. There are even a few bioinfomatics programs for undergraduates. You might find cognitive science or statistics interesting. Heck, many good physics departments offer a computational physics/scientific computing course(s). It just depends.
The other option might be to suffer through a few CS courses, and get a degree in something else and study CS at the graduate level. Most CS departments take people from other disciplines. Math is the best in that regard. Some MIS programs (like CMUs) allow you to focus on non-programming areas and are pretty good. You might like a program like Boston University's "Cognitive and Neural Systems". CalTech has a similar program at the Koch Lab. I even saw a "computational mathematics" program at JHU that required little programming. In fact, some of the best computer scientists are secretly mathematicians. Knuth, (Martin) Davis, Minsky, Ritchie, and many others have PhDs in math.
The little joke among computer scientists is that the best don't often study it. Logicians and combinatorical mathematicians tend to be better with the theory. Engineers are better with hardware. EEs are usually the ones who write device drivers. Heck, who wouldn't want a Claude Shannon or Lofti Zadeh working on CS problems. Frankly, I don't understand the point of modern-day CS. It's not math and it's not quite engineering. I like CS, but I just hate the boring coursework.
If you're still not convinced take a look at "The Feynman Lectures on Computation" and "Feynman and Computation". One of his hobbies was algorithm analysis. The man wasn't just a brilliant physicist. He did ground-breaking work with computers. I was first introduced to analog computation and quantum computation by Richard Feynman's work. He also worked on some deeper computational problems during the Manhattan Project (see "Surely You're Joking" [his memoirs]).
Type analog computation in a search engine and you'll see that this area of CS is done by other other fields. I've been reading about the applications of analog computation and their relation to limits of computation (see Neural Networks and Analog Computation: Beyond the Turing Limit). In fact, the future of computing may lie in some analog world. The computer program is math (see An Introduction to Kolmogorov Complexity and Its Applications). Church's Thesis may prove to be the most valuable piece of 20th century mathematics. In fact, I've seen a few logicians that use LISP code to do mathematical work (like Gregory Chaitin).
Ultimately, I think you need to figure out what you really enjoy doing and find other people who are doing it. -
CS is an interdisciplinary science
I've spent the last 5 years writing code. I've gone back to school to finish my degree.I hate writing code. I enjoy mathematical logic. I like the rigour of foundational mathematics/theoretical CS.
Unfortunately, CS courses don't transfer well, and I don't feel like paying large ammounts to finish non-major coursework (unfortunately I can't transfer it in from another university) at my old school.
I hate writing stupid code. I hate paying someone for the privilege of writing trivial classroom code. I'm working without the degree, so a math/physics double major with a minor in CS will work for me. Frankly, no one cares what your major was in IT. CS-based math courses (theory of computation|algorithms|discrete math) tend to lack rigour. My experience is that they often stop sort of proof. How can you study graph theory without proofs? Erdos and Dykstra are rolling over in their graves! This may be differ by school. CS is the one field you can teach yourself.
Do you want to be in IT or do you like applying computers to scientific problems? Frankly, physics, chemistry, and biology have computational subfields. There are even a few bioinfomatics programs for undergraduates. You might find cognitive science or statistics interesting. Heck, many good physics departments offer a computational physics/scientific computing course(s). It just depends.
The other option might be to suffer through a few CS courses, and get a degree in something else and study CS at the graduate level. Most CS departments take people from other disciplines. Math is the best in that regard. Some MIS programs (like CMUs) allow you to focus on non-programming areas and are pretty good. You might like a program like Boston University's "Cognitive and Neural Systems". CalTech has a similar program at the Koch Lab. I even saw a "computational mathematics" program at JHU that required little programming. In fact, some of the best computer scientists are secretly mathematicians. Knuth, (Martin) Davis, Minsky, Ritchie, and many others have PhDs in math.
The little joke among computer scientists is that the best don't often study it. Logicians and combinatorical mathematicians tend to be better with the theory. Engineers are better with hardware. EEs are usually the ones who write device drivers. Heck, who wouldn't want a Claude Shannon or Lofti Zadeh working on CS problems. Frankly, I don't understand the point of modern-day CS. It's not math and it's not quite engineering. I like CS, but I just hate the boring coursework.
If you're still not convinced take a look at "The Feynman Lectures on Computation" and "Feynman and Computation". One of his hobbies was algorithm analysis. The man wasn't just a brilliant physicist. He did groundbreaking work with computers. I was first introduced to analog computation and quantum computation by Richard Feynman's work. He also worked on some deeper computational problems during the Manhattan Project (see "Surely You're Joking" [his memoirs]).
Type analog computation in a search engine and you'll see that this area of CS is done by other other fields. I've been reading about the applications of analog computation and their relation to limits of computation (see Neural Networks and Analog Computation:
Beyond the Turing Limit. In fact, the future of computing may lie in some analog world. The computer program is math (see An Introduction to Kolmogorov Complexity and Its Applications) -
Re:what if theory didn't exist?
I don't know of a proof online, but here is a reference to the definitive text An Introduction to Kolmogorov Complexity and Its Applications. The book is a very good introduction, and I find the whole subject to be extremely interesting and beautiful.
This Usenet article gives more references, and Google searches for "Kolmogorov Complexity Theory" and "Kolmogorov Complexity Theory Occam's Razor" gives many hits. Check it out - it's very interesting stuff! -
Re:Instructions
-
Re:Somewhat off topic but...Just to add to the above, if you use MacPython, they you do get more Applescript-like functionality. i.e. for controlling other Applications. There is some confusion on this since Apple supports the standard Python. MacPython, while using the same language, is technically a different beast. A lot of the language extensions work in MacPython but not the command line Python (and not the variant Python that you may have installed with Fink). Confusing? Yes. But MacPython includes a nice IDE so is useful for many reasons anyway.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}