 Slashdot Mirror
Slashdot Mirror
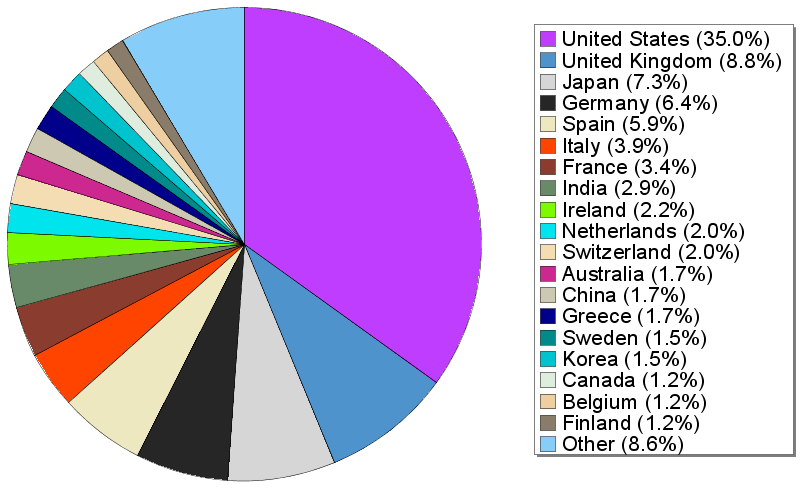
Domain: w3.org
Stories and comments across the archive that link to w3.org.
Comments · 6,785
-
Unforgivable error in article (and device!) SMIL
Supports captions through Microsoft's SAMI (synchronized accessible media interchange, or *.smi files, are basically Microsoft's answer to RealPlayer's *.smil or "smile" files)
WHAT THE FUCK! SMIL is an XML mulitmedia synch language with 10 areas of functionality. The Synchronized Multimedia Integration Language is not from Real - although they HAVE turned themselves around and made a nice implementation, without extending it *COUGH*adobe-svg*cough*.
Does it support this microsoft extedned bullshit, or is it a typo they misread? I think
At least it supports ogg... I can only assume the previous error is indeed an error. -
Re:A Question
If I may answer my own question:
from http://www.w3.org/Protocols/rfc2616/rfc2616-sec14. html#sec14.43
[The User-Agent header] is for statistical purposes, the tracing of protocol violations, and automated recognition of user agents for the sake of tailoring responses to avoid particular user agent limitations.
So there you have it, it should be used to tailor a page for a specific browser, but I think a lot of sites have taken that too far. Blocking out a web page because they think it doesn't work isn't right, and most of the time it works fine anyways. -
Maybe because...
Usually the spacing is already at optimal settings. Or maybe you don't know about text justification. Most online texts don't use it. and I find it annoying in newspapers and magazines.
http://www.google.com/search?q=%22text+justificati on
First item turns up CSS3 Text Effects Module and it appears to be this that Microsoft is patenting -
Awful website.
Not only do they claim that the site is not compatible with IE (which renders it fine) But they claim that the website is w3 compliant.
After the page loads I get a nice JavaScript error, and also decided to check the w3 validator and found 24 errors, not making the website compliant.
If your going to complain about " standard compliant browsers" you should at least make your site compliant to THE standards you claim to enforce.
-
W3C info...
There is much truth to your statement:
The key members of the organization are 3 universities which manage operations of the W3C (MIT CSAIL (USA), ERCIM (France), and Keio Univ. (Japan)). That being said, members of the organization are also businesses (like Microsoft, IBM, and Intel)
From looking at the site, it appears most of the actual implementation is done by graduate students or PHD researchers - which might explain some of the choices made.
Nevertheless the mission of the W3C is: "To lead the World Wide Web to its full potential by developing protocols and guidelines that ensure long-term growth for the Web." It says nothing about implementing said protocols or guidelines - so anything we get from them that works is a plus imho. Additionally, the Amaya browser/xml editor has some very neat capabilities (annotating existing webpages - without altering the actual website of the originating document, mathematical formulas and vector graphics) that certainly make it a very good technology testbed. Finally all of the code they generate is GPL and OSI license equivalent. Given that and the fact that their Director is Tim Berners-Lee - I can cut them some slack.
Given its mission, I would go here first if I intended to implement those standards. Apparently Mozilla, IE, and other browsers do not think its important to do a complete implementation this go-round. Some of that might be ameliorated with plugins...if you really need some specific display functionality not covered by your favorite browser (that presumes you could implement a plugin yourself - or have friends who can do it for you). -
Re:One easy workaround...
What about the HTTP/1.1 header "Cache-Control: no-store"? Although the rfc description of what it does seems rather confusing to me.
-
Re:I liked Internet Explorer 7 the first time...
If I was a betting man I would say that the Amaya browser created by the world wide web consortium probably would pass the test. Since the W3C also owns the CSS standards that is probably a no-brainer.
-
Re:This may be off-topic
Don't develop for any browser, develop according to the standards. I've been doing this for 7 years.
Kudos for recommending Firefox to your customers.
-
Wow! Media-specific rendering instructions.
...content on the web will be automatically customized according to the device being used to access it (PDA, smartphone,etc)
That sounds rather like a prediction of the present.
-
Re:innerHTML replacement
Take a look here.
Yes, I'm well aware of that note. I quote:
This document is a Note made available by the World Wide Web Consortium (W3C) for your information. Publication of this Note by W3C indicates no endorsement by W3C or the W3C Team, or any W3C Members.
Feel free to ignore it, it's something some W3C members published for guidance, it's certainly not normative, it hasn't gone through the normal W3C publication process involving peer review, and means about as much as a tutorial found on a non-W3C site. Don't let the fact that it appears on the W3C website fool you.
I was mistaken though, it is the DOCTYPE that sends the browser into quirks mode, not the content-type.
Only some doctypes send browsers into quirks mode - some HTML and XHTML doctypes do it, some don't. You can use XHTML without triggering quirks mode just fine.
According to W3C specifications, sending XHTML 1.1 strict as text/html is invalid.
That's not exactly true. It has nothing to do with validity, and it's an IETF specification, although it was co-written by a W3C member. It is against spec to send XHTML 1.1 as text/html, but you can send XHTML 1.0 documents following Appendix C as text/html just fine according to spec.
"Tag soup" originally meant code that was written as if tags were commands, rather than to arrange a document into a tree-like structure, and was usually characterised by mis-nested tags. These days, it's often used as a synonym for "code I don't like".
Sending XHTML 1.0 strict as text/html would make the browser read it as tag soup
No. Sending XHTML 1.0 Strict as text/html makes some browsers process it with the rendering engine they use for tag soup. It does not make XHTML into tag soup. The XHTML continues to be valid, compliant with the XML specification, and perfectly within spec. The fact that some browsers don't treat it as such is irrelevent.
Thus, a browser interpreting a Web page as XHTML will refuse to display the page if it encounters a well-formedness error, ensuring that future XHTML will not be tag soup.
This statement merely says that the thing that caused people to write tag soup (i.e. tags as commands instead of tags defining a tree) is not present in XHTML because of the well-formed requirement of the XML 1.0 specification. It sounds to me as if you are reading more into it.
Because XHTML 1.0 served to browsers as HTML is parsed as if it were badly-formed HTML, XHTML 1.0 is affected by tag soup in the same way as HTML.
I'm not sure what that statement means to say, it's very badly written. What does "affected by tag soup" mean? Serving an XHTML document as text/html doesn't leave open a vulnerability where evil tags can come in and corrupt your documents. "Tag soup" is a property of invalid documents, if you write valid XHTML, then there is no tag soup to affect anything.
Ah. You really shouldn't quote Wikipedia, it's not an authoritive source. I've noticed a number of technical errors in the articles there in the past. Refer to the specifications instead.
I am not saying that serving up the content as text/html changes it from XHTML to HTML, but it will affect the rendering of the page
Yes it will. In this particular case we are discussing, it will let you use innerHTML in Gecko-based browsers.
and it may not work the way you expect it to. That is why it is a bad practice.
If you don't know what you are doing, anything is a bad practice. I'm well aware of the differences between HTML and XHTML; in fact I've written several testcases for browsers bugs to help fix XHTML support fairly recently.
I'm saying:
- Serving XHTML 1.0 documents as text/h
-
SVG - VML compiler
It seems that VML never became a W3C recommendation, as it was superseded by SVG. MSIE only supports VML because it's a Microsoft Office format. As far as I know, there are no plans to support SVG natively in MSIE.
Perhaps it is possible to get MSIE to support a simple subset of SVG by first transforming it into VML. Since both formats are based on XML, perhaps it could even be done on the client side using XSLT. Has anyone tried this? It could be packaged as part of IE7 (the Dean Edwards hack, not the next version of MSIE)?
If such a hack were accomplished, it could spark the development of some nifty SVG-based applications. With Opera, Mozilla/Firefox and Safari all supporting SVG natively (now or in the near future), and MSIE supporting it via VML, it would be possible to reach a wide audience without any plugins!
-
SVG - VML compiler
It seems that VML never became a W3C recommendation, as it was superseded by SVG. MSIE only supports VML because it's a Microsoft Office format. As far as I know, there are no plans to support SVG natively in MSIE.
Perhaps it is possible to get MSIE to support a simple subset of SVG by first transforming it into VML. Since both formats are based on XML, perhaps it could even be done on the client side using XSLT. Has anyone tried this? It could be packaged as part of IE7 (the Dean Edwards hack, not the next version of MSIE)?
If such a hack were accomplished, it could spark the development of some nifty SVG-based applications. With Opera, Mozilla/Firefox and Safari all supporting SVG natively (now or in the near future), and MSIE supporting it via VML, it would be possible to reach a wide audience without any plugins!
-
Re:innerHTML replacement
Take a look here.
Also, take a look here for some information on sending IE into quirks mode. I was mistaken though, it is the DOCTYPE that sends the browser into quirks mode, not the content-type.
According to W3C specifications, sending XHTML 1.1 strict as text/html is invalid. Sending XHTML 1.0 strict as text/html would make the browser read it as tag soup, which is not what you want to do:
"How XHTML affects tag soup
XHTML is a reformulation of the HTML language based on XML. The XML Specification clearly defines what a conforming user agent (such as a web browser) must do when malformed code is encountered. Thus, a browser interpreting a Web page as XHTML will refuse to display the page if it encounters a well-formedness error, ensuring that future XHTML will not be tag soup.
However, XHTML 1.0 states that XHTML may be interpreted by current Web browsers as HTML if it follows a set of compatibility guidelines defined in Appendix C of the XHTML 1.0 Recommendation. At this time, the popular web browser Internet Explorer is unable to interpret XHTML documents as XML, and thus most current XHTML pages are served to browsers as HTML, using the MIME type of "text/html".
Because XHTML 1.0 served to browsers as HTML is parsed as if it were badly-formed HTML, XHTML 1.0 is affected by tag soup in the same way as HTML.
Future versions of XHTML after version 1.0 do not allow the XHTML to be served to browsers as HTML. If implemented according to the recommendation, this should prevent the problem of tag soup once XHTML served as XHTML is supported by all major browsers."
Source
I am not saying that serving up the content as text/html changes it from XHTML to HTML, but it will affect the rendering of the page - and it may not work the way you expect it to. That is why it is a bad practice. The W3C recommends that you serve XHTML documents as they are supposed to be served up: application/xml+xhtml.
Here is also a page that talks about why serving XHTML as text/html is considered harmful.
I'm also not saying that you can't serve up XHTML as text/html, just that it's probably not a good idea, and that it could cause problems later.
Thanks for the explanation of invalid vs. malformed. -
Re:innerHTML replacement
Take a look here.
Also, take a look here for some information on sending IE into quirks mode. I was mistaken though, it is the DOCTYPE that sends the browser into quirks mode, not the content-type.
According to W3C specifications, sending XHTML 1.1 strict as text/html is invalid. Sending XHTML 1.0 strict as text/html would make the browser read it as tag soup, which is not what you want to do:
"How XHTML affects tag soup
XHTML is a reformulation of the HTML language based on XML. The XML Specification clearly defines what a conforming user agent (such as a web browser) must do when malformed code is encountered. Thus, a browser interpreting a Web page as XHTML will refuse to display the page if it encounters a well-formedness error, ensuring that future XHTML will not be tag soup.
However, XHTML 1.0 states that XHTML may be interpreted by current Web browsers as HTML if it follows a set of compatibility guidelines defined in Appendix C of the XHTML 1.0 Recommendation. At this time, the popular web browser Internet Explorer is unable to interpret XHTML documents as XML, and thus most current XHTML pages are served to browsers as HTML, using the MIME type of "text/html".
Because XHTML 1.0 served to browsers as HTML is parsed as if it were badly-formed HTML, XHTML 1.0 is affected by tag soup in the same way as HTML.
Future versions of XHTML after version 1.0 do not allow the XHTML to be served to browsers as HTML. If implemented according to the recommendation, this should prevent the problem of tag soup once XHTML served as XHTML is supported by all major browsers."
Source
I am not saying that serving up the content as text/html changes it from XHTML to HTML, but it will affect the rendering of the page - and it may not work the way you expect it to. That is why it is a bad practice. The W3C recommends that you serve XHTML documents as they are supposed to be served up: application/xml+xhtml.
Here is also a page that talks about why serving XHTML as text/html is considered harmful.
I'm also not saying that you can't serve up XHTML as text/html, just that it's probably not a good idea, and that it could cause problems later.
Thanks for the explanation of invalid vs. malformed. -
SVG (Scaleable Vector Graphics)?
It would be nice if they supported SVG. Sure its not native in most browsers yet, but its on its way and in the meantime there is Adobe's SVG plugin. Opera has support, Firefox should have it by 1.5 and KHTML has it in the works.
SVG is a W3C approved standard. Adobe has more marketing oriented description of the technology.
Other than Microsoft is anyone else using VML? -
SVG (Scaleable Vector Graphics)?
It would be nice if they supported SVG. Sure its not native in most browsers yet, but its on its way and in the meantime there is Adobe's SVG plugin. Opera has support, Firefox should have it by 1.5 and KHTML has it in the works.
SVG is a W3C approved standard. Adobe has more marketing oriented description of the technology.
Other than Microsoft is anyone else using VML? -
Re:Convoluted to sign up?
Well, according to this, they might even be TOO effective...
That may not be the exact answer you were looking for, though. -
Re:Apple isn't stupidYou should learn about
If I am not mistaken, I think
XAML, if you want to do a little reading for fun, there is a good review of it that concludes:
Examined superficially, XAML tags have many of the features of traditional Web standards like HTML, as well as those of newer Web approaches like Mozilla's XUL. Alas, it lacks proper CSS stylesheet support. Examined more deeply, however, XAML tags reuse, reinvent, and renew many standard idioms from the software development world in a highly integrated way.
There are also people out there who see XAML as just a proprietary XML and MS will try to do to XML what they did with JScript/JavaScript
That doesn't count loads of other features, like the explorer, IE 7, a ton of security features, better search, better web services through Indigo (try doing web services with PHP now - I've done it, and it's such a pain that it's not really worth it. Microsoft nailed web services in 2002, and the new stuff is even better!).
I have alway been happy with SOAP/XML and it seems like they are doing pretty well Also, it seems like Indigo isn't what it used to be, or at least not yet. We also do not know how these new services will affect other internet users, presumably they will be a Vista only feature and in that case, how many developers will fully embrace them with MS's current adoption rate for XP. Will the Vista adoption rate be better or worse? One could argue not as good due to the increased system requirements for the "full" Vista experience, compared to the 98/2000 upgrade path. We went from 66MHz/16MB/225MB to 133MHz/64MB/2GB to "current processor, current computer". From that I guess 2GHz/512MB-1GB/64MB-128MB-256 VRAM, (hard drive space is not an issue anymore) That is quite an increase in specs, though I admit that is extrapolation from this:
Will my PC run Vista? That depends on how recently you bought it. Microsoft Allchin said in an April interview that he expects Vista will need about 512MB of memory and "today's level" of processor. The ability to display all the fancy new graphics will depend on what type of graphics card one has. On some older machines, the graphics may look similar to today's Windows.
Apple is doing the slapdash hacks, and Microsoft leads the way in beautifully architected software.
Now you are just tossing out some flamebait. "Slapdash hacks" is a disservice to the wonderful integretion of OOS into OS X. Also OS X has been lauded by many (I hate to do this, but this was the best all-in-one collection I could find without searching/cutting/pasting all night. This is only slightly bigger than the attention Apple was given for Panther.
Also, MS has been accused of many, many things, but has never been accused of creating "beautifully architected software". Seriously, XP SP2 took some important steps, but I am not going to say any such words until I see a final p
-
Ontologies
It sounds like Microsoft has learned about ontologies, you know those things that we're going to use to build the semantic web. Now they're trying to build an identity ontology to allow software agents to act on your behalf. I'd prefer to see something based on authorization rather than identification but MS doesn't work along those lines. I looked at the 'Laws of Identity' page and the blog it's sourced from, but didn't watch the vid... so consume this comment with some skepticism.
-
Re:The 2G file limit...
While HTTP had always been great for file downloads, it would be a bit more difficult to hack a sophisticated "PUT" mechanism into it.
PUT has been part of the HTTP 1.1 specification for years and years.
Most httpd's do not run as "root" (or equivalent), so unless you're satisfied with all created files being owned by something like "www-data", you have to use something different.
Most httpds do run as root, but drop privileges. The same goes for ftpds. As for ownership, it's not an easy problem to solve, but there are plenty of different solutions, e.g. the Apache on port 80 is a proxy for Apaches on other ports running as the correct user.
-
Some moreOK, let's see it:
First, we have this.
And a quote from the default config file:# Specify a default charset for all pages sent out. This is
OK. So I'll define as follows:
# always a good idea and opens the door for future internationalisation
# of your web site, should you ever want it. Specifying it as
# a default does little harm; as the standard dictates that a page
# is in iso-8859-1 (latin1) unless specified otherwise i.e. you
# are merely stating the obvious. There are also some security
# reasons in browsers, related to javascript and URL parsing
# which encourage you to always set a default char set.AddDefaultCharset UTF-8
Then, we have this.
OK, so I have some legacy documents, so I'll just define as follows in <HEAD>:<META http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
And let's try it out... WTF?? It does not work! My browser thinks it is UTF-8.
Oh wait, it actually works, if I'll define this instead of that above:<META http-equiv="Content-Type" content="text/html; charset=iso-8859-1">
Brilliant! So if the AddDefaultCharset is defined in httpd.conf, the Content-Type encoding of the actual document must be defined in lowercase, or it'll be ingnored! Now, where the f*** this is documented??! Examples at w3.org specifically uses uppercase. Apache permits uppercase in httpd.conf.
Apache messed it up again. -
Re:Firefox or Mozilla
I'm saying it's almost universally accepted that 'World Wide Web' means HTTP+HTML.
This thread started because an AC felt the need to "correct" somebody's "misuse" of the term 'web'. Obviously it's not that universally accepted, especially as the guy who invented the term doesn't agree with the definition.
I would not imagine that he considers email to be part of the Web.
What's the point in me posting links if you aren't going to read them? The reason URIs are called URIs and not UDIs is because the web includes non-document resources like email addresses. Axioms of Web Architecture written by Tim Berners-Lee explicitly mentions mailto.
-
Re:Firefox or Mozilla
Are you actually disagreeing with Tim Berners-Lee, or are you saying that he doesn't really mean it when he explains what the WWW is?
I'm saying it's almost universally accepted that 'World Wide Web' means HTTP+HTML. As for the opinions of Mr Berners-Lee, his original proposal describes the WWW as hypertext based. I would not imagine that he considers email to be part of the Web.
-
Re:I am glad that they are doing somethingThere is a difference between rendering web pages "properly" and rendering web pages "as the author intended". While MSIE might get the "as...intended" correct more often (simply because the author didn't use "proper" HTML practices and instead used multiple wrongs that within particular versions of MSIE at particular font+window sizes make a quasi-right), Firefox arguably does better at rendering "properly".
I don't suppose you've tried validating the webgames' web pages? It's really easy with Firefox.
-
Re:Does this mean they'll fix launch.yahoo.com bug
They should make launch.yahoo.com use valid HTML, just like all good music sites do.
-
Re: Anti-slash
- whinging does not mean 'to whinge'. Whinge means 'to whine' you cannot simply place 'ing' on any word and make it a process you 'moran' http://www.eskimokaka.be/images/morans.jpg
- I am complaining! It is not too much to ask that slashdot editors not make something that is not news news. News is something that is 'new'! It might be news to you but to the site it is not news. news news news news news news news...
Q: Why can't the slashdot editors find the dupes?
A: Lazy, or just greedy. Every page load generates them a bit of money. By posting more often, readers are duped (pun intended) into refreshing.
Q: why can't anti-slash run real articles? Something interesting?
A: I dont really care, they do not claim to be a news site! They are simply there to point out slashdots mistakes (exactly like you stated, * for you). If slashdot fixes the problems there will be no need for anti-slash. If this ever happens, I'm there with you.
Slashdot is a professional news site (trying not to laugh), it doesn't even validate its html, but instead if you try to validate their site you get the following: http://validator.w3.org/check?uri=http%3A%2F%2Fsla shdot.org. This does not happen by mistake, they are blocking the validator purposely (long story, check the duped archives). Where is all the money going? You would think that some of it would find its way back into the slashcode.
disclaimer: I am NOT associated with anti-slash, in fact I hate what they do. They shouldn't have to though! - whinging does not mean 'to whinge'. Whinge means 'to whine' you cannot simply place 'ing' on any word and make it a process you 'moran' http://www.eskimokaka.be/images/morans.jpg
-
Here's a link for ya...
-
Re:Python will kill Ruby
While you are rewriting your PURL server, could you make it easy to switch individual redirects (that's not me) to 303 Founds to be compliant with HTTPRange-14? Even better, a per PURL option for 302 or 303 redirects would be nice. I don't really like the HTTPRange-14 compromise, but it is better than nothing I guess.
-
Re:Python will kill Ruby
While you are rewriting your PURL server, could you make it easy to switch individual redirects (that's not me) to 303 Founds to be compliant with HTTPRange-14? Even better, a per PURL option for 302 or 303 redirects would be nice. I don't really like the HTTPRange-14 compromise, but it is better than nothing I guess.
-
becoming a standard
mabye this could become incorporated into the XLink standard. Using javascript (as previous people have done) seems quite barbaric to me and it looses it's semantics and breaks horribly in a few browsers. Using CSS (what this example does) works well but, surprise, surprise! it doesn't work in IE and it still doesn't quite have the proper semantics.
-
Re:CSS2 a flawed standard?In light of the original quote, do you anticipate Microsoft controlling CSS 2.1/3?
Here's a link at the W3C that details why CSS 2.1 even exists, namely that it's a bugfix on 2. 2.1 isn't adopted yet.
I'm sure if pressed they would claim the fact that 2.1 isn't formally adopted yet is the reason for their hesitation, but that's never stopped them before. I think they are using this as a stalling tactic until they get something that won't look like dog shit next to Firefox.
-
Re:Stupid......IE Tricks
HTML is a structural markup language - it should not be used to describe the appearance of a webpage - that's what CSS is for. What does <b> mean to a screenreader?
<b> is presentational, rather than semantic markup, and therefore depreciated.
-
Re:All browsers != standards
The W3C guide you mention is fascinating, and a good read, at http://www.w3.org/TR/WAI-WEBCONTENT/.
It mentions how to do CSS well and avoid the weirdnesses so common to the auto-generated stylesheets of various design tools that I mention above, and I can where such well-written CSS could help.
However, the badly written, auto-generating, extremely bad "GUI" based webdesign tools such as FrontPage among Windows users yield complete trash. Given the overwhelming percentage of such awful CSS on websites, and the use of such style sheets where simply not necessary at all, I'm forced to conclude that the underlying technology should be discarded where feasible.
Everything good that style sheets does can be done in PHP. This creates a slight serverload, but in my experience creates much better, cleaner, fast-to-download web pages. -
Re:Stupid......IE Tricks
You should use the tty media type to "detect" text browsers, not the UA string.
-
Re:CSS2 a flawed standard?
CSS 2.1 is still a working draft (well, it was, until 2 days ago). And last time I checked, Mozilla/Firefox didn't implemented it (took me some time to understand why "white-space: pre-wrap" wouldn't work).
-
Re:Back To The Status QuoNewsflash: every browser has bugs. No browser is "standards compliant" (hint: the W3C is a vendor consortium that publishes specifications, they are not a standards body that publish standards).
Uh oh. Someone better tell them.
W3C primarily pursues its mission through the creation of Web standards and guidelines. In its first ten years, W3C published more than eighty such W3C Recommendations. W3C also engages in education and outreach, develops software, and serves as an open forum for discussion about the Web. In order for the Web to reach its full potential, the most fundamental Web technologies must be compatible with one another and allow any hardware and software used to access the Web to work together. W3C refers to this goal as "Web interoperability." By publishing open (non-proprietary) standards for Web languages and protocols, W3C seeks to avoid market fragmentation and thus Web fragmentation.
But then maybe our definition of standards is different
q
-
Re:Let them release first, then we'll see
You are wrong. Have you ever read the specification? CSS has these features, it's just IE that doesn't implement them. Display: table and friendsCSS fanatics always claim that you should not use tables for layout, but I find that CSS lacks some basic features for alignment especially at the bottom edge of the content area, which are very simple to implement when using a table.
-
Re:CSS2 a flawed standard?
http://www.w3.org/TR/CSS21/about.html#q1
http://annevankesteren.nl/2005/06/css-21
CSS 2.1 is in nearly-done stage I think. At least IE devs can start working on it already... -
A better idea...
Validate with the World Wide Web Consortium . If the site breaks on IE7... put a disclaimer on the main page, telling your viewers whose fault it is, and that there are other, better, standards-compliant browsers out there!
-
Nope...
As this article states, IE7 will not support CSS2. But come on! Give MS some slack! The CSS2 standard is only 7 years old. You must give them some time to implement the thing..!
-
It was never about a single country
Presuming you have enough language skill to know that "create" is not equal to "develop, nurture, and improve", which country did create it?
No one country did. That's exactly the point. For a start, the Internet is almost by definition a network of networks, many of which are not in the US. Moreover, there is no clear "creation date"; different aspects of what we know today as "the Internet" appeared at very different times in history.
What became today's Internet was mostly driven by academic research. While I'll certainly concede that much of the initial research during the '60s and early '70s happened in the US, it's still clear that from a very early stage, the research effort was international. For example, ISoc's brief history of the Internet mentions researchers in the UK working in parallel with the US research as early as 1967, until the groups discovered each other and started collaborating.
The infrastructure is obviously international, and for the most part quite capable of surviving without any one country. Networks that now form major parts of the Internet have existed in other countries for over 20 years. (The same history notes the existence of the JANET in the UK in 1984, while another mentions satellite links to Hawaii and the UK as early as 1975 and the creation of EUnet, connecting the Netherlands, Denmark, Sweden, and UK, in 1982.)
The software side, in particular the established communications protocols for things like e-mail, WWW, Usenet or FTP communication, has come from diverse sources. What was effectively the first TCP/IP standard was presented to an international working group at Sussex University in the UK in 1973.
Bodies like the IETF and W3C have geographically diverse memberships. While the US has by far the largest single category of W3C membership today, it still represents less than 40% of the total, which isn't much more than Europe, for example. There are a total of 28 countries with member organisations.
For any one country, including the US, to claim that this whole picture developed because of it, or wouldn't have happened in a similar way without it, is simply a delusion of grandeur. It might not have happened as fast, or in exactly the same way, but it would still have happened, probably working off the research done in Europe.
I find it deeply ironic that one of the other replies to my GP post was an AC who claimed I was trolling, and challenged me to provide information about other countries that contributed to the Internet's creation, while another accuses me of rewriting history. Fortunately, while a lot of mostly US-based Internet history pages choose to ignore the contributions from outside and focus on the US academic network during the early stages, the kind of information above (all of which is written by the people and organisations at the heart of the Internet) is freely available, even to those in the US.
-
Re:well, since i can't get to the link
not to mention slash can't seem to make up its mind if its outputting html 3.2 or 4.0 as the validator shows
http://validator.w3.org/check?uri=www.slashdot.org 5 %2F1212241%26threshold%3D-1%26tid%3D169%26tid%3D8
http://validator.w3.org/check?uri=http%3A%2F%2Fsla shdot.org.nyud.net%3A8090%2Farticle.pl%3Fsid%3D05% 2F07%2F15%2F1212241%26threshold%3D-1%26tid%3D169%2 6tid%3D8&charset=(detect+automatically)&doctype=HT ML+4.01+Transitional
notice that very few things are flagges as errors in both. -
Re:well, since i can't get to the link
not to mention slash can't seem to make up its mind if its outputting html 3.2 or 4.0 as the validator shows
http://validator.w3.org/check?uri=www.slashdot.org 5 %2F1212241%26threshold%3D-1%26tid%3D169%26tid%3D8
http://validator.w3.org/check?uri=http%3A%2F%2Fsla shdot.org.nyud.net%3A8090%2Farticle.pl%3Fsid%3D05% 2F07%2F15%2F1212241%26threshold%3D-1%26tid%3D169%2 6tid%3D8&charset=(detect+automatically)&doctype=HT ML+4.01+Transitional
notice that very few things are flagges as errors in both. -
Re:The web was always GUI
Actually, by 1993 WorldWideWeb displayed images inline. (Development of NCSA Mosaic 0.1a began that same year.) WorldWideWeb may not have been first, but if not, it wasn't far behind.
1. Yes, the source code to the original (1990/1991?) version of WorldWideWeb can be found in the W3.org history section.
2. It definitely doesn't work on Mac OS X as-is, though I've been wondering for a few months how much effort would be required to get it working, just for kicks. -
Re:The web was always GUI
Actually, by 1993 WorldWideWeb displayed images inline. (Development of NCSA Mosaic 0.1a began that same year.) WorldWideWeb may not have been first, but if not, it wasn't far behind.
1. Yes, the source code to the original (1990/1991?) version of WorldWideWeb can be found in the W3.org history section.
2. It definitely doesn't work on Mac OS X as-is, though I've been wondering for a few months how much effort would be required to get it working, just for kicks. -
Re:Not really new, but interesting
Unless your shell script is an HTTP user agent
Did you mean HTML user-agent? HTTP has clients, not user-agents.
If a shell script processes HTML, it's an HTML user-agent. From the spec:
An HTML user agent is any device that interprets HTML documents. User agents include visual browsers (text-only and graphical), non-visual browsers (audio, Braille), search robots, proxies, etc.
I can see you making the argument that JavaScript is "general purpose processing by user agents", but I don't see you making the case for the same with a shell script.
Why not? Because you don't think it's an HTML user-agent? It is. It doesn't have to be a browser to be an HTML user-agent.
And from that you say that calling the class attribute's intention to attach CSS behavior to an element as '"wisdom"' and 'completely wrong', which seems like quite a bit of an overstatement, if not also completely wrong.
No. If I had said that, then I would be completely wrong. I didn't say that though. What I did say was that your assertion that the class attribute is for CSS but not Javascript is completely wrong. The class attribute is for general-purpose processing. This includes CSS, Javascript, shell scripts, and pretty much anything else you can think of.
-
WorldWideWeb today
"Anybody know if 1. the code to WorldWideWeb is still around..."
http://www.w3.org/History/1991-WWW-NeXT/Implementa tion/
"if it works on OS X?"
This says no.
"Which is based upon NeXTStep."
My understanding is that MacOS X isn't really so-much "based on" NeXTStep (in terms of re-using the same implementation pieces), but rather makes use of many of the same ideas and interfaces. So "inspired by" might be a better term. -
CERN, NSCA, Netscape
"How about Cern and Tim Berners-Lee? The initial Netscape release was basically the same as NCSA Mosaic which came before it."
Just to clarify:
CERN is the European Organization for Nuclear Research (the acroynm isn't English-language). Tim Berners-Lee "created" the original web browser, WorldWideWeb, while he was working there.
Mosaic was developed at NCSA, the National Center for Supercomputing Applications at the University of Illinois in Urbana-Champaign.
Marc Andreesen and Eric Bina were the original creators of Mosaic while they were students working at NCSA. Andreesen later founded Netscape Communications (originally Mosaic Communications) to try and build a company around the success of Mosaic. -
CERN, NSCA, Netscape
"How about Cern and Tim Berners-Lee? The initial Netscape release was basically the same as NCSA Mosaic which came before it."
Just to clarify:
CERN is the European Organization for Nuclear Research (the acroynm isn't English-language). Tim Berners-Lee "created" the original web browser, WorldWideWeb, while he was working there.
Mosaic was developed at NCSA, the National Center for Supercomputing Applications at the University of Illinois in Urbana-Champaign.
Marc Andreesen and Eric Bina were the original creators of Mosaic while they were students working at NCSA. Andreesen later founded Netscape Communications (originally Mosaic Communications) to try and build a company around the success of Mosaic. -
the history of the web from CERN:
You may have a look at this:
http://public.web.cern.ch/public/Content/Chapters/ AboutCERN/Achievements/WorldWideWeb/WWW-en.html
among others, includes the link to the proposal of the WWW made at CERN by Tim in 1989:
http://www.w3.org/History/1989/proposal.html
and refined by Robert Cailliau in 1990:
http://www.w3.org/Proposal.html
BTW, noone seems to remember about Robert Cailliau, the co-author of the thing...
{kind=link}
{kind=link}