 Slashdot Mirror
Slashdot Mirror
Domain: caida.org
Stories and comments across the archive that link to caida.org.
Comments · 161
-
Re:Routing
Not specific to mesh networks, but routing in general, a lot of work has been done in recent years to firmly establish theoretical limits on the best a routing scheme can do, and develop schemes that approach those limits. In particular, of all known network topologies, internet-like graphs are the worse case for address aggregation--transitioning to IPv6 may buy us a constant factor reduction in routing table sizes, but it will continue to scale just as poorly as in IPv4.
I believe this may also be relevant to the conversation, regarding the cost of routing table updates:
The most pessimistic fact from this theory is that there can exist no routing algorithm that would be able to converge with the number of control messages growing slower than linearly with the network size in the worst case. The most pessimistic finding in this paper is that the small-world topologies are this worst case. Almost all complex network topologies, including the Internet, are small-world: the average shortest path length in them grows (sub)logarithmically with the network size.
That being said, the routing algorithms in use today (BGP in particular) are exceptionally bad from a the standpoint of convergence cost. There's a lot of room for improvement before we hit the theory wall.
-
Re:Good - more transparency
http://www.kitchenlab.org/www/bmah/Software/pchar/
http://www.isc.org/software/irrtoolset
http://oss.oetiker.ch/mrtg/
http://www.caida.org/tools/If you want transparency, you can always do it yourself. Why wait for Google? You've a list of tools right there that will tell you who is throttling, when, where, how, by how much, and maybe even what they had for breakfast.
http://www.internettrafficreport.com/main.htm
http://www.internettrafficreport.com/namerica.htmThen there's the Weather Channel for geeks. That should give you a good indication of "unusual" packet losses, indicative of throttling.
http://www.noc.ucla.edu/weather.html
http://www.cgl.ucsf.edu/weather/weather.htmlFor more local weather on the tens, there's UCLA and UCSF.
There ya go, and it cost you rather less than the same information is costing Google.
-
Re:Buffer Bloat
The original gatech study showed not only bufferbloat, but enormous variation of base latencies in the first mile for different brands of cable modem as well as for different kinds of DSL and wireless technologies.
Slides: http://www.caida.org/workshops/isma/1102/slides/aims1102_ssundaresan.pdf
Some commentary: http://gettys.wordpress.com/2011/02/17/caida-workshop/
I look forward to the followup!
-
Re:The Internet is Full
For an easier view, you can have a look a this map:
http://www.caida.org/research/id-consumption/census-map/images/20061108.png
Data is from November 2006, but the situation in these hogged A blocks shouldn't have changed much. Note that the 18.0.0.0/8 block used by MIT will be a little harder to reclaim, since they spread out the internally-assigned addresses quite uniformously (at the contrary of IBM's 9.0.0.0/8)
-
Re:Ill bet this will happen
You missed the caveats on the page about the image:
A visualization of IPv4 addresses that responded to ICMP (ping) packets during a two-month (very slow) scan of the IPv4 address space. Some hosts do not respond to the probes due to firewalls, NAT boxes, and ICMP filtering. Thus, the data and map give us a lower bound on IPv4 address utilization.
That explains why places like the US-DoD are big black holes on the map.
-
Re:Ill bet this will happen
A good question, and AC above definitely provides the right gist of an answer; rather than be terrified over the sky falling, poke the sky!
Luckily, other people have already done this research for us. This report is a couple years out of date, but the current state is likely highly reflective of these results:
http://www.caida.org/research/id-consumption/census-map/images/20061108.png
-
Re:I guess it is good news...
I have always been the "paranoia is good" type of administrator and I didn't want to trust any third party DNS in case they get hijacked or misconfigured. I admit this may change with Google, I might decide to trust them but then again...
So yes, I query the root servers, ping time is between 21ms and 225ms for them with several between 21-28ms and bind pickups the closest ones so I am not worrying about the multiple round trips that much especially since my DNS will first cache the
http://www.caida.org/outreach/papers/2003/dnsplacement/dnsplacement.pdf
Also, remember root DNS addresses are routed differently, so chances are you should always have one close to you . Of course, this won't help your problem if you have a 1 second latency between yourself and your provider router.
"The modern trend is to use anycast addressing and routing to provide resilience and load balancing across a wide geographic area. For example, the j.root-servers.net root server, maintained by VeriSign, is represented by 41 (as of July 2008[update]) individual server systems located around the world which can be queried using anycast addressing."
-
Re:So?
That's not new. Check out "The Rallying Problem" section from this 4-year old presentation.
-
Internet Telescope
What I thought was interesting was the internet telescope mentioned in the article. No wonder we're running out of IPv4 addresses, someone's wasting millions of them!
-
Re:Everybody makes mistakes, false positives
I would agree. You have to accept false positives. Humans carefully checking stuff are too slow. The Sapphire Worm doubled in size every 8.5 seconds. See this. Phishing is going to be slower, but I do not want to rely on a bureaucratic check-with-my-lawyer system.
One key point is the
-
Re: You can't jail them
Something that the CNET article failed to address was this: This work was _exactly_ in line with the norms and standards of networking research. It is quite normal for network operators to collect partial or full traffic traces, for both operational and research purposes.
If you believe that this study was inappropriate, then so is a very large fraction of networking measurement research. Consider at the very least:
* Just about everything done by CAIDA.
* The papers at IMC - the Internet Measurement Conference.
* Data at CRAWDAD - the Community Resource for Archiving Wireless Data at Dartmouth.A large part of computer science research consists of observing how systems are used and how they work or don't work. You can do some small-scale studies on a private system with the explicit agreement of all users, but for something as large and complicated as the Internet, the only way to do meaningful research is to observe the real thing, which necessarily means that you can't identify and get the consent of all the users involved. That's the way this field works. Responsible researchers collect the least invasive information possible for their purposes, use it benignly, and anonymise anything they release so that individual users cannot be identified. The authors of this study did exactly those things.
Now, if you want to ban all observation-based networking research, I suppose that's a legitimate position. But you have to be willing to forgo the benefits of that research. Otherwise, you should accept that the authors acted responsibly and within the norms of the field. Moreover, the purpose of this research was to understand and thereby _improve_ TOR. The researchers identified several serious problems which were already being exploited by "black hats" for malicious purposes. Research like this enables those problems to be addressed before actual harm results.
-
Re:They can't be stupid.
Something that the CNET article failed to address was this: This work was _exactly_ in line with the norms and standards of networking research. It is quite normal for network operators to collect partial or full traffic traces, for both operational and research purposes.
If you believe that this study was inappropriate, then so is a very large fraction of networking measurement research. Consider at the very least:
* Just about everything done by CAIDA.
* The papers at IMC - the Internet Measurement Conference.
* Data at CRAWDAD - the Community Resource for Archiving Wireless Data at Dartmouth.A large part of computer science research consists of observing how systems are used and how they work or don't work. You can do some small-scale studies on a private system with the explicit agreement of all users, but for something as large and complicated as the Internet, the only way to do meaningful research is to observe the real thing, which necessarily means that you can't identify and get the consent of all the users involved. That's the way this field works. Responsible researchers collect the least invasive information possible for their purposes, use it benignly, and anonymise anything they release so that individual users cannot be identified. The authors of this study did exactly those things.
Now, if you want to ban all observation-based networking research, I suppose that's a legitimate position. But you have to be willing to forgo the benefits of that research. Otherwise, you should accept that the authors acted responsibly and within the norms of the field. Moreover, the purpose of this research was to understand and thereby _improve_ TOR. The researchers identified several serious problems which were already being exploited by "black hats" for malicious purposes. Research like this enables those problems to be addressed before actual harm results.
-
Why indeed...
why traffic goes to "retired" address space is a difficult question to answer. http://www.caida.org/workshops/wide/0611/ has a pointer to some early work done on the "B" renumbering. There was agreement by the operators of "B","L","J", and "M" to collect data during the DITL-2008 collection to see if any correlation btwn querying nodes. That said, ICANN should have renumbered the node when they took it over. They did not. They have not had permission to use the prefix since 2004 - but for stability sake, I did not make a big fuss.
bill manning -
Re:If comcast want'sto do this
Then why can Verizon offer unlimited downloading/uploading on their DSL and FiOS products for about the same price as most cable offerings (cheaper in some cases)? I don't see them rushing to restrict what their customers can do.
Cause they cut out the big fat middle man?
Verizon Business (what became of UUNET/MCI when Verizon acquired them) are about tied with AT&T as the largest Tier 1 provider in the US. They resell their bandwidth to competitors at preposterous rates. Since the geographical circumstances and last mile delivery can be different for each competitor they deliver to, just maybe they fudge the numbers up as they please based on who they are selling to and get away with it.
They're also "The Phone Company". The largest ILEC in the US. I think they can virtually print money at this point.
I should not have to say that cable is a big threat to them. Undersell a better product to potential cable customers, and oversell your OC-12 to the local Comcast headend. I don't doubt that this is their model for crushing those annoying cable companies.
If Comcast is evil Verizon is evilerr. -
Re:Tipping the scales?
The percentage of potential hosts in the entire pool is the important part, not the total number of hosts. Whether the pool is one thousand or one billion computers, the chance that one infected OS X host will run into another OS X host will still be 4%. The ability of an infected host to find and infect other hosts before it "dies" is the important part.
As I said before network-based worms that require no human interaction (like all those windows worms from a few years ago) are not hampered by low numbers, since they reach a huge number of hosts in very little time. The "Black ICE" worm from 2004 is the perfect example.
OS X comes with good defaults in this regard, as it doesn't have any network daemons come "spread-eagle" out of the box, like Windows. -
Re:Egomanical monitoring of the populace?
I'm a professional paranoid, but I can't really make myself worry about that. It would require random Win boxes to accept incoming connections from other random Win boxes. That sort of thing would have to appear in a EULA, and world + dog would freak. With good reason, as it would probably become a leading attack vector within about two days.
Or there's the possibility of a worm which propagates with Slammer-like speed. See http://www.caida.org/publications/papers/2003/sapp hire/sapphire.html if you're not familiar with how truly horrible that was. The potential for an epic PR nightmare should be enough to prevent MS from doing such a thing.
In addition, firmware updates would probably be required on a gazillion routers, firewalls, etc. Assuming it's even possible to run a firewall in such an environment.
In short, this would be perhaps the most insecure software system possible. We'd need new terminology. "Optimally insecure," anyone? -
Re:I dare to ask, "who the hell cares"?the rest of the world seems to have no problems with its much smaller usage. This part is false. China and Japan are actively adopting ipv6 right now since they are feeling squeezed by their current ipv4 allocation.
By the way, as far as current ipv4 space goes, allocation exhaustion is predicted to be March 2009. -
Re:DING DING DING
No, it's been proven that worms can spread in populations as small as 10,000 machines. Remember the Witty worm?
-
Re:Ah, charts in Perl...
Grace can produce some nice results, but the Perl interface to it is just a wrapper around their terrible command line interface (maybe it's improved in the last few years, but when I tried it it was almost entirely undocumented and nigh-unusable).
I like grace a lot. I use it through the GUI & occasionally through python, so can't comment extensively on the perl interfaces. Neither Chart::GRACE nor Chart::Graph::Xmgrace seem TOO obscure.
The command line interface of grace isn't terrible--it is MUCH more powerful than most plotting software which has a GUI. I do agree it is under-documented, though. Fortunately, the developers are very responsive in the forums. -
niche status is not protection: Witty Worm et. al.
Pining for the fjords, eh? Serious security professsionals realized this argument was stone cold (in fact I took the liberty of examinging this here argument and discovered that the only reason it was still standing on its perch at all was that it had been nailed there) dead when the Witty Worm smacked all the vulnerable systems for a given defect within an hour. The particular realization perhaps didn't sink in until a day or so later when the number of said vulnerable systems was shown to be something quite small, quite possibly as few as 12,000 total vulnerable systems. Exploiting niche platforms became no more difficult than exploting any other platform given a remote root vulnerability.
Elsewhere in this discussion it's claimed that worms are irrelevant because modern attacks are directed at browsers and the like. The continual emergence of new worms suggests that malware authors do not agree with that assessment. Even if it were true, recent surveys suggest that over 4% of web surfers are using Safari. That's millions of potential victims. A botnet master needs only a few thousand systems to spam the bejeezus out of the entire world.
The niche platform argument is bogus and should be consigned to the dustbin of history. -
False Flag Operation?My bet is that it is a false flag operation by Vixie et al to concentrate power and control in his little pay to play club https://oarc.isc.org/
Of course, if he and his followers truly wanted to have a secure and resilient dns system, they would advocate using a distributed root system. Simply have a signed root zone (its very small - 50K for the ORSC root zone http://orsc.net/ ), distribute it via BT or similar and have people who run a dns cache, also run a local root. The data in the root zone has a fairly low churn rate so the the zone could be update once per day or even less frequently without causing major problems; certainly fewer problems than the bogging down of the root servers. Anyone who can run a dns cache, can run a local root. I run them everwhere I run a dns cache. One way to do it: http://cr.yp.to/dnsroot.html
Suddenly, all this ZOMG! they are attacking the root becomes a non-issue and the dns system as a whole becomes extremely hard to attack in any effective way. And as freebie side effects dns lookup become faster, diagnosing dns problems is easier, people who are DOSing the root servers due to misconfiguration would instead be DOSing only themselves and their local servers (see the http://www.caida.org/ and other studies), traffic on the net drops and the sun shines brighter.
But that is not the objective and thus we are where we are - the objective is central control and an annoying type of elitism.
Karl, what about this stuff instead of the need for a strong centralized institution?
Paul Mockapetris, chief scientist at Nominum Inc. and founder of the DNS system, recently suggested that DNS operators keep a current copy of root zones in order to isolate themselves from future root-server attacks. Sexton points out that if local root zones were a common practice, DNS operators would seldom notice any root-server outages. An obstacle to this approach is the perception that it requires considerable technical expertise. Furthermore, the localized DNS automatically updates Root Zone data. This configuration allows the casual user to have up-to-date personal mirrors of root-server data without an intimidating hurdle of configuration. Such an approach could also be adapted for ISP or corporate DNS servers. The root-slave approach allows DNS operators to avoid the risk of future root-server attacks and, if implemented on a wide scale by individuals using a localized DNS or other DNS operators, it could reduce the motivation for future root-server attacks.
http://www.computerworld.com/securitytopics/securi ty/story/0,10801,78500,00.html -
this is interesting. . .
. . . even if it is quite old: http://www.caida.org/publications/presentations/i
e tf0112/dns.damage.html. -
Re:Rasterizer.obligatory reference to the CAIDA maps: http://www.caida.org/analysis/topology/as_core_ne
t work/I realy do like the simple structure of the xkcd map though; like the London Underground map it is a simple representation that took much work to make it so simple!
-
Re:Insignificant
It probes for ipv6 first, then falls back to ipv4. This is the default setting for many unix systems as well. You usually find your system running slowly, then find a setting for this and turn it off to eliminate the timeout delay.
As for how big a spike it can cause, see this for the effect of Windows' active directory update scheme on the root servers. -
Re:Steganography...
Uh no. It isn't. After watching a program on CyberTerror on the Internet and how terrorists are using steganography to communicate back and forth, I am convinced that it is efil.
I appreciate the skill and magic of Steganography, however, I see the inherent dangers that it possesses, and hope to goodness that there are monitors out there for it by now. It's clear that this method has been used to transmit operational data - the researchers suggested it may have been used to help coordinate 9/11.
Oh, the source - Histories Mysteries, History Channel - it aired yesterday afternoon. -
Identifying machines behind a NAT router
One of the new faculty members here at the University of Washington has discovered a way to "fingerprint" remote machines based on their clock skew, which is leaked out to the world via the TCP timestamp option. NATing routers don't mask this, so you can potentially differentiate multiple machines using the same IP. This was reported on Slashdot over a year ago, and here's the actual paper.
So, you're not as anonymous as you'd think. -
Re:Stats on IP usage?
See the first few graphics in kc claffy's presentation to ARIN. Poke around caida.org for more tasty data.
-
market niche is not safety
The Witty Worm demonstrated that a market niche as small as perhaps 12,000 systems can be vulnerable to a worm based attack. The Macintosh is not inherently safe due to niche status. Anybody making this claim is seriously not keeping up with the field of information security.
Worms that have targeted other niche platforms including web servers and database servers of various kinds have also demonstrated that platforms with a few hundred thousand deployed systems (much smaller than the deployed base of Macintosh systems) are vulnerable to worm attacks. -
Re:Im confused
Lots of people do, tragically: http://www.caida.org/publications/presentations/i
e tf0112/dns.damage.html
Sample quote: "Win2k shipped with default configuration trying to update roots". -
Re:Im confused
Lots of people do, tragically: http://www.caida.org/publications/presentations/i
e tf0112/dns.damage.html
Sample quote: "Win2k shipped with default configuration trying to update roots". -
Re:They aren't USING anything!
i am paying for a connection, my provider pays to be connected, to provide me with service.
The problem is, who does your provider pay for their connection? Is it the same company that connects to the end node (server)? The internet is not a train track of direct connections, but an amorphous mass of possible connections. The backbone providers are widely interconnected and currently data passes freely between them. Here's some topology to give you an idea. In fact, parts of a file may pass through completely different backbones during one download only to have all of the parts (hopefully) end up in the same place. This is fundamental to how TCP/IP works and how the internet can "route around failures" as it were.Here's a fun experiment: tracert the same far away address once a week for a month and see how many different in-between networks you get. This used to be an exotic passtime in the early days when sometimes a packet would get routed around somplace bizarre every so often and there were so few network providers that you pretty much could identify them all in the tracert. Now, packets traveling through places with little infrastructure can have a similar effect. Try a
-
Re:What's worse?
That is incorrect. It is certainly possible to make a worm that infects a niche market; that was proven by the Witty Worm, which took down most boxes using ISS's various firewalls, very very quickly. There's a great discussion of this here. The vulnerable population was about 12,000 machines. There are a lot more than 12,000 Macs out there.
This makes the fact that it hasn't happened to Macs even more impressive. -
Re:The Nightmare worm
How did you get a "total infection" within 10 minutes from this?
Probably becaause he linked to the wrong article. Here's the correct one http://www.caida.org/outreach/papers/2003/sapphire /sapphire.html. -
Re:Gotta love this business model
Oddly enough, DNS does use a fair bit of bandwidth (~13Gbps at the root servers based on numbers in [1]). Adding a new TLD involves adding an entry to these root servers. The root servers already have a hard time answering queries for ~300 TLD's that are quite cachable (60-85% are queries that should have been cached but are not [1]). Adding thousands of additional TLD's which are harder to cache only exuberates this problem. Add to the fact that the root servers are a central point of failure, and represent a big target for DDoS; they require a lot of extra provisioning and security. Medling with the DNS root is no laughing matter.
Now I don't know how these guys came up with their cost numbers, and whether or not they are justifiable, but I am pretty sure that adding a DNS TLD will cost them a fair bit.
[1] http://www.caida.org/outreach/papers/2001/DNSMeasR oot/dmr.pdf -
Re:an integer between 1 and 999Considering that The number of known viruses surpassed 70,000 in January 2002 it does seem a bit strange to deliberately set this sort of limitation in the design.
It also seems to ignore the existing CVE numbering scheme which surely was designed with similar intent.
This all reminds me somewhat of the patch numbering schemes developed by different software vendors. The one that I've found best in practice comes from Sun Microsystems. Rather than being a plain integer or some equally cryptic enumerator, it's a pair of integers, one identifying the patch, and the other its version. This provides an explicit distinction between intent and implementation, very useful considering that patches themselves often undergo refinement over time, and may need to be reapplied to the same system.
We already know that a similar approach is needed for viruses as well, since many viruses are recognized as minor variants of the same code. The existing ad hoc virus naming scheme already takes this effect into account, though without the rigor that would potentially be available in a vendor-neutral format.
So there's no question that a common virus taxonomy is a great idea, and that CERT would be a natural candidate to be responsible for the virus database, as it has for the CVE list. But the scheme itself seems belated and remarkably toothless. Is this really offered as some kind of sop to the virus detection industry?
-
Innovation may rescue the Windows monoculture
"The software-based solution is using a real OS."
Windows won't be going away any time soon, so there will remain plenty of worm fodder. I am surprised by the number of relatively unsophisticated home users who are switching to Mac OS X or Linux as a result of adware, spyware, and worms, but I haven't seen the same switcher phenomenon occurring in corporations.
Besides, worms probably wouldn't go away even if Windows did. Although conventional wisdom says that a large pool of exploitable systems is required for successful worm propagation, that's not true, demonstrated by the Witty Worm's exploitation of a very small population of vulnerable systems. Although they are not as common, worms have exploited other, non-Windows systems and application software, and certainly buffer overflow exploits are discovered periodically in such systems. Granted, the UNIX architecture makes worm exploitation of application software less likely to result in super-user access, but routers, DNS servers, and others remain vulnerable to the extent that they contain worm-able security defects -- and clearly many do.
Worms are getting more sophisticated all the time. From the starting point of their current capabilities, worms and botnets could easily be extended to automatically harvest particular types of data from particular companies or government agencies, using the chaos of a massive worm outbreak for cover. Their ability to receive arbitrary commands from remote attackers over IRC control channels means that they may already be in use for this purpose.
My company specializes in antiworm technology and consulting. The FireBreak AntiWorm system impedes worm propagation without interfering with normal network operations -- including bit torrent.
There is a tremendous amount of innovation going in in the software security area lately, driven by the relatively recent realization among large corporations that they must now spend money on worm prevention, containment, and recovery if they want their heavy investment in the Windows monoculture to survive.
Opting out of the monoculture simply isn't feasible for most large corporations at this point. It's not just the cost of the desktop PC -- if that's all it was, a bunch of them would have switched en masse to Mac OS X Tiger when it came out. The applications, the developers who write them, the help-desk workers, the system administrators, the managers, the employees -- at this point all they know is Windows.
Switching a desktop is so hard for a large company, that the survival of the Windows monoculture is virtually assured for about as long as one can predict anything in the IT world (5 years, I'm told). The the problems that come with it will be creating market opportunities for a long while to come. -
Witty Worm Nuked Drives
It didn't get much press attention, but the researchers are all still very interested in The Witty Worm. It did something similar to your suggestion, and demonstrated that a worm can be destructive without limiting its propagation -- saturate first, then destroy. It also saturated a niche population of systems (much smaller than the Macintosh market, whose security record people incorrectly attribute to the smaller number of systems).
Modern worms can spread so rapidly that a small delay in the destruction, as you suggest, is all that's needed. If you saturate the entire target population in an hour, and start erasing random bits from the hard drive, tremendous damage could result. If a worm like Witty had exploited MS05-039, we would see a few hundred thousand wrecked systems today.
Why don't we see that? Because these worms are designed to build fleets of useful systems, gather information, steal identities, log keystrokes, collect passwords, and all manner of really nasty stuff.
The victims would be far, far better off if the worm merely waxed the hard drive.
These worms wouldn't be able to achieve their aims if they wrecked the C: drives. The "non-destructive" nature of these worms gets widely reported, because people don't understand that these systems are remotely controlled by hostile attackers from outside the corporate network from the early moments of the worm outbreak. Hey, the system still runs and users can still get their corporate email, so it can't be that bad, right? This remote control stuff is theoretical, right?
Wrong. This crop of worms is efficient, and very, very nasty. I have an IRC session log which shows literally hundreds of MB of files being stolen from infected computers, and many MB of files downloaded and executed on those same systems. Files that are not recognized by AntiVirus, files that don't get cleaned up with the magic bullet clean up tools. It also shows the bots responding when a firewall rule was put up to block the initial IRC connection. These bots are becoming smarter all the time, and these are definitely not "gentle peaceful worms" that seek only to spread from system to system. -
Re:Premise is nonsense
I'm trying to track down the paper, but not having much luck. It looks like you're going to be looking for a paper:
Mullin, R., Nemeth, E. and Weidenhofer, N., "Will Public Key Crypto Systems Live up to Their Expectations? HEP Implementation of the Discrete Log Codebreaker", Proc. of the 1984 Intl Conf on Parallel Processing, Aug. 21-24, 1984, pp. 193-196.
This information from Evi Nemeth's bio page. Evi appears to have an e-mail address (on the same page)--you could try contacting her directly. -
Niche products don't help (was: Anti-malware tips)
Since the market share for a non-Microsoft OS is so small, it isn't worth the malware author's time to attack them. A successful attack (if possible) would yeild little or no damage in a collective sense.
You could also use a non-Microsoft, niche product like the ISS personal firewall to help protect yourself if you must use Windows.
And then you can get nailed with something like Witty.
There were only about 12,000 Black Ice systems out there. There are over 10 million OS X systems deployed in the world, and no telling how many others (Linux, *BSD, etc.). Each is probably a big enough "niche" to get attention when the opportunity arises (which will happen sooner or later).
There is really no longer anywhere safe to hide.
/jonathan
-
Re:IPv6 - solution without a problem?
That solution has worked so well that few feel the need to use IPv6.
The non US part of the world runs out of addresses and migrates to ipv6. The US will realize they've fallen behind and try to catch up.
I wonder what will happen to force the issue?
According to this study at CAIDA, the US got 62% of the ipv4 addresses. According to a talk I heard a while ago, organized by the WLUG, the rest of the world, especially asia, is slowly adopting ipv6. -
Re:Help from private technology firms
P'raps the bad guys have already had a trial run. Notice that the witty worm didn't make big headlines at the time, but it attacked a particular sensitive part of internet infrastructure. Analysis was done by a consortium of private firms,
-
Re:Help from private technology firms
P'raps the bad guys have already had a trial run. Notice that the witty worm didn't make big headlines at the time, but it attacked a particular sensitive part of internet infrastructure. Analysis was done by a consortium of private firms,
-
Slashdoted
Because we are uniquely situated to receive traffic That's why it is not slashdoted yet. BTW thses are the links to the large maps
http://www.caida.org/analysis/security/witty/anima tions/world_big-witty_2h.gif
http://www.caida.org/analysis/security/witty/anima tions/usa_big-witty_2h.gif -
Slashdoted
Because we are uniquely situated to receive traffic That's why it is not slashdoted yet. BTW thses are the links to the large maps
http://www.caida.org/analysis/security/witty/anima tions/world_big-witty_2h.gif
http://www.caida.org/analysis/security/witty/anima tions/usa_big-witty_2h.gif -
MOD PARENT UP
Not only is an animated GIF not a virus, but it's not some scare tactic windows program by an anti-virus company.
To keep this from being a pointless "mod up" post,
The full article is http://www.caida.org/analysis/security/sapphire/ -
Real data: Analysis of the Witty worm
/. discussed the Witty worm back in 2004. This analysis used UCSD Network Telescope IP block (containing 1/256 of IPv4 space) to sample the randomly spewed packets created by the worm. They were able to analyze quite a few interesting features, including the fact that the worm was jump-started by an infection of about 110 PCs at the outset, 24-hour cycles in infected/reinfected machines, and data on the distribution of bit-rates of worm transmitters.
-
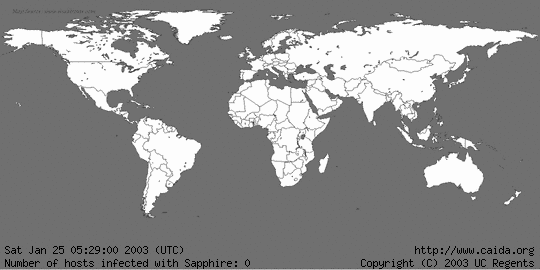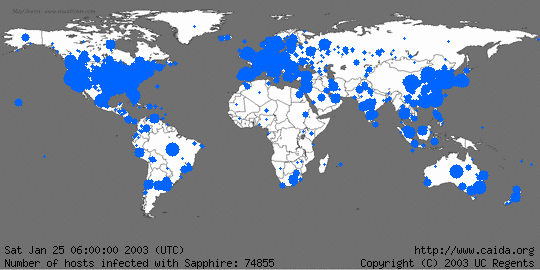
Slammer/Sapphire
I've already see how a worm spreads. Especially one that initially grows exponentially with a time constant of 8.5 seconds. Yes, 8.5 seconds.
Slammer
Pay attention to the time and infected hosts data at the bottom. -
CAIDA did this for earlier worms...
... and in a WWW based format, as opposed to the executable from an AV company. I think it was two of their researchers -- Colleen Shannon and David Moore. The animation for Code Red is here .
-
Recent Worms DO organize to manage utilizationMost of the interesting recent viruses *do* have some level of organization to reduce duplication of effort, and the postulated "Warhol Worms" designed to take over the entire Internet in 15 minutes would need to do so, because otherwise they're not as effective. Some of them pre-scan the net to find a list of vulnerable machines to infect first, and then haul around parts of the list. Others partition the address space quasi-deterministically (e.g. Phase 1 scans all of the valid
Code Red II implemented a randomized variant on this: "1/8th of the time, CodeRedII probes a completely random IP address. 1/2 of the time, CodeRedII probes a machine in the same
At least one worm that took this sort of approach had a bad random number generator, so it kept hitting the same territory too hard and missing other wide-open spaces, which protected a few parts of the net from infection.
-
Re:UCSD network folks doing good stuff...
Plus Varghese, Marzullo and Pasquale, and the folks at CAIDA. Check out all the work these guys have been doing (full list of papers). 14 papers in the last five SIGCOMMs! 10 papers in the last five Infocoms, etc.
{kind=link}
{kind=link}
{kind=link}
{kind=link}