 Slashdot Mirror
Slashdot Mirror
Domain: slashdot.org
Stories and comments across the archive that link to slashdot.org.
Stories · 37,380
-
CMI Director Alex King Talks About Rare Earth Supplies (Video 2)
Yesterday we ran video #1 of 2 about the Critical Materials Institute (CMI) at the Iowa State Ames Laboratory in Ames, Iowa. They have partners from other national laboratories, universities, and industry, too. Obviously there is more than enough information on this subject that Dr. King can easily fill two 15-minute videos, not to mention so many Google links that instead of trying to list all of them, we're giving you one link to Google using the search term "rare earths." Yes, we know Rare Earth would be a great name for a rock band. But the mineral rare earths are important in the manufacture of items ranging from strong magnets to touch screens and rechargeable batteries, so please watch the video(s) or at least read the transcript(s). (Alternate Video Link) -
Interviews: Ask Adora Svitak About Education and Women In STEM and Politics
samzenpus writes Adora Svitak is a child prodigy, author and activist. She taught her first class on writing at a local elementary school when she was 7, the same year her book, Flying Fingers was published. In 2010, Adora spoke at a TED Conference. Her speech, "What Adults Can Learn from Kids", has been viewed over 3.7 million times and has been translated into over 40 different languages. She is an advocate for literacy, youth empowerment, and for the inclusion of more women and girls in STEM and politics. 17 this year, she served as a Youth Advisor to the USA Science and Engineering Festival in Washington, DC. and is a freshman at UC Berkeley. Adora has agreed to take some time from her books and answer any questions you may have. As usual, ask as many as you'd like, but please, one per post. -
"Barbie: I Can Be a Computer Engineer" Pulled From Amazon
New submitter clcto writes Back in 2010, Computer Engineer Barbie was released. Now, with the attention brought to the Frozen themed programming game from Disney and Code.org, unwanted attention has been given to the surprisingly real book "Barbie: I Can Be a Computer Engineer". So much so, that Mattel has pulled the book from Amazon. The book shows Barbie attempting to write a computer game. However, instead of writing the code, she enlists two boys to write the code as she just does the design. She then proceeds to infect her computer and her sister's computer with a virus and must enlist the boys to fix that for her as well. In the end she takes all the credit, and proclaims "I guess I can be a computer engineer!" A blog post commenting on the book (as well as giving pictures of the book and its text) has been moved to Gizmodo due to high demand. -
WhatsApp To Offer End-to-End Encryption
L-One-L-One (173461) writes In a surprise move, nine months after being bought by Facebook, WhatsApp has begun rolling out end-to-end encryption for its users. With true end-to-end encryption data becomes unaccessible to admins of WhatsApp or law enforcement authorities. This new feature first proposed on Android only has been developed in cooperation with Open Whisper Systems, based on TextSecure. With hundreds of million users, WhatsApp becomes by far the largest secure messaging application. FBI Director James Comey might not be pleased. Do you have a current favorite for encrypted online chat? -
What Would Have Happened If Philae Were Nuclear Powered?
StartsWithABang writes After successfully landing on a comet with all 10 instruments intact, but failing to deploy its thrusters and harpoons to anchor onto the surface, Philae bounced, coming to rest in an area with woefully insufficient sunlight to keep it alive. After exhausting its primary battery, it went into hibernation, most likely never to wake again. We'll always be left to wonder what might have been if it had functioned optimally, and given us years of data rather than just 60 hours worth. The thing is, it wouldn't have needed to function optimally to give us years of data, if only it were better designed in one particular aspect: powered by Plutonium-238 instead of by solar panels. -
What Would Have Happened If Philae Were Nuclear Powered?
StartsWithABang writes After successfully landing on a comet with all 10 instruments intact, but failing to deploy its thrusters and harpoons to anchor onto the surface, Philae bounced, coming to rest in an area with woefully insufficient sunlight to keep it alive. After exhausting its primary battery, it went into hibernation, most likely never to wake again. We'll always be left to wonder what might have been if it had functioned optimally, and given us years of data rather than just 60 hours worth. The thing is, it wouldn't have needed to function optimally to give us years of data, if only it were better designed in one particular aspect: powered by Plutonium-238 instead of by solar panels. -
CMI Director Alex King Talks About Rare Earth Supplies (Video)
CMI in this context is the Critical Materials Institute at the Iowa State Ames Laboratory in Ames, Iowa. They have partners from other national laboratories, universities, and industry, too. Rare earths, while not necessarily as rare as the word "rare" implies, are hard to mine, separate, and use. They are often found in parts per million quantities, so it takes supercomputers to suss out which deposits are worth going after. This is what Dr. King and his coworkers spend their time doing; finding concentrations of rare earths that can be mined and refined profitably.
On November 3 we asked you for questions to put to Dr. King. Timothy incorporated some of those questions into the conversation in this video -- and tomorrow's video too, since we broke this into two parts because, while the subject matter may be fascinating, we are supposed to hold video lengths down to around 10 minutes, and in this case we still ended up with two videos close to 15 minutes each. And this stuff is important enough that instead of lining up a list of links, we are giving you one link to Google using the search term "rare earths." Yes, we know Rare Earth would be a great name for a rock band. But the mineral rare earths are important in the manufacture of items from strong magnets to touch screens and rechargeable batteries. (Alternate Video Link) -
CMI Director Alex King Talks About Rare Earth Supplies (Video)
CMI in this context is the Critical Materials Institute at the Iowa State Ames Laboratory in Ames, Iowa. They have partners from other national laboratories, universities, and industry, too. Rare earths, while not necessarily as rare as the word "rare" implies, are hard to mine, separate, and use. They are often found in parts per million quantities, so it takes supercomputers to suss out which deposits are worth going after. This is what Dr. King and his coworkers spend their time doing; finding concentrations of rare earths that can be mined and refined profitably.
On November 3 we asked you for questions to put to Dr. King. Timothy incorporated some of those questions into the conversation in this video -- and tomorrow's video too, since we broke this into two parts because, while the subject matter may be fascinating, we are supposed to hold video lengths down to around 10 minutes, and in this case we still ended up with two videos close to 15 minutes each. And this stuff is important enough that instead of lining up a list of links, we are giving you one link to Google using the search term "rare earths." Yes, we know Rare Earth would be a great name for a rock band. But the mineral rare earths are important in the manufacture of items from strong magnets to touch screens and rechargeable batteries. (Alternate Video Link) -
Three-Way Comparison Shows PCs Slaying Consoles In Dragon Age Inquisition
MojoKid writes: "BioWare's long-awaited Dragon Age Inquisition has dropped for the PS4, Xbox One, and PCs. A comparison of the visuals in key scenes between all three platforms shows that while the PC variant clearly looks the best in multiple areas (as it should), there's evidence of good, intelligent optimization for consoles and PCs alike. After the debacle of Assassin's Creed Unity, Inquisition could provide an important taste of how to do things right. As expected though, when detail levels are increased, the PC still pulls away with the best overall visuals. The Xbox One and PS4 are largely matched, while PC renders of characters have better facial coloring and slightly more detailed textures. The lighting models are also far more detailed on the PC version with the PS4 following behind. The Xbox One, in contrast, is rather muddy. Overall, the PC and PS4 are closest in general detail, with the Xbox One occasionally lagging behind. -
Debian Votes Against Mandating Non-systemd Compatibility
paskie writes: Voting on a Debian General Resolution that would require packagers to maintain support even for systems not running systemd ended tonight with the resolution failing to gather enough support.
This means that some Debian packages could require users to run systemd on their systems in theory — however, in practice Debian still works fine without systemd (even with e.g. GNOME) and this will certainly stay the case at least for the next stable release Jessie.
However, the controversial general resolution proposed late in the development cycle opened many wounds in the community, prompting some prominent developers to resign or leave altogether, stirring strong emotions — not due to adoption of systemd per se, but because of the emotional burn-out and shortcomings in the decision processes apparent in the wake of the systemd controversy.
Nevertheless, work on the next stable release is well underway and some developers are already trying to mend the community and soothe the wounds. -
Debian Votes Against Mandating Non-systemd Compatibility
paskie writes: Voting on a Debian General Resolution that would require packagers to maintain support even for systems not running systemd ended tonight with the resolution failing to gather enough support.
This means that some Debian packages could require users to run systemd on their systems in theory — however, in practice Debian still works fine without systemd (even with e.g. GNOME) and this will certainly stay the case at least for the next stable release Jessie.
However, the controversial general resolution proposed late in the development cycle opened many wounds in the community, prompting some prominent developers to resign or leave altogether, stirring strong emotions — not due to adoption of systemd per se, but because of the emotional burn-out and shortcomings in the decision processes apparent in the wake of the systemd controversy.
Nevertheless, work on the next stable release is well underway and some developers are already trying to mend the community and soothe the wounds. -
Nokia's N1 Android Tablet Is Actually a Foxconn Tablet
sfcrazy writes: "Nokia surprised everyone when it announced the N1 Android tablet during the Slush conference in Finland, today. This story has a twist, though: the N1 is not a Nokia device. Nokia doesn't have a device unit anymore: it sold its Devices and Services business to Microsoft in 2013. The N1 is made by Taiwanese contract manufacturing company Foxconn, which also manufactures the iPhone and the iPad.
But Nokia's relationship with Foxconn is different from Apple's. You buy iDevices from Apple, not Foxconn; you call Apple for support, not Foxconn. You never deal with Foxconn. In the case of N1, Foxconn will be handling the sales, distribution, and customer care for the device. Nokia is licensing the brand, the industrial design, the Z Launcher software layer, and the IP on a running royalty basis to Foxconn. -
Collin Graver and his Wooden Bicycle (Video)
This is not a practical bike. "Even on smooth pavement, your vision goes blurry because you're vibrating so hard," Collin said to an Atlanta Journal-Constitution reporter back in 2012 when he was only 15 -- and already building wooden bicycles. Collin's wooden bikes are far from the first ones. Wikipedia says, "The first bicycles recorded, known variously as velocipedes, dandy horses, or hobby horses, were constructed from wood, starting in 1817." And not all wooden bicycles made today are as crude as Collin's. A Portland (OR) company called Renovo makes competition-quality hardwood bicycle frames -- for as little as $2200, and a bunch more for a complete bike with all its hardware fitted and ready to roll.
Of course, while it might be sensible to buy a Renovo product if you want a wood-framed bike to Race Across America, you won't improve your woodworking skills the way Collin's projects have improved his to the point where he's made a nice-looking pair of wood-framed sunglasses described in his WOOD YOU? SHOULD YOU? blog. (Alternate Video Link) -
Interviews: Ask Malcolm Gladwell a Question
Malcolm Gladwell is a speaker, author, and staff writer for The New Yorker since 1996. Gladwell's writing often focuses on research in the social sciences and the unexpected connections or theories made from such research. His books: The Tipping Point: How Little Things Can Make a Big Difference, Outliers: The Story of Success, and David and Goliath: Underdogs, Misfits, and the Art of Battling Giants are all New York Times best sellers. Malcolm has agreed to give us some of his time to answer any question you may have. As usual, ask as many as you'd like, but please, one per post. -
Crowdfunded Linux Voice Magazine Releases First Issue CC-BY-SA
M-Saunders (706738) writes Linux Voice, the crowdfunded GNU/Linux magazine that Slashdot has covered previously, had two goals at its launch: to give 50% of its profits back to the community after one year, and release each issue's contents under the Creative Commons after nine months. Well, it's been nine months since issue 1, so the whole thing is now online and free to share. Readers and supporters have also made audio versions of articles, for listening to on the commute to work. -
NVIDIA SHIELD Tablet Android Lollipop Update Performance Explored
MojoKid writes Last week, NVIDIA offered information regarding its Android Lollipop update for the SHIELD Tablet and also revealed a new game bundle for it. This week, NVIDIA gave members of the press early access to the Lollipop update and it will also be rolling out to the general public sometime later today. Some of the changes are subtle, but others are more significant and definitely give the tablet a different look and feel over the original Android KitKat release. Android Lollipop introduces a new "material design" that further flattens out the look of the OS. Google seems to have taken a more minimalist approach as everything from the keyboard to the settings menus have been cleaned up considerably. Many parts of the interface don't have any markings except for the absolute necessities. While the OS definitely feels more fluid and responsive, the default look isn't always better, depending on your personal view. The app tray for example has a plain, white background which looks kind of jarring if you've using a colorful background. And finding the proper touch points for things like a settings menu or clearing notifications isn't always clear. Performance-wise, NVIDIA's Shield Tablet showed significantly better performance on Lollipop for general compute tasks in benchmarks like Mobile XPRT but lagged behind Kit Kat in graphics performance slightly, which could be attributed to driver optimization. -
Scientists Optimistic About Getting a Mammoth Genome Complete Enough To Clone
Clark Schultz writes The premise behind Jurassic Park just got a bit more real after scientists in South Korea said they are optimistic they can extract enough DNA from the blood of a preserved woolly mammoth to clone the long-extinct mammal. The ice-wrapped woolly mammoth was found last year on an island off of Siberia. The development is being closely watched by the scientific community with opinion sharply divided on the ethics of the project. -
Interviews: Warren Ellis Answers Your Questions
Recently you had a chance to ask acclaimed author of comics, novels, and television, Warren Ellis, about his work and sci-fi in general. Below you'll find his answers to your questions. Authors in the industry
by TWX
I've noticed that some authors are quite happy to see their works adapted into other formats, but some authors like Alan Moore seem upset, to the point of being hostile when this happens, even though they had to license or sell the rights for this to occur. Did you have control over the rights to some of your work that was turned into movies, and if so, how did you feel about that process and the end result? Have there been works by you or other writers that you felt were especially well or poorly executed in their adaptation?
Ellis: If I sell people the right to adapt my work, I don’t get to be upset when they adapt it. If people adapt the work I don’t own or control, then I can either ignore it or view it with curiosity, depending on my mood.
The Alan Moore projects that have been adapted are more complex, and some have aspects that were kind of unprecedented. Outside parties can have opinions, but some of their points are incorrect or irrelevant. I know interviewers like to encourage Alan to be the Grumpy Wizard Of Northampton Cave or whatever, but, really, people need to cut that shit out, because the important facts in many of these situations get completely obscured by the hyperbole elicited.
Adapting your works
by robstout
How do you feel about movie adpatations of your work? Does it annoy you when the look and feel of a book changes significantly between your book, and the resulting movie? The movie Red is much lighter than the comic was.
Ellis: Red is much lighter than the comic, yeah, but the central themes of the book are still in place. See above about selling the rights to adapt. And, as in that Raymond Chandler story I like to tell, it’s not like the books are destroyed or sent away. I wrote the books to tell the story I wanted. Sometimes I’m prepared to sell someone the rights to look at the work in a different way. It’s really not something to stress over.
Self Censorship in Your Industry
by eldavojohn
I've never really enjoyed main stream comics but the imprints that dodge the archaic Comics Code have pulled me in with various titles -- some of yours even. According to your wikipedia page you left Hellblazer after DC refused to print a controversial comic of yours in such an imprint: "He left that series when DC announced, following the Columbine High School massacre, that it would not publish "Shoot", a Hellblazer story about school shootings, although the story had been written and illustrated prior to the Columbine massacre."
Is this common in comic books/graphic novels? Have you experienced this elsewhere in your career? Do you feel that DC and other big publishers are too afraid of another Fredric Wertham to toe the line?
Ellis: This is kind of an archaic thing, now. The Comics Code doesn’t exist any more. Also, if a company owns a property, they get to decide how that property acts, which doesn’t technically count as censorship. Is it censorship if Disney hire me to write Toy Story 4 and then reject the script because I insist on including an anal scene? No. I can insist that they’re wrong, and present my arguments, but ultimately it’s their call. Work-for-hire, as it’s called, is just housepainting. The client gets to fire me if I decide to paint their house in orange and blue polka dots, regardless of my artistic integrity in doing so.
Nobody’s afraid of a new Wertham. In some ways, his worst nightmare happened: violent children’s comics have become the backbone of massive multinational corporations who are too big to shame or threaten.
What would you write if your editors allowed it?
by Khopesh
When writing within a popular series (e.g. X-Men or Hellblazer), there are certain hard limits in what liberties you can take. As a mundane example, you can't kill characters without planning out a large arc that builds up to it and/or quickly bringing them back, all with editorial approval from up on high.
What would you write within a popular series if only you could get permission to do it?
Ellis: To some extent, I would say “see above.” Also: I didn’t actually get into this business to write other people’s characters – it’s an interesting sideline, for me – and so I’ve never really spent a lot of time sitting around thinking about this. If I want to write something “without permission,” as it were, then I create something new that I want to talk about and publish it in a place that agrees to do that with me. It’s a recipe for depression and failure to slump in my chair muttering “if only I could do an X-Men series where giant alien structures fell on the Earth ten years ago and thereby indirectly caused a city in China to have all its cultural restrictions removed so I can do a fish-out-of-water story with a very confused bisexual painter.” That’s just insane. Anyone who is just waiting to do that Batman story where Bruce Wayne and Dick Grayson finally get married in Vermont needs to be in another business. Ideally one nowhere near mine.
Just talk about Planetary for a bit
by c0d3g33k
Mr Ellis, I enjoy all your work, but I view Planetary as a "love letter to the things I love". I would appreciate it if you just wrote a little bit about what you were thinking/feeling when you were working on Planetary. That work covers a lot of territory, but my reaction on first reading was to weep because you captured so perfectly the essence of all those wonderful stories that I loved as a young man. I didn't think anyone loved that shit as much as I did, but Planetary seemed to capture the essence of all those great stories whilst bringing them in to the modern age and reminding us why they were relevant and maybe still are.
So, if you would, just riff a bit on Planetary and all the things you had in your head when you were working that all out. Planetary as the finished work we have as a reference - I'm interested in the stew in your mind containing all that wonderful stuff that eventually was distilled into Planetary. Talk about that a bit, if you are so inclined.
Thanks.
Ellis: Well, my memories of it aren’t as fond as yours. I got so sick during the extended production of that book that I was at one point briefly speculatively diagnosed with a brain tumour. After my dad died, I was guided to a thread on a message board where people were trying to put together a class action suit against DC to compel me to write Planetary for them, citing in part the “fact” that I had taken too much time off previous to and during my father’s death. That sort of thing. On and on. Including the times people tried to remove my collaborators. It was an uphill battle. So I don’t really remember the book with a smile!
A lot of Planetary came down to my having to learn the superhero genre during my early years at Marvel, as I was never particularly a student of that genre. Which meant that, by 1998 or thereabouts, my head was just rammed full of this stuff and I needed to get it out. Reading seventy years’ worth of superhero material in a couple of years gives you, I would imagine, a peculiar perspective on the genre, and it seemed to me that I could clearly see the progression of the genre from its non-comics roots to the fairly debased form that existed in the 90s. I found that I just wanted to try and scrape away all those barnacles to see the thing that charmed and fascinated people right at the start. I still don’t know that I managed that to anyone’s satisfaction, but the act of it seemed to me to reveal a story about the genre itself. Which sounds wanky, I know, but it was the turn of the century, and we were all about the looking-back and the meta. Comics-about-comics should probably be some kind of felony.
It was an awfully pretty comic, though.
Transmetropolitan Adaptation
by Verdatum
I don't know very much about comic books. With the exception of my parents' Mad Magazines and silver age Superman comics, I never got into them. Transmet has been one of very few exceptions. By about volume 3, I was rather terrified that this might get horribly adapted into a movie. I just couldn't imagine any way the story could be decently converted into a 90-120 minute format. The animated series adaptation idea, on the other hand, rather intrigued me. I was bummed to see it fall through; the animation looked quite promising (I seem to recall Chris Prynoski/Titmouse Inc. was somehow involved, but can't find confirmation on that). I realize nothing is currently in production, but is there any chance of another attempt at such an adaptation in the future?
Ellis: There are occasionally movements in the direction of Transmet, but, right now, I don’t see anyone doing it. In a lot of ways, that book is more relevant than it’s been in years (ignoring, please, the obvious datedness that creeps into all science fiction). But, ultimately, nobody is going to commission an R-rated film or language-uncensored tv series that is also an incredibly expensive and fully-immersed science fiction setting. You can either have it look like Transmet or you can retain Spider’s voice, but you can’t do both. As some famous American tv networks have told me. And adult-oriented animation that isn’t outright comedy? Forget it.
And, yes, those animation tests were Titmouse. I actually wrote one of those. In success, Patrick Stewart would have voiced Spider. But that all fell apart, as these things do.
Who do you enjoy reading?
by TJ_Phazerhacki
What authors (or writers, or artists) do you enjoy reading most? I often find that the people I like to read like to read the people I should be reading.
Also, thank you for Spider.
Ellis: I read a lot, and mostly non-fiction or literary stuff. I also re-read quite a lot – The Rings of Saturn by WG Sebald, for instance, is a book I go back to annually. Lemme pull up this year on Kindle
Okay, this year so far I’ve read and re-read some Thoreau: I have especial fondness for the language in Walking. Iain Sinclair’s new one was good. I re-read Tarkovsky’s Sculpting In Time, because it is, perversely, a good way to get back into thinking about comics. I read Rene Redzepi’s A Work In Process and Noma: Time and Place In Nordic Cuisine, and Magnus Nilsson’s Faviken and North: The New Nordic Cuisine of Iceland by Gunnar Karl Gislason, because the New Nordic style reads like science fiction to me, and anyone who works creatively for a living should read Work In Progress anyway.
I’ll always read a new Bruce Sterling, and his Epic Struggle of the Internet of Things was great. Same with Daniel Suarez’ Kill Decision. Finally got around to Alan Garner’s Boneland, which was revelatory. I read a lot of history: The King In the North was very good. Slavoj Zizek’s Event, like most of the Zizek I’ve read, started off great and ended up in a patch of philosophic quicksand somewhere outside Ljubljana. Peter Bebergal’s Season of the Witch was good, as was Blake Butler’s Three Hundred Million. Re-read some of Against the Day, the Pynchon that I return to again and again. Started reading the collected Samuel Beckett from the beginning. And I think that I’ll stop there because the eleven people still reading this have fallen into a coma.
What cybernetic implant would you choose first?
by hawkinspeter
You obviously have an interest in the boundary of society and technology, so if cybernetic implants became common, what would be your favourite upgrade and why?
Ellis: Well, I’m 46 now, so I’m in the market for a full-body upgrade at this point. I’ve never used contact lenses, but I was always interested in a head-up-display contact lens, not least because that would be less stupid and intrusive than HUD glasses (which I also don’t wear). I’d dismissed glasses as useful long before Google Glass – the ones in Transmet were just a gag, after all. Possibly what I’d be most interested in is a brain/internet connection, two-way, not least because I could use both a rolling log for surfaced thoughts and a separate Dropbox folder for cohesive trains of thought labelled with a strongly visualized hashtag. -
Big Talk About Small Samples
Bennett Haselton writes: My last article garnered some objections from readers saying that the sample sizes were too small to draw meaningful conclusions. (36 out of 47 survey-takers, or 77%, said that a picture of a black woman breast-feeding was inappropriate; while in a different group, 38 out of 54 survey-takers, or 70%, said that a picture of a white woman breast-feeding was inappropriate in the same context.) My conclusion was that, even on the basis of a relatively small sample, the evidence was strongly against a "huge" gap in the rates at which the surveyed population would consider the two pictures to be inappropriate. I stand by that, but it's worth presenting the math to support that conclusion, because I think the surveys are valuable tools when you understand what you can and cannot demonstrate with a small sample. (Basically, a small sample can present only weak evidence as to what the population average is, but you can confidently demonstrate what it is not.) Keep reading to see what Bennett has to say.The smallest sample I've ever used to make an argument was when I submitted some legal briefs, each no longer than five pages, in the anti-spam cases that I'd been filing in Washington State small claims court. Since I suspected the judges were not taking the cases seriously, I filed the briefs with the third and fourth pages stuck together in the center, by a tiny thread of paper joining the back of the third page to the front of the fourth page. (If someone were to turn the pages and actually readthe brief, the thread would break.) I did something similar in six different cases, and when the motions were all rejected, I went to the courthouse to look at the paper motions still in the file. In three out of six cases, the judge had rejected the motion without reading it first.
Now, the point was not to make any accurate estimation of the actual proportion, in the total population of small claims court judges, who would reject a brief in an anti-spam case without reading it. There's no basis for saying that the proportion of such judges is close to 50%. But we can still probably reject any contention that the proportion of such judges is very low. If only 10% of judges were rejecting motions without reading them, then there is only about a 1.4% chance of taking a random sample of six rejected motions and finding that in three or more cases, the judge did not read the motion. Even if 20% of judges were doing so, for an event with a probability of p=0.20 you would still only see it occur in three out of six cases, about 8.2% of the time. (If an event has probability p, the exact probability of that event occuring three or more times in six trials is given by 20*(p^3)*((1-p)^3) + 15*(p^4)*((1-p)^2) + 6*(p^5)*((1-p)^1) + 1*(p^6)*((1-p)^0).) So we can say that the proportion of such judges is quite probably more than 20%. I did this repeatedly because even after I had "caught" the first judge, I wanted to head off any objection that this was just an isolated case of rare behavior.
And, as always, it's important not to generalize too much about the behavior whose probability we're estimating. I don't think that 20% or more of judges, even in small claims court, are throwing most types of cases without reading or listening to the arguments. My impression was that most judges see view small claims court as a place to redress injustices, and that they see anti-spam and anti-telemarketer plaintiffs as just trying to "make money" at it, so they take those suits less seriously. I disagreed with this stance because (1) anti-spam plaintiffs usually really have been harmed and are not just "whining about one email" which they are trying to "cash in" (I still get so much spam that it interferes somewhat with the operation of my server and with my ability to get through my daily email); and (2) the law is intended after all as a deterrent, with disproportionate damages in order to discourage spammers from spamming in the first place. However, the charitable reading of the results is to assume that judges are merely biased against anti-spam plaintiffs -- but at least they probably don't treat all cases as casually as they treat anti-spam suits!
Back to the issue of small samples. My previous article was prompted by an editorial about the online response that had been elicited by two different photos -- one showing a black woman breastfeeding, and a nearly identical photo showing a white woman breastfeeding. The author asserted that the photos had received vastly different responses, which she attributed to racism. I presented a survey to a sample if users recruited from Amazon's Mechanical Turk, randomly showed each survey-taker one of the two photos, and asked:
Our academic department has asked everyone to submit a "fun" photo of themselves, so that our photos can be displayed together on the department home page. One of our employees submitted a photo that has caused some internal debate about whether the photo is inappropriate. I wanted to do a poll to get the opinion of a random sample of Internet users of different backgrounds.
Do you think this is an appropriate picture to be used in a photo collection on our academic department home page?Out of 47 respondents who saw the black woman's photo, 36 of them (77%) said it was inappropriate. Out of 54 respondents who saw the white woman's photo, 38 of them (70%) said it was inappropriate.
As before, these samples are to small to say precisely what the relevant proportions in the background populations are, but we can probably reject certain statements about the populations -- for example, that the percentage of users offended by the black woman's photo is 20 percentage points higher than the percentage of users offended by the white woman's photo. This is where the counterintuitive part comes in. Suppose that in the background population, 81% of respondents would find the black woman's photo offensive, but only 61% would be offended by the white woman's photo. What are the odds of getting 77% or less "yes that's offensive" responses from a sample of 47 users shown the black woman's photo, and getting 70% or more "yes that's offensive" responses from a sample of 54 users shown the white woman's photo? It doesn't sound unlikely at all, because the percentages are quite close to the originals -- but you can verify, either with statistical calculations or with a quickly written computer program, that the odds are only about 2.5%.
Two main factors contribute to this counterintuitive result. First, even with a sample size of a few dozen, the frequency of an event starts to tend very closely to the frequency in the background population (if 80% of your population has some trait, and you take a sample of size 50, there's about a 95% chance that the number with that trait in your population will be between 34 and 46). Second, to find the odds of seeing both of these deviations at the same time (deviating from an assumed 81% in the background population down to 77% in the first sample, and deviating from an assumed 61% in the background population up to 70% in the second sample), you have to mutiply the probabilities of these two unlikely events. The probability of the first deviation is about 19%, the probability of the second is about 13%, and so the probability of them both occurring is about 2.5%.
The reason I calculated the odds of getting 77% or less "offended" responses for the black woman's photo while also getting 70% or more "offended" responses for the white woman's photo, is that in calculating the "unlikeliness" of a statistical result, it's customary to calculate the odds of getting "this result or a more extreme one". For example, suppose you want to know if a company's hiring process is gender-balanced (assuming a 50/50 gender split in the population), and you notice that in a random sample of 100 recent hires, 61 were men. You wouldn't ask "What are the odds of there being exactly 61 men in this sample?", because the odds of getting any particular number, are small. You'd ask, "What are the odds of getting this result or a more extreme one -- i.e. the odds of getting 61 or more men out of a random sample of 100, if the population were truly gender-balanced? As this calculation tool shows, the odds are only about 1.7%.
Similarly, in the case of the two populations being measured, the author of the original editorial hypothesized that there was some significant gap between the percentages of the population that were offended by the two photos, which I arbitrarily assumed to be 20 percentage points. Under that assumption, showing the two pictures to two different groups and having them be offended at similar rates, is the unexpected, "extreme" result, and the closer the rates are to each other, the more extreme the result is. That's why I calculated "77% of less" for the first group vs. "70% or more" for the second group.
And out of the pairs of numbers that I tested which were separated by 20 percentage points, 81% and 61% were the numbers which made the given result the least unlikely. 80/60 and 79/59 give odds of about 2.5% and 2.4%; 82/62 and 83/63 give odds of 2.4% and 2.2%.
You can do the statistical calculations directly, but in case you won't believe it unless you see the results unfold with your own eyes, you can run this perl script, which iterates through a million trials of the experiment, counting the number of times that the unexpected result occurs.
Why did I assume a 20-point gap? That was the most subjective leap that I made. Looking through the original editorial, I figured that on the basis of inflammatory statements like
"Only one woman was called 'adorable' by the media and portrayed with girlish innocence, and it wasn't the black one. It never is."
and
"The contrast in headlines is so stark, it deserves to be examined" [I assume here she meant the contrast in responses]
the author meant to imply a difference in people's attitudes that was at least that large. But the results suggest that it isn't.
For all of this effort, of course, I could have just expanded the original experiment to a sample of several hundred and mollified some people's concerns. But I wanted to argue for what you can show, even with small samples, because I would like to try (and would like others to try) similar experiments in the future, and do not think people should be discouraged if they can't afford to pay a thousand Amazon Mechanical Turk workers to take their survey. I paid my 100 respondents $0.25 each; naturally, one experiment I'd like to do soon is to figure out what's the lowest I can get away with paying them.
-
Big Talk About Small Samples
Bennett Haselton writes: My last article garnered some objections from readers saying that the sample sizes were too small to draw meaningful conclusions. (36 out of 47 survey-takers, or 77%, said that a picture of a black woman breast-feeding was inappropriate; while in a different group, 38 out of 54 survey-takers, or 70%, said that a picture of a white woman breast-feeding was inappropriate in the same context.) My conclusion was that, even on the basis of a relatively small sample, the evidence was strongly against a "huge" gap in the rates at which the surveyed population would consider the two pictures to be inappropriate. I stand by that, but it's worth presenting the math to support that conclusion, because I think the surveys are valuable tools when you understand what you can and cannot demonstrate with a small sample. (Basically, a small sample can present only weak evidence as to what the population average is, but you can confidently demonstrate what it is not.) Keep reading to see what Bennett has to say.The smallest sample I've ever used to make an argument was when I submitted some legal briefs, each no longer than five pages, in the anti-spam cases that I'd been filing in Washington State small claims court. Since I suspected the judges were not taking the cases seriously, I filed the briefs with the third and fourth pages stuck together in the center, by a tiny thread of paper joining the back of the third page to the front of the fourth page. (If someone were to turn the pages and actually readthe brief, the thread would break.) I did something similar in six different cases, and when the motions were all rejected, I went to the courthouse to look at the paper motions still in the file. In three out of six cases, the judge had rejected the motion without reading it first.
Now, the point was not to make any accurate estimation of the actual proportion, in the total population of small claims court judges, who would reject a brief in an anti-spam case without reading it. There's no basis for saying that the proportion of such judges is close to 50%. But we can still probably reject any contention that the proportion of such judges is very low. If only 10% of judges were rejecting motions without reading them, then there is only about a 1.4% chance of taking a random sample of six rejected motions and finding that in three or more cases, the judge did not read the motion. Even if 20% of judges were doing so, for an event with a probability of p=0.20 you would still only see it occur in three out of six cases, about 8.2% of the time. (If an event has probability p, the exact probability of that event occuring three or more times in six trials is given by 20*(p^3)*((1-p)^3) + 15*(p^4)*((1-p)^2) + 6*(p^5)*((1-p)^1) + 1*(p^6)*((1-p)^0).) So we can say that the proportion of such judges is quite probably more than 20%. I did this repeatedly because even after I had "caught" the first judge, I wanted to head off any objection that this was just an isolated case of rare behavior.
And, as always, it's important not to generalize too much about the behavior whose probability we're estimating. I don't think that 20% or more of judges, even in small claims court, are throwing most types of cases without reading or listening to the arguments. My impression was that most judges see view small claims court as a place to redress injustices, and that they see anti-spam and anti-telemarketer plaintiffs as just trying to "make money" at it, so they take those suits less seriously. I disagreed with this stance because (1) anti-spam plaintiffs usually really have been harmed and are not just "whining about one email" which they are trying to "cash in" (I still get so much spam that it interferes somewhat with the operation of my server and with my ability to get through my daily email); and (2) the law is intended after all as a deterrent, with disproportionate damages in order to discourage spammers from spamming in the first place. However, the charitable reading of the results is to assume that judges are merely biased against anti-spam plaintiffs -- but at least they probably don't treat all cases as casually as they treat anti-spam suits!
Back to the issue of small samples. My previous article was prompted by an editorial about the online response that had been elicited by two different photos -- one showing a black woman breastfeeding, and a nearly identical photo showing a white woman breastfeeding. The author asserted that the photos had received vastly different responses, which she attributed to racism. I presented a survey to a sample if users recruited from Amazon's Mechanical Turk, randomly showed each survey-taker one of the two photos, and asked:
Our academic department has asked everyone to submit a "fun" photo of themselves, so that our photos can be displayed together on the department home page. One of our employees submitted a photo that has caused some internal debate about whether the photo is inappropriate. I wanted to do a poll to get the opinion of a random sample of Internet users of different backgrounds.
Do you think this is an appropriate picture to be used in a photo collection on our academic department home page?Out of 47 respondents who saw the black woman's photo, 36 of them (77%) said it was inappropriate. Out of 54 respondents who saw the white woman's photo, 38 of them (70%) said it was inappropriate.
As before, these samples are to small to say precisely what the relevant proportions in the background populations are, but we can probably reject certain statements about the populations -- for example, that the percentage of users offended by the black woman's photo is 20 percentage points higher than the percentage of users offended by the white woman's photo. This is where the counterintuitive part comes in. Suppose that in the background population, 81% of respondents would find the black woman's photo offensive, but only 61% would be offended by the white woman's photo. What are the odds of getting 77% or less "yes that's offensive" responses from a sample of 47 users shown the black woman's photo, and getting 70% or more "yes that's offensive" responses from a sample of 54 users shown the white woman's photo? It doesn't sound unlikely at all, because the percentages are quite close to the originals -- but you can verify, either with statistical calculations or with a quickly written computer program, that the odds are only about 2.5%.
Two main factors contribute to this counterintuitive result. First, even with a sample size of a few dozen, the frequency of an event starts to tend very closely to the frequency in the background population (if 80% of your population has some trait, and you take a sample of size 50, there's about a 95% chance that the number with that trait in your population will be between 34 and 46). Second, to find the odds of seeing both of these deviations at the same time (deviating from an assumed 81% in the background population down to 77% in the first sample, and deviating from an assumed 61% in the background population up to 70% in the second sample), you have to mutiply the probabilities of these two unlikely events. The probability of the first deviation is about 19%, the probability of the second is about 13%, and so the probability of them both occurring is about 2.5%.
The reason I calculated the odds of getting 77% or less "offended" responses for the black woman's photo while also getting 70% or more "offended" responses for the white woman's photo, is that in calculating the "unlikeliness" of a statistical result, it's customary to calculate the odds of getting "this result or a more extreme one". For example, suppose you want to know if a company's hiring process is gender-balanced (assuming a 50/50 gender split in the population), and you notice that in a random sample of 100 recent hires, 61 were men. You wouldn't ask "What are the odds of there being exactly 61 men in this sample?", because the odds of getting any particular number, are small. You'd ask, "What are the odds of getting this result or a more extreme one -- i.e. the odds of getting 61 or more men out of a random sample of 100, if the population were truly gender-balanced? As this calculation tool shows, the odds are only about 1.7%.
Similarly, in the case of the two populations being measured, the author of the original editorial hypothesized that there was some significant gap between the percentages of the population that were offended by the two photos, which I arbitrarily assumed to be 20 percentage points. Under that assumption, showing the two pictures to two different groups and having them be offended at similar rates, is the unexpected, "extreme" result, and the closer the rates are to each other, the more extreme the result is. That's why I calculated "77% of less" for the first group vs. "70% or more" for the second group.
And out of the pairs of numbers that I tested which were separated by 20 percentage points, 81% and 61% were the numbers which made the given result the least unlikely. 80/60 and 79/59 give odds of about 2.5% and 2.4%; 82/62 and 83/63 give odds of 2.4% and 2.2%.
You can do the statistical calculations directly, but in case you won't believe it unless you see the results unfold with your own eyes, you can run this perl script, which iterates through a million trials of the experiment, counting the number of times that the unexpected result occurs.
Why did I assume a 20-point gap? That was the most subjective leap that I made. Looking through the original editorial, I figured that on the basis of inflammatory statements like
"Only one woman was called 'adorable' by the media and portrayed with girlish innocence, and it wasn't the black one. It never is."
and
"The contrast in headlines is so stark, it deserves to be examined" [I assume here she meant the contrast in responses]
the author meant to imply a difference in people's attitudes that was at least that large. But the results suggest that it isn't.
For all of this effort, of course, I could have just expanded the original experiment to a sample of several hundred and mollified some people's concerns. But I wanted to argue for what you can show, even with small samples, because I would like to try (and would like others to try) similar experiments in the future, and do not think people should be discouraged if they can't afford to pay a thousand Amazon Mechanical Turk workers to take their survey. I paid my 100 respondents $0.25 each; naturally, one experiment I'd like to do soon is to figure out what's the lowest I can get away with paying them.
-
Big Talk About Small Samples
Bennett Haselton writes: My last article garnered some objections from readers saying that the sample sizes were too small to draw meaningful conclusions. (36 out of 47 survey-takers, or 77%, said that a picture of a black woman breast-feeding was inappropriate; while in a different group, 38 out of 54 survey-takers, or 70%, said that a picture of a white woman breast-feeding was inappropriate in the same context.) My conclusion was that, even on the basis of a relatively small sample, the evidence was strongly against a "huge" gap in the rates at which the surveyed population would consider the two pictures to be inappropriate. I stand by that, but it's worth presenting the math to support that conclusion, because I think the surveys are valuable tools when you understand what you can and cannot demonstrate with a small sample. (Basically, a small sample can present only weak evidence as to what the population average is, but you can confidently demonstrate what it is not.) Keep reading to see what Bennett has to say.The smallest sample I've ever used to make an argument was when I submitted some legal briefs, each no longer than five pages, in the anti-spam cases that I'd been filing in Washington State small claims court. Since I suspected the judges were not taking the cases seriously, I filed the briefs with the third and fourth pages stuck together in the center, by a tiny thread of paper joining the back of the third page to the front of the fourth page. (If someone were to turn the pages and actually readthe brief, the thread would break.) I did something similar in six different cases, and when the motions were all rejected, I went to the courthouse to look at the paper motions still in the file. In three out of six cases, the judge had rejected the motion without reading it first.
Now, the point was not to make any accurate estimation of the actual proportion, in the total population of small claims court judges, who would reject a brief in an anti-spam case without reading it. There's no basis for saying that the proportion of such judges is close to 50%. But we can still probably reject any contention that the proportion of such judges is very low. If only 10% of judges were rejecting motions without reading them, then there is only about a 1.4% chance of taking a random sample of six rejected motions and finding that in three or more cases, the judge did not read the motion. Even if 20% of judges were doing so, for an event with a probability of p=0.20 you would still only see it occur in three out of six cases, about 8.2% of the time. (If an event has probability p, the exact probability of that event occuring three or more times in six trials is given by 20*(p^3)*((1-p)^3) + 15*(p^4)*((1-p)^2) + 6*(p^5)*((1-p)^1) + 1*(p^6)*((1-p)^0).) So we can say that the proportion of such judges is quite probably more than 20%. I did this repeatedly because even after I had "caught" the first judge, I wanted to head off any objection that this was just an isolated case of rare behavior.
And, as always, it's important not to generalize too much about the behavior whose probability we're estimating. I don't think that 20% or more of judges, even in small claims court, are throwing most types of cases without reading or listening to the arguments. My impression was that most judges see view small claims court as a place to redress injustices, and that they see anti-spam and anti-telemarketer plaintiffs as just trying to "make money" at it, so they take those suits less seriously. I disagreed with this stance because (1) anti-spam plaintiffs usually really have been harmed and are not just "whining about one email" which they are trying to "cash in" (I still get so much spam that it interferes somewhat with the operation of my server and with my ability to get through my daily email); and (2) the law is intended after all as a deterrent, with disproportionate damages in order to discourage spammers from spamming in the first place. However, the charitable reading of the results is to assume that judges are merely biased against anti-spam plaintiffs -- but at least they probably don't treat all cases as casually as they treat anti-spam suits!
Back to the issue of small samples. My previous article was prompted by an editorial about the online response that had been elicited by two different photos -- one showing a black woman breastfeeding, and a nearly identical photo showing a white woman breastfeeding. The author asserted that the photos had received vastly different responses, which she attributed to racism. I presented a survey to a sample if users recruited from Amazon's Mechanical Turk, randomly showed each survey-taker one of the two photos, and asked:
Our academic department has asked everyone to submit a "fun" photo of themselves, so that our photos can be displayed together on the department home page. One of our employees submitted a photo that has caused some internal debate about whether the photo is inappropriate. I wanted to do a poll to get the opinion of a random sample of Internet users of different backgrounds.
Do you think this is an appropriate picture to be used in a photo collection on our academic department home page?Out of 47 respondents who saw the black woman's photo, 36 of them (77%) said it was inappropriate. Out of 54 respondents who saw the white woman's photo, 38 of them (70%) said it was inappropriate.
As before, these samples are to small to say precisely what the relevant proportions in the background populations are, but we can probably reject certain statements about the populations -- for example, that the percentage of users offended by the black woman's photo is 20 percentage points higher than the percentage of users offended by the white woman's photo. This is where the counterintuitive part comes in. Suppose that in the background population, 81% of respondents would find the black woman's photo offensive, but only 61% would be offended by the white woman's photo. What are the odds of getting 77% or less "yes that's offensive" responses from a sample of 47 users shown the black woman's photo, and getting 70% or more "yes that's offensive" responses from a sample of 54 users shown the white woman's photo? It doesn't sound unlikely at all, because the percentages are quite close to the originals -- but you can verify, either with statistical calculations or with a quickly written computer program, that the odds are only about 2.5%.
Two main factors contribute to this counterintuitive result. First, even with a sample size of a few dozen, the frequency of an event starts to tend very closely to the frequency in the background population (if 80% of your population has some trait, and you take a sample of size 50, there's about a 95% chance that the number with that trait in your population will be between 34 and 46). Second, to find the odds of seeing both of these deviations at the same time (deviating from an assumed 81% in the background population down to 77% in the first sample, and deviating from an assumed 61% in the background population up to 70% in the second sample), you have to mutiply the probabilities of these two unlikely events. The probability of the first deviation is about 19%, the probability of the second is about 13%, and so the probability of them both occurring is about 2.5%.
The reason I calculated the odds of getting 77% or less "offended" responses for the black woman's photo while also getting 70% or more "offended" responses for the white woman's photo, is that in calculating the "unlikeliness" of a statistical result, it's customary to calculate the odds of getting "this result or a more extreme one". For example, suppose you want to know if a company's hiring process is gender-balanced (assuming a 50/50 gender split in the population), and you notice that in a random sample of 100 recent hires, 61 were men. You wouldn't ask "What are the odds of there being exactly 61 men in this sample?", because the odds of getting any particular number, are small. You'd ask, "What are the odds of getting this result or a more extreme one -- i.e. the odds of getting 61 or more men out of a random sample of 100, if the population were truly gender-balanced? As this calculation tool shows, the odds are only about 1.7%.
Similarly, in the case of the two populations being measured, the author of the original editorial hypothesized that there was some significant gap between the percentages of the population that were offended by the two photos, which I arbitrarily assumed to be 20 percentage points. Under that assumption, showing the two pictures to two different groups and having them be offended at similar rates, is the unexpected, "extreme" result, and the closer the rates are to each other, the more extreme the result is. That's why I calculated "77% of less" for the first group vs. "70% or more" for the second group.
And out of the pairs of numbers that I tested which were separated by 20 percentage points, 81% and 61% were the numbers which made the given result the least unlikely. 80/60 and 79/59 give odds of about 2.5% and 2.4%; 82/62 and 83/63 give odds of 2.4% and 2.2%.
You can do the statistical calculations directly, but in case you won't believe it unless you see the results unfold with your own eyes, you can run this perl script, which iterates through a million trials of the experiment, counting the number of times that the unexpected result occurs.
Why did I assume a 20-point gap? That was the most subjective leap that I made. Looking through the original editorial, I figured that on the basis of inflammatory statements like
"Only one woman was called 'adorable' by the media and portrayed with girlish innocence, and it wasn't the black one. It never is."
and
"The contrast in headlines is so stark, it deserves to be examined" [I assume here she meant the contrast in responses]
the author meant to imply a difference in people's attitudes that was at least that large. But the results suggest that it isn't.
For all of this effort, of course, I could have just expanded the original experiment to a sample of several hundred and mollified some people's concerns. But I wanted to argue for what you can show, even with small samples, because I would like to try (and would like others to try) similar experiments in the future, and do not think people should be discouraged if they can't afford to pay a thousand Amazon Mechanical Turk workers to take their survey. I paid my 100 respondents $0.25 each; naturally, one experiment I'd like to do soon is to figure out what's the lowest I can get away with paying them.
-
State Department Joins NOAA, USPS In Club of Hacked Federal Agencies
Hot on the heels of recent cyber attacks on NOAA, the USPS, and the White House, the New York Times reports that the U.S. State Department has also suffered an online security breach, though it's not clear who to blame. “This has impacted some of our unclassified email traffic and our access to public websites from our main unclassified system,” said one senior State Department official, adding that the department expected its systems to be up soon. ....The breach at the White House was believed to be the work of hackers in Russia, while the breaches at NOAA and the Postal Service were believed to the work of hackers inside China. Attributing attacks to a group or nation is difficult because hackers typically tend to route their attack through compromised web servers all over the world. A senior State Department official said the breach was discovered after “activity of concern” was detected on portions of its unclassified computer system. Officials did not say how long hackers may have been lurking in those systems, but security improvements were being added to them on Sunday. -
State Department Joins NOAA, USPS In Club of Hacked Federal Agencies
Hot on the heels of recent cyber attacks on NOAA, the USPS, and the White House, the New York Times reports that the U.S. State Department has also suffered an online security breach, though it's not clear who to blame. “This has impacted some of our unclassified email traffic and our access to public websites from our main unclassified system,” said one senior State Department official, adding that the department expected its systems to be up soon. ....The breach at the White House was believed to be the work of hackers in Russia, while the breaches at NOAA and the Postal Service were believed to the work of hackers inside China. Attributing attacks to a group or nation is difficult because hackers typically tend to route their attack through compromised web servers all over the world. A senior State Department official said the breach was discovered after “activity of concern” was detected on portions of its unclassified computer system. Officials did not say how long hackers may have been lurking in those systems, but security improvements were being added to them on Sunday. -
State Department Joins NOAA, USPS In Club of Hacked Federal Agencies
Hot on the heels of recent cyber attacks on NOAA, the USPS, and the White House, the New York Times reports that the U.S. State Department has also suffered an online security breach, though it's not clear who to blame. “This has impacted some of our unclassified email traffic and our access to public websites from our main unclassified system,” said one senior State Department official, adding that the department expected its systems to be up soon. ....The breach at the White House was believed to be the work of hackers in Russia, while the breaches at NOAA and the Postal Service were believed to the work of hackers inside China. Attributing attacks to a group or nation is difficult because hackers typically tend to route their attack through compromised web servers all over the world. A senior State Department official said the breach was discovered after “activity of concern” was detected on portions of its unclassified computer system. Officials did not say how long hackers may have been lurking in those systems, but security improvements were being added to them on Sunday. -
Billionaire Donors Lavish Millions On Code.org Crowdfunding Project
theodp (442580) writes "Whether it's winning yacht races, assembling the best computer science faculty, or even dominating high school basketball, billionaires like to win. Which may help explain why three tech billionaires — Code.org backers (and FWD.us founders) Mark Zuckerberg, VC John Doerr, and Sean Parker — stepped up to the plate and helped out Code.org's once-anemic Hour of Code Indiegogo crowdfunding project with $500k donations. When matched by Code.org's largest donors (Bill Gates, Reid Hoffman and others), the three donations alone raised $3,000,000, enough to reach the organization's goal of becoming the most funded crowdfunding campaign ever on Indiegogo. On its campaign page, Code.org remarked that "to sustain our organization for the long haul, we need to engage parents and community members," which raises questions about how reliant the K-12 learn-to-code movement might be on the kindness of its wealthy corporate and individual donors. Code.org started shedding some light on its top donors a few months back, but contributor names are blank in the 2013 IRS 990 filing posted by the organization on its website, although GuideStar suggests the biggest contributors in 2013 were Microsoft ($3,149,411) and Code.org founders Hadi and Ali Partovi ($1,873,909 in Facebook stock). Coincidentally, in a Reddit AMA at Code.org's launch, CEO and Founder Hadi Partovi noted that his next-door-neighbor is Microsoft General Counsel and Code.org Board member Brad Smith, whose FWD.us bio notes is responsible for Microsoft's philanthropic work. Just months before Code.org and FWD.us emerged on the lobbying scene, Smith announced Microsoft's National Talent Strategy, which called for "an increase in developing the American STEM pipeline in exchange for these new [H-1B] visas and green cards," a wish that President Obama is expected to grant shortly via executive action." -
AT&T Stops Using 'Super Cookies' To Track Cellphone Data
jriding (1076733) writes AT&T Mobility, the nation's second-largest cellular provider, says it's no longer attaching hidden Internet tracking codes to data transmitted from its users' smartphones. The practice made it nearly impossible to shield its subscribers' identities online. Would be nice to hear something similar from Verizon. -
Ask Slashdot: Is Non-USB Flash Direct From China Safe?
Dishwasha (125561) writes I recently purchased a couple 128GB MicroSDXC card from a Chinese supplier via Alibaba at 1/5th the price of what is available in the US. I will be putting one in my phone and another in my laptop. A few days after purchased, it occurred to me there may be a potential risk with non-USB flash devices similar to USB firmware issues. Does anybody know if there are any known firmware issues with SD or other non-USB flash cards that could effectively allow a foreign seller/distributor to place malicious software on my Android phone or laptop simply on insertion of the device with autoplay turned off? -
Education Chief Should Know About PLATO and the History of Online CS Education
theodp writes Writing in Vanity Fair, U.S. Secretary of Education Arne Duncan marvels that his kids can learn to code online at their own pace thanks to "free" lessons from Khan Academy, which Duncan credits for "changing the way my kids learn" (Duncan calls out his kids' grade school for not offering coding). The 50-year-old Duncan, who complained last December that he "didn't have the opportunity to learn computer skills" while growing up attending the Univ. of Chicago Lab Schools and Yale, may be surprised to learn that the University of Illinois was teaching kids how to program online in the '70s with its PLATO system, and it didn't look all that different from what Khan Academy came up with for his kids 40 years later (Roger Ebert remarked in his 2011 TED Talk that seeing Khan Academy gave him a flashback to the PLATO system he reported on in the '60s). So, does it matter if the nation's education chief — who presides over a budget that includes $69 billion in discretionary spending — is clueless about The Hidden History of Ed-Tech? Some think so. "We can't move forward," Hack Education's Audrey Watters writes, "til we reconcile where we've been before." So, if Duncan doesn't want to shell out $200 to read a 40-year-old academic paper on the subject (that's a different problem!) to bring himself up to speed, he presumably can check out the free offerings at Ed.gov. A 1975 paper on Interactive Systems for Education, for instance, notes that 650 students were learning programming on PLATO during the Spring '75 semester, not bad considering that Khan Academy is boasting that it "helped over 2000 girls learn to code" in 2014 (after luring their teachers with funding from a $1,000,000 Google Award). Even young techies might be impressed by the extent of PLATO's circa-1975 online CS offerings, from lessons on data structures and numerical analysis to compilers, including BASIC, PL/I, SNOBOL, APL, and even good-old COBOL. -
Ubisoft Points Finger At AMD For Assassin's Creed Unity Poor Performance
MojoKid (1002251) writes "Life is hard when you're a AAA publisher. Last month, Ubisoft blamed weak console hardware for the troubles it had bringing Assassin's Creed Unity up to speed, claiming that it could've hit 100 FPS but for weak console CPUs. Now, in the wake of the game's disastrous launch, the company has changed tactics — suddenly, all of this is AMD's fault. An official company forum post currently reads: "We are aware that the graphics performance of Assassin's Creed Unity on PC may be adversely affected by certain AMD CPU and GPU configurations. This should not affect the vast majority of PC players, but rest assured that AMD and Ubisoft are continuing to work together closely to resolve the issue, and will provide more information as soon as it is available." There are multiple problems with this assessment. First, there's no equivalent Nvidia-centric post on the main forum, and no mention of the fact that if you own an Nvidia card of any vintage but a GTX 970 or 980, you're going to see less-than ideal performance. According to sources, the problem with Assassin's Creed Unity is that the game is issuing tens of thousands of draw calls — up to 50,000 and beyond, in some cases. This is precisely the kind of operation that Mantle and DirectX 12 are designed to handle, but DirectX 11, even 11.2, isn't capable of efficiently processing that many calls at once. It's a fundamental limit of the API and it kicks in harshly in ways that adding more CPU cores simply can't help with. -
HYREL 3-D Printers Were Developed by 3-D Printer Users (Video)
HYREL 3-D had a display Timothy spotted at last month's Maker Faire Atlanta. They're not trying to hustle Kickstarter donors; they exceeded their $50,000 goal by over $100,000. Their main pitch was (and still is) that they are making high-reliability 3-D printers that can run many hours without breaking. Project spokesperson Daniel Hutchison says he and other people he knows who were making prototypes and short-run parts in the Atlanta area were continually disappointed by the poor reliability of available 3-D printers, which is why they decided to make their own. Open Source? Somewhat, partially, kind of... but they have a bunch of proprietary secret sauce in their software, too. Daniel goes into this in more detail in the video, so there's no need for us to repeat his words when you can hear them (or read them in the transcript) for yourself. (Alternate Video Link) -
Debunking a Viral Internet Post About Breastfeeding Racism
Bennett Haselton writes: A editorial with 24,000 Facebook shares highlights the differences in public reaction to two nearly identical breastfeeding photos, one showing a black woman and one showing a white woman, each breastfeeding an infant. The editorial decries the outrage provoked by the black woman's photo compared to the mild reaction elicited by the white woman's photo, and attributes the difference to racism. I tried an experiment using Amazon's Mechanical Turk to test that theory. Read on to see the kind of results Bennett found.You can see the side-by-side pictures in the November 10 editorial by Ruby Hamad. My first thought, upon seeing the pictures, was that this is not a controlled experiment -- the woman on the left is breastfeeding in public, while the woman on the right is breastfeeding against a blank wall inside a presumably private room. While I think breastfeeding in public should be completely normalized, it's not the same thing as breastfeeding in private, and so that might have accounted for the difference in reactions, if there was any.
My second thought was that the data on people's reactions was not collected in a systematic way. According to the editorial, the black photo of the black mother, Karlesha Thurman, was posted on the Facebook page Black Women Do Breastfeed, and "[w]hile Karlesha received many supportive comments, the backlash was so severe, she eventually deleted the photo." The photo of the Australian woman, Jacci Sharkey, was posted by the University of the Sunshine Coast on their Facebook page, where it received 275,000 Facebook "likes", but also, according to the editorial, "more than a few detractors, proving that breastfeeding in public is (still!) a contentious issue for women of all races." There's no apples-to-apples comparison gauging people's reactions to the two photos under similar conditions.
But just because the methodology was imprecise, doesn't mean that the underlying phenomenon might not be real. Maybe Internet users really do have different gut reactions to pictures of black women and white women breastfeeding.
One quick way to get a rough answer is Amazon's Mechanical Turk service, where you can pay legions of workers some small amount of money per person to complete some menial task that can't be automated by a computer. I've used it dozens of times for surveys (such as gauging whether people would strongly prefer slideout keyboard phones) and for amateur psychological experiments (including one experiment which suggested that people who answered a math problem correctly were more likely to disagree with an attorney general's dubious legal argument). So I created a poll on Mechanical Turk, limited to U.S. users and with a payout of 25 cents for each person who answered. The poll asked:
Our academic department has asked everyone to submit a "fun" photo of themselves, so that our photos can be displayed together on the department home page. One of our employees submitted a photo that has caused some internal debate about whether the photo is inappropriate. I wanted to do a poll to get the opinion of a random sample of Internet users of different backgrounds.
Do you think this is an appropriate picture to be used in a photo collection on our academic department home page?Since the original photos had been published in different contexts anyway, I tried to find a middle ground for the wording of the survey question, to emphasize that the photos were going to be published in a "fun" setting, but still integrated into the women's professional environments. The survey-takers were then (randomly) shown either the black woman's photo or the white woman's photo, and answered "Yes, the image is fine" or "No, the image is inappropriate". Then respondents were asked to fill in their age, gender, ethnicity, and education level.
(One thing that I've found with all of my previous surveys on Mechanical Turk, is that there is strong evidence that survey-takers are not answering randomly. Strong correlations often occur where you would expect them to -- for example, in a survey about what are the greatest causes of global strife, the same people tend to select "Energy shortages" and "Environmental damage" above other options, whereas another subgroup will tend to select both "Atheism" and "Decline of traditional values". And any survey where I've added a textbox for users to enter "more thoughts", most users enter something reasonably thoughtful which corresponds to the multiple-choice answers they've selected. Formal research by the psychologist Samuel Gosling has similarly found that Internet surveys can be useful for psychological research and are not plagued with bot-responders or random answers. So I'm working under that assumption.)
The results: Out of 47 respondents who saw the black girl's picture, 36 said the image was inappropriate (77%). Out of 54 respondents who saw the white girl's picture, 38 said the image was inappropriate (70%). For such a small sample, that's not enough to definitively say whether the small difference is due to random chance, or due to small differences in opinion in the population being surveyed. What it does show, even with such a small sample, is that in the underlying population there's almost certainly no huge gap between people's opinions of black women vs. white women breastfeeding in photos.
In both surveys, both male and female respondents voted the photos "inappropriate" with about the same frequency. For the black woman's photo, 22 out of 26 men (86%) and 14 out of 21 women (67%) voted the photo inappropriate; for the white woman's photo, 19 out of 30 men (63%) and 19 out of 24 women (79%) voted it inappropriate. There also didn't appear to be any correlation between the age of the respondents and their responses. (You can view the breakdown of answers in terms of respondent demographics here for the black woman's picture and here for the white woman's picture; the crummy layout is because I just copied-and-pasted the output from my own custom-written survey-taking tool, where I usually just view the results for myself.) As for the gap between black and white survey-takers, in the case of the black woman's photo, 24 out of 34 white survey-takers (70%) and 5 out of 6 black survey-takers (83%) voted it inappropriate, while for the white woman's photo, 25 out of 36 white survey-takers (69%) and 4 out of 4 (100%) of black survey-takers voted it inappropriate -- but those discrepancies probably don't mean much, since the population of self-identified black respondents was too small in both cases to draw any conclusions.
Even with small samples, though, I would argue that this is a better way to answer the question of latent racism than to draw fuzzy conclusions based on the trolling comments posted on a Facebook photo. My guess is that even if there was an underlying difference in the frequency of negative comments posted to the two photos, part of it could have been due to the photo being posted in a Facebook group titled "Black Women Do Breastfeed", a group name that is practically begging for trolls to wait for a chance to try and provoke an outraged response. The white woman's photo, on the other hand, was posted on the University of the Sunshine Coast Facebook page, which is not the kind of place that maladjusted nitwits hang out trying to start a flame war. And for the trolls who did post on the white woman's photo, their natural inclination would be to make some immature comment about b00bs; whereas for the trolls posting on the black woman's photo, the easiest cheap shot would be to make it about race. But that doesn't mean that there is actually a racially motivated difference in people's reactions to the photos.
Besides, if you want to use Facebook to raise awareness of racism, there are properly controlled scientific experiments that have demonstrated the extent of prejudice, such as the infamous 2003 resume callback experiment which showed that resumes with white-sounding names on them received about 50% more callbacks than resumes with black-sounding names. A viral story with 24,000 Facebook shares, about two isolated incidents under different circumstances, is not necessarily evidence of racism. It might be. But you have to do some kind of controlled experiment to check first.
-
Debunking a Viral Internet Post About Breastfeeding Racism
Bennett Haselton writes: A editorial with 24,000 Facebook shares highlights the differences in public reaction to two nearly identical breastfeeding photos, one showing a black woman and one showing a white woman, each breastfeeding an infant. The editorial decries the outrage provoked by the black woman's photo compared to the mild reaction elicited by the white woman's photo, and attributes the difference to racism. I tried an experiment using Amazon's Mechanical Turk to test that theory. Read on to see the kind of results Bennett found.You can see the side-by-side pictures in the November 10 editorial by Ruby Hamad. My first thought, upon seeing the pictures, was that this is not a controlled experiment -- the woman on the left is breastfeeding in public, while the woman on the right is breastfeeding against a blank wall inside a presumably private room. While I think breastfeeding in public should be completely normalized, it's not the same thing as breastfeeding in private, and so that might have accounted for the difference in reactions, if there was any.
My second thought was that the data on people's reactions was not collected in a systematic way. According to the editorial, the black photo of the black mother, Karlesha Thurman, was posted on the Facebook page Black Women Do Breastfeed, and "[w]hile Karlesha received many supportive comments, the backlash was so severe, she eventually deleted the photo." The photo of the Australian woman, Jacci Sharkey, was posted by the University of the Sunshine Coast on their Facebook page, where it received 275,000 Facebook "likes", but also, according to the editorial, "more than a few detractors, proving that breastfeeding in public is (still!) a contentious issue for women of all races." There's no apples-to-apples comparison gauging people's reactions to the two photos under similar conditions.
But just because the methodology was imprecise, doesn't mean that the underlying phenomenon might not be real. Maybe Internet users really do have different gut reactions to pictures of black women and white women breastfeeding.
One quick way to get a rough answer is Amazon's Mechanical Turk service, where you can pay legions of workers some small amount of money per person to complete some menial task that can't be automated by a computer. I've used it dozens of times for surveys (such as gauging whether people would strongly prefer slideout keyboard phones) and for amateur psychological experiments (including one experiment which suggested that people who answered a math problem correctly were more likely to disagree with an attorney general's dubious legal argument). So I created a poll on Mechanical Turk, limited to U.S. users and with a payout of 25 cents for each person who answered. The poll asked:
Our academic department has asked everyone to submit a "fun" photo of themselves, so that our photos can be displayed together on the department home page. One of our employees submitted a photo that has caused some internal debate about whether the photo is inappropriate. I wanted to do a poll to get the opinion of a random sample of Internet users of different backgrounds.
Do you think this is an appropriate picture to be used in a photo collection on our academic department home page?Since the original photos had been published in different contexts anyway, I tried to find a middle ground for the wording of the survey question, to emphasize that the photos were going to be published in a "fun" setting, but still integrated into the women's professional environments. The survey-takers were then (randomly) shown either the black woman's photo or the white woman's photo, and answered "Yes, the image is fine" or "No, the image is inappropriate". Then respondents were asked to fill in their age, gender, ethnicity, and education level.
(One thing that I've found with all of my previous surveys on Mechanical Turk, is that there is strong evidence that survey-takers are not answering randomly. Strong correlations often occur where you would expect them to -- for example, in a survey about what are the greatest causes of global strife, the same people tend to select "Energy shortages" and "Environmental damage" above other options, whereas another subgroup will tend to select both "Atheism" and "Decline of traditional values". And any survey where I've added a textbox for users to enter "more thoughts", most users enter something reasonably thoughtful which corresponds to the multiple-choice answers they've selected. Formal research by the psychologist Samuel Gosling has similarly found that Internet surveys can be useful for psychological research and are not plagued with bot-responders or random answers. So I'm working under that assumption.)
The results: Out of 47 respondents who saw the black girl's picture, 36 said the image was inappropriate (77%). Out of 54 respondents who saw the white girl's picture, 38 said the image was inappropriate (70%). For such a small sample, that's not enough to definitively say whether the small difference is due to random chance, or due to small differences in opinion in the population being surveyed. What it does show, even with such a small sample, is that in the underlying population there's almost certainly no huge gap between people's opinions of black women vs. white women breastfeeding in photos.
In both surveys, both male and female respondents voted the photos "inappropriate" with about the same frequency. For the black woman's photo, 22 out of 26 men (86%) and 14 out of 21 women (67%) voted the photo inappropriate; for the white woman's photo, 19 out of 30 men (63%) and 19 out of 24 women (79%) voted it inappropriate. There also didn't appear to be any correlation between the age of the respondents and their responses. (You can view the breakdown of answers in terms of respondent demographics here for the black woman's picture and here for the white woman's picture; the crummy layout is because I just copied-and-pasted the output from my own custom-written survey-taking tool, where I usually just view the results for myself.) As for the gap between black and white survey-takers, in the case of the black woman's photo, 24 out of 34 white survey-takers (70%) and 5 out of 6 black survey-takers (83%) voted it inappropriate, while for the white woman's photo, 25 out of 36 white survey-takers (69%) and 4 out of 4 (100%) of black survey-takers voted it inappropriate -- but those discrepancies probably don't mean much, since the population of self-identified black respondents was too small in both cases to draw any conclusions.
Even with small samples, though, I would argue that this is a better way to answer the question of latent racism than to draw fuzzy conclusions based on the trolling comments posted on a Facebook photo. My guess is that even if there was an underlying difference in the frequency of negative comments posted to the two photos, part of it could have been due to the photo being posted in a Facebook group titled "Black Women Do Breastfeed", a group name that is practically begging for trolls to wait for a chance to try and provoke an outraged response. The white woman's photo, on the other hand, was posted on the University of the Sunshine Coast Facebook page, which is not the kind of place that maladjusted nitwits hang out trying to start a flame war. And for the trolls who did post on the white woman's photo, their natural inclination would be to make some immature comment about b00bs; whereas for the trolls posting on the black woman's photo, the easiest cheap shot would be to make it about race. But that doesn't mean that there is actually a racially motivated difference in people's reactions to the photos.
Besides, if you want to use Facebook to raise awareness of racism, there are properly controlled scientific experiments that have demonstrated the extent of prejudice, such as the infamous 2003 resume callback experiment which showed that resumes with white-sounding names on them received about 50% more callbacks than resumes with black-sounding names. A viral story with 24,000 Facebook shares, about two isolated incidents under different circumstances, is not necessarily evidence of racism. It might be. But you have to do some kind of controlled experiment to check first.
-
Comet Probe Philae Unanchored But Stable — And Sending Back Images
An anonymous reader writes with an update to the successful landing of the ESA's comet probe Philae, which (as mentioned yesterday) had problems attaching to the surface of the comet's Rosetta: "BBC now reports that Philae is stable on the surface. Although no source claims so, we can all imagine a faint humming of 'Still Alive' coming from the probe." Not just stable, but sending pictures while it can. From the article: The probe left Rosetta with 60-plus hours of battery life, and will need at some point to charge up with its solar panels. But early reports indicate that in its present position, the robot is receiving only one-and-a-half hours of sunlight during every 12-hour rotation of the comet. This will not be enough to sustain operations. As a consequence, controllers here are discussing using one of Philae's deployable instruments to try to launch the probe upwards and away to a better location. But this would be a last-resort option. New submitter Thanshin notes that the persistent Philae bounced a few times, and actually performed 3 landings, at 15:33, 17:26 & 17:33 UTC.Thanshin adds links to a handful of relevant Twitter feeds, if you want to follow in something close to real time: Philae2014; esa_rosetta; and Philae_MUPUS (MUlti PUrpose Sensor One). -
Data Center Study Reveals Top 5 SMART Stats That Correlate To Drive Failures
Lucas123 writes Backblaze, which has taken to publishing data on hard drive failure rates in its data center, has just released data from a new study of nearly 40,000 spindles revealing what it said are the top 5 SMART (Self-Monitoring, Analysis and Reporting Technology) values that correlate most closely with impending drive failures. The study also revealed that many SMART values that one would innately consider related to drive failures, actually don't relate it it at all. Gleb Budman, CEO of Backblaze, said the problem is that the industry has created vendor specific values, so that a stat related to one drive and manufacturer may not relate to another. "SMART 1 might seem correlated to drive failure rates, but actually it's more of an indication that different drive vendors are using it themselves for different things," Budman said. "Seagate wants to track something, but only they know what that is. Western Digital uses SMART for something else — neither will tell you what it is." -
Google's Lease of NASA Airfield Criticized By Consumer Group
Spy Handler writes Yesterday's announcement that Google will lease Moffett Field from NASA for 60 years drew criticism from a group called Consumer Watchdog, which stated "This is like giving the keys to your car to the guy who has been siphoning gas from your tank. It is unfairly rewarding unethical and wrongful behavior. These Google guys seem to think they can do whatever they want and get away with it – and, sadly, it looks like that is true.” -
Interviews: Ask Rachel Sussman About Photography and the Oldest Living Things
samzenpus writes Rachel Sussman is a photographer whose work covers the junction of art, science, and philosophy. Perhaps her most famous work is the "Oldest Living Things in the World" project. Working with biologists, she traveled all over the world to find and photograph organisms that are 2,000 years old and older. Sussman gave a TED talk highlighting parts of the project including a clonal colony of quaking aspen 80,000-years-old and 2,000-year-old brain coral off Tobago's coast. Rachel has agreed to put down her camera and answer any questions you may have about photography or any of her projects. As usual, ask as many as you'd like, but please, one per post. -
After Silk Road 2.0 Shutdown, Rival Dark Net Markets Grow Quickly
apexcp writes: A week ago, Silk Road 2.0 was theatrically shut down by a global cadre of law enforcement. This week, the dark net is realigning. "In the wake of the latest police action against online bazaars, the anonymous black market known as Evolution is now the biggest Dark Net market of all time. Today, Evolution features 20,221 products for sale, a 28.8 percent increase from just one month ago and an enormous 300 percent increase over the past six months." -
Groupon Backs Down On Gnome
Rambo Tribble writes: Groupon has announced it will abandon the 'Gnome' name for their product, ending the recent naming controversy that had the open source community up in arms. They said, "After additional conversations with the open source community and the Gnome Foundation, we have decided to abandon our pending trademark applications for 'Gnome.' We will choose a new name for our product going forward." The GNOME Foundation has thanked everyone who helped.
My question... does this represent Gnu thinking on the part of Groupon? -
ISPs Removing Their Customers' Email Encryption
Presto Vivace points out this troubling new report from the Electronic Frontier Foundation: Recently, Verizon was caught tampering with its customer's web requests to inject a tracking super-cookie. Another network-tampering threat to user safety has come to light from other providers: email encryption downgrade attacks. In recent months, researchers have reported ISPs in the U.S. and Thailand intercepting their customers' data to strip a security flag — called STARTTLS — from email traffic. The STARTTLS flag is an essential security and privacy protection used by an email server to request encryption when talking to another server or client.
By stripping out this flag, these ISPs prevent the email servers from successfully encrypting their conversation, and by default the servers will proceed to send email unencrypted. Some firewalls, including Cisco's PIX/ASA firewall do this in order to monitor for spam originating from within their network and prevent it from being sent. Unfortunately, this causes collateral damage: the sending server will proceed to transmit plaintext email over the public Internet, where it is subject to eavesdropping and interception. -
US Postal Service Suspends Telecommuting Following Massive Breach
An anonymous reader writes: The folks at the USPS have responded to the recent breach that exposed data on 800K employees and another some 2.8 million customers. They have suspended telecommuting for all employees until further notice while they replace their VPN with a more secure version. "Additionally, the postal service will upgrade some of its equipment and systems in the coming weeks and months as part of a broad security overhaul in response to the breach." -
Microsoft Patches OLE Zero-Day Vulnerability
msm1267 writes: Microsoft today released a patch for a zero-day vulnerability under active exploit in the wild. The vulnerability in OLE, or Microsoft Windows Object Linking and Embedding, enables a hacker to remotely execute code on an infected machine, and has been linked to attacks by the Sandworm APT group against government agencies and energy utilities. Microsoft also issued a massive Internet Explorer patch, but warned organizations that have deployed version 5.0 of its Enhanced Mitigation Experience Toolkit (EMET) to upgrade to version 5.1 before applying the IE patches. Version 5.1 resolves some compatibility issues, in addition to several mitigation enhancements. -
Apple's Luxembourg Tax Deals
Presto Vivace sends a report from the Australian Financial Review on how Apple uses a holding company based in Luxembourg to avoid taxes on its iTunes revenue. Quoting: The 2011 accounts for iTunes Sàrl [the holding company] give the first inside view of how Apple accounts for its growing earnings from digital content. They are part of a massive leak of Luxembourg tax documents uncovered in an investigation led by the International Consortium of Investigative Journalists. Remarkably, the accounts show Luxembourg has been more effective in extracting tax from iTunes than Ireland has with much larger Apple sales. Turnover for iTunes Sàrl exploded from €353 million ($508 million) in 2009 to €2.05 billion in 2013. Secret appendices to the 2011 accounts break down some of Apple’s costs. It shows that Apple takes a third of iTunes’ revenues as its gross profit margin. The 2011 figures showed that a flat 50 per cent of this gross profit was paid in intercompany charges. (Followup on a similar strategy from Amazon we discussed last week.) -
Multi-Process Comes To Firefox Nightly, 64-bit Firefox For Windows 'Soon'
An anonymous reader writes with word that the Mozilla project has made two announcements that should make hardcore Firefox users very happy. The first is that multi-process support is landing in Firefox Nightly, and the second is that 64-bit Firefox is finally coming to Windows. The features are a big deal on their own, but together they show Mozilla's commitment to the desktop version of Firefox as they both improve performance and security. The news is part of a slew of unveilings from the company on the browser's 10th anniversary — including new Firefox features and the debut of Firefox Developer Edition. -
Multi-Process Comes To Firefox Nightly, 64-bit Firefox For Windows 'Soon'
An anonymous reader writes with word that the Mozilla project has made two announcements that should make hardcore Firefox users very happy. The first is that multi-process support is landing in Firefox Nightly, and the second is that 64-bit Firefox is finally coming to Windows. The features are a big deal on their own, but together they show Mozilla's commitment to the desktop version of Firefox as they both improve performance and security. The news is part of a slew of unveilings from the company on the browser's 10th anniversary — including new Firefox features and the debut of Firefox Developer Edition. -
Worrying Aspects of Linux Gaming
jones_supa writes: Former Valve engineer Rich Geldreich has written up a blog post about the state of Linux Gaming. It's an interesting read, that's for sure. When talking about recent bigger game ports, his take is that the developers doing these ports just aren't doing their best to optimize these releases for Linux and/or OpenGL. He points out how it took significant resources from Valve to properly optimize Source engine for Linux, but that other game studios are not walking the last mile. About drivers, he asks "Valve is still paying LunarG to find and fix silly perf bugs in Intel's slow open source driver. Surely this can't be a sustainable way of developing a working driver?" He ends his post by agreeing with a Slashdot comment where someone is basically saying that SteamOS is done, and that we will never get our hands on the Steam Controller. -
Worrying Aspects of Linux Gaming
jones_supa writes: Former Valve engineer Rich Geldreich has written up a blog post about the state of Linux Gaming. It's an interesting read, that's for sure. When talking about recent bigger game ports, his take is that the developers doing these ports just aren't doing their best to optimize these releases for Linux and/or OpenGL. He points out how it took significant resources from Valve to properly optimize Source engine for Linux, but that other game studios are not walking the last mile. About drivers, he asks "Valve is still paying LunarG to find and fix silly perf bugs in Intel's slow open source driver. Surely this can't be a sustainable way of developing a working driver?" He ends his post by agreeing with a Slashdot comment where someone is basically saying that SteamOS is done, and that we will never get our hands on the Steam Controller. -
Mozilla Updates Firefox With Forget Button, DuckDuckGo Search, and Ads
Krystalo writes: In addition to the debut of the Firefox Developer Edition, Mozilla today announced new features for its main Firefox browser. The company is launching a new Forget button in Firefox to help keep your browsing history private, adding DuckDuckGo as a search option, and rolling out its directory tiles advertising experiment. -
New Book Argues Automation Is Making Software Developers Less Capable
dcblogs writes: Nicholas Carr, who stirred up the tech world with his 2003 essay, IT Doesn't Matter in the Harvard Business Review, has published a new book, The Glass Cage, Automation and Us, that looks at the impact of automation of higher-level jobs. It examines the possibility that businesses are moving too quickly to automate white collar jobs. It also argues that the software profession's push to "to ease the strain of thinking is taking a toll on their own [developer] skills." In an interview, Carr was asked if software developers are becoming less capable. He said, "I think in many cases they are. Not in all cases. We see concerns — this is the kind of tricky balancing act that we always have to engage in when we automate — and the question is: Is the automation pushing people up to higher level of skills or is it turning them into machine operators or computer operators — people who end up de-skilled by the process and have less interesting work?
I certainly think we see it in software programming itself. If you can look to integrated development environments, other automated tools, to automate tasks that you have already mastered, and that have thus become routine to you that can free up your time, [that] frees up your mental energy to think about harder problems. On the other hand, if we use automation to simply replace hard work, and therefore prevent you from fully mastering various levels of skills, it can actually have the opposite effect. Instead of lifting you up, it can establish a ceiling above which your mastery can't go because you're simply not practicing the fundamental skills that are required as kind of a baseline to jump to the next level." -
Pitivi Video Editor Surpasses 50% Crowdfunding Goal, Releases Version 0.94
kxra writes With the latest developments, Pitivi is proving to truly be a promising libre video editor for GNU distributions as well as a serious contender for bringing libre video production up to par with its proprietary counterparts. Since launching a beautifully well-organized crowdfunding campaign (as covered here previously), the team has raised over half of their 35,000 € goal to pay for full-time development and has entered "beta" status for version 1.0. They've released two versions, 0.94 (release notes) being the most recent, which have brought full MPEG-TS/AVCHD support, porting to Python 3, lots of UX improvements, and—of course—lots and lots of bug fixes. The next release (0.95) will run on top of Non Linear Engine, a refined and incredibly more robust backend Pitivi developers have produced to replace GNonLin and bring Pitivi closer to the rock-solid stability needed for the final 1.0 release. -
Book Review: Countdown To Zero Day
benrothke writes A word to describe the book Takedown: The Pursuit and Capture of Americas Most Wanted Computer Outlaw was hyperbole. While the general storyline from the 1996 book was accurate, filler was written that created the legend of Kevin Mitnick. This in turn makes the book a near work of historical fiction. Much has changed in nearly 20 years and Countdown to Zero Day: Stuxnet and the Launch of the Worlds First Digital Weapon has certainly upped the ante for accurate computer security journalism. The book is a fascinating read and author Kim Zetters attention to detail and accuracy is superb. In the inside cover of the book, Kevin Mitnick describes this as an ambitious, comprehensive and engrossing book. The irony is not lost in that Mitnick was dogged by misrepresentations in Markoff's book. Keep reading for the rest of Ben's review. Countdown to Zero Day: Stuxnet and the Launch of the Worlds First Digital Weapon author Author: Kim Zetter pages 448 publisher Crown rating 10/10 reviewer Ben Rothke ISBN 978-0770436179 summary Outstanding narrative about Stuxnet and how it was developed, quarantined and debugged For those that want to know the basics about Stuxnet, its Wikipedia entry will suffice. The book take a detailed look at how the Stuxnet worm of 2010 came to be, how it was written, discovered and deciphered, and what it means for the future and provides nearly everything known to date about Stuxnet.
The need to create Stuxnet was the understanding that a nuclear Iran was dangerous to the world. The book notes that it just wasn't the US and Israel that wanted a nuclear free Iran; Egypt and Saudi Arabia were highly concerned about the dangers a nuclear Iran would bring to the region.
What is eminently clear is that Iran chronically lied about their nuclear intentions and actions (chapter 17 notes that former United Kingdom Prime Minister Gordon Brown told the international community that they had to do something over Iran's serial deception of many years) and that the United Nations International Atomic Energy Agency (IAEA) is powerless to do anything, save for monitoring and writing reports.
Just last week, President Obama said a big gap remains in international nuclear negotiations with Iran and he questioned whether talks would succeed. He further said "are we going to be able to close this final gap so that (Iran) can reenter the international community, sanctions can be slowly reduced and we have verifiable, lock tight assurances that they cant develop a nuclear weapon, there's still a big gap. We may not be able to get there". It's that backdrop to which Stuxnet was written.
While some may debate if Stuxnet was indeed the worlds first digital weapon, it's undeniable that it is the first piece of known malware that could be considered a cyber-weapon. Stuxnet was unlike any other previous malware. Rather than just hijacking targeted computers or stealing information from them, it created physical destruction on centrifuges the software controlled.
At just over 400 pages, the book is a bit wordy at times, but Zetter does a wonderful job of keeping the book extremely readable and the narrative enthralling. Writing about debugging virus code, Siemens industrial programmable logic controllers (PLC) and Step7 software (which was what Stuxnet was attacking) could easily be mind-numbingly boring, save for Zetter's ability to make it a compelling read.
While a good part of the book details the research Symantec, Kaspersky Lab and others did to debug Stuxnet, the book doesn't have any software code, which makes it readable for the non-programmer. The book is technical and Zetter gets into the elementary details of how Stuxnet operated; from reverse engineering, digital certificates and certificate authorities, cryptographic hashing and much more. The non-technical reader certainly won't be overwhelmed, but at the same time might not be able to appreciate what went into designing and making Stuxnet work.
As noted earlier, the book is extremely well researched and all significant claims are referenced. The book is heavily footnoted, which makes the book much more readable than the use of endnotes. Aside from the minor error of mistakenly calling Kurt Gödel a cryptographer on page 295, he was a logician; Zetter's painstaking attention to detail is to be commended.
Whoever wrote Stuxnet counted on the Iranians not having the skills to uncover or decipher the malicious attacks on their own. But as Zetter writes, they also didn't anticipate the crowdsourced wisdom of the hive — courtesy of the global cybersecurity community that would handle the detection and analysis for them. That detection and analysis spanned continents and numerous countries.
The book concludes with chapter 19 — Digital Pandora — which departs from the details of Stuxnet and gets into the bigger picture of what cyber-warfare means and its intended and unintended consequences. There are no simple answers here and the stakes are huge.
The chapter quotes Marcus Ranum who is outspoken on the topic of cyber-warfare. At the 2014 MISTI Infosec World Conference, Ranum gave a talk on Cyberwar: Putting Civilian Infrastructure on the Front Lines, Again. Be it the topic or Marcus just being Marcus, a third of the participants left within the first 15 minutes. But they should have stayed, as Ranum, agree with him or not, provided some riveting insights on the topic.
The book leaves two unresolved questions; who did it, and how did it get into the Nantanz enrichment facility. It is thought the US with some assistance from Israel created Stuxnet; but Zetter also writes that Germany and Great Britain may have done the work or at least provided assistance.
It's also unknown how Stuxnet got into the air-gapped facility. It was designed to spread via an infected USB flash drive. It's thought that since they couldn't get into the facility, what needed to be done was to infect computers belonging to a few outside firms that sold devices that would in turn be connected to the facility. The book identified a few of these companies, but it's still unclear if they were the ones, or the perpetrators somehow had someone on the inside.
As to zero day in the title, what was unique about Stuxnet is that it contained 5 zero day exploits. Zero day is also relevant in that Zetter describes the black and gray markets of firms that discover zero-day vulnerabilities who in turn sell them to law enforcement and intelligence agencies.
Creating Stuxnet was a huge challenge that took scores of programmers from a nation state many months to create. Writing a highly readable and engrossing book about the obscure software vulnerabilities that it exploited was also a challenge, albeit one that few authors could do efficaciously. In Countdown to Zero Day: Stuxnet and the Launch of the Worlds First Digital Weapon, Kim Zetter has written one of the best computer security narratives; a book you will likely find quite hard to put down.
Reviewed by Ben Rothke.
You can purchase Countdown to Zero Day: Stuxnet and the Launch of the Worlds First Digital Weapon from amazon.com. Slashdot welcomes readers' book reviews (sci-fi included) -- to see your own review here, read the book review guidelines, then visit the submission page. If you'd like to see what books we have available from our review library please let us know.
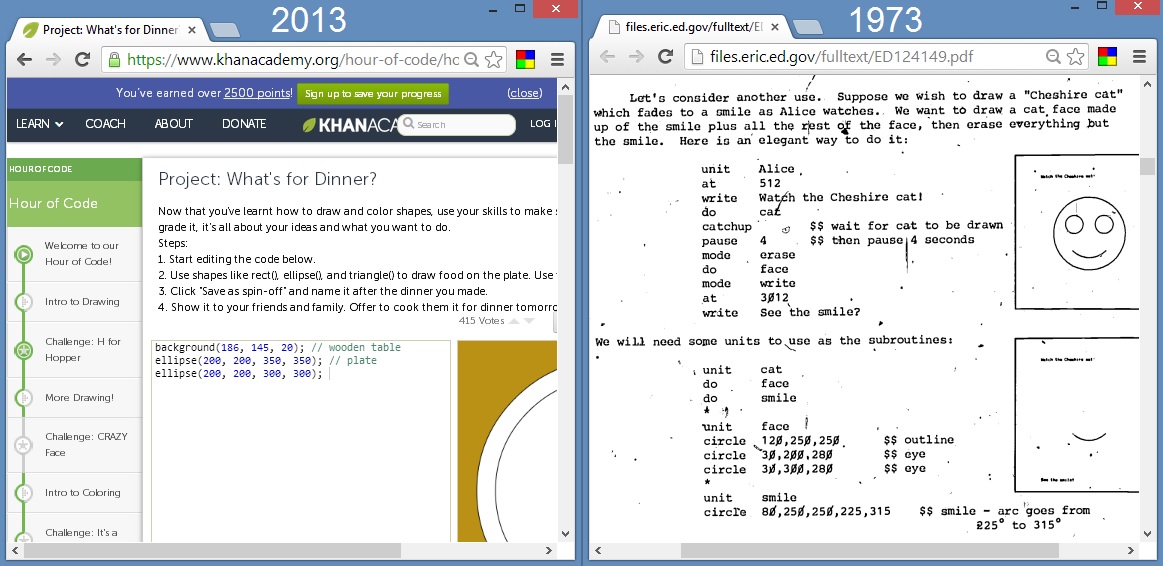{kind=link}