 Slashdot Mirror
Slashdot Mirror
Domain: ucsd.edu
Stories and comments across the archive that link to ucsd.edu.
Comments · 1,055
-
Watch the sample videos
The system has a success rate of 80%, which means that far too many false positives (or, in the case of crimes, false negatives) will be flagged. If you look at the videos that they used to typify the violent/non-violent behaviors, showing a hug and a push, you can see that the actors they had moved in very deilberate and unrealistic manners.
So, we have a system that fails 20% of the time (for really, in a system such as this, it is failure rate that is the concern) when using highly exaggerated actions. How many hugs have you had where the impact of it send you and the person in your arms staggering backwards? How many confrontations have you seen where one person is within inches of another's face, pushing and bumping in very small stages? How many muggings or holdups have you seen that are kept low-profile? Many. So, imagine this system, which already fails 1/5 of the time, trying to deduce the complexities of human interaction. -
Re:Does it need to be said?
Secure erase firmware is built into all new drives:
http://cmrr.ucsd.edu/Hughes/SecureErase.html
This is suitable for military sanitize up to secret level. -
Re:a better operating system ..
According to this it relies on special processes to isolate user data. Something I would have thought was de rigur for any moderm Operating System. In the context of the quote I don't see why you need alternative OS. Couldn't something similar be added to the current OSs. Better than that is to embed such functionality directly into the hardware. It's a good idea but hardly a paradigm shift in OS design. Yet another abuse of the I word.
" Asbestos
In additional you could innoculate the system against exploits by uniquely scrambling the microcode table and randomly loading data into memory. -
Network Analytics book review -from another readerI have read the book and liked it very much.. I write drivers and applications on routers of a reputed company and encounter the problems mentioned in the book almost on a day-to-day basis. The algorithms and case studies in book are really good and they are valid in the present state of network devices. I would recommend this book any engineer working on networking devices and applications.
In addition, the products George Varghese's research work were implemented by different network device manufactures including Cisco, Juniper, Procket etc. Lot of research papers can be found in his homepage.
-
Re:target audience
Before you jump to conclusions, keep in mind that Varghese is one of the leading experts in the design of routing algorithms and similar topics. Take a peek at his industrial impact list; he's not kidding. The fast route lookup algorithm he developed while at WUSTL was, along with some work done concurrently at Lulea university in Sweden, the most major advance in fast route lookup algorithms in about a decade. In other words - don't judge the book by the qualifications of someone who decided to review it.
Though the reviewer is right - many of the algorithms in the book would be useful in software-based routers, though there's room for caution: some of them are encumbered by patents of various sorts, and are recent enough that they'll remain so for a while. -
Re:Hopefully this will put to rest allegations...
that the US faked the moon landings!
Well, personally, I've always hoped that the objective proof of the lunar ranging experiment would have put that to rest, but apparently nobody is interested in that pesky detail.
Or, they think that is faked too. Very sad, actually.
Cheers -
Um...
Yawn. Old news.
-
Re:Thanks, everyone!
I haven't looked at all the posts, but just in case here are some links that might be useful in your search.
http://www.ams.org/employment/
http://www.ams.org/early-careers/
http://www.maa.org/careers/index.html
http://www.ams.org/careers/
http://math.ucsd.edu/~sbuss/GradInfo/index.html
http://www.beanactuary.org/
http://www.nsa.gov/careers/index.cfm
http://www.census.gov/hrd/www/jobs/emp_opp.html -
BioinformaticsSpeaking as an Immunologist, we're screaming for bioinformaticists at the moment and it's certainly an area that I would look at if I was in your position. Throw in some side work as a statistician, and you're set.
I think you'll find the bioinformatics field to be broad enough to meet just about any interest that you may have - work ranges from programming pattern recognition/alignment software (for protein or DNA work) to mathematical modeling of protein networks. Don't worry if biology isn't your greatest strength as you'll be working as a programmer/mathematician solving a biological problem, not as a biologist working with computers (in fact, graduate level programs in bioinformatics tend to recruit computer science majors as the biology/biochem/etc majors don't have the required background).
Some links for further information:
International Society for Computational Biology
National Institute of Health
UCSD
Stanford
IBM -
Re:Two technologies
Read the PolyHeme FAQ - PolyHeme FAQ
What are the potential risks of participating in the study?
Rash
Transmission of hepatitis and HIV viruses
Unforeseen happenings
You trade the chance of dying against the chance of requiring a liver transplant, or a chronic
illness requiring lifelong medication, no medical insurance, your family not wanting to be near
you, and having no employer wanting to employ you. -
Just out of curiosity,
how does this affect our understanding of spatial dynamics? I only understand physics insofar as it affects 3D graphics (specifically, light and particle dynamics), so you'll have to forgive my relative ignorance. I just find myself wondering if it's going to be a minor amendment to the current theories, or a complete re-write. If it's the second option, I'll just sit and wait for the maths patches for my various 3D software tools, shall I? Also, on a totally puerile note: you can tell that they're physicists, and not web designers, can't you? Their page http://physics.ucsd.edu/~tmurphy/apollo/apollo.ht
m l looks like it was designed around the same era the rocket they're named from was launched... -
Re:Trust
I'm sure for you a regular email client is fine. However, the problems really appear in the corporate world where people are getting 500-1000 email messages a day, with varying degrees of context, relevance, and time-critical importance. In these situations it is important to understand who is emailing you, why, how to manage your responses to write, and prioritize the mental processing of loads of email. This is where typical filing/folder methods starts to break down--it doesn't allow you as a user to add & manage new state onto the emails themselves. In the paper mail world, when you receive a letter you are free to manipulate it in many ways. One might receive it in their inbox originally, but it is free to be written on, passed around, and sorted in temporary piles (for more background see Kirsh - Intelligent use of space).
Part of the main problem is that email has been repurposed in so many different ways, that its generic form is hard to depart from because it creates specialized interfaces that mentally constrain users into a specific task/mode/usage. Yet for enough people (mostly in the corporate world), their tasks/usages are well enough defined they not only could benifit from but require a better interface to cope with the volume and task-specific needs. Furthermore, email is socially-unaware. It doesn't understand how people connect together, collaborate, or how information flows across people and contexts globally. This is why we need more research into better email interfaces. As Edward Tufte said, to clarify add detail. -
Re:Got that yesterday...
1-8xy are toll free numbers only if x==y, otherwise they're usually some area code.
http://www.cs.ucsd.edu/users/bsy/area.html -
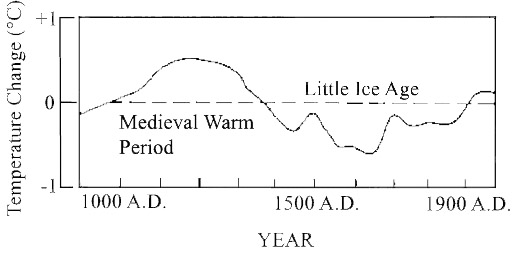
Re:temperature
Look at this, from UCSD:
Can you read? You linked to an article that
(graph): http://earthguide.ucsd.edu/virtualmuseum/images/ra w/LM_Fig8_2_1.jpg
(article): http://earthguide.ucsd.edu/virtualmuseum/climatech ange2/04_3.shtml,
and: http://en.wikipedia.org/wiki/Little_Ice_Age. Now, of course that doesn't mean we should be responsible, and reduce our emissions. I'm just tired of all of the FUD and fearmongering being spread around about doomsday and the like. A little science if you please.- Explains a hypothesis according to which global warming is not due to human activity
- Argues that this hypothesis generates harder to answer questions than the ones that it solves
-
Re:temperature
Look at this, from UCSD:
Can you read? You linked to an article that
(graph): http://earthguide.ucsd.edu/virtualmuseum/images/ra w/LM_Fig8_2_1.jpg
(article): http://earthguide.ucsd.edu/virtualmuseum/climatech ange2/04_3.shtml,
and: http://en.wikipedia.org/wiki/Little_Ice_Age. Now, of course that doesn't mean we should be responsible, and reduce our emissions. I'm just tired of all of the FUD and fearmongering being spread around about doomsday and the like. A little science if you please.- Explains a hypothesis according to which global warming is not due to human activity
- Argues that this hypothesis generates harder to answer questions than the ones that it solves
-
Re:temperature
Okay, I'm going to get a -1 flaimbait for this one...
<rant>
What happens after an ice age is over? It warms up, right? Well, we've been in a post-ice age period since, well, the last ice age. It's still significantly cooler than it has been in the distant past, and IMHO the earth is going to warm up, whether we do it or not.
Look at this, from UCSD:
(graph): http://earthguide.ucsd.edu/virtualmuseum/images/ra w/LM_Fig8_2_1.jpg
(article): http://earthguide.ucsd.edu/virtualmuseum/climatech ange2/04_3.shtml,
and: http://en.wikipedia.org/wiki/Little_Ice_Age.
Now, of course that doesn't mean we should be responsible, and reduce our emissions. I'm just tired of all of the FUD and fearmongering being spread around about doomsday and the like. A little science if you please.
</rant> -
Re:temperature
Okay, I'm going to get a -1 flaimbait for this one...
<rant>
What happens after an ice age is over? It warms up, right? Well, we've been in a post-ice age period since, well, the last ice age. It's still significantly cooler than it has been in the distant past, and IMHO the earth is going to warm up, whether we do it or not.
Look at this, from UCSD:
(graph): http://earthguide.ucsd.edu/virtualmuseum/images/ra w/LM_Fig8_2_1.jpg
(article): http://earthguide.ucsd.edu/virtualmuseum/climatech ange2/04_3.shtml,
and: http://en.wikipedia.org/wiki/Little_Ice_Age.
Now, of course that doesn't mean we should be responsible, and reduce our emissions. I'm just tired of all of the FUD and fearmongering being spread around about doomsday and the like. A little science if you please.
</rant> -
Re:Acronyms
-
Mihir Bellare's crypto courses at UCSD
You're missing out on possibly the most amazing undergraduate and graduate crypto classes out there. His research and course notes (which are almost book-like) have become a standard in the community. (And other schools, such as Berkeley and Maryland, use his course notes for their crypto classes.)
-
Mihir Bellare's crypto courses at UCSD
You're missing out on possibly the most amazing undergraduate and graduate crypto classes out there. His research and course notes (which are almost book-like) have become a standard in the community. (And other schools, such as Berkeley and Maryland, use his course notes for their crypto classes.)
-
Use the security erase feature of the ATA spec
...which is made for this purpose.
You could use MHDD to do this. Just password protect your drive using an ATA-command, then hack into it 3 times (MHDD does this automatically) to activate the security erase of the harddrive.
Wait a little while (2-6 hours, depending on the harddrive), and you're done.
I can also recommend this article, which details info on the very subject of erase protocols for harddrive, including DOD-protocols. -
No kidding
Er, yeah. No kidding.
When I was writing applications at the San Diego Supercomputer Center, latency between nodes was the single greatest obstacle to getting your CPUs to running at their full capacity. A CPU waiting to get its data is a useless CPU.
Generally speaking, clusters who want high performance used something like Myrnet instead of ethernet. It's like the difference between consumer, prosumer, and professional products you see in, oh, every industry across the board.
As a side note, how many parallel apps solve the latency issue is by overlapping their communication and computation phases, instead of having them in discrete phases, this can greatly reduce the time a CPU is idle.
The KeLP kernel does overlapping automatically for you if you want: http://www-cse.ucsd.edu/groups/hpcl/scg/kelp.html -
ISSCC paper describing Multigig technology
Is this real??? check out the Multigig web site... I noticed that Multigig has multiple papers on their technology. http://multigig.com/publications/DRAFT_ISSCC_2006
_ PAPER.pdf Multigig comments on multiple application use for Clock trees, RF and analog. I noticed a paper on analog applications at http://www.oea.com/document/DesignConPaper_04.pdf but the most interesting is a copy of an ISSCC paper at UCSD? http://www-cse.ucsd.edu/classes/wi06/cse291-b/slid e/let8/rotary.pdf -
possible prior art
The vat/vic audio/video conferencing projects at Lawrence Berkeley Nat'l Labs during the 1990s led by Steve McCanne et. al., used adaptive compression schemes for real time conferencing over IP multicast networks (the MBone).
Here's a 1996 paper. -
Re:It's not exactly clear what they have in mind
Where did I find the Evil Research(tm)? Where else but directly from the source of evil -- no, no, not Microsoft, the *other* source of evil -- Intel
It's already in their compiler;
http://www.intel.com/software/products/compilers/c lin/docs/main_cls/mergedprojects/optaps_cls/common /optaps_pgo_sspopt.htm
(Their compiler absolutely rocks BTW)
And their excellent paper titled "Speculative Precomputation: Long-range Prefetching of Delinquent Loads" by Jamison Collins, Hong Wang, Dean Tullsen, Christopher Hughes, Yong-Fong Lee, Dan Lavery, and John Shen can be found here;
http://www.intel.com/research/mrl/library/148_coll ins_j.pdf
(Those damn delinquent loads -- GET OFF OF MY LAWN YOU DELINQUENTS!
There's also
"Physical Experimentation with Prefetching Helper Threads on Intel's Hyper-Threaded Processors" by
Dongkeun Kim, Steve Shih-wei Liao, Perry Wang, Juan del Cuvillo, Xinmin Tian, Xiang Zou, Hong Wang, Donald Yeung, Milind Girkar, and John Shen which can be found here;
http://www.cgo.org/cgo2004/papers/02_80_Kim_D_REVI SED.pdf
And also;
"Speculative Precomputation on Chip Multiprocessors" by Jeffery Brown, Hong Wang, George Chrysos, Perry Wang, and John Shen at;
http://www.cs.ucsd.edu/~jbrown/papers/sp-cmp.pdf
There, that ought to cure your insomnia and answer your question: "How could a thread possibly be executed far enough in advance to make the time savings worth while, yet be sure that it is "predicting" memory accesses correctly?"
Read the papers carefully -- there will be a quiz later. -
It's not exactly clear what they have in mind
There are several techniques for increased performance or throughput that the designers of next gen microarchitectures are likely looking at.
There are extensions to known techniques;
A: more execution units, deeper reorder buffers, etc trying to extract more Instruction Level Paralelism (ILP).
B: More cores = more threads
C: hyper threading -- fill in pipeline bubbles in an OOO superscaler architetcure; also = more threads
I personally don't think any of these carry you very far...
Then there are some new ideas:
a: run-ahead threads -- use another core/hyperthread to perform only the work needed to discover what memory accesses are going to be performed and preload them into the cache - mainly a memory latency hiding technique, but that's not a bad thing as there are many codes that are dominated by memory latency
a': More aggressive OoO run-ahead where other latencies are hidden
Intel has published some good papers on these techniques, but according to those papers these techniques help in-order (read Itanic) cores much more than OoO.
b: aggressive peephole optimization (possibly other simple optimizations usually performed by compilers) done on a large trace cache. Macro/micro-op fusion is a very simple and limited start at this sort of thing. (Don't know if this is a good idea or not, or whether anyone is doing it)
But it's far from clear what AMD is doing. Whatever it is, anything that improves single threaded performance will be very welcome. Threading is hard (hard to design, implement, debug, maintain, and hard to QA). And not all code bases or algorithms are amenable to it.
Intels next gen (nahalem) is likely going to do some OoO look-ahead, as they have Andy Glew working on it, and that's been an area of interest to him...
A very interesting new concept is that of "strands" (AKA: dependency chains, traces, or sub-threads). (The idea is instead of scheduling independent instructions, schedule independent dependency chains. - For more info, see http://www.cse.ucsd.edu/users/calder/papers/IPDPS- 05-DCP.pdf)
But it's not clear how well it would apply to OoO architectures, but I would expect that likely approaches would also need large trace caches.
Applying this to an OoO x86 architecture, and detecting the critical strand dynamically in that processor could be very cool, and potentially revolutionary.
It will be very interesting to see what Intel and AMD are up to -- it would be even cooler of they both find different ways to make things go faster... -
Re:Yes...
How about just letting it bounce off of the wall....
something that small shouldn't be so heavy that it gets damaged from hitting a wall
(how fast it is going anyway?)
so, let it bounce around the room, even aimlessly....
use post-processing algorithms on the receivers to remove camera jiggle and bounce.
project the video on to a VR of the room.... and let the operators
look into the virtual room....
saw something similar on TV once.. this is the closest googling got me:
http://ucsdnews.ucsd.edu/newsrel/science/RealityFl ythrough.asp -
Re:More appropriate as an extension?Even better, from the bug report (copy and paste URL to location bar). This is Fritz Schneider, a Google employee speaking:
> Will google continue releasing the extension as part
> of Google Labs, or a product offering?
Great question. We're end-of-lifing the stand-alone extension as it is
released on Labs. Instead, we've integrated this feature into the
Google Toolbar for Firefox and it will go out in the next
release. Then one of two things happens. Case one is this feature (or
something like it) makes it into Firefox, in which case we rip it out
of the Toolbar and do all new development in Moz cvs tree. Case two is
that this feature does not make it into Firefox, in which case we
continue to support it in the Toolbar.
So, to answer your question, we'd very much like active development to
move into Moz cvs tree. But we won't force it. -
Re:Make sure you account for everything
Theres no point in travelling at close to light speed if your have no way of stopping....SPLAT
Well, considering that the nearest star systems are greater than 4.3 light years away, you do not have to worry about it, as you would be dead from starvation.
It's the same reason that Nuclear subs are not limited by how much time they can stay underwater, but how much food they can carry. The need for food makes such long distances impractical, if not intolerable. "Growing" food along the way would mean a very limited diet for eight years (assuming you want to come home), something else that is intolerable.
The first use of this could be unmanned probes - but a four year wait time for signals to travel means that it would be impossible controlling it, and would have to have it's own artificial inteligence.
Of course, if you just wanted to visit the Mars and breath its clean fresh air and gaze upon its deep green pastures then this...oh wait...Mars doesn't have that.
I think the best way to travel long distances is by using a stargate. Mondays on the sci-fi channel. -
Re:Ants
I know Argentine ants hitchiked on a ship from South American to other countries like United States. See http://www-biology.ucsd.edu/news/article_051500.h
t ml
"The tiny dark-brown and black ants, which are about two millimeters in length, are thought to have entered the United States aboard ships carrying coffee or sugar from Argentina during the 1890s, then expanded throughout California and the southern parts of the United States. In the Southeast and much of the South, their proliferation is now limited to some extent by the introduction of fire ants." -
Re:Internet bullshit pseudoscience
Lay off the Doctor! Just because he knew how to write for an audience doesn't mean he is comparable to some unhinged psuedoscience wackjob:
http://orpheus.ucsd.edu/speccoll/dspolitic/ -
Someone beat stanford to this
This must be old news to these guys http://www-cse.ucsd.edu/aboutcse/newstories/20030
1 24-games.html -
Similar to the video game course offered at UCSD
Except you get a good grade instead of a prize for creating a good game. There's nothing like 6 guys spending 10 weeks to develop a 3d multiplayer game. Tons of fun. Tons of sleepless hours in the lab. http://pisa.ucsd.edu/cse190/
-
Re:Negative Refraction
http://physics.ucsd.edu/~drs/left_home.htm
or search google for "metamaterials" -
Re:They've been aroundCheck out the description, and particularly the JPEG images, linked from this site: http://physics.ucsd.edu/lhmedia/whatis.html
The blue lines represent the path taken by light. The red lines represent the surface of the material.
The MPEGs might be worthwhile as well. I couldn't take the time to view them because of my dog-slow web access here at work.
And to clarify on the importance of these developments... No, left-handed materials are not really "new" in either theory or in practical use. What is new is materials that are left-handed for light in the visible spectrum. Recall that index of refraction is dependent on wavelength (or frequency, take your pick). To get left-handed material, you need two rare scenarios to occur at once: one electrical and one magnetic, and it has been more difficult to create this situation with some wavelengths (such as visible light) than with others (such as microwaves).
I believe they have taken to being called "metamaterials" because we need to "build" custom crystal structures tailored for our needs, and they don't tend to grow in "normal" ways.
-
Re:Your trouble is with editors at news sources
Amen. Just yesterday I saw a piece on BBC World News about vitamin D deficiency (sorry, the BBC News web link actually tells enough information to be useful). The TV spot didn't even tell how much vitamin D seems to cut the risk of certain cancers in half! By contrast, the UCSD press release had plenty of useful information. What irks me is that they still send you on a wild goose chase to find a summary written by the scientists. I think the problem is not only editors wanting tabloid content, but in these cases, a public relations department whose job is perceived as being to put the best possible spin on things for the organization. Regardless of the quality of the "reporting" by the PR department, the actual reporters are going to have to get more information, and the media contact is the PR person who wrote the article, not a scientist. The reporters also talk to someone else for a differing opinion and try to show the "debate" whether there is one or not. They may then find some expert in the subject who hasn't read the study, and it goes downhill from there. It's a bad game of telephone mixed up with putting someone on the spot about a paper they haven't seen: a recipe for disaster.
-
Re:Biggest useless (yet meaningful) number ever?
Yep. I remember reading a Number Theory book long ago that Skewe's number 10^10^10^34 was "the largest number which has ever served any definite purpose in mathematics", but apparently, things have changed since then. The largest meaningful (but useless, as you pointed out) number used is apparently Graham's Number, which has even been listed by the Guinness Book of World Records as such. Tetration is explained here, or quite a lot of notation is explained here.
The best page about large numbers, however, is clearly the one at MROB, beautifully written.
But the amusing thing about this Graham's Number is that it is an upper bound on some quantity, which experts believe is equal to 6. That's right, SIX. So it's not only the largest number ever used; it's also probably the worst upper-bound ever -
Re:Drugs are bad mmkay...
well, there's actually a large scientific backing to mixing senses, it's called synethesia, consider it mixed up wiring in neural circuitry. check out: http://psy.ucsd.edu/chip/pdf/SciAm_2003.pdf. pretty cool really...
-
Re:Temporary measure
Interesting, I'd have thought there were more area codes, but if you take all the foreign codes out of http://www.cs.ucsd.edu/users/bsy/area.html you get about 320 area codes left, and some of those are "overlay" codes, which means calling between them isn't long distance. (Of course, in rural areas, even calling within a particular area code could still be long distance, when I was a kid I lived in one such place, but this could reach all of the even medium-sized cities)
-
Re:The Dumbing-Down Of America, part XXVII
-
Re:Hear hear
Do you really want evidence, or are you just looking for an excuse to attack me because I falsified the "evidence" that you provided? I did mention a few things in previous posts, but I think you ignored them so that you could say that I didn't present any evidence.
Read some of the many resources at this site if you doubt that ID has scientific merit. And also, I still want to hear your defense of the chimp argument, or you can concede that it wasn't really a good argument and we can move on. If you don't defend it or toss it out, I'll just assume you'd rather attack me than stand behind your words, and our conversation will be over.
-
Re:Factor?
Presently we do not know of any methods to factor a number in polynomial time while we can create primes in polynomial time, but an algorithm may exist that can factor primes in polynomial time. If one is discovered, encryption as we know it today will be impossible...
Nonsense. First of all, factoring per se only affects RSA encryption.
It's likely that a major advance in factoring would also affect the security of Diffie-Hellman key exchange and ElGamal encryption, but it's not an absolute certainty. These are based on discrete logarithms, and while finding discrete logarithms hasn't (TTBOMK) been proven equivalent to factoring, current factoring methods can also be applied to finding discrete logarithms, and there's some theoretical basis for assuming any future ones will as well. For example, here is a paper discussing the relationship between the two (warning: quite mathematical).
Those aren't the only methods of public-key cryptography though -- for example, elliptic curve cryptography might well be unaffected. In particular, both factoring and discrete logarithms display a property called "smoothness" (about which, see the paper above) which is necessary for the various "sieve"-type algorithms to operate correctly. At least so far, nobody has shown that elliptic curves have the property of smoothness (though various mathematicians argue both for and against its likelihood). As a consequence, breaking elliptic curve cryptogaphy uses entirely different methods, and there's little reason to believe that even a major advance in factoring would necessarily have any real effect on elliptical curve cryptography at all.
Then we come to all the symmetric ciphers -- DES, 3DES, IDEA, FEAL, RC4, RC5, RC6, AES, and many, many more. The vast majority of these have little or nothing to do with prime numbers, and even the most amazing advance in factoring would be unlikely to affect any of them at all. The applicable area of mathematics is entirely different -- most symmetric algorithms are based in number theory while most symmetric algorithms are based on group theory.
Since "quantum" has been thrown around a bit, I'll try to add a bit of clarification on that subject as well. Unfortunately, there are two rather different sorts of things related to cryptography that use quantum in their names. As has been noted elsethread, what's generally called quantum cryptography would more accurately be called quantum key exchange. It's basically just a way of sendin some bits over a fiber optic cable, and the receiver can detect whether anybody has tapped into the line to see what was sent.
The second "quantum" thing is quantum computers. The Shor algorithm (due to Peter Shor) does factoring on a quantum computer in polynomial time, which is more or less the holy grail in fast factoring. The problem is that at least at the present time, there's no such thing as a practical quantum computer -- the most "powerful" quantum computers to date haven't even been sufficiently capable to replace a pocket calculator. Worse, the methods used to create quantum computers so far are widely believed to be unscalable, so there's no certainty that quantum computers can ever become practical -- though there's a great deal of research being devoted to the subject, and there's certainly a possibilty that they might.
If quantum computers were to become practical, they would also affect symmetric ciphers. Basically, searching for the key of a symmetric cipher is normally proportional to the size of the key space. For a quantum computer, the search is proportional to the square root of the size of the key space instead.
This, however, has less effect that most people realize. In particular, the size of the key space is squared by doubling the size of the key. In point of fact, many (if not most) current symmetric ciphers already use keys large enough to render attacks by quantum computers
-
They've been doig this at UCSD for years...
Of course this makes headlines when MIT does it, but everyone ignores that UC San Diego began something similar years ago. They gave out PDAs (crappy ones, mind you... HP Jornada) to a few thousand students so that they could see each other as long as they were within range of the access points. I have to admit, I never used it because the PDA they gave me lasted about 30 minutes on a full battery charge, but it looked pretty interesting when I was a freshman there. I'm sure they're not the only other campus to have tried this, either. http://activecampus.ucsd.edu/
-
Re:Already available..
> There should be some standard interchange format for the FPGA data. gcc should be able to take some C code an output FPGA intermediate programming data from it.
Smile! This stuff already exists for years:
You just have to build a library that
- shoves "compiled" logic chunks to the chip
- uses the FPGA-board's upload functionality as a pluggable driver
- does the resource management.
Everything else is already there.
- You can get some FPGA developer board to develop and test your library:
- You can use SPARK to compile your C-code to VHDL.
- I guess VHDL can be uploaded directly to the FPGA. If not maybe stuff like gEDA or similar stuff for VHDL helps...
- I am a total n00b in things of hardware design, but i found this in 1-2 hous of investigation and reading via wikipeda.
The problem is that FPGA-boards are pretty expensive... (The least expensive i found was some 66MHz devboard for 150$. The most expensive had 500MHz and a price tag of ~7000$!! [including a ton of golden analog contacts and stuff
-
what photorealism?The trouble with "photorealistic" games is that they really aren't actually photorealistic at all, because they don't accont for indirect illumination. Games keep adding more and more triangles, yet that approach has reached a point of diminishing returns. Graphics cards have become faster and more programmable, but they're using the wrong algorithms. Should we be surprised when gamers complain that new games are starting to look more and more like old games?
Unfortunately, the alternatives have historically been computationally too difficult for real time use (though one could make the case that ray tracing is actually faster than rasterization once one passes a certain threshold of scene complexity), though that may change as hardware gets faster and algorithms get better.
Here are some animations of the sorts of effects that should be present in games if they are to truly be called "photorealistic" (and no, I don't know how long it took to render those).
Of course, this is orthogonal to the argument of whether games should be photorealistic at all, but I suspect a non-photorealistic renderer based on ray tracing and photon mapping could still look much better in general than a non-photorealistic renderer based on triangle rasterization (assuming you have enough cpu power to do the former).
-
Applications are already using this
There is a short list of applications that are already using this. Most notably Skyhook Wireless, Meetro and Active Campus.
-
University of California locks away public domainThe source is my personal experience with the UCSD, UCI, and UCLA libraries. I assume the other UCs have the same or similar policy against digitizing books. Gutenburg is not a corporation, it's private individuals (volunteers). It's usually one guy (or gal) with a scanner, OCR software, and a little bit of time to proofread.
would not surprise me to learn that a campus counsel or some such wouldn't let a library give away rights to content that UC held the rights to (like a library's special collections holdings)
So in other words, the public domain is locked away. The PD consists of OLD books, which are largely in special collections.
Here's some policies I digged up. It's worse than the policy though. They say write a letter explaining your needs and they ignore you.
- UC Irvine: royalty fees required for PD books and other nonsense
- UC San Diego: royalty fees required for PD books and other nonsense
- UC San Diego: 20-page limit policy and no scanning policy
- Can't find UCLA's policies online, but they also prohibit scanning and wanted a $200/page royality!
-
University of California locks away public domainThe source is my personal experience with the UCSD, UCI, and UCLA libraries. I assume the other UCs have the same or similar policy against digitizing books. Gutenburg is not a corporation, it's private individuals (volunteers). It's usually one guy (or gal) with a scanner, OCR software, and a little bit of time to proofread.
would not surprise me to learn that a campus counsel or some such wouldn't let a library give away rights to content that UC held the rights to (like a library's special collections holdings)
So in other words, the public domain is locked away. The PD consists of OLD books, which are largely in special collections.
Here's some policies I digged up. It's worse than the policy though. They say write a letter explaining your needs and they ignore you.
- UC Irvine: royalty fees required for PD books and other nonsense
- UC San Diego: royalty fees required for PD books and other nonsense
- UC San Diego: 20-page limit policy and no scanning policy
- Can't find UCLA's policies online, but they also prohibit scanning and wanted a $200/page royality!
-
Re:Moderating"Not one person said they liked using Windows". Just so you can stop using that line, I would like to say that I like using Windows.
Well, can you prove that you're a person?
-
Image for everyone to use!
Raster: http://www.code.cx/what-have.png
Vector: http://openclipart.org/clipart/unsorted/what_have_ you_done_dani_.svg
Props to Dr. Seuss for providing the inspriation.
http://orpheus.ucsd.edu/speccoll/dspolitic/pm/1942 /20305cs.jpg
{kind=link}
{kind=link}
{kind=link}
{kind=link}