 Slashdot Mirror
Slashdot Mirror
Domain: genome.gov
Stories and comments across the archive that link to genome.gov.
Comments · 60
-
Re:False positives
Actually those markers always have strong overlaps with one out of random 30 people on the planet.
If you find a match, there are literally something like 240,000,000 potential matches. Of course you can filter them out by match of race, blood type etc and narrow it to perhaps 300, but thats it.
Keep in mind humans and chimps are 96% identically: https://www.genome.gov/1551509...Basing evidence or proof on "high variable" random DNA is possible, if you have 3 possible culprits, and one of the three has a matching DNA
-
Already law for genetic discrimination
These databases need to be deleted too. The privacy violates are incredible.
What do you do when an insurance company notices that someone in your family has a hereditary disease and decides to jack up your premiums? We need strong laws to protect DNA data and prevent that kind of abuse.
We already have a law, it's called Genetic Information Nondiscrimination Act of 2008. The only catch, congress didnt put any protection for life insurance, disability insurance, and long-term care insurance.
-
Re:Behind what?
>Want to know what's leaving us behind?
>Money spent on higher education and grants.Yeah and doing research on what? Bioengineering is one of the domain with the most fabulous progress of the last decades. We have got a choice :
- let the nature do as she wants: anything!
- or to be human, and to control our environment. GMO, including humans, is part of that.The choice is the same as being an asshole (NIMBY syndrome, probably a genetic syndrome) and reasonable.
-
Re:Monkey to God in under 6 seconds. . .
Your link doesn't really back up your claim. .
Someone who has learned enough economics to use terms like "diminishing return" should also have been taught that knowledge capital does not apply. Does lighting someone else's candle diminish your own lit candle? It is as if you are saying that water boils at 100 C, so evaporation can only occur at 100 C. I could go to the trouble to explain/prove everything myself, or I could just point you to the textbook ("Authority") saying otherwise for brevity. At the end of the day, the onerous is on you to prove that generally accepted facts and theories are wrong.
If you could go back in time and ask people in the early 20th century what the early 21st century would be like I think they'd be surprised not by all of the technology that looks like magic to them, but with how little has really changed.
Thanks, this goes back to my point of, "If they are so advanced, then where are their giant horses!?" Technological advances have occurred in the most important areas for them to occur. That people have failed to realize where these were going to be in the past is merely a testament of their limited knowledge/foresight and says nothing of the technological progress that has taken place. Your comment here says more about yourself than anything else.
Some technologies (like nuclear) are extremely centralized, government regulated, and monopolistic. Then there are technologies that are on the opposite spectrum. The latter is improving exponentially . -
Re:How do they define GM?
His point doesn't address what the OP said.
He is making a line you can't cross in the taxological tree because reasons. Why can we manipulate the genes in species but not Kingdom? Oh, I know... God did it, right? That was the whole point of OP when he said: "It's a very hazy line there... is it just stuff made by Monsanto or *all* GM stuff, like... say just about *all* corn that's grown on the planet?" There are concerns with Monsanto, (see below in thread) that seem legitimate. But to label "ALL GM is bad" is proclaiming ignorance. Just like the GP misunderstanding what a species is.
"DNA that's totally foreign." What is foreign? When do you define DNA as foreign? How far up the taxological tree do you have go when it becomes foreign? how far back in evolutionary history do you have to go? How do you define that line in taxonomy? As if our DNA does not have the remnants of endogenous retroviruses, or the 60% of DNA we share with a banana plant.
The misinformed nature of his post is modded (as of now) +4 informative. It just shows you that the anti-GMO camp is mostly uninformed. If you want to talk about specific ecological effects, or copyright, or monopoly on agriculture then I am all ears. But to say "this potato plant with a specific jellyfish DNA sequence is bad" is just as dumb as saying a tangelo is not GMO. It is an arbitrary line that he created to suit his political compass.
-
Re:Fraudulent herbal supplements?
You are aware that you can pay people with specialized skills who have specialized equipment to do things for you, right? And you'll be able to do it yourself soon enough. (Puts Moore's Law to shame)
-
Re:Fraudulent herbal supplements?
You are aware that you can pay people with specialized skills who have specialized equipment to do things for you, right? And you'll be able to do it yourself soon enough. (Puts Moore's Law to shame)
-
Re:What's odd is that
There is no such evidence
Yes, actually, there is.
http://www.livescience.com/430...
http://www.genome.gov/27556491under same circumstances in our days the death toll would be the same
No, the existence of antibiotics would change the outcome dramatically.
And as that IF does not exist,
Your unsourced, un-cited assertions do not eliminate the data suggesting that some heritable resistance to Y pestis exists, or that the Black Plague outbreaks in the 1300's had noticeable effects on the genetic makeup of the population of Europe.
-
All the mammals have very similar DNA.
This is no big surprise. All the mammals have surprisingly similar DNA.
-
Re: finds little...
We know that the most important distinctions between humans and other animals are in RNA genes, that most of the genome is transcribed as RNA genes and that the brain modifies itself using them and that malfunctions in them cause disease. This study ignored RNA genes entirely, AFAICT. Its mindset is about ten years out of date and simply reaffirms what everyone already assumed: proteins aren't everything. Intelligence probably still has a significant genetic component, this study just looks in the wrong place. (Psst: SNP studies are snake oil in almost all unsolved diseases.)
-
Re:It's a gene
Someone in molecular and computational biology (like me) would also call the controlling element a gene. Science journalism is far too often full of such odd definitions and misunderstandings.
The "gene encodes a protein" idea still seems quite common in educational efforts that at least *ought* to have real scientists behind them. See, for example, page 4 of http://www.genome.gov/Pages/Ed.... One who monitors the science news also will frequently encounter press releases like "We sequenced organism X's genome and it contains (pick a number) genes, compared to the (human gene count du jour)." Presumably molecular biologists provided these numbers, but they appear to refer to protein coding sequences only. Oh, well, it's no sillier than counting galaxies (I'm an astrophysicist, and we pretend to do that frequently).
-
Re:$99 vs. $8000
Missing link here.
http://www.genome.gov/images/content/cost_per_genome_apr.jpg
-
Re:Python
I have a friend who works for a company that does gene sequencing and other genetic research and, from what he's told me, the whole industry uses mostly python.
I work in a Gene Sequencing company and the current debate is: Python vs Clojure vs Scala:
Python unquestionably has the best bioinformatics support. Period. No debate. But the lack of language features has irked many programmers, myself included.
Clojure is gaining attention as a pure functional language with an R-like environment for large scale machine learning tasks. (Bioinformatics is machine learning applied to biomedicine). This makes porting Matlab/Octave/R code much easier, or so the thinking goes.
Scala has its backers. Java is nearly invisible in the bioinformatics world, but the JVM is hard to ignore. Scala has excellent support for Machine Learning but terrible support for "biological and medical applications". Hat tip: you can hire scala programmers or teach Scala to Java programmers in short time
BIG DATA is a bigger problem for us today than previously:
"genome wide arrays" used to mean all ~25,000 gene transcripts or 500,000 single DNA changes (SNP).
These revolutionary technologies are already considered "old".
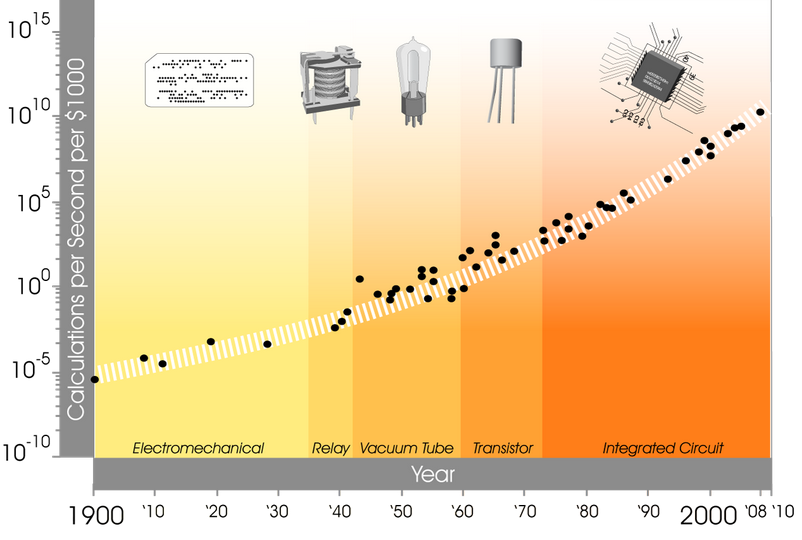
The rise in performance and drop of cost of DNA sequencing is much faster than the commodification of CPUs during the internet dot-com race . -
Re:How could evolution work?
So if an animal with 22 mutated and was accidentally born with 23, it could not breed with it's brethren. Unless another animal was similarly mutated to have 23 chromosomes. What is the likelihood that two mutated animals would even live in close enough proximity to one another to successfully mate?
That's NOT how it works. Genes mutate, not chromosome counts. And chromosome counts does not mean you can't produce hybrids with different chromosome counts.
http://en.wikipedia.org/wiki/Mule
A mule is the offspring of a male donkey and a female horse.[1] Horses and donkeys are different species, with different numbers of chromosomes. Of the two F1 hybrids between these two species, a mule is easier to obtain than a hinny (the offspring of a male horse and a female donkey).
Look up interbreeding in canine family. Not all can interbreed with each other. A coyote can interbreed with some wolfs, but not others. Yet those wolfs can interbreed with each other.
http://en.wikipedia.org/wiki/Coywolf
http://en.wikipedia.org/wiki/List_of_organisms_by_chromosome_count
http://en.wikipedia.org/wiki/F1_hybrid
PS. Even humans have different chromosome counts and they are not "different species".
http://www.genome.gov/11508982
lots of "abnormalities". That's how evolution works. "Abnormalities" combined with selection pressure. If there is no selection pressure (ie. death before reproduction), abnormalities just stick around. That's how evolution works. If you want to know, read books. Some are free now, like The Origin of Species.
-
Re:Cost hasn't been dropping for a long time
What we realized is that genome sequencing technology is plummeting in cost and increasing in speed independent of our competition. Today, companies can do this for less than $5,000 per genome, in a few days or less - and are moving quickly towards the goals we set for the prize.
If you look at the graphs at https://www.genome.gov/sequencingcosts/ what it actually shows is that after plummeting faster than Moore's Law for 3 years between 2008 and 2011, the cost has been basically flat for the past year and a half, probably due to lack of competition.
Or it could be simple supply and demand and the market, so to speak, has reached equilibrium. With cuts in federal research dollars, manufacturers of sequencers can either lower the price of their wares or leave the price alone and not sell any. It's basic econ 101.
-
Re:Cancelled because winning was a possibility?
"You forgot the part where only two companies entered. Sure it's a race, but it's not much of one."
Watching the contest in progress would not be a spectator sport. The goal is not a spectacular race. The objective of the XPrize is to achieve a spectacular goal, by providing a financial incentive. For that reason, two contestants is enough to provide a drive to be first. After all, in XPrizes every contestant other than the winner is cannon fodder (contestant who ends up with nothing).
By canceling the prize, the goal will be reached later. Hurray.
Bert
From a post by arobatino above:
If you look at the graphs at https://www.genome.gov/sequencingcosts/ [genome.gov] what it actually shows is that after plummeting faster than Moore's Law for 3 years between 2008 and 2011, the cost has been basically flat for the past year and a half, probably due to lack of competition [blogspot.com]. -
Cost hasn't been dropping for a long time
What we realized is that genome sequencing technology is plummeting in cost and increasing in speed independent of our competition. Today, companies can do this for less than $5,000 per genome, in a few days or less - and are moving quickly towards the goals we set for the prize.
If you look at the graphs at https://www.genome.gov/sequencingcosts/ what it actually shows is that after plummeting faster than Moore's Law for 3 years between 2008 and 2011, the cost has been basically flat for the past year and a half, probably due to lack of competition.
-
Re:IonTorrent? LOL.
TFA was written based on an interview that took place in April of LAST YEAR.
It shows a graph indicating that cost is decreasing too fast that is also based on data ending at the beginning of last year. Conveniently before 2012 actually happened, where the cost sat completely flat for 12 months and even increased in Q4 as Illumina released new (more expensive) reagents.
(updated image:) http://www.genome.gov/images/content/cost_per_genome.jpg -
Re:Would Someone Explain This?
It sounds a little implausible, but perhaps I am unaware of the forensic issues. Due to massive improvements in DNA sequencing, it costs less than $10,000 to acquire a full genome (see https://www.genome.gov/sequencingcosts/ ). So, back-of-the-envelope:
(a) $20k to acquire both genomes, plus
(b) some computational effort to identify interesting DNA polymorphisms ($0 - $1000 ???), plus
(c) PCR'ing out and sequencing of a region of the crime-scene DNA (cheap; less than $100).
So $22k, not counting labor costs?Not quite that easy. Since they are identical twins, you need to look for very low frequency mutations that are private to one twin or the other, meaning they occurred in cell lines after the embryos separated. In order to tell these low frequency, new mutations apart from sequencing errors, you would have to sequence the genomes to a very very high level of coverage. This means you would essentially have to sequence the genomes many times over. The quoted cost seen for genome sequencing is sequencing the genome enough times to identify most common frequency mutations.
Secondly, PCRing to increase the concentration of the DNA from the crime scene causes some areas to be overrepresented from the others and introduces new mutations in the process. So, it is not robust if your goal is to identify copy number variants or to identify very rare, private mutations.
Computational effort to identify new mutations and copy number variation is not as easy or standardized as finding known mutations. Secondly, the expert time involved in explaining all of the sequencing and new procedures to a jury/court is probably very very expensive.
-
Re:Would Someone Explain This?
It sounds a little implausible, but perhaps I am unaware of the forensic issues. Due to massive improvements in DNA sequencing, it costs less than $10,000 to acquire a full genome (see https://www.genome.gov/sequencingcosts/ ). So, back-of-the-envelope:
(a) $20k to acquire both genomes, plus
(b) some computational effort to identify interesting DNA polymorphisms ($0 - $1000 ???), plus
(c) PCR'ing out and sequencing of a region of the crime-scene DNA (cheap; less than $100).
So $22k, not counting labor costs?
IAAMB (I am a molecular biologist), but not a forensic one. Maybe it just doesn't work that way. Anyone have other information? -
Re:Epigenetics
This keeps on getting repeated so as a biology grad student I feel the obligation to inform everyone: yes, epigenetics is very important and makes up much of the story, but while a lot about it is still unknown, we have just as many tools to tackle it as we do with genomic DNA. We can sequence the epigenome (both histone marks and DNA CpG methylation), the transcriptome, the translatome, and the proteome (by mass spec, though not de novo) - almost any "ome" that involves any combination of nucleic acids and proteins can be probably sequenced and profiled by technology that we have today. The only thing that we probably can't easily do yet is metabolomics, because small molecules are not built out of well-understood monomeric units, but I bet there are tens if not hundreds of labs around the world working on this kind of technology as we speak.
My point is, the explosion in sequencing technology that have occurred in the 10 years since the completion of the human genome have put us solidly in the "post-genomics" era. The technologies to find the needle in the haystack exist in the here and now - the only real constraints are time, manpower (brainpower?), sample availability, and (to some extent) cost, in the sense that you need to not be in the bottom 30% of labs in terms of your funding situation in order to have enough money to be able to use these technologies. Brooke is human so there will be limitations in terms of what kinds of samples we can take without harming her health, but the people working on this will be able learn a lot from her genome (and her epigenome, transcriptome, and so on and so forth) and then they will be able to find those mutant candidate genes and make mouse or Drosophila models so that we can get a really detailed understanding of what is going on at the mechanistic level, and in those model organisms we can then whatever we want in order to get whatever types of data we need.
A reference for those who haven't seen it yet: http://www.genome.gov/sequencingcosts/
-
A bit confused...
Please don't mistake protein sequencing and DNA sequencing as equivalents.
This MinION is designed to do DNA sequencing and protein sensing, which is not quite as interesting, since most people doing DNA sequencing are used to have access to high output sequencers, which are faster and reusable.
Besides, this item only managed to read a DNA strand of 48500 bp (for reference, human genome has around 6 billion) so it won't be of much use for humans.About the price :
http://www.genome.gov/sequencingcosts/
gives us a cost per raw megabase of 0.1$
so I don't see why I would like to pay 900$ for something that cant even squence one million base...Let's wait and see.
-
Sequencing of tumors
Actually, probably the best use of these machines will be to sequence tumor DNA to determine the best treatment option.
For example, is your melanoma response to RAF inhibitors?
Such work is going on at the NIH NGS paper (PDF) and, in this case, the more data to correlate responses with, the better.
Of course, not really something for your average doctor. -
Re:And does it really cost $1000 to do a sequencin
Just curious since I remember reading, admittedly on a blog, somebody take that "It takes X dollars to do 1 MRI" statement
The DNA sequencing table shows a precipitous drop in costs down below $10,000 and under
-
Re:Wrong problem
Well, as others have said, this is kind of correct. After sequencing, the raw reads (short sequences of DNA) are assembled into either transcripts of genome fragments (usually called contigs). This leads to a great reduction in the amount of data, but there is a lot of concern by scientists over whether or not to save all the raw data for future work. My take is that unless the sample is impossible to collect DNA/RNA from again, then toss it and assume that the sequencing technology will be better/faster/cheaper/longer in the future.
I'm actually involved with a large US National Science Foundation project to help build the cyberinfrastructure to help handle these data and analyses: the iPlant Collaborative: http://iplantcollaborative.org./ In addition, I maintain a set of web-based software for comparative genomics: CoGe, http://genomevolution.org./ From the standpoint of genomes, I adopted the philosophy of building a system that can easily accommodate new versions of existing genomes and new genomes. Thus, as new data becomes available, they get quickly loaded into the system and made available for analysis by any of the existing tools or compared to any of the already loaded genomes. So far, the system has scaled quite well and it is storing over 16,000 genomes from over 12,500 organisms. While the science is a lot of fun (sort of like the ultimate video game except no one knows the rules and there are no pre-built user interfaces), it is awesome to see how quickly the number of sequenced genomes has grown over such a short period of time. This is driven by how cheap the technology has become to use and the quantity of data that can be produced. For those interested, the National Human Genome Research Institute keeps track of this and has some very informative graphs: http://www.genome.gov/SequencingCosts/.
While it has also been said, the analyses and interpretation of these data is extremely rate limiting. Lots of opportunity for folks with programming, algorithm, data visualization, web, and user interface experience. -
Re:Moore's Law of DNAI don't argue that the cost-per-base of sequence is dropping dramatically - but comparing the output of an Illumina sequencer (the tens-of-thousands of dollars pricepoint) to the Human Genome Project is misleading. The reason the HGP cost so much is the quality of the reference sequence they produced - the so-called Bermuda standard, of one error in 10,000 bases. The HGP researchers assembled all those individual sequence reads into an almost unbroken reference of astounding quality and utility.
In comparison, the sequence data people are producing today is crap. The individual reads are 30-80 base pairs and get put together into contiguous runs of only several thousand bases of length, on average. This is good for some kinds of work, but it doesn't give nearly the same picture of the genome that made the original human genome sequence such a masterpiece.
(I'm a genomics grad student. Can you tell?)
-
Re:scary part of TFA
People in the sequencing biz talk about the "thousand dollar genome" as kind of the magic number, and the consensus is that we can expect to get there in five years or so. At that point, yes, it will be a routine part of everyone's medical record. As for discrimination, the best we can do is guard against it; the Genetic Information Nondiscrimination Act (GINA) is a very good start. There is no way in hell that we are going to turn our backs on the enormous medical potential of cheap, nearly universal sequencing because of fears cobbled together -- as most anti-genetics rants seem to be -- out of massive ignorance and half-remembered ideas picked up from Frankenstein, Jurassic Park, and Gattaca.
-
Re:Can of Worms?
Genetic discrimination is a worry, of course, but the risk of it is far outweighed by the benefits which understanding the role of genetics in human health offers. And the Genetic Information Nondiscrimination Act (GINA) is actually a pretty good law.
As for the medical usefulness of genetics
-
Re:GATTACA
http://www.genome.gov/10002328
What's the Genetic Information Nondiscrimination Act (GINA)?
The Genetic Information Nondiscrimination Act of 2008, also referred to as GINA, is a new federal law that protects Americans from being treated unfairly because of differences in their DNA that may affect their health. The new law prevents discrimination from health insurers and employers. The President signed the act into federal law on May 21, 2008. The parts of the law relating to health insurers will take effect by May 2009, and those relating to employers will take effect by November 2009.
Their logo even has "GATTACA" in it.
-
Re:Damned sure glad...
"This is why we passed GINA: http://www.genome.gov/24519851"
I'm just waiting for the Commonwealth of Virginia to pass their version.
-
Re:Damned sure glad...
This is why we passed GINA: http://www.genome.gov/24519851
-
Re:The Good, the Bad, the Ugly......except that congress passed a law making this illegal?
-
Illegal to Discriminate
As of 2008, it is illegal for insurance companies to require any information about a DNA sample.
Genetic Information Nondiscrimination Act
http://www.genome.gov/10002328
One of the last things Bush did in Office.
-
Re:ur doin it rong
Genome wide association studies. http://www.genome.gov/20019523
-
Re:Data Control
It won't be long before we're able to identify all kinds of disorders and diseases with a simple genetic screening. Then we just call having a 90% chance to develop cancer a pre-existing condition, and you're screwed.
There is a law against that that just went into effect.
Also, people don't actually have that many lethal genes. There's the whole natural selection thing going on.
-
Re:Data Control
That's why the US has GINA (Genetic Information Nondiscrimination Act (GINA) of 2008).
Whether it'll actually work is a separate issue. One of the points of this project is that trying to keep your genetic information private is a losing battle and that it might be better/neutral to just be open about it.
-
Massive loophole
As the genome gets further and further mapped, expect more and more people to be "uninsurable at any price".
Discrimination based on genetics is already outlawed by the Genetic Information Nondiscrimination Act.
Prove that's the reason they turned you down?
-
Re:yet another argument for universal health care.
As the genome gets further and further mapped, expect more and more people to be "uninsurable at any price".
Discrimination based on genetics is already outlawed by the Genetic Information Nondiscrimination Act.
How about a better one.. what about the fact men pay about 25% more than women for health, life, and auto?
Funny how some forms of discrimination are allowed, but not based on genetic tests.. OH WAIT, IT IS ALLOWED, they can examine your records, determine tests showed genetic predisposition, deny coverage.
-
Re:yet another argument for universal health care.
As the genome gets further and further mapped, expect more and more people to be "uninsurable at any price".
Discrimination based on genetics is already outlawed by the Genetic Information Nondiscrimination Act.
-
Re:Id venture
"There is no genetic rights. Businesses can exclude you from working for them due to it. Health insurance can disclaim all the "bad gene" illnesses, that is if they accept you at all. The government can pidgeonhole you in some god-awful plan in which you cannot escape."
Not (legally) in the US, because of the Genetic Information Nondiscrimination Act. (http://www.genome.gov/24519851)
-
Re:I'd do this in a second
Or stay in the US where it is already illegal for employers and insurers to discriminate based on genetic information. Genetic Information Nondiscrimination Act
-
Re:I'd do this in a second
The Genetic Information Nondiscrimination Act makes that illegal.
-
Re:The good doctor was a vicar instead
'He just showed them why it is not such a good idea to put a religious person at the head of a science organisation.'
What, you mean like Francis Collins?:
http://www.genome.gov/10001018
Dawkins isn't a big fan of his views either:
http://www.time.com/time/printout/0,8816,1555132,00.html
but apparently that whole 'human genome project' thing turned out to be quite successful...
-
Re:Important caveats
Fortunately not, if you live in the US.
-
Re:Are these simple molecules?
Simple and complex is somewhat in the eye of the beholder. I'm a biochemist and have primarily worked on protein structure and enzymology. To me, anything under 1,000 Da is small (and I suppose it follows, simple). My brother however has an extensive background in physical chemistry and modeling compounds in excruciating detail like how a "big" (complex) molecule like say ethanol (46 Da) interacts with a catalytic substrate. His concept of big and my concept of small as far as chemistry goes don't even overlap!
Another thing that you might find interesting is that DNA and RNA are arguably really simple molecules. A sugar group, some phosphates, and four different bases that just repeat. It was actually a major debate into the 1950's as to whether protein or DNA was the true genetic material. The point against DNA at the time was it's simplicity! However two experiments put that idea to rest: the Avery, MacLeod and McCarty experiment put forth good evidence in favor of DNA, but it wasn't until 1952 that just about all the "DNA's too simple" skeptics conceded with the Hershey-Chase experiment. -
Re:Insurance implications?
Don't trust everything your professors (or lawyers) tell you.
A genetic predisposition for a disease in a currently healthy individual is not the same as having the disease. According to HIPAA, genetic information in the absence of a current diagnosis of illness does not constitute a pre-existing condition.
But HIPAA is just the beginning of genetic information protection. The real deal is something called GINA: Genetic Information Nondiscrimination Act (GINA), which recently passed in the U.S. Congress and is pending in the Senate. President Bush has openly supported this bill. So it has some decent momentum.
Further reading: Navigenics provides some good resources about legal rights regarding the use of your genetic information, and there was a good article in the Boston Globe on this in Sep 2007.
-
Re:you've never met religous engineers?
You had better mention that to Francis S. Collins, M.D., Ph.D. Director, National Human Genome Research Institute who is also a christian.
-
Re:Insurance
Suppose there's a disease for which there is a genetic test, but also good preventative care options. Ideally, you'd want to take the test, find out that you're at risk, and have the insurance company pay for the prevantative care. In an ideal world, that's what they would want too -- the preventative care would cost them less than paying if you actually did get sick.
I disagree.
Suppose the insurance company gets the results of the test. Then the company could just drop coverage altogether, so that they have to pay neither the preventive care cost, nor the cost of the disease.
Suppose the insurance company does NOT get the results of the test. Then the company could just drop coverage as soon as the cost of the disease becomes apparent.
Dropping coverage could also involve increasing premiums to an unaffordable rate, thus having the same effect.
Relatedly, the House passed the Genetic Information Nondiscrimination Act of 2007 (H.R. 493) by 420-3. The three were Republicans: Flake (AZ), Paul (TX), and Royce (CA). Well done, nutjobs. The Senate has yet to pass its version (S.358).
In any case, since the bill is not yet law, there may be nothing stopping insurance companies from discriminating against your genetic makeup.
--Rob
-
Re:Not yetMy only argument is Genetic discrimination. Also, a lot more information can be found here.
No one gets to choose their genetic makeup, sex or race when they are born, so why discriminate people based on something which is out of their control?
Take a look at the Genetic Information Nondiscrimination Act of 2007:The Genetic Nondiscrimination Act of 2007 (GINA) was passed in the U.S. House of Representatives, by a vote of 420-3. The act will protect individuals against discrimination based on their genetic information when it comes to health insurance and employment. These protections are intended to encourage Americans to take advantage of genetic testing as part of their medical care.
-
Re:Not yetMy only argument is Genetic discrimination. Also, a lot more information can be found here.
No one gets to choose their genetic makeup, sex or race when they are born, so why discriminate people based on something which is out of their control?
Take a look at the Genetic Information Nondiscrimination Act of 2007:The Genetic Nondiscrimination Act of 2007 (GINA) was passed in the U.S. House of Representatives, by a vote of 420-3. The act will protect individuals against discrimination based on their genetic information when it comes to health insurance and employment. These protections are intended to encourage Americans to take advantage of genetic testing as part of their medical care.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}