 Slashdot Mirror
Slashdot Mirror
Domain: twitter.com
Stories and comments across the archive that link to twitter.com.
Stories · 1,968
-
Why CSI: Cyber Matters
New submitter hypercard writes: CSI: Cyber has been the butt of many jokes in the infosec community since its inception. But in addition to facilitating lots of cyber bingo events and live tweets to call out technical errors, the show has real value in bringing awareness about infosec issues to the masses. Members of the Army Cyber Institute at West Point discuss the upside of CSI: Cyber in an article in the Cyber Defense Review. "Children all over the country have been inspired to be law enforcement agents by shows like Criminal Minds, NCIS, Bones, and CSI." One of CSI: Cyber's cast members, Shad Moss, has more followers than the entire top one thousand information security professionals on Twitter. -
SeaWorld and Others Discover That a Hashtag Can Become a Bashtag
HughPickens.com writes Alison Griswold writes that in an effort to improve its tanking image, SeaWorld launched a new advertising campaign this week to educate the public about its "leadership in the care of killer whales" and other work to protect whales in captivity and in the wild. As part of that head-on initiative, someone at SeaWorld decided to invite Twitter users to pose their questions to the company directly using the hashtag #AskSeaWorld. That was not a good idea as twitter users bashed Sea World relentlessly.. "As easy as it is to make fun of SeaWorld here, the real question is why any company still thinks hosting an open Twitter forum could be good for public relations," writes Griswold. "So maybe SeaWorld's social and PR folks just really have no idea what they're doing. Even so, you'd think they'd have learned from the corporate failures before them."
Let's review some of the times this has backfired, starting with the infamous McDonald's #McDStories Twitter campaign of January 2012. Rather than prompting customers to share their heart-warming McDonald's anecdotes, the hashtag gave critics a highly visible forum to share their top McDonald's horror stories. MacDonalds pulled the campaign within two hours but they discovered that crowd-sourced campaigns are hard to control. Three years later the #McDStories hashtag is still gathering comments. "Twitter Q&As are a terrible idea.," concludes Griswold. "A well-meaning hashtag gives critics an easy way to assemble and voice their complaints in a public forum. Why companies still try them is a great mystery. Maybe they'll all finally learn from SeaWorld and give this one horrible PR trick up for good." -
Github Under JS-Based "Greatfire" DDoS Attack, Allegedly From Chinese Government
An anonymous reader writes: During the past two days, popular code hosting site GitHub has been under a DDoS attack, which has led to intermittent service interruptions. As blogger Anthr@X reports from traceroute lists, the attack originated from MITM-modified JavaScript files for the Chinese company Baidu's user tracking code, changing the unencrypted content as it passed through the great firewall of China to request the URLs github.com/greatfire/ and github.com/cn-nytimes/. The Chinese government's dislike of widespread VPN usage may have caused it to arrange the attack, where only people accessing Baidu's services from outside the firewall would contribute to the DDoS. This wouldn't have been the first time China arranged this kind of "protest." -
A Bechdel Test For Programmers?
Nerval's Lobster writes In order for a movie or television show to pass the Bechdel Test (named after cartoonist and MacArthur genius Alison Bechdel), it must feature two female characters, have those two characters talk to one another, and have those characters talk to one another about something other than a man. A lot of movies and shows don't pass. How would programming culture fare if subjected to a similar test? One tech firm, 18F, decided to find out after seeing a tweet from Laurie Voss, CTO of npm, which explained the parameters of a modified Bechdel Test. According to Voss, a project that passes the test must feature at least one function written by a woman developer, that calls a function written by another woman developer. 'The conversation started with us quickly listing the projects that passed the Bechdel coding test, but then shifted after one of our devs then raised a good point,' read 18F's blog posting on the experiment. 'She said some of our projects had lots of female devs, but did not pass the test as defined.' For example, some custom languages don't have functions, which means a project built using those languages would fail even if written by women. Nonetheless, both startups and larger companies could find the modified Bechdel Test a useful tool for opening up a discussion about gender balance within engineering and development teams. -
A Sucker Is Optimized Every Minute
theodp writes Now that we have hard data on everything, observes the NY Times' Virginia Heffernan in A Sucker Is Optimized Every Minute, we no longer make decisions from our hearts, guts or principles. "The gut is dead," writes Heffernan. "Long live the data, turned out day and night by our myriad computers and smart devices. Not that we trust the data, as we once trusted our guts. Instead, we 'optimize' it. We optimize for it. We optimize with it." To win Presidential elections. To turn web pages into Googlebait. To sucker people into registering for websites. Of the soon-to-arrive Apple Watch, Heffernan notes: "After time keeping, the watch's chief feature is 'fitness tracking': It clocks and stores physiological data with the aim of getting you to observe and change your habits of sloth and gluttony. Evidently I wasn't the only one whose thoughts turned to 20th-century despotism: The entrepreneur Anil Dash quipped on Twitter, albeit stretching the truth, 'Not since I.B.M. sold mainframes to the Nazis has a high-tech company embraced medical data at this scale.'" -
Elon Musk Pledges To End "Range Anxiety" For Tesla Model S
An anonymous reader writes: Elon Musk has used his Twitter account to announce a press conference on Thursday which he claims will end "range anxiety" for Tesla's Model S sedan. Whatever change they're making will be implemented through an over-the-air software update to the cars, affecting the entire fleet. Range anxiety is the term for a fear that your vehicle won't have enough fuel/charge to reach its destination. It's a common reason for people to avoid buying electric cars, given the much smaller infrastructure build-out compared to gas stations. If Tesla is improving the Model S's range through a software update, then it likely involves optimizations to the battery and to the ways in which power is used. Tesla has also talked about developing a feature called "torque sleep," which puts one of the drive units to sleep while not needed. They say it can wake up and begin delivering torque again "so fast that the driver can't perceive it." -
Twitter Will Ban Revenge Porn and Non-consensual Nudes
AmiMoJo writes: Twitter has changed its rules to state it will forbid users from posting revenge porn and non-consensual nudes on its service. In the private information section of the site's policy list, the company added that users "may not post intimate photos or videos that were taken or distributed without the subject's consent." Twitter seemed to indicate that it would use some combination of automated and manual checks to decide whether a reported post is revenge porn or not before removing the post. "We will ask a reporting user to verify that he or she is the individual in question in content alleged to be violating our policy and to confirm that the photo or video in question was posted without consent." There will be an appeal process too.
In February, reddit made a similar rules change after the site was embroiled in controversy for allowing the posting of stolen nude celebrity photos in 2014. Banning "involuntary pornography," reddit urged victims to e-mail the site with details so administrators could remove the offending posts. -
Another Upscaled Console Game: Battlefield Hardline
jones_supa writes Video game developer Visceral Games has confirmed the actual resolution that the coming Battlefield Hardline will run on when it is launched on the Xbox One and on the PlayStation 4. An official message from the Twitter account of the studio explains that gamers will get a 720p resolution on the Microsoft console and Sony platform gamers will get the game running in 900p. 60 frames per second is promised for both consoles, but many fans are still expressing their disappointment that neither of the two versions will be able to properly deliver the native 1080p resolution of the consoles. When development started, Visceral Games and publisher Electronic Arts said they were aiming to use the power of the modern consoles to push the game engine as far as it would go, but they clearly couldn't fit that target without cutting corners. This is similar to what happened with Titanfall, which renders into an 1408x792 framebuffer on Xbox One. -
SpaceX Falcon 9 Launches Dual Satellite Mission
JoeSilva writes SpaceX successfully launched two satellites towards Geosynchronous Orbit. There's already a video of one deployment. Word is the launch went very smoothly and bodes well for their next launch in three weeks, as they work to fulfill what is now a very full launch manifest. In addition Elon had one more thing to share: "Upgrades in the works to allow landing for geo missions: thrust +15%, deep cryo oxygen, upper stage tank vol +10%." -
SpaceX Falcon 9 Launches Dual Satellite Mission
JoeSilva writes SpaceX successfully launched two satellites towards Geosynchronous Orbit. There's already a video of one deployment. Word is the launch went very smoothly and bodes well for their next launch in three weeks, as they work to fulfill what is now a very full launch manifest. In addition Elon had one more thing to share: "Upgrades in the works to allow landing for geo missions: thrust +15%, deep cryo oxygen, upper stage tank vol +10%." -
H-1B Visas Proving Lucrative For Engineers, Dev Leads
Nerval's Lobster (2598977) writes Ever wanted to know how much H-1B holders make per year? Developer Swizec Teller, who is about to apply for an H-1B visa, took data from the U.S. Department of Labor and visualized it in a series of graphs that break down H-1B salaries on a state-by-state basis. Teller found that the average engineer with an H-1B makes $87,000 a year, a good deal higher than developers ($74,000) and programmers ($61,000) with the same visa. ("Don't call yourself a programmer," he half-joked on Twitter.) Architects, consultants, managers, administrators, and leads with H-1Bs can likewise expect six-figure annual salaries, depending on the state and company. Teller's site is well worth checking out for the interactive graphs, which he built with React and D3.js. The debate over H-1Bs is an emotional one for many tech pros, and research into the visa's true impact on the U.S. labor market wasn't helped by the U.S. Department of Labor's recent decision to destroy H-1B records after five years. "These are the only publicly available records for researchers to analyze on the demand by employers for H-1B visas with detail information on work locations," Neil Ruiz, who researches visa issues for The Brookings Institution, told Computerworld after the new policy was announced in late 2014. -
Ten Lies T-Mobile Told Me About My Data Plan
reifman (786887) writes "Last June, my post "Yes, You Can Spend $750 in International Data Roaming in One Minute on AT&T" was slashdotted and this led to T-Mobile CEO John Legere tweeting 'how crappy @ATT is' and welcoming me to the fold. Unfortunately, now it's TMobile that's having trouble tracking data; it seems to be related to the rollout of their new DataStash promotion. Just like AT&T, they're blaming the customer. Here are the ten lies T-Mobile told me about my data usage today." -
In Space, a Laptop Doubles As a VR Headset
Nerval's Lobster writes: On Earth, the engineers and developers in charge of building the Oculus Rift and other virtual-reality headsets are concerned about weight: Who wants to strap on something so heavy it cricks their neck? But in space, weight isn't an issue, which is why an astronaut can strap a laptop to his head via a heavy and complicated-looking rig and use it as a virtual-reality device. NASA astronaut Terry Virts recently did just that to train himself in the use of SAFER (Simplified Aid for EVA Rescue), a jetpack worn during spacewalks. (In the movie Gravity, George Clooney's character uses a highly unrealistic version of SAFER to maneuver around a space shuttle.) -
Automakers Move Toward OTA Software Upgrades
Lucas123 writes: While some carmakers today offer over-the-air software upgrades to navigation maps and infotainment head units, Tesla became the first last week to perform a powertrain upgrade overnight. But as the industry begins adopting internal vehicle bus standards with greater bandwidth and more robust security, experts believe vehicle owners will no longer be required to visit dealerships or perform downloads to USB sticks. IHS predicts that in the next three to five years, most, if not all automakers, will offer fully fledged OTA software-enabled platforms that encompass upgrades to every vehicle system — from infotainment, safety, comfort, and powertrain. First, however, carmakers must deploy more open OS platforms, remove hardened firewalls between vehicle ECUs, and deploy networking topologies such as Ethernet, with proven security. -
Female-Run Companies Often do Better Than Male-Run Ones (Video)
Today's interviewee, Viktoria Tsukanov, is one of the executives at predictive marketing company Mintigo who did a study in January, 2015 that seemed to show that large companies with female CEOs "achieve up to 18% higher revenue per employee than male CEOs." The study, titled "She’s the CEO and She’s Sensational," used financial data Mintigo collected on 20 million companies, and determined CEOs' genders by analyzing first names, so it was not subject to survey vagaries but was a straight data analysis job. Could this be a case of correlation and causation being unrelated? It's possible. It's also possible that the revenue per employee figures are affected by the fact that female CEOs are more common in healthcare and non-profit organizations, while men dominate manufacturing and construction -- and, as Viktoria pointed out in a blog post headlined "Women Just Raised the Bar. Big Time." there may be other factors at work as well.
The "18% higher revenue" figure specifically applies to companies with more than 1000 workers, while companies with fewer workers may average more revenue per employee if they have male CEOs. Besides discussing the study itself, in our interview Viktoria talks about how male employees might want to alter (or not alter) their behavior if they find themselves working for a female boss for the first time. She also discusses challenges a woman might face if she is suddenly put in charge of a heavily male IT or programming staff. Other thoughts she shares have to do with finding mentors and dealing with negative people, both of which apply to people of all genders. Interesting food for thought all around. -
WA Bill Takes Aim at Boys' Dominance In Computer Classes
theodp writes Boys' over-representation in K-12 computer classes has perplexed educators for 30+ years. Now, following on the heels of Code.org's and Google's attempts to change the game with boys-don't-count gender-based CS teacher funding schemes, Washington State lawmakers have introduced House Bill 1813, legislation that requires schools seeking K-12 computer education funding to commit to preventing boys from ruling the computer class roost. Computer science and education grant recipients, HB 1813 explains, "must demonstrate engaged and committed leadership in support of introducing historically underrepresented students [including girls, low-income students, and minority students]" and "demonstrate a plan to engage historically underrepresented students with computer science." Calling it "a bold new bill that we hope more states will follow," corporate and tech billionaire-backed Code.org tweeted its support for the bill. -
Lizard Squad Hits Malaysia Airlines Website
An anonymous reader writes: Lizard Squad, the hacking collaborative that went after the PlayStation Network, Xbox Live, and the North Korean internet last year, has now targeted Malaysia Airlines with an attack. Bloomberg links to images of the hacks (including the rather heartless 404 jab on its home page) and columnist Adam Minter wonders why Malaysia Airlines, which has had so much bad press in the past 12 months, was worthy of Lizard Squad's ire. In apparent answer, @LizardMafia (the org's reputed Twitter handle) messaged Mr. Minter this morning: "More to come soon. Side Note: We're still organizing the @MAS email dump, stay tuned for that." -
Doxing Victim Zoe Quinn Launches Online "Anti-harassment Task Force"
AmiMoJo writes: On Friday, developer and doxing victim Zoe Quinn launched an online "anti-harassment task force" toolset, staffed by volunteers familiar with such attacks, to assist victims of a recent swell of "doxing" and "swatting" attacks. The Crash Override site, built by Quinn and game developer Alex Lifschitz, offers free services from "experts in information security, white hat hacking, PR, law enforcement, legal, threat monitoring, and counseling" for "victims of online mob harassment."
They have already managed to preemptively warn at least one victim of a swatting attempt in Enumclaw, Washington. As a result, the police department's head e-mailed the entire department to ask any police sent to the address in question to "knock with your hand, not your boot." -
NJ Museum Revives TIROS Satellite Dish After 40 Years
evanak writes TIROS was NASA's Television Infrared Observation Satellite. It launched in April 1960. One of the ground tracking stations was located at the U.S. Army's secret "Camps Evans" Signals Corps electronics R&D laboratory. That laboratory (originally a Marconi wireless telegraph lab) became the InfoAge Science Center in the 2000s. [Monday], after many years of restoration, InfoAge volunteers (led by Princeton U. professor Dan Marlowe) successfully received data from space. The dish is now operating for the first time in 40 years! The received data are in very raw form, but there is a clear peak riding on top of the noise background at 0.4 MHz (actually 1420.4 MHz), which is the well-known 21 cm radiation from the Milky Way. The dish was pointing south at an elevation of 45 degrees above the horizon. -
SpaceX Landing Attempt Video Released
An anonymous reader writes: Last week, SpaceX attempted to land a Falcon 9 rocket on an autonomous ocean platform after successfully launching supplies to the ISS. It didn't work, but Elon Musk said they were close. Now, an amazing video has been recovered from an onboard camera, and it shows just how close it was. You can see the rocket hitting the platform while descending at an angle, then breaking up. Musk said a few days ago that not only do they know what the problem was, but they've already solved it. The rocket's guiding fins require hydraulic fluid to operate. They had enough fluid to operate for 4 minutes, but ran out just prior to landing. Their next launch already carries 50% more hydraulic fluid, so it shouldn't be an issue next time. -
There's a Problem In the Silk Road Trial: the Jury Doesn't Get the Internet
sarahnaomi (3948215) writes "The trial began this week for Ross Ulbricht, the 30-year-old Texas man accused of being the mastermind behind the dark net drug market, Silk Road. But as the jury began hearing testimony in the case, it was clear the technological knowledge gap would impede the proceedings. Judge Katherine Forrest said right off the bat when the case began that "highly technical" issues must be made clear to the jury. "If I believe things are not understandable to the average juror, we will talk about what might be a reasonable way to proceed at that time," she said. After the first day of proceedings, Forrest told the prosecution to be more clear with explanations of concepts central to the case, noting she was unhappy with its "mumbo-jumbo" explanation of the anonymizing service Tor. She also requested all readings of chat transcripts include emoticons." -
Ammonia Leak Alarm On the ISS Forces Evacuation of US Side: Crew Safe
New submitter BabelBuilder writes: An alarm signaling a possible ammonia leak aboard the ISS this morning caused the crew to evacuate the U.S. side of the station. All crew aboard the station are safe. "Flight controllers in Mission Control at NASA's Johnson Space Center in Houston saw an increase in pressure in the station's water loop for thermal control system B then later saw a cabin pressure increase that could be indicative of an ammonia leak in the worst case scenario. Acting conservatively to protect for the worst case scenario, the crew was directed to isolate themselves in the Russian segment while the teams are evaluating the situation." They don't yet know whether it was caused by a faulty sensor, a problem in the relay box, or another malfunction. -
Gunmen Kill 12, Wound 7 At French Magazine HQ
An anonymous reader writes: A pair of gunmen have stormed the office of French satirical magazine Charlie Hebdo, killing 12 people and wounding seven more. The magazine had recently published a cartoon of ISIS leader Abu Bakr al-Baghdadi, and witnesses say the gunmen shouted, "we have avenged the Prophet Muhammad," before leaving. "Four of the magazine's well-known cartoonists, including its editor-in-chief Stephane Charbonnier were reported among those killed, as well as at least two police officers. Mr Charbonnier, 47, had received death threats in the past and was living under police protection." The attackers engaged police in a gunfire outside the building, then fled in a car. At the time of this writing, they are still at large. Currently, the BBC has the most information out of English news outlets. French speakers can consult the headline at Le Monde for more current news. -
Finnish Bank OP Under Persistent DDoS Attack
An anonymous reader writes The Finnish bank OP Pohjola Group has been a target of a dedicated DDoS attack for days. The attack, which investigators said was launched from both Finland and abroad, began on New Year's Eve. OP was forced to open a helpline for customers unable to confirm payments or transfer money because of jammed systems. On Saturday the firm said it would compensate people for any losses or late payment fees incurred as a result of attack. On Sunday morning the bank tweeted that its services were operating normally and even customers based outside Finland were able to access their accounts — and that it was still monitoring traffic carefully to try and ward off any renewed strikes. However, on Sunday afternoon further denial of service attacks took place delaying payments and preventing access to banking services for OP customers. A formal police complaint has been filed and OP says that KRP is looking into the case. -
Would Twitter Make President Obama 'Follow' the Tea Party If the Price Is Right?
theodp (442580) writes Giving others the impression that individuals support something that they actually don't could get you fined and placed under house arrest. But if you're Twitter, it could boost your bottom line. Gigaom's Carmel DeAmicis reports that brands pay Twitter to falsely appear in your following list, an advertising technique brought to light by William Shatner after he saw that 'MasterCard' appeared in his following list despite the fact that he didn't follow it. "By making it look like someone follows an account that they don't," writes DeAmicis, "it sends a false signal that said user cares about that brand. Although the brands are marked as 'promoted,' it's not necessarily clear that the user in question doesn't actually follow the brand. There's ethical considerations to be had. Hypothetical examples: What if you're vegan and don't want people to think you're following Burger King? Or you're the CEO of Visa and don't want people thinking you're following MasterCard? Or you're a pro-life activist and don't want people thinking you're following Planned Parenthood?" Or, if you're @BarackObama and don't want people to think you're following @TPPatriots! -
Would Twitter Make President Obama 'Follow' the Tea Party If the Price Is Right?
theodp (442580) writes Giving others the impression that individuals support something that they actually don't could get you fined and placed under house arrest. But if you're Twitter, it could boost your bottom line. Gigaom's Carmel DeAmicis reports that brands pay Twitter to falsely appear in your following list, an advertising technique brought to light by William Shatner after he saw that 'MasterCard' appeared in his following list despite the fact that he didn't follow it. "By making it look like someone follows an account that they don't," writes DeAmicis, "it sends a false signal that said user cares about that brand. Although the brands are marked as 'promoted,' it's not necessarily clear that the user in question doesn't actually follow the brand. There's ethical considerations to be had. Hypothetical examples: What if you're vegan and don't want people to think you're following Burger King? Or you're the CEO of Visa and don't want people thinking you're following MasterCard? Or you're a pro-life activist and don't want people thinking you're following Planned Parenthood?" Or, if you're @BarackObama and don't want people to think you're following @TPPatriots! -
Would Twitter Make President Obama 'Follow' the Tea Party If the Price Is Right?
theodp (442580) writes Giving others the impression that individuals support something that they actually don't could get you fined and placed under house arrest. But if you're Twitter, it could boost your bottom line. Gigaom's Carmel DeAmicis reports that brands pay Twitter to falsely appear in your following list, an advertising technique brought to light by William Shatner after he saw that 'MasterCard' appeared in his following list despite the fact that he didn't follow it. "By making it look like someone follows an account that they don't," writes DeAmicis, "it sends a false signal that said user cares about that brand. Although the brands are marked as 'promoted,' it's not necessarily clear that the user in question doesn't actually follow the brand. There's ethical considerations to be had. Hypothetical examples: What if you're vegan and don't want people to think you're following Burger King? Or you're the CEO of Visa and don't want people thinking you're following MasterCard? Or you're a pro-life activist and don't want people thinking you're following Planned Parenthood?" Or, if you're @BarackObama and don't want people to think you're following @TPPatriots! -
Gmail Access Starts To Come Back In China, State-Run Paper Blames Google
An anonymous reader writes Basic access to Gmail is starting to come back online in China on Tuesday after going down on Friday. The state-run Global Times China did not explain what caused the four-day outage, despite the fact that the government clearly implemented the block, and instead pointed to Google's unwillingness to obey Chinese law. All of Google's products have been severely disrupted in China since June. While users in Chinaare not able to access Gmail via the website, email protocols such as IMAP, SMTP, and POP3 had been accessible. The Great Firewall of China started blocking the IP addresses used by Gmail for these protocols, leaving users in China with no way of sending or receiving emails. -
White House Touts Obama's 1-Liner as 2014 Tech Highlight
theodp (442580) writes That President Obama became the first President to write a line of code (as a top Microsoft lobbyist looked on) is #1 on the White House's Top 9 science and technology highlights from 2014. To kick off this year's Hour of Code, the President 'learned to code' by moving a Disney Princess Elsa character 100 pixels on a screen, first by dragging-and-dropping Blockly puzzle pieces and then by coding 1 line of JavaScript. Interestingly, Bill Clinton might have been The First President To Write Code had Microsoft seen fit to use its patented, circa-1995 Graphical Programming System and Method for Enabling a Person to Learn Text-Based Programming — which describes how kids as young as 8-12 years of age can be taught to program by progressing from creating a program using graphical objects to doing so using text-based programming — to teach President Clinton to code some 20 years ago! -
An Algorithm To Prevent Twitter Hashtag Degeneration
Bennett Haselton writes The corruption of the #Ferguson and #Gamergate hashtags demonstrates how vulnerable the hashtag system is to being swamped by an "angry mob". An alternative algorithm could be created that would allow users to post tweets and browse the ones that had been rated "thoughtful" by other users participating in the same discussion. This would still allow anyone to contribute, even average users lacking a large follower base, while keeping the most stupid and offensive tweets out of most people's feeds. Keep reading to see what Bennett has to say.As demonstrations and looting took place in Ferguson, some friends of mine and many public commentators expressed disgust with some of the most prejudiced comments tweeted with the #ferguson hashtag. A few high-profile cases led to incidents such as security concerns at one high school and a teacher being fired from another, but most of my friends paying attention said it was more about the steady drumbeat of subtly racist, ignorant, or epically point-missing tweets limping past, often larded with passive-aggressive sarcasm. (Typical example that I just pulled from #ferguson, courtesy of "Wayne Dupree Show": "Liberal Logic 101: Blacks don't commit crimes, Police are just racist. It's sad but that's the narrative being pushed #ferguson #ericgarner". But on the other side, hashtag names like "#BlackLivesMatter" are pretty passive-aggressive too.)
It reminded me of the corruption of the original #GamerGate tag, which today is infamously known for crude sexist trolling, but in its original incarnation (as coined by actor Alec Baldwin), the hashtag apparently referred to some somewhat reasonable questions being raised about ethics in gaming journalism and the statements of one (female) indie game developer. Regardless of what you think of the original arguments or the people making them -- even if you accept, for the sake of argument, that everything they were saying was wrong -- they didn't deserve for the hashtag to be associated with sexist piggishness that became synonymous with #GamerGate, to the exclusion of any discussion of the original points.
Whether a hashtag is corrupted by opponents (#ferguson) or by Neanderthals who nominally claim to be supporting you (#GamerGate), in either case it's possible for a sufficiently large mob to effectively ruin the discussion for many of the participants. In the case of #GamerGate, the point of the original discussion was drowned out completely; in the case of #ferguson, a high proportion of tweets are still aligned with the original point, but a reader is still going to quit reading if each victim-blaming tweet depresses them so much that the next 10 decent tweets won't make up for it.
So, what can you do? You could follow only the people you trust to say something thoughtful (or, at least, not proudly ignorant), and filter their posts for the #ferguson hashtag, but then you'd miss the overwhelming majority of other people's tweets on the subject, even the good ones. You can follow all posts with the hashtag and block the most egregious repeat "offenders", but that won't help much when the problematic messages come from so many different accounts.
What Twitter could do, on the other hand, would be to set up a system for browsing tweets under a given hashtag that would reward the tweets that are given the highest rating by other users following the same hashtag. That would not replace the current Twitter default of strict reverse chronological order for tweets, which hardcore Twitter fans consider sacrosanct. But it could be an alternative model for browsing the tweets grouped under a given hashtag.
Similar to the system I suggested for Twitter to adjudicate abuse reports, a tweet under a given hashtag could initially be shown to a random subset of, say, 100 users who are following that hashtag, and rated as to whether the tweet is funny, informative, interesting, etc. (sound familiar)? Then if the average rating is high enough, the tweet would be shown to users who are browsing the "highest rated" tweets on a given topic.
(The simpler and more obvious solution would be to display tweets as "highest rated" if they had been favorited or retweeted by lots of people. However, this is problematic because it allows a person to game the system by having all of their friends -- or sockpuppet accounts -- "like" a tweet in order to drive it to the top of the pile. By having the ratings come from a random subset of users, this resists attempts to game the system, because there's no way for a user to ensure that their friends will be among the random subset that is selected to rate the tweet.)
This is, essentially, the same algorithm that I've recommended for many other similar problems, even including, say, ways to identify the best new songs in a given genre (so that trance fans can rate the best new trance songs, country fans can rate the best new country songs, and in both cases, the new songs with the highest average rating get the widest promotion to all self-declared fans of that genre). However, there's a signficant twist in the case of rating tweets under a political hashtag. Fans of trance music can be reasonably sure that country music fans are not going to sign up to rate trance songs and given upvotes to the stupidest trance music. But on the other hand, if you create the #ferguson hashtag to discuss reforms to the justice system, there's a good chance that plenty of trolls will sign up to follow the #ferguson hashtag if it gives them the opportunity to upvote racist and victim-blaming tweets that defeat the purpose of the original discussion. Even if you assume that the racists and victim-blamers constitute a minority of users following the hashtag, it might also be the case that they will have a higher response rate whenever they happen to part of a random sample which is asked to "rate" a given tweet to determine whether that tweet is promoted to a wider audience. The trolls might end up constituting a majority of votes cast, which would defeat the purpose.
So perhaps a modified version of the algorithm could work better. As before, new tweets under a given hashtag would be rated by a random subset of users following that hashtag. However, for some random subset of those tweets, the tweets would also be rated by a random subset of all Twitter users. (How to solicit ratings from the general population of Twitter users is a good question. If you simply displayed those tweets to random Twitter users in a sidebar and asked, "Please rate this tweet, even though it's for a hashtag that you're not following," the response rate would likely be very low. But whatever the low rate was, if you display the tweet and the rating request to enough users, eventually you will get a sample of ratings that is statistically significant.) If the system determines that, in many cases, the rating of the tweet's quality from average Twitter users is significantly far apart from the rating from users following that hashtag, then that hashtag can be considered "compromised" (i.e., the majority of people following tweets on that hashtag are probably trolls, or at the least, voting far differently from how average Twitter users vote). And then, perhaps, the highest-rated tweets under that hashtag could be displayed with a disclaimer saying that the ratings have probably been manipulated and are not reliable (but here are the highest-rated tweets anyway, in case you want to read them).
This does raise a philosophical question: What if some subset of Twitter users -- whether skinheads, or communists, or Beliebers -- want to engage in a discussion where posts are rated according to their appeal to members of that in-group, without regard for those posts' appeal to the rest of the user base? Isn't that a perfectly valid form of discussion? My sympathies lie against that point of view. Apart from the fact that the group obviously has the legal right to engage in whatever in-group discussion they want to have, I don't think it's healthy to engage only with like-minded people whose mindset is radically different from almost everyone else's. (In any case, the system could still display the highest-rated tweets, just with the ever-present reminder that those ratings are wildly different from the average ratings given by users who are not following the hashtag. Unfortunately that might just embolden members of the in-group who take pride in the fact that their philosophy sets them apart from most of the rest of the world.)
Unfortunately a "deference to the majority" also means that the protocol wouldn't do much good in cases where the majority really is wrong. If Twitter had existed 60 years ago and had implemented something like what I'm describing, then Twitter discussions of homosexuality or interracial marriage might never have gotten off the ground, because the majority probably would have downvoted anything advocating or even tolerating those lifestyle options. (What year would you guess was the first year in which surveys showed that a majority of Americans supported interracial marriage? 1997.) Peer review, even in the random-sample, non-gameable fashion that I'm talking about, doesn't do much good to advance the discussion when we are the trolls, oblivious to the things we're bigoted and ignorant about that we'll look back and shake our heads at in another fifty years.
-
An Algorithm To Prevent Twitter Hashtag Degeneration
Bennett Haselton writes The corruption of the #Ferguson and #Gamergate hashtags demonstrates how vulnerable the hashtag system is to being swamped by an "angry mob". An alternative algorithm could be created that would allow users to post tweets and browse the ones that had been rated "thoughtful" by other users participating in the same discussion. This would still allow anyone to contribute, even average users lacking a large follower base, while keeping the most stupid and offensive tweets out of most people's feeds. Keep reading to see what Bennett has to say.As demonstrations and looting took place in Ferguson, some friends of mine and many public commentators expressed disgust with some of the most prejudiced comments tweeted with the #ferguson hashtag. A few high-profile cases led to incidents such as security concerns at one high school and a teacher being fired from another, but most of my friends paying attention said it was more about the steady drumbeat of subtly racist, ignorant, or epically point-missing tweets limping past, often larded with passive-aggressive sarcasm. (Typical example that I just pulled from #ferguson, courtesy of "Wayne Dupree Show": "Liberal Logic 101: Blacks don't commit crimes, Police are just racist. It's sad but that's the narrative being pushed #ferguson #ericgarner". But on the other side, hashtag names like "#BlackLivesMatter" are pretty passive-aggressive too.)
It reminded me of the corruption of the original #GamerGate tag, which today is infamously known for crude sexist trolling, but in its original incarnation (as coined by actor Alec Baldwin), the hashtag apparently referred to some somewhat reasonable questions being raised about ethics in gaming journalism and the statements of one (female) indie game developer. Regardless of what you think of the original arguments or the people making them -- even if you accept, for the sake of argument, that everything they were saying was wrong -- they didn't deserve for the hashtag to be associated with sexist piggishness that became synonymous with #GamerGate, to the exclusion of any discussion of the original points.
Whether a hashtag is corrupted by opponents (#ferguson) or by Neanderthals who nominally claim to be supporting you (#GamerGate), in either case it's possible for a sufficiently large mob to effectively ruin the discussion for many of the participants. In the case of #GamerGate, the point of the original discussion was drowned out completely; in the case of #ferguson, a high proportion of tweets are still aligned with the original point, but a reader is still going to quit reading if each victim-blaming tweet depresses them so much that the next 10 decent tweets won't make up for it.
So, what can you do? You could follow only the people you trust to say something thoughtful (or, at least, not proudly ignorant), and filter their posts for the #ferguson hashtag, but then you'd miss the overwhelming majority of other people's tweets on the subject, even the good ones. You can follow all posts with the hashtag and block the most egregious repeat "offenders", but that won't help much when the problematic messages come from so many different accounts.
What Twitter could do, on the other hand, would be to set up a system for browsing tweets under a given hashtag that would reward the tweets that are given the highest rating by other users following the same hashtag. That would not replace the current Twitter default of strict reverse chronological order for tweets, which hardcore Twitter fans consider sacrosanct. But it could be an alternative model for browsing the tweets grouped under a given hashtag.
Similar to the system I suggested for Twitter to adjudicate abuse reports, a tweet under a given hashtag could initially be shown to a random subset of, say, 100 users who are following that hashtag, and rated as to whether the tweet is funny, informative, interesting, etc. (sound familiar)? Then if the average rating is high enough, the tweet would be shown to users who are browsing the "highest rated" tweets on a given topic.
(The simpler and more obvious solution would be to display tweets as "highest rated" if they had been favorited or retweeted by lots of people. However, this is problematic because it allows a person to game the system by having all of their friends -- or sockpuppet accounts -- "like" a tweet in order to drive it to the top of the pile. By having the ratings come from a random subset of users, this resists attempts to game the system, because there's no way for a user to ensure that their friends will be among the random subset that is selected to rate the tweet.)
This is, essentially, the same algorithm that I've recommended for many other similar problems, even including, say, ways to identify the best new songs in a given genre (so that trance fans can rate the best new trance songs, country fans can rate the best new country songs, and in both cases, the new songs with the highest average rating get the widest promotion to all self-declared fans of that genre). However, there's a signficant twist in the case of rating tweets under a political hashtag. Fans of trance music can be reasonably sure that country music fans are not going to sign up to rate trance songs and given upvotes to the stupidest trance music. But on the other hand, if you create the #ferguson hashtag to discuss reforms to the justice system, there's a good chance that plenty of trolls will sign up to follow the #ferguson hashtag if it gives them the opportunity to upvote racist and victim-blaming tweets that defeat the purpose of the original discussion. Even if you assume that the racists and victim-blamers constitute a minority of users following the hashtag, it might also be the case that they will have a higher response rate whenever they happen to part of a random sample which is asked to "rate" a given tweet to determine whether that tweet is promoted to a wider audience. The trolls might end up constituting a majority of votes cast, which would defeat the purpose.
So perhaps a modified version of the algorithm could work better. As before, new tweets under a given hashtag would be rated by a random subset of users following that hashtag. However, for some random subset of those tweets, the tweets would also be rated by a random subset of all Twitter users. (How to solicit ratings from the general population of Twitter users is a good question. If you simply displayed those tweets to random Twitter users in a sidebar and asked, "Please rate this tweet, even though it's for a hashtag that you're not following," the response rate would likely be very low. But whatever the low rate was, if you display the tweet and the rating request to enough users, eventually you will get a sample of ratings that is statistically significant.) If the system determines that, in many cases, the rating of the tweet's quality from average Twitter users is significantly far apart from the rating from users following that hashtag, then that hashtag can be considered "compromised" (i.e., the majority of people following tweets on that hashtag are probably trolls, or at the least, voting far differently from how average Twitter users vote). And then, perhaps, the highest-rated tweets under that hashtag could be displayed with a disclaimer saying that the ratings have probably been manipulated and are not reliable (but here are the highest-rated tweets anyway, in case you want to read them).
This does raise a philosophical question: What if some subset of Twitter users -- whether skinheads, or communists, or Beliebers -- want to engage in a discussion where posts are rated according to their appeal to members of that in-group, without regard for those posts' appeal to the rest of the user base? Isn't that a perfectly valid form of discussion? My sympathies lie against that point of view. Apart from the fact that the group obviously has the legal right to engage in whatever in-group discussion they want to have, I don't think it's healthy to engage only with like-minded people whose mindset is radically different from almost everyone else's. (In any case, the system could still display the highest-rated tweets, just with the ever-present reminder that those ratings are wildly different from the average ratings given by users who are not following the hashtag. Unfortunately that might just embolden members of the in-group who take pride in the fact that their philosophy sets them apart from most of the rest of the world.)
Unfortunately a "deference to the majority" also means that the protocol wouldn't do much good in cases where the majority really is wrong. If Twitter had existed 60 years ago and had implemented something like what I'm describing, then Twitter discussions of homosexuality or interracial marriage might never have gotten off the ground, because the majority probably would have downvoted anything advocating or even tolerating those lifestyle options. (What year would you guess was the first year in which surveys showed that a majority of Americans supported interracial marriage? 1997.) Peer review, even in the random-sample, non-gameable fashion that I'm talking about, doesn't do much good to advance the discussion when we are the trolls, oblivious to the things we're bigoted and ignorant about that we'll look back and shake our heads at in another fifty years.
-
An Algorithm To Prevent Twitter Hashtag Degeneration
Bennett Haselton writes The corruption of the #Ferguson and #Gamergate hashtags demonstrates how vulnerable the hashtag system is to being swamped by an "angry mob". An alternative algorithm could be created that would allow users to post tweets and browse the ones that had been rated "thoughtful" by other users participating in the same discussion. This would still allow anyone to contribute, even average users lacking a large follower base, while keeping the most stupid and offensive tweets out of most people's feeds. Keep reading to see what Bennett has to say.As demonstrations and looting took place in Ferguson, some friends of mine and many public commentators expressed disgust with some of the most prejudiced comments tweeted with the #ferguson hashtag. A few high-profile cases led to incidents such as security concerns at one high school and a teacher being fired from another, but most of my friends paying attention said it was more about the steady drumbeat of subtly racist, ignorant, or epically point-missing tweets limping past, often larded with passive-aggressive sarcasm. (Typical example that I just pulled from #ferguson, courtesy of "Wayne Dupree Show": "Liberal Logic 101: Blacks don't commit crimes, Police are just racist. It's sad but that's the narrative being pushed #ferguson #ericgarner". But on the other side, hashtag names like "#BlackLivesMatter" are pretty passive-aggressive too.)
It reminded me of the corruption of the original #GamerGate tag, which today is infamously known for crude sexist trolling, but in its original incarnation (as coined by actor Alec Baldwin), the hashtag apparently referred to some somewhat reasonable questions being raised about ethics in gaming journalism and the statements of one (female) indie game developer. Regardless of what you think of the original arguments or the people making them -- even if you accept, for the sake of argument, that everything they were saying was wrong -- they didn't deserve for the hashtag to be associated with sexist piggishness that became synonymous with #GamerGate, to the exclusion of any discussion of the original points.
Whether a hashtag is corrupted by opponents (#ferguson) or by Neanderthals who nominally claim to be supporting you (#GamerGate), in either case it's possible for a sufficiently large mob to effectively ruin the discussion for many of the participants. In the case of #GamerGate, the point of the original discussion was drowned out completely; in the case of #ferguson, a high proportion of tweets are still aligned with the original point, but a reader is still going to quit reading if each victim-blaming tweet depresses them so much that the next 10 decent tweets won't make up for it.
So, what can you do? You could follow only the people you trust to say something thoughtful (or, at least, not proudly ignorant), and filter their posts for the #ferguson hashtag, but then you'd miss the overwhelming majority of other people's tweets on the subject, even the good ones. You can follow all posts with the hashtag and block the most egregious repeat "offenders", but that won't help much when the problematic messages come from so many different accounts.
What Twitter could do, on the other hand, would be to set up a system for browsing tweets under a given hashtag that would reward the tweets that are given the highest rating by other users following the same hashtag. That would not replace the current Twitter default of strict reverse chronological order for tweets, which hardcore Twitter fans consider sacrosanct. But it could be an alternative model for browsing the tweets grouped under a given hashtag.
Similar to the system I suggested for Twitter to adjudicate abuse reports, a tweet under a given hashtag could initially be shown to a random subset of, say, 100 users who are following that hashtag, and rated as to whether the tweet is funny, informative, interesting, etc. (sound familiar)? Then if the average rating is high enough, the tweet would be shown to users who are browsing the "highest rated" tweets on a given topic.
(The simpler and more obvious solution would be to display tweets as "highest rated" if they had been favorited or retweeted by lots of people. However, this is problematic because it allows a person to game the system by having all of their friends -- or sockpuppet accounts -- "like" a tweet in order to drive it to the top of the pile. By having the ratings come from a random subset of users, this resists attempts to game the system, because there's no way for a user to ensure that their friends will be among the random subset that is selected to rate the tweet.)
This is, essentially, the same algorithm that I've recommended for many other similar problems, even including, say, ways to identify the best new songs in a given genre (so that trance fans can rate the best new trance songs, country fans can rate the best new country songs, and in both cases, the new songs with the highest average rating get the widest promotion to all self-declared fans of that genre). However, there's a signficant twist in the case of rating tweets under a political hashtag. Fans of trance music can be reasonably sure that country music fans are not going to sign up to rate trance songs and given upvotes to the stupidest trance music. But on the other hand, if you create the #ferguson hashtag to discuss reforms to the justice system, there's a good chance that plenty of trolls will sign up to follow the #ferguson hashtag if it gives them the opportunity to upvote racist and victim-blaming tweets that defeat the purpose of the original discussion. Even if you assume that the racists and victim-blamers constitute a minority of users following the hashtag, it might also be the case that they will have a higher response rate whenever they happen to part of a random sample which is asked to "rate" a given tweet to determine whether that tweet is promoted to a wider audience. The trolls might end up constituting a majority of votes cast, which would defeat the purpose.
So perhaps a modified version of the algorithm could work better. As before, new tweets under a given hashtag would be rated by a random subset of users following that hashtag. However, for some random subset of those tweets, the tweets would also be rated by a random subset of all Twitter users. (How to solicit ratings from the general population of Twitter users is a good question. If you simply displayed those tweets to random Twitter users in a sidebar and asked, "Please rate this tweet, even though it's for a hashtag that you're not following," the response rate would likely be very low. But whatever the low rate was, if you display the tweet and the rating request to enough users, eventually you will get a sample of ratings that is statistically significant.) If the system determines that, in many cases, the rating of the tweet's quality from average Twitter users is significantly far apart from the rating from users following that hashtag, then that hashtag can be considered "compromised" (i.e., the majority of people following tweets on that hashtag are probably trolls, or at the least, voting far differently from how average Twitter users vote). And then, perhaps, the highest-rated tweets under that hashtag could be displayed with a disclaimer saying that the ratings have probably been manipulated and are not reliable (but here are the highest-rated tweets anyway, in case you want to read them).
This does raise a philosophical question: What if some subset of Twitter users -- whether skinheads, or communists, or Beliebers -- want to engage in a discussion where posts are rated according to their appeal to members of that in-group, without regard for those posts' appeal to the rest of the user base? Isn't that a perfectly valid form of discussion? My sympathies lie against that point of view. Apart from the fact that the group obviously has the legal right to engage in whatever in-group discussion they want to have, I don't think it's healthy to engage only with like-minded people whose mindset is radically different from almost everyone else's. (In any case, the system could still display the highest-rated tweets, just with the ever-present reminder that those ratings are wildly different from the average ratings given by users who are not following the hashtag. Unfortunately that might just embolden members of the in-group who take pride in the fact that their philosophy sets them apart from most of the rest of the world.)
Unfortunately a "deference to the majority" also means that the protocol wouldn't do much good in cases where the majority really is wrong. If Twitter had existed 60 years ago and had implemented something like what I'm describing, then Twitter discussions of homosexuality or interracial marriage might never have gotten off the ground, because the majority probably would have downvoted anything advocating or even tolerating those lifestyle options. (What year would you guess was the first year in which surveys showed that a majority of Americans supported interracial marriage? 1997.) Peer review, even in the random-sample, non-gameable fashion that I'm talking about, doesn't do much good to advance the discussion when we are the trolls, oblivious to the things we're bigoted and ignorant about that we'll look back and shake our heads at in another fifty years.
-
An Algorithm To Prevent Twitter Hashtag Degeneration
Bennett Haselton writes The corruption of the #Ferguson and #Gamergate hashtags demonstrates how vulnerable the hashtag system is to being swamped by an "angry mob". An alternative algorithm could be created that would allow users to post tweets and browse the ones that had been rated "thoughtful" by other users participating in the same discussion. This would still allow anyone to contribute, even average users lacking a large follower base, while keeping the most stupid and offensive tweets out of most people's feeds. Keep reading to see what Bennett has to say.As demonstrations and looting took place in Ferguson, some friends of mine and many public commentators expressed disgust with some of the most prejudiced comments tweeted with the #ferguson hashtag. A few high-profile cases led to incidents such as security concerns at one high school and a teacher being fired from another, but most of my friends paying attention said it was more about the steady drumbeat of subtly racist, ignorant, or epically point-missing tweets limping past, often larded with passive-aggressive sarcasm. (Typical example that I just pulled from #ferguson, courtesy of "Wayne Dupree Show": "Liberal Logic 101: Blacks don't commit crimes, Police are just racist. It's sad but that's the narrative being pushed #ferguson #ericgarner". But on the other side, hashtag names like "#BlackLivesMatter" are pretty passive-aggressive too.)
It reminded me of the corruption of the original #GamerGate tag, which today is infamously known for crude sexist trolling, but in its original incarnation (as coined by actor Alec Baldwin), the hashtag apparently referred to some somewhat reasonable questions being raised about ethics in gaming journalism and the statements of one (female) indie game developer. Regardless of what you think of the original arguments or the people making them -- even if you accept, for the sake of argument, that everything they were saying was wrong -- they didn't deserve for the hashtag to be associated with sexist piggishness that became synonymous with #GamerGate, to the exclusion of any discussion of the original points.
Whether a hashtag is corrupted by opponents (#ferguson) or by Neanderthals who nominally claim to be supporting you (#GamerGate), in either case it's possible for a sufficiently large mob to effectively ruin the discussion for many of the participants. In the case of #GamerGate, the point of the original discussion was drowned out completely; in the case of #ferguson, a high proportion of tweets are still aligned with the original point, but a reader is still going to quit reading if each victim-blaming tweet depresses them so much that the next 10 decent tweets won't make up for it.
So, what can you do? You could follow only the people you trust to say something thoughtful (or, at least, not proudly ignorant), and filter their posts for the #ferguson hashtag, but then you'd miss the overwhelming majority of other people's tweets on the subject, even the good ones. You can follow all posts with the hashtag and block the most egregious repeat "offenders", but that won't help much when the problematic messages come from so many different accounts.
What Twitter could do, on the other hand, would be to set up a system for browsing tweets under a given hashtag that would reward the tweets that are given the highest rating by other users following the same hashtag. That would not replace the current Twitter default of strict reverse chronological order for tweets, which hardcore Twitter fans consider sacrosanct. But it could be an alternative model for browsing the tweets grouped under a given hashtag.
Similar to the system I suggested for Twitter to adjudicate abuse reports, a tweet under a given hashtag could initially be shown to a random subset of, say, 100 users who are following that hashtag, and rated as to whether the tweet is funny, informative, interesting, etc. (sound familiar)? Then if the average rating is high enough, the tweet would be shown to users who are browsing the "highest rated" tweets on a given topic.
(The simpler and more obvious solution would be to display tweets as "highest rated" if they had been favorited or retweeted by lots of people. However, this is problematic because it allows a person to game the system by having all of their friends -- or sockpuppet accounts -- "like" a tweet in order to drive it to the top of the pile. By having the ratings come from a random subset of users, this resists attempts to game the system, because there's no way for a user to ensure that their friends will be among the random subset that is selected to rate the tweet.)
This is, essentially, the same algorithm that I've recommended for many other similar problems, even including, say, ways to identify the best new songs in a given genre (so that trance fans can rate the best new trance songs, country fans can rate the best new country songs, and in both cases, the new songs with the highest average rating get the widest promotion to all self-declared fans of that genre). However, there's a signficant twist in the case of rating tweets under a political hashtag. Fans of trance music can be reasonably sure that country music fans are not going to sign up to rate trance songs and given upvotes to the stupidest trance music. But on the other hand, if you create the #ferguson hashtag to discuss reforms to the justice system, there's a good chance that plenty of trolls will sign up to follow the #ferguson hashtag if it gives them the opportunity to upvote racist and victim-blaming tweets that defeat the purpose of the original discussion. Even if you assume that the racists and victim-blamers constitute a minority of users following the hashtag, it might also be the case that they will have a higher response rate whenever they happen to part of a random sample which is asked to "rate" a given tweet to determine whether that tweet is promoted to a wider audience. The trolls might end up constituting a majority of votes cast, which would defeat the purpose.
So perhaps a modified version of the algorithm could work better. As before, new tweets under a given hashtag would be rated by a random subset of users following that hashtag. However, for some random subset of those tweets, the tweets would also be rated by a random subset of all Twitter users. (How to solicit ratings from the general population of Twitter users is a good question. If you simply displayed those tweets to random Twitter users in a sidebar and asked, "Please rate this tweet, even though it's for a hashtag that you're not following," the response rate would likely be very low. But whatever the low rate was, if you display the tweet and the rating request to enough users, eventually you will get a sample of ratings that is statistically significant.) If the system determines that, in many cases, the rating of the tweet's quality from average Twitter users is significantly far apart from the rating from users following that hashtag, then that hashtag can be considered "compromised" (i.e., the majority of people following tweets on that hashtag are probably trolls, or at the least, voting far differently from how average Twitter users vote). And then, perhaps, the highest-rated tweets under that hashtag could be displayed with a disclaimer saying that the ratings have probably been manipulated and are not reliable (but here are the highest-rated tweets anyway, in case you want to read them).
This does raise a philosophical question: What if some subset of Twitter users -- whether skinheads, or communists, or Beliebers -- want to engage in a discussion where posts are rated according to their appeal to members of that in-group, without regard for those posts' appeal to the rest of the user base? Isn't that a perfectly valid form of discussion? My sympathies lie against that point of view. Apart from the fact that the group obviously has the legal right to engage in whatever in-group discussion they want to have, I don't think it's healthy to engage only with like-minded people whose mindset is radically different from almost everyone else's. (In any case, the system could still display the highest-rated tweets, just with the ever-present reminder that those ratings are wildly different from the average ratings given by users who are not following the hashtag. Unfortunately that might just embolden members of the in-group who take pride in the fact that their philosophy sets them apart from most of the rest of the world.)
Unfortunately a "deference to the majority" also means that the protocol wouldn't do much good in cases where the majority really is wrong. If Twitter had existed 60 years ago and had implemented something like what I'm describing, then Twitter discussions of homosexuality or interracial marriage might never have gotten off the ground, because the majority probably would have downvoted anything advocating or even tolerating those lifestyle options. (What year would you guess was the first year in which surveys showed that a majority of Americans supported interracial marriage? 1997.) Peer review, even in the random-sample, non-gameable fashion that I'm talking about, doesn't do much good to advance the discussion when we are the trolls, oblivious to the things we're bigoted and ignorant about that we'll look back and shake our heads at in another fifty years.
-
Seeking Coders, Tech Titans Turn To K-12 Schools
theodp writes: Politico reports on how a tech PR blitz on the importance of coding in K-12 schools has won over President Obama, who's now been dubbed the "coder-in-chief" after sitting down Monday to "write" a few lines of computer code with middle school students as part of a PR campaign for the Hour of Code, which has earned bipartisan support in Washington. From the article: "The $30 million campaign to promote computer science education has been financed by the tech industry, led by Steve Ballmer, Bill Gates and Mark Zuckerberg, with corporate contributions from Microsoft, Google, Amazon and other giants. It's been a smash success: So many students opened up a free coding tutorial on Monday that the host website crashed. But the campaign has also stirred unease from some educators concerned about the growing influence of corporations in public schools. And it's raised questions about the motives of tech companies, which are sounding an alarm about the lack of computer training in American schools even as they lobby Congress for more H-1B visas to bring in foreign programmers." -
Node.js Forked By Top Contributors
New submitter jonhorvath writes: Several of the top contributors to Node.js, a popular open source run-time environment, have decided to fork the project, creating io.js as an alternative. The developers were unhappy with how cloud computing company Joyent was directing work on Node.js. Mikeal Rogers said, "We don't want to have just one person who's appointed by a company making decisions. We want contributors to have more control, to seek consensus." Here's the new repository, and a README file to go with it. A developer at Uber tweeted that they've already migrated to io.js on their production systems. It'll be interesting to see how many other sites follow. -
Twitter Should Use Random Sample Voting For Abuse Reports
Bennett Haselton writes: Twitter has announced new protocols for filing and handling abuse reports, making it easier to flag specific types of content (e.g. violence or suicide threats). But with the volume of abusive tweets being reported to the company every day, the internal review process will always be a bottleneck. The company could handle more abuse reports properly by recruiting public volunteers. Read what Bennett thinks below.In August, Twitter user Kristin Puhl made public the fact that another Twitter user had tweeted at her:
f@#king die feminist moron i'm coming after u and raping u.
and when Puhl filed an abuse complaint with Twitter, Twitter responded after two days:
We've investigated the account and reported Tweets for violent threats and abusive behavior, and have found that it's currently not violating the Twitter Rules (https://twitter.com/rules).
(The "rules" linked in the message include the clause "You may not publish or post direct, specific threats of violence against others.") Twitter must have changed their mind eventually, because the account of the user who sent the message is now gone, but why didn't they close it the first time?
Twitter can't effectively adjudicate all the abuse complaints that they get, but I don't blame them. I don't think they publicize numbers for how many abuse complaints they receive every day, but I'm sure that it's more than an internal review panel could handle fairly. Twitter should not be faulted for that. They've created a world-changing tool, and they shouldn't have had to stifle the growth of their platform just because it grew faster than their ability to handle the abuse reports.
But now that they're publicizing their latest tools for handling online harassment, it's fair to ask more of them. And while the tools may streamline the process of categorizing incoming abuse reports, there's always going to be a human review bottleneck, which will get tighter as the Twitter platform continues to grow.
So I'd suggest the same solution that I suggested for Facebook abuse reports: recruit a pool of volunteers from the general public to review "abuse reports". (You would need a "critical mass" of at least tens of thousands of reviewers for my idea to work, but Twitter shouldn't have trouble amassing that many people for a special program.) Then when an abuse report comes in, do the following:
- Some small number of reviewers -- say, ten -- are randomly recruited from the pool of volunteers.
- Each of them looks at the reported content and the category of abuse that it was reported under, and votes Yes or No as to whether the content meets the criteria for abuse.
- If some threshold of users (say, eight) vote that it does, then the report gets bumped up to a higher-level review. This "higher-level review" could mean having a new, larger pool of users (say, twenty) look at the content and vote on it, in case the original eight-out-of-ten vote was a statistical fluke. Or it could mean forwarding the reported tweet to some human review panel at Twitter -- which now has far fewer abuse cases to review, because it only has to look at the reported tweets that cleared the hurdle of getting eight out of ten votes for violating the guidelines.
These numbers are just guesses. I might be over-optimistic about how many reviewers would even respond when Twitter asked them to vote on whether some content was abusive (even though that's what the reviewers signed up to do) -- it might turn out that to get even ten responses, Twitter would have to nag 50 people to come and vote on a piece of content. And the size of the voting initial voting panel should be large enough to avoid statistical flukes most of the time -- if a tweet is inoffensive enough that only 10% of the reviewer population would consider it "abusive", you'd have to be really unlucky to convene a panel of 10 users where 7 out of 10 voted to label the tweet as "abuse".
As long as the size of the reviewer population grows in proportion with the Twitter user base (or, more precisely, as long as it grows in proportion with the volume of abuse reports coming in), this system scales as much as you want it to. (Well, unless the "higher-level review" involves review by an internal panel at Twitter, which still creates a bottleneck.)
Because the voting panel is randomly selected from among the entire pool of volunteers, that means you can't "game the system" by forming a mob with dozens of your friends so that everyone can file an abuse report about the same content at once. As long as your mob only comprises a tiny proportion of the 100,000+ reviewers in the system, there's virtually no change that a randomly selected panel would contain enough of you to swing the vote.
This could also potentially result in an almost-instant turnaround time for handling abuse cases (a matter of reassurance for victims of normal harassment, and a matter of life and death in the case of suicide threats or threats of violence). Twitter could restrict their random sample to only those users who happen to be signed in at the present moment, and who have a minute or two to review a piece of content and vote on whether it violates the guidelines.
Tweets are by definition public, so there wouldn't be any potential privacy violation in taking someone's tweet, putting it before a panel of 10 volunteer reviewers, and asking them to determine if it violated the terms of service. Direct Messages sent via Twitter, on the other hand, are intended only for the recipient, and are not public by default. If a recipient wanted to flag a Direct Message as abusive, they would have to specify whether they want the content to be reviewable by a panel of randomly selected public volunteers. So in the case of the tweet received by Kristin Puhl -- "fucking die feminist moron i'm coming after u and raping u" -- even if she had received it as a Direct Message from someone she was following (you can only receive DMs from someone if you're following them), presumably she would have been OK with showing the tweet to a panel of volunteers, who probably would have voted that it was in fact abusive. On the other hand, sometimes a user might receive abusive DMs where they want to report the abuse, but the DMs might contain sensitive information that they don't want publicized to randomly selected volunteers. So those abuse reports might have to be handled the old-fashioned way at Twitter, by internal review, which still creates a bottleneck. But hopefully the abuse reports about Direct Messages comprise only a small minority of abuse reports that Twitter receives, since most talk about abuse on Twitter comes in the form of public tweets. (If someone is "abusing" you via DMs, you can just unfollow them.)
Twitter could even be completely transparent about the entire voting process: "Your complaint has been reviewed by 10 people. 8 of them agreed that the tweet in question violated our guidelines. This is above our minimum threshold of 7 that triggers a higher-level review of this content." (Twitter presumably wouldn't want to tell the complainer who the voters on the panel were, since the complainer might harass the individual voters if the voting panel as a whole rejected the complaint. But there's no reason not to be transparent about the actual numbers.)
Why would someone sign up to volunteer to review abusive content? Maybe for the glimpse into strangers' lives. Maybe hoping to save copies of some of the porn contained in the tweets that get reported for abuse. (Of course, there are easier ways to get porn online, but maybe they get off on the fact that some particular pornographic image made someone angry and upset enough to report it.) Maybe they altruistically believe it's part of their civic duty towards the Twitter community. Maybe because they're bored.
Whatever people's myriad motivations for signing up, the important thing is that there's still a statistically significant difference between the number of "yes" votes received when content truly is abusive, and when it's not. Even if you have people signing up as reviewers for all kinds of weird reasons, a tweet like "fucking die feminist moron i'm coming after u and raping u" is still going to receive, on average, more "yes" votes than a tweet like "I respectfully disagree, so let's go our separate ways".
If Twitter were nervous about rolling out a system like this, ceding control of the abuse-report-handling process to a pool of volunteers, they could always do their own random sampling of the random-sample-voting system, to see how it was working. An internal auditor could pull 100 of the abuse report cases that have been handled by the random-sample-voting system recently, decide in each case whether the tweet did in fact violate the abuse guidelines, and then look to see if the voting system reached the same answer. As a control in the experiment, look at some abuse reports that were routed to the old-fashioned internal review panel during the same period, see how they handled the reports, and see how they fared in comparison. I would confidently bet money that the random sample voting system would handle the abuse reports more accurately, and faster, as well.
This won't do much to deter abusers who create an endless series of throwaway accounts for harassment purposes, which makes it futile to block or report any particular account. But it would at least get step zero right, which is to correctly adjudicate whether a tweet is abusive or not. And it would do it in a way that is scalable, non-gameable, and transparent. Plus a few volunteers would get an interesting story to tell at dinner.
-
Twitter Should Use Random Sample Voting For Abuse Reports
Bennett Haselton writes: Twitter has announced new protocols for filing and handling abuse reports, making it easier to flag specific types of content (e.g. violence or suicide threats). But with the volume of abusive tweets being reported to the company every day, the internal review process will always be a bottleneck. The company could handle more abuse reports properly by recruiting public volunteers. Read what Bennett thinks below.In August, Twitter user Kristin Puhl made public the fact that another Twitter user had tweeted at her:
f@#king die feminist moron i'm coming after u and raping u.
and when Puhl filed an abuse complaint with Twitter, Twitter responded after two days:
We've investigated the account and reported Tweets for violent threats and abusive behavior, and have found that it's currently not violating the Twitter Rules (https://twitter.com/rules).
(The "rules" linked in the message include the clause "You may not publish or post direct, specific threats of violence against others.") Twitter must have changed their mind eventually, because the account of the user who sent the message is now gone, but why didn't they close it the first time?
Twitter can't effectively adjudicate all the abuse complaints that they get, but I don't blame them. I don't think they publicize numbers for how many abuse complaints they receive every day, but I'm sure that it's more than an internal review panel could handle fairly. Twitter should not be faulted for that. They've created a world-changing tool, and they shouldn't have had to stifle the growth of their platform just because it grew faster than their ability to handle the abuse reports.
But now that they're publicizing their latest tools for handling online harassment, it's fair to ask more of them. And while the tools may streamline the process of categorizing incoming abuse reports, there's always going to be a human review bottleneck, which will get tighter as the Twitter platform continues to grow.
So I'd suggest the same solution that I suggested for Facebook abuse reports: recruit a pool of volunteers from the general public to review "abuse reports". (You would need a "critical mass" of at least tens of thousands of reviewers for my idea to work, but Twitter shouldn't have trouble amassing that many people for a special program.) Then when an abuse report comes in, do the following:
- Some small number of reviewers -- say, ten -- are randomly recruited from the pool of volunteers.
- Each of them looks at the reported content and the category of abuse that it was reported under, and votes Yes or No as to whether the content meets the criteria for abuse.
- If some threshold of users (say, eight) vote that it does, then the report gets bumped up to a higher-level review. This "higher-level review" could mean having a new, larger pool of users (say, twenty) look at the content and vote on it, in case the original eight-out-of-ten vote was a statistical fluke. Or it could mean forwarding the reported tweet to some human review panel at Twitter -- which now has far fewer abuse cases to review, because it only has to look at the reported tweets that cleared the hurdle of getting eight out of ten votes for violating the guidelines.
These numbers are just guesses. I might be over-optimistic about how many reviewers would even respond when Twitter asked them to vote on whether some content was abusive (even though that's what the reviewers signed up to do) -- it might turn out that to get even ten responses, Twitter would have to nag 50 people to come and vote on a piece of content. And the size of the voting initial voting panel should be large enough to avoid statistical flukes most of the time -- if a tweet is inoffensive enough that only 10% of the reviewer population would consider it "abusive", you'd have to be really unlucky to convene a panel of 10 users where 7 out of 10 voted to label the tweet as "abuse".
As long as the size of the reviewer population grows in proportion with the Twitter user base (or, more precisely, as long as it grows in proportion with the volume of abuse reports coming in), this system scales as much as you want it to. (Well, unless the "higher-level review" involves review by an internal panel at Twitter, which still creates a bottleneck.)
Because the voting panel is randomly selected from among the entire pool of volunteers, that means you can't "game the system" by forming a mob with dozens of your friends so that everyone can file an abuse report about the same content at once. As long as your mob only comprises a tiny proportion of the 100,000+ reviewers in the system, there's virtually no change that a randomly selected panel would contain enough of you to swing the vote.
This could also potentially result in an almost-instant turnaround time for handling abuse cases (a matter of reassurance for victims of normal harassment, and a matter of life and death in the case of suicide threats or threats of violence). Twitter could restrict their random sample to only those users who happen to be signed in at the present moment, and who have a minute or two to review a piece of content and vote on whether it violates the guidelines.
Tweets are by definition public, so there wouldn't be any potential privacy violation in taking someone's tweet, putting it before a panel of 10 volunteer reviewers, and asking them to determine if it violated the terms of service. Direct Messages sent via Twitter, on the other hand, are intended only for the recipient, and are not public by default. If a recipient wanted to flag a Direct Message as abusive, they would have to specify whether they want the content to be reviewable by a panel of randomly selected public volunteers. So in the case of the tweet received by Kristin Puhl -- "fucking die feminist moron i'm coming after u and raping u" -- even if she had received it as a Direct Message from someone she was following (you can only receive DMs from someone if you're following them), presumably she would have been OK with showing the tweet to a panel of volunteers, who probably would have voted that it was in fact abusive. On the other hand, sometimes a user might receive abusive DMs where they want to report the abuse, but the DMs might contain sensitive information that they don't want publicized to randomly selected volunteers. So those abuse reports might have to be handled the old-fashioned way at Twitter, by internal review, which still creates a bottleneck. But hopefully the abuse reports about Direct Messages comprise only a small minority of abuse reports that Twitter receives, since most talk about abuse on Twitter comes in the form of public tweets. (If someone is "abusing" you via DMs, you can just unfollow them.)
Twitter could even be completely transparent about the entire voting process: "Your complaint has been reviewed by 10 people. 8 of them agreed that the tweet in question violated our guidelines. This is above our minimum threshold of 7 that triggers a higher-level review of this content." (Twitter presumably wouldn't want to tell the complainer who the voters on the panel were, since the complainer might harass the individual voters if the voting panel as a whole rejected the complaint. But there's no reason not to be transparent about the actual numbers.)
Why would someone sign up to volunteer to review abusive content? Maybe for the glimpse into strangers' lives. Maybe hoping to save copies of some of the porn contained in the tweets that get reported for abuse. (Of course, there are easier ways to get porn online, but maybe they get off on the fact that some particular pornographic image made someone angry and upset enough to report it.) Maybe they altruistically believe it's part of their civic duty towards the Twitter community. Maybe because they're bored.
Whatever people's myriad motivations for signing up, the important thing is that there's still a statistically significant difference between the number of "yes" votes received when content truly is abusive, and when it's not. Even if you have people signing up as reviewers for all kinds of weird reasons, a tweet like "fucking die feminist moron i'm coming after u and raping u" is still going to receive, on average, more "yes" votes than a tweet like "I respectfully disagree, so let's go our separate ways".
If Twitter were nervous about rolling out a system like this, ceding control of the abuse-report-handling process to a pool of volunteers, they could always do their own random sampling of the random-sample-voting system, to see how it was working. An internal auditor could pull 100 of the abuse report cases that have been handled by the random-sample-voting system recently, decide in each case whether the tweet did in fact violate the abuse guidelines, and then look to see if the voting system reached the same answer. As a control in the experiment, look at some abuse reports that were routed to the old-fashioned internal review panel during the same period, see how they handled the reports, and see how they fared in comparison. I would confidently bet money that the random sample voting system would handle the abuse reports more accurately, and faster, as well.
This won't do much to deter abusers who create an endless series of throwaway accounts for harassment purposes, which makes it futile to block or report any particular account. But it would at least get step zero right, which is to correctly adjudicate whether a tweet is abusive or not. And it would do it in a way that is scalable, non-gameable, and transparent. Plus a few volunteers would get an interesting story to tell at dinner.
-
Twitter Should Use Random Sample Voting For Abuse Reports
Bennett Haselton writes: Twitter has announced new protocols for filing and handling abuse reports, making it easier to flag specific types of content (e.g. violence or suicide threats). But with the volume of abusive tweets being reported to the company every day, the internal review process will always be a bottleneck. The company could handle more abuse reports properly by recruiting public volunteers. Read what Bennett thinks below.In August, Twitter user Kristin Puhl made public the fact that another Twitter user had tweeted at her:
f@#king die feminist moron i'm coming after u and raping u.
and when Puhl filed an abuse complaint with Twitter, Twitter responded after two days:
We've investigated the account and reported Tweets for violent threats and abusive behavior, and have found that it's currently not violating the Twitter Rules (https://twitter.com/rules).
(The "rules" linked in the message include the clause "You may not publish or post direct, specific threats of violence against others.") Twitter must have changed their mind eventually, because the account of the user who sent the message is now gone, but why didn't they close it the first time?
Twitter can't effectively adjudicate all the abuse complaints that they get, but I don't blame them. I don't think they publicize numbers for how many abuse complaints they receive every day, but I'm sure that it's more than an internal review panel could handle fairly. Twitter should not be faulted for that. They've created a world-changing tool, and they shouldn't have had to stifle the growth of their platform just because it grew faster than their ability to handle the abuse reports.
But now that they're publicizing their latest tools for handling online harassment, it's fair to ask more of them. And while the tools may streamline the process of categorizing incoming abuse reports, there's always going to be a human review bottleneck, which will get tighter as the Twitter platform continues to grow.
So I'd suggest the same solution that I suggested for Facebook abuse reports: recruit a pool of volunteers from the general public to review "abuse reports". (You would need a "critical mass" of at least tens of thousands of reviewers for my idea to work, but Twitter shouldn't have trouble amassing that many people for a special program.) Then when an abuse report comes in, do the following:
- Some small number of reviewers -- say, ten -- are randomly recruited from the pool of volunteers.
- Each of them looks at the reported content and the category of abuse that it was reported under, and votes Yes or No as to whether the content meets the criteria for abuse.
- If some threshold of users (say, eight) vote that it does, then the report gets bumped up to a higher-level review. This "higher-level review" could mean having a new, larger pool of users (say, twenty) look at the content and vote on it, in case the original eight-out-of-ten vote was a statistical fluke. Or it could mean forwarding the reported tweet to some human review panel at Twitter -- which now has far fewer abuse cases to review, because it only has to look at the reported tweets that cleared the hurdle of getting eight out of ten votes for violating the guidelines.
These numbers are just guesses. I might be over-optimistic about how many reviewers would even respond when Twitter asked them to vote on whether some content was abusive (even though that's what the reviewers signed up to do) -- it might turn out that to get even ten responses, Twitter would have to nag 50 people to come and vote on a piece of content. And the size of the voting initial voting panel should be large enough to avoid statistical flukes most of the time -- if a tweet is inoffensive enough that only 10% of the reviewer population would consider it "abusive", you'd have to be really unlucky to convene a panel of 10 users where 7 out of 10 voted to label the tweet as "abuse".
As long as the size of the reviewer population grows in proportion with the Twitter user base (or, more precisely, as long as it grows in proportion with the volume of abuse reports coming in), this system scales as much as you want it to. (Well, unless the "higher-level review" involves review by an internal panel at Twitter, which still creates a bottleneck.)
Because the voting panel is randomly selected from among the entire pool of volunteers, that means you can't "game the system" by forming a mob with dozens of your friends so that everyone can file an abuse report about the same content at once. As long as your mob only comprises a tiny proportion of the 100,000+ reviewers in the system, there's virtually no change that a randomly selected panel would contain enough of you to swing the vote.
This could also potentially result in an almost-instant turnaround time for handling abuse cases (a matter of reassurance for victims of normal harassment, and a matter of life and death in the case of suicide threats or threats of violence). Twitter could restrict their random sample to only those users who happen to be signed in at the present moment, and who have a minute or two to review a piece of content and vote on whether it violates the guidelines.
Tweets are by definition public, so there wouldn't be any potential privacy violation in taking someone's tweet, putting it before a panel of 10 volunteer reviewers, and asking them to determine if it violated the terms of service. Direct Messages sent via Twitter, on the other hand, are intended only for the recipient, and are not public by default. If a recipient wanted to flag a Direct Message as abusive, they would have to specify whether they want the content to be reviewable by a panel of randomly selected public volunteers. So in the case of the tweet received by Kristin Puhl -- "fucking die feminist moron i'm coming after u and raping u" -- even if she had received it as a Direct Message from someone she was following (you can only receive DMs from someone if you're following them), presumably she would have been OK with showing the tweet to a panel of volunteers, who probably would have voted that it was in fact abusive. On the other hand, sometimes a user might receive abusive DMs where they want to report the abuse, but the DMs might contain sensitive information that they don't want publicized to randomly selected volunteers. So those abuse reports might have to be handled the old-fashioned way at Twitter, by internal review, which still creates a bottleneck. But hopefully the abuse reports about Direct Messages comprise only a small minority of abuse reports that Twitter receives, since most talk about abuse on Twitter comes in the form of public tweets. (If someone is "abusing" you via DMs, you can just unfollow them.)
Twitter could even be completely transparent about the entire voting process: "Your complaint has been reviewed by 10 people. 8 of them agreed that the tweet in question violated our guidelines. This is above our minimum threshold of 7 that triggers a higher-level review of this content." (Twitter presumably wouldn't want to tell the complainer who the voters on the panel were, since the complainer might harass the individual voters if the voting panel as a whole rejected the complaint. But there's no reason not to be transparent about the actual numbers.)
Why would someone sign up to volunteer to review abusive content? Maybe for the glimpse into strangers' lives. Maybe hoping to save copies of some of the porn contained in the tweets that get reported for abuse. (Of course, there are easier ways to get porn online, but maybe they get off on the fact that some particular pornographic image made someone angry and upset enough to report it.) Maybe they altruistically believe it's part of their civic duty towards the Twitter community. Maybe because they're bored.
Whatever people's myriad motivations for signing up, the important thing is that there's still a statistically significant difference between the number of "yes" votes received when content truly is abusive, and when it's not. Even if you have people signing up as reviewers for all kinds of weird reasons, a tweet like "fucking die feminist moron i'm coming after u and raping u" is still going to receive, on average, more "yes" votes than a tweet like "I respectfully disagree, so let's go our separate ways".
If Twitter were nervous about rolling out a system like this, ceding control of the abuse-report-handling process to a pool of volunteers, they could always do their own random sampling of the random-sample-voting system, to see how it was working. An internal auditor could pull 100 of the abuse report cases that have been handled by the random-sample-voting system recently, decide in each case whether the tweet did in fact violate the abuse guidelines, and then look to see if the voting system reached the same answer. As a control in the experiment, look at some abuse reports that were routed to the old-fashioned internal review panel during the same period, see how they handled the reports, and see how they fared in comparison. I would confidently bet money that the random sample voting system would handle the abuse reports more accurately, and faster, as well.
This won't do much to deter abusers who create an endless series of throwaway accounts for harassment purposes, which makes it futile to block or report any particular account. But it would at least get step zero right, which is to correctly adjudicate whether a tweet is abusive or not. And it would do it in a way that is scalable, non-gameable, and transparent. Plus a few volunteers would get an interesting story to tell at dinner.
-
Syrian Electronic Army Takes Credit For News Site Hacking
New submitter ddtmm writes The Syrian Electronic Army is claiming responsibility for the hacking of multiple news websites, including CBC News. Some users trying to access the CBC website reported seeing a pop-up message reading: "You've been hacked by the Syrian Electronic Army (SEA)." It appears the hack targeted a network used by many news organizations and businesses. A tweet from an account appearing to belong to the Syrian Electronic Army suggested the attacks were meant to coincide with the U.S. Thanksgiving on Thursday. The group claimed to have used the domain Gigya.com, a company that offers businesses a customer identity management platform, to hack into other sites via GoDaddy, its domain registrar. Gigya is "trusted by more than 700 leading brands," according to its website. The hacker or hackers redirected sites to the Syrian Electronic Army image that users saw. Gigya's operations team released a statement Thursday morning saying that it identified an issue with its domai registrar at 6:45 a.m. ET. The breach "resulted in the redirect of the Gigya.com domain for a subset of users," the company said. Among the websites known to be hacked so far are New York Times, Chicago Tribune, CNBC, PC World, Forbes, The Telegraph, Walmart and Facebook. -
Windows 10 To Feature Native Support For MKV and FLAC
jones_supa writes Windows Media Player is going to become a more useful media player for those who want to play geeky file formats. Microsoft has earlier confirmed that Windows 10 will come with native support for Matroska Video, but the company now talks about also adding FLAC support. Microsoft's Gabriel Aul posted a teaser screenshot in Twitter showing support for this particular format. It can be expected to arrive in a future update for people running the Windows 10 Technical Preview. Not many GUI changes seem to be happening around Media Player, but work is done under the hood. -
Longtime Debian Developer Tollef Fog Heen Resigns From Systemd Maintainer Team
An anonymous reader writes Debian developer Tollef Fog Heen submitted his resignation to the Debian Systemd package maintainers team mailing list today (Sun. Nov. 16th, 2014). In his brief post, he praises the team, but claims that he cannot continue to contribute due to the "load of continued attacks...becoming just too much." Presumably, he is referring to the heated and, at times, even vitriolic criticism of Debian's adoption of Systemd as the default init system for its upcoming Jessie release from commenters inside and outside of the Debian community. Currently, it is not known if Tollef will cease contributing to Debian altogether. A message from his twitter feed indicates that he may blog about his departure in the near future. -
Education Chief Should Know About PLATO and the History of Online CS Education
theodp writes Writing in Vanity Fair, U.S. Secretary of Education Arne Duncan marvels that his kids can learn to code online at their own pace thanks to "free" lessons from Khan Academy, which Duncan credits for "changing the way my kids learn" (Duncan calls out his kids' grade school for not offering coding). The 50-year-old Duncan, who complained last December that he "didn't have the opportunity to learn computer skills" while growing up attending the Univ. of Chicago Lab Schools and Yale, may be surprised to learn that the University of Illinois was teaching kids how to program online in the '70s with its PLATO system, and it didn't look all that different from what Khan Academy came up with for his kids 40 years later (Roger Ebert remarked in his 2011 TED Talk that seeing Khan Academy gave him a flashback to the PLATO system he reported on in the '60s). So, does it matter if the nation's education chief — who presides over a budget that includes $69 billion in discretionary spending — is clueless about The Hidden History of Ed-Tech? Some think so. "We can't move forward," Hack Education's Audrey Watters writes, "til we reconcile where we've been before." So, if Duncan doesn't want to shell out $200 to read a 40-year-old academic paper on the subject (that's a different problem!) to bring himself up to speed, he presumably can check out the free offerings at Ed.gov. A 1975 paper on Interactive Systems for Education, for instance, notes that 650 students were learning programming on PLATO during the Spring '75 semester, not bad considering that Khan Academy is boasting that it "helped over 2000 girls learn to code" in 2014 (after luring their teachers with funding from a $1,000,000 Google Award). Even young techies might be impressed by the extent of PLATO's circa-1975 online CS offerings, from lessons on data structures and numerical analysis to compilers, including BASIC, PL/I, SNOBOL, APL, and even good-old COBOL. -
Comet Probe Philae Unanchored But Stable — And Sending Back Images
An anonymous reader writes with an update to the successful landing of the ESA's comet probe Philae, which (as mentioned yesterday) had problems attaching to the surface of the comet's Rosetta: "BBC now reports that Philae is stable on the surface. Although no source claims so, we can all imagine a faint humming of 'Still Alive' coming from the probe." Not just stable, but sending pictures while it can. From the article: The probe left Rosetta with 60-plus hours of battery life, and will need at some point to charge up with its solar panels. But early reports indicate that in its present position, the robot is receiving only one-and-a-half hours of sunlight during every 12-hour rotation of the comet. This will not be enough to sustain operations. As a consequence, controllers here are discussing using one of Philae's deployable instruments to try to launch the probe upwards and away to a better location. But this would be a last-resort option. New submitter Thanshin notes that the persistent Philae bounced a few times, and actually performed 3 landings, at 15:33, 17:26 & 17:33 UTC.Thanshin adds links to a handful of relevant Twitter feeds, if you want to follow in something close to real time: Philae2014; esa_rosetta; and Philae_MUPUS (MUlti PUrpose Sensor One). -
Comet Probe Philae Unanchored But Stable — And Sending Back Images
An anonymous reader writes with an update to the successful landing of the ESA's comet probe Philae, which (as mentioned yesterday) had problems attaching to the surface of the comet's Rosetta: "BBC now reports that Philae is stable on the surface. Although no source claims so, we can all imagine a faint humming of 'Still Alive' coming from the probe." Not just stable, but sending pictures while it can. From the article: The probe left Rosetta with 60-plus hours of battery life, and will need at some point to charge up with its solar panels. But early reports indicate that in its present position, the robot is receiving only one-and-a-half hours of sunlight during every 12-hour rotation of the comet. This will not be enough to sustain operations. As a consequence, controllers here are discussing using one of Philae's deployable instruments to try to launch the probe upwards and away to a better location. But this would be a last-resort option. New submitter Thanshin notes that the persistent Philae bounced a few times, and actually performed 3 landings, at 15:33, 17:26 & 17:33 UTC.Thanshin adds links to a handful of relevant Twitter feeds, if you want to follow in something close to real time: Philae2014; esa_rosetta; and Philae_MUPUS (MUlti PUrpose Sensor One). -
Comet Probe Philae Unanchored But Stable — And Sending Back Images
An anonymous reader writes with an update to the successful landing of the ESA's comet probe Philae, which (as mentioned yesterday) had problems attaching to the surface of the comet's Rosetta: "BBC now reports that Philae is stable on the surface. Although no source claims so, we can all imagine a faint humming of 'Still Alive' coming from the probe." Not just stable, but sending pictures while it can. From the article: The probe left Rosetta with 60-plus hours of battery life, and will need at some point to charge up with its solar panels. But early reports indicate that in its present position, the robot is receiving only one-and-a-half hours of sunlight during every 12-hour rotation of the comet. This will not be enough to sustain operations. As a consequence, controllers here are discussing using one of Philae's deployable instruments to try to launch the probe upwards and away to a better location. But this would be a last-resort option. New submitter Thanshin notes that the persistent Philae bounced a few times, and actually performed 3 landings, at 15:33, 17:26 & 17:33 UTC.Thanshin adds links to a handful of relevant Twitter feeds, if you want to follow in something close to real time: Philae2014; esa_rosetta; and Philae_MUPUS (MUlti PUrpose Sensor One). -
Philae Lands Successfully On Comet
The European Space Agency has confirmed that the Philae probe has successfully landed on the comet 67P/Churyumov–Gerasimenko and established contact with headquarters. The harpoons have deployed and reeled in the slack, and the landing gear has retracted. (Edit: They're now saying the harpoons didn't fire after all.) There are no photos from the surface yet, but the Rosetta probe snapped this picture of Philae after initial separation, and Philae took this picture of Rosetta. Emily Lakdawalla has a timeline of the operation (cached). She notes that there was a problem with the gas thruster mounted on top of the lander. The purpose of the thruster was to keep the lander on the comet after landing, since there was a very real possibility that it could bounce off. (The comet's local gravity is only about 10^-3 m/s^2.) The pins that were supposed to puncture the wax seal on the jet were unable to do so for reasons unknown. Still, the jet did not seem to be necessary. The official ESA Rosetta site will be continually updating as more data comes back. -
Philae Lands Successfully On Comet
The European Space Agency has confirmed that the Philae probe has successfully landed on the comet 67P/Churyumov–Gerasimenko and established contact with headquarters. The harpoons have deployed and reeled in the slack, and the landing gear has retracted. (Edit: They're now saying the harpoons didn't fire after all.) There are no photos from the surface yet, but the Rosetta probe snapped this picture of Philae after initial separation, and Philae took this picture of Rosetta. Emily Lakdawalla has a timeline of the operation (cached). She notes that there was a problem with the gas thruster mounted on top of the lander. The purpose of the thruster was to keep the lander on the comet after landing, since there was a very real possibility that it could bounce off. (The comet's local gravity is only about 10^-3 m/s^2.) The pins that were supposed to puncture the wax seal on the jet were unable to do so for reasons unknown. Still, the jet did not seem to be necessary. The official ESA Rosetta site will be continually updating as more data comes back. -
Philae Lands Successfully On Comet
The European Space Agency has confirmed that the Philae probe has successfully landed on the comet 67P/Churyumov–Gerasimenko and established contact with headquarters. The harpoons have deployed and reeled in the slack, and the landing gear has retracted. (Edit: They're now saying the harpoons didn't fire after all.) There are no photos from the surface yet, but the Rosetta probe snapped this picture of Philae after initial separation, and Philae took this picture of Rosetta. Emily Lakdawalla has a timeline of the operation (cached). She notes that there was a problem with the gas thruster mounted on top of the lander. The purpose of the thruster was to keep the lander on the comet after landing, since there was a very real possibility that it could bounce off. (The comet's local gravity is only about 10^-3 m/s^2.) The pins that were supposed to puncture the wax seal on the jet were unable to do so for reasons unknown. Still, the jet did not seem to be necessary. The official ESA Rosetta site will be continually updating as more data comes back. -
What Happens When Nobody Proofreads an Academic Paper
An anonymous reader writes: Drafts are drafts for a reason. Not only do they tend to contain unpolished writing and unfinished thoughts, they're often filled with little notes we leave ourselves to fill in later. Slate reports on a paper recently published in the journal Ethology that contained an unfortunate self-note that made it into the final, published article, despite layers upon layers of editing, peer review, and proofreading. In the middle of a sentence about shoaling preferences, the note asks, "should we cite the crappy Gabor paper here?" When notified of the mistake, the publisher quickly took it down and said they would "investigate" how the line wasn't caught. One of the authors said it wasn't intentional and apologized for the impolite error. -
Rosetta's Philae Probe To Land On Comet Tomorrow
An anonymous reader writes: After more than 10 years travelling, the Rosetta mission will take its next, momentous step by landing the Philae probe on comet 67P/Churyumov-Gerasimenko tomorrow. How f!@#$%ing cool is that?! Follow the landing live using the webcast, blog, or Twitter feed. (Keep in mind there's a 28-minute delay due to the time it takes the radio signals to reach Earth). Here's the scheduling info: "For the primary landing scenario, targeting Site J, Rosetta will release Philae at 08:35 GMT/09:35 CET at a distance of 22.5 km from the center of the comet, landing about seven hours later. The one-way signal travel time between Rosetta and Earth on 12 November is 28 minutes 20 seconds, meaning that confirmation of the landing will arrive at Earth ground stations at around 16:00 GMT/17:00 CET. If a decision is made to use the backup Site C, separation will occur at 13:04 GMT/14:04 CET, 12.5 km from the center of the comet. Landing will occur about four hours later, with confirmation on Earth at around 17:30 GMT/18:30 CET. The timings are subject to uncertainties of several minutes."
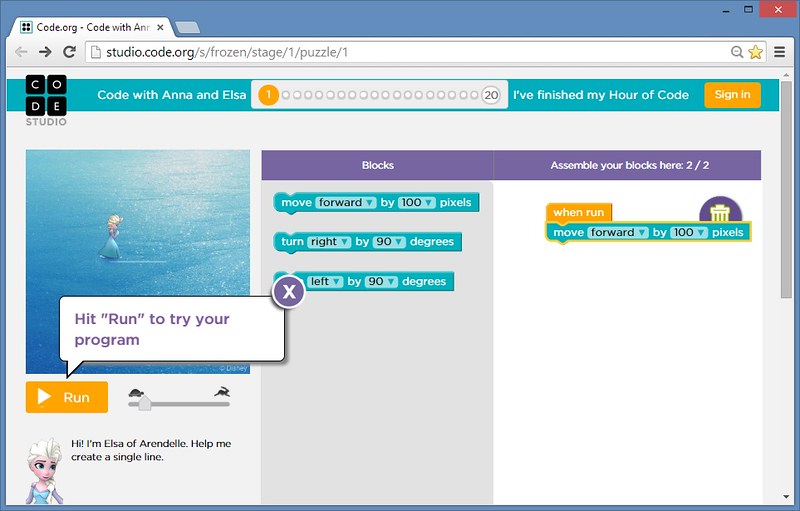{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}