 Slashdot Mirror
Slashdot Mirror
Domain: slashdot.org
Stories and comments across the archive that link to slashdot.org.
Stories · 37,380
-
Can High-Tech Academia Survive Silicon Valley's Talent Binge?
An anonymous reader writes: Earlier this year, Carnegie Mellon had one of the most capable robotics research centers in the world. Then, Uber hired away dozens of workers in a frantic push to jump start development of autonomous driving technology, which left CMU reeling. Now the NY Times asks whether such high-tech labs can continue to exist; Silicon Valley seems ready to flood such organizations with money whenever a vital new technology is almost ripe. "Carnegie Mellon's experience is a familiar one in the world of high-tech research. As a field matures, universities can wake up one day to find money flooding the premises; suddenly they're in a talent war with deep-pocketed firms from Silicon Valley. The impacts are also intellectual. When researchers leave for industry, their expertise winks off the map; they usually can't publish what they discover — or even talk about it over drinks with former colleagues. ... [Also], the intellectual register of their work changes. No more exploring hard, ''basic'' problems out of deep curiosity; they need to solve problems that will make their employers money." -
Ask Slashdot: Definitive Password Management Best Practices Using OSS?
jmcbain writes: I am an software engineer for a client-server user account system handling both Web and smartphone clients. I have been searching for definitive and crystal-clear best practices for managing user account and password data using open-source software, but I have only cobbled together a complete picture from dozens of websites. I currently have a system that sends passwords over SSL and performs bcrypt hashing for storage and authentication checking at the server side. Is that good enough? The recent Ashley Madison breach and the exposure of MD5-hashed passwords (as opposed to bcrypt) has me worried again. Can someone please suggest a definitive, cookbook-style Web resource or book on how to use open-source software to handle user passwords for multiple client-server scenarios? I would like answers to questions such as: Where do I perform hashing (smartphone/web client or server)? What hash algorithm should I use? How do I store the hashes? How can clients recover forgotten passwords? etc. -
First Library To Support Anonymous Internet Browsing Halts Project After DHS Email
An anonymous reader writes with an update to the news we discussed in July that a small library in New Hampshire would be used as a Tor exit relay. Shortly after the project went live, the local police department received an email from the Department of Homeland Security. The police then met with city officials and discussed all the ways criminals could make use of the relay. They ultimately decided to suspend the project, pending a vote of the library board of trustees on Sept. 15. DHS spokesman Shawn Neudauer said the agent was simply providing "visibility/situational awareness," and did not have any direct contact with the Lebanon police or library. "The use of a Tor browser is not, in [or] of itself, illegal and there are legitimate purposes for its use," Neudauer said, "However, the protections that Tor offers can be attractive to criminal enterprises or actors and HSI [Homeland Security Investigations] will continue to pursue those individuals who seek to use the anonymizing technology to further their illicit activity." ...Deputy City Manager Paula Maville said that when she learned about Tor at the meeting with the police and the librarians, she was concerned about the service’s association with criminal activities such as pornography and drug trafficking. "That is a concern from a public relations perspective and we wanted to get those concerns on the table," she said. -
John McAfee On Why He's Running For President
Velcroman1 writes: Our government is in a dysfunctional state. It is also illiterate when it comes to technology. Technology is not a tool that should be used for a government to invade our privacy. Technology should not be the scapegoat when we fail to protect our digital assets and tools of commerce. These are matters of priorities." So says John McAfee, offering up a brief explanation into why he's running for president. As noted earlier on slashdot, McAfee has filed paperwork already (PDF) to found a new party. -
Interviews: RMS Answers Your Questions
The Free Software Foundation will be celebrating its 30th anniversary on Oct. 3rd. Recently, you had a chance to ask its founder Richard Stallman about GNU/Linux, free software, and other issues of public concern. Below you'll find his answers to your questions. Learn more about how you can join the FSF here, and help fight the good fight. Companies Selling Actually Free Software?
by eldavojohn
I found your piece on selling free software to be pretty logical on paper. However, has it ever worked in the wild? Can you name companies or revenues that currently operate on this idea (and I'm not talking about services or support of the software)? I simply can't come up with a widely used monetized piece of software licensed under the GNU GPL whereby the original software was sold at a single price and shipped with the source code -- free for the original purchaser to distribute by the license's clauses. Can you list any revenue generation from that? I must admit I'm not exactly enamored with paying for free software (as in your definition of free) before it's written yet I cannot think of any other way this would fairly compensate the developer.
RMS: I have to exert all my self control to respond civilly after seeing the word "monetize". Implicit in that word is the idea that you want to turn everything into money. The only point in writing a program is to turn it into money. Feh!
I don't object to making money in an ethical way. I don't object to raising money ethically to work on free software. But when you talk in terms of "monetizing", your thoughts have become twisted in a direction that will lead you to be a parasite.
Simply selling copies of free software was an effective way to raise money when I wrote that article, and remained so through the early 90s. As you've noted, that isn't usually the case.
But we have effective ethical ways of funding free software development. For instance, selling support to commercial users, selling exceptions, developing solutions for clients' internal use, and crowdfunding. Simply asking satisfied users for donations works for some developers.
How do you feel about web applications?
by bigsexyjoe
I know you don't like Software as a Service. However, there are some web applications that really only work as a web application. Slashdot is an example of this. Do you feel that creators of web applications should be obliged to make their source code available? Also, if I am employed as web application developer, am I a bad person?
RMS: That's not quite correct. What I reject is somewhat different: Service as a Software Substitute (SaaSS). This means a service that does a job that you could do by running a program in your own computer.
The two concepts overlap only partly. I don't think I disapprove of _all_ the things you'd call "Software as a Service", because not all of them are SaaSS.
I don't like to use the term "web application" because it is designed to ignore a distinction I consider crucial, between the software in the server and the software in the client. Even if they are designed to work together, they raise totally different ethical issues.
To avoid confusing them, I insist on talking separately about "services" and "client programs". Of course, I reject a non-free client program like any other non-free program.
As for the server software that implements a service, that doesn't directly affect me as a user of the service. I don't even need to know whether it's done with software or by humans. For your sake, though, if you use software in your server, I hope it is free-libre so that it respects your freedom and you have control over your own server.
Slashdot is a web service. In the past, one could access it with a free web browser -- no special client software was needed. Maybe that is still true -- I don't know. Many web servers send programs to run in the user's browser, generally in the form of Javascript code. Most of these programs are proprietary, and I use LibreJS to prevent those from running in my computer. That means there are services that won't work for me. I value my freedom too much to run their non-free software.
If Slashdot sends Javascript code to the user, it should make sure that code carries a free license and (if minimized or otherwise transformed) a pointer to the real source code.
However, I am not happy about automatically running a program sent to my browser by a server even if it carries a free license. For users to maintain a modified version of that software is inconvenient even if it is authorized. Thus, I'd rather not run substantial Javascript code. If I am going to run a program on my computer, I want to install it the same way I install Emacs, GNOME or LibreOffice.
As always, I don't want to talk about "web applications". We must keep web services and client programs separate.
Ethical treatment of your users calls for making all your client-side software (including Javascript) free.
I don't think web services are wrong _in general_, but they raise various ethical issues. For instance, you shouldn't collect any data about your users, or remember what they do on the site, unless the essence of the service consists of remembering this data. A secondary "social" (I'd rather call it "antisocial") functionality does not justify imposing surveillance on users who want only the principal functionality.
Do not try to excuse adding a brick to the wall of massive surveillance.
Re: On the matter of smartphones
by Anonymous Coward
How do we take smart phones out of the control of corporations and back into user's control? There's GNU/Linux for computers which gives the users freedoms, but there's no equivalent for smart phones yet. I see this as a serious problem because people are largely abandoning computers and laptops to move toward smart phones and tablets. So my question is: How to make a smartphone that truly has the user's interest at heart? (Not trying to sell them apps, spy and track on them, restrict them to a walled garden, etc.)
RMS: There are phones on which you can run Replicant, the free version of Android. Some peripherals don't work, but you can do calls and texts.
Portable phones have another problem: the radio modem processor which talks with the phone network always runs proprietary software, written for a secret processor. Nowadays it checks signatures, so that software is tivoized; Even if we had free replacement software, the processor would refuse to run it.
Even worse, that proprietary program has a universal back door, so it can be altered by commands sent by radio. In most phone models, the modem processor can take control of the main processor and replace its software. Thus, even if you have installed Replicant, the phone company and others have the power to remotely overwrite it with something nasty.
The usual "something nasty" is software that listens all the time and transmits all the speech it hears.
By designing the phone carefully, it is possible to prevent the modem processor from sabotaging the main processor or from accessing the microphone. Unfortunately, we know of no such phone model that can use its peripherals without non-free drivers.
There is another problem that we can never fix, because it is inherent in the way the cellular network works. The phone sends signals all the time it is turned on (except in airplane mode), and the phone network uses those signals to determine where the phone is located. That system records where the phone has been.
In other words, every portable phone is a tracking device.
I know of a possible fix for that: build a one-way pager into the phone. Then you can keep the phone in "airplane mode" (no tracking) nearly all the time, and tell people that they should page you when they have something to say to you. When you are paged, you can decide when it is safe to connect to the phone radio network and reveal your location -- presumably when you are in a place that is not sensitive.
The future of private and free tech?
by Anonymous Coward
My biggest concern in this day and age is the dumbing down and commercialization of computing. What used to be open, interoperable programs has now turned into ad based, proprietary apps. We've gone from having something like Pidgin being able to run all instant messaging clients ad free to now having to download a separate app for every messenger, for example (no one uses the older ones anymore, or they've been shut down). Also, free standards like email have been falling out of favor due to corporate pushes to lock down users into walled gardens like Facebook. Of course there's always the option of not using these proprietary apps, but it really hinders your social life. Also, programs (now called "apps") are designed to milk the users for money, rather than to benefit the users, as you know is the case with things like " defective by design" DRM.
Is there any way computing can truly become free and user centric again, or do you think it's truly a lost cause? If so, how can we do it without losing connection with the rest of the world who will not give up their FB/WhatsApp/Kik (and don't answer their phone or emails anymore)?
RMS: Please don't associate me with advocacy of something "open". I have never used that term.
I disagree with “open source”, of course. However, before that term was coined in 1998, the term "open software" was used to mean something else. It meant that users could choose from various components that could interoperate. I think that's the term this question refers to.
Unix was referred to as "open software", in that sense. However, although Unix was "open", it was not free software or even close to it. Being "open" meant that the user had (in theory) a choice between various proprietary programs -- but that's not freedom, that's only having the chance to choose your master. Being "open" was insufficient because what we need is "free". That's why I needed to write a free operating system, the GNU operating system, to replace Unix.
That's why "GNU" stands for "GNU's Not Unix".
The first step in opposing these evil tendencies is to refuse, firmly and persistently, to yield to them. No matter what anyone else does, I will never be a used of Facebook. I will never use those messenger cr...apps because they are non-free software; not to mention that I won't use the non-free platforms they run on.
If that means there are some people I can't talk with, I will live with that. I might want to talk with them, but not badly enough to surrender my freedom to do it.
Your question presents the issue as an all-or-nothing binary choice, total victory or total defeat. But that's not how it is.
It's a shame that they use those, but we don't need them to _stop_ using those things just in order for us to talk with them. It's enough for them to resume using email and phone calls.
You could send these people a card, once in a while, saying "I'd still like to be friends with you, if you'd like to talk by email or a phone call. I won't be used by Facebook or run WhatsApp. I can't talk with you that way, but that's nothing personal. I'd like to see you some day."
Then either they get back to you or they don't.
On the matter of privacy
by GeekWithAKnife
In your opinion, how can a government strike a fair balance between privacy and snooping powers? Given that the government needs to be able to spy on potentially dangerous people and groups and such desires have grown legs, wings and multiple heads over the years...
RMS: Over the past 20 years, digital technology has been used to implement a tremendous increase in surveillance. Most citizens of the US live under far more surveillance than the citizens of the Soviet Union knew.
As a result, the balance between privacy and investigation is totally skewed. It's not just a little off, it is wildly wrong, so much that it threatens democracy. Democracy depends on whistleblowers to tell the public what the government is doing, so if surveillance is enough for the government to find and imprison whistleblowers, democracy is directly threatened.
We need to redesign digital systems so that they do not accumulate dossiers about people other than court-designated suspects. Read here for more arguments, plus suggestions about how to do this.
We should also praise Edward Snowden vigorously on every pertinent occasion. The US political class -- which mostly tolerates or promotes oppressive surveillance -- condemns him and continues to demonize him. It's up to us to oppose that.
This is why I lead "three cheers for Edward Snowden" when I talk about surveillance in my speeches.
The next big thing
by laffer1
What do you see as the next big issue coming up with software licensing that isn't addressed with the existing GPL and AGPL licenses?
RMS: I don't know of any. GPL version 3 seems to be what we need; there is no flaw or problem that would require another license.
People have suggested making a "Lesser Affero GPL", and I agree it might be a good thing -- it would take the form of an exception added to the Affero GPL -- but the first step is to figure out what it ought to _do_. What uses should it permit that the existing Affero GPL does not?
I am interested in getting suggestions about this from developers that have real software they might want to release under such a license.
Microsoft's Contributions to Free Software
by jrnvk
It seems like Microsoft is starting to contribute more to free products. What's your take on them joining the community, given their rather different approach in historical times?
RMS: Microsoft's most important software continues to be proprietary, and malware too. In fact, Windows 10 is even nastier malware than Windows 8 was.
This is an enormous wrong, and we can't excuse Microsoft for this just because it develops some free programs also.
What are your views on console gaming?
by Kethinov
It's long been possible to run entirely free software on a PC, but the world of game consoles has been a proprietary hellscape for many years. In recent years there's been an attempt to open it up in some very modest ways, mainly through the proliferation of Android "microconsoles" and other Android-based set top boxes. Do you find these new developments to be a step in the right direction and are you worried as I am that they're not catching on very well?
RMS: Alas, I know nothing about them. Since you say "open it up", and "open" is not the same thing as "free", I can't tell from your question whether those projects do, or can, lead to a community based on free games.
What I can say is that I wouldn't run a non-free game any more than I'd run a non-free operating system or a non-free compiler or a non-free messaging program.
Teaching about Free Software in CS courses
by daveagp
I teach CS at a university, often including introductory courses. Regarding free software, what message(s) is/are the most vital to communicate to people who are writing computer programs for the first time?
RMS: Here's the message I would give:
If you become skilled at programming, you will come to notice how non-free programs, denying you the source code, restrict and oppress you. But non-free software is prevalent only because the users tolerate it. As recognition of its injustice spreads, we will be able to put an end to it.
I have chosen free software for this class because I value my freedom and I refuse to give it up. Also because I don't want to be responsible for leading you to surrender your freedom.
Please read this for more about this issue.
Then I'd prepare to spend the next class session discussing that reading.
GFDL?
by ISayWeOnlyToBePolite
The Gnu Free Documentation License (GFDL) has not been embraced with nearly as much love as the GPL and numerous issues have been raised:
- Non compatibility with GPL (both ways).
- Non-freeness (as deemed by Debian) of invariant sections.
- Cumbersomeness of having to print the full license when distributing physical printouts.
Wikipedia for example does not accept contributions licensed under the GFDL only. What do you see as a way forward in addressing the issues raised regarding the GFDL?
RMS: That is a fact.- Two different copyleft licenses, each with different requirements, can't help being incompatible. Thus, CC-SA is incompatible with the GNU GPL also. The only way to avoid that is if one presents the other as an option, as some other free licenses permit relicensing under the GPL.
- You'll have to talk with the Debian people about that. I am not responsible for their views.
- The GNU GPL has the same requirement: every copy of the work must
_come with_ a copy of the license. I adopted that criterion so that
works won't get separated from their license.
Under today's insane copyright law, a copyright can last for more than a century. We can expect Disney to try to buy a 20-year increase soon, as it did in 1998. If you live 40 more years, works that you write today will still be copyrighted in 2125, unless we have defeated the copyright industry by then.
We have convenient ways for a work to refer to a license, and I expect they will still work 5 years from now, but we can't count on them to function in a hundred years. In 10 or 20 years, the World Wide Web could be wiped out by the cr...apps that most mobile operating systems promote. Or, considering a much smaller change, the US government might confiscate the domain gnu.org for posting forbidden dissident material such as this.
Keeping a copy of the license with the work is the only way we can make sure people several decades from now will see what how are allowed to use it.
I was disappointed when Wikipedia decided to change to CC-SA as its primary license, but given that it has done so, I can't criticize this policy.
I know of one way [of addressing the issues raised regarding the GFDL]: release your documentation under the GFDL. -
An Algorithm To Stop Joke Plagiarists
Bennett Haselton writes: The comedy world crucified Josh "Fat Jew" Ostrovsky for building his career on re-tweeting other people's jokes without attribution. But Twitter, or whichever company rises as their successor, could easily implement an algorithm that could stop plagiarists from building a following, while still rewarding joke writers who come up with original content. Read on for Bennett's take on how such a system could work.The basic algorithm is very similar to the random-sample-voting algorithm that I've advocated as a way to stop vote manipulation on Digg, how to handle abuse reports in a scalable way on Twitter and on Facebook, and how to identify the best ideas submitted to the White House's "We The People" petition site. The algorithm can be used to rate the best jokes (at least according to the average rating of users, not according to some Platonic ideal), while still flagging plagiarized jokes and preventing anyone from building up a following by using them.
Under the algorithm, suppose a subset of users -- let's say, 1 million -- signs up to receive tweets in the general humor category. When a would-be amateur comedian comes up with a funny tweet, then in addition to tweeting it to their followers (if they have any), they can submit it to the humor category generally. The joke is first pushed to the feeds of, say, 1,000 randomly selected users, who have the option of rating it (independently of each other, without seeing the opinions of other raters). Once the joke has acquired enough ratings to constitute a statistically significant sample -- so that the average rating really does reflect the community's "opinion" of the joke -- then the joke gets released into the general pool of jokes available to all 1 million users subscribed to the "humor" category. Those users can decide what threshold of quality they want to set for the jokes that show up in their feed -- for example, if you only want to see jokes that got an average rating of 9 out of 10 or higher, you might only see 50 a day, but if you can lower your standards down to an 8, you might see 100 or 200. And if a user really likes a particular joke that they see in their "threshold feed," they can browse the other jokes in that author's Twitter feed and decide whether to follow them.
So if your joke sucks, it will only end up wasting the time of about 1,000 people, but if it gets a high rating, it will be available in the feeds of up to 1 million people. Thus from the user's point of view, only about 0.1% of the jokes that they see in their feed, are sucky jokes that were pushed to them as part of an initial "focus group" to measure their quality; the other 99.9% is made up of jokes that met whatever threshold they set for the average rating.
As I've stressed in the case of other applications of the random-sample-voting algorithm, this system is scalable, because the number of available reviewers grows as the community grows. It's also non-gameable -- because the raters are randomly selected, even if you create a large number of zombie accounts to try and upvote your own joke, the zombies won't constitute a significant portion of the raters, if the raters are selected from the entire pool of 1 million users.
Still, even under this system, it would be possible to take a highly rated joke and re-word it slightly (to fool any text filters looking for blatant copy-and-paste jobs), and pass it off as your own, hoping that your re-worded version will also get pushed out to a wide audience and net you some extra followers. To prevent this, you can implement a "duplicate" flagging feature that also relies on the random-sample-voting system:
- If a user recognizes a joke as a re-worded version of someone else's tweet, they can flag it as a "duplicate", with a link to the earlier tweet that they think is similar. (Flagging it as intentional "plagiarism" would be a bit harsh, since it's quite common for multiple comedians to come up with the same joke.)
- The flagged joke, along with a copy of the earlier joke, would once again be sent out to a random sample of subscribers to the humor category, who are then asked to vote on whether the two jokes are substantially similar.
- If a statistically significant majority of those users vote that the two jokes are essentially duplicates, then the second tweet gets displayed with a flag icon (shorthand for "our users have identified this as a duplicate of an earlier joke") with a link back to other tweet that was identified as an earlier version of essentially the same joke.
- If a majority votes that the two jokes are not similar, then nothing happens. Optionally, if an overwhelming majority of the users vote that the two jokes are not at all similar, then some kind of reputation point penalty could be applied to the user who flagged the second joke as a "duplicate". This discourages people from frivolously duplicate-flagging a joke.
This does have the unfortunate result that if you unintentionally write a joke that duplicates someone else's, it will still end up with the "duplicate" flag after users recognize the similarity to the earlier version. This is, however, something that I don't think any algorithm can solve, because it's impossible to detect the difference between someone copying another person's joke and independently coming up with it on their own. A comedian whose joke ends up being labeled with the "duplicate flag", just because someone else came up with the same gag first, could leave the joke in their feed, but they might consider the duplicate flag to be a mild embarrassment.
On the other hand, if you're just a full-time plagiarist like the Fat Jew, and virtually all of your jokes end up being flagged as clones of other people's work, then your entire feed will be littered with "duplicate" flags that mark you as a hack. Depending on whether Twitter's terms of service prohibit serial plagiarism, your account could even get suspended.
Meanwhile, anybody could still set themselves up as a curator who re-tweets other people's jokes with the original attribution intact. Many users would find that they wouldn't need curators at all, when they can just subscribe to all jokes that get an average rating of, say, 8.5 or higher, but if your humor happens to align very closely with the kind of jokes picked out by a particular curator, you could subscribe to get jokes re-tweeted directly from them. And since the original attribution would be intact, any time you saw a joke that you really liked, you could subscribe to updates directly from that author. Curating can still serve a valuable function that plagiarism does not.
In addition to dealing with plagiarists, though, what I think is interesting about this system is how it would overturn everything we know about what it takes to build a reputation. In the current ecosystem, to build a following, it helps to have good content, but what really matters is hustle -- making friends in high places who might be able to give you a boost with a re-tweet or a shout-out, looking out for opportunities for free publicity, etc. Well, I admire the people who have the energy to keep that up. But from an economic standpoint, "hustling" is a non-productive activity, because it doesn't actually make your content better, it's just an attempt to crowd out someone else's content with your own, which may be better or worse, and it's a zero-sum game. The "hustling" ecosystem is also non-optimal from the user's point of view -- if Joe is better at writing jokes, but Bob is better at hustling, then you as the user are more likely to be exposed to Bob's sub-optimal content, and may never even hear about Joe.
The random-sample rating system, however, makes the entire notion of "hustling" obsolete. The only way to get your content in front of lots of people, is to write content that gets a high average rating from the initial sample of people who see it.
If such a system ever gets implemented, by Twitter or any other company, maybe the Fat Jew can find out if any of his own original material meets the bar. But don't hold your breath -- the marquee joke currently displayed on his Twitter feed is "You can't get an STD if you never get tested."
-
An Algorithm To Stop Joke Plagiarists
Bennett Haselton writes: The comedy world crucified Josh "Fat Jew" Ostrovsky for building his career on re-tweeting other people's jokes without attribution. But Twitter, or whichever company rises as their successor, could easily implement an algorithm that could stop plagiarists from building a following, while still rewarding joke writers who come up with original content. Read on for Bennett's take on how such a system could work.The basic algorithm is very similar to the random-sample-voting algorithm that I've advocated as a way to stop vote manipulation on Digg, how to handle abuse reports in a scalable way on Twitter and on Facebook, and how to identify the best ideas submitted to the White House's "We The People" petition site. The algorithm can be used to rate the best jokes (at least according to the average rating of users, not according to some Platonic ideal), while still flagging plagiarized jokes and preventing anyone from building up a following by using them.
Under the algorithm, suppose a subset of users -- let's say, 1 million -- signs up to receive tweets in the general humor category. When a would-be amateur comedian comes up with a funny tweet, then in addition to tweeting it to their followers (if they have any), they can submit it to the humor category generally. The joke is first pushed to the feeds of, say, 1,000 randomly selected users, who have the option of rating it (independently of each other, without seeing the opinions of other raters). Once the joke has acquired enough ratings to constitute a statistically significant sample -- so that the average rating really does reflect the community's "opinion" of the joke -- then the joke gets released into the general pool of jokes available to all 1 million users subscribed to the "humor" category. Those users can decide what threshold of quality they want to set for the jokes that show up in their feed -- for example, if you only want to see jokes that got an average rating of 9 out of 10 or higher, you might only see 50 a day, but if you can lower your standards down to an 8, you might see 100 or 200. And if a user really likes a particular joke that they see in their "threshold feed," they can browse the other jokes in that author's Twitter feed and decide whether to follow them.
So if your joke sucks, it will only end up wasting the time of about 1,000 people, but if it gets a high rating, it will be available in the feeds of up to 1 million people. Thus from the user's point of view, only about 0.1% of the jokes that they see in their feed, are sucky jokes that were pushed to them as part of an initial "focus group" to measure their quality; the other 99.9% is made up of jokes that met whatever threshold they set for the average rating.
As I've stressed in the case of other applications of the random-sample-voting algorithm, this system is scalable, because the number of available reviewers grows as the community grows. It's also non-gameable -- because the raters are randomly selected, even if you create a large number of zombie accounts to try and upvote your own joke, the zombies won't constitute a significant portion of the raters, if the raters are selected from the entire pool of 1 million users.
Still, even under this system, it would be possible to take a highly rated joke and re-word it slightly (to fool any text filters looking for blatant copy-and-paste jobs), and pass it off as your own, hoping that your re-worded version will also get pushed out to a wide audience and net you some extra followers. To prevent this, you can implement a "duplicate" flagging feature that also relies on the random-sample-voting system:
- If a user recognizes a joke as a re-worded version of someone else's tweet, they can flag it as a "duplicate", with a link to the earlier tweet that they think is similar. (Flagging it as intentional "plagiarism" would be a bit harsh, since it's quite common for multiple comedians to come up with the same joke.)
- The flagged joke, along with a copy of the earlier joke, would once again be sent out to a random sample of subscribers to the humor category, who are then asked to vote on whether the two jokes are substantially similar.
- If a statistically significant majority of those users vote that the two jokes are essentially duplicates, then the second tweet gets displayed with a flag icon (shorthand for "our users have identified this as a duplicate of an earlier joke") with a link back to other tweet that was identified as an earlier version of essentially the same joke.
- If a majority votes that the two jokes are not similar, then nothing happens. Optionally, if an overwhelming majority of the users vote that the two jokes are not at all similar, then some kind of reputation point penalty could be applied to the user who flagged the second joke as a "duplicate". This discourages people from frivolously duplicate-flagging a joke.
This does have the unfortunate result that if you unintentionally write a joke that duplicates someone else's, it will still end up with the "duplicate" flag after users recognize the similarity to the earlier version. This is, however, something that I don't think any algorithm can solve, because it's impossible to detect the difference between someone copying another person's joke and independently coming up with it on their own. A comedian whose joke ends up being labeled with the "duplicate flag", just because someone else came up with the same gag first, could leave the joke in their feed, but they might consider the duplicate flag to be a mild embarrassment.
On the other hand, if you're just a full-time plagiarist like the Fat Jew, and virtually all of your jokes end up being flagged as clones of other people's work, then your entire feed will be littered with "duplicate" flags that mark you as a hack. Depending on whether Twitter's terms of service prohibit serial plagiarism, your account could even get suspended.
Meanwhile, anybody could still set themselves up as a curator who re-tweets other people's jokes with the original attribution intact. Many users would find that they wouldn't need curators at all, when they can just subscribe to all jokes that get an average rating of, say, 8.5 or higher, but if your humor happens to align very closely with the kind of jokes picked out by a particular curator, you could subscribe to get jokes re-tweeted directly from them. And since the original attribution would be intact, any time you saw a joke that you really liked, you could subscribe to updates directly from that author. Curating can still serve a valuable function that plagiarism does not.
In addition to dealing with plagiarists, though, what I think is interesting about this system is how it would overturn everything we know about what it takes to build a reputation. In the current ecosystem, to build a following, it helps to have good content, but what really matters is hustle -- making friends in high places who might be able to give you a boost with a re-tweet or a shout-out, looking out for opportunities for free publicity, etc. Well, I admire the people who have the energy to keep that up. But from an economic standpoint, "hustling" is a non-productive activity, because it doesn't actually make your content better, it's just an attempt to crowd out someone else's content with your own, which may be better or worse, and it's a zero-sum game. The "hustling" ecosystem is also non-optimal from the user's point of view -- if Joe is better at writing jokes, but Bob is better at hustling, then you as the user are more likely to be exposed to Bob's sub-optimal content, and may never even hear about Joe.
The random-sample rating system, however, makes the entire notion of "hustling" obsolete. The only way to get your content in front of lots of people, is to write content that gets a high average rating from the initial sample of people who see it.
If such a system ever gets implemented, by Twitter or any other company, maybe the Fat Jew can find out if any of his own original material meets the bar. But don't hold your breath -- the marquee joke currently displayed on his Twitter feed is "You can't get an STD if you never get tested."
-
An Algorithm To Stop Joke Plagiarists
Bennett Haselton writes: The comedy world crucified Josh "Fat Jew" Ostrovsky for building his career on re-tweeting other people's jokes without attribution. But Twitter, or whichever company rises as their successor, could easily implement an algorithm that could stop plagiarists from building a following, while still rewarding joke writers who come up with original content. Read on for Bennett's take on how such a system could work.The basic algorithm is very similar to the random-sample-voting algorithm that I've advocated as a way to stop vote manipulation on Digg, how to handle abuse reports in a scalable way on Twitter and on Facebook, and how to identify the best ideas submitted to the White House's "We The People" petition site. The algorithm can be used to rate the best jokes (at least according to the average rating of users, not according to some Platonic ideal), while still flagging plagiarized jokes and preventing anyone from building up a following by using them.
Under the algorithm, suppose a subset of users -- let's say, 1 million -- signs up to receive tweets in the general humor category. When a would-be amateur comedian comes up with a funny tweet, then in addition to tweeting it to their followers (if they have any), they can submit it to the humor category generally. The joke is first pushed to the feeds of, say, 1,000 randomly selected users, who have the option of rating it (independently of each other, without seeing the opinions of other raters). Once the joke has acquired enough ratings to constitute a statistically significant sample -- so that the average rating really does reflect the community's "opinion" of the joke -- then the joke gets released into the general pool of jokes available to all 1 million users subscribed to the "humor" category. Those users can decide what threshold of quality they want to set for the jokes that show up in their feed -- for example, if you only want to see jokes that got an average rating of 9 out of 10 or higher, you might only see 50 a day, but if you can lower your standards down to an 8, you might see 100 or 200. And if a user really likes a particular joke that they see in their "threshold feed," they can browse the other jokes in that author's Twitter feed and decide whether to follow them.
So if your joke sucks, it will only end up wasting the time of about 1,000 people, but if it gets a high rating, it will be available in the feeds of up to 1 million people. Thus from the user's point of view, only about 0.1% of the jokes that they see in their feed, are sucky jokes that were pushed to them as part of an initial "focus group" to measure their quality; the other 99.9% is made up of jokes that met whatever threshold they set for the average rating.
As I've stressed in the case of other applications of the random-sample-voting algorithm, this system is scalable, because the number of available reviewers grows as the community grows. It's also non-gameable -- because the raters are randomly selected, even if you create a large number of zombie accounts to try and upvote your own joke, the zombies won't constitute a significant portion of the raters, if the raters are selected from the entire pool of 1 million users.
Still, even under this system, it would be possible to take a highly rated joke and re-word it slightly (to fool any text filters looking for blatant copy-and-paste jobs), and pass it off as your own, hoping that your re-worded version will also get pushed out to a wide audience and net you some extra followers. To prevent this, you can implement a "duplicate" flagging feature that also relies on the random-sample-voting system:
- If a user recognizes a joke as a re-worded version of someone else's tweet, they can flag it as a "duplicate", with a link to the earlier tweet that they think is similar. (Flagging it as intentional "plagiarism" would be a bit harsh, since it's quite common for multiple comedians to come up with the same joke.)
- The flagged joke, along with a copy of the earlier joke, would once again be sent out to a random sample of subscribers to the humor category, who are then asked to vote on whether the two jokes are substantially similar.
- If a statistically significant majority of those users vote that the two jokes are essentially duplicates, then the second tweet gets displayed with a flag icon (shorthand for "our users have identified this as a duplicate of an earlier joke") with a link back to other tweet that was identified as an earlier version of essentially the same joke.
- If a majority votes that the two jokes are not similar, then nothing happens. Optionally, if an overwhelming majority of the users vote that the two jokes are not at all similar, then some kind of reputation point penalty could be applied to the user who flagged the second joke as a "duplicate". This discourages people from frivolously duplicate-flagging a joke.
This does have the unfortunate result that if you unintentionally write a joke that duplicates someone else's, it will still end up with the "duplicate" flag after users recognize the similarity to the earlier version. This is, however, something that I don't think any algorithm can solve, because it's impossible to detect the difference between someone copying another person's joke and independently coming up with it on their own. A comedian whose joke ends up being labeled with the "duplicate flag", just because someone else came up with the same gag first, could leave the joke in their feed, but they might consider the duplicate flag to be a mild embarrassment.
On the other hand, if you're just a full-time plagiarist like the Fat Jew, and virtually all of your jokes end up being flagged as clones of other people's work, then your entire feed will be littered with "duplicate" flags that mark you as a hack. Depending on whether Twitter's terms of service prohibit serial plagiarism, your account could even get suspended.
Meanwhile, anybody could still set themselves up as a curator who re-tweets other people's jokes with the original attribution intact. Many users would find that they wouldn't need curators at all, when they can just subscribe to all jokes that get an average rating of, say, 8.5 or higher, but if your humor happens to align very closely with the kind of jokes picked out by a particular curator, you could subscribe to get jokes re-tweeted directly from them. And since the original attribution would be intact, any time you saw a joke that you really liked, you could subscribe to updates directly from that author. Curating can still serve a valuable function that plagiarism does not.
In addition to dealing with plagiarists, though, what I think is interesting about this system is how it would overturn everything we know about what it takes to build a reputation. In the current ecosystem, to build a following, it helps to have good content, but what really matters is hustle -- making friends in high places who might be able to give you a boost with a re-tweet or a shout-out, looking out for opportunities for free publicity, etc. Well, I admire the people who have the energy to keep that up. But from an economic standpoint, "hustling" is a non-productive activity, because it doesn't actually make your content better, it's just an attempt to crowd out someone else's content with your own, which may be better or worse, and it's a zero-sum game. The "hustling" ecosystem is also non-optimal from the user's point of view -- if Joe is better at writing jokes, but Bob is better at hustling, then you as the user are more likely to be exposed to Bob's sub-optimal content, and may never even hear about Joe.
The random-sample rating system, however, makes the entire notion of "hustling" obsolete. The only way to get your content in front of lots of people, is to write content that gets a high average rating from the initial sample of people who see it.
If such a system ever gets implemented, by Twitter or any other company, maybe the Fat Jew can find out if any of his own original material meets the bar. But don't hold your breath -- the marquee joke currently displayed on his Twitter feed is "You can't get an STD if you never get tested."
-
An Algorithm To Stop Joke Plagiarists
Bennett Haselton writes: The comedy world crucified Josh "Fat Jew" Ostrovsky for building his career on re-tweeting other people's jokes without attribution. But Twitter, or whichever company rises as their successor, could easily implement an algorithm that could stop plagiarists from building a following, while still rewarding joke writers who come up with original content. Read on for Bennett's take on how such a system could work.The basic algorithm is very similar to the random-sample-voting algorithm that I've advocated as a way to stop vote manipulation on Digg, how to handle abuse reports in a scalable way on Twitter and on Facebook, and how to identify the best ideas submitted to the White House's "We The People" petition site. The algorithm can be used to rate the best jokes (at least according to the average rating of users, not according to some Platonic ideal), while still flagging plagiarized jokes and preventing anyone from building up a following by using them.
Under the algorithm, suppose a subset of users -- let's say, 1 million -- signs up to receive tweets in the general humor category. When a would-be amateur comedian comes up with a funny tweet, then in addition to tweeting it to their followers (if they have any), they can submit it to the humor category generally. The joke is first pushed to the feeds of, say, 1,000 randomly selected users, who have the option of rating it (independently of each other, without seeing the opinions of other raters). Once the joke has acquired enough ratings to constitute a statistically significant sample -- so that the average rating really does reflect the community's "opinion" of the joke -- then the joke gets released into the general pool of jokes available to all 1 million users subscribed to the "humor" category. Those users can decide what threshold of quality they want to set for the jokes that show up in their feed -- for example, if you only want to see jokes that got an average rating of 9 out of 10 or higher, you might only see 50 a day, but if you can lower your standards down to an 8, you might see 100 or 200. And if a user really likes a particular joke that they see in their "threshold feed," they can browse the other jokes in that author's Twitter feed and decide whether to follow them.
So if your joke sucks, it will only end up wasting the time of about 1,000 people, but if it gets a high rating, it will be available in the feeds of up to 1 million people. Thus from the user's point of view, only about 0.1% of the jokes that they see in their feed, are sucky jokes that were pushed to them as part of an initial "focus group" to measure their quality; the other 99.9% is made up of jokes that met whatever threshold they set for the average rating.
As I've stressed in the case of other applications of the random-sample-voting algorithm, this system is scalable, because the number of available reviewers grows as the community grows. It's also non-gameable -- because the raters are randomly selected, even if you create a large number of zombie accounts to try and upvote your own joke, the zombies won't constitute a significant portion of the raters, if the raters are selected from the entire pool of 1 million users.
Still, even under this system, it would be possible to take a highly rated joke and re-word it slightly (to fool any text filters looking for blatant copy-and-paste jobs), and pass it off as your own, hoping that your re-worded version will also get pushed out to a wide audience and net you some extra followers. To prevent this, you can implement a "duplicate" flagging feature that also relies on the random-sample-voting system:
- If a user recognizes a joke as a re-worded version of someone else's tweet, they can flag it as a "duplicate", with a link to the earlier tweet that they think is similar. (Flagging it as intentional "plagiarism" would be a bit harsh, since it's quite common for multiple comedians to come up with the same joke.)
- The flagged joke, along with a copy of the earlier joke, would once again be sent out to a random sample of subscribers to the humor category, who are then asked to vote on whether the two jokes are substantially similar.
- If a statistically significant majority of those users vote that the two jokes are essentially duplicates, then the second tweet gets displayed with a flag icon (shorthand for "our users have identified this as a duplicate of an earlier joke") with a link back to other tweet that was identified as an earlier version of essentially the same joke.
- If a majority votes that the two jokes are not similar, then nothing happens. Optionally, if an overwhelming majority of the users vote that the two jokes are not at all similar, then some kind of reputation point penalty could be applied to the user who flagged the second joke as a "duplicate". This discourages people from frivolously duplicate-flagging a joke.
This does have the unfortunate result that if you unintentionally write a joke that duplicates someone else's, it will still end up with the "duplicate" flag after users recognize the similarity to the earlier version. This is, however, something that I don't think any algorithm can solve, because it's impossible to detect the difference between someone copying another person's joke and independently coming up with it on their own. A comedian whose joke ends up being labeled with the "duplicate flag", just because someone else came up with the same gag first, could leave the joke in their feed, but they might consider the duplicate flag to be a mild embarrassment.
On the other hand, if you're just a full-time plagiarist like the Fat Jew, and virtually all of your jokes end up being flagged as clones of other people's work, then your entire feed will be littered with "duplicate" flags that mark you as a hack. Depending on whether Twitter's terms of service prohibit serial plagiarism, your account could even get suspended.
Meanwhile, anybody could still set themselves up as a curator who re-tweets other people's jokes with the original attribution intact. Many users would find that they wouldn't need curators at all, when they can just subscribe to all jokes that get an average rating of, say, 8.5 or higher, but if your humor happens to align very closely with the kind of jokes picked out by a particular curator, you could subscribe to get jokes re-tweeted directly from them. And since the original attribution would be intact, any time you saw a joke that you really liked, you could subscribe to updates directly from that author. Curating can still serve a valuable function that plagiarism does not.
In addition to dealing with plagiarists, though, what I think is interesting about this system is how it would overturn everything we know about what it takes to build a reputation. In the current ecosystem, to build a following, it helps to have good content, but what really matters is hustle -- making friends in high places who might be able to give you a boost with a re-tweet or a shout-out, looking out for opportunities for free publicity, etc. Well, I admire the people who have the energy to keep that up. But from an economic standpoint, "hustling" is a non-productive activity, because it doesn't actually make your content better, it's just an attempt to crowd out someone else's content with your own, which may be better or worse, and it's a zero-sum game. The "hustling" ecosystem is also non-optimal from the user's point of view -- if Joe is better at writing jokes, but Bob is better at hustling, then you as the user are more likely to be exposed to Bob's sub-optimal content, and may never even hear about Joe.
The random-sample rating system, however, makes the entire notion of "hustling" obsolete. The only way to get your content in front of lots of people, is to write content that gets a high average rating from the initial sample of people who see it.
If such a system ever gets implemented, by Twitter or any other company, maybe the Fat Jew can find out if any of his own original material meets the bar. But don't hold your breath -- the marquee joke currently displayed on his Twitter feed is "You can't get an STD if you never get tested."
-
California Overturns Uber's Appeal: Its Drivers Are Employees, Not Contractors
An anonymous reader writes: Uber's third attempt to overturn a California court ruling stating that its drivers are employees and not contractors has ended in failure, with the appeal dismissed by the California Employment Development Department (EDD). The California Labor Commission ruled in June on the matter, and in a later appeal one judge effectively decided that the difference between 'firing' a driver and deactivating their account is purely semantic. -
US-Appointed Egg Lobby Paid Food Blogs and Targeted Chef To Crush Vegan Startup
An anonymous reader writes: The American Egg Board targeted publications, popular food bloggers, and a celebrity chef as part of an effort to combat a perceived threat from Hampton Creek, an egg-replacement startup backed by some of Silicon Valley's biggest names, according to internal emails. The Gaurdian reports: A detailed review of emails, sent from inside the AEB and obtained by the Guardian, shows that the lobbyist's anti-Hampton Creek campaign sought to:- Pay food bloggers as much as $2,500 a post to write online recipes and stories about the virtue of eggs that repeated the egg lobby group's "key messages."
- Confront Andrew Zimmern, who had featured Hampton Creek on his popular Travel Channel show Bizarre Foods and praised the company in a blog post characterized by top egg board executives as a "love letter."
- Target publications including Forbes and Buzzfeed that had written broadly positive articles about a Silicon Valley darling.
- Unsuccessfully tried to recruit both the animal rights and autism activist Temple Grandin and the bestselling author and blogger Ree Drummond to publicly support the egg industry.
- Buy Google advertisements to show AEB-sponsored content when people searched for Hampton Creek or its founder Josh Tetrick.
-
White House Petition To Let Foreign STEM Grads Work Longer In US Hits 100K Signatures
theodp writes: Computerworld reports that a petition urging the White House to act urgently on a court ruling that could force thousands of recent foreign STEM graduates working in the U.S. on OPT STEM extensions to leave the States early next year reached 100,000 signatures Tuesday, the threshold for an official government response. It could present a political conundrum of sorts for the Obama administration. Because the administration didn't act to protect U.S. workers at Southern California Edison and Disney, explained an attorney in the case, "now that foreign workers will be losing their jobs, how would it look if Obama went into overdrive to protect their jobs?" By the way, using a map to gauge whether support for the petition comes from all over the country (as the White House suggests), indicates that support for the OPT STEM Extension petition is largely concentrated in tech hotspots and universities, including off-the-beaten-path college towns that host large international student populations. -
Hedgehog Rovers Hop and Tumble In Microgravity
New submitter rgreid writes: Prototypes of a new type of rover designed to explore the surface of comets and asteroids have been demonstrated recently by JPL and Stanford. Videos of the rovers in NASA's "vomit comet" show the Hedgehog prototypes performing hopping and tumbling maneuvers in a low-gravity environment. The low gravity and rough terrains found on comets and asteroids make driving with traditional rovers difficult and hazardous— the Hedgehog rovers are specifically designed to overcome these challenges and use the low gravity environment to their advantage. A last-resort "tornado" maneuver shows how the Hedgehogs could leap upwards if they get stuck in a sinkhole. The team's concept was previously covered in 2013; this recent work goes a long way toward demonstrating that Hedgehog rovers could work on a real comet or asteroid. -
Amazon Stops Selling Fire Phone
An anonymous reader writes: Last June Amazon announced their Fire Phone, an Android device packed with interesting but questionably useful tech that left reviewers unimpressed. Now, just a few weeks after big layoffs in Amazon's Fire Phone division, the phone has gone out of stock globally and seems unlikely to return. GeekWire says it's "an indication that they've finally exhausted their supply and they don't have plans to manufacture anymore." -
Amazon Stops Selling Fire Phone
An anonymous reader writes: Last June Amazon announced their Fire Phone, an Android device packed with interesting but questionably useful tech that left reviewers unimpressed. Now, just a few weeks after big layoffs in Amazon's Fire Phone division, the phone has gone out of stock globally and seems unlikely to return. GeekWire says it's "an indication that they've finally exhausted their supply and they don't have plans to manufacture anymore." -
John McAfee Pondering Presidential Bid
An anonymous reader writes: Since this U.S. presidential election cycle clearly isn't chaotic enough already, it seems John McAfee is now considering a campaign as well. Wired reports that McAfee hasn't decided for sure yet, and he's hoping to persuade somebody more charismatic to run with his backing. He said his advisors are pressing him to run, adding, "I have many thousands of emails saying please run for President. It's not something I would just choose to do on my own." What would his platform be? It actually sounds pretty simple: "It's clear that the leadership of our country is illiterate on the fundamental technology that supports everything in life for us now, that is cyber science, our smartphones, our military hardware, our communications." He'd be a strong proponent for privacy and autonomy. We should know in a few days whether McAfee is in or out — Wired says he "seems far more concerned with having his voice heard on one particular issue than with taking a seat in the Oval Office." Something seems to have changed his mind about politics: in a 2014 interview here, McAfee said. "I would never run for office, neither would I want to be in office, of any kind. I would rather drive a nail through my foot." According to the paperwork McAfee has filed, he is founding a new party (PDF). -
Windows Telemetry Rolls Out
ihtoit writes: Last week came the warning, now comes the roll out. One of the most most controversial aspects of Windows 10 is coming to Windows 7 and 8. Microsoft has released upgrades which enable the company to track what a user is doing. The updates – KB3075249, KB3080149 and KB3068708 – all add "customer experience and diagnostic telemetry" to the older versions. gHacks points out that the updates will ignore any previous user preferences reporting: "These four updates ignore existing user preferences stored in Windows 7 and Windows 8 (including any edits made to the Hosts file) and immediately starts exchanging user data with vortex-win.data.microsoft.com and settings-win.data.microsoft.com." -
DDoS-Style YouTube Dislikes For Sale
An anonymous reader writes: Dell's Joe Stewart chronicles the tale of the YouTube channel that came under attack in the form of an avalanche of 'dislikes' for any videos that touched upon a certain company or even which examined themes around the company's product without mentioning it. The number of dislikes was so disproportionate to the casual number of viewers for the channel, and so concentrated as to constitute a particular type of net-attack — one that appeared to originate in Vietnam. Stewart eschews the notion of a "cottage industry" of Vietnamese YouTube "dislikers" in favor of the fact that any network exploits are eminently reproducible in a country which has only five ISPs among nearly ninety million people — and a widely distributed vulnerable router. -
Why the Black Hole Information Paradox Is Such a Problem
New submitter TheAlexKnapp writes: Here's a really nice explanation of the Black Hole Information Paradox for those who are unfamiliar with it. The article lays out the basic gist — that right now if you take two black holes, one made from the collapse of one type of star, and the second from the collapse of a different type, you can't tell which is which. Ethan Siegel points out that Hawking's big announcement was really just a small step heading towards a possible solution, and highlights that the paradox highlights the incompleteness of our understanding of some types of physics. -
Samsung Unveils Gear S2, Gear S2 Classic Smartwatches Running Tizen
MojoKid writes: Samsung announced their latest smartwatches the other day, the Gear S2 and Gear S2 Classic. At a hands-on press event in New York this week, Samsung had the Gear S2 and Gear S2 Classic up and running. Both of these smartwatches feature 11.4mm-thick casings and 1.2-inch, 360x360 displays that are completely circular, unlike the "flat tire" displays used on the Moto360. At the heart of the Gear S2 is an undisclosed Samsung-sourced 1GHz dual-core processor paired with 512MB of RAM. NFC technology is incorporated into the watches as well, which will support Samsung Pay in the near future. The Gear S2 and Gear S2 Classic are IP68 certified for dust and water resistance and there will be versions with and without integrated 3G connectivity. Both watches feature a rotating ring around the display, in addition to two buttons at the side, intelligently located at 2 and 4 o'clock to minimize accidental actuation, for navigating the various menus and apps. Samsung allows user customization of some watch-faces to show personalized info, and offers dynamic watch-faces with notifications presented on-screen at all times, along with the time. -
Facebook's Solution To 'One of Education's Biggest Problems' Is a Dashboard
theodp writes: Gushing in July that Facebook engineers had solved one of education's biggest problems, Melinda Gates perhaps set up Segway-like expectations for Facebook's education software. And while The Verge sings the praises of what appears to be progress-tracking dashboards that connect students to mostly free 3rd-party lessons — not unlike Khan Academy or even the 50-year-old PLATO system — it's hard to get jazzed based on the screenshots (1, 2, 3) that Facebook provided in a .zip file accompanying its announcement. The "personalized learning plan" dashboards are a joint effort of Facebook and the Meg Whitman-led and backed Summit charter schools. In a nice circle-of-tech-CEO-education-reform-life twist, the first Summit high school opened in a building in Redwood City after students attending the Bill Gates-touted and backed Silicon Valley High Tech High charter there were evicted to make way, and the Gates Foundation is now spending $8M to bring HP CEO Whitman's Summit charter schools — and presumably Facebook CEO Mark Zuckerberg's personalized learning plans — to Seattle children. -
Facebook's Solution To 'One of Education's Biggest Problems' Is a Dashboard
theodp writes: Gushing in July that Facebook engineers had solved one of education's biggest problems, Melinda Gates perhaps set up Segway-like expectations for Facebook's education software. And while The Verge sings the praises of what appears to be progress-tracking dashboards that connect students to mostly free 3rd-party lessons — not unlike Khan Academy or even the 50-year-old PLATO system — it's hard to get jazzed based on the screenshots (1, 2, 3) that Facebook provided in a .zip file accompanying its announcement. The "personalized learning plan" dashboards are a joint effort of Facebook and the Meg Whitman-led and backed Summit charter schools. In a nice circle-of-tech-CEO-education-reform-life twist, the first Summit high school opened in a building in Redwood City after students attending the Bill Gates-touted and backed Silicon Valley High Tech High charter there were evicted to make way, and the Gates Foundation is now spending $8M to bring HP CEO Whitman's Summit charter schools — and presumably Facebook CEO Mark Zuckerberg's personalized learning plans — to Seattle children. -
Facebook's Solution To 'One of Education's Biggest Problems' Is a Dashboard
theodp writes: Gushing in July that Facebook engineers had solved one of education's biggest problems, Melinda Gates perhaps set up Segway-like expectations for Facebook's education software. And while The Verge sings the praises of what appears to be progress-tracking dashboards that connect students to mostly free 3rd-party lessons — not unlike Khan Academy or even the 50-year-old PLATO system — it's hard to get jazzed based on the screenshots (1, 2, 3) that Facebook provided in a .zip file accompanying its announcement. The "personalized learning plan" dashboards are a joint effort of Facebook and the Meg Whitman-led and backed Summit charter schools. In a nice circle-of-tech-CEO-education-reform-life twist, the first Summit high school opened in a building in Redwood City after students attending the Bill Gates-touted and backed Silicon Valley High Tech High charter there were evicted to make way, and the Gates Foundation is now spending $8M to bring HP CEO Whitman's Summit charter schools — and presumably Facebook CEO Mark Zuckerberg's personalized learning plans — to Seattle children. -
Report: Google Will Return To China
An anonymous reader writes: Google famously withdrew from mainland China in 2010 after fending off a series of cyberattacks from local sources. Now, according to a (paywalled) report from The Information, the company is working on plans to return. "As part of the deal Google is looking to strike, Google would follow the country's laws and block apps that the government objects to, one person told The Information." They're also seeking approval for a Chinese version of Google Play. -
Pentagon Halts Work at Labs For Dangerous Pathogens After Anthrax Scare
An anonymous reader writes: The Pentagon announced yesterday it is issuing a moratorium on work at nine different biodefense labs after live anthrax was discovered outside containment at Dugway Proving Ground in Utah. The facility was discovered to have been shipping live anthrax specimens — instead of dead ones — to other labs. Work can only begin again after the shuttered facilities are certain to be clean of anthrax and assured of safe conduct. "The review calls for the military labs to ensure that personnel are properly trained on lab safety procedures and that necessary maintenance is conducted on biosafety level 3 lab facilities that work with some of the most dangerous pathogens. It calls for validating record-keeping and inventories of the military's 'Critical Reagents Program' — including 'ensuring that all materials associated with the CRP are properly accounted for.'" -
ThinkGeek Opens First Physical Store In Orlando
New submitter Enderxeno writes with news that on September 25th, geek merchandise retailer ThinkGeek will open its first brick-and-mortar store in Orlando, Florida. The store will open in a mall, and the company will be running it with the help of GameStop, who bought ThinkGeek back in June. The new store will have a 3,000 square foot space that used to be occupied by Radio Shack, and it will focus "entirely on collectibles." (Disclosure: Slashdot and ThinkGeek used to share a corporate overlord. We don't talk anymore, but we still like them. Even though they finally took away our employee discounts.) -
Survey: More Women Are Going Into Programming
itwbennett writes: We've previously discussed the dearth of women in computing. Indeed, according to U.S. Bureau and Labor Statistics estimates, in 2014 four out of five programmers and software developers in the U.S. were men. But according to a survey conducted this spring by the Application Developers Alliance and IDC, that may be changing. The survey of 855 developers worldwide found that women make up 42% of developers with less than 1 year of experience and 30% of those with between 1 and 5 years of experience. Of course, getting women into programming is one thing; keeping them is the next big challenge. -
New Russian Laboratory To Study Mammoth Cloning
An anonymous reader writes: While plans to clone a woolly mammoth are not new, a lab used in a joint effort by Russia and South Korea is. The new facility is devoted to studying extinct animal DNA in the hope of creating clones from the remains of animals found in the permafrost. IBtimes reports: "The Sakha facility has the world's largest collection of frozen ancient animal carcasses and remains, with more than 2,000 samples in its possession, including some that are tens of thousands years old, such as a mammoth discovered on the island of Maly Lyakhovsky; experts believe it may be more than 28,000 years old."
-
New Russian Laboratory To Study Mammoth Cloning
An anonymous reader writes: While plans to clone a woolly mammoth are not new, a lab used in a joint effort by Russia and South Korea is. The new facility is devoted to studying extinct animal DNA in the hope of creating clones from the remains of animals found in the permafrost. IBtimes reports: "The Sakha facility has the world's largest collection of frozen ancient animal carcasses and remains, with more than 2,000 samples in its possession, including some that are tens of thousands years old, such as a mammoth discovered on the island of Maly Lyakhovsky; experts believe it may be more than 28,000 years old."
-
New Russian Laboratory To Study Mammoth Cloning
An anonymous reader writes: While plans to clone a woolly mammoth are not new, a lab used in a joint effort by Russia and South Korea is. The new facility is devoted to studying extinct animal DNA in the hope of creating clones from the remains of animals found in the permafrost. IBtimes reports: "The Sakha facility has the world's largest collection of frozen ancient animal carcasses and remains, with more than 2,000 samples in its possession, including some that are tens of thousands years old, such as a mammoth discovered on the island of Maly Lyakhovsky; experts believe it may be more than 28,000 years old."
-
New Russian Laboratory To Study Mammoth Cloning
An anonymous reader writes: While plans to clone a woolly mammoth are not new, a lab used in a joint effort by Russia and South Korea is. The new facility is devoted to studying extinct animal DNA in the hope of creating clones from the remains of animals found in the permafrost. IBtimes reports: "The Sakha facility has the world's largest collection of frozen ancient animal carcasses and remains, with more than 2,000 samples in its possession, including some that are tens of thousands years old, such as a mammoth discovered on the island of Maly Lyakhovsky; experts believe it may be more than 28,000 years old."
-
More Popcorn Time Users Sued
An anonymous reader writes: The torrent-based video streaming software Popcorn Time has been in the news lately as multiple entities have initiated legal action over its use. Now, 16 Oregon-based Comcast subscribers have been targeted for their torrenting of the movie Survivor. The attorney who filed the lawsuit (PDF) says his client, Survivor Productions Inc., doesn't plan to seek any more than the minimum $750 fine, and that their goal is to "deter infringement." The lawsuit against these Popcorn Time users was accompanied by 12 other lawsuits targeting individuals who acquired copies of the movie using more typical torrenting practices. -
More Popcorn Time Users Sued
An anonymous reader writes: The torrent-based video streaming software Popcorn Time has been in the news lately as multiple entities have initiated legal action over its use. Now, 16 Oregon-based Comcast subscribers have been targeted for their torrenting of the movie Survivor. The attorney who filed the lawsuit (PDF) says his client, Survivor Productions Inc., doesn't plan to seek any more than the minimum $750 fine, and that their goal is to "deter infringement." The lawsuit against these Popcorn Time users was accompanied by 12 other lawsuits targeting individuals who acquired copies of the movie using more typical torrenting practices. -
Comcast To Charge $30 For Unlimited Data Over 300GB Cap
For some time, Comcast has been testing 300 GB monthly data caps in certain markets. An anonymous reader notes a policy change unveiled today that gives customers in those markets the ability to switch back to unlimited data for $30 extra. Previously (and currently, for customers who don't pay the extra $30), Comcast would charge $10 per 50GB above the cap. "Comcast's intent on this front has been clear for some time. Comcast lobbyist and VP David Cohen last year strongly suggested that usage caps would be arriving for all Comcast customers sooner or later. The idea of charging users a premium to avoid arbitrary usage restrictions has been a pipe dream of incumbent ISP executives for a decade." The new policy goes into effect on October 1. -
Mozilla, Microsoft, Amazon, Google, and Others Form 'Alliance For Open Media'
BrianFagioli tips news that Mozilla, Microsoft, Google, Cisco, Intel, Amazon, and Netflix are teaming up to create the Alliance for Open Media, "an open-source project that will develop next-generation media formats, codecs and technologies in the public interest." Several of these companies have been working on this problem alone: Mozilla started Daala, Google has VP9 and VP10, and Cisco just recently announced Thor. Amazon and Netflix, of course, are major suppliers of online video streaming, so they have a vested interested in royalty-free codecs. They're inviting others to join them — the more technology and patents they get on their side, the less likely they'll run into the issues that Microsoft's VC-1 and Google's VP8 struggled with. "The Alliance will operate under W3C patent rules and release code under an Apache 2.0 license. This means all Alliance participants are waiving royalties both for the codec implementation and for any patents on the codec itself." -
Carbon Dating Shows Koran May Predate Muhammad
HughPickens.com writes: Brian Booker writes at Digital Journal that carbon dating suggests the Koran, or at least portions of it, may actually be older than the prophet Muhammad himself, a finding that if confirmed could rewrite early Islamic history and shed doubt on the "heavenly" origins of the holy text. Scholars believe that a copy of the Koran held by the Birmingham Library was actually written sometime between 568 AD and 645, while the Prophet Mohammad was believed to have been born in 570 AD and to have died in 632 AD. It should be noted, however, that the dating was only conducted on the parchment, rather than the ink, so it is possible that the Koran was simply written on old paper. Some scholars believe, however, that Muhammad did not receive the Koran from heaven, as he claimed during his lifetime, but instead collected texts and scripts that fit his political agenda. "This gives more ground to what have been peripheral views of the Koran's genesis, like that Muhammad and his early followers used a text that was already in existence and shaped it to fit their own political and theological agenda, rather than Muhammad receiving a revelation from heaven," says Keith Small, from the University of Oxford's Bodleian Library. "'It destabilises, to put it mildly, the idea that we can know anything with certainty about how the Koran emerged," says Historian Tom Holland. "and that in turn has implications for the history of Muhammad and the Companions." Update: 09/01 17:32 GMT by S : There was a typo in the dates used by the original linked article — in the press release from the University of Birmingham, the date range given for the parchment is between 568 AD and 645 AD, which overlaps more closely with Muhammad's lifetime. The dates and link have been fixed now in the summary. Historians say this new information highlights the uncertainty surrounding the emergence of such religious texts, rather than being a major upheaval. -
Book Review: Effective Python: 59 Specific Ways To Write Better Python
MassDosage writes: If you are familiar with the "Effective" style of books then you probably already know how this book is structured. If not here's a quick primer: the book consists of a number of small sections each of which focus on a specific problem, issue or idea and these are discussed in a "here's the best way to do X" manner. These sections are grouped into related chapters but can be read in pretty much any order and generally don't depend on each other (and when they do this will be called out in the text). The idea is that you can read the book from cover to cover if you want but you can also just dip in and out and read only the sections that are of interest to you. This also means that you can use the book as a reference in future when you inevitably forget the details or want to double check something. Read below for the rest of Mass Dosage's review. Effective Python: 59 Specific Ways To Write Better Python author Brett Slatkin pages 227 publisher Addison-Wesley rating 9/10 reviewer Mass Dosage ISBN 978-0-13-403428-7 summary helps you harness the full power of Python to write exceptionally robust, efficient, maintainable, and well-performing code. Effective Python stays true to this ethos and delivers 59 (not 60, nope, not 55) but 59 specific ways to write better Python. These are logically grouped into chapters covering broader conceptual topics like "Pythonic thinking", general technical features like "Concurrency and parallelism" as well as nitty gritty language details like "Meta classes and attributes". The range of topics is excellent and cover relevant aspects of the language that I'd imagine pretty much any developer will encounter at some point while developing Python programs. Even though there is no required order to reading the various sections if you want to read the book from cover to cover it's organized in such a way that you can do this. It starts off with getting your head around coding in Python before moving on to specifics of the language and then ending with advice on collaboration and setting up and running Python programs in production environments.
I really enjoyed the author's approach to each of the topics covered. He explains each item in a very thorough and considered manner with plenty of detail but manages to do this while still being clear and concise. Where relevant he describes multiple ways of achieving a goal while contrasting the pros and cons of various alternative solutions, ending off with what he considers the preferred approach. The reader can then make up their own mind based on the various options which applies best in a given situation instead of just being given one solution. The author clearly understand the internals of the Python language and the philosophy behind some of the design decisions that have resulted in certain features. This means that instead of just offering a solution he also gives you the context and reasoning behind things which I found made it a lot easier to understand. The discussions and reasoning feel balanced and informed by the experience of a developer who has been doing this "in the trenches" for years as opposed to someone in an ivory tower issuing dictates which sound good in theory but don't actually work in the real world. The vast majority of the topics are illustrated through code samples which are built on and modified at each stage along the way to a final solution. This gives the reader something practical they can take away and use and experiment with and clearly shows how something is done. The code samples are easily comprehensible with just enough code to demonstrate a point but not so much that you get distracted by unnecessary additions.
While most of the topics are Python specific plenty of the best practices and advice apply equally well to other programming languages. For example in one section the author recommends resisting some of the brevity offered by the Python where this can lead to unreadable code that is hard to understand but the same could be said of writing code in many other languages (I'm looking at you, Perl). This also applies to a section related to choosing the best data structure for the problem at hand — if you end up nesting Maps within Maps in your code then you're probably doing something wrong regardless of the language. Still, the main focus here is Python and the author does not shy away from going deep into technical details so you'll definitely need some knowledge of the language and ideally some experience using it in order to get the most out of it.
Effective Python is not a book for complete newbies to Python and I think it's suited more to intermediate users of the language wanting to take their skills to the next level or advanced programmers who might need some fresh takes on the way they do things. The subjects and opinions in this book could either convince you to do something differently or reassure you of the reasons why you're already doing things a certain way (external affirmation that you're right is also useful at times!) I'm no Python expert but I found the book drew me in and kept my attention and I certainly learnt a lot which will come in handy the next time I put on my Pythonista hat and do some Python coding. Highly recommended.
You can purchase Effective Python: 59 Specific Ways to Write Better Python from amazon.com. Slashdot welcomes readers' book reviews (sci-fi included) -- to see your own review here, read the book review guidelines, then visit the submission page. If you'd like to see what books we have available from our review library please let us know. -
Book Review: Effective Python: 59 Specific Ways To Write Better Python
MassDosage writes: If you are familiar with the "Effective" style of books then you probably already know how this book is structured. If not here's a quick primer: the book consists of a number of small sections each of which focus on a specific problem, issue or idea and these are discussed in a "here's the best way to do X" manner. These sections are grouped into related chapters but can be read in pretty much any order and generally don't depend on each other (and when they do this will be called out in the text). The idea is that you can read the book from cover to cover if you want but you can also just dip in and out and read only the sections that are of interest to you. This also means that you can use the book as a reference in future when you inevitably forget the details or want to double check something. Read below for the rest of Mass Dosage's review. Effective Python: 59 Specific Ways To Write Better Python author Brett Slatkin pages 227 publisher Addison-Wesley rating 9/10 reviewer Mass Dosage ISBN 978-0-13-403428-7 summary helps you harness the full power of Python to write exceptionally robust, efficient, maintainable, and well-performing code. Effective Python stays true to this ethos and delivers 59 (not 60, nope, not 55) but 59 specific ways to write better Python. These are logically grouped into chapters covering broader conceptual topics like "Pythonic thinking", general technical features like "Concurrency and parallelism" as well as nitty gritty language details like "Meta classes and attributes". The range of topics is excellent and cover relevant aspects of the language that I'd imagine pretty much any developer will encounter at some point while developing Python programs. Even though there is no required order to reading the various sections if you want to read the book from cover to cover it's organized in such a way that you can do this. It starts off with getting your head around coding in Python before moving on to specifics of the language and then ending with advice on collaboration and setting up and running Python programs in production environments.
I really enjoyed the author's approach to each of the topics covered. He explains each item in a very thorough and considered manner with plenty of detail but manages to do this while still being clear and concise. Where relevant he describes multiple ways of achieving a goal while contrasting the pros and cons of various alternative solutions, ending off with what he considers the preferred approach. The reader can then make up their own mind based on the various options which applies best in a given situation instead of just being given one solution. The author clearly understand the internals of the Python language and the philosophy behind some of the design decisions that have resulted in certain features. This means that instead of just offering a solution he also gives you the context and reasoning behind things which I found made it a lot easier to understand. The discussions and reasoning feel balanced and informed by the experience of a developer who has been doing this "in the trenches" for years as opposed to someone in an ivory tower issuing dictates which sound good in theory but don't actually work in the real world. The vast majority of the topics are illustrated through code samples which are built on and modified at each stage along the way to a final solution. This gives the reader something practical they can take away and use and experiment with and clearly shows how something is done. The code samples are easily comprehensible with just enough code to demonstrate a point but not so much that you get distracted by unnecessary additions.
While most of the topics are Python specific plenty of the best practices and advice apply equally well to other programming languages. For example in one section the author recommends resisting some of the brevity offered by the Python where this can lead to unreadable code that is hard to understand but the same could be said of writing code in many other languages (I'm looking at you, Perl). This also applies to a section related to choosing the best data structure for the problem at hand — if you end up nesting Maps within Maps in your code then you're probably doing something wrong regardless of the language. Still, the main focus here is Python and the author does not shy away from going deep into technical details so you'll definitely need some knowledge of the language and ideally some experience using it in order to get the most out of it.
Effective Python is not a book for complete newbies to Python and I think it's suited more to intermediate users of the language wanting to take their skills to the next level or advanced programmers who might need some fresh takes on the way they do things. The subjects and opinions in this book could either convince you to do something differently or reassure you of the reasons why you're already doing things a certain way (external affirmation that you're right is also useful at times!) I'm no Python expert but I found the book drew me in and kept my attention and I certainly learnt a lot which will come in handy the next time I put on my Pythonista hat and do some Python coding. Highly recommended.
You can purchase Effective Python: 59 Specific Ways to Write Better Python from amazon.com. Slashdot welcomes readers' book reviews (sci-fi included) -- to see your own review here, read the book review guidelines, then visit the submission page. If you'd like to see what books we have available from our review library please let us know. -
Ask Slashdot: What Would You Do If You Were Suddenly Wealthy?
An anonymous reader writes: There are a few articles floating around today about comments from Markus Persson, aka "Notch," the creator of Minecraft. He sold his game studio to Microsoft last year for $2.5 billion, but he seems to be having a hard time adjusting to his newfound fame and wealth. He wrote, "The problem with getting everything is you run out of reasons to keep trying, and human interaction becomes impossible due to imbalance. ... Found a great girl, but she's afraid of me and my life style and went with a normal person instead. I would Musk and try to save the world, but that just exposes me to the same type of a$#@%&*s that made me sell minecraft again." While he later suggests he was just having a bad day, he does seem to be dealing with some isolation issues. Granted, it can be hard to feel sorry for a billionaire, but I've wondered at times how I'd handle sudden wealth like that, and I long ago decided it would make the human relationships I'm accustomed to rather difficult. So, how would you deal with Notch's problem? It seems like one the tech industry should at least be aware of, given the focus on startup culture. -
Google Facing Fine of Up To $1.4 Billion In India Over Rigged Search Results
An anonymous reader writes: The Competition Commission of India has opened an investigation into Google to decide whether the company unfairly prioritized search results to its own services. Google could face a fine of up to $1.4 billion — 10% of its net income in 2014. A number of other internet companies, including Facebook and FlipKart, responded to queries from the CCI by confirming that Google does this. "The CCI's report accuses Google of displaying its own content and services more prominently in search results than other sources that have higher hit rates. It also states that sponsored links shown in search results are dependent on the amount of advertising funds Google receives from its clients. Ecommerce portal Flipkart noted that it found search results to have a direct correlation with the amount of money it spent on advertising with Google." The company has faced similar antitrust concerns in the EU and the U.S -
Google Facing Fine of Up To $1.4 Billion In India Over Rigged Search Results
An anonymous reader writes: The Competition Commission of India has opened an investigation into Google to decide whether the company unfairly prioritized search results to its own services. Google could face a fine of up to $1.4 billion — 10% of its net income in 2014. A number of other internet companies, including Facebook and FlipKart, responded to queries from the CCI by confirming that Google does this. "The CCI's report accuses Google of displaying its own content and services more prominently in search results than other sources that have higher hit rates. It also states that sponsored links shown in search results are dependent on the amount of advertising funds Google receives from its clients. Ecommerce portal Flipkart noted that it found search results to have a direct correlation with the amount of money it spent on advertising with Google." The company has faced similar antitrust concerns in the EU and the U.S -
Metal Gear Solid V PC Disc Contains Steam Installer, Nothing Else
dotarray writes: The boxed copy of Metal Gear Solid V: The Phantom Pain reportedly contains nothing but a Steam installer. That's right, even if you fork out real-world money for a physical copy of the game, you'll still have to download the whole thing from the internet. The game officially launches tomorrow. Early critical reviews are quite positive, though you should take that with a grain of salt until the game is more widely distributed. Game Informer says, "Unlike the linear design of previous entries, The Phantom Pain rarely assumes you have particular weapons and equipment, so the missions are brilliantly designed with multiple paths to success." The Washington Post notes, "The Phantom Pain’s openness feels like Kojima finally found a technical platform broad enough to make use of all of those tools and trusts players to build their own narrative drama from the way they choose to put these tools together for each mission." IGN has this criticism: "... where Phantom Pain’s gameplay systems are far richer and meatier than any the series has ever seen, its story feels insubstantial and woefully underdeveloped by comparison." Metal Gear Solid 5 is launching for PCs, current consoles, and previous-gen consoles; Digital Foundry thinks is likely to be the last true cross-generation AAA title. -
OnHub Router -- Google's Smart Home Trojan Horse?
An anonymous reader writes: A couple weeks ago, Google surprised everybody by announcing a new piece of hardware: the OnHub Wi-Fi router. It packs a ton of processing power and a bunch of wireless radios into a glowy cylinder, and they're going to sell it for $200, which is on the high end for home networking equipment. Google sent out a number of units for testing, and the reviews are starting to come out. The device is truly Wi-Fi-centric, with only a single port for an ethernet cable. It runs on a Qualcomm IPQ8064 dual-core 1.4GHz SoC with 1GB of RAM and 4GB of storage. You can only access the router's admin settings by using the associated app on a mobile device.
OnHub's data transfer speeds couldn't compete with a similarly priced Asus router, but it had no problem blanketing the area with a strong signal. Ron Amadeo puts his conclusion simply: "To us, this looks like Google's smart home Trojan horse." The smartphone app that accompanies OnHub has branding for something called "Google On," which they speculate is Google's new hub for smart home products. "There are tons of competing smart home protocols out there, all of which are incompatible with one another—imagine HD-DVD versus Blu-Ray, but with about five different players. ... Other than Bluetooth and Wi-Fi, everything in OnHub is a Google/Nest/Alphabet protocol. And remember, the "Built for Google On" stamp on the bottom of the OnHub sure sounds like a third-party certification program." -
NSF Makes It Rain: $722K Award To Evaluate Microsoft-Backed TEALS
theodp writes: Microsoft has $92 billion in cash parked offshore, so it's kind of surprising to see a $722K National Science Foundation award is going towards validating the efficacy of Microsoft TEALS, the pet program of CEO Satya Nadella that sends volunteer software engineers with no teaching experience into high schools to teach kids and their teachers computer science. Among its Program Changes for 2015, TEALS said it "explicitly commits to provide a core set of curriculum materials that are complete, organized, and adaptable," which should help improve the outcome of the Developing Computer Science Pedagogical Content Knowledge through On-the-Job Learning NSF study schools are being asked to participate in. Meanwhile, CSTUY, a volunteer organization led by experienced CS teachers (including Slashdot user zamansky), finds itself turning to Kickstarter for $25K to fund Saturday Hacking Sessions. So, as Microsoft-backed Code.org — which has also attracted NSF award money to validate its CS program — is fond of saying: What's wrong with this picture? (To be fair to TEALS: it may have Microsoft backing, but it's not strictly a Microsoft effort, and also started out as a pure volunteer effort, as founder Kevin Wang explained earlier this year.) -
Linux Kernel 4.2 Released
An anonymous reader writes: The Linux 4.2 kernel is now available. This kernel is one of the biggest kernel releases in recent times and introduces rewrites of some of the kernel's Intel Assembly x86 code, new ARM board support, Jitter RNG improvements, queue spinlocks, the new AMDGPU kernel driver, NCQ TRIM handling, F2FS per-file encryption, and many other changes to benefit most Linux users. -
AMD's R9 Fury On Open-Source: Prepare for Disappointment, For Now
An anonymous reader writes: With Linux 4.3 AMD is adding the initial open-source driver for the R9 Fury graphics cards. Unfortunate for Linux gamers, the R9 Fury isn't yet in good shape on the open-source driver and it's not good with the Catalyst Linux driver either as previously discussed. With the initial code going into Linux 4.3, the $550 R9 Fury runs slower than graphics cards like the lower-cost and older R7 370 and HD 7950 GPUs, since AMD's open-source developers haven't yet found the time to implement power management / re-clocking support. The R9 Fury also only advertises OpenGL 3.0 support while the hardware is GL4.5-capable and the other open-source AMD GCN driver ships OpenGL 4.1. It doesn't look like AMD has any near-term R9 Fury Linux fix for either driver, but at least their older hardware is performing well with the open-source code. -
AMD's R9 Fury On Open-Source: Prepare for Disappointment, For Now
An anonymous reader writes: With Linux 4.3 AMD is adding the initial open-source driver for the R9 Fury graphics cards. Unfortunate for Linux gamers, the R9 Fury isn't yet in good shape on the open-source driver and it's not good with the Catalyst Linux driver either as previously discussed. With the initial code going into Linux 4.3, the $550 R9 Fury runs slower than graphics cards like the lower-cost and older R7 370 and HD 7950 GPUs, since AMD's open-source developers haven't yet found the time to implement power management / re-clocking support. The R9 Fury also only advertises OpenGL 3.0 support while the hardware is GL4.5-capable and the other open-source AMD GCN driver ships OpenGL 4.1. It doesn't look like AMD has any near-term R9 Fury Linux fix for either driver, but at least their older hardware is performing well with the open-source code. -
Malaysia Blocking Websites Based On Political Content
An anonymous reader writes: A few days ago Slashdot carried a piece of news from Malaysia whereby [news] websites based in Malaysia must be registered. Now comes the news that Malaysia is actively blocking websites which carry political opinion contrary to those of the ruling elite. Granted, Malaysia is no US of A nor Europe, but the world must understand that Malaysia is the only country in the world where racial apartheid laws are still being actively practiced — and have received endorsement from the ruling elite which has controlled Malaysia for the past 58 years. (Wikipedia lists some other candidates for modern-day apartheid in its entry on Contemporary segregation.) -
Kristian von Bengston's New Goal: The Moon
Kristian von Bengtson, co-founder of DIY manned space program Copenhagen Suborbitals (which he left in 2014) writes with this pithy plug for his newest venture: "This year, we (a great crew) have been preparing for the next adventure with a mission plan going public Oct 1. Go sign up and join the project at moonspike.com." (You may want to check out our video inteview with von Bengston; he's a person who gets things done.) -
Uber Hires Hackers Who Remotely Killed a Jeep
An anonymous reader writes: The past several weeks have been rife with major vulnerabilities in modern cars, but none were so dramatic as when Charlie Miller and Chris Valasek tampered with the systems on a moving Jeep Cherokee. Now, Miller and Valasek have left their jobs to join a research laboratory for Uber. It's the same lab that became home for a number of autonomous vehicle experts poached from Carnegie Mellon University. From the article: "As Uber plunges more deeply into developing or adapting self-driving cars, Miller and Valasek could help the company make that technology more secure. Uber envisions autonomous cars that could someday replace its hundreds of thousands of contract drivers. The San Francisco company has gone to top-tier universities and research centers to build up this capability."
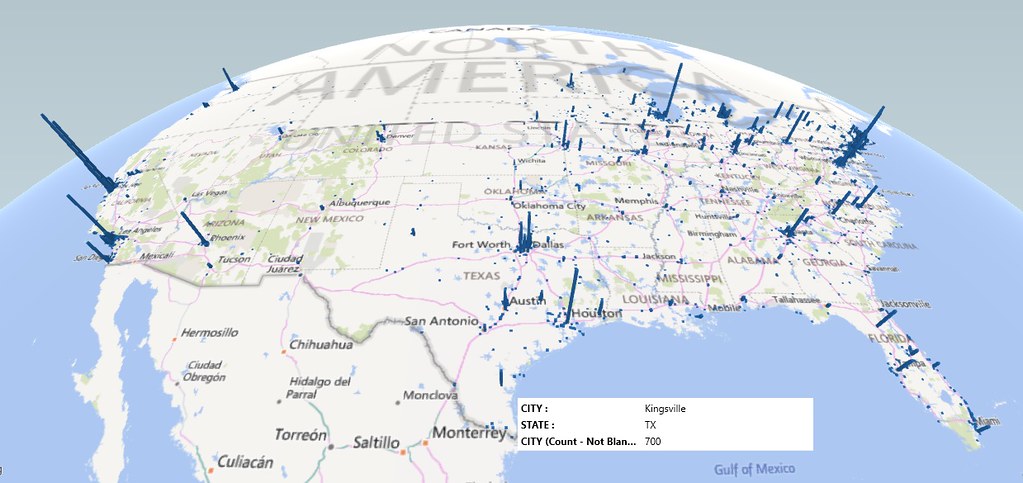{kind=link}
{kind=link}
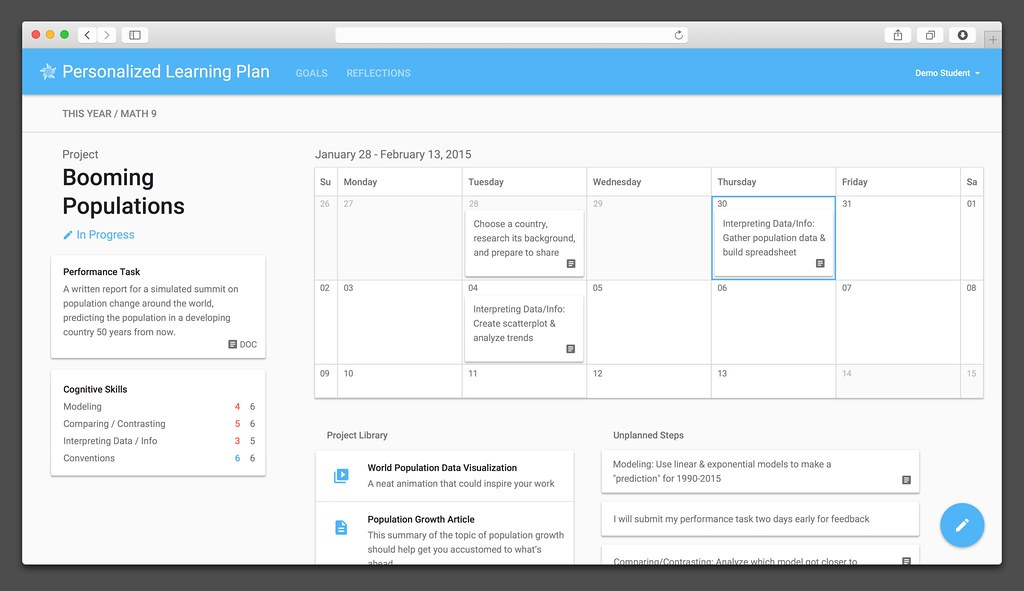{kind=link}
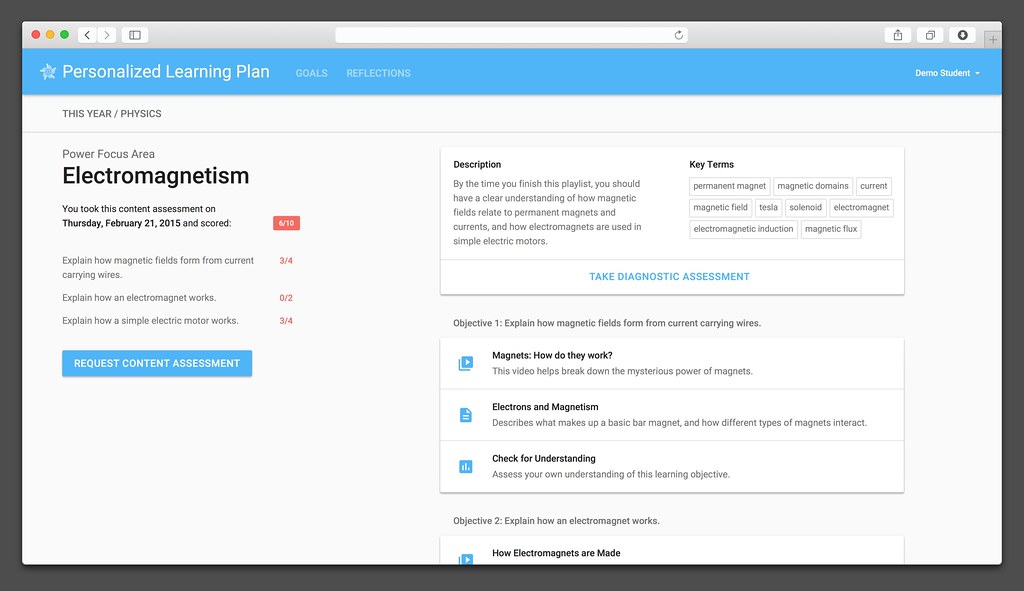{kind=link}